
Задумывались ли вы когда-нибудь о том, как данные, с которыми вы работаете, выглядят в недрах Python? О том, как переменные создаются и хранятся в памяти? О том, как и когда они удаляются? Материал, перевод которого мы публикуем, посвящён исследованиям глубин Python, в ходе которых мы попытаемся выяснить особенности управления памятью в этом языке. Изучив эту статью, вы разберётесь с тем, как работают низкоуровневые механизмы компьютеров, в особенности те из них, которые связаны с памятью. Вы поймёте то, как Python абстрагирует низкоуровневые операции и познакомитесь с тем, как он управляет памятью.

Знание того, что происходит в Python, позволит вам лучше понимать некоторые особенности поведения этого языка. Это, хочется надеяться, даст вам возможность по достоинству оценить ту огромную работу, которая делается внутри используемой вами реализации этого языка для того, чтобы ваши программы работали именно так, как вам нужно.
Компьютерную память, в самом начале работы с ней, можно представить в виде пустой книги, предназначенной для коротких рассказов. Пока на её страницах ничего нет, но очень скоро появятся авторы рассказов, каждый из которых захочет свой рассказ в эту книгу записать.
Так как один рассказ нельзя записать поверх другого, авторам надо внимательно относиться к тому, на каких именно страницах книги они пишут. Перед тем, как что-нибудь записать, они консультируются с главным редактором. Он решает — куда именно авторам можно записывать рассказы.
Так как книга, о которой мы говорим, существует уже довольно давно, многие рассказы в ней уже устарели. Если никто не читает некий рассказ или не упоминает его в своих работах, этот рассказ из книги убирают, освобождая место для новых историй.
В целом можно сказать, что компьютерная память очень похожа на такую вот книгу. На самом деле, непрерывные блоки памяти фиксированной длины даже называют страницами, поэтому мы полагаем, что сравнение памяти с книгой является весьма удачным.
Авторы, которые записывают свои рассказы в книгу — это разные приложения или процессы, которым нужно хранить данные в памяти. Главный редактор, который принимает решения о том, на каких именно страницах книги можно делать записи авторам — это тот механизм, который занимается управлением памятью. А того, кто убирает из книги старые истории, освобождая место для новых, можно сравнить с механизмом сборки мусора.
Управление памятью — это процесс, в ходе реализации которого программы выполняют запись данных в память и чтение их из неё. Менеджер памяти — это сущность, которая определяет то, где именно приложение может разместить свои данные в памяти. Та как число фрагментов памяти, которое может быть выделено приложениям, не бесконечно, так же как не бесконечно и число страниц в любой книге, менеджеру памяти, обслуживая приложения, нужно находить свободные фрагменты памяти и предоставлять их приложениям. Этот процесс, в ходе которого приложениям «выдают» память, называется выделением памяти.
С другой стороны, когда некие данные больше не нужны, их можно удалить, или, другими словами, освободить память, которую они занимают. Но что именно «выделяют» и «освобождают», говоря о памяти?
Где-то в вашем компьютере есть физическое устройство, которое хранит данные, используемые во время работы Python-программами. Прежде чем некий объект Python окажется в физической памяти, коду приходится пройти через множество слоёв абстракции.
Один из главных таких слоёв, который расположен поверх аппаратного обеспечения (такого, как оперативная память или жёсткий диск) — это операционная система (ОС). Она выполняет (или отказывается выполнять) запросы на чтение данных из памяти и на запись данных в память.
Поверх ОС находится приложение, в нашем случае — одна из реализаций Python (это может быть программный пакет, входящий в состав вашей ОС или загруженный с python.org). Именно этот программный пакет и занимается управлением памятью, обеспечивая работу вашего Python-кода. В центре внимания этой статьи находятся алгоритмы и структуры данных, которые Python использует для управления памятью.
Эталонная реализация Python называется CPython. Она написана на языке C. Когда я впервые об этом услышал, это буквально выбило меня из колеи. Язык программирования, который написан на другом языке? Ну, на самом деле, это не совсем так.
Спецификация Python описана в этом документе на обычном английском языке. Однако, сама по себе эта спецификация код, написанный на Python, выполнять, конечно, не может. Для этого нужно что-то, что, следуя правилам из этой спецификации, сможет интерпретировать код, написанный на Python.
Кроме того, нужно что-то, что может выполнить интерпретированный код на компьютере. Эталонная реализация Python решает обе эти задачи. Она преобразует код в инструкции, которые потом выполняются на виртуальной машине.
Виртуальные машины похожи на обычные компьютеры, созданные из кремния, металла и других материалов, но они реализованы программными средствами. Они обычно заняты обработкой базовых инструкций, похожих на команды, написанные на Ассемблере.
Python — это интерпретируемый язык. Код, написанный на Python, компилируется в набор инструкций, с которым удобно работать компьютеру, в так называемый байт-код. Эти инструкции интерпретируются виртуальной машиной когда вы запускаете свою программу.
Вам доводилось видеть файлы с расширением
Важно отметить, что, помимо CPython, существуют и другие реализации Python. Например, при использовании IronPython код на Python компилируется в инструкции Microsoft CLR. В Jython код компилируется в байт-код Java и выполняется на виртуальной машине Java. В мире Python есть такое явление как PyPy, но оно достойно отдельной статьи, поэтому тут мы просто упомянем о нём.
Для целей этой статьи я сосредоточусь на том, как работают механизмы управления памятью в эталонной реализации Python — CPython.
Надо отметить, что хотя большая часть того, о чём мы будем тут говорить, будет справедлива и для новых версий Python, в будущем положение дел может измениться. Поэтому обратите внимание на то, что в этой статье я ориентируюсь на самую свежую на момент её написания версию Python — Python 3.7.
Итак, программный пакет CPython написан на C, он интерпретирует байт-код Python. Какое это имеет отношение к управлению памятью? Дело в том, что алгоритмы и структуры данных, используемые для управления памятью, существуют в коде CPython, написанном, как уже было сказано, на C. Для того чтобы понять то, как в Python работает управлению памятью, сначала нужно немного разобраться с CPython.
