
Материал, перевод которого мы публикуем сегодня, посвящён рассказу о том, как в Airbnb оптимизируют серверные части веб-приложений с прицелом на всё более широкое использование технологий серверного рендеринга. В течение нескольких лет компания постепенно переводила весь свой фронтенд на единообразную архитектуру, в соответствии с которой веб-страницы представляют собой иерархические структуры React-компонентов, наполняемые данными из их API. В частности, в ходе этого процесса шёл планомерный отказ от Ruby on Rails. На самом деле, Airbnb планирует переход на новый сервис, основанный исключительно на Node.js, благодаря которому в браузеры пользователей будут попадать полностью готовые страницы, отрендеренные на сервере. Этот сервис будет формировать большую часть HTML-кода для всех продуктов Airbnb. Движок рендеринга, о котором идёт речь, отличается от большинства используемых компанией бэкенд-сервисов в силу того, что он не написан на Ruby или Java. Однако отличается он и от традиционных высоконагруженных Node.js-сервисов, вокруг которых построены ментальные модели и вспомогательные инструменты, используемые в Airbnb.

Размышляя о платформе Node.js, можно нарисовать в воображении то, как некое приложение, построенное с учётом возможностей этой платформы по асинхронной обработке данных, быстро и эффективно обслуживает сотни или тысячи параллельных подключений. Сервис вытаскивает отовсюду необходимые ему данные и немного их обрабатывает для того, чтобы они соответствовали нуждам огромного множества клиентов. У владельца такого приложения нет поводов жаловаться, он уверен в используемой им легковесной модели одновременной обработки данных (в этом материале мы, для передачи термина «concurrent» используем слово «одновременный», для термина «parallel» — «параллельный»). Она отлично решает поставленную перед ней задачу.
Серверный рендеринг (SSR, Server Side Rendering) меняет базовые идеи, ведущие к подобному видению вопроса. Так, серверный рендеринг требует больших вычислительных ресурсов. Код в среде Node.js выполняется в одном потоке, в результате, для решения вычислительных задач (в отличие от задач ввода/вывода) код можно выполнять одновременно, но не параллельно. Платформа Node.js способна обрабатывать большое количество параллельных операций ввода/вывода, однако, если речь идёт о вычислениях, ситуация меняется.
Так как при применении серверного рендеринга вычислительная часть задачи по обработке запроса увеличивается по сравнению с той её частью, которая относится к вводу/выводу, одновременно поступающие запросы будут воздействовать на скорость отклика сервера из-за того, что они соперничают за ресурсы процессора. Надо отметить, что и при применении асинхронного рендеринга соперничество за ресурсы всё ещё присутствует. Асинхронный рендеринг решает проблемы отзывчивости процесса или браузера, но не улучшает ситуацию с задержками или параллелизмом. В этом материале мы сосредоточимся на простой модели, включающей в себя исключительно вычислительные нагрузки. Если же говорить о смешанной нагрузке, включающей в себя и операции ввода/вывода и вычисления, то одновременно поступающие запросы увеличат задержки, но с учётом преимущества, заключающегося в более высокой пропускной способности системы.
Рассмотрим команду вида

Параллельное выполнение операций средствами подсистемы ввода/вывода
Если же
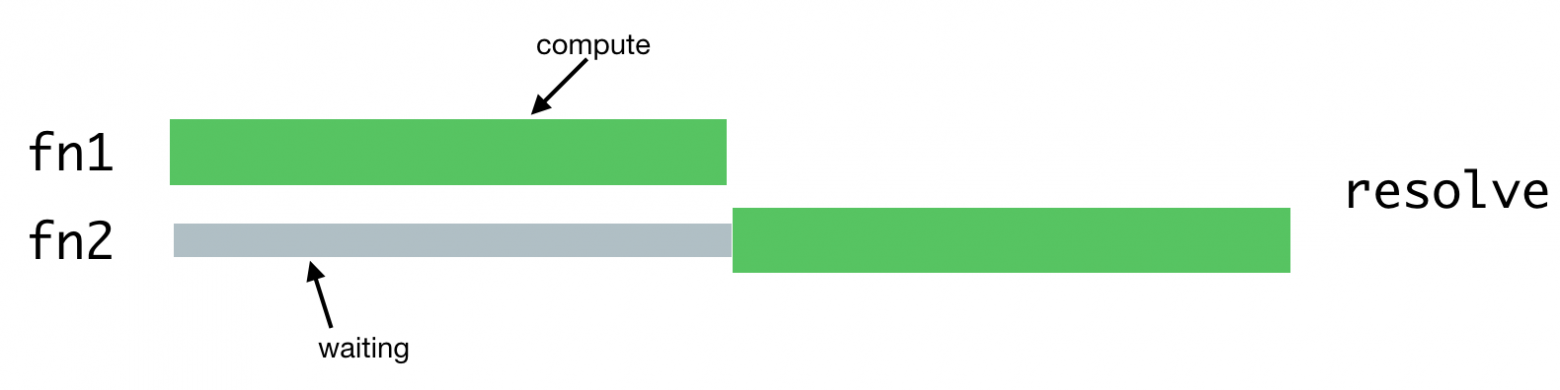
Выполнение вычислительных задач
Одной из операций придётся ждать завершения второй операции, так как в Node.js имеется лишь один поток.
В случае с серверным рендерингом эта проблема возникает в том случае, когда процессу сервера приходится обрабатывать несколько одновременно поступивших запросов. Обработка таких запросов будет задержана до тех пор, пока не будут обработаны запросы, поступившие ранее. Вот как это выглядит.
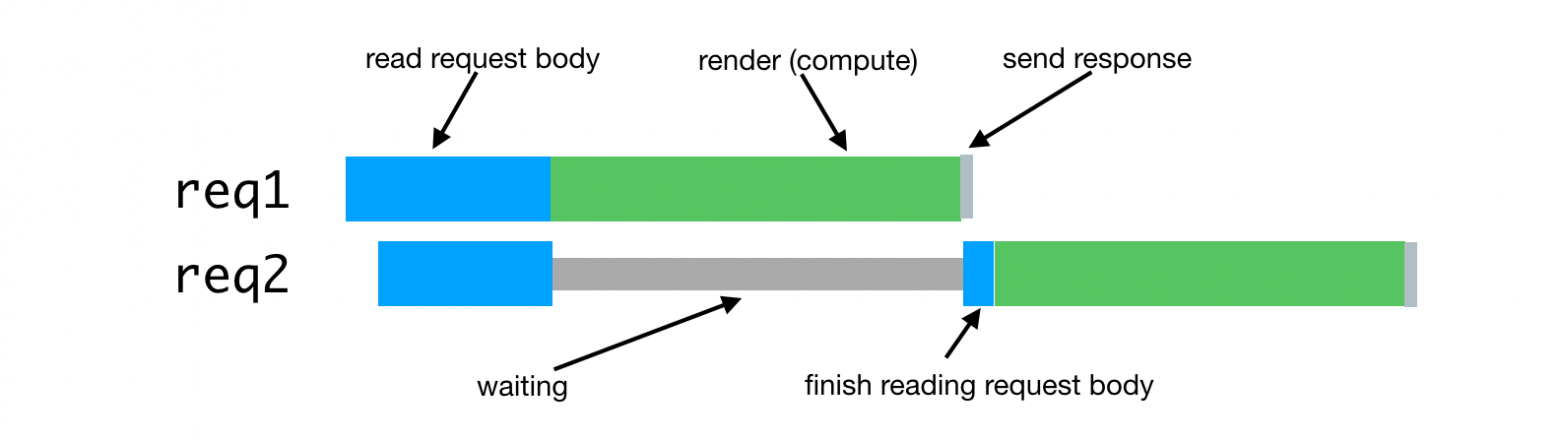
Обработка одновременно поступивших запросов
На практике обработка запроса часто состоит из множества асинхронных фаз, даже в том случае, если они подразумевают серьёзную вычислительную нагрузку на систему. Это может привести к ещё более тяжёлой ситуации с чередованием задач по обработке таких запросов.
Предположим, наши запросы состоят из цепочки задач, напоминающей вот такую:
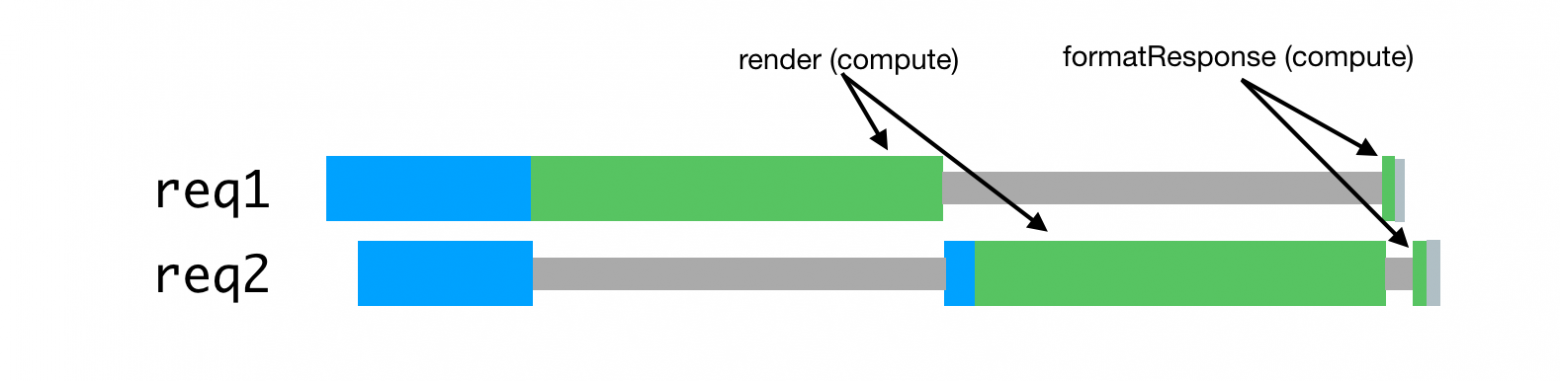
Обработка запросов, пришедших с незначительным интервалом, проблема борьбы за ресурсы процессора
В данном случае на обработку каждого запроса уходит примерно в два раза больше времени, чем на обработку отдельного запроса. При росте числа одновременно обрабатываемых запросов ситуация становится ещё хуже.
Кроме того, одной из типичных целей внедрения SSR является возможность использования одинакового или очень похожего кода и на клиенте, и на сервере. Серьёзное различие между этими окружениями заключается в том, что клиентское окружение, по существу, является окружением, в котором работает один клиент, а серверные окружения, по своему характеру, являются многоклиентскими средами. То, что хорошо работает на клиенте, вроде синглтонов или других подходов к хранению глобального состояния приложения, приводит к ошибкам, утечкам данных, и, в целом, к беспорядку, при одновременной обработке множества запросов, поступающих на сервер.
Эти особенности становятся проблемами в ситуации, когда нужно одновременно обрабатывать множество запросов. Всё обычно вполне нормально работает под более низкими нагрузками в уютном окружении среды разработки, которым пользуется один клиент в лице программиста.
Это приводит к ситуации, которая серьёзно отличается от классических примеров Node.js-приложений. Надо отметить, что мы используем среду выполнения JavaScript ради богатого набора доступных в ней библиотек, и из-за того, что она поддерживается браузерами, а не ради её модели одновременной обработки данных. В рассматриваемом приложении асинхронная модель одновременной обработки данных демонстрирует все свои недостатки, не компенсируемые преимуществами, которых либо очень мало, либо вовсе нет.
Наш новые сервис рендеринга, Hyperloop, станет основным сервисом, с котором будут взаимодействовать пользователи сайта Airbnb. В результате его надёжность и производительность играют важнейшую роль в обеспечении удобства работы с ресурсом. Внедряя Hyperloop в продакшн, мы учитываем тот опыт, который получили, работая с нашей более ранней системой серверного рендеринга — Hypernova.
