Comments 146
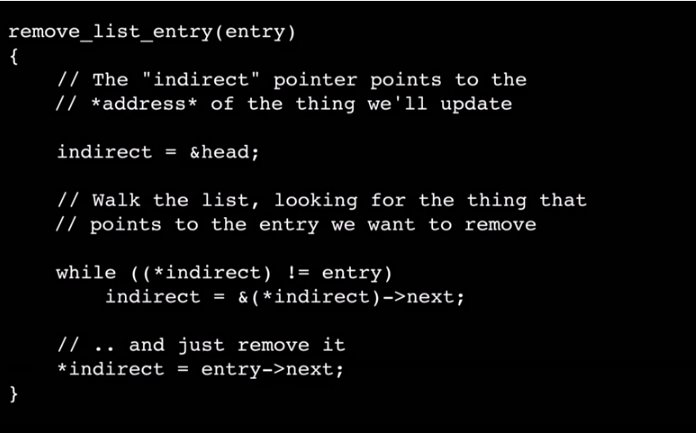
Главное при этом не забывать высвободить память.
Там кроме утечки проблема с удалением последнего элемента.
Да, меня уже поправили. Пишу в основном на С++, поэтому отвык от трюков "указатель на указатель".
Все свалится.
Эта штука удаляет ноду по указателю. Следовательно, указатель надо ещё где-то получить. Подозреваю, это пример какой-то внутренней функции.
ЛЮБЫЕ входящие аргументы нужно проверять на корректность :-( Даже если лично вы не предполагали, что эта функция(метод) будет использована где-то, кроме как у вас.
В C/C++ принят иной подход: проверки осуществляются там и тогда, когда про это явно написано. И нигде более. Скажем написано что
delete принимает NULL и ничего не делает — значит передавать туда можно, не написано что free может его принимать — значит нельзя и никаких проверок там не будет.Спорить о философиях — бессмысленно, ходить со своим уставом в чужой монастырь — тем более.
Случай с памятью — возможно, функция служит лишь для открепления элемента. То есть, список предназначен чтобы иметь указатели на объекты, но не владеть ими в плане памяти.
Случай с последним элементом — какая там по вашему ошибка? В последнем элементе next должен быть nullptr, следовательно next предпоследнего элемента встанет в next последнего, то есть nullptr. Вы думали, цикл while останавливается на последнем элементе, на самом деле он останавливается на указателе на указатель next предпоследнего.
финальная версия будет неоптимальна из-за кэш-промахов.
Может вы поясните каким образом и почему она будет неоптимальна с т.з. кэш-промахов? Интересно. Спасибо.
Вероятно, имелось в виду, что поочередное обращение к "далеко-расположенным" в памяти данным потребует постоянной перегрузки данных между кэшем данных процессора и оперативной памятью. Вики
Когда процессор читает из памяти байт — он копирует его из оперативной памяти в кеш. На всякий случай копирует не только его, но и его соседей. В достаточно большом количестве. Поэтому, если читаешь или пишешь соседние байты, то считывать данные в кеш много раз не надо — достаточно одного.
А если читаешь или пишешь не соседние байты, то нужно копировать их в кеш по много раз.
Когда процессор читает из памяти байт — он копирует его из оперативной памяти в кеш. На всякий случай копирует не только его, но и его соседей.
Процессор никак не может читать из памяти. Он с нею никак не связан. Никаких «случаев» нету — память читается в кеш, а в кеше минимальная адресуемая единица — кешлайн.
Поэтому, если читаешь или пишешь соседние байты, то считывать данные в кеш много раз не надо — достаточно одного.
Опять какая-то муть. Все остальные «байты» итак пишутся. Я конечно понимаю, что отвечать на вопросы прямо вы не можете, но всё же:
что поочередное обращение к «далеко-расположенным» в памяти данным потребует постоянной перегрузки данных между кэшем данных процессора и оперативной памятью.
Имеем юзкейкес «линейное чтение из 2-х мест». На основании чего «копия памяти» из места А будет инвалидировать «копию памяти» из места Б?
Я конечно понимаю, что отвечать на вопросы прямо вы не можете
Вот это — хамство. Вы можете считать ответ на вопрос неправильным, но это ответ именно на ваш вопрос. Хамить людям, которые не хамили вам — нехорошо.
Вы можете считать ответ на вопрос неправильным
Дело не в том, что я что-то там считаю — дело в том, что ваш ответ не состоятельный. И вам объяснили почему.
