Во время разговоров о cgroups пользователи Red Hat довольно часто задают один и тот же вопрос: «У меня есть одно приложение, очень чувствительное в смысле задержек. Можно ли с помощью cgroups изолировать это приложение от остальных, привязав его к определенным процессорным ядрам?»

Разумеется, можно. Иначе мы бы не выбрали этот вопрос в качестве темы сегодняшней статьи.
В детстве нам часто говорили, что делиться – это хорошо и правильно. По большому счету, так оно и есть. Но бывают исключения.
Как мы писали в первом посте этой серии, по умолчанию Red Hat Enterprise Linux 7 ведет себя как сферическая добрая бабушка. В том смысле, что она старается справедливо распределять системные ресурсы между всеми, кто их просит. Однако в реальной жизни у бабушек бывают любимчики, которым достается больше. В переводе на сисадминский это означает, что бывают ситуации, когда одни приложения или сервисы важнее других, поэтому им надо уделять всё возможное внимание, чтобы они были максимально отзывчивы.
В Red Hat Enterprise Linux 7 это делается в два этапа:
В Hat Enterprise Linux 7.4 изменился механизм работы с недолговечными слайсами, типа пользовательских сеансов. В результате для них больше нельзя менять настройки cgroup на лету, вносить постоянные изменения в конфигурацию, а также создавать файлы drop-in с помощью команды systemctl set-property. Да, это обидно, но так уж решило сообщество разработки Linux. Хорошая новость в том, что эти изменения не затронули службы. То есть, если приложения запускаются и останавливаются через юнит-файлы (работают в качестве демонов), то все наши примеры работают. Кроме того, остается возможность создавать собственные cgroups с помощью таких древних инструментов, как cgcreate и cgset, и затем помещать в эти группы пользовательские сеансы и процессы, чтобы задействовать CPU-шары и прочие регуляторы. В жизни все меняется, поэтому нам остается только приспосабливаться и изобретать новые техники. А теперь переходим к сегодняшней теме.
Одна из самых важных составляющих в ядре Linux – это планировщик (диспетчер) процессов. Если чуть глубже, то процесс – это исполняемый код, являющийся часть приложения или сервиса. По сути, процесс состоит из серии инструкций, которые компьютер выполняет, делая ту или иную работу, будь просмотр котиков или что-то посерьезнее.
Выполнением этих инструкций занимается центральный процессор, он же CPU. На современных компьютерах CPU, как правило, состоит из нескольких процессоров, которые называются ядрами.
По умолчанию планировщик рассматривает каждое процессорное ядро как один из исполнительных модулей, которым он поручает новые процессы по мере их появления. При этом планировщик старается более-менее равномерно распределять возникающие процессы между ядрами с учетом нагрузки. К сожалению, планировщику нельзя сказать, что вот этот конкретный процесс со временем породит целую группу процессов, и эту группу надо будет выполнять изолированно от остальных процессов, в том смысле, что у них не должно быть общих процессорных ядер.
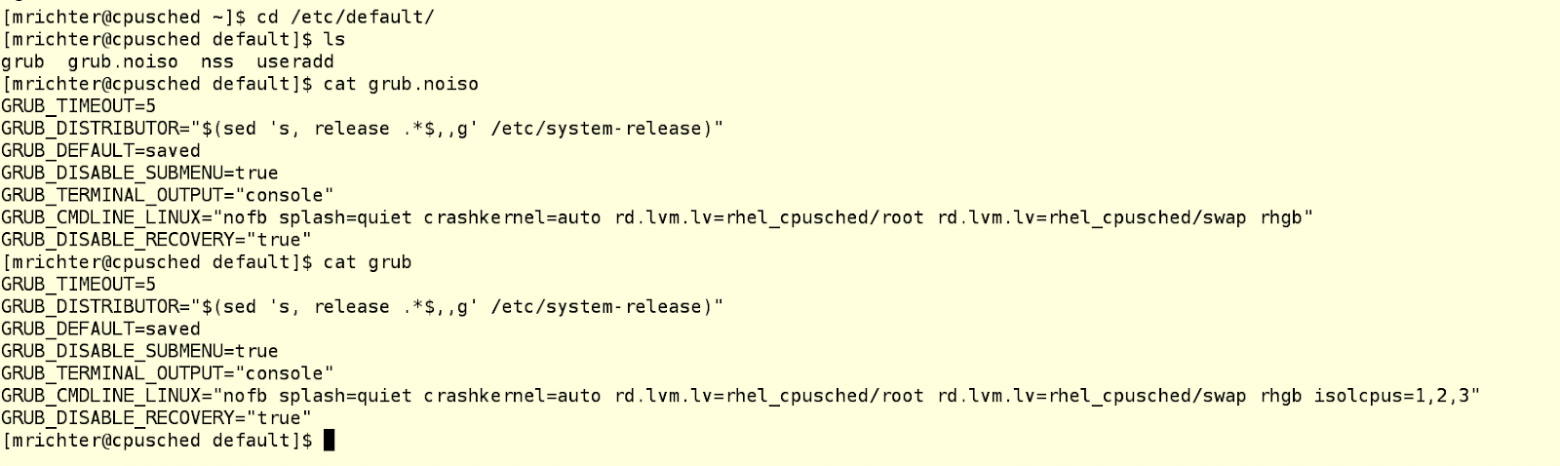
Поэтому нам надо как-то сказать планировщику, чтобы он не трогал часть процессорных ядер, то есть не отдавал им какие ни попадя процессы. А затем мы сами (или с помощью какого-то другого процесса) будем принудительно сажать на эти изолированные от планировщика ядра те процессы, которые посчитаем нужными. Это можно сделать с помощью параметра isolcpus в строке загрузки ядра в конфигурационном файле grub. В примере ниже у нас машина с четырьмя ядрам, на которой есть два файла grub: один лежит в /etc/default и называется grub.noiso (это резервная копия конфигурации по умолчанию), а второй лежит там же и называется просто grub, чтобы его подхватывал grub2-mkconfig. Этот второй файл подредактирован так, чтобы изолировать ядра 1-3 от планировщика процессов.
ВНИМАНИЕ: в Red Hat Enterprise Linux 7 никогда не надо вручную модифицировать файл grub.conf в папке /boot. Вместо этого внесите необходимые изменения в /etc/default/grub и затем пересоберите grub.conf file с помощью соответствующей утилиты, например, так:

При использовании параметра isolcpus надо через запятую перечислить высвобождаемые процессорные ядра, нумерация начинается с 0. После перезагрузки системы планировщик процессов не будет использовать эти ядра ни для чего, за исключением определенных процессов системного уровня, которые ДОЛЖНЫ БЫТЬ на каждом ядре. Чтобы проверить, сработал ли наш метод, запустим несколько нагрузочных процессов и затем посмотрим загрузку каждого ядра с помощью команды top.

Как видим, все нагрузочные процессы сели на CPU 0, вместо того, чтобы равномерно распределиться по всем четырем ядрам. Значит, мы прописали загрузочный параметр правильно.
Теперь переходим к вещам, которые лучше не делать, если вы не понимаете, зачем это делаете, а также которые лучше развертывать в продакшне только после тщательного тестирования.
К чему эти предостережения? К тому, что мы будем делать, в общем-то, простые вещи с помощью инструментария libcgroup, о котором писали в прошлом посте. Если помните, это просто набор команд для создания, модифицирования и уничтожения групп cgroups. Вообще-то они являются частью Red Hat Enterprise Linux 6, но их можно установить и на Red Hat Enterprise Linux 7, хотя не исключено, что в будущем эта возможность исчезнет. Вкратце напомним основные рекомендации по использованию libcgroup:
С концепцией cpuset все просто – это список процессорных ядер (нумерация, напомним, начинается с 0), принимающий задачи, которые будут исполняться ТОЛЬКО на этих ядрах. Это самые обычные процессорные ядра, они могут находиться либо под управлением планировщика процессов (именно так система настроена по умолчанию), либо, наоборот, могут быть изолированы от планировщика (как мы сделали в примере выше).
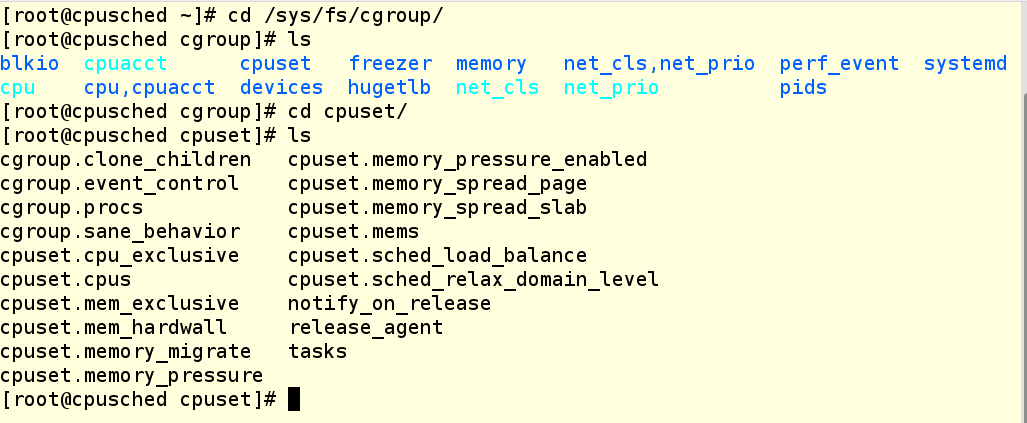
Давайте проверим каталог /sys/fs/cgroup filesystem на системе из нашего примера. Как видим, каталог cpuset уже существует, поскольку этот контроллер – это часть ядра (хотя он и не находится под управлением systemd). Однако в нем пока нет cgroups, поэтому мы видим в этом каталоге только настройки по умолчанию.
Проверим, что на нашей машине установлен инструментарий libcgroup:

Если не установлен, то это легко исправить командой yum install libcgroup, даже перезагрузка не понадобится.
Теперь создадим cpuset. Для этого мы будем использовать следующие команды, чтобы создать новую cgroup для cpuset и прописать ее свойства:
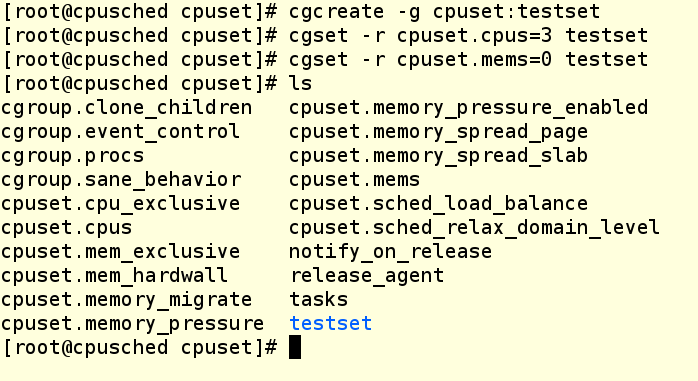
Команда Cgcreate создает cgroup с именем testset и размещает ее внутри контроллера cpuset. Затем мы назначаем третье ядро нашей ВМ этому новому cpuset’у и выделяем ему же NUMA-зону 0. Даже если ваша система не использует NUMA (а наша как раз не использует), зону все равно надо прописывать, иначе не получится назначать задачи группе cgroup. Теперь проверим, что в файловой системе создался каталог testset, и посмотрим, что у него внутри.

Как видим, наши изменения на месте, но на этом cpuset’е пока что не выполняется ни один процесс. Как посадить сюда какой-нибудь процесс?
Это можно сделать несколькими способами:
Давайте посмотрим вариант с cgexec.

Мы запустили foo.exe, он в свою очередь запустил дочерний процесс, который только и делает, что активно грузит процессор. Опция --sticky в команде cgexec говорит, что «любой дочерний процесс должен оставаться в той же cgroup, что и родительский процесс». Так что это важная опция, и ее надо запомнить. Теперь мы видим, что в нашей cgroup крутятся два процесса, и мы знаем их PID’ы. Глянем top:
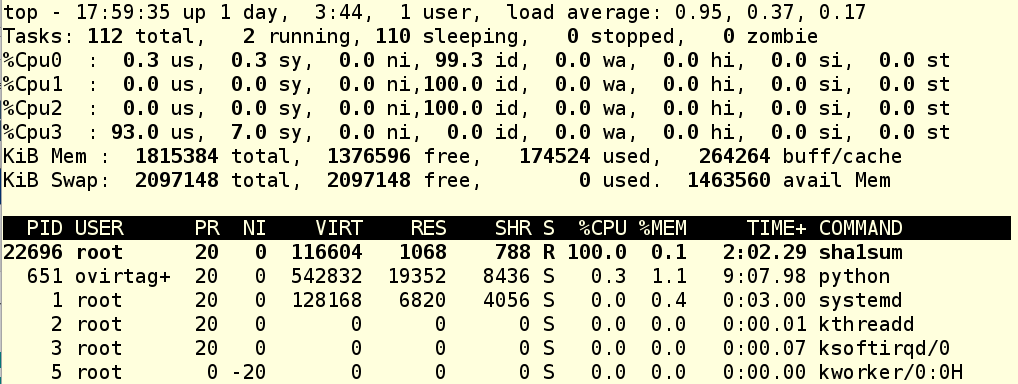
Как видим, CPU 3 теперь загружен под завязку, а остальные прохлаждаются.
А вот как выглядит юнит-файл для запуска того же приложения в качестве сервиса systemd:

В юнит-файле есть три команды ExecStartPre, которые выполняют настройки, которые мы уже успели сделать руками. Затем идет команда ExecStart, которая запускает приложение. А при остановке приложения, команда ExecStopPost подчищает за собой, удаляя cgroup.

Как видите, в последнем примере мы создали новую cgroup по имени set1. Мы сделали это, чтобы показать, что можно иметь несколько активных cgroups, которые делят одни и те же CPU. Кому это может показаться полезным, а кого-то наоборот запутать.
Ну что, все работает? Похоже, да!

