Привет, Хабр!
Мы раскупорили последние резервы книги "Apache Kafka. Потоковая обработка и анализ данных" и отправили ее в допечатку. Более того, мы получили контракт на книгу "Kafka Streams in Action" и приступаем к ее переводу буквально на будущей неделе.

Чтобы показать занятный кейс использования библиотеки Kafka Streams, мы решили перевести статью о парадигме Event Sourcing в Kafka от того самого Адама Уорски, чья статья о языке Scala выходила у нас две недели назад. Тем интереснее, что мнение Адама Уорски не бесспорное: вот здесь, например, утверждается, что эта парадигма решительно для Kafka не подходит. Тем более запоминающимся, надеемся, получится впечатление от статьи.
Термин «Event Sourcing» переведен как «Регистрация событий» и в нашем издании "Чистой архитектуры" Роберта Мартина, и в данной статье. Если кому-нибудь импонирует перевод «прокачка событий» — дайте знать пожалуйста.
Создавая систему, в которой предусмотрена регистрация событий (event sourcing), мы рано или поздно сталкиваемся с проблемой сохраняемости (persistence) – и здесь у нас возникает пара вариантов. Во-первых, есть EventStore, зрелая реализация, закаленная в боях. В качестве альтернативы можно задействовать akka-persistence, чтобы на полную мощность использовать масштабируемость Cassandra, а также опираться на производительность акторной модели. Другой вариант – старая добрая реляционная база данных, где подход
Кроме этих (и, пожалуй, многих других) возможностей, появившихся благодаря нескольким недавно реализованным вещам, сегодня стало весьма просто организовать регистрацию событий и поверх Kafka. Давайте рассмотрим как.
Что такое регистрация событий?
На эту тему есть ряд отличных вводных статей, поэтому я ограничусь максимально кратким введением. При регистрации событий мы сохраняем не «текущее» состояние сущностей, используемых в нашей системе, а поток событий, относящихся к этим сущностям. Каждое событие — это факт, описывающий изменение состояния, (уже!) произошедшее с объектом. Как известно, факты не обсуждаются и неизменны.
Когда у нас поток таких событий, актуальное состояние сущности можно выяснить, свернув все относящиеся к нему события; однако, учтите, что обратное невозможно – сохраняя лишь «актуальное» состояние, мы отбрасываем массу ценной хронологической информации.
Регистрация событий может мирно сосуществовать с более традиционными способами хранения состояния. Как правило, система обрабатывает ряд типов сущностей (например: пользователи, заказы, товары, …) и вполне возможно, что регистрация событий окажется целесообразна лишь для некоторых из этих категорий. Важно отметить, что здесь перед нами не стоит выбор «все или ничего»; речь просто о дополнительной возможности управления состоянием в нашем приложении.
Хранение событий в Kafka
Первая проблема, которую необходимо решить: как хранить события в Kafka? Есть три возможные стратегии:
Третья стратегия (по-топику-на-сущность) практически неосуществима. Если при появлении в системе каждого нового пользователя на него приходилось бы заводить отдельный топик, вскоре количество топиков стало бы неограниченным. Любая агрегация в таком случае оказалась бы очень сложна, например, было бы трудно индексировать всех пользователей в поисковике; мало того, что при этом пришлось бы потреблять огромное количество топиков – так еще бы и не все из них были известны заранее.
Поэтому остается выбирать между 1 и 2. У обоих вариантов есть свои достоинства и недостатки. Имея единственный топик, проще получить глобальное представление обо всех событиях. С другой стороны, выделяя по топику на каждый тип сущностей, можно масштабировать и сегментировать поток каждой сущности в отдельности. Выбор одной из двух стратегий зависит от конкретного варианта использования.
Кроме того, можно внедрить и обе стратегии сразу, если у вас есть дополнительное пространство в хранилище: производить топики по типу сущностей из одного всеобъемлющего топика.