Вы влезли в разговор и попытались ответить, но опять же ничего не смогли, кроме как ретрансляции поверий уровня детского садика. При этом даже не можете понять, либо хоть как-то пытаться их взять логически с вопросом.
Какое отношение ваш ответ имеет к предмету обсуждаемому здесь? Вы можете хоть каким-то образом объяснить — где конкретно в данном случае это проявляется и каким образом решение предложенной автором первоначального коммента решает проблему?
То, что автор мне ничего не ответит я знал изначально и написал это только лишь для того, чтобы те кто его плюсанул/почитал поняли, что он обычный балабол. Так бы человек читающий поверил, а так задумается — а понимает ли этот пассажир то, о чём собственно говорит.
Минусанул — не отвечал, после сослался на другой коммент и выкатил первую ссылку из гугла, которую нагуглил после прочтения чужого коммента, при это ни тот коммент, ни его ссылка к теме отношения не имеют — после минуснул и слился. Типичный эксперт.
он обычный балаболВот сейчас обидно было.
Дело не в том, что я что-то там считаю — дело в том, что ваш ответ не состоятельный. И вам объяснили почему.
Тот факт, что мой ответ не состоятельный — не повод хамить. Не повод вести себя так, как ведёте себя вы. То, что из вашего коментария можно вычленить, что инвалидация кеша в данном случае не происходит — хорошо. То, что вы попутно показали себя грубияном — плохо.
То, что автор мне ничего не ответит я знал изначально и написал это только лишь для того, чтобы те кто его плюсанул/почитал поняли, что он обычный балабол.
Было бы гораздо лучше, чтобы вы писали коментарии не для того, чтобы окружающие понимали, что кто-то там балабол, а для того, чтобы рассказать окружающим как оно на самом деле.
По ссылке сравнение обхода по столбцам и строкам, что вызвано не «поочередное обращение к „далеко-расположенным“ в памяти данным», а разницей между шириной чтения реальной и используемоей — т.е. основная часть пропускной способности летит в трубу и кеш тут непричём. Что собственно там и написано.
Осталось только понять каким образом связан юзкейс тот и тот, что представлен в статье. В данном случае никак обход изменить нельзя — он всегда будет по столбцам. При этом запись в столбцы никак не будет вытеснять строки, ибо хитов в столбец будет ровно один, а строку намного больше.
Если проще — между итерациями данные(строк) в кеше никуда не пропадут, ибо имеют больший приоритет из-за частоты использования.
В целом всё остаётся к силе.
Ну и да, каким образом «ссылочка на пример» имеет отношение к данному юзкейсу? Мне интересно. В очередной раз тутошние экперты оказались настоящими экспертами.
Может это реально не вы меня минусовали и я ошибся, но не особо это что-то меняет итак понятно почему.
Если производительность важна, то однозначно да.
Причем абсолютно верно, что столбцы одним циклом, ибо скорее всего правая предыдущая ячейка в том же блоке памяти, что текущая левая.
Проблема в том, что кроме параметра "красоты" код должен быть рабочим. По этому параметру плохи оба варианта.
Исходный пример делает по сути detach, не удаляя саму ноду списка.
Пример "со вкусом" оставляет утечку entry->next — т.к. "удалённая" нода перезаписывается копией следующей — но исходная останется висеть в памяти. Не говоря о том, что он свалится при удалении хвоста, у которого нет next
for (r = 0; r < GRID_SIZE; ++r) {
for (c = 0; c < GRID_SIZE; ++c) {
bool itsEdge = (r == 0 || c == 0 || c == GRID_SIZE - 1 || r == GRID_SIZE - 1);
if(itsEdge) grid[r][c] = 0;
}
}
Ради того, чтобы засетать края квадрата проходить по всем его элементам? Серьёзно?
for (r = 0; r < GRID_SIZE; ++r) {
for (c = 0; c < GRID_SIZE; ++c) {
// Верхний край
if (r == 0)
grid[r][c] = 0;
// Левый край
if (c == 0)
grid[r][c] = 0;
// Правый край
if (c == GRID_SIZE - 1)
grid[r][c] = 0;
// Нижний край
if (r == GRID_SIZE - 1)
grid[r][c] = 0;
}
}
И исправление только по поводу читаемости, понятности, количества строк.