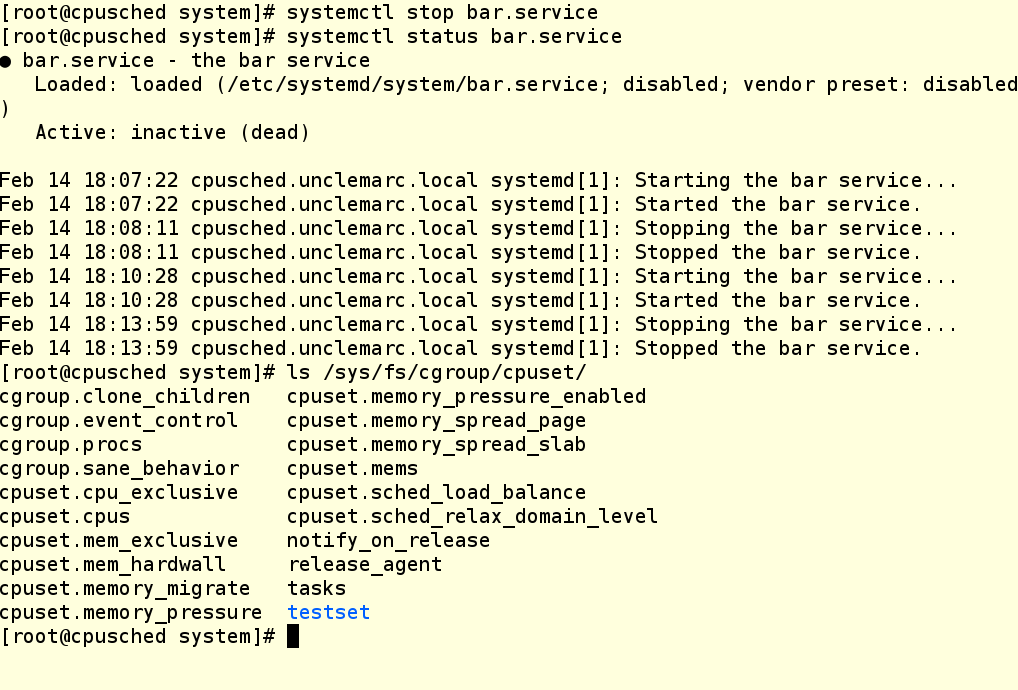
А теперь завершим работу нашего сервиса и проверим, что cgroup уничтожилась:
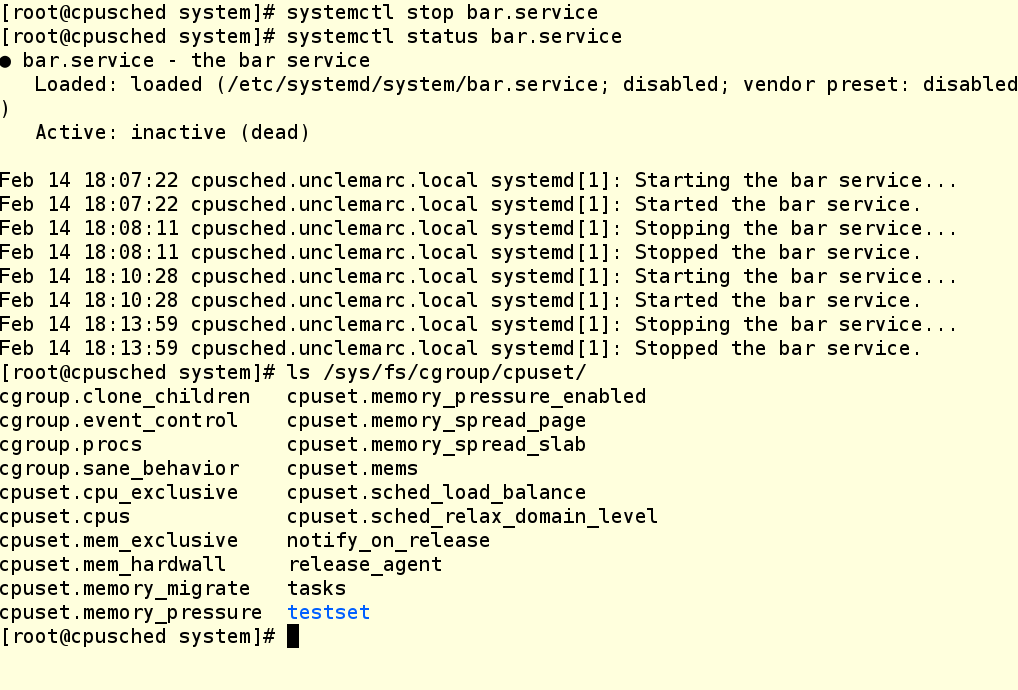
ВНИМАНИЕ: Группы cgroup, создаваемые с помощью cgcreate, не сохраняются после перезагрузки. Поэтому создание таких групп надо прописывать в сценариях запуска и юнит-файлах.
Так что теперь в вашем арсенале есть еще парочка инструментов для работы с cgroups. Надеемся, они пригодятся!
Другие посты по cgroups из нашей серии «Борьба за ресурсы» доступны по ссылкам:

Разумеется, можно. Иначе мы бы не выбрали этот вопрос в качестве темы сегодняшней статьи.
В детстве нам часто говорили, что делиться – это хорошо и правильно. По большому счету, так оно и есть. Но бывают исключения.
Как мы писали в первом посте этой серии, по умолчанию Red Hat Enterprise Linux 7 ведет себя как сферическая добрая бабушка. В том смысле, что она старается справедливо распределять системные ресурсы между всеми, кто их просит. Однако в реальной жизни у бабушек бывают любимчики, которым достается больше. В переводе на сисадминский это означает, что бывают ситуации, когда одни приложения или сервисы важнее других, поэтому им надо уделять всё возможное внимание, чтобы они были максимально отзывчивы.
В Red Hat Enterprise Linux 7 это делается в два этапа:
- Изолируем часть процессорных ядер, чтобы передать их в эксклюзивное пользование такому приложению.
- Создаем группы cgroups и юнит-файлы, привязывающие это приложение к изолированными ядрам.
Небольшое отступление касательно примеров из этих постов
В Hat Enterprise Linux 7.4 изменился механизм работы с недолговечными слайсами, типа пользовательских сеансов. В результате для них больше нельзя менять настройки cgroup на лету, вносить постоянные изменения в конфигурацию, а также создавать файлы drop-in с помощью команды systemctl set-property. Да, это обидно, но так уж решило сообщество разработки Linux. Хорошая новость в том, что эти изменения не затронули службы. То есть, если приложения запускаются и останавливаются через юнит-файлы (работают в качестве демонов), то все наши примеры работают. Кроме того, остается возможность создавать собственные cgroups с помощью таких древних инструментов, как cgcreate и cgset, и затем помещать в эти группы пользовательские сеансы и процессы, чтобы задействовать CPU-шары и прочие регуляторы. В жизни все меняется, поэтому нам остается только приспосабливаться и изобретать новые техники. А теперь переходим к сегодняшней теме.
Устраиваем сепаратизм с помощью isolcpus
Одна из самых важных составляющих в ядре Linux – это планировщик (диспетчер) процессов. Если чуть глубже, то процесс – это исполняемый код, являющийся часть приложения или сервиса. По сути, процесс состоит из серии инструкций, которые компьютер выполняет, делая ту или иную работу, будь просмотр котиков или что-то посерьезнее.
Выполнением этих инструкций занимается центральный процессор, он же CPU. На современных компьютерах CPU, как правило, состоит из нескольких процессоров, которые называются ядрами.
По умолчанию планировщик рассматривает каждое процессорное ядро как один из исполнительных модулей, которым он поручает новые процессы по мере их появления. При этом планировщик старается более-менее равномерно распределять возникающие процессы между ядрами с учетом нагрузки. К сожалению, планировщику нельзя сказать, что вот этот конкретный процесс со временем породит целую группу процессов, и эту группу надо будет выполнять изолированно от остальных процессов, в том смысле, что у них не должно быть общих процессорных ядер.
Поэтому нам надо как-то сказать планировщику, чтобы он не трогал часть процессорных ядер, то есть не отдавал им какие ни попадя процессы. А затем мы сами (или с помощью какого-то другого процесса) будем принудительно сажать на эти изолированные от планировщика ядра те процессы, которые посчитаем нужными. Это можно сделать с помощью параметра isolcpus в строке загрузки ядра в конфигурационном файле grub. В примере ниже у нас машина с четырьмя ядрам, на которой есть два файла grub: один лежит в /etc/default и называется grub.noiso (это резервная копия конфигурации по умолчанию), а второй лежит там же и называется просто grub, чтобы его подхватывал grub2-mkconfig. Этот второй файл подредактирован так, чтобы изолировать ядра 1-3 от планировщика процессов.
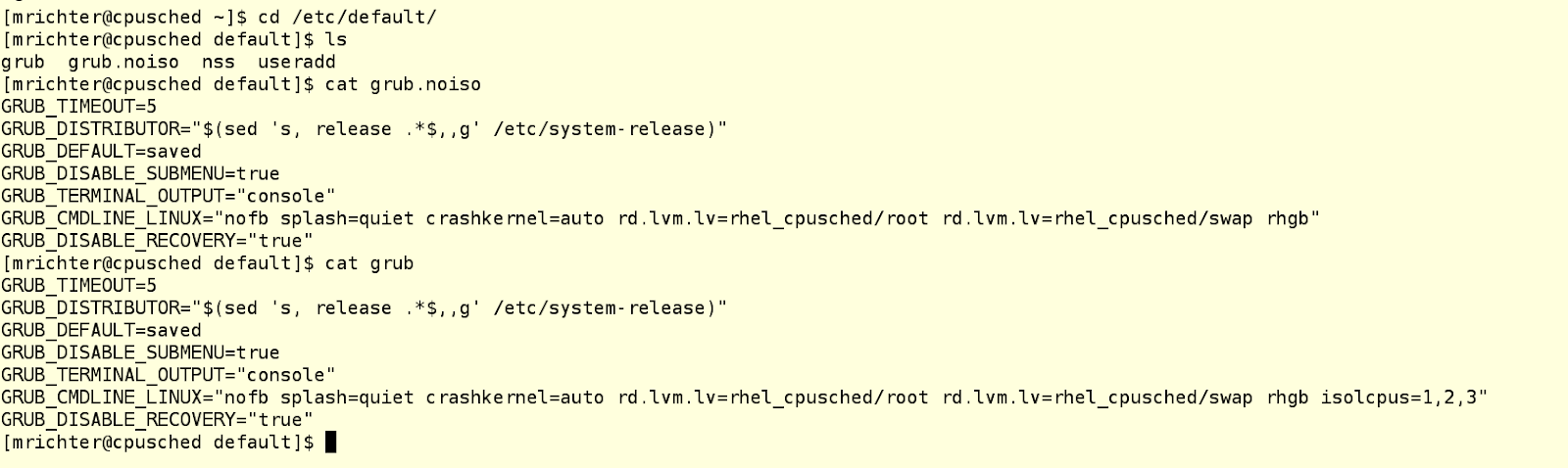
ВНИМАНИЕ: в Red Hat Enterprise Linux 7 никогда не надо вручную модифицировать файл grub.conf в папке /boot. Вместо этого внесите необходимые изменения в /etc/default/grub и затем пересоберите grub.conf file с помощью соответствующей утилиты, например, так:
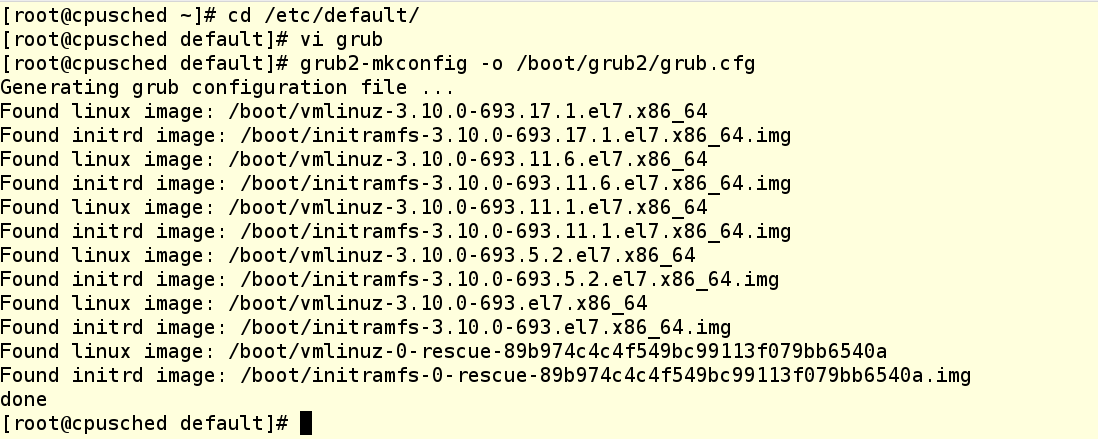
При использовании параметра isolcpus надо через запятую перечислить высвобождаемые процессорные ядра, нумерация начинается с 0. После перезагрузки системы планировщик процессов не будет использовать эти ядра ни для чего, за исключением определенных процессов системного уровня, которые ДОЛЖНЫ БЫТЬ на каждом ядре. Чтобы проверить, сработал ли наш метод, запустим несколько нагрузочных процессов и затем посмотрим загрузку каждого ядра с помощью команды top.