Hypernova работает не так, как наш новый сервис. Это — чистая система рендеринга. Она вызывается из нашего монолитного Rail-сервиса, который называется Monorail, и возвращает только HTML-фрагменты для конкретных отрендеренных компонентов. Во многих случаях подобный «фрагмент» представляет собой львиную долю страницы, а Rails предоставляет лишь макет страницы. При использовании устаревших технологий части страницы можно связать вместе с использованием ERB. В любом случае, однако, Hypernova не занимается загрузкой каких-либо данных, необходимых для формирования страницы. Это — задача Rails.
Таким образом, Hyperloop и Hypernova имеют похожие рабочие характеристики, относящиеся к вычислениям. При этом Hypernova, как сервис, работающий в продакшне и обрабатывающий значительные объёмы трафика, предоставляет хорошее поле для испытаний, ведущих к пониманию того, как замена Hypernova будет вести себя в боевых условиях.
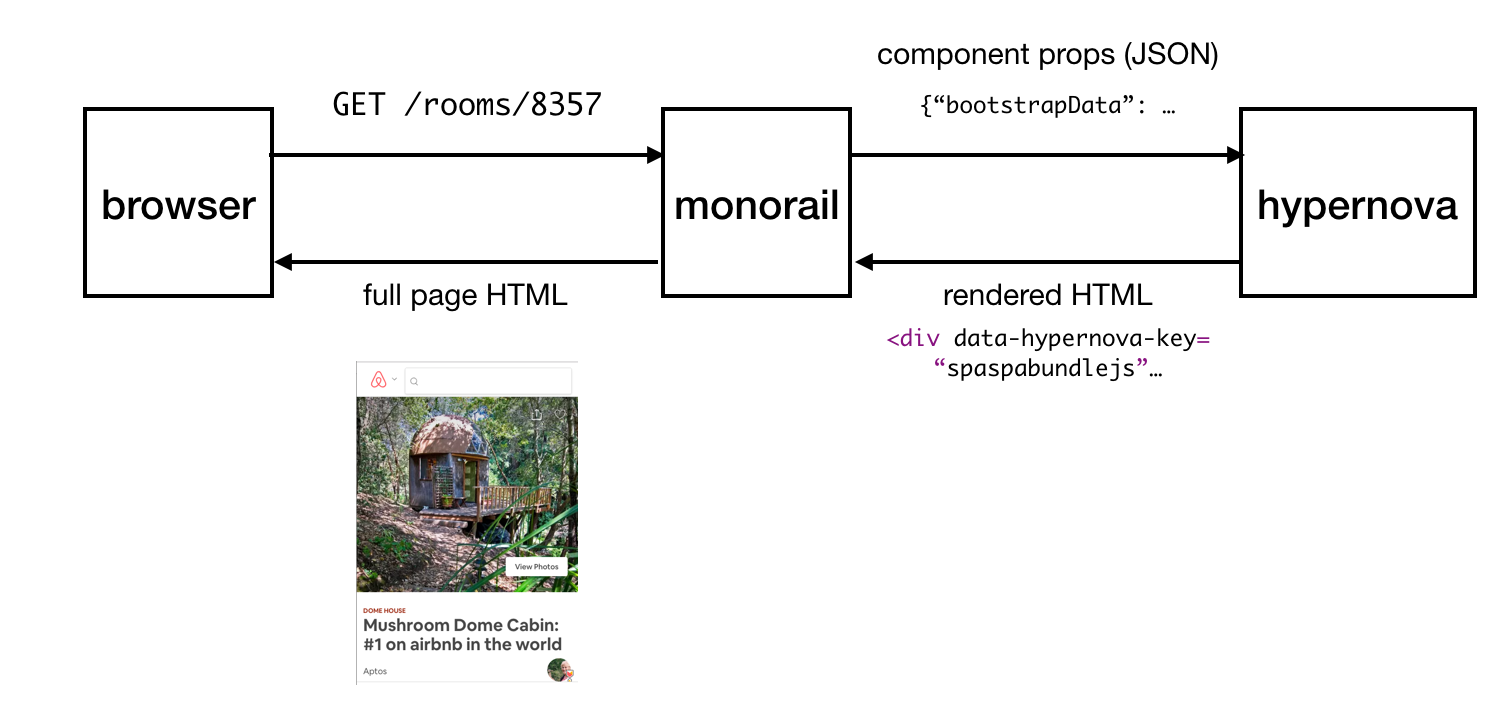
Схема работы Hypernova
Вот как работает Hypernova. Запросы пользователя приходят к нашему главному Rails-приложению, Monorail, которое собирает свойства React-компонентов, которые нужно вывести на некоей странице и делает запрос к Hypernova, передавая эти свойства и имена компонентов. Hypernova рендерит компоненты со свойствами для того, чтобы сгенерировать HTML-код, который нужно вернуть приложению Monorail, которое после этого внедрит этот код в шаблон страницы и отправит это всё обратно клиенту.

Отправка готовой страницы клиенту
В случае возникновения внештатной ситуации (это может быть ошибка или превышение времени ожидания ответа) в Hypernova, существует запасной вариант, при использовании которого компоненты и их свойства встраиваются в страницу без сгенерированного на сервере HTML, после чего всё это отправляется на клиент и рендерится уже там, как мы надеемся, успешно. Это привело нас к тому, что мы не считали сервис Hypernova критически важной частью системы. В результате мы могли допустить возникновение некоторого количества отказов и ситуаций, в которых срабатывает таймаут. Настраивая таймауты запросов, мы, основываясь на наблюдениях, установили их примерно на уровень P95. В результате неудивительно то, что система работала с базовым показателем срабатывания таймаутов менее 5%.
В ситуациях достижения трафиком пиковых значений, мы могли видеть, что до 40% запросов к Hypernova закрываются по таймаутам в Monorail. Со стороны Hypernova мы видели пики ошибок

Пиковые значения срабатывания таймаутов (красные линии)
Так как наша система могла работать и без Hypernova, на эти особенности мы не обращали особенного внимания, они воспринимались скорее как досадные мелочи, а не как серьёзные проблемы. Мы объясняли эти проблемы особенностями платформы, тем, что запуск приложения оказывается медленным из-за достаточно тяжёлой первоначальной операции по сборке мусора, из-за особенностей компиляции кода и кэширования данных и по другим причинам. Мы надеялись, что новые релизы React или Node будут включать в себя улучшения производительности, которые позволят смягчить недостатки медленного запуска сервиса.
Я подозревал, что происходящее, весьма вероятно, было результатом плохой балансировки нагрузки или последствием проблем в сфере развёртывания решения, когда увеличивающиеся задержки проявлялись из-за чрезмерной вычислительной нагрузки на процессы. Я добавил в систему вспомогательный слой для логирования сведений о числе запросов, обрабатываемых одновременно отдельными процессами, а также для фиксирования случаев, в которых процессу на обработку поступало более одного запроса.
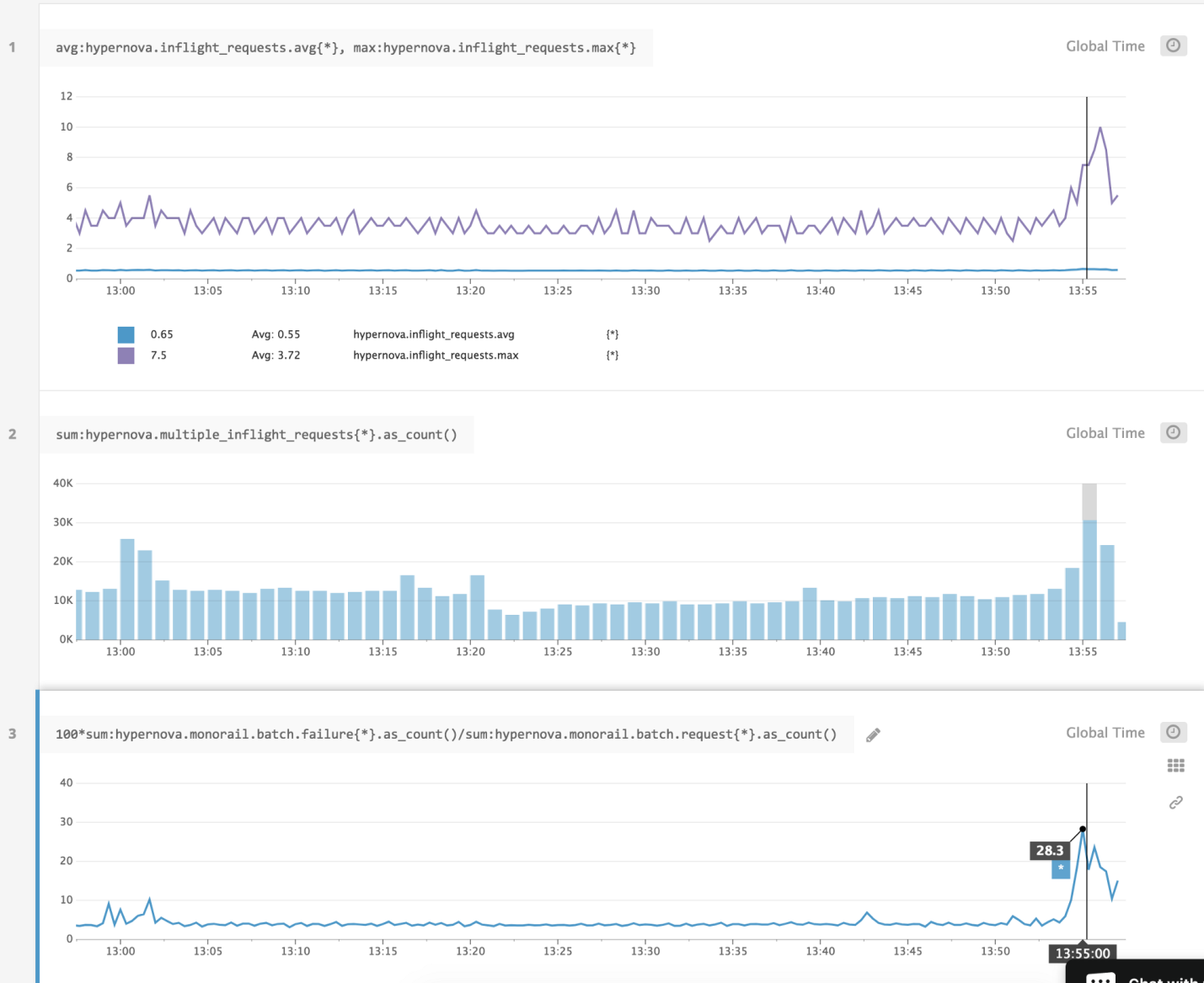
Результаты исследования
Мы считали виновником задержек медленный запуск сервиса, а на самом деле проблема была вызвана параллельными запросами, борющимися за процессорное время. По результатам измерений оказалось, что время, потраченное запросом в ожидании завершения обработки других запросов, соответствует времени, потраченному на обработку запроса. Кроме того, это означало, что увеличение задержек по причине одновременной обработки запросов выглядит так же, как увеличение задержек из-за увеличения вычислительной сложности кода, что ведёт к повышению нагрузки на систему при обработке каждого запроса.
Это, кроме того, сделало более очевидным то, что ошибку

Ошибка, вызываемая отключением клиента, не дождавшегося ответа
Мы решили справиться с этой проблемой, воспользовавшись парой стандартных инструментов, в работе с которыми у нас был немалый опыт. Речь идёт об обратном прокси-сервере (nginx) и о балансировщике нагрузки (HAProxy).
Для того чтобы воспользоваться преимуществами многоядерной процессорной архитектуры, мы запускаем несколько процессов Hypernova, применяя встроенный модуль Node.js cluster. Так как эти процессы являются независимыми, мы можем параллельно обрабатывать одновременно поступающие запросы.

Параллельная обработка запросов, поступающих одновременно
Проблема тут заключается в том, что каждый процесс Node оказывается полностью занят всё то время, которое длится обработка одного запроса, включая чтение тела запроса, переданного от клиента (его роль в данном случае играет Monorail). Хотя мы можем параллельно читать множество запросов в единственном процессе, это, когда дело доходит до рендеринга, ведёт к чередованию вычислительных операций.
Использование ресурсов процессов Node оказывается привязанным к скорости клиента и сети.