Легко понять вот такое?
if(r == 0 || c == 0 || c == GRID_SIZE - 1 || r == GRID_SIZE - 1) grid[r][c] = 0;
Нет, не легко, вообще не ясно.
В моей же варианте мы явно говорим, что сначала мы проверяем край это или нет.
А потом в зависимости от этого уже что-то делаем
Второй пример — отличный контраргумент в споре о том, нужны ли алгоритмы. Никакой вменяемый программист, который понимает работу алгоритмов, не будет реализовывать n^2 решение для задачи, явно требующей линейного времени. Да и вообще, подозреваю что большинство бы реализовало сразу же последний вариант, т.к. он очевиден. Так что здесь скорее не о вкусе, а вообще о понимании, что ты делаешь.
Я вообще ничего не имею против С программистов, но реализовывать одни и те же вещи раз за разом это НЕ хороший вкус. И дело даже не в криворукости, а в потраченном времени. Посмотрите на какую-нибудь реализацию std::sort в stl и подумайте, сколько времени понадобилось бы «не криворукому» программисту на аналогичную по эффективности и гибкости реализацию, учитывая дебаг, оптимизацию, тестирование и бенчмаркинг.
Я не знаком с миром микроконтроллеров, но это слишком узкая специфика, давайте может вообще о программировании для картриджей NES поговорим? Если какая-то область разработки полна велосипедов и костылей и при этом работает, это не значит, что у них все в порядке со вкусом/качеством итд.
Вот тот пример от Линуса — он не только сделал код короче. Он ещё и убрал один условный переход чем сильно облегчил жизнь процессору. Теперь процессору не надо будет сбрасывать конвеер, если предсказатель переходов ошибся.
Наверное потому, что компилятор простой и потому удобно писать вещи вроде ОС? В плане производительности некоторое подмножество С++ не хуже будет.
> Он ещё и убрал один условный переход чем сильно облегчил жизнь процессору. Теперь процессору не надо будет сбрасывать конвеер, если предсказатель переходов ошибся
Один условный переход — это сильно, конечно. Вот только скачки по указателям, которые мажут мимо кэша практически полностью нивелирует эту оптимизацию. Я не говорю, что рефакторинг плох, просто изначально пример выбран странный.
list довольно широко используется в ядре. Во-первых, удобно добавлять/удалять элементы в начало (+ в конец в double linked-list), а индексация не так часто нужна. Во-вторых, объекты бывают довольно тяжёлыми, поэтому (пере-)выделять и копировать память лишний раз не станут (что в случае динамического массива происходит периодически). Думаю, немаловажен и детерминизм списка: мы точно не начнём возиться с памятью, когда нам нужно найти кандидата из процессов на квант времени. Хоть hard real-time и не поддерживается, в ядре важна детерминированность.
Насчёт промахов по кэшу согласен, список плох. В пространстве пользователя почти нет смысла использовать (кроме, опять же, больших объектов). Но, по-видимому, в ядре достоинства перевешивают.
По поводу объектов, кстати, ничто не мешает хранить указатели в массиве, сами объекты двигать не нужно тогда. Конечно, это лишний переход по указателю, но в списке их гораздо больше. Для добавления в конец и начало есть дек (хотя никогда не тестировал его производительность). Но если для ядра амортизация не подходит, то да, прийдется использовать список.
Меня очень радует ваша самоуверенность и пренебрежение к работе других людей. Вы ведь никогда не тестировали производительность std::sort, правда? И, кстати, привести пример «приспособления к данным»? А вообще не вижу смысла что-то объяснять, у вас явно есть очень четкая позиция.
C-реализацию хэш-таблицы vs std::map и std::set.
Я могу не глядя в реализации сказать, что O(1) обычно быстрее O(log n), не говоря уже об ужасной аллокации памяти в деревьях (как в списках, только хуже). Вы, кстати, хэш-таблицу не на списках писали, я надеюсь?
А где вы тут углядели пренебрежение совсем непонятно. Скорей наоборот, это вы отказываете в здравомыслии всем, кроме разработчиков каких-то отдельных библиотек.
Повторюсь, дело не в здравомыслии, а во времени. Я просто не считаю себя умнее группы других людей, работавших над данной конкретной задачей достаточно долгое время. Конечно, если вы пишете на С, то вы не можете пользоваться той же STL, но нужно понимать, что отсутствие хорошей стандартной библиотеки — это недостаток, а не достоинство.