Как видим, все нагрузочные процессы сели на CPU 0, вместо того, чтобы равномерно распределиться по всем четырем ядрам. Значит, мы прописали загрузочный параметр правильно.
Привязываем процессы к ядрам с помощью cpuset
Теперь переходим к вещам, которые лучше не делать, если вы не понимаете, зачем это делаете, а также которые лучше развертывать в продакшне только после тщательного тестирования.
К чему эти предостережения? К тому, что мы будем делать, в общем-то, простые вещи с помощью инструментария libcgroup, о котором писали в прошлом посте. Если помните, это просто набор команд для создания, модифицирования и уничтожения групп cgroups. Вообще-то они являются частью Red Hat Enterprise Linux 6, но их можно установить и на Red Hat Enterprise Linux 7, хотя не исключено, что в будущем эта возможность исчезнет. Вкратце напомним основные рекомендации по использованию libcgroup:
- Используйте systemd для управления теми контроллерами-регуляторами cgroup, которые находятся под управлением самого systemd (это CPU, память и блочный ввод-вывод).
- Используйте инструменты libcgroup для управления всеми остальными контроллерами-регуляторами cgroup.
- Будьте очень осторожны в плане незапланированных последствий ваших действий.
С концепцией cpuset все просто – это список процессорных ядер (нумерация, напомним, начинается с 0), принимающий задачи, которые будут исполняться ТОЛЬКО на этих ядрах. Это самые обычные процессорные ядра, они могут находиться либо под управлением планировщика процессов (именно так система настроена по умолчанию), либо, наоборот, могут быть изолированы от планировщика (как мы сделали в примере выше).
Давайте проверим каталог /sys/fs/cgroup filesystem на системе из нашего примера. Как видим, каталог cpuset уже существует, поскольку этот контроллер – это часть ядра (хотя он и не находится под управлением systemd). Однако в нем пока нет cgroups, поэтому мы видим в этом каталоге только настройки по умолчанию.