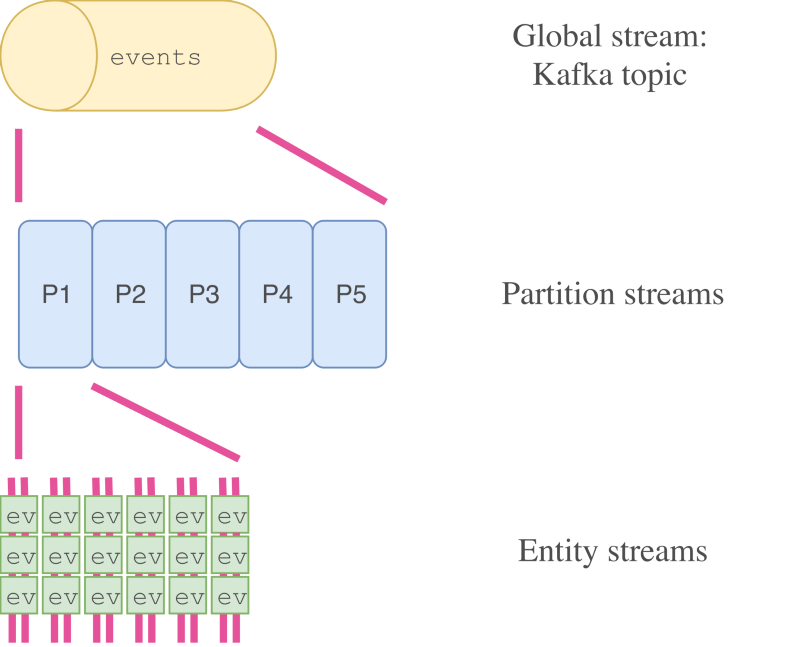
В оставшейся части статьи мы будем работать всего с одним типом сущностей и с единственным топиком, хотя, изложенный материал легко экстраполировать и применить для работы со множеством топиков или типов сущностей.
(РЕД.: как отмечал Крис Хант, есть отличная статья Мартина Клеппмана, где детально рассмотрено, как распределять события по топикам и сегментам).
Простейшие операции с хранилищем в парадигме регистрации событий
Простейшая операция, которую логично ожидать от хранилища, поддерживающего регистрацию событий – считывание «текущего» (свернутого) состояния конкретной сущности. Как правило, каждая сущность имеет тот или иной
Истиной в последней инстанции нам послужит лог событий: актуальное состояние всегда можно вывести из потока событий, связанных с конкретной сущностью. Для этого движку базу данных потребуется чистая функция (без побочных эффектов), принимающая событие и исходное состояние, и возвращающая измененное состояние:
Упрощенная реализация операции “считывания текущего состояния” в Kafka собирает поток из всех событий из топика, фильтрует их, оставляя лишь события с заданным
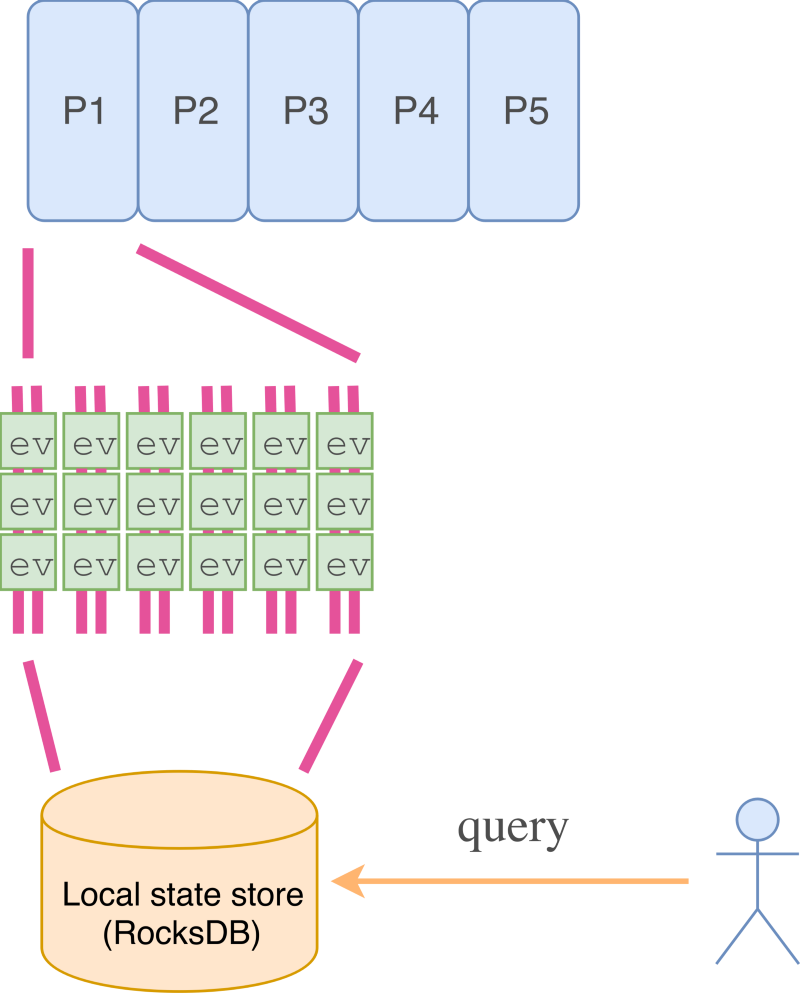
Поэтому нужен более рациональный способ. Именно здесь нам и пригодятся kafka-streams и хранилища состояний. Приложения Kafka-streams работают на целом кластере узлов, совместно потребляющих определенные топики. Каждому узлу присваивается ряд сегментов потребляемых топиков, точно как и в случае с обычным консьюмером Kafka. Однако, в kafka-streams предоставляются более высокоуровневые операции над данными, при помощи которых гораздо проще создавать производные потоки.