При написании уеб-говнокода (херак, херак и в продакшн), да, дело во времени. При написании ядра операционки — в здравомыслии. Линус специалист по второму. Об этом и рассказывает и учит. Зачем ему учить первому? «специалистов» по первому учить не надо, они сами плодятся.
>нужно понимать, что отсутствие хорошей стандартной библиотеки — это недостаток, а не достоинство.
На уровне ядра «стандартная библиотека» — это только то, что они написали сами. Это не достоинство и не недостаток, это реальность. Да и в любом другом случае, стандартная библиотека не появляется ниоткуда божественным провидением. И её, сурпрайз, приходится кому-то писать. И даже херак-херак код далеко не всегда, оу, ещё один сурпрайз, состоит из последовательного применения функций стандартной библиотеки.
Еще короче: велосипедить — плохо.
Если решения нет, то его, естественно, придется создать, я этого ни в коем случае не отрицаю. Просто заметьте, что в наше время львиная доля базовых, не очень базовых и совсем не базовых вещей уже реализована. Хоть свой Bolgenos пилите, ядро Linux вот прям по ссылке доступно.
Кто утверждает? Линус?? Вы серьёзно? Кто этот «кто-то»?
По-моему вы выдумали какую-то глупость и пытаетесь «кого-то» убедить, что это глупость. А о том, что мир не заканчивается и даже не начинается на херак-херак коде даже услышать не в состоянии. Тем не менее, это так. А статья вообще не об этом.
что O(1)
Вы, кстати, хэш-таблицу не на списках писали, я надеюсь?
Такие взаимоисключающие параграфы.
Я могу не глядя в реализации сказать,
А ничего, что O(1) стоит 4кб на елемент минимум? А уж про время ресайза я даже не говорю.
не говоря уже об ужасной аллокации памяти в деревьях (как в списках, только хуже).
Ужасные аллокации( что это?) проблемы stl в который не завезли вменяемый аллокатор.
Я просто не считаю себя умнее группы других людей, работавших над данной конкретной задачей достаточно долгое время.
А над какой задачей работали эти люди? И какое-такое «долгое время»?
Конечно, если вы пишете на С, то вы не можете пользоваться той же STL, но нужно понимать, что отсутствие хорошей стандартной библиотеки — это недостаток, а не достоинство.
Это достоинство. При осмысленном использование си — это не язык — это подход.
Ну и кто вообще сказал, что stl — это «хорошая библиотека»/«хороший подход» с т.з. производительности? Это хорошая обобщенная библиотека и продукт ограниченный рамками заранее определённого интерфейса и интеграции.
И вообще — этот один std::sort может породить столько кода, что сожрёт половину места под программу на контроллере — и всё равно будет тормозить потому что обтимизирован под объёмы которые в микроконтроллер просто не влезут.
Стандартные библиотеки почти всегда работают не так уж хорошо, на самом деле. Их используют не потому, что нельзя сделать быстрее, а потому, что сделать быстрее и «правильнее» с точки зрения конкретной задачи банально дольше и сложнее.
Представляется, что проблема культуры Си-программирования именно в том, что люди почти всегда сами реализуют структуры данных для программ, поэтому редко выходят за определённый уровень сложности, за которым начинается совсем другая жизнь и по эффективности, и вообще по возможностям более оптимально выстроить программу.
Как пример: тема юниядер (unikernels) в ML. Ребята умудряются загружать виртуальную машину с полноценным web-сервером за время dns-ответа клиенту.
И мы знаем, как оптимально этот набор реализовывать для тех или иных условий исполнения: микроконтроллеры или многоядерные процессоры, много памяти или мало, и т.д.Знаем, да. Чего мы не знаем — так это способа сделать нечто что будет работать хорошо везде. Можно сделать библиотеку, которая будет отлично работать на микроконтроллерах, но тогда на NUMA-системах она будет «сливать», можно сделать что-то, что будет отлично работать на серверах с 128 процессорами — но тогда на одном она будет тормозить и т.д. и т.п.
Стандартная библиотека же делается так, чтобы везде вести себя «прилично» — в результате максимальной скорости они не достигает нигде. И памяти они тоже использует «немного» — что может быть неприемлемо для микроконтроллеров, и медленно на серверах с сотнями гигабайт памяти.
То, что ML умеет загрузить виртуальную машину за время dns-ответа — это круто, конечно, но говорит скорее о том, что dns-ответ — штука медленная. И, потом, они явно не на микроконтроллере это делают. А сервер на микроконтроллере вполне может понадобится — и что вы будете делать если уже заложились на использование отдельной виртуальной машины для каждого запроса?