Язык C, на котором написан CPython, не обладает встроенной поддержкой объектно-ориентированного программирования. Из-за этого в коде CPython применено немало интересных архитектурных решений.
Возможно, вы слышали о том, что всё в Python — это объект, даже примитивные типы данных вроде
Структура (
Счётчик ссылок используется для реализации механизма сборки мусора. Другое поле
У каждого объекта есть собственный, уникальный для такого объекта, механизм выделения памяти, который знает о том, как получить память, необходимую для хранения этого объекта. Кроме того, у каждого объекта есть и собственный механизм освобождения памяти, который и «освобождает» память после того, как она больше не нужна.
Однако надо отметить, что во всех этих разговорах о выделении и освобождении памяти есть один важный фактор. Дело в том, что компьютерная память является разделяемым ресурсом. Если, в одно и то же время, два разных процесса попытаются записать что-то в одну и ту же область памяти, может произойти что-то нехорошее.
Глобальная блокировка интерпретатора (Global Interpreter Lock, GIL) — это решение распространённой проблемы, возникающей при работе с разделяемыми ресурсами компьютера наподобие памяти. Когда два потока пытаются одновременно модифицировать один и тот же ресурс, они могут друг с другом «столкнуться». В результате получится беспорядок и ни один из потоков не достигнет того, к чему стремился.
Давайте снова вернёмся к аналогии с книгой. Представим себе, что два автора самовольно решили, что сейчас — их очередь делать записи. Но они, кроме того, решили делать записи одновременно и на одной и той же странице.
Каждый из них не обращает внимания на то, что другой пытается написать свою историю. Вместе они начинают писать текст на странице. В результате там будут записаны два рассказа, один поверх другого, что сделает страницу совершенно нечитаемой.
Одно из решений подобной проблемы — это единый глобальный механизм интерпретатора, который блокирует разделяемые ресурсы, с которыми работает некий поток. В нашем примере — это «механизм», который «блокирует» страницу книги. Такой механизм исключает вышеописанную ситуацию, в которой два автора одновременно пишут текст на одной и той же странице.
Механизм GIL в Python достигает этой цели, блокируя весь интерпретатор. В результате ничто не может помешать работе текущего потока. И когда CPython занимается работой с памятью, он использует GIL для того, чтобы эта работа делалась бы безопасно и качественно.
У такого подхода есть сильные и слабые стороны, и GIL является предметом ожесточённых споров в сообществе Python. Для того чтобы больше узнать о GIL можете взглянуть на этот материал.
Давайте опять вернёмся к аналогии с книгой и представим себе, что некоторые из рассказов, записанные в этой книге, безнадёжно устарели. Никто их не читает, никто их нигде не упоминает. А если никто некий материал не читает и не ссылается на него в своих работах, то от этого материала можно избавиться, освободив место для новых текстов.
Эти старые, всеми забытые рассказы, можно сравнить с объектами Python, счётчики ссылок которых равняются нулю. Это — те самые счётчики, о которых мы говорили, обсуждая структуру
Увеличение счётчика ссылок производится по нескольким причинам. Например, счётчик увеличивается в том случае, если объект, хранящийся в одной переменной, записали ещё в одну переменную:
Он увеличивается и тогда, когда объект передают некоей функции в качестве аргумента:
А вот ещё один пример ситуации, в которой число в счётчике ссылок увеличивается. Это происходит в том случае, если объект включают в список:
Python позволяет программисту узнавать текущее значение счётчика ссылок некоего объекта с помощью модуля
Пользуясь ей, нужно помнить о том, что передача объекта методу
В любом случае, если объект всё ещё используется где-то в коде, его счётчик ссылок будет больше 0. Когда же значение счётчика упадёт до 0, в дело вступит специальная функция, которая «освобождает» память, занимаемую объектом. Эту память потом смогут использовать другие объекты.
Зададимся теперь вопросами о том, что такое «освобождение памяти», и о том, как другие объекты могут этой памятью воспользоваться. Для того чтобы ответить на эти вопросы поговорим о механизмах управления памятью в CPython.
Сейчас мы поговорим о том, как в CPython устроена архитектура памяти и как там выполняется управление памятью.
Как уже было сказано, между CPython и физической памятью имеются несколько слоёв абстракции. Операционная система абстрагирует физическую память и создаёт слой виртуальной памяти, с которым могут работать приложения (это относится и к Python).
Менеджер виртуальной памяти конкретной операционной системы выделяет фрагмент памяти для процесса Python. Тёмно-серые области на следующем изображении — это те фрагменты памяти, которые принадлежат процессу Python.
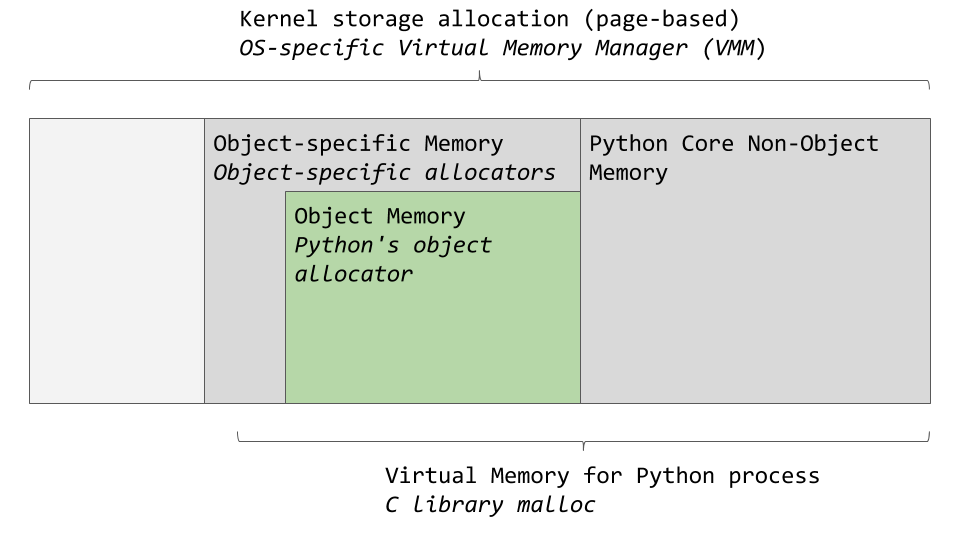
Области памяти, используемые CPython
Python задействует некую область памяти для внутреннего использования и для нужд, не связанных с выделением памяти для объектов. Ещё один фрагмент памяти используется для хранения объектов (это — значения типов
В CPython есть средство выделения памяти под объекты, которое ответственно за выделение памяти в области, предназначенной для хранения объектов. Самое интересное происходит именно при работе этого механизма. Он вызывается тогда, когда объект нуждается в памяти, или в случаях, когда память нужно освободить.
Обычно добавление или удаление данных в объекты Python наподобие
Комментарии в исходном коде описывают средство выделения памяти как «быстрый, специализированный инструмент выделения памяти для небольших блоков, который предназначен для использования поверх универсального malloc». В данном случае
Давайте обсудим стратегию выделения памяти, используемую CPython. Сначала мы поговорим о трёх сущностях — так называемых блоках (block), пулах (pool) и аренах (arena), и о том, как они связаны друг с другом.
Арены — это самые большие фрагменты памяти. Они выровнены по границам страниц памяти. Граница страницы — это место, где оканчивается непрерывный блок памяти фиксированной длины, используемый операционной системой. Python, в ходе работы с памятью, исходит из предположения о том, что размер системной страницы памяти равняется 256 Кб.
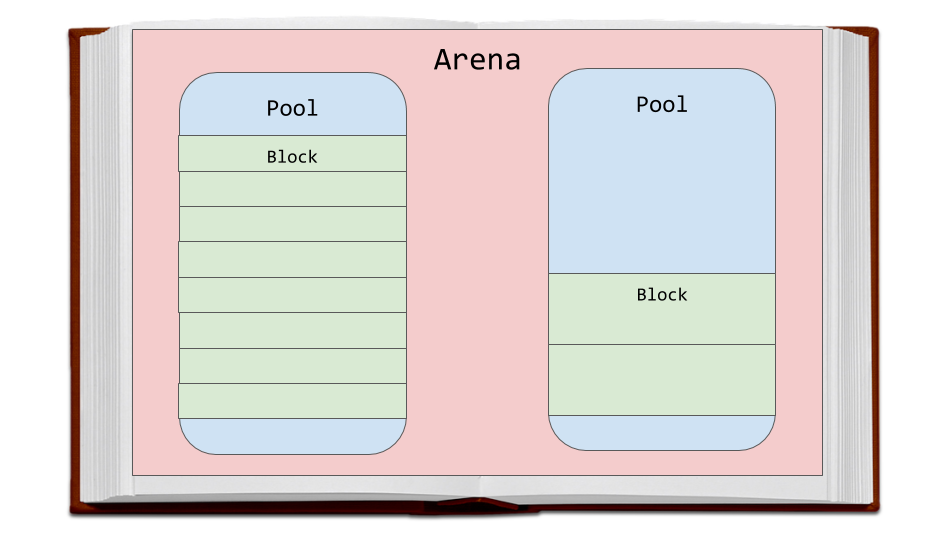
Арены, пулы и блоки
На аренах расположены пулы, представляющие собой виртуальные страницы памяти размером 4 Кб. Они напоминают страницы книги из нашего примера. Пулы разделены на небольшие блоки памяти.
Все блоки в одном пуле принадлежат к одному и тому же классу размера (size class). Класс размера, к которому принадлежит блок, определяет размер этого блока, который выбирается с учётом запрошенного объёма памяти. Вот таблица, взятая из исходного кода, в которой продемонстрированы объёмы данных, запросы на сохранение которых в памяти обрабатывает система, размеры выделяемых блоков и идентификаторы классов размеров.
Например, если запрошено сохранение 42 байтов, то данные будут помещены в 48-байтовый блок.
Пулы состоят из блоков, принадлежащих к одному классу размера. Каждый пул связан с другими пулами, содержащими блоки одинакового с ним класса размера, с использованием механизма двусвязного списка. При таком подходе алгоритм выделения памяти может легко найти свободное место для блока заданного размера, даже если речь идёт о поиске свободного места в разных пулах.
Список
Сами пулы должны пребывать в одном из трёх состояний. А именно, они могут использоваться (состояние
Список
Предположим, что в пуле, находящемся в состоянии
Знание этого алгоритма позволяет понять то, как меняется состояние пулов во время работы (и то, как меняются классы размеров, блоки, принадлежащие к которым, можно в них хранить).

Используемые, полные и пустые пулы
Как можно понять из предыдущей иллюстрации, пулы содержат указатели на «свободные» блоки памяти, которые в них содержатся. В том, что касается работы с блоками, нужно отметить одну небольшую особенность, на которую есть указание в исходном коде. Используемая в CPython система управления памятью, на всех уровнях (арены, пулы, блоки) стремиться выделять память только тогда, когда это абсолютно необходимо.
Это означает, что пулы могут содержать блоки, которые находятся в одном из трёх состояний:
Указатель
По мере того, как средство управления памятью делает блоки «свободными», они, приобретая состояние

Односвязный список freeblock
Арены содержат пулы. Эти пулы, как уже было сказано, могут пребывать в состояниях
Арены организованы в двусвязный список, который называется

Список usable_arenas
Это значит, что арена, сильнее других заполненная данными, будет выбираться для размещения в ней новых данных. А почему не наоборот? Почему бы не размещать новые данные на той арене, на которой больше всего свободного места?