В качестве решения этой проблемы можно рассмотреть буферизующий обратный прокси-сервер, который позволит поддерживать сеансы связи с клиентами. Источником вдохновения для этой идеи стал веб-сервер unicorn, который мы используем для наших Rails-приложений. Принципы, декларируемые unicorn, отлично объясняют — почему это так. Для этой цели мы воспользовались nginx. Nginx считывает запрос, поступающий от клиента, в буфер, и передаёт запрос Node-серверу только после того, как он будет полностью прочитан. Этот сеанс передачи данных выполняет на локальной машине, через интерфейс loopback или с помощью сокетов домена Unix, а это — гораздо быстрее и надёжнее, чем передача данных между отдельными компьютерами.
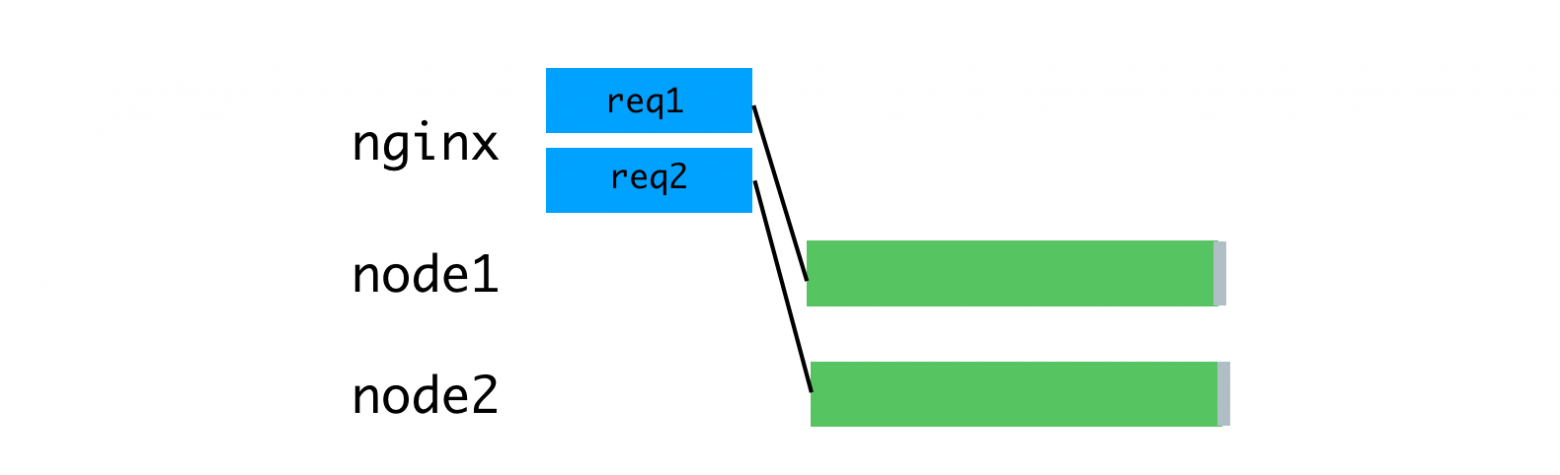
Nginx буферизует запросы, после чего отправляет их Node-серверу
Благодаря тому, что чтением запросов теперь занимается nginx, нам удалось достичь более равномерной загрузки Node-процессов.

Равномерная загрузка процессов благодаря использованию nginx
Кроме того, мы использовали nginx для обработки некоторых запросов, которые не требуют обращения к Node-процессам. Слой обнаружения и маршрутизации нашего сервиса использует не создающие большой нагрузки на системы запросы к
Следующее улучшение касается балансировки нагрузки. Нам нужно принимать продуманные решения о распределении запросов между Node-процессами. Модуль
Модуль
Алгоритм round-robin хорош, когда наблюдается низкая изменчивость задержек запросов. Например, в ситуации, проиллюстрированной ниже.

Алгоритм round-robin и соединения, по которым стабильно поступают запросы
Этот алгоритм уже не так хорош, когда приходится обрабатывать запросы разных типов, для обработки которых могут понадобиться совершенно различные затраты времени. Самый последний запрос, отправленный некоему процессу, вынужден ждать завершения обработки всех запросов, отправленных ранее, даже если существует другой процесс, имеющий возможность такой запрос обработать.

Неравномерная нагрузка на процессы
Если распределить запросы, показанные выше, более рационально, то получится примерно то, что показано на рисунке ниже.

Рациональное распределение запросов по потокам
При таком подходе минимизируется ожидание и появляется возможность быстрее отправлять ответы на запросы.
Достичь подобного можно, размещая запросы в очереди, и назначая их процессу только тогда, когда он не занят обработкой другого запроса. Для этой цели мы используем HAProxy.
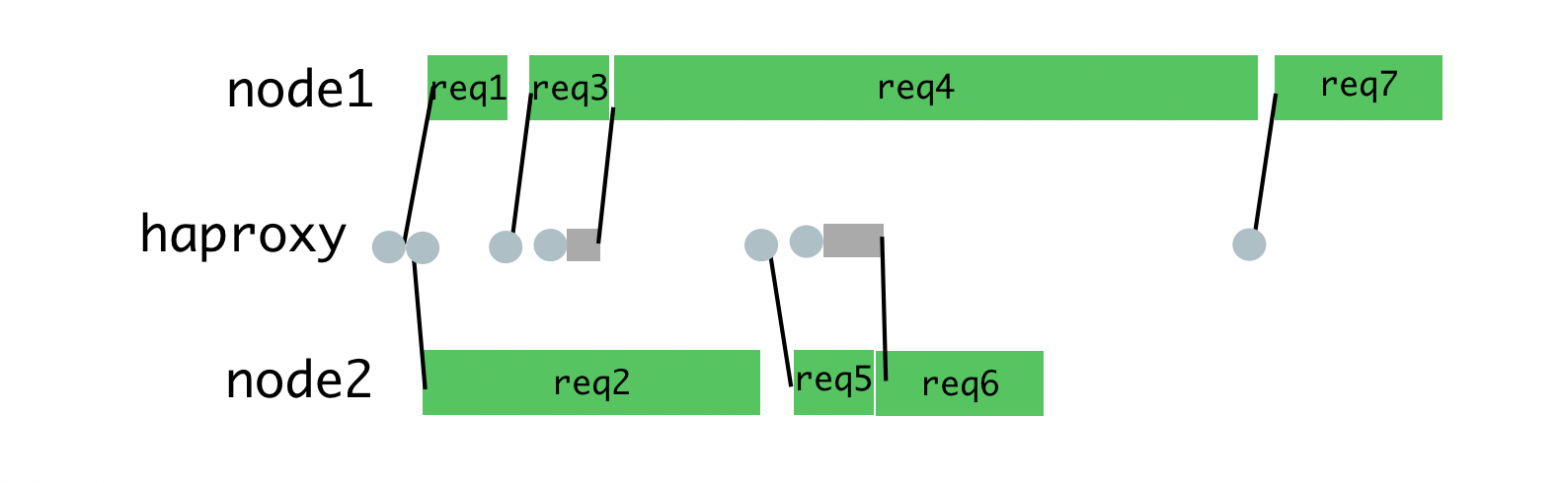
HAProxy и балансировка нагрузки на процессы
Когда мы использовали HAProxy для балансировки нагрузки на Hypernova, мы полностью исключили пики таймаутов, а также — ошибки
Одновременные запросы были также основной причиной задержек в ходе нормальной работы, данный подход снизил такие задержки. Одним из последствий этого стало то, что теперь по таймауту закрывались лишь 2% запросов, а не 5%, с теми же настройками таймаутов. То, что нам удалось перейти от ситуации с 40% ошибок к ситуации со срабатыванием таймаута в 2% случаев, показало, что мы двигаемся в верном направлении. В результате сегодня наши пользователи видят загрузочный экран веб-сайта гораздо реже. При этом надо отметить, что стабильность системы будет иметь для нас особую важность с ожидаемым переходом на новую систему, не имеющую такого же резервного механизма, какой есть у Hypernova.
Для того чтобы всё это заработало, нужно настроить nginx, HAProxy и Node-приложение. Вот пример похожего приложения, использующего nginx и HAProxy, проанализировав который, можно понять устройство рассматриваемой системы. Этот пример основан на той системе, которую мы используем в продакшне, но он упрощён и изменён так, чтобы можно было выполнять его на переднем плане от имени непривилегированного пользователя. В продакшне всё следует конфигурировать с помощью некоего супервизора (мы используем runit, или, всё чаще, kubernetes).
Конфигурация nginx довольно стандартна, тут используется сервер, прослушивающий порт 9000, настроенный на проксирование запросов к серверу HAProxy, который прослушивает порт 9001 (в нашей конфигурации мы используем сокеты домена Unix).
Кроме того, этот сервер перехватывает запросы к конечной точке
Модуль Node.js
В настройках HAProxy указано, что прокси слушает порт 9001 и занимается перенаправлением трафика четырём рабочим процессам, слушающим порты с 9002 по 9005. Самый важный параметр здесь —

Стартовая страница HAProxy
HAProxy отслеживает текущее количество открытых соединений между ним и каждым из рабочих процессов. У него есть лимит, заданный через свойство
Возможно, рассматриваемая здесь конфигурация очень близка к тому, что вам хотелось бы получить от подобной системы. Тут есть и другие интересные параметры (как и стандартные настройки). В процессе подготовки этой конфигурации мы провели множество тестов, как в нормальных, так и в аномальных условиях, и воспользовались значениями, полученным на основе этих испытаний. Надо сказать, что это может завести нас в дебри конфигурирования серверов и не является абсолютно необходимым для понимания описываемой тут системы, но мы поговорим об этом в следующем разделе.
Многое в нашей системе зависит от правильной работы HAProxy. Система не принесла бы нам особой пользы, если бы она не обрабатывала одновременно поступающие запросы так, как мы того ожидали, если бы неправильно их распределяла между рабочими процессами или не так ставила бы в очередь. Кроме того, нам было важно понять, как здесь обрабатываются (или не обрабатываются) сбои различных типов. Нам нужна была уверенность в том, что новая система является подходящей заменой для существующей, основанной на модуле
В ходе испытаний мы пользовались утилитой
В нашей конфигурации использовалось 15 рабочих потоков вместо 4-х из приложения-примера, и мы запускали
Первый набор тестов представлял собой имитацию обычной работы системы, в общем-то, ничего особо интересного тут не происходило. Следующий набор тестов был проведён после аккуратного перезапуска всех процессов, как происходило бы при развёртывании системы. При выполнении последнего набора этих тестов я, случайным образом, останавливал некоторые процессы, имитируя ситуацию возникновения неперехваченных исключений, которые приводили бы к остановке этих процессов. Кроме того, у нас возникали некоторые проблемы, связанные с бесконечными циклами в коде приложения, мы исследовали и эти проблемы.
Тесты помогли сформировать конфигурацию, а также — лучше понять особенности работы нашей системы.
При обычном функционировании параметр
Мы не использовали мониторинг работоспособности HTTP или TCP на бэкендах, так как мы обнаружили, что от этого больше проблем, чем пользы. Возникало такое ощущение, что мониторинг не учитывает параметр
Мы обнаружили, что проверки работоспособности не отличаются достаточной управляемостью для того, чтобы, в нашем случае, ими пользоваться, и решили избежать возникновения непредсказуемых ситуаций, связанных с использованием перекрывающихся режимов проверки работоспособности.
Вот ошибки подключения — это то, с чем мы могли работать. Мы применили параметр
Это относится лишь к соединениям, отклонённым из-за того, что соответствующий сервис не прослушивал свой порт. Таймаут соединения в данной ситуации не особенно полезен, так как мы работаем в локальной сети. Мы изначально ожидали, что сможем установить небольшой таймаут соединения для защиты от процессов, которые попали в бесконечный цикл. Мы установили таймаут в 100 мс и были удивлены, когда наши запросы завершались по таймауту через 10 секунд, что определялось другими параметрами, установленными в то время. При этом управление в цикл событий не возвращалось, что не позволяло принимать новые соединения. Это объясняется тем, что ядро считает соединение установленным с точки зрения клиента до вызова
Интересным побочным эффектом этого является то, что даже задание лимита очереди входящих соединений (backlog) не приводит к тому, что соединения перестают устанавливаться. Длина очереди определяется после ответа сервера SYN-ACK (реализовано это, на самом деле, так, что сервер не обращает внимания на ответ ACK от клиента). Последствием подобного поведения системы является то, что запрос с уже установленным соединением, не может быть повторно диспетчеризован, так как у нас нет способа узнать, обработал бэкенд этот запрос или нет.