Без «кучи».
Когда ещё были в ходу компакт диски (или ещё раньше, когда флопы), при попытке обращения к дефектному диску колом вставала вся операционка.
А когда у меня на работе была вин2000, я по приходу включал компьютер и шёл к коллегам пить кофе. Как раз к возвращению она успевала загрузиться (не всегда). Вот что она делала? ;) лучше бы она была написана на лиспе. :)
Когда ещё были в ходу компакт диски (или ещё раньше, когда флопы), при попытке обращения к дефектному диску колом вставала вся операционка.
Вы, веротяно, имеете в виду врмена 9х, когда Ос использовала драйвера ДОС, которые действительно могли встать колом.
А когда у меня на работе была вин2000, я по приходу включал компьютер и шёл к коллегам пить кофе.
Когда у меня на работе была В2000, она была эталоном и скорости и стабильности в мире Вин. ХР на том же железе загружалась медленнее. Не представляю, что с ней надо сделать, чтобы загрузка так растянулась.
И даже не снятся по ночам переменные вида lpctszStr = «blabla»?
Счастливый вы человек!
>Вы, веротяно, имеете в виду врмена 9х
Ноусэр! Тёмные времена 9х я объехал на варпе (os/2 warp). Это были nt4 и xp.
>Когда у меня на работе была В2000, она была эталоном и скорости и стабильности в мире Вин.
Как вы, наверное, понимаете, мне от этого ничуть не легче.
>Не представляю, что с ней надо сделать, чтобы загрузка так растянулась.
Ничего сверх того, что она сама позволяла. Там вообще мало что было — JDK, эклипс, фотошоп, ну, и вездесущий офис. Ума не приложу что она всё это время делала, но, подозреваю, что на лиспе она сделала бы это быстрее :).
Ещё у 2к любимым развлечением было залочить файло, присланное по самбе так, что и с админскими правами их нельзя было удалить (это не моя делала — соседняя).
Ума не приложу что она всё это время делала, но, подозреваю, что на лиспе она сделала бы это быстрее :).
Это ещё почему?
И даже не снятся по ночам переменные вида lpctszStr = «blabla»?
Счастливый вы человек!
А вы не путайте код интерфейса Win32 для юзерспейса и код ядра.
Ноусэр! Тёмные времена 9х я объехал на варпе (os/2 warp). Это были nt4 и xp.
Тогда не верю про «вставала колом вся операционка». Или вы очень вольно используете слова «вся операционка».
Как вы, наверное, понимаете, мне от этого ничуть не легче.
Как вы, наверно, понимаете, это значит, что вы что-то делаете не так.
Ничего сверх того, что она сама позволяла. Там вообще мало что было — JDK, эклипс, фотошоп, ну, и вездесущий офис.
Да хоть 100 прикладных программ. При чем тут загрузка системы?
А код интерфейса Win32 не является виндосом? Как интересно! А чем он является? Может линуксом? Или макосью?
>Тогда не верю про «вставала колом вся операционка»
Пожимая плечами — не может быть потому что не может быть никогда? А, ну-ну. Разумеется.
> Или вы очень вольно используете слова «вся операционка».
Ну, поскольку с вашей точки зиения, как выяснилось, отдельные части виндоса виндосом не являются, то, таки да. Например, таймер, скорее всего, продолжал тикать. «вся операционка, кроме таймера» — так устроит? Только вот это ничего не меняет.
>Как вы, наверно, понимаете, это значит, что вы что-то делаете не так.
Стандартный приём демагогии микрософта. Разумеется, что-то не так. Посмел вставить в сидюк сбоящий диск. Вот я подлец-то какой! На какой страничке eula, говорите, запрещено вставлять в сидюк сбоящий диск?
>Да хоть 100 прикладных программ. При чем тут загрузка системы?
Вот и мне интересно. Впрочем, нет. Не было интересно ни тогда — вызывало только раздражение, не интересно и теперь — проще проголосовать ногами. Всего лишь отметил этот печальный факт.
А код интерфейса Win32 не является виндосом? Как интересно! А чем он является? Может линуксом? Или макосью?
Я имею в виду декларации API, не распаляйтесь. Да, э то не «код Windows».