На самом деле, эта особенность приводит нас к идее настоящего освобождения памяти. Вы могли заметить, что нередко мы пользовались здесь понятием «освобождение памяти», заключая его в кавычки. Причина, по которой это делалось, заключается в том, что хотя блок и может считаться «свободным», участок памяти, которую он представляет, на самом деле, не возвращён операционной системе. Процесс Python удерживает этот участок памяти и позже использует его для хранения новых данных. Настоящее освобождение памяти — это возврат её операционной системе, которая сможет ей воспользоваться.
Арены — это единственная сущность в рассмотренной здесь схеме, память, представленная которой, может быть освобождена по-настоящему. Здравый смысл подсказывает, что вышеописанная схема работы с аренами направлена на то, чтобы позволить тем аренам, которые почти пусты, опустеть полностью. При таком подходе тот фрагмент памяти, который представлен полностью опустевшей ареной, может быть по-настоящему освобождён, что снизит объём памяти, потребляемой Python.
Вот о чём вы узнали, прочтя этот материал:
Управление памятью — это неотъемлемая часть работы компьютерных программ. Python решает практически все задачи по управлению памятью незаметно для программиста. Python позволяет тому, кто пишет на этом языке, абстрагироваться от множества мелких деталей, касающихся работы с компьютерами. Это даёт программисту возможность работать на более высоком уровне, создавать свой код, не заботясь о том, где хранятся его данные.
Уважаемые читатели! Если у вас есть опыт Python-разработки — просим вас рассказать о том, как вы подходите к использованию памяти в своих программах. Например, стремитесь ли вы её экономить?


Знание того, что происходит в Python, позволит вам лучше понимать некоторые особенности поведения этого языка. Это, хочется надеяться, даст вам возможность по достоинству оценить ту огромную работу, которая делается внутри используемой вами реализации этого языка для того, чтобы ваши программы работали именно так, как вам нужно.
Память — это пустая книга
Компьютерную память, в самом начале работы с ней, можно представить в виде пустой книги, предназначенной для коротких рассказов. Пока на её страницах ничего нет, но очень скоро появятся авторы рассказов, каждый из которых захочет свой рассказ в эту книгу записать.
Так как один рассказ нельзя записать поверх другого, авторам надо внимательно относиться к тому, на каких именно страницах книги они пишут. Перед тем, как что-нибудь записать, они консультируются с главным редактором. Он решает — куда именно авторам можно записывать рассказы.
Так как книга, о которой мы говорим, существует уже довольно давно, многие рассказы в ней уже устарели. Если никто не читает некий рассказ или не упоминает его в своих работах, этот рассказ из книги убирают, освобождая место для новых историй.
В целом можно сказать, что компьютерная память очень похожа на такую вот книгу. На самом деле, непрерывные блоки памяти фиксированной длины даже называют страницами, поэтому мы полагаем, что сравнение памяти с книгой является весьма удачным.
Авторы, которые записывают свои рассказы в книгу — это разные приложения или процессы, которым нужно хранить данные в памяти. Главный редактор, который принимает решения о том, на каких именно страницах книги можно делать записи авторам — это тот механизм, который занимается управлением памятью. А того, кто убирает из книги старые истории, освобождая место для новых, можно сравнить с механизмом сборки мусора.
Управление памятью: путь от железа к программам
Управление памятью — это процесс, в ходе реализации которого программы выполняют запись данных в память и чтение их из неё. Менеджер памяти — это сущность, которая определяет то, где именно приложение может разместить свои данные в памяти. Та как число фрагментов памяти, которое может быть выделено приложениям, не бесконечно, так же как не бесконечно и число страниц в любой книге, менеджеру памяти, обслуживая приложения, нужно находить свободные фрагменты памяти и предоставлять их приложениям. Этот процесс, в ходе которого приложениям «выдают» память, называется выделением памяти.
С другой стороны, когда некие данные больше не нужны, их можно удалить, или, другими словами, освободить память, которую они занимают. Но что именно «выделяют» и «освобождают», говоря о памяти?
Где-то в вашем компьютере есть физическое устройство, которое хранит данные, используемые во время работы Python-программами. Прежде чем некий объект Python окажется в физической памяти, коду приходится пройти через множество слоёв абстракции.
Один из главных таких слоёв, который расположен поверх аппаратного обеспечения (такого, как оперативная память или жёсткий диск) — это операционная система (ОС). Она выполняет (или отказывается выполнять) запросы на чтение данных из памяти и на запись данных в память.
Поверх ОС находится приложение, в нашем случае — одна из реализаций Python (это может быть программный пакет, входящий в состав вашей ОС или загруженный с python.org). Именно этот программный пакет и занимается управлением памятью, обеспечивая работу вашего Python-кода. В центре внимания этой статьи находятся алгоритмы и структуры данных, которые Python использует для управления памятью.
Эталонная реализация Python
Эталонная реализация Python называется CPython. Она написана на языке C. Когда я впервые об этом услышал, это буквально выбило меня из колеи. Язык программирования, который написан на другом языке? Ну, на самом деле, это не совсем так.
Спецификация Python описана в этом документе на обычном английском языке. Однако, сама по себе эта спецификация код, написанный на Python, выполнять, конечно, не может. Для этого нужно что-то, что, следуя правилам из этой спецификации, сможет интерпретировать код, написанный на Python.
Кроме того, нужно что-то, что может выполнить интерпретированный код на компьютере. Эталонная реализация Python решает обе эти задачи. Она преобразует код в инструкции, которые потом выполняются на виртуальной машине.
Виртуальные машины похожи на обычные компьютеры, созданные из кремния, металла и других материалов, но они реализованы программными средствами. Они обычно заняты обработкой базовых инструкций, похожих на команды, написанные на Ассемблере.
Python — это интерпретируемый язык. Код, написанный на Python, компилируется в набор инструкций, с которым удобно работать компьютеру, в так называемый байт-код. Эти инструкции интерпретируются виртуальной машиной когда вы запускаете свою программу.
Вам доводилось видеть файлы с расширением
.pyc или папку __pycache__? В них и находится тот самый байт-код, который интерпретируется виртуальной машиной.Важно отметить, что, помимо CPython, существуют и другие реализации Python. Например, при использовании IronPython код на Python компилируется в инструкции Microsoft CLR. В Jython код компилируется в байт-код Java и выполняется на виртуальной машине Java. В мире Python есть такое явление как PyPy, но оно достойно отдельной статьи, поэтому тут мы просто упомянем о нём.
Для целей этой статьи я сосредоточусь на том, как работают механизмы управления памятью в эталонной реализации Python — CPython.
Надо отметить, что хотя большая часть того, о чём мы будем тут говорить, будет справедлива и для новых версий Python, в будущем положение дел может измениться. Поэтому обратите внимание на то, что в этой статье я ориентируюсь на самую свежую на момент её написания версию Python — Python 3.7.
Итак, программный пакет CPython написан на C, он интерпретирует байт-код Python. Какое это имеет отношение к управлению памятью? Дело в том, что алгоритмы и структуры данных, используемые для управления памятью, существуют в коде CPython, написанном, как уже было сказано, на C. Для того чтобы понять то, как в Python работает управлению памятью, сначала нужно немного разобраться с CPython.
Язык C, на котором написан CPython, не обладает встроенной поддержкой объектно-ориентированного программирования. Из-за этого в коде CPython применено немало интересных архитектурных решений.
Возможно, вы слышали о том, что всё в Python — это объект, даже примитивные типы данных вроде
int и str. И это действительно так на уровне реализации языка в CPython. Тут существует структура, которая называется PyObject, которой пользуются объекты, создаваемые в CPython.Структура (
struct) — это композитный тип данных, который способен группировать данные разных типов. Если сравнить это с объектно-ориентированным программированием, то структура похожа на класс, у которого есть атрибуты, но нет методов.PyObject — предок всех объектов Python. Эта структура содержит всего два поля:ob_refcnt— счётчик ссылок.ob_type— указатель на другой тип.
Счётчик ссылок используется для реализации механизма сборки мусора. Другое поле
PyObject — это указатель на конкретный тип объекта. Этот тип представлен ещё одной структурой, которая и описывает объект Python (например — это может быть тип dict или int).У каждого объекта есть собственный, уникальный для такого объекта, механизм выделения памяти, который знает о том, как получить память, необходимую для хранения этого объекта. Кроме того, у каждого объекта есть и собственный механизм освобождения памяти, который и «освобождает» память после того, как она больше не нужна.
Однако надо отметить, что во всех этих разговорах о выделении и освобождении памяти есть один важный фактор. Дело в том, что компьютерная память является разделяемым ресурсом. Если, в одно и то же время, два разных процесса попытаются записать что-то в одну и ту же область памяти, может произойти что-то нехорошее.
Глобальная блокировка интерпретатора
Глобальная блокировка интерпретатора (Global Interpreter Lock, GIL) — это решение распространённой проблемы, возникающей при работе с разделяемыми ресурсами компьютера наподобие памяти. Когда два потока пытаются одновременно модифицировать один и тот же ресурс, они могут друг с другом «столкнуться». В результате получится беспорядок и ни один из потоков не достигнет того, к чему стремился.
Давайте снова вернёмся к аналогии с книгой. Представим себе, что два автора самовольно решили, что сейчас — их очередь делать записи. Но они, кроме того, решили делать записи одновременно и на одной и той же странице.
Каждый из них не обращает внимания на то, что другой пытается написать свою историю. Вместе они начинают писать текст на странице. В результате там будут записаны два рассказа, один поверх другого, что сделает страницу совершенно нечитаемой.
Одно из решений подобной проблемы — это единый глобальный механизм интерпретатора, который блокирует разделяемые ресурсы, с которыми работает некий поток. В нашем примере — это «механизм», который «блокирует» страницу книги. Такой механизм исключает вышеописанную ситуацию, в которой два автора одновременно пишут текст на одной и той же странице.
Механизм GIL в Python достигает этой цели, блокируя весь интерпретатор. В результате ничто не может помешать работе текущего потока. И когда CPython занимается работой с памятью, он использует GIL для того, чтобы эта работа делалась бы безопасно и качественно.
У такого подхода есть сильные и слабые стороны, и GIL является предметом ожесточённых споров в сообществе Python. Для того чтобы больше узнать о GIL можете взглянуть на этот материал.
Сборка мусора
Давайте опять вернёмся к аналогии с книгой и представим себе, что некоторые из рассказов, записанные в этой книге, безнадёжно устарели. Никто их не читает, никто их нигде не упоминает. А если никто некий материал не читает и не ссылается на него в своих работах, то от этого материала можно избавиться, освободив место для новых текстов.
Эти старые, всеми забытые рассказы, можно сравнить с объектами Python, счётчики ссылок которых равняются нулю. Это — те самые счётчики, о которых мы говорили, обсуждая структуру
PyObject.Увеличение счётчика ссылок производится по нескольким причинам. Например, счётчик увеличивается в том случае, если объект, хранящийся в одной переменной, записали ещё в одну переменную:
numbers = [1, 2, 3]
# Счётчик ссылок = 1
more_numbers = numbers
# Счётчик ссылок = 2Он увеличивается и тогда, когда объект передают некоей функции в качестве аргумента:
total = sum(numbers)А вот ещё один пример ситуации, в которой число в счётчике ссылок увеличивается. Это происходит в том случае, если объект включают в список:
matrix = [numbers, numbers, numbers]Python позволяет программисту узнавать текущее значение счётчика ссылок некоего объекта с помощью модуля
sys. Для этого используется такая конструкция:sys.getrefcount(numbers)Пользуясь ей, нужно помнить о том, что передача объекта методу
getfefcount() увеличивает значение счётчика на 1.В любом случае, если объект всё ещё используется где-то в коде, его счётчик ссылок будет больше 0. Когда же значение счётчика упадёт до 0, в дело вступит специальная функция, которая «освобождает» память, занимаемую объектом. Эту память потом смогут использовать другие объекты.
Зададимся теперь вопросами о том, что такое «освобождение памяти», и о том, как другие объекты могут этой памятью воспользоваться. Для того чтобы ответить на эти вопросы поговорим о механизмах управления памятью в CPython.
Механизмы управления памятью в CPython
Сейчас мы поговорим о том, как в CPython устроена архитектура памяти и как там выполняется управление памятью.
Как уже было сказано, между CPython и физической памятью имеются несколько слоёв абстракции. Операционная система абстрагирует физическую память и создаёт слой виртуальной памяти, с которым могут работать приложения (это относится и к Python).
Менеджер виртуальной памяти конкретной операционной системы выделяет фрагмент памяти для процесса Python. Тёмно-серые области на следующем изображении — это те фрагменты памяти, которые принадлежат процессу Python.
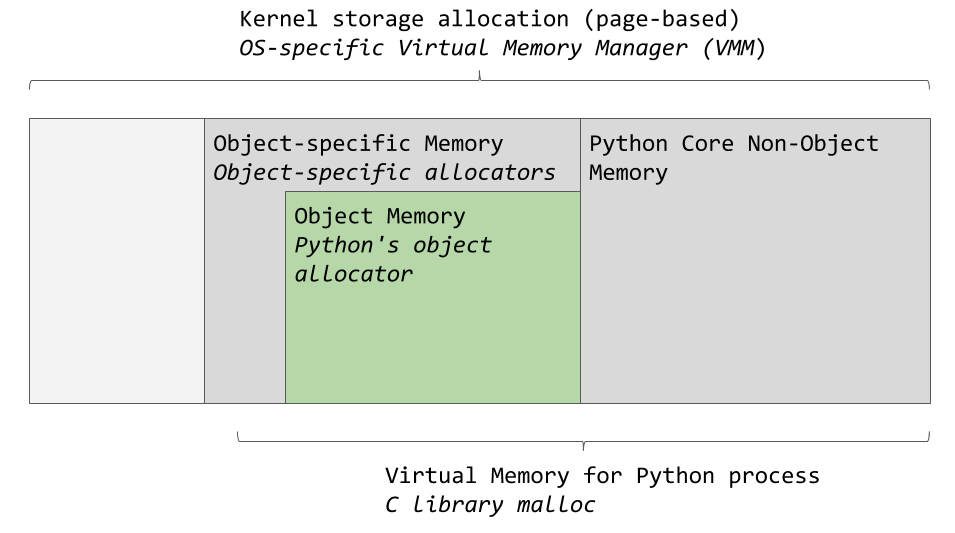
Области памяти, используемые CPython
Python задействует некую область памяти для внутреннего использования и для нужд, не связанных с выделением памяти для объектов. Ещё один фрагмент памяти используется для хранения объектов (это — значения типов
int, dict, и другие подобные). Обратите внимание на то, что это — упрощённая схема. Если вы хотите увидеть полную картину — взгляните на исходный код CPython, где происходит всё то, о чём мы тут говорим.В CPython есть средство выделения памяти под объекты, которое ответственно за выделение памяти в области, предназначенной для хранения объектов. Самое интересное происходит именно при работе этого механизма. Он вызывается тогда, когда объект нуждается в памяти, или в случаях, когда память нужно освободить.
Обычно добавление или удаление данных в объекты Python наподобие
list и int не предусматривает одномоментную обработку очень больших объёмов информации. Поэтому архитектура средства выделения памяти построена с прицелом на обработку маленьких объёмов данных. Кроме того, это средство стремится к тому, чтобы не выделять память до тех пор, пока не станет ясно то, что это совершенно необходимо.Комментарии в исходном коде описывают средство выделения памяти как «быстрый, специализированный инструмент выделения памяти для небольших блоков, который предназначен для использования поверх универсального malloc». В данном случае
malloc — это функция библиотеки C, предназначенная для выделения памяти.Давайте обсудим стратегию выделения памяти, используемую CPython. Сначала мы поговорим о трёх сущностях — так называемых блоках (block), пулах (pool) и аренах (arena), и о том, как они связаны друг с другом.
Арены — это самые большие фрагменты памяти. Они выровнены по границам страниц памяти. Граница страницы — это место, где оканчивается непрерывный блок памяти фиксированной длины, используемый операционной системой. Python, в ходе работы с памятью, исходит из предположения о том, что размер системной страницы памяти равняется 256 Кб.
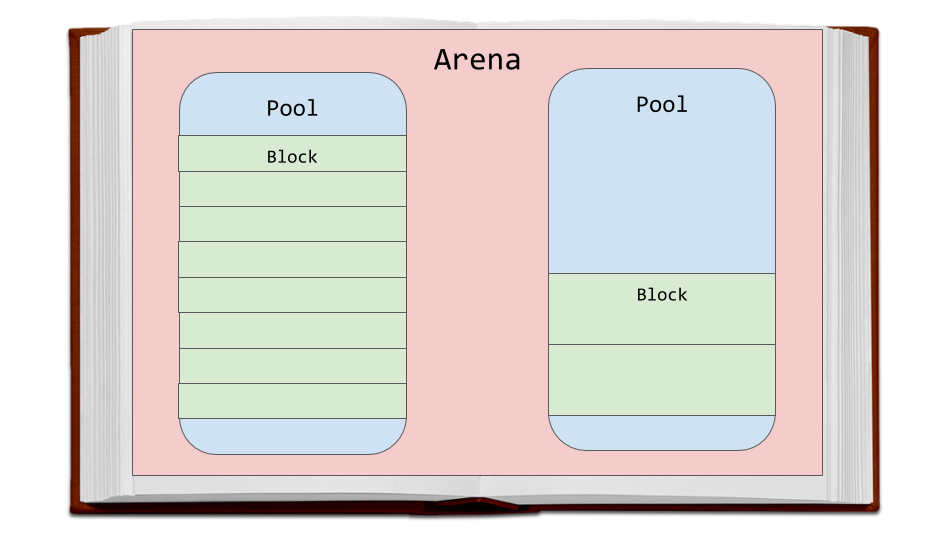
Арены, пулы и блоки
На аренах расположены пулы, представляющие собой виртуальные страницы памяти размером 4 Кб. Они напоминают страницы книги из нашего примера. Пулы разделены на небольшие блоки памяти.
Все блоки в одном пуле принадлежат к одному и тому же классу размера (size class). Класс размера, к которому принадлежит блок, определяет размер этого блока, который выбирается с учётом запрошенного объёма памяти. Вот таблица, взятая из исходного кода, в которой продемонстрированы объёмы данных, запросы на сохранение которых в памяти обрабатывает система, размеры выделяемых блоков и идентификаторы классов размеров.
| Объём данных в байтах |
Объём выделенного блока |
idx класса размера |
| 1-8 |
8 |
0 |
| 9-16 |
16 |
1 |
| 17-24 |
24 |
2 |
| 25-32 |
32 |
3 |
| 33-40 |
40 |
4 |
| 41-48 |
48 |
5 |
| 49-56 |
56 |
6 |
| 57-64 |
64 |
7 |
| 65-72 |
72 |
8 |
| … |
… |
… |
| 497-504 |
504 |
62 |
| 505-512 |
512 |
63 |
Например, если запрошено сохранение 42 байтов, то данные будут помещены в 48-байтовый блок.
Пулы
Пулы состоят из блоков, принадлежащих к одному классу размера. Каждый пул связан с другими пулами, содержащими блоки одинакового с ним класса размера, с использованием механизма двусвязного списка. При таком подходе алгоритм выделения памяти может легко найти свободное место для блока заданного размера, даже если речь идёт о поиске свободного места в разных пулах.
Список
usedpools позволяет отслеживать все пулы, в которых есть место для данных, принадлежащих к определённому классу размера. Когда запрашивается сохранение блока некоего размера, алгоритм проверяет этот список на предмет нахождения списка пулов, хранящих блоки нужного размера.Сами пулы должны пребывать в одном из трёх состояний. А именно, они могут использоваться (состояние
used), они могут быть заполненными (full) или пустыми (empty). В используемом пуле есть свободные блоки, в которых можно сохранить данные подходящего размера. Все блоки заполненного пула выделены под данные. Пустой пул не содержит данных, и он, при необходимости, может быть назначен для хранения блоков, принадлежащих к любому классу размера.Список
freepools хранит сведения обо всех пулах, находящихся в состоянии empty. Например, если в списке usedpools нет записей о пулах, хранящих блоки размером 8 байт (класс с idx 0), тогда инициализируется новый пул, пребывающий в состоянии empty, предназначенный для хранения таких блоков. Этот новый пул добавляется в список usedpools, его можно будет использовать для выполнения запросов на сохранение данных, поступающих после его создания.Предположим, что в пуле, находящемся в состоянии
full, освобождаются некоторые блоки. Происходит это из-за того, что данные, хранящиеся в них, больше не нужны. Этот пул опять попадёт в список usedpools и его можно будет использовать для данных соответствующего класса размера.Знание этого алгоритма позволяет понять то, как меняется состояние пулов во время работы (и то, как меняются классы размеров, блоки, принадлежащие к которым, можно в них хранить).
Блоки
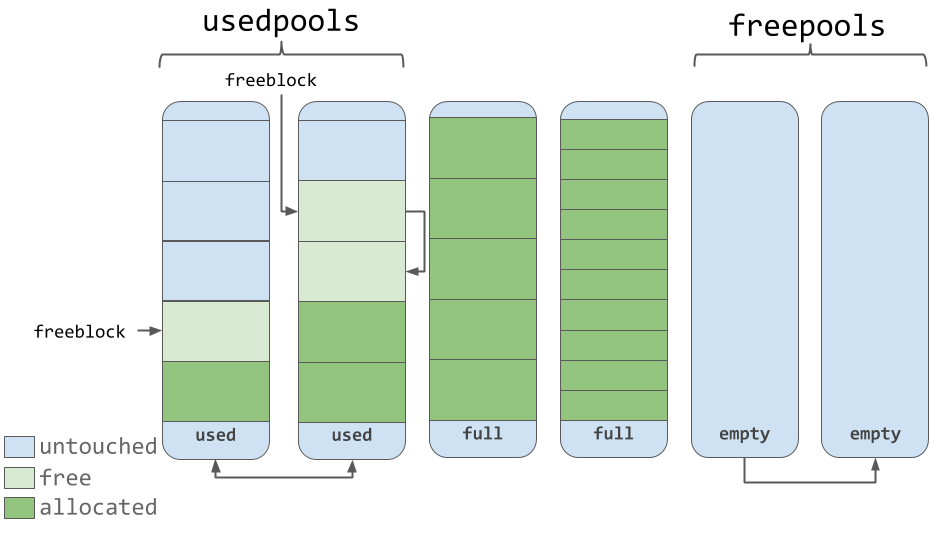
Используемые, полные и пустые пулы
Как можно понять из предыдущей иллюстрации, пулы содержат указатели на «свободные» блоки памяти, которые в них содержатся. В том, что касается работы с блоками, нужно отметить одну небольшую особенность, на которую есть указание в исходном коде. Используемая в CPython система управления памятью, на всех уровнях (арены, пулы, блоки) стремиться выделять память только тогда, когда это абсолютно необходимо.
Это означает, что пулы могут содержать блоки, которые находятся в одном из трёх состояний:
untouched— часть памяти, которая ещё не была выделена.free— часть памяти, которая уже выделялась, но позже была сделана «свободной» средствами CPython и больше не содержит никаких ценных данных.allocated— часть памяти, которая содержит ценные данные.
Указатель
freeblock указывает на односвязный список свободных блоков памяти. Другими словами — это список мест, куда можно поместить данные. Если для размещения данных нужно больше одного свободного блока, то средство выделения памяти возьмёт из пула несколько блоков, находящихся в состоянии untouched.По мере того, как средство управления памятью делает блоки «свободными», они, приобретая состояние
free, попадают в начало списка freeblock. Блоки, содержащиеся в этом списке, необязательно представляют собой непрерывную область памяти, похожую на ту, что изображена на предыдущем рисунке. Они, на самом деле, могут выглядеть так, как показано ниже.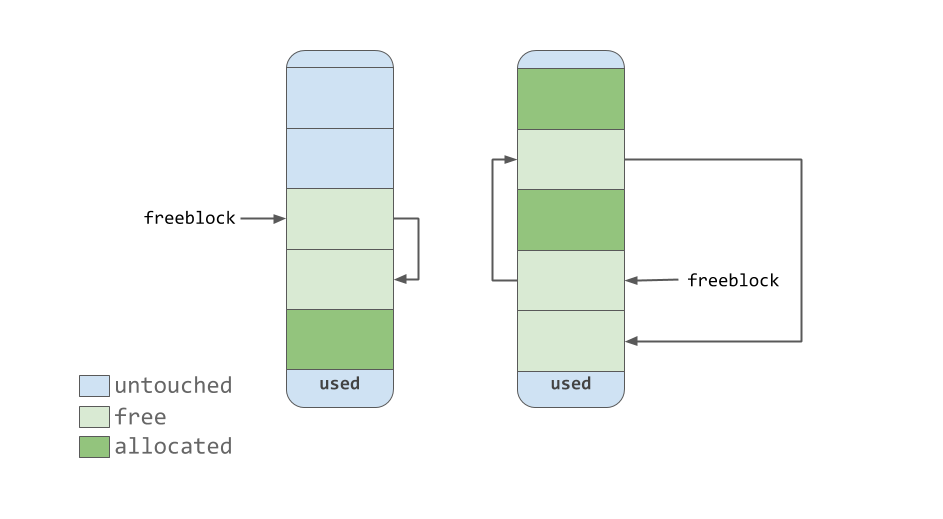
Односвязный список freeblock
Арены
Арены содержат пулы. Эти пулы, как уже было сказано, могут пребывать в состояниях
used, full или empty. Надо отметить, что у арен нет состояний, подобных тем, которые есть у пулов.Арены организованы в двусвязный список, который называется
usable_arenas. Этот список отсортирован по числу доступных свободных пулов. Чем меньше на арене свободных пулов — тем ближе арена к началу списка.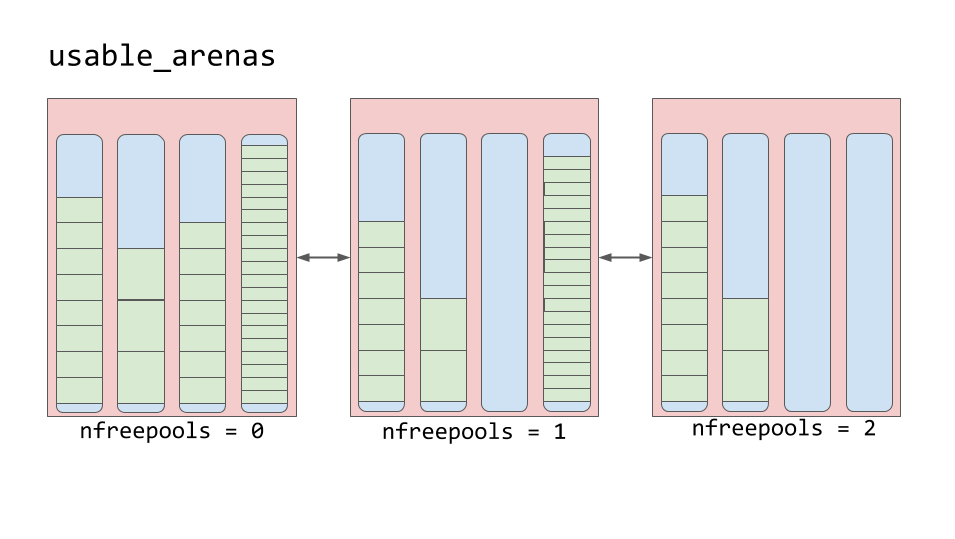
Список usable_arenas
Это значит, что арена, сильнее других заполненная данными, будет выбираться для размещения в ней новых данных. А почему не наоборот? Почему бы не размещать новые данные на той арене, на которой больше всего свободного места?
На самом деле, эта особенность приводит нас к идее настоящего освобождения памяти. Вы могли заметить, что нередко мы пользовались здесь понятием «освобождение памяти», заключая его в кавычки. Причина, по которой это делалось, заключается в том, что хотя блок и может считаться «свободным», участок памяти, которую он представляет, на самом деле, не возвращён операционной системе. Процесс Python удерживает этот участок памяти и позже использует его для хранения новых данных. Настоящее освобождение памяти — это возврат её операционной системе, которая сможет ей воспользоваться.
Арены — это единственная сущность в рассмотренной здесь схеме, память, представленная которой, может быть освобождена по-настоящему. Здравый смысл подсказывает, что вышеописанная схема работы с аренами направлена на то, чтобы позволить тем аренам, которые почти пусты, опустеть полностью. При таком подходе тот фрагмент памяти, который представлен полностью опустевшей ареной, может быть по-настоящему освобождён, что снизит объём памяти, потребляемой Python.
Итоги
Вот о чём вы узнали, прочтя этот материал:
- Что такое управление памятью и почему это важно.
- Как устроена эталонная реализация Python, Cpython, написанная на языке программирования C.
- Какие структуры данных и алгоритмы используются в CPython для управления памятью.
Управление памятью — это неотъемлемая часть работы компьютерных программ. Python решает практически все задачи по управлению памятью незаметно для программиста. Python позволяет тому, кто пишет на этом языке, абстрагироваться от множества мелких деталей, касающихся работы с компьютерами. Это даёт программисту возможность работать на более высоком уровне, создавать свой код, не заботясь о том, где хранятся его данные.
Уважаемые читатели! Если у вас есть опыт Python-разработки — просим вас рассказать о том, как вы подходите к использованию памяти в своих программах. Например, стремитесь ли вы её экономить?