Одна из таких операций в kafka-streams – это свертка потока в локальном хранилище. В каждом локальном хранилище содержатся данные лишь из тех сегментов, что потребляются заданным узлом. «Из коробки» доступны две реализации локальных хранилищ: в оперативной памяти и на основе RocksDB.
Возвращаясь к теме регистрации событий, отметим, что можно свернуть поток событий в хранилище состояний, держа на локальном узле «текущее состояние» каждой сущности из сегментов, присваиваемых узлу. Если мы используем реализацию хранилища состояний на основе RocksDB, то лишь от объема дискового пространства зависит, сколько сущностей мы сможем отслеживать на отдельно взятом узле.
Вот как выглядит свертка событий в локальное хранилище при использовании Java API (serde означает «сериализатор/десериализатор»):
Полный пример с обработкой заказов на основе микросервисов доступен на сайте Confluent.
(РЕД.: по замечанию Сергея Егорова и Никиты Сальникова в Twitter, для системы с регистрацией событий, вероятно, потребуется изменить задаваемые в Kafka по умолчанию настройки хранения данных, чтобы не действовали никакие пределы ни по времени, ни по размеру, а также, опционально, включить сжатие данных.)
Просмотр текущего состояния
Мы создали хранилище состояний, где находятся актуальные состояния всех сущностей, поступающих из сегментов, присвоенных узлу, но как теперь запрашивать это хранилище? Если запрос локальный (то есть, исходит с того же узла, на котором находится хранилище), то все довольно просто:
Но что, если мы хотим запросить данные, расположенные на другом узле? И как выяснить, что это за узел? Здесь нам пригодится еще одна возможность, недавно появившаяся в Kafka: интерактивные запросы. С их помощью можно обращаться к метаданным Kafka и выяснять, какой узел обрабатывает сегмент топика с заданным
Далее нужно как-то переадресовать запрос на правильный узел. Обратите внимание: конкретный способ, которым реализуется и обрабатывается межузловая коммуникация — будь то REST, akka-remote или любой другой — не относится к зоне ответственности kafka-streams. Kafka просто обеспечивает доступ к хранилищу состояний и предоставляет информацию о том, на каком узле расположено хранилище состояний для заданного
Восстановление после отказа
Хранилища состояний выглядят симпатично, но что произойдет при отказе узла? Воссоздание локального хранилища состояний для того или иного сегмента также может оказаться затратной операцией. Она может надолго спровоцировать возросшие задержки или пропажу запросов, поскольку потребуется перебалансировка kafka-streams (после добавления или удаления узла).
Вот почему по умолчанию долговременные хранилища состояний логируются: то есть, все изменения, вносимые в хранилище, дополнительно записываются в changelog-topic. Этот топик сжимается (ведь для каждого
Однако, при перебалансировке в таком случае все равно возможны задержки. Чтобы еще сильнее их сократить, в kafka-streams предусмотрена возможность держать несколько резервных реплик (
Согласованность
При настройках, задаваемых по умолчанию, Kafka обеспечивает как минимум однократную доставку. То есть, в случае отказа узлов некоторые сообщения могут доставляться по нескольку раз. Например, возможно, что определенное событие будет дважды применено к хранилищу состояний, если произошел отказ системы уже после записи в журнал изменений хранилища состояний, но до того, как было выполнено смещение для данного конкретного события. Возможно, это и не причинит сложностей: наша функция обновления состояний (
Следовательно, если наша функция обновления состояния этого требует, мы можем включить семантику обработки потоков «строго однократная доставка» при помощи единственной конфигурационной опции:
Слушание событий
Теперь, когда мы рассмотрели основы — запрашивание «текущего состояния» и его обновление для каждой сущности — что насчет запуска побочных эффектов? В какой-то момент это станет необходимо, например, для:
Все эти задачи в той или иной степени являются блокирующими и связаны с операциями ввода/вывода (это естественно для побочных эффектов), так что, пожалуй, не лучшая идея выполнять их в рамках логики обновления состояния: в результате может возрасти частота сбоев в главном цикле событий, а по части производительности возникнет узкое место.