Стандартный приём демагогии микрософта. Разумеется, что-то не так. Посмел вставить в сидюк сбоящий диск. Вот я подлец-то какой! На какой страничке eula, говорите, запрещено вставлять в сидюк сбоящий диск?
Да нет, просто со времен 95-98 ни разу такого не было, хотя диски самой разной сбойности читал. Вот и удивляюсь.
Я понимаю, что вы имеете в виду. И теперь меня терзает вопрос (так, что кюшат нэ могу) — чей же это код?
Да и как быть со Спольски? Он подробно описывал «венгерскую» нотацию, какая она должна быть, почему всё пошло не так и про то, что именно вариант «не так» прижился и широко распространился и в мс тоже (не говоря о том, что это был рекомендованый вариант во всей мс документации). Неужели Джоэль соврал?
Я понимаю, что вы имеете в виду. И теперь меня терзает вопрос (так, что кюшат нэ могу) — чей же это код?
Чего угодно — это декларации для взаимодействия с системой, а не сама система.
Да и как быть со Спольски? Он подробно описывал «венгерскую» нотацию, какая она должна быть, почему всё пошло не так и про то, что именно вариант «не так» прижился и широко распространился и в мс тоже (не говоря о том, что это был рекомендованый вариант во всей мс документации). Неужели Джоэль соврал?
Отчасти да. «Неправильная» венгерская нотация используется в API, продуктах MS типа офиса и прочего юзерспейса. Внутри этого нет.
Ой, как интересно! Выглядит как утка, ходит как утка, крякает как утка — всё что уголно, только не утка! И что ещё, по вашему, из виндовс не является виндусом? Графическая оболочка — это же не виндовс, правда? Всё, что угодно, но не виндовс. Или, вот, ядро. Оно же — ядро системы, оно же не система., ага? Смешно.
>Отчасти да. «Неправильная» венгерская нотация используется в API, продуктах MS типа офиса и прочего юзерспейса. Внутри этого нет.
Ну, вот, оказывается, что и Джоэль всё врёт! Он-то утверждает, что в офисе использовалась «правильная» венгерская нотация (которая называлась, внимание, венгерской нотацией для приложений), а в остальном виндовс, во всей документации — дебильная (которая так и называлась, внимание-внимание, системная венгерская нотация. Системная, Карл!). Врёт значит. И виндовсе ничто виндовсом не является. Супер. Вы хоть понимаете насколько ценными выглядят ваши утверждения? Кстати, ваше имя не д`Артаньян случайно?
Зы пошёл жечь книги лгунишки Спольского. Один д`Артаньян открыл мне глаза на его истинную сущность…
Графическая оболочка — это же не виндовс, правда? Всё, что угодно, но не виндовс. Или, вот, ядро. Оно же — ядро системы, оно же не система., ага? Смешно.
Почему? Я просто указал на то, что венгерская нотация, которая не понравилась моему собеседнику, применяется не везде. Об этом же говорит Д.С.
Ну, вот, оказывается, что и Джоэль всё врёт! Он-то утверждает, что в офисе использовалась «правильная» венгерская нотация (которая называлась, внимание, венгерской нотацией для приложений)
А давайте мы предметно обсудим, с конкретными цитатами? Я готов отступить от «продуктах MS типа офиса и прочего юзерспейса.» к «продуктах MS юзерспейса и документации» и признать, что я неправ относительно именно офиса. Это не меняет сути — есть «правильная» ВН, есть «дебильная». И есть код вовсе без ВН, о котором я и говорил.
а в остальном виндовс, во всей документации — дебильная
Насколько я помню его заметку, он вел речь как раз о пользовательской венгерской нотации (пользовательской — в смысле применяемой с «пользовательской» стороны, не со стороны ядра, 0 кольца).
(которая так и называлась, внимание-внимание, системная венгерская нотация. Системная, Карл!). Врёт значит.
Любой может найти код, скажем, диспетчера памяти NT, да чего угодно и убедиться самостоятельно — «дебильной» венгерской нотации там нет. Название «системная» скорее всего относится как раз к системному API.
Зы пошёл жечь книги лгунишки Спольского. Один д`Артаньян открыл мне глаза на его истинную сущность…
Какая экспрессия. Человек спросил «Спольски врет?» — это не я предложил такую форму общения. Замечу, слово «врет» не обязательно означает намеренную ложь. Я всего лишь сказал, что такое-то и такое-то утверждение не соответствует действительности, остальное — ваше воображение дорисовывает. Будьте спокойнее.
