
В предыдущей части мы разобрали, чем являются пространства имен, и какую роль они играют в современных системах, после чего познакомились с двумя их видами: PID и NET. Во второй и заключительной части материала мы изучим пространства имен USER, MNT, UTS, IPC и CGROUP, а в завершении объединим полученные знания, создав полностью изолированную среду для процесса.
USER namespace
Все процессы в мире Linux кому-то принадлежат. Существуют привилегированные и непривилегированные процессы, что определяется их пользовательским ID (UID). В зависимости от этого UID процессы получают разные привилегии в ОС. Пользовательское пространство имен – это функционал ядра, позволяющий выполнять виртуализацию этого атрибута для каждого процесса. В документации Linux это пространство имен определяется так:
«Пользовательские пространства имен изолируют связанные с безопасностью идентификаторы и атрибуты. В частности, ID пользователей, групповые ID, корневой каталог, ключи и возможности. Пользователь процесса и групповые ID внутри и вне user namespace* могут отличаться. Если конкретно, то процесс может иметь обычный непривилегированныйUIDвне этого пространства имен и в то же время иметьUID=0внутри него».
*Прим. пер.: С целью облегчить чтение по ходу статьи выражения «пространство имен» и «namespace» будут использоваться попеременно.
По сути, это означает, что процесс имеет полные привилегии для операций внутри его текущего пользовательского пространства имен, но вне него является непривилегированным.
Начиная с Linux 3.8 (и в отличие от флагов, используемых для создания других типов пространств имен), в некоторых дистрибутивах Linux для создания user namespace привилегий не требуется. Попробуем!
cryptonite@cryptonite:~ $uname -a
Linux qb 5.11.0-25-generic #27~20.04.1-Ubuntu SMP Tue Jul 13 17:41:23 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
# корневое user namespace
cryptonite@cryptonite:~ $id
uid=1000(cryptonite) gid=1000(cryptonite) groups=1000(cryptonite) ...
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)В новом user namespace наш процесс принадлежит пользователю
nobody с UID=65334, который в системе отсутствует. Хорошо, но откуда он берется, и как ОС обрабатывает его, когда дело касается общесистемных операций (изменение файлов, взаимодействие с программами)? В документации говорится, что это предопределено в файле:«ЕслиUIDне имеет отображения внутри пространства имен, тогда системные вызовы, возвращающие пользовательские ID, возвращают значение, определенное в файле/proc/sys/kernel/overflowuid. В стандартной системе по умолчанию этим значением является65534. Изначально, user namespace не имеет отображенияUID, поэтому всеUIDвнутри него отображаются в это значение».
На вторую же часть вопроса ответ такой – для ситуаций, когда процессу нужно выполнять общесистемные операции, существует динамическое отображение
UID.#внутри user namespace создаем файл
nobody@cryptonite:~$ touch hello
nobody@cryptonite:~ $ls -l hello
-rw-rw-r-- 1 nobody nogroup 0 Jun 29 17:06 helloЗдесь мы видим, что созданный файл принадлежит пользователю
nobody, который по факту в текущей системе не существует. Давайте проверим владение этим файлом с позиции процесса в корневом user namespace.cryptonite@cryptonite:~ $ls -al hello
-rw-rw-r-- 1 cryptonite cryptonite 0 Jun 29 17:09 hello
# под каким UID выполняется процесс, создавший этот файл?
cryptonite@cryptonite:~ $ps l | grep /bin/bash
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 1000 18609 3135 20 0 19648 5268 poll_s S+ pts/0 0:00 /bin/bashКак видно из фрагмента выше, процесс оболочки в корневом user namespace видит, что процесс внутри
user namespace имеет такой же UID. Это также объясняет, почему файл, созданный nobody и видимый как принадлежащий nobody в новом user namespace, на деле принадлежит пользователю с ID=1000.Как уже говорилось, пользовательские пространства имен могут быть и вложенными – процесс может иметь родительское пространство имен (за исключением процессов в корневом пространстве имен) и нуль или более дочерних пространств имен. Теперь посмотрим, как процесс видит файловую систему, в которой владение содержимым определяется в корневом user namespace.
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:/$ ls -al
drwxr-xr-x 20 nobody nogroup 4096 Jun 12 17:25 .
drwxr-xr-x 20 nobody nogroup 4096 Jun 12 17:25 ..
lrwxrwxrwx 1 nobody nogroup 7 Jun 12 17:21 bin -> usr/bin
drwxr-xr-x 5 nobody nogroup 4096 Jun 25 10:23 boot
...
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
nobody@cryptonite:~$ touch /heloo.txt
touch: cannot touch '/heloo.txt': Permission deniedСтранно – содержимое корневого каталога, видимое из нового user namespace, принадлежит пользователю, владеющему процессом внутри этого namespace, но содержимое данного каталога этот пользователь изменять не может? В новом user namespace пользователь (корневой), владеющий этими файлами, не переотображается, а значит не существует. Именно поэтому процесс видит
nobody и nogroup. Но, когда он пробует изменить содержимое каталога, то делает это с помощью своего
UID в корневом user namespace, который отличается от UID файлов. Ладно, но как в таком случае процесс может взаимодействовать с файловой системой? Придется использовать отображение.Отображение UID и GID
Некоторые процессы должны запускаться под действующим
UID=0, чтобы предоставить свои службы и иметь возможность взаимодействовать с файловой системой ОС. Одним из типичных случаев при использовании пользовательских пространств имен является определение отображений. Выполняется оно при помощи файлов /proc/‹PID
›/uid_map и /proc/‹PID›/gid_map в следующем формате:ID-внутри-ns ID-вне-ns длинаID-внутри-ns (соответственно ID-вне-ns) определяет начальную точку отображения UID внутри user namespace (соответственно вне этого пространства имен), а длина определяет количество последующих отображений UID (соответственно GID). Эти отображения применяются, когда процесс внутри user namespace пытается манипулировать ресурсами системы, принадлежащими user namespace.Некоторые важные правила из документации Linux:
«Если два процесса находятся в одном пространстве имен, тогдаID-вне-nsинтерпретируется какUID(GID) в родительском user namespace идентификатора (PID) процесса. Здесь типичным случаем является процесс, производящий запись в собственный файл отображения (/proc/self/uid_mapили/proc/self/gid_map)».
Если два процесса находятся в разных пространствах имен, тоID-вне-nsинтерпретируется какUID(GID) в user namespace процесса, открывающего/proc/PID/uid_map(/proc/PID/gid_map). Тогда записывающий процесс определяет отображение относительно его собственного user namespace.
Хорошо, проверим все это:
# добавление отображения для процесса оболочки с PID=18609 в user namespace
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/18609/uid_map
0 1000 65335
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/18609/gid_map
0 1000 65335
# возвращаемся в оболочку в user namespace
nobody@cryptonite:~$ id
uid=0(root) gid=0(root) groups=0(root)
# создаем файл
nobody@cryptonite:~$ touch hello
# возвращаемся в корневое пространство имен
cryptonite@cryptonite:~ $ls -l hello
-rw-rw-r-- 1 cryptonite cryptonite 0 Jun 29 17:50 helloПроцесс внутри пользовательского пространства имен считает, что его действительный
UID является корневым, но в вышестоящем (корневом) пространстве имен его UID такой же, как у создавшего его процесса (zsh с UID=1000). Вот иллюстрация для вышеприведенного фрагмента кода:
В более общем виде процесс переотображения показан здесь:

Также важно отметить, что в созданном user namespace процесс имеет действительный
UID=0, и все возможности устанавливаются а разрешенном наборе.Посмотрим, как выглядит файловая система для процесса, находящегося внутри переотображенного user namespace.
# в корневом user namespace
cryptonite@cryptonite:~ $ls -l
total 0
-rw-rw-r-- 1 cryptonite cryptonite 0 Jul 2 11:07 hello
# в дочернем user namespace
nobody@cryptonite:~/test$ ls -l
-rw-rw-r-- 1 root root 0 Jul 2 11:07 helloЗдесь мы видим, что переотображенный пользователь воспринимает владение файлами относительно текущего отображения user namespace. Поскольку файл принадлежит
UID=1000, который отображен в UID=0 (корень), этот процесс видит файл как принадлежащий корневому пользователю в текущем пространстве имен. Инспектирование текущих отображений процесса
Файлы
/proc/‹PID
›/uid_map и /proc/‹PID›/gid_map также можно использовать для инспектирования отображения заданного процесса. Это инспектирование происходит относительно пользовательского пространства имен, в котором процесс находится. Здесь есть два правила:
- Если процесс внутри одного namespaceинспектирует отображение другого процесса в том же namespace, то он увидит отображение на родительское user namespace.