Более того, функцию с логикой обновления состояния (E
К счастью, поскольку мы работаем с топиками Kafka, мы располагаем изрядной гибкостью. На этапе потоков, где обновляется хранилище состояний, события могут испускаться в неизмененном (или, если нужно – и в модифицированном) виде, и результирующий поток/топик (в Kafka эти понятия эквивалентны) можно потреблять как угодно. Более того, его можно потреблять либо до, либо после этапа обновления состояния. Наконец, мы можем управлять и тем, как будем запускать побочные эффекты: минимум однократно или максимум однократно. Первый вариант обеспечивается, если выполнять смещение потребленного топика-события лишь после того, как все побочные эффекты успешно завершатся. И наоборот, при максимум однократном запуске мы выполняем смещения до запуска побочных эффектов.
Существует несколько вариантов запуска побочных эффектов, они зависят от конкретной практической ситуации. Прежде всего, можно определить этап Kafka-streams, на котором побочные эффекты для каждого события запускаются в рамках функции обработки потоков.
Настроить такой механизм довольно просто, но это решение негибкое, когда приходится иметь дело с повторными попытками, управлением смещениями и конкурентным выполнением смещений сразу для множества событий. В таких более сложных случаях бывает более уместно определить обработку при помощи, скажем, reactive-kafka или другого механизма, потребляющего топики Kafka «напрямую».
Также возможно, что одно событие будет инициировать другие события — например, событие “заказ” может спровоцировать события “подготовка к отправке” и “уведомление клиента”. Это также можно реализовать на этапе kafka-streams.
Наконец, если бы мы хотели сохранять события или некие данные, извлеченные из событий, в базе данных или поисковике, скажем, в ElasticSearch или PostgreSQL, то можно было бы задействовать коннектор Kafka Connect, который обработает за нас все детали, связанные с потреблением топиков.
Создание представлений и проекций
Обычно требования к системе не ограничиваются запрашиванием и обработкой только лишь одиночных потоков сущностей. Также должна поддерживаться агрегация, комбинирование множества потоков событий. Такие комбинированные потоки часто именуются проекциями, а в свернутом виде могут применяться для создания представлений данных. Можно ли реализовать их при помощи Kafka?
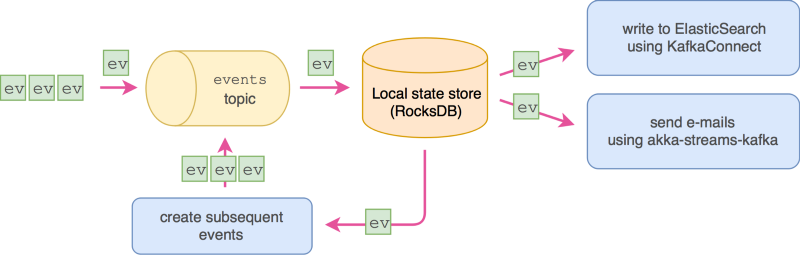
Опять – да! Помните, что принципиально мы имеем дело просто с топиком Kafka, где хранятся наши события; следовательно, мы располагаем всей мощью «сырых» консьюмеров/продюсеров Kafka, комбинатором kafka-streams и даже KSQL — все это пригодится нам для определения проекций. Например, с помощью kafka-streams можно фильтровать поток, отображать, группировать по ключу, агрегировать во временных или сеансовых окнах и т.д. либо на уровне кода, либо при помощи SQL-подобного KSQL.
Такие потоки можно долговременно хранить и предоставлять для запросов при помощи хранилищ состояний и интерактивных запросов, точно как мы поступали с отдельными потоками сущностей.
Что дальше
Чтобы предотвратить бесконечное разрастание потока событий по мере развития системы, может пригодиться такой вариант сжатия, как сохранение мгновенных снимков «текущего состояния». Таким образом, мы сможем ограничиться хранением лишь нескольких недавних снимков и тех событий, что произошли после их создания.
Хотя, в Kafka отсутствует прямая поддержка мгновенных снимков (а в некоторых других системах, работающих по принципу регистрации событий, она есть), определенно можно самостоятельно добавить функционал такого рода, воспользовавшись некоторыми вышеупомянутыми механизмами, как то потоками, консьюмерами, хранилищами состояний и т.д.
Резюме
Хотя, исходно Kafka не проектировался с оглядкой на парадигму регистрации событий, по сути он является движком потоковой обработки данных с поддержкой репликации топиков, сегментирования, хранилищ состояния и потоковых API, и при этом очень гибок. Следовательно, поверх Kafka можно без труда реализовать систему регистрации событий. Более того, поскольку на фоне всего происходящего у нас всегда будет топик Kafka, мы приобретем дополнительную гибкость, так как сможем работать либо с высокоуровневыми потоковыми API, либо с низкоуровневыми консьюмерами.
Мы раскупорили последние резервы книги "Apache Kafka. Потоковая обработка и анализ данных" и отправили ее в допечатку. Более того, мы получили контракт на книгу "Kafka Streams in Action" и приступаем к ее переводу буквально на будущей неделе.

Чтобы показать занятный кейс использования библиотеки Kafka Streams, мы решили перевести статью о парадигме Event Sourcing в Kafka от того самого Адама Уорски, чья статья о языке Scala выходила у нас две недели назад. Тем интереснее, что мнение Адама Уорски не бесспорное: вот здесь, например, утверждается, что эта парадигма решительно для Kafka не подходит. Тем более запоминающимся, надеемся, получится впечатление от статьи.
Термин «Event Sourcing» переведен как «Регистрация событий» и в нашем издании "Чистой архитектуры" Роберта Мартина, и в данной статье. Если кому-нибудь импонирует перевод «прокачка событий» — дайте знать пожалуйста.
Создавая систему, в которой предусмотрена регистрация событий (event sourcing), мы рано или поздно сталкиваемся с проблемой сохраняемости (persistence) – и здесь у нас возникает пара вариантов. Во-первых, есть EventStore, зрелая реализация, закаленная в боях. В качестве альтернативы можно задействовать akka-persistence, чтобы на полную мощность использовать масштабируемость Cassandra, а также опираться на производительность акторной модели. Другой вариант – старая добрая реляционная база данных, где подход
CRUD комбинируется с использованием событий, и максимум пользы выжимается из транзакций. Кроме этих (и, пожалуй, многих других) возможностей, появившихся благодаря нескольким недавно реализованным вещам, сегодня стало весьма просто организовать регистрацию событий и поверх Kafka. Давайте рассмотрим как.
Что такое регистрация событий?
На эту тему есть ряд отличных вводных статей, поэтому я ограничусь максимально кратким введением. При регистрации событий мы сохраняем не «текущее» состояние сущностей, используемых в нашей системе, а поток событий, относящихся к этим сущностям. Каждое событие — это факт, описывающий изменение состояния, (уже!) произошедшее с объектом. Как известно, факты не обсуждаются и неизменны.
Когда у нас поток таких событий, актуальное состояние сущности можно выяснить, свернув все относящиеся к нему события; однако, учтите, что обратное невозможно – сохраняя лишь «актуальное» состояние, мы отбрасываем массу ценной хронологической информации.
Регистрация событий может мирно сосуществовать с более традиционными способами хранения состояния. Как правило, система обрабатывает ряд типов сущностей (например: пользователи, заказы, товары, …) и вполне возможно, что регистрация событий окажется целесообразна лишь для некоторых из этих категорий. Важно отметить, что здесь перед нами не стоит выбор «все или ничего»; речь просто о дополнительной возможности управления состоянием в нашем приложении.
Хранение событий в Kafka
Первая проблема, которую необходимо решить: как хранить события в Kafka? Есть три возможные стратегии:
- Хранить все события для всех типов сущностей в единственном топике (со множеством сегментов)
- По-топику-на-каждый-тип-сущностей, т.е., выносим в отдельный топик все события, связанные с пользователем, в отдельный – все, связанные с продуктом и т.п.
- По-топику-на-сущность, т.е., по отдельному топику на каждого конкретного пользователя и каждое наименование товара
Третья стратегия (по-топику-на-сущность) практически неосуществима. Если при появлении в системе каждого нового пользователя на него приходилось бы заводить отдельный топик, вскоре количество топиков стало бы неограниченным. Любая агрегация в таком случае оказалась бы очень сложна, например, было бы трудно индексировать всех пользователей в поисковике; мало того, что при этом пришлось бы потреблять огромное количество топиков – так еще бы и не все из них были известны заранее.
Поэтому остается выбирать между 1 и 2. У обоих вариантов есть свои достоинства и недостатки. Имея единственный топик, проще получить глобальное представление обо всех событиях. С другой стороны, выделяя по топику на каждый тип сущностей, можно масштабировать и сегментировать поток каждой сущности в отдельности. Выбор одной из двух стратегий зависит от конкретного варианта использования.
Кроме того, можно внедрить и обе стратегии сразу, если у вас есть дополнительное пространство в хранилище: производить топики по типу сущностей из одного всеобъемлющего топика.

В оставшейся части статьи мы будем работать всего с одним типом сущностей и с единственным топиком, хотя, изложенный материал легко экстраполировать и применить для работы со множеством топиков или типов сущностей.
(РЕД.: как отмечал Крис Хант, есть отличная статья Мартина Клеппмана, где детально рассмотрено, как распределять события по топикам и сегментам).
Простейшие операции с хранилищем в парадигме регистрации событий
Простейшая операция, которую логично ожидать от хранилища, поддерживающего регистрацию событий – считывание «текущего» (свернутого) состояния конкретной сущности. Как правило, каждая сущность имеет тот или иной
id. Соответственно, зная этот id, наша система хранения должна возвращать актуальное состояние объекта.Истиной в последней инстанции нам послужит лог событий: актуальное состояние всегда можно вывести из потока событий, связанных с конкретной сущностью. Для этого движку базу данных потребуется чистая функция (без побочных эффектов), принимающая событие и исходное состояние, и возвращающая измененное состояние:
Event = > State => State. При наличии такой функции и значения исходного состояния текущее состояние является сверткой потока событий (функция изменения состояния должна быть чистой, чтобы ее свободно можно было многократно применять к одним и тем же событиям.)Упрощенная реализация операции “считывания текущего состояния” в Kafka собирает поток из всех событий из топика, фильтрует их, оставляя лишь события с заданным
id и свертывает при помощи указанной функции. Если событий много (а со временем количество событий только растет), эта операция может становиться медленной и потреблять массу ресурсов. Даже если ее результат будет кэшироваться в памяти и храниться на сервисном узле, эту информацию все равно придется периодически воссоздавать, например, из-за отказов узла или из-за вытеснения данных кэша.
Поэтому нужен более рациональный способ. Именно здесь нам и пригодятся kafka-streams и хранилища состояний. Приложения Kafka-streams работают на целом кластере узлов, совместно потребляющих определенные топики. Каждому узлу присваивается ряд сегментов потребляемых топиков, точно как и в случае с обычным консьюмером Kafka. Однако, в kafka-streams предоставляются более высокоуровневые операции над данными, при помощи которых гораздо проще создавать производные потоки.
Одна из таких операций в kafka-streams – это свертка потока в локальном хранилище. В каждом локальном хранилище содержатся данные лишь из тех сегментов, что потребляются заданным узлом. «Из коробки» доступны две реализации локальных хранилищ: в оперативной памяти и на основе RocksDB.
Возвращаясь к теме регистрации событий, отметим, что можно свернуть поток событий в хранилище состояний, держа на локальном узле «текущее состояние» каждой сущности из сегментов, присваиваемых узлу. Если мы используем реализацию хранилища состояний на основе RocksDB, то лишь от объема дискового пространства зависит, сколько сущностей мы сможем отслеживать на отдельно взятом узле.
Вот как выглядит свертка событий в локальное хранилище при использовании Java API (serde означает «сериализатор/десериализатор»):
KStreamBuilder builder = new KStreamBuilder();
builder.stream(keySerde, valueSerde, "my_entity_events")
.groupByKey(keySerde, valueSerde)
// функция свертки: должна возвращать новое состояние
.reduce((currentState, event) -> ..., "my_entity_store");
.toStream(); // выдает поток промежуточных состояний
return builder;Полный пример с обработкой заказов на основе микросервисов доступен на сайте Confluent.
(РЕД.: по замечанию Сергея Егорова и Никиты Сальникова в Twitter, для системы с регистрацией событий, вероятно, потребуется изменить задаваемые в Kafka по умолчанию настройки хранения данных, чтобы не действовали никакие пределы ни по времени, ни по размеру, а также, опционально, включить сжатие данных.)
Просмотр текущего состояния
Мы создали хранилище состояний, где находятся актуальные состояния всех сущностей, поступающих из сегментов, присвоенных узлу, но как теперь запрашивать это хранилище? Если запрос локальный (то есть, исходит с того же узла, на котором находится хранилище), то все довольно просто:
streams
.store("my_entity_store", QueryableStoreTypes.keyValueStore());
.get(entityId);Но что, если мы хотим запросить данные, расположенные на другом узле? И как выяснить, что это за узел? Здесь нам пригодится еще одна возможность, недавно появившаяся в Kafka: интерактивные запросы. С их помощью можно обращаться к метаданным Kafka и выяснять, какой узел обрабатывает сегмент топика с заданным
id (в данном случае неявно используется инструмент для сегментирования топиков):metadataService
.streamsMetadataForStoreAndKey("my_entity_store", entityId, keySerde)Далее нужно как-то переадресовать запрос на правильный узел. Обратите внимание: конкретный способ, которым реализуется и обрабатывается межузловая коммуникация — будь то REST, akka-remote или любой другой — не относится к зоне ответственности kafka-streams. Kafka просто обеспечивает доступ к хранилищу состояний и предоставляет информацию о том, на каком узле расположено хранилище состояний для заданного
id.Восстановление после отказа
Хранилища состояний выглядят симпатично, но что произойдет при отказе узла? Воссоздание локального хранилища состояний для того или иного сегмента также может оказаться затратной операцией. Она может надолго спровоцировать возросшие задержки или пропажу запросов, поскольку потребуется перебалансировка kafka-streams (после добавления или удаления узла).
Вот почему по умолчанию долговременные хранилища состояний логируются: то есть, все изменения, вносимые в хранилище, дополнительно записываются в changelog-topic. Этот топик сжимается (ведь для каждого
id нас интересует лишь последняя запись, без истории изменений, поскольку история хранится в самих событиях) – следовательно, он настолько мал, насколько это возможно. Именно поэтому воссоздание хранилища на другом узле может происходить гораздо быстрее.Однако, при перебалансировке в таком случае все равно возможны задержки. Чтобы еще сильнее их сократить, в kafka-streams предусмотрена возможность держать несколько резервных реплик (
num.standby.replicas) для каждого хранилища. Эти реплики применяют все обновления, извлекаемые из топиков с журналами изменений по мере их поступления, и готовы перейти в режим основного хранилища состояний для заданного сегмента, как только актуальное основное хранилище откажет.Согласованность
При настройках, задаваемых по умолчанию, Kafka обеспечивает как минимум однократную доставку. То есть, в случае отказа узлов некоторые сообщения могут доставляться по нескольку раз. Например, возможно, что определенное событие будет дважды применено к хранилищу состояний, если произошел отказ системы уже после записи в журнал изменений хранилища состояний, но до того, как было выполнено смещение для данного конкретного события. Возможно, это и не причинит сложностей: наша функция обновления состояний (
Event = > State => State) может вполне нормально справляться с такими ситуациями. Однако, может и не справляться: на такой случай можно задействовать предоставляемые в Kafka гарантии строго однократной доставки. Такие гарантии применяются лишь при считывании и записи топиков Kafka, но именно этим мы здесь и занимаемся: на заднем плане все записи в топики Kafka сводятся к обновлению журнала изменений для хранилища состояний и выполнению смещений. Все это можно делать в виде транзакций.Следовательно, если наша функция обновления состояния этого требует, мы можем включить семантику обработки потоков «строго однократная доставка» при помощи единственной конфигурационной опции:
processing.guarantee. Из-за этого падает производительность, но ничто не дается даром.Слушание событий
Теперь, когда мы рассмотрели основы — запрашивание «текущего состояния» и его обновление для каждой сущности — что насчет запуска побочных эффектов? В какой-то момент это станет необходимо, например, для:
- Отправки уведомительных электронных сообщений
- Индексирования сущностей в поисковике
- Вызова внешних сервисов через REST (или SOAP, CORBA, т.д. )
Все эти задачи в той или иной степени являются блокирующими и связаны с операциями ввода/вывода (это естественно для побочных эффектов), так что, пожалуй, не лучшая идея выполнять их в рамках логики обновления состояния: в результате может возрасти частота сбоев в главном цикле событий, а по части производительности возникнет узкое место.
Более того, функцию с логикой обновления состояния (E
Event = > State => State) можно запускать многократно (в случае отказов или перезапусков), и чаще всего мы хотим минимизировать количество случаев, в которых побочные эффекты для конкретного события прогоняются многократно.К счастью, поскольку мы работаем с топиками Kafka, мы располагаем изрядной гибкостью. На этапе потоков, где обновляется хранилище состояний, события могут испускаться в неизмененном (или, если нужно – и в модифицированном) виде, и результирующий поток/топик (в Kafka эти понятия эквивалентны) можно потреблять как угодно. Более того, его можно потреблять либо до, либо после этапа обновления состояния. Наконец, мы можем управлять и тем, как будем запускать побочные эффекты: минимум однократно или максимум однократно. Первый вариант обеспечивается, если выполнять смещение потребленного топика-события лишь после того, как все побочные эффекты успешно завершатся. И наоборот, при максимум однократном запуске мы выполняем смещения до запуска побочных эффектов.
Существует несколько вариантов запуска побочных эффектов, они зависят от конкретной практической ситуации. Прежде всего, можно определить этап Kafka-streams, на котором побочные эффекты для каждого события запускаются в рамках функции обработки потоков.
Настроить такой механизм довольно просто, но это решение негибкое, когда приходится иметь дело с повторными попытками, управлением смещениями и конкурентным выполнением смещений сразу для множества событий. В таких более сложных случаях бывает более уместно определить обработку при помощи, скажем, reactive-kafka или другого механизма, потребляющего топики Kafka «напрямую».
Также возможно, что одно событие будет инициировать другие события — например, событие “заказ” может спровоцировать события “подготовка к отправке” и “уведомление клиента”. Это также можно реализовать на этапе kafka-streams.
Наконец, если бы мы хотели сохранять события или некие данные, извлеченные из событий, в базе данных или поисковике, скажем, в ElasticSearch или PostgreSQL, то можно было бы задействовать коннектор Kafka Connect, который обработает за нас все детали, связанные с потреблением топиков.
Создание представлений и проекций
Обычно требования к системе не ограничиваются запрашиванием и обработкой только лишь одиночных потоков сущностей. Также должна поддерживаться агрегация, комбинирование множества потоков событий. Такие комбинированные потоки часто именуются проекциями, а в свернутом виде могут применяться для создания представлений данных. Можно ли реализовать их при помощи Kafka?

Опять – да! Помните, что принципиально мы имеем дело просто с топиком Kafka, где хранятся наши события; следовательно, мы располагаем всей мощью «сырых» консьюмеров/продюсеров Kafka, комбинатором kafka-streams и даже KSQL — все это пригодится нам для определения проекций. Например, с помощью kafka-streams можно фильтровать поток, отображать, группировать по ключу, агрегировать во временных или сеансовых окнах и т.д. либо на уровне кода, либо при помощи SQL-подобного KSQL.
Такие потоки можно долговременно хранить и предоставлять для запросов при помощи хранилищ состояний и интерактивных запросов, точно как мы поступали с отдельными потоками сущностей.
Что дальше
Чтобы предотвратить бесконечное разрастание потока событий по мере развития системы, может пригодиться такой вариант сжатия, как сохранение мгновенных снимков «текущего состояния». Таким образом, мы сможем ограничиться хранением лишь нескольких недавних снимков и тех событий, что произошли после их создания.
Хотя, в Kafka отсутствует прямая поддержка мгновенных снимков (а в некоторых других системах, работающих по принципу регистрации событий, она есть), определенно можно самостоятельно добавить функционал такого рода, воспользовавшись некоторыми вышеупомянутыми механизмами, как то потоками, консьюмерами, хранилищами состояний и т.д.
Резюме
Хотя, исходно Kafka не проектировался с оглядкой на парадигму регистрации событий, по сути он является движком потоковой обработки данных с поддержкой репликации топиков, сегментирования, хранилищ состояния и потоковых API, и при этом очень гибок. Следовательно, поверх Kafka можно без труда реализовать систему регистрации событий. Более того, поскольку на фоне всего происходящего у нас всегда будет топик Kafka, мы приобретем дополнительную гибкость, так как сможем работать либо с высокоуровневыми потоковыми API, либо с низкоуровневыми консьюмерами.