Variable Names
Variable names are either in «initial caps» format, or they are unstructured. The following two sections describe when each is appropriate.
Note that the NT OS/2 system does not use the Hungarian naming convention used in some of the other Microsoft products.
В конце-концов, даже если вы действительно работаете в тестах, это всего лишь означает, что drystone написан хорошо. А вы просили обратные примеры :).
Я не работаю в тестах, но если у меня есть подозрение, то я предпочитаю проверять, чем выдвигать голословные утверждения.
Так вот, ни один интерпретатор, никогда не сможет получить компилируемую производительность. Обратные утверждения — профанация.
Разумеется, сравнивать можно только одинаковые алгоритмы.
Что проверяете? Вы сомневаетесь, что код может быть написан плохо? Уверяю вас, вы сомневаетесь совершенно напрасно. Можете, хотя бы, посмотреть код автора из этой статьи. Что начальный, что, в общем-то, и конечный.
>Так вот, ни один интерпретатор, никогда не сможет получить компилируемую производительность. Обратные утверждения — профанация.
А я этого и не утверждал. Я утверждал совершенно другое.
>Разумеется, сравнивать можно только одинаковые алгоритмы.
Ну-у-у! Менять правила в ходе игры некрасиво.
Для списков и очередей я бы назвал стандартной queue.h. Но оно такое, полностью на макросах.
Программисты на С настолько суровы, что не используют библиотеки?
Так вот приведен пример кода такой библиотеки, что не так? Почему вы думаете, что это велосипед?
Ну и в любом случае, связный список — очень плохая структура данных
Серьезно? Вот в NT двусвязный список применяется, например, для связки структур типа EPROCESS в кольцо. Очень удобно и затрат накладных — ноль целых, мал-мала десятых.
Предложите альтернативу, учитывая, что элементы в памяти расположены произвольно, добавление/удаление происходит редко. Отдельный вектор с постоянным ресайзом?
Так вот приведен пример кода такой библиотеки, что не так? Почему вы думаете, что это велосипед?
Да, я был не прав, когда писал про 100 процентов. В библиотеке, безусловно, список придется реализовать. Но в реальности всё это давно написано и переписано десятки раз. Поэтому с большой вероятностью можно сказать, что что-то пошло не так, если вам пришлось писать свой список.
Вот в NT двусвязный список применяется, например, для связки структур типа EPROCESS в кольцо. Очень удобно и затрат накладных — ноль целых, мал-мала десятых.
Не знаком с этим, к сожалению. Возможно, это тот случай из 1 процента. А, вероятно, отдельный вектор был бы оптимальнее, с учетом того, что добавление/удаление происходит редко, как вы сами сказали.
Да даже не важно, квадратные массивы, или нет.
Код понятным должен быть.
Как нормальные люди рисуют рамку?
Рисуют верхнюю линию, потом нижнюю, потом левую, потом правую.
Или верхнюю, потом правую, потом нижнюю, потом левую. Короче линию за линией рисуют. А тут предлагается написать непонятный код, который к тому же будет медленнее, чем понятный.
Про первоначальный вариант я вообще молчу.
for i in range(max(cols,rows)):
# up
grid[0][min(cols-1,i)] = 0
# down
grid[rows-1][min(cols-1,i)] = 0
# left
grid[min(rows-1,i)][0] = 0
# right
grid[min(rows-1,i)][cols-1] = 0
В случае «некрасивого» решения это просто сращивание указателей, не очень красиво, но эффективно, а в случае «красивого» — это проход по всему списку от начала до конца — множество обращений к памяти, практически исключение процессорного кеша из применения, так как элементы списка не обязаны лежать линейно и т.п.? Или я что-то не понял из статьи?
char* p = &grid[0][0];
for (int i = 0; i < GRID_SIZE;)
*p = *(p + (GRID_SIZE-1) * i++) =
*(p + (GRID_SIZE-1) * i) =
*(p++ + (GRID_SIZE-1) * GRID_SIZE) = 0;
А потом будет рассказывать о хорошем вкусе :)
Но нет… Он вовремя остановился… Видимо, у него и правда есть хороший вкус.
static Singleton getInstance()
{
if(mInstance == null)
{
mInstance = new Singleton();
}
return mInstance;
}Поэтому я в какой-то момент перешёл на ручную иницализацию при запуске приложения:
static void initInstance()
{
mInstance = new Singleton();
}
static Singleton getInstance()
{
return mInstance;
}
static const Singleton& getInstance()
{
static Singleton instance;
return instance;
}И никаких висячих if.