Проверим, что на нашей машине установлен инструментарий libcgroup:

Если не установлен, то это легко исправить командой yum install libcgroup, даже перезагрузка не понадобится.
Теперь создадим cpuset. Для этого мы будем использовать следующие команды, чтобы создать новую cgroup для cpuset и прописать ее свойства:
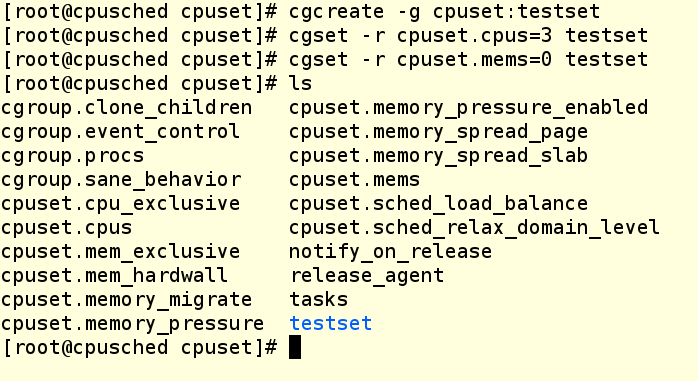
Команда Cgcreate создает cgroup с именем testset и размещает ее внутри контроллера cpuset. Затем мы назначаем третье ядро нашей ВМ этому новому cpuset’у и выделяем ему же NUMA-зону 0. Даже если ваша система не использует NUMA (а наша как раз не использует), зону все равно надо прописывать, иначе не получится назначать задачи группе cgroup. Теперь проверим, что в файловой системе создался каталог testset, и посмотрим, что у него внутри.
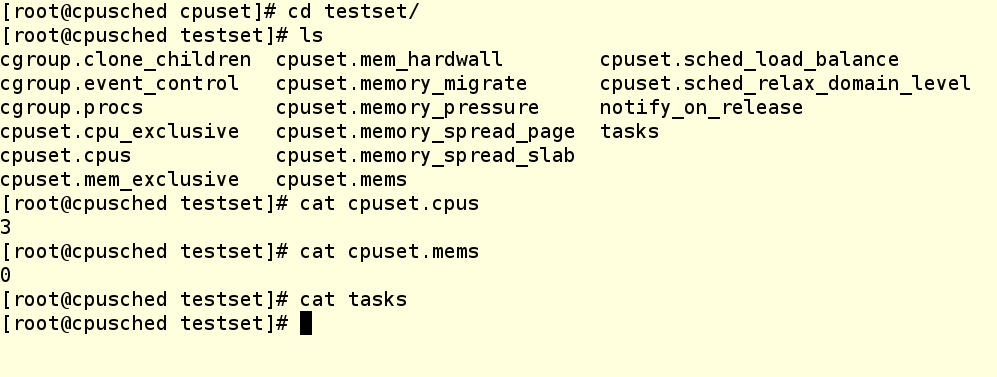
Как видим, наши изменения на месте, но на этом cpuset’е пока что не выполняется ни один процесс. Как посадить сюда какой-нибудь процесс?
Это можно сделать несколькими способами:
- Можно вбить PID существующего процесса в файл tasks. Это работает, но не очень красиво.
- Можно воспользоваться cgexec и указать группу при запуске процесса. Это работает, если приложение не является демоном; к тому же, все это можно красиво прописать в скрипт запуска приложения.
- Для приложения, которое запускаются в качестве демона под управлением systemd, можно создать service-файл.
Давайте посмотрим вариант с cgexec.

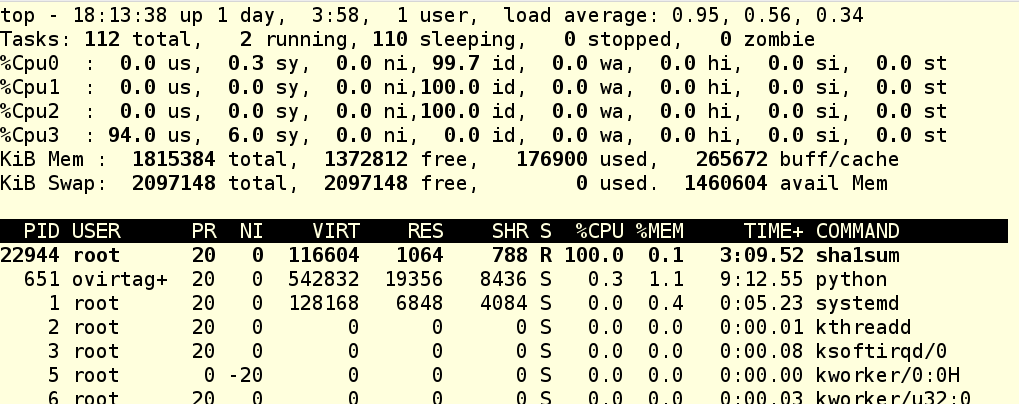
Мы запустили foo.exe, он в свою очередь запустил дочерний процесс, который только и делает, что активно грузит процессор. Опция --sticky в команде cgexec говорит, что «любой дочерний процесс должен оставаться в той же cgroup, что и родительский процесс». Так что это важная опция, и ее надо запомнить. Теперь мы видим, что в нашей cgroup крутятся два процесса, и мы знаем их PID’ы. Глянем top:

Как видим, CPU 3 теперь загружен под завязку, а остальные прохлаждаются.
А вот как выглядит юнит-файл для запуска того же приложения в качестве сервиса systemd:
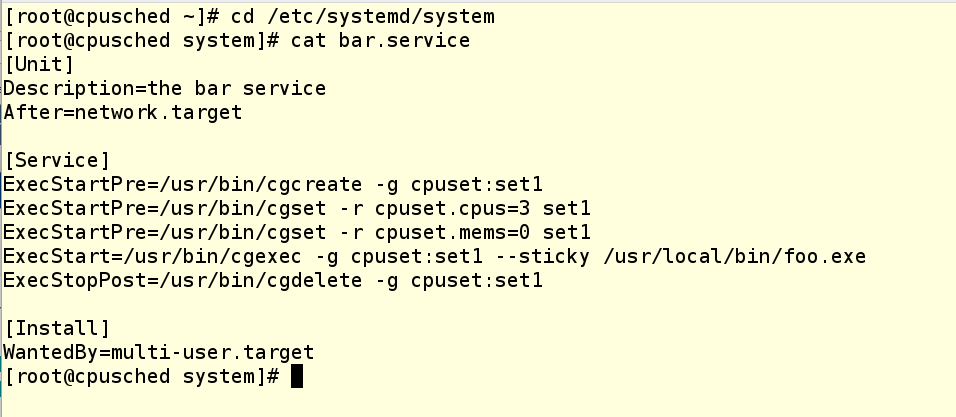
В юнит-файле есть три команды ExecStartPre, которые выполняют настройки, которые мы уже успели сделать руками. Затем идет команда ExecStart, которая запускает приложение. А при остановке приложения, команда ExecStopPost подчищает за собой, удаляя cgroup.
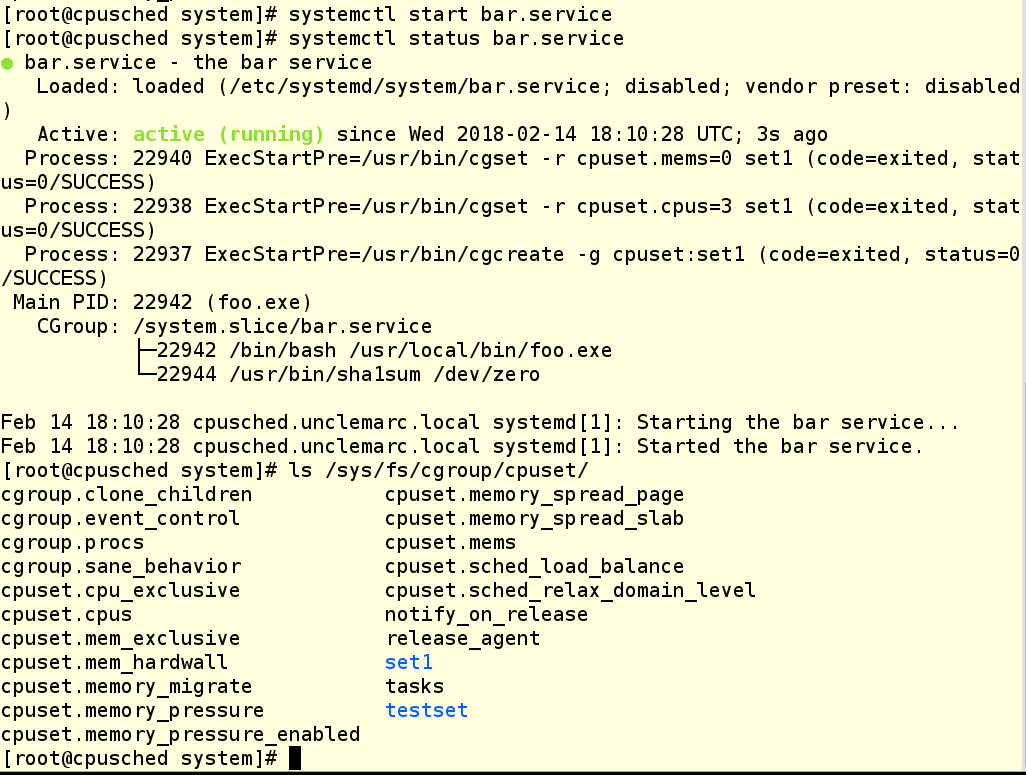
Как видите, в последнем примере мы создали новую cgroup по имени set1. Мы сделали это, чтобы показать, что можно иметь несколько активных cgroups, которые делят одни и те же CPU. Кому это может показаться полезным, а кого-то наоборот запутать.
Ну что, все работает? Похоже, да!
А теперь завершим работу нашего сервиса и проверим, что cgroup уничтожилась:
ВНИМАНИЕ: Группы cgroup, создаваемые с помощью cgcreate, не сохраняются после перезагрузки. Поэтому создание таких групп надо прописывать в сценариях запуска и юнит-файлах.
Так что теперь в вашем арсенале есть еще парочка инструментов для работы с cgroups. Надеемся, они пригодятся!
Другие посты по cgroups из нашей серии «Борьба за ресурсы» доступны по ссылкам:
