
В первой статье этого цикла я рассказал, как и почему мы выбрали опенсорсный Graylog2 для централизованного сбора и просмотра логов в компании. В этот раз я поделюсь, как мы разворачивали грейлог в production, и с какими столкнулись проблемами.
Напомню, кластер будет размещаться на площадке хостера, логи будут собираться со всего мира по TCP, а среднее количество логов — около 1,2 Тб/день при нормальных условиях.
В настоящее время мы используем CentOS 7 и Graylog 2.2, поэтому все конфигурации и опции будут описываться исключительно для этих версий (в Graylog 2.2 и Graylog 2.3 ряд опций отличается).
Планирование размещения
По нашим подсчетам, нам нужно 6 серверов. В каждом сервере по 2 сетевых интерфейса; первый — 100Мб в мир и 1Гб приватная сеть. На внешнем интерфейсе будет слушать веб-интерфейс и на части нод будет слушать HAproxy, но об этом позже. Приватная 1Гб сеть используется для сообщения всего остального.
Итого у нас есть 6 серверов Hp DL380p Gen8, 2x Intel Octa-Core Xeon E5-2650, 64 GB RAM, 12x4TB SATA. Это стандартная конфигурация хостера. Диски мы разбили так: 1 диск под систему, монгу и журнал грейлога, остальные — в 0 рейд и под хранилище эластика. Так как репликация происходит на уровне самого эластика, другие рейды нам нужны не сильно.
Сервера распределены следующим образом:
- на первых 4-х: HAproxy, elasticsearch, graylog, mongod, keepalived, cerebro;
- на оставшихся 2-х только elasticsearch и graylog.
Схематично это выглядит вот так:
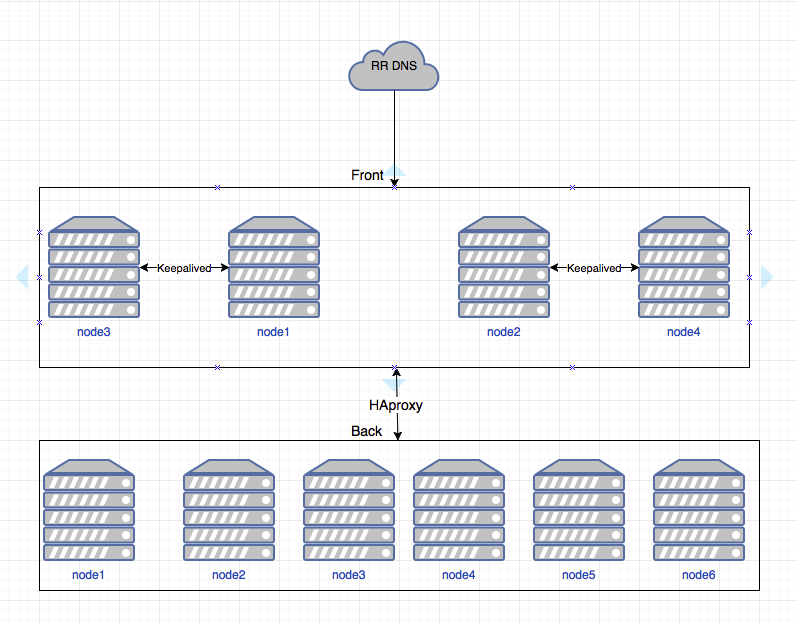
Настройки:
- в DNS указаны 2 адреса, которые обычно находятся на 1 и 2 нодах;
- между 1-3 и 2-4 настроен HAproxy, чтобы в случае падения ноды адрес поднимался на другой ноде;
- дальше каждая нода при помощи HAproxy раскидывает трафик по всем нодам грейлога;
- грейлог в свою очередь тоже балансирует обработку логов по нодам.
(На настройке HAproxy и keepalived останавливаться не будем, так как это находится за рамками данной статьи.)
Первоначальная настройка
Первоначальная настройка Graylog2 довольно проста и банальна, поэтому я всем просто крайне советую действовать по официальным инструкциям:
- docs.graylog.org/en/2.2/pages/installation/operating_system_packages.html
- docs.graylog.org/en/2.2/pages/architecture.html#big-production-setup
- docs.graylog.org/en/2.2/pages/configuration/multinode_setup.html#configure-multinode
Там много полезной информации, которая в дальнейшем поможет в понимании принципов конфигурирования и тюнинга. При первоначальной настройке у меня ни разу не возникало проблем, поэтому перейдем к конфигурационным файлам.
В server.conf грейлога на первом этапе мы указали:
#Указываем нашу тайм зону
root_timezone = Europe/Moscow#Так как хостов не очень много, тут указываем все хосты эластика
elasticsearch_discovery_zen_ping_unicast_hosts =
elasticsearch_discovery_zen_ping_multicast_enabled = false#Разрешаем начинать поиск с вайлдкарда, потоум что у нас все понимают, что это и чем грозит
allow_leading_wildcard_searches = true#Это относится больше к тюнингу, но на первом этапе мы указали ring_size равный половине L2 кеша процессора.
#И указываем данные для отправки писем грейлогом (в пустые строки нужно вставить ваши данные).
#Email transport
transport_email_enabled = true
transport_email_hostname = smtp.gmail.com
transport_email_port = 465
transport_email_use_auth = true
transport_email_use_tls = false
transport_email_use_ssl = true
transport_email_auth_username =
transport_email_auth_password =
transport_email_subject_prefix = [graylog]
transport_email_from_email =
transport_email_web_interface_url = Дальше нужно потюнить хипсайз эластика в файле /etc/sysconfig/elasticsearch (в доке рекомендуют 31 Гб):
ES_HEAP_SIZE=31gНа первичном этапе мы больше ничего не правили и некоторое время даже не знали никаких проблем. Поэтому перейдём непосредственно к запуску и настройке самого грейлога.
Хранение и сборка логов, права доступа
Пришло время настроить наш грейлог и начать получать данные. Первое, что нам необходимо — это определиться с тем, как мы будем получать логи. Мы остановились на GELF TCP — он позволяет конфигурировать коллекторы через веб-интерфейс (покажу чуть ниже).
Настраиваем наш первый инпут. В веб-интерфейсе System/Inputs слева вверху выбираем GELF TCP и потом Launch new input:
Открывается окно:
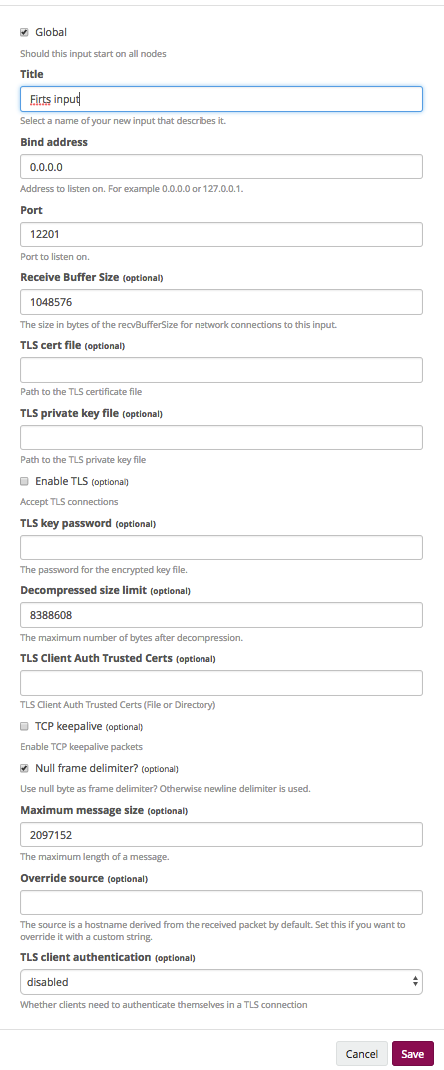
- Global. Говорит о том, что инпут будет поднят на всех нодах.
- Title. Как будет называться инпут.
- Bind address. На какой адрес будет байндиться наш инпут (в нашем случае это 0.0.0.0, потому что на всех нодах разные адреса).
- Port. Тут нужно помнить, что у нас перед инпутами стоит HAproxy как балансировщик, соответственно, сюда вписываем порт, на который будет перенаправлять балансер.
- Receive Buffer Size, Decompressed size limit и Maximum message size. Подбирается исходя из конкретных случаев.
- Настройка ssl по желанию.
Теперь у нас есть наш первый инпут, который будет принимать сообщения. Приступаем к настройке хранения логов. Необходимо определиться сколько логов и как мы будем их хранить.
Мы поделили всё на проекты и логически связанные сервисы внутри проектов, а потом поделили на количество логов, которое нам необходимо хранить. Лично мы часть логов храним 14 дней, а часть — 140.
Хранение данных происходит в индексах грейлога. Индексы в свою очередь делятся на шарды. Шарды бывают праймари и реплика. По умолчанию данные пишутся в праймари шарды и реплицируются в реплику. Реплицируем мы только важные индексы. Большие индексы у нас имеют 2 праймари шарды и по одной реплике, что гарантирует выход из строя 2-х нод без потери данных.
Давайте создадим индекс который будет иметь 2 шарда и 1 реплику и будет хранить их логи 14 дней.
Идём в System\Indices, там нажимаем Create index set:
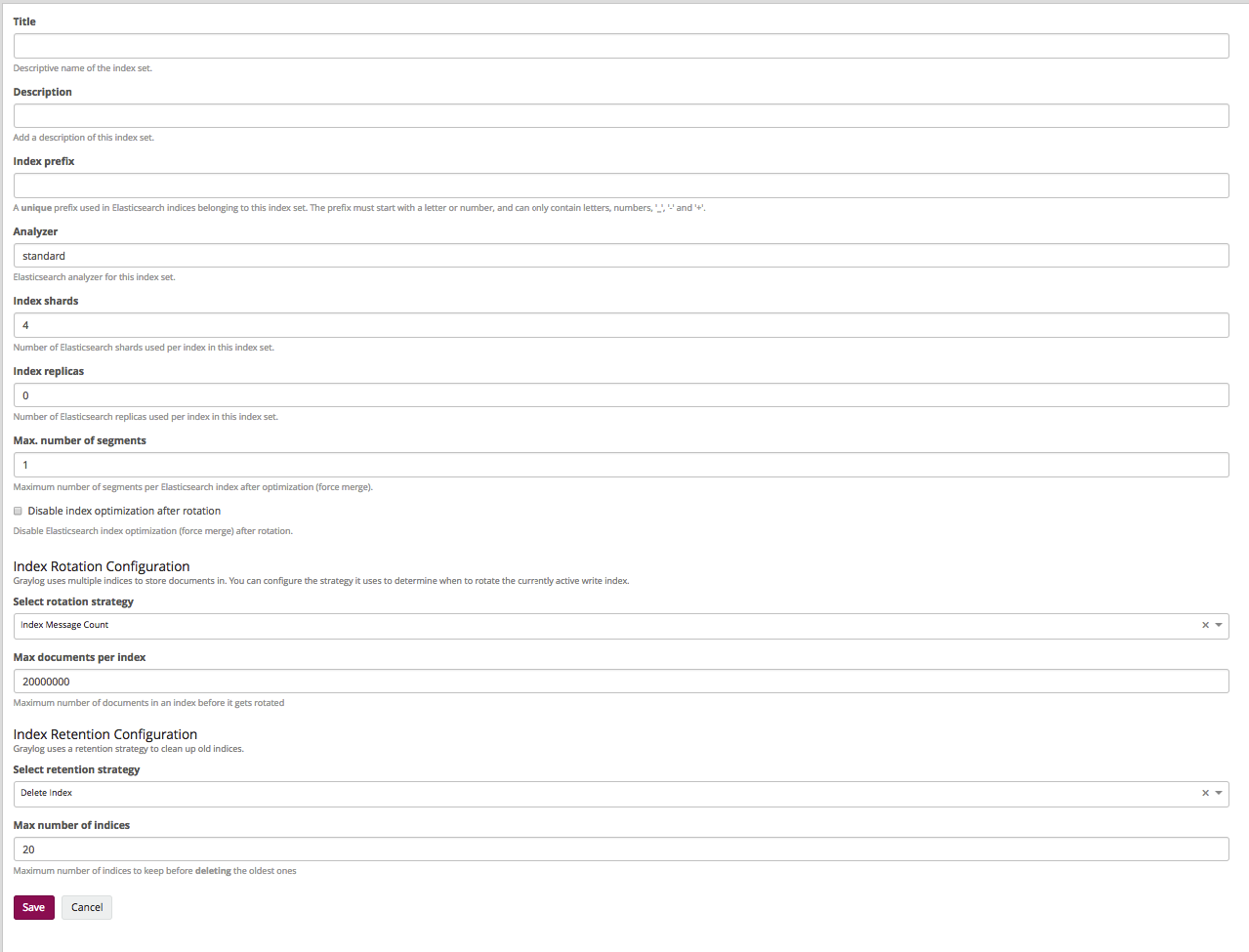
- Title и Description. Тут всё ясно — имя и описание.
- Index prefix. Какой префикс в эластике будут иметь индексы (обычно как-то отражает название самого индекса в грейлоге).
- Analyzer. Мы не меняем.
- Index shards. Количество шардов (мы хотим иметь 2 праймари шарда, поэтому тут надо поставить 2).
- Index replicas. Количество реплик каждого шарда оставляем 1.
- Max. number of segments. Обычно мы не оптимизируем шарды, поэтому оставляем 1.
Следующие пункты отвечают за количество хранимых логов и по названиям становится ясно, что их можно хранить по количеству сообщений, по времени, и по размеру индекса. Мы хотим хранить 14 дней.
- Select rotation strategy — Index Time.
- Rotation period (ISO8601 Duration). Есть в документации, мы оставляем P1D, что говорит: один индекс — один день.
- Select retention strategy — Delete index. Будем удалять старые индексы.
- Max number of indices. Максимальное количество индексов, ставим 14, что в данном случае говорит о том, что будет храниться 14 индексов по 1 дню.
Теперь нам нужно сделать так называемый стрим. Грейлог предоставляет права на уровне этих самых стримов. Суть такова: в стриме указываем, в какой индекс писать данные и по каким условиям. Находится это в Sterams. Настройка происходит в 2 этапа.
1. Создание стрима.
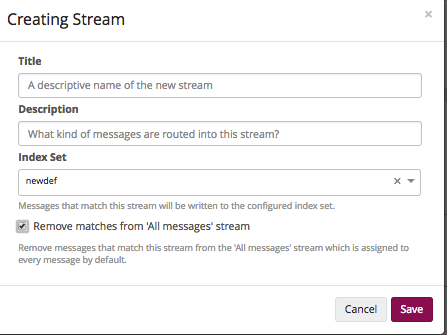
- Title и Description. Как обычно — имя и описание.
- Index Set. В какой индекс писать данные, тут выбираем тот, который создали ранее.
- Remove matches from 'All messages' stream. Удалять сообщения из 'All messages'. Чтобы не было путаницы — удаляем.
2. Дальше Manage Rules.
Там всё просто: добавляем необходимые правила, по которым туда будут попадать логи.
Теперь у нас есть инпут, который принимает логи; индекс, который их сохраняет; и стрим, который по сути собирает много логов в одно пространство.
Дальше настраиваем отправку логов в сам грейлог.
Настройка агентов
Путь настройки агентов описан здесь. Работает это всё следующим образом: на клиенте ставится Graylog Collector Sidecar, который управляет бэкендом сборщика логов (в нашем случае для линукса и винды это — nxlog).
Подготовим правила сборки логов System\Collectors\Manage Configurations. Создаём конфигурацию и переходим к её настройке, там сразу переходим на вкладку NXLog. Видим 3 поля: Output, Configure NXLog Inputs и Define NXLog Snippets. Это всё кусочки конфигов этого самого NXLog’a, которые будут коллектором забираться на конечные ноды. Отсюда мы будем управлять полями и их значениями, а также файлами, которые мы будем мониторить и т.д.
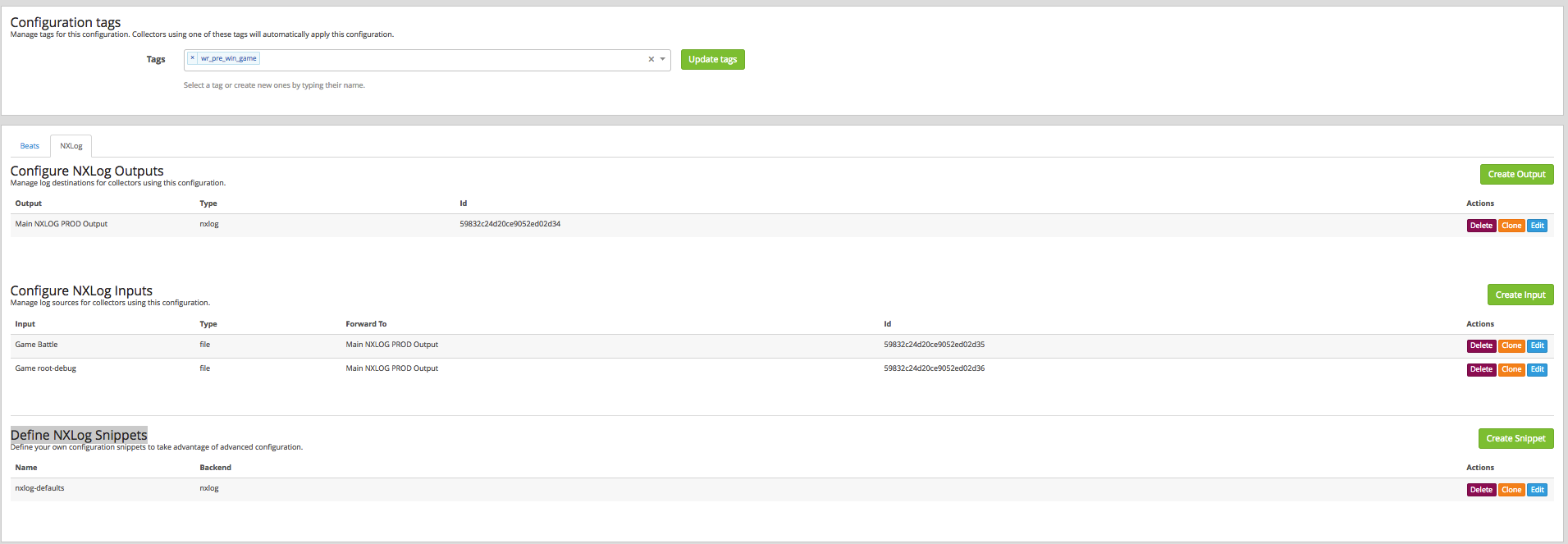
Начнём с тегов. Вбиваем теги, по которым клиент будет понимать, какую конфигурацию ему нужно забрать.
Поле Output, тут одна конфигурация:
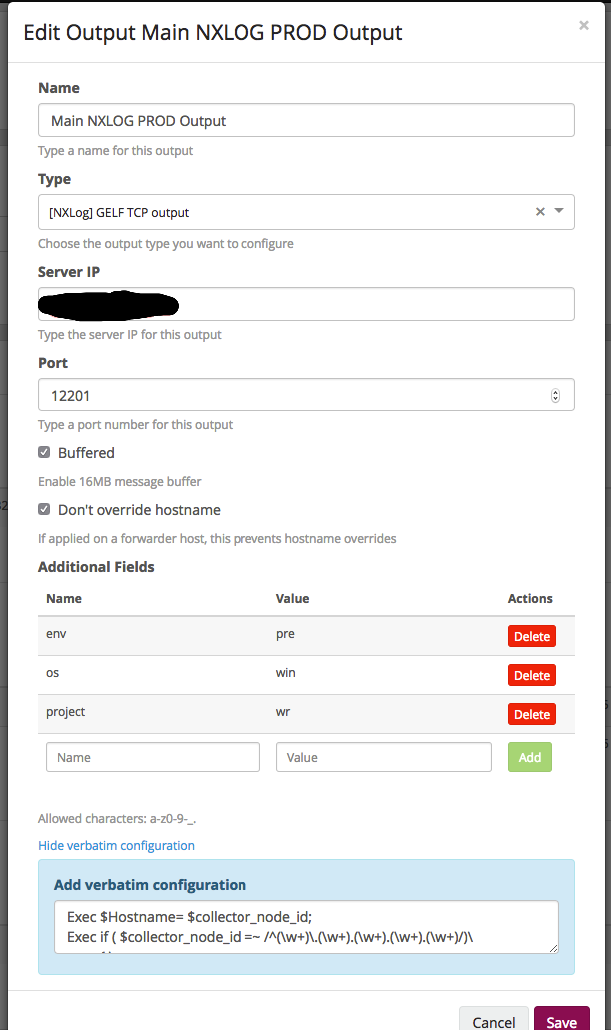
- Name. Тут всё ясно — имя, по которому мы поймём, что это.
- Type. В нашем случае это TCP.
- Server IP. Тут указываем адрес, куда отправлять логи (в нашем случае это днс, имя которое разрешается в 2 адреса).
- Port. Как помним, у нас используется балансировщик — на входе мы указываем порт именно балансировщика, который в свою очередь раскидает на ноды грейлога.
- Дальше включаем буфер на хосте.
- И не перезаписываем хостнейм.
- Additional Fields. Тут добавляем дополнительные поля, которые будут применяться на уровне конфигурации.
- Дальше поле для ручной конфигурации полей. Детально можно почитать на сайте NXLog’a. В нашем случае, как пример, просто разбиение хостнейма на нужные поля:
Exec $Hostname= $collector_node_id;
Exec if ( $collector_node_id =~ /^(\w+)\.(\w+).(\w+).(\w+).(\w+)/)\
{ \
$name = $1;\
$datacenter = $2; \
$region = $3;\
$platform = $5;\
};
Это была общая настройка конфигурации, куда отправлять и как подписывать каждый лог. Дальше в поле Configure NXLog Inputs укажем, какие файлы мониторить.
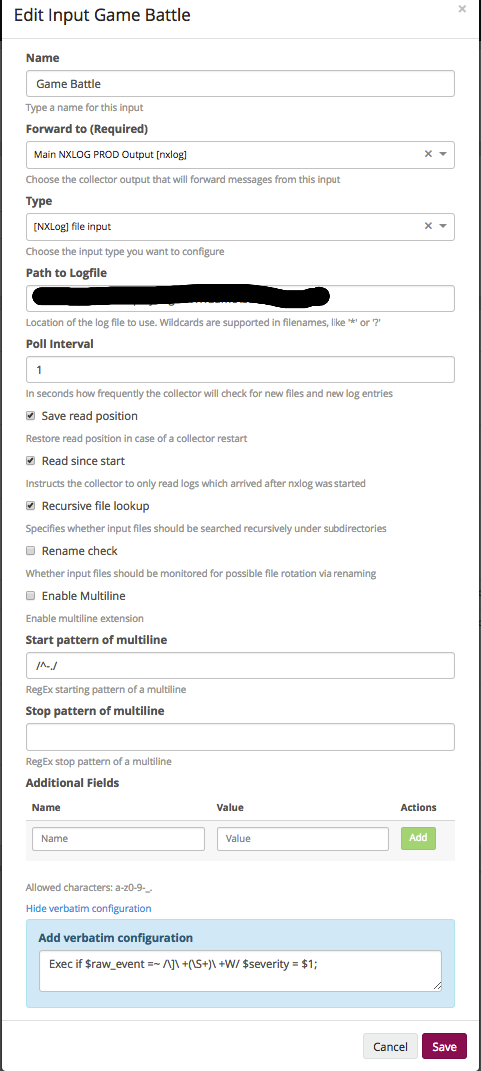
- Name — …
- Forward to (Required). Сюда выше созданный аутпут.
- Type. Типов, которые умеет NXLog, довольно много, в данном случае укажем файл, что говорит о том, что данные будем брать из файла.
- Path to Logfile. Путь до файла или файлов. Поддерживаются регэкспы, нужно только помнить, что в случае винды у файла обязательно должно быть расширение и все файлы в директории выглядят вот так: “*.*”.
- Poll Interval. Как часто проверять изменения в секундах.
- Следующий набор чек-боксов описывает поведение работы с файлом и зависит от специфики ваших логов.
- И дальше опять же кастомные поля и raw поле. В данном случае из лога мы выбираем поле и передаем его как severity.
Define NXLog Snippets мы обычно не трогаем.
На этом будем считать, что дефолтная настройка закончена, вы же можете добавить туда больше файлов, полей и т.д.
Перейдем к установке агента. Вообще, она очень хорошо описана по ссылке, поэтому здесь мы не будем останавливаться на ручной раскатке агентов, а сразу перейдём к автоматизации. Делаем мы это ансиблом.
В условиях линукса нет ничего ничего сложного, а на винде есть проблема в автоматической установке, поэтому мы просто распаковываем файл и на стороне ансибла генерим уникальный UUID. Роли для ансибла:
На этом настройку можно считать законченной и первые логи уже начнут появляться в системе.
Ещё бы я хотел рассказать о том, как мы тюнили систему под свои нужды, но так как статья и так получилась довольно объёмной, то продолжение следует.