Нууу да. Там выходит что-то типа такого:
pushq %rbp
movq %rsp, %rbp
movb guard variable for instance()::instance(%rip), %al
testb %al, %al
jne .LBB0_3
movl guard variable for instance()::instance, %edi
callq __cxa_guard_acquire
testl %eax, %eax
je .LBB0_3
movl instance()::instance, %edi
callq Singleton::Singleton()
movl guard variable for instance()::instance, %edi
callq __cxa_guard_release
.LBB0_3:
movl instance()::instance, %eax
popq %rbp
ret`
Если уж лишний test мешает, то, наверное, можно, презрев приличия, сохранить в этом месте локальную копию указателя на объект. Только с потоками не налажать.
Я бы такой говнокод как в первом и во втором варианте не написал бы никогда в принципе, даже в детстве, на моем спектруме это бы просто год работало бы.
Как вообще полное решение могло в голову автору прийти?
GRID_SIZE_X != GRID_SIZE_Y, что обычно встречается на практике.
Как тут было замечено строки (или столбцы, в зависимости от последовательности выделения памяти) лучше обнулять с помощью memset(...), а потом столбцы (или строки) в цикле. Нет условий и максимальная скорость работы.
де факто там получится оптимально первая строка кроме последней ячейки, потом цикл по правому краю, кроме последней строки (+ левый край через адрес+1), потом нижняя строка, кроме первого элемента )
а вот использовать цикл или memset — не так уж и важно. современные компиляторы очень хорошо оптимизируют такой код, и for может оказаться быстрее за счет использования векторных инструкций. библиотека может оказаться не оптимизированной под ваш target.
for (char *p = &grid[0][0], *q = p+GRID_X; p < q; p++) *p = *(p + GRID_X*(GRID_Y-1)) = 0;
for (char *p = &grid[0][0], *q = p+GRID_X*GRID_Y; p < q; p += GRID_X) *p = *(p + GRID_X-1) = 0;
Но на мой вкус лучше делать одним циклом с разумным минимумом условий:
char *p = &grid[0][0], *q = p;
for (int i = 0; i < max(GRID_X, GRID_Y); i++, p++, q += GRID_X) {
if (i < GRID_X) *p = *(p + GRID_X*(GRID_Y-1)) = 0;
if (i < GRID_Y) *q = *(q + GRID_X-1) = 0;
}
К примеру, на CMS Drupal функционал каталога можно реализовать (1) кастомным кодом, (2) используя контриб модули Ubercart или Commerce, (3) используя встроенные штатные модули Taxonomy + Views.
Третий вариант, на мой взгляд, это и есть концепция «хорошего вкуса». Позволяет сделать именно то, что нужно. Не тянет лишних зависимостей или лишнего функционала, как у второго варианта. Безопаснее и легче в поддержке по сравнению с первым.
ИМХО, если нет супер критических требований по производительности, можно забить на все эти оптимизации по уменьшению количеству проходов по циклам, условий и т.д… На первом месте должна стоять простота, читабельность и понятность кода, даже в ущерб производительности и меньшему объему кода (понятное дело что совсем маргиналить с трема влоежными циклами или еще чем-то — не надо). В 90% задачах разницы в скорости все-равно не будет видно а более короткий код далеко не всегда более читабельный код.
Мне кажется или в вашем коде возникнет проблема если массив будет пустым?
И правда, очень красивое решение, и лучше не сделаешь, как ни крути.
- находим в памяти указатель на удаляемый элемент
- перезаписываем этот указатель следующим
const int last = GRID_SIZE - 1;
for (int i = 0; i < last; i++) { // <-- Здесь цикл идёт до last-1, не включая last
grid[0][i] = 0; // Верхняя граница
grid[last][i] = 0; // Нижняя граница
grid[i][0] = 0; // Левая граница
grid[i][last] = 0; // Правая граница
}// Инициализация массива с явно заданными границами
var grid = new int[GRID_SIZE, GRID_SIZE];
// Используем индексаторы для целого диапазона
grid[0, ..] = 0; // Верхняя строка
grid[last, ..] = 0; // Нижняя строка
grid[.., 0] = 0; // Левый столбец
grid[.., last] = 0; // Правый столбец
Правила хорошего вкуса от Линуса Торвальдса. Делаем код быстрее, проще и понятнее