Ещё один интересный результат наших тестов, касающийся исследования процессов, попавших в бесконечный цикл, заключался в том, что таймауты приводят к неожиданному поведению системы. Когда процессу отправляют запрос, приводящий к попаданию его в бесконечный цикл, счётчик соединений бэкенда устанавливается в 1. Благодаря параметру
Кроме того, мы обнаружили довольно неприглядную ситуацию, возникающую при высокой нагрузке. Если рабочий процесс завершается с ошибкой (подобное должно происходить крайне редко) в то время, когда у сервера постоянно имеется очередь запросов, будут делаться попытки отправки запросов к остановившемуся бэкенду, но соединение установить не удастся, так как на этом бэкенде нет процесса, ожидающего подключений. Затем HAProxy произведёт перенаправление запроса на следующий бэкенд с открытым слотом соединения, которым будет тот же самый бэкенд, к которому только что не удалось обратиться (так как все остальные бэкенды заняты обработкой запросов). В ходе подобных обращений к неработающему серверу очень быстро будет достигнут предел лимита повторных запросов, что приведёт к отказу запроса, так как сообщения об ошибках соединения выдаются гораздо быстрее, чем выполняется рендеринг HTML. Процесс при этом продолжит пытаться отдать неработающему бэкенду другие запросы, имеющиеся в очереди, и происходить это будет до опустошения очереди. Это плохо, но это смягчается редкостью аварийного завершения процессов, редкостью наличия постоянно заполненной очереди запросов (если запросы постоянно попадают в очередь, это означает, что в системе недостаточно серверов). В нашем конкретном случае неправильно работающий сервис привлечёт внимание системы мониторинга работоспособности, которая быстро выяснит, что он непригоден для обработки новых запросов и соответствующим образом это отметит. Хорошего тут мало, но это, по крайней мере, минимизирует риск. В будущем с подобным можно бороться через более глубокую интеграцию HAProxy, где процесс супервизора наблюдает за завершением процессов и назначает им статус MAINT через сокет статистики HAProxy.
Ещё одно изменение, на которое стоит обратить внимание, заключается в том, что
Кроме того, мы обнаружили, что установка параметра
И, наконец, тут может пригодиться настройка параметра Node
Достичь этого можно, реализуя раздельную очередь для каждого процесса, как это сделано, например, здесь.
Использование серверного рендеринга на Node.js означает повышенную вычислительную нагрузку на систему. Такая нагрузка отличается от традиционной, связанной, преимущественно, с обработкой операций ввода-вывода. Именно в таких ситуациях платформа Node.js показывает себя наилучшим образом. В нашем случае, мы, попытавшись добиться высокой производительности серверной части приложения, столкнулись с рядом проблем, которые удалось решить, поработав над архитектурой системы и воспользовавшись вспомогательными механизмами, такими, как nginx и HAProxy.
Надеемся, опыт компании Airbnb пригодится всем, кто использует Node.js для решения задач серверного рендеринга.
Уважаемые читатели! Используете ли вы серверный рендеринг в своих проектах?


Платформа Node.js
Размышляя о платформе Node.js, можно нарисовать в воображении то, как некое приложение, построенное с учётом возможностей этой платформы по асинхронной обработке данных, быстро и эффективно обслуживает сотни или тысячи параллельных подключений. Сервис вытаскивает отовсюду необходимые ему данные и немного их обрабатывает для того, чтобы они соответствовали нуждам огромного множества клиентов. У владельца такого приложения нет поводов жаловаться, он уверен в используемой им легковесной модели одновременной обработки данных (в этом материале мы, для передачи термина «concurrent» используем слово «одновременный», для термина «parallel» — «параллельный»). Она отлично решает поставленную перед ней задачу.
Серверный рендеринг (SSR, Server Side Rendering) меняет базовые идеи, ведущие к подобному видению вопроса. Так, серверный рендеринг требует больших вычислительных ресурсов. Код в среде Node.js выполняется в одном потоке, в результате, для решения вычислительных задач (в отличие от задач ввода/вывода) код можно выполнять одновременно, но не параллельно. Платформа Node.js способна обрабатывать большое количество параллельных операций ввода/вывода, однако, если речь идёт о вычислениях, ситуация меняется.
Так как при применении серверного рендеринга вычислительная часть задачи по обработке запроса увеличивается по сравнению с той её частью, которая относится к вводу/выводу, одновременно поступающие запросы будут воздействовать на скорость отклика сервера из-за того, что они соперничают за ресурсы процессора. Надо отметить, что и при применении асинхронного рендеринга соперничество за ресурсы всё ещё присутствует. Асинхронный рендеринг решает проблемы отзывчивости процесса или браузера, но не улучшает ситуацию с задержками или параллелизмом. В этом материале мы сосредоточимся на простой модели, включающей в себя исключительно вычислительные нагрузки. Если же говорить о смешанной нагрузке, включающей в себя и операции ввода/вывода и вычисления, то одновременно поступающие запросы увеличат задержки, но с учётом преимущества, заключающегося в более высокой пропускной способности системы.
Рассмотрим команду вида
Promise.all([fn1, fn2]). Если fn1 или fn2 — это промисы, разрешаемые средствами подсистемы ввода/вывода, то в ходе выполнения этой команды можно достичь параллельного выполнения операций. Выглядит это так:
Параллельное выполнение операций средствами подсистемы ввода/вывода
Если же
fn1 и fn2 представляют собой вычислительные задачи, выполняться они будут так:
Выполнение вычислительных задач
Одной из операций придётся ждать завершения второй операции, так как в Node.js имеется лишь один поток.
В случае с серверным рендерингом эта проблема возникает в том случае, когда процессу сервера приходится обрабатывать несколько одновременно поступивших запросов. Обработка таких запросов будет задержана до тех пор, пока не будут обработаны запросы, поступившие ранее. Вот как это выглядит.
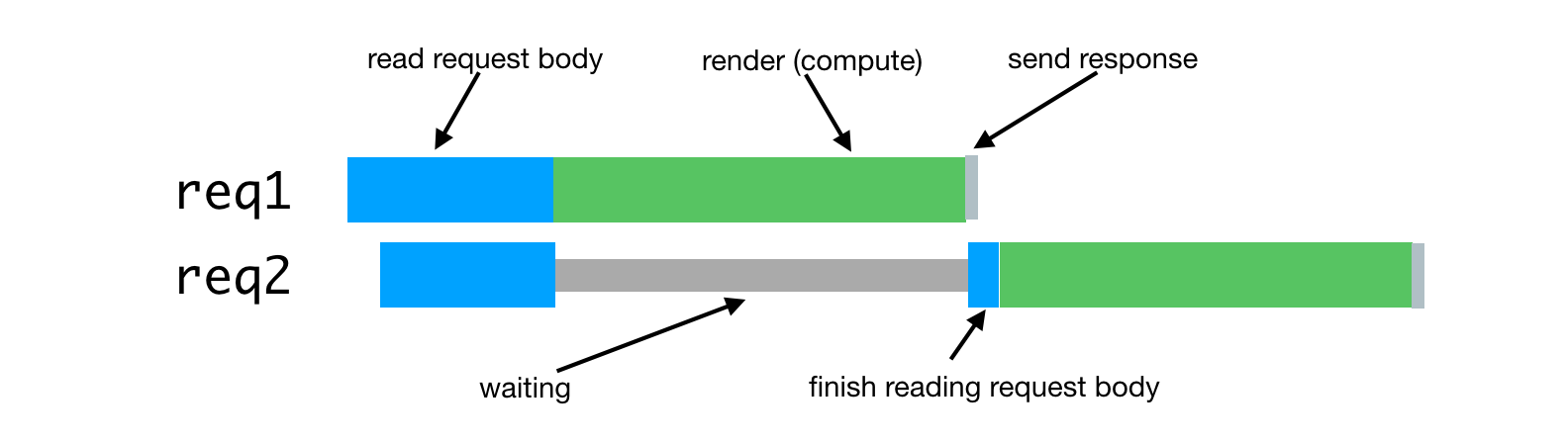
Обработка одновременно поступивших запросов
На практике обработка запроса часто состоит из множества асинхронных фаз, даже в том случае, если они подразумевают серьёзную вычислительную нагрузку на систему. Это может привести к ещё более тяжёлой ситуации с чередованием задач по обработке таких запросов.
Предположим, наши запросы состоят из цепочки задач, напоминающей вот такую:
renderPromise().then(out => formatResponsePromise(out)).then(body => res.send(body)). При поступлении в систему пары таких запросов, с незначительным интервалом между ними, мы можем наблюдать следующую картину.
Обработка запросов, пришедших с незначительным интервалом, проблема борьбы за ресурсы процессора
В данном случае на обработку каждого запроса уходит примерно в два раза больше времени, чем на обработку отдельного запроса. При росте числа одновременно обрабатываемых запросов ситуация становится ещё хуже.
Кроме того, одной из типичных целей внедрения SSR является возможность использования одинакового или очень похожего кода и на клиенте, и на сервере. Серьёзное различие между этими окружениями заключается в том, что клиентское окружение, по существу, является окружением, в котором работает один клиент, а серверные окружения, по своему характеру, являются многоклиентскими средами. То, что хорошо работает на клиенте, вроде синглтонов или других подходов к хранению глобального состояния приложения, приводит к ошибкам, утечкам данных, и, в целом, к беспорядку, при одновременной обработке множества запросов, поступающих на сервер.
Эти особенности становятся проблемами в ситуации, когда нужно одновременно обрабатывать множество запросов. Всё обычно вполне нормально работает под более низкими нагрузками в уютном окружении среды разработки, которым пользуется один клиент в лице программиста.
Это приводит к ситуации, которая серьёзно отличается от классических примеров Node.js-приложений. Надо отметить, что мы используем среду выполнения JavaScript ради богатого набора доступных в ней библиотек, и из-за того, что она поддерживается браузерами, а не ради её модели одновременной обработки данных. В рассматриваемом приложении асинхронная модель одновременной обработки данных демонстрирует все свои недостатки, не компенсируемые преимуществами, которых либо очень мало, либо вовсе нет.
Уроки проекта Hypernova
Наш новые сервис рендеринга, Hyperloop, станет основным сервисом, с котором будут взаимодействовать пользователи сайта Airbnb. В результате его надёжность и производительность играют важнейшую роль в обеспечении удобства работы с ресурсом. Внедряя Hyperloop в продакшн, мы учитываем тот опыт, который получили, работая с нашей более ранней системой серверного рендеринга — Hypernova.
Hypernova работает не так, как наш новый сервис. Это — чистая система рендеринга. Она вызывается из нашего монолитного Rail-сервиса, который называется Monorail, и возвращает только HTML-фрагменты для конкретных отрендеренных компонентов. Во многих случаях подобный «фрагмент» представляет собой львиную долю страницы, а Rails предоставляет лишь макет страницы. При использовании устаревших технологий части страницы можно связать вместе с использованием ERB. В любом случае, однако, Hypernova не занимается загрузкой каких-либо данных, необходимых для формирования страницы. Это — задача Rails.
Таким образом, Hyperloop и Hypernova имеют похожие рабочие характеристики, относящиеся к вычислениям. При этом Hypernova, как сервис, работающий в продакшне и обрабатывающий значительные объёмы трафика, предоставляет хорошее поле для испытаний, ведущих к пониманию того, как замена Hypernova будет вести себя в боевых условиях.
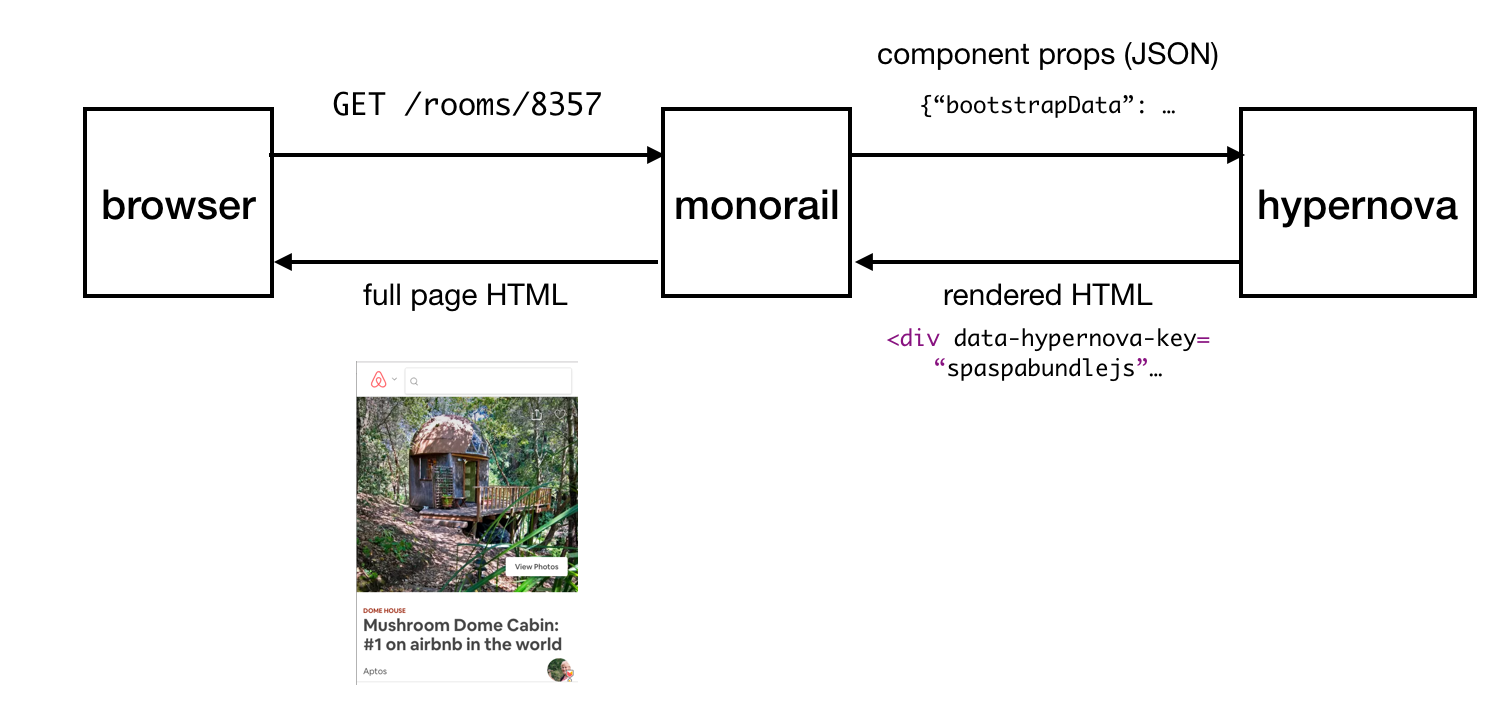
Схема работы Hypernova
Вот как работает Hypernova. Запросы пользователя приходят к нашему главному Rails-приложению, Monorail, которое собирает свойства React-компонентов, которые нужно вывести на некоей странице и делает запрос к Hypernova, передавая эти свойства и имена компонентов. Hypernova рендерит компоненты со свойствами для того, чтобы сгенерировать HTML-код, который нужно вернуть приложению Monorail, которое после этого внедрит этот код в шаблон страницы и отправит это всё обратно клиенту.
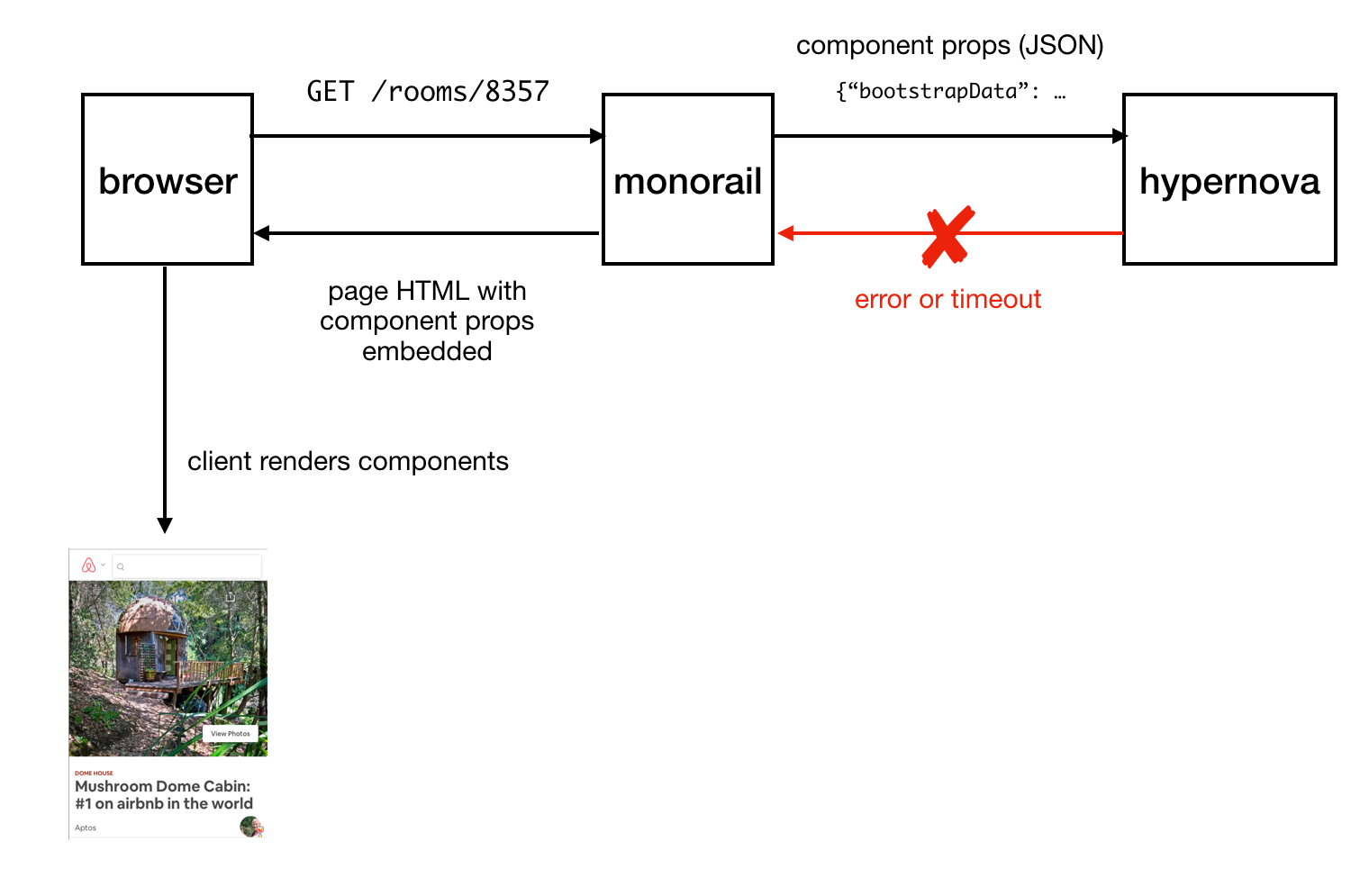
Отправка готовой страницы клиенту
В случае возникновения внештатной ситуации (это может быть ошибка или превышение времени ожидания ответа) в Hypernova, существует запасной вариант, при использовании которого компоненты и их свойства встраиваются в страницу без сгенерированного на сервере HTML, после чего всё это отправляется на клиент и рендерится уже там, как мы надеемся, успешно. Это привело нас к тому, что мы не считали сервис Hypernova критически важной частью системы. В результате мы могли допустить возникновение некоторого количества отказов и ситуаций, в которых срабатывает таймаут. Настраивая таймауты запросов, мы, основываясь на наблюдениях, установили их примерно на уровень P95. В результате неудивительно то, что система работала с базовым показателем срабатывания таймаутов менее 5%.
В ситуациях достижения трафиком пиковых значений, мы могли видеть, что до 40% запросов к Hypernova закрываются по таймаутам в Monorail. Со стороны Hypernova мы видели пики ошибок
BadRequestError: Request aborted меньшей высоты. Эти ошибки, кроме того, существовали и в обычных условиях, при этом в штатном режиме работы, за счёт архитектуры решения, остальные ошибки были не особенно заметны.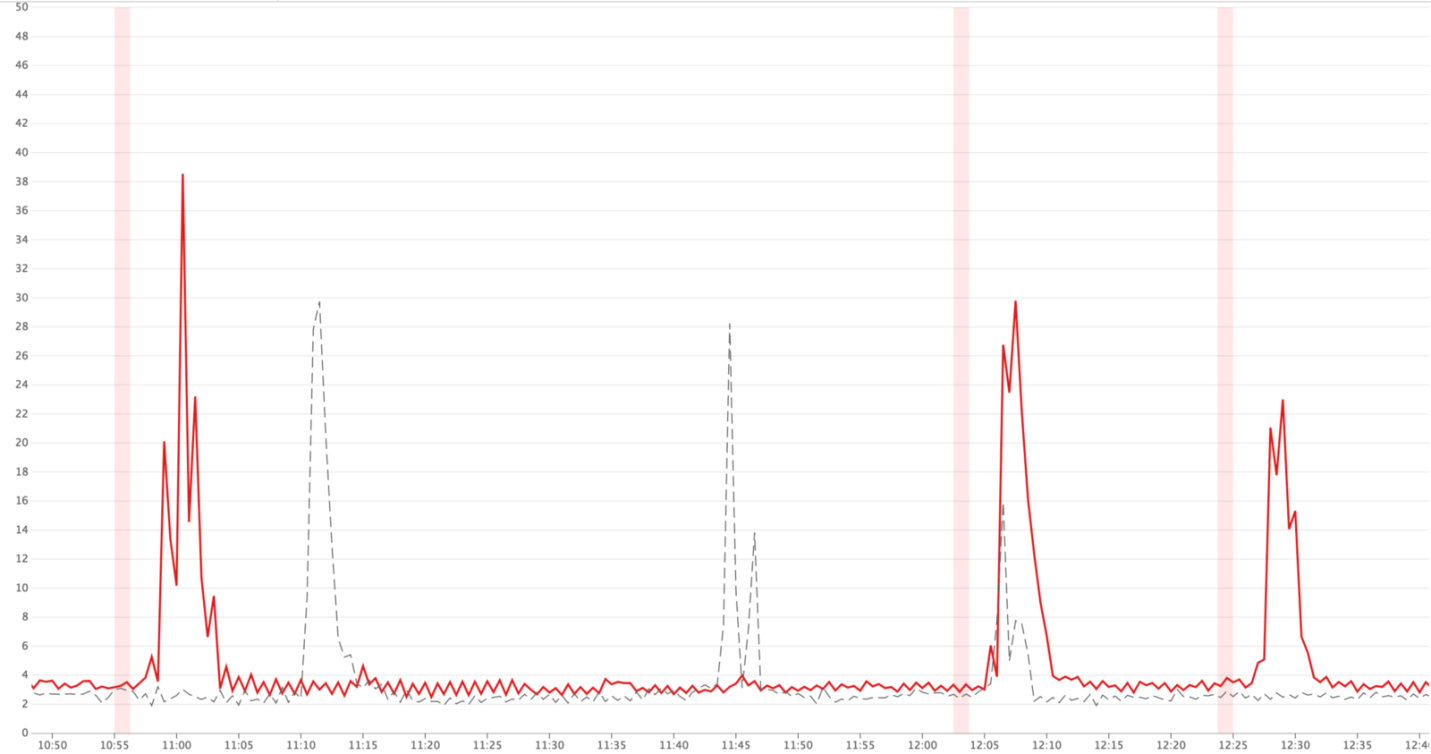
Пиковые значения срабатывания таймаутов (красные линии)
Так как наша система могла работать и без Hypernova, на эти особенности мы не обращали особенного внимания, они воспринимались скорее как досадные мелочи, а не как серьёзные проблемы. Мы объясняли эти проблемы особенностями платформы, тем, что запуск приложения оказывается медленным из-за достаточно тяжёлой первоначальной операции по сборке мусора, из-за особенностей компиляции кода и кэширования данных и по другим причинам. Мы надеялись, что новые релизы React или Node будут включать в себя улучшения производительности, которые позволят смягчить недостатки медленного запуска сервиса.
Я подозревал, что происходящее, весьма вероятно, было результатом плохой балансировки нагрузки или последствием проблем в сфере развёртывания решения, когда увеличивающиеся задержки проявлялись из-за чрезмерной вычислительной нагрузки на процессы. Я добавил в систему вспомогательный слой для логирования сведений о числе запросов, обрабатываемых одновременно отдельными процессами, а также для фиксирования случаев, в которых процессу на обработку поступало более одного запроса.

Результаты исследования
Мы считали виновником задержек медленный запуск сервиса, а на самом деле проблема была вызвана параллельными запросами, борющимися за процессорное время. По результатам измерений оказалось, что время, потраченное запросом в ожидании завершения обработки других запросов, соответствует времени, потраченному на обработку запроса. Кроме того, это означало, что увеличение задержек по причине одновременной обработки запросов выглядит так же, как увеличение задержек из-за увеличения вычислительной сложности кода, что ведёт к повышению нагрузки на систему при обработке каждого запроса.
Это, кроме того, сделало более очевидным то, что ошибку
BadRequestError: Request aborted нельзя было уверенно объяснить медленным запуском системы. Ошибка исходила из кода разбора тела запроса, и происходила тогда, когда клиент отменял запрос до того, как сервер был способен полностью прочесть тело запроса. Клиент прекращал работу, закрывал соединение, лишая нас тех данных, которые нужны для того, чтобы продолжить обработку запроса. Гораздо вероятнее то, что это происходило из-за того, что мы начинали обработку запроса, после этого цикл событий оказывался заблокированным рендерингом для другого запроса, а затем мы возвращались к прерванной задаче для того, чтобы её завершить, но в результате оказывалось, что клиент, отправивший нам этот запрос, уже отключился, прервав запрос. Кроме того, данные, передаваемые в запросах к Hypernova были достаточно объёмными, в среднем, в районе нескольких сотен килобайт, а это, определённо, не способствовало улучшению ситуации.
Ошибка, вызываемая отключением клиента, не дождавшегося ответа
Мы решили справиться с этой проблемой, воспользовавшись парой стандартных инструментов, в работе с которыми у нас был немалый опыт. Речь идёт об обратном прокси-сервере (nginx) и о балансировщике нагрузки (HAProxy).
Обратное проксирование и балансировка нагрузки
Для того чтобы воспользоваться преимуществами многоядерной процессорной архитектуры, мы запускаем несколько процессов Hypernova, применяя встроенный модуль Node.js cluster. Так как эти процессы являются независимыми, мы можем параллельно обрабатывать одновременно поступающие запросы.

Параллельная обработка запросов, поступающих одновременно
Проблема тут заключается в том, что каждый процесс Node оказывается полностью занят всё то время, которое длится обработка одного запроса, включая чтение тела запроса, переданного от клиента (его роль в данном случае играет Monorail). Хотя мы можем параллельно читать множество запросов в единственном процессе, это, когда дело доходит до рендеринга, ведёт к чередованию вычислительных операций.
Использование ресурсов процессов Node оказывается привязанным к скорости клиента и сети.
В качестве решения этой проблемы можно рассмотреть буферизующий обратный прокси-сервер, который позволит поддерживать сеансы связи с клиентами. Источником вдохновения для этой идеи стал веб-сервер unicorn, который мы используем для наших Rails-приложений. Принципы, декларируемые unicorn, отлично объясняют — почему это так. Для этой цели мы воспользовались nginx. Nginx считывает запрос, поступающий от клиента, в буфер, и передаёт запрос Node-серверу только после того, как он будет полностью прочитан. Этот сеанс передачи данных выполняет на локальной машине, через интерфейс loopback или с помощью сокетов домена Unix, а это — гораздо быстрее и надёжнее, чем передача данных между отдельными компьютерами.
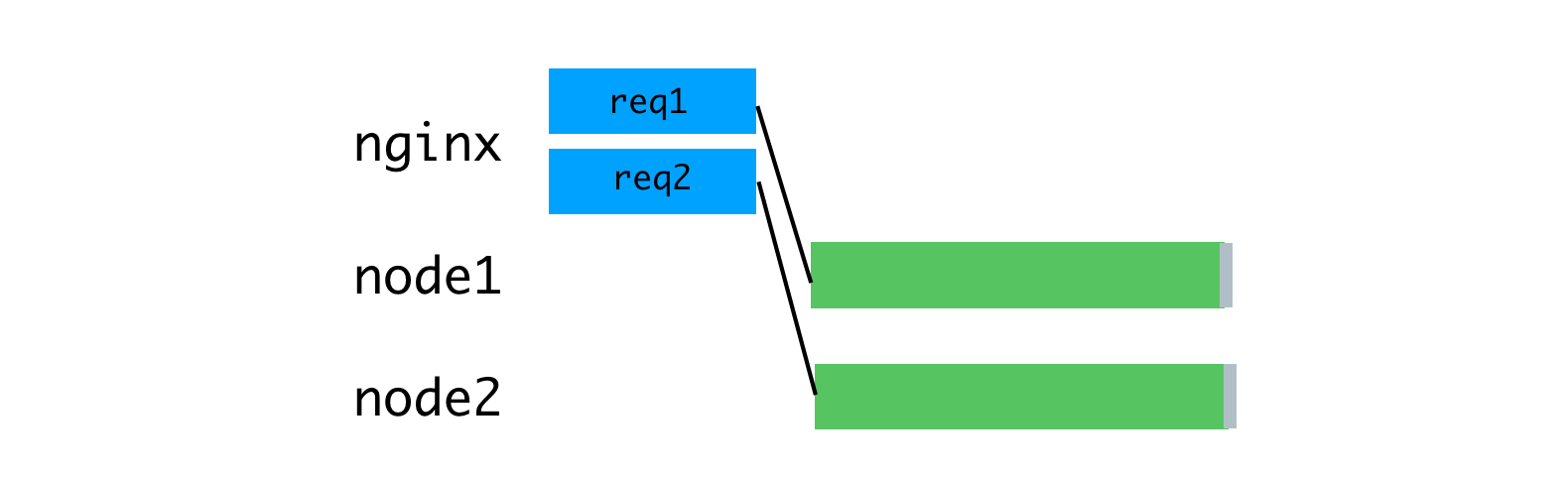
Nginx буферизует запросы, после чего отправляет их Node-серверу
Благодаря тому, что чтением запросов теперь занимается nginx, нам удалось достичь более равномерной загрузки Node-процессов.
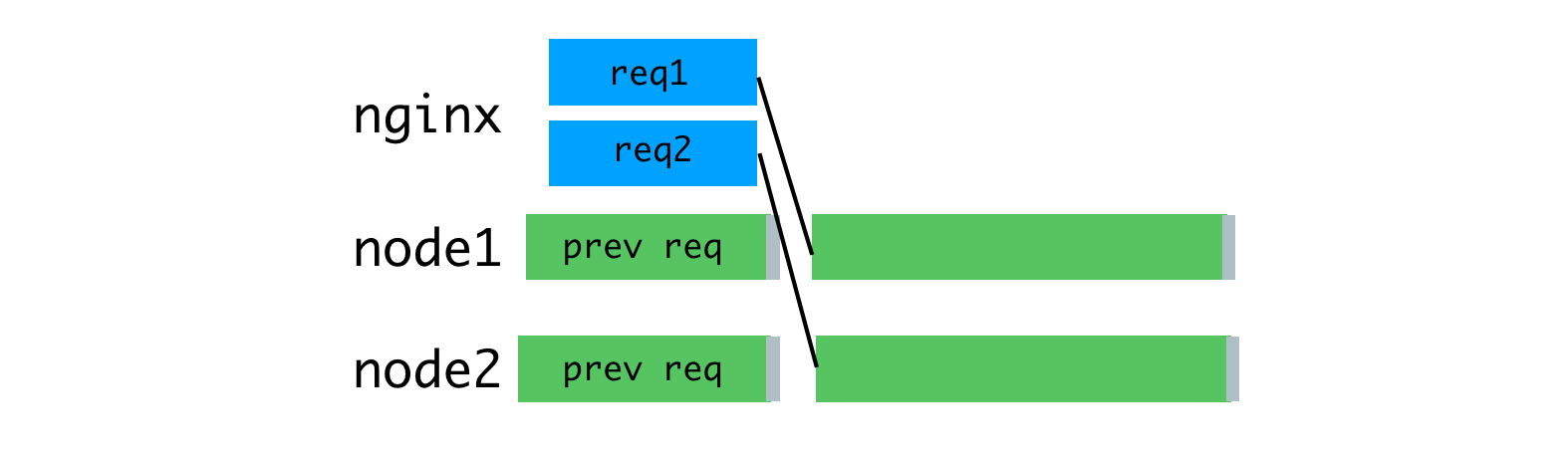
Равномерная загрузка процессов благодаря использованию nginx
Кроме того, мы использовали nginx для обработки некоторых запросов, которые не требуют обращения к Node-процессам. Слой обнаружения и маршрутизации нашего сервиса использует не создающие большой нагрузки на системы запросы к
/ping для проверки связи между хостами. Обработка всего этого в nginx устраняет значительный источник дополнительной (хотя и небольшой) нагрузки на процессы Node.js.Следующее улучшение касается балансировки нагрузки. Нам нужно принимать продуманные решения о распределении запросов между Node-процессами. Модуль
cluster распределяет запросы в соответствии с алгоритмом round-robin, в большинстве случаев — с попытками обойти процессы, которые не отвечают на запросы. При таком подходе каждый процесс получает запрос в порядке очереди.Модуль
cluster распределяет соединения, а не запросы, поэтому всё это работает не так, как нам нужно. Ситуация становится ещё хуже, когда используются постоянные соединения. Любое постоянное соединение от клиента привязано к единственному конкретному рабочему процессу, что усложняет эффективное распределение задач.Алгоритм round-robin хорош, когда наблюдается низкая изменчивость задержек запросов. Например, в ситуации, проиллюстрированной ниже.
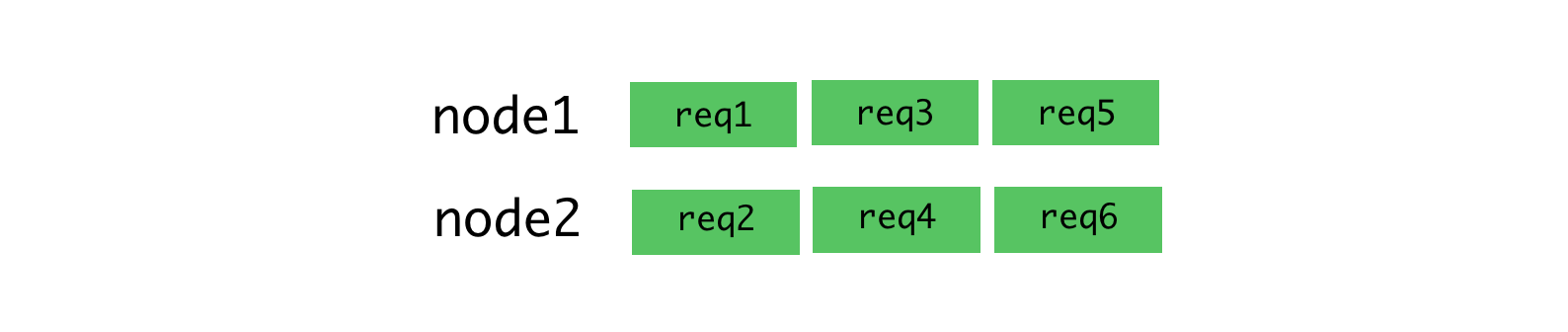
Алгоритм round-robin и соединения, по которым стабильно поступают запросы
Этот алгоритм уже не так хорош, когда приходится обрабатывать запросы разных типов, для обработки которых могут понадобиться совершенно различные затраты времени. Самый последний запрос, отправленный некоему процессу, вынужден ждать завершения обработки всех запросов, отправленных ранее, даже если существует другой процесс, имеющий возможность такой запрос обработать.
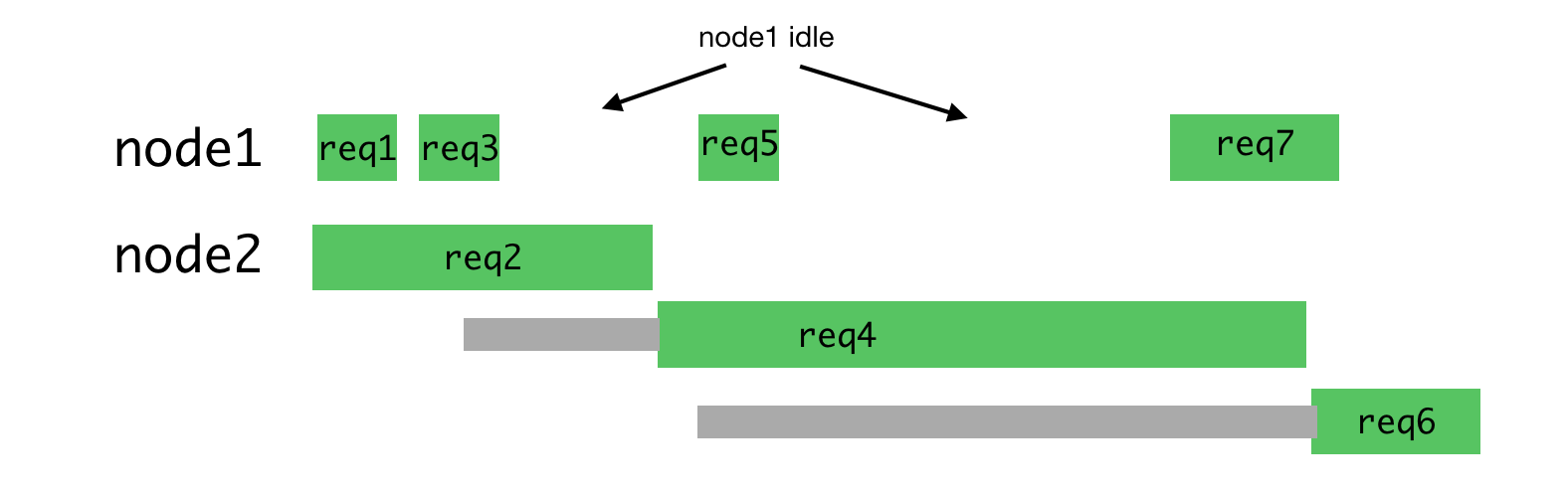
Неравномерная нагрузка на процессы
Если распределить запросы, показанные выше, более рационально, то получится примерно то, что показано на рисунке ниже.
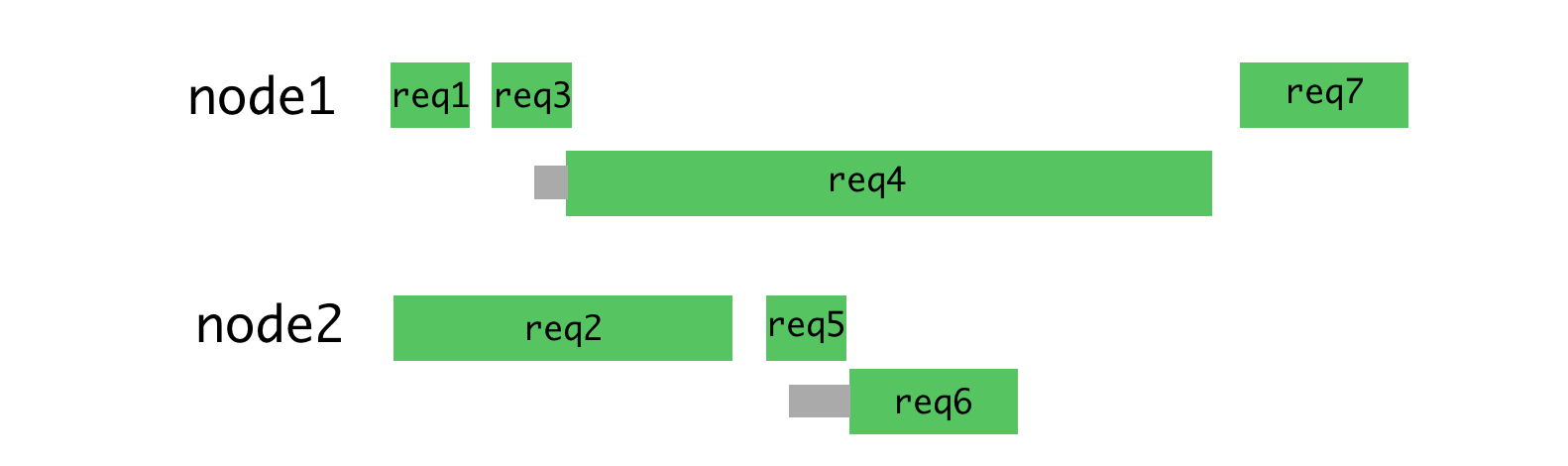
Рациональное распределение запросов по потокам
При таком подходе минимизируется ожидание и появляется возможность быстрее отправлять ответы на запросы.
Достичь подобного можно, размещая запросы в очереди, и назначая их процессу только тогда, когда он не занят обработкой другого запроса. Для этой цели мы используем HAProxy.
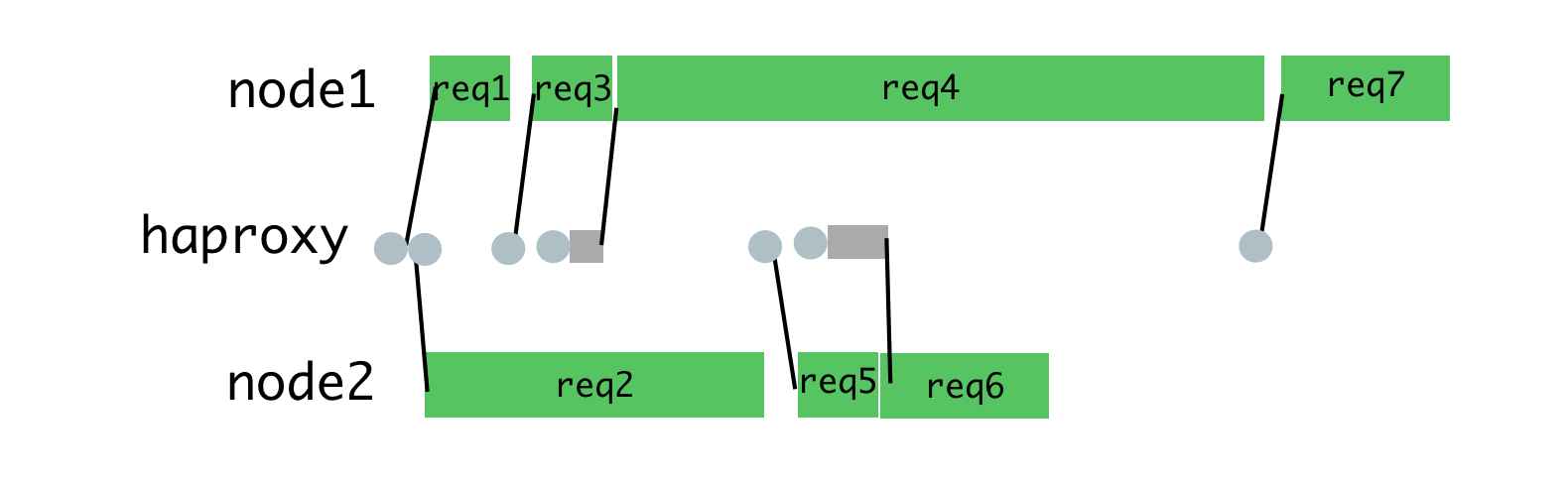
HAProxy и балансировка нагрузки на процессы
Когда мы использовали HAProxy для балансировки нагрузки на Hypernova, мы полностью исключили пики таймаутов, а также — ошибки
BadRequestErrors.Одновременные запросы были также основной причиной задержек в ходе нормальной работы, данный подход снизил такие задержки. Одним из последствий этого стало то, что теперь по таймауту закрывались лишь 2% запросов, а не 5%, с теми же настройками таймаутов. То, что нам удалось перейти от ситуации с 40% ошибок к ситуации со срабатыванием таймаута в 2% случаев, показало, что мы двигаемся в верном направлении. В результате сегодня наши пользователи видят загрузочный экран веб-сайта гораздо реже. При этом надо отметить, что стабильность системы будет иметь для нас особую важность с ожидаемым переходом на новую систему, не имеющую такого же резервного механизма, какой есть у Hypernova.
Подробности о системе и о её настройках
Для того чтобы всё это заработало, нужно настроить nginx, HAProxy и Node-приложение. Вот пример похожего приложения, использующего nginx и HAProxy, проанализировав который, можно понять устройство рассматриваемой системы. Этот пример основан на той системе, которую мы используем в продакшне, но он упрощён и изменён так, чтобы можно было выполнять его на переднем плане от имени непривилегированного пользователя. В продакшне всё следует конфигурировать с помощью некоего супервизора (мы используем runit, или, всё чаще, kubernetes).
Конфигурация nginx довольно стандартна, тут используется сервер, прослушивающий порт 9000, настроенный на проксирование запросов к серверу HAProxy, который прослушивает порт 9001 (в нашей конфигурации мы используем сокеты домена Unix).
Кроме того, этот сервер перехватывает запросы к конечной точке
/ping для прямого обслуживания запросов, направленных на проверку связности сети. Эта конфигурация отличается от нашей внутренней стандартной конфигурации nginx тем, что мы уменьшили показатель worker_processes до 1, так как один процесс nginx — это более чем достаточно для удовлетворения нужд нашего единственного процесса HAProxy и Node-приложения. Кроме того, мы используем большие буферы запросов и ответов, так как свойства компонентов, передаваемые Hypernova, могут быть довольно большими (сотни килобайт). Вам следует подобрать размер буферов в соответствии с размерами ваших запросов и ответов.Модуль Node.js
cluster занимался и балансировкой нагрузки и созданием новых процессов. Для того чтобы переключить балансировку нагрузки на HAProxy, нам понадобилось создать замену для той части cluster, которая занимается управлением процессами. Задачу управления процессами в нашем случае решает pool-hall. Это — система, которая использует собственный подход к управлению рабочими процессами, отличающийся от того, который применяет cluster, но она совершенно не участвует в балансировке нагрузки. В примере показано использование pool-hall для запуска четырёх рабочих процессов, каждый из которых слушает собственный порт.В настройках HAProxy указано, что прокси слушает порт 9001 и занимается перенаправлением трафика четырём рабочим процессам, слушающим порты с 9002 по 9005. Самый важный параметр здесь —
maxconn 1, заданный для каждого рабочего процесса. Он ограничивает каждый из них обработкой одного запроса за раз. Это можно видеть на стартовой странице HAProxy (она доступна на порту 8999).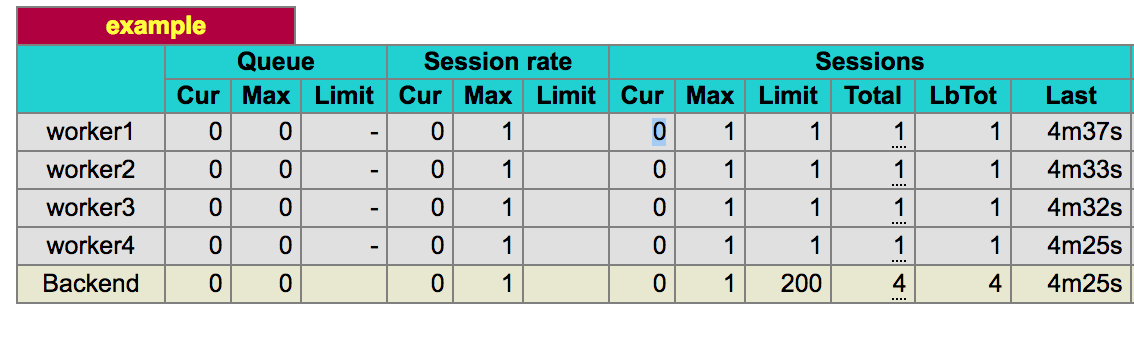
Стартовая страница HAProxy
HAProxy отслеживает текущее количество открытых соединений между ним и каждым из рабочих процессов. У него есть лимит, заданный через свойство
maxconn. Маршрутизация установлена на static-rr (static round-robin), в результате, как правило, каждый рабочий процесс получает запрос по очереди. Благодаря установленному лимиту, маршрутизация производится на основе алгоритма round-robin, но, если число запросов к рабочему процессу достигло лимита, система, до его освобождения, не назначает ему новые запросы. Если заняты все рабочие процессы, то запрос ставится в очередь и будет отправлен тому процессу, который освободится первым. Нам нужно именно такое поведение системы.Возможно, рассматриваемая здесь конфигурация очень близка к тому, что вам хотелось бы получить от подобной системы. Тут есть и другие интересные параметры (как и стандартные настройки). В процессе подготовки этой конфигурации мы провели множество тестов, как в нормальных, так и в аномальных условиях, и воспользовались значениями, полученным на основе этих испытаний. Надо сказать, что это может завести нас в дебри конфигурирования серверов и не является абсолютно необходимым для понимания описываемой тут системы, но мы поговорим об этом в следующем разделе.
Особенности использования HAProxy
Многое в нашей системе зависит от правильной работы HAProxy. Система не принесла бы нам особой пользы, если бы она не обрабатывала одновременно поступающие запросы так, как мы того ожидали, если бы неправильно их распределяла между рабочими процессами или не так ставила бы в очередь. Кроме того, нам было важно понять, как здесь обрабатываются (или не обрабатываются) сбои различных типов. Нам нужна была уверенность в том, что новая система является подходящей заменой для существующей, основанной на модуле
cluster. Для того чтобы это выяснить, мы провели серию испытаний.В ходе испытаний мы пользовались утилитой
ab (Apache Benchmark) для выполнения 10000 запросов к серверу. В разных тестах эти запросы были по-разному распределены во времени. Для запуска тестов использовалась команда следующего вида:ab -l -c <CONCURRENCY> -n 10000 http://<HOSTNAME>:9000/renderВ нашей конфигурации использовалось 15 рабочих потоков вместо 4-х из приложения-примера, и мы запускали
ab на отдельном компьютере для того, чтобы избежать нежелательного воздействия теста на испытываемую систему. Мы запускали тесты на низкой нагрузке (concurrency=5), на высокой нагрузке (concurrency=13), и на очень высокой нагрузке, под которой система начинает пользоваться очередью запросов (concurrency=20). В последнем случае нагрузка столь высока, что обеспечивает постоянное применение очереди запросов.Первый набор тестов представлял собой имитацию обычной работы системы, в общем-то, ничего особо интересного тут не происходило. Следующий набор тестов был проведён после аккуратного перезапуска всех процессов, как происходило бы при развёртывании системы. При выполнении последнего набора этих тестов я, случайным образом, останавливал некоторые процессы, имитируя ситуацию возникновения неперехваченных исключений, которые приводили бы к остановке этих процессов. Кроме того, у нас возникали некоторые проблемы, связанные с бесконечными циклами в коде приложения, мы исследовали и эти проблемы.
Тесты помогли сформировать конфигурацию, а также — лучше понять особенности работы нашей системы.
При обычном функционировании параметр
maxconn 1 проявляет себя в точности так, как ожидалось, ограничивая каждый процесс обработкой одного запроса за один раз. Мы не использовали мониторинг работоспособности HTTP или TCP на бэкендах, так как мы обнаружили, что от этого больше проблем, чем пользы. Возникало такое ощущение, что мониторинг не учитывает параметр
maxconn, хотя в коде я этого не проверял. Мы ожидали такого поведения системы, при котором процесс либо находится в хорошем состоянии и способен обслуживать запросы, либо не прослушивает порт и мгновенно выдаёт ошибку соединения (тут, однако, имеется одно важное исключение).Мы обнаружили, что проверки работоспособности не отличаются достаточной управляемостью для того, чтобы, в нашем случае, ими пользоваться, и решили избежать возникновения непредсказуемых ситуаций, связанных с использованием перекрывающихся режимов проверки работоспособности.
Вот ошибки подключения — это то, с чем мы могли работать. Мы применили параметр
option redispatch и использовали установку retries 3, что позволяло переводить запросы, при попытке обработать которые мы получали сообщение об ошибке соединения, на другой бэкенд, который, как можно было надеяться, сможет обработать запрос. Благодаря быстроте получения сообщений об отклонении соединения мы могли поддерживать работоспособность системы.Это относится лишь к соединениям, отклонённым из-за того, что соответствующий сервис не прослушивал свой порт. Таймаут соединения в данной ситуации не особенно полезен, так как мы работаем в локальной сети. Мы изначально ожидали, что сможем установить небольшой таймаут соединения для защиты от процессов, которые попали в бесконечный цикл. Мы установили таймаут в 100 мс и были удивлены, когда наши запросы завершались по таймауту через 10 секунд, что определялось другими параметрами, установленными в то время. При этом управление в цикл событий не возвращалось, что не позволяло принимать новые соединения. Это объясняется тем, что ядро считает соединение установленным с точки зрения клиента до вызова
accept сервером.Интересным побочным эффектом этого является то, что даже задание лимита очереди входящих соединений (backlog) не приводит к тому, что соединения перестают устанавливаться. Длина очереди определяется после ответа сервера SYN-ACK (реализовано это, на самом деле, так, что сервер не обращает внимания на ответ ACK от клиента). Последствием подобного поведения системы является то, что запрос с уже установленным соединением, не может быть повторно диспетчеризован, так как у нас нет способа узнать, обработал бэкенд этот запрос или нет.
Ещё один интересный результат наших тестов, касающийся исследования процессов, попавших в бесконечный цикл, заключался в том, что таймауты приводят к неожиданному поведению системы. Когда процессу отправляют запрос, приводящий к попаданию его в бесконечный цикл, счётчик соединений бэкенда устанавливается в 1. Благодаря параметру
maxconn это приводит к ожидаемому поведению системы и не даёт другим запросам попасть в ту же ловушку. Счётчик соединений сбрасывается в 0 после того, как истечёт таймаут, что позволяет нарушать наше правило, касающееся того, что один процесс не начинает обработку нового запроса до тех пор, пока не обработает предыдущий запрос. Это приводит к неправильной обработке следующего запроса, поступающего к тому же процессу. Когда клиент закрывает соединение по таймауту или по какой-то другой причине, на счётчик соединений это не влияет, у нас продолжает работать всё та же система маршрутизации. Установка abortonclose приводит к уменьшению счётчика соединений сразу после того, как клиент закрывает соединение. Учитывая это, лучше всего увеличить таймауты и не включать abortonclose. Более жёсткие таймауты могут быть установлены на клиенте или на стороне nginx.Кроме того, мы обнаружили довольно неприглядную ситуацию, возникающую при высокой нагрузке. Если рабочий процесс завершается с ошибкой (подобное должно происходить крайне редко) в то время, когда у сервера постоянно имеется очередь запросов, будут делаться попытки отправки запросов к остановившемуся бэкенду, но соединение установить не удастся, так как на этом бэкенде нет процесса, ожидающего подключений. Затем HAProxy произведёт перенаправление запроса на следующий бэкенд с открытым слотом соединения, которым будет тот же самый бэкенд, к которому только что не удалось обратиться (так как все остальные бэкенды заняты обработкой запросов). В ходе подобных обращений к неработающему серверу очень быстро будет достигнут предел лимита повторных запросов, что приведёт к отказу запроса, так как сообщения об ошибках соединения выдаются гораздо быстрее, чем выполняется рендеринг HTML. Процесс при этом продолжит пытаться отдать неработающему бэкенду другие запросы, имеющиеся в очереди, и происходить это будет до опустошения очереди. Это плохо, но это смягчается редкостью аварийного завершения процессов, редкостью наличия постоянно заполненной очереди запросов (если запросы постоянно попадают в очередь, это означает, что в системе недостаточно серверов). В нашем конкретном случае неправильно работающий сервис привлечёт внимание системы мониторинга работоспособности, которая быстро выяснит, что он непригоден для обработки новых запросов и соответствующим образом это отметит. Хорошего тут мало, но это, по крайней мере, минимизирует риск. В будущем с подобным можно бороться через более глубокую интеграцию HAProxy, где процесс супервизора наблюдает за завершением процессов и назначает им статус MAINT через сокет статистики HAProxy.
Ещё одно изменение, на которое стоит обратить внимание, заключается в том, что
server.close в Node.js ожидает завершения существующих запросов, но всё в очереди HAProxy будет работать неправильно, так как сервер не знает о том, что ему нужно ждать завершения запросов, которые он даже ещё не получил. В большинстве случаев для того, чтобы справиться с этой проблемой, нужно устанавливать адекватное время между тем моментом, когда экземпляр прекращает получать запросы, и тем моментом, когда начинается процесс перезапуска сервера.Кроме того, мы обнаружили, что установка параметра
balance first, благодаря которому большая часть трафика отправляется первому доступному рабочему процессу (обычно нагружая работой worker1) уменьшает задержки в нашем приложении примерно на 15% и под синтетической, и под реальной нагрузкой, если сравнить показатели, полученные с использованием параметра balance static-rr. Этот эффект проявляется на достаточно длинных отрезках времени, его вряд ли можно просто объяснить «прогревом» процесса. Он длится часы после запуска системы. Когда проходит больше времени (12 часов), производительность ухудшается, вероятно, из-за утечек памяти в интенсивно работающих процессах. При таком подходе, кроме того, система менее гибко реагирует на пики трафика, так как «холодные» процессы не успевают достаточно «разогреться». У нас пока нет достойного объяснения этого явления.И, наконец, тут может пригодиться настройка параметра Node
server.maxconnections, (мне казалось, что это так), но мы обнаружили, что она, на самом деле, не несёт особенной пользы и иногда приводит к ошибкам. Эта настройка не даёт серверу принимать больше соединений, чем указано в maxconnection, закрывая любые новые обработчики после того, как обнаружится, что заданный лимит превышен. Эта проверка производится в JavaScript, поэтому она не защищает от случая с бесконечным циклом (запрос корректно завершится только после возврата в цикл событий). Кроме того, мы видели ошибки соединения, вызванные этой настройкой в ходе нормального функционирования системы, даже хотя других свидетельств выполнения обработки нескольких запросов не наблюдалось. Мы подозреваем, что это либо небольшая проблема, связанная с таймингами, либо результат разницы мнений между HAProxy и Node по вопросу о том, когда соединение начинается и когда оно завершается. Мы поддерживаем стремление к тому, чтобы на стороне приложения существовали бы надёжные механизмы, позволяющие использовать синглтоны или другие глобальные хранилища состояния приложения.Достичь этого можно, реализуя раздельную очередь для каждого процесса, как это сделано, например, здесь.
Итоги
Использование серверного рендеринга на Node.js означает повышенную вычислительную нагрузку на систему. Такая нагрузка отличается от традиционной, связанной, преимущественно, с обработкой операций ввода-вывода. Именно в таких ситуациях платформа Node.js показывает себя наилучшим образом. В нашем случае, мы, попытавшись добиться высокой производительности серверной части приложения, столкнулись с рядом проблем, которые удалось решить, поработав над архитектурой системы и воспользовавшись вспомогательными механизмами, такими, как nginx и HAProxy.
Надеемся, опыт компании Airbnb пригодится всем, кто использует Node.js для решения задач серверного рендеринга.
Уважаемые читатели! Используете ли вы серверный рендеринг в своих проектах?