- Если процесс инспектирует отображение процесса из другого namespace, то он увидит отображение относительно его собственного отображения.
Все это немного запутывает, так что посмотрим наглядно:
# в оболочке номер 1
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:~$
# в оболочке номер 2 определяем переотображение пользователя
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/6638/uid_map
0 1000 65335
# восприятие изнутри переотображенного namespace
nobody@cryptonite:~ $cat /proc/self/uid_map
0 1000 65335
nobody@cryptonite:~ $id
uid=0(root) gid=65534(nogroup) groups=65534(nogroup)
# теперь в 3-й оболочек создаем новое user namespace
cryptonite@cryptonite:~ $unshare -U /bin/sh
$
# во 2-й оболочке определяем новое отображение оболочки sh
cryptonite@cryptonite:~ $echo "200 1000 65335" | sudo tee /proc/7061/uid_map
# возвращаемся в оболочку sh
# восприятие собственного переотображения
$ cat /proc/self/uid_map
200 1000 65335
# восприятие переотображения оболочки bash
$ cat /proc/6638/uid_map
0 200 65335Хорошо, мы видим, что переотображенный процесс оболочки
sh воспринимает переотображение пользователя на основе его собственного user namespace. Результаты можно интерпретировать так: процесс UID=0 в user namespace для процесса 6638 соответствует UID=200 в текущем namespace. Все это относительно. Выдержка из документации:«Если процесс, открывающий файл, находится в том же user namespace, что иPIDэтого процесса, тогдаID-вне-nsопределяется относительно родительского user namespace. Если процесс, открывающий файл, находится в другом user namespace, тогдаID-вне-nsопределяется относительно user namespace этого открывающего файл процесса».
Существуют кое-какие важные правила по определению переотображения внутри файла:
«Определение переотображения – это одноразовая операция для каждого пространства имен: мы можем выполнить только одну операцию записи (которая может содержать несколько разделенных пустыми строками записей) в файл uid_map или ровно один из процессов в user namespace. Более того, сейчас в файл можно записать не более пяти строк».«Файл/proc/PID/uid_mapпринадлежитUID, который создал пространство имен, и делать запись в него может только этот пользователь (или привилегированный). При этом должны быть выполнены следующие требования:
- записывающий процесс должен иметь возможность
CAP_SETUID(CAP_SETGIDдляgid_map) в user namespace своегоPID;- независимо от возможностей, записывающий процесс должен находиться либо в user namespace
PIDпроцесса, либо в ближайшем родительском user namespace идентификатора процесса».
User namespace и возможности
Как я уже говорил, первый процесс в новом user namespace имеет полный набор возможностей внутри этого user namespace.
Выдержка из документации:
«Когда создается user namespace, первый процесс в нем получает полный набор возможностей для данного namespace. Это позволяет ему выполнять любые необходимые инициализации до создания других процессов в этом namespace. Причем несмотря на то, что новый процесс имеет весь набор возможностей в новом user namespace, в родительском namespace он их не имеет совсем. Это верно независимо от полномочий и возможностей процесса, вызывающегоclone(). В частности, даже если корень задействуетclone(CLONE_NEWUSER), результирующий дочерний процесс не будет иметь возможностей в родительском namespace».
Так что, даже возможности процесса инициализируются и интерпретируются относительно user namespace. Рассмотрим все это на примере, используя небольшую программу, порождающую новый процесс внутри user namespace и показывающую его возможности с позиции родительского user namespace и дочернего namespace.
cryptonite@cryptonite:~ $ ./main
Capabilities of child process viewed from parent namespace =
Capabilities of child process viewed from child namespace =ep
Namespaced process eUID = 65534; eGID = 65534;Как видно, процесс внутри нового пространства имен имеет полный набор разрешенных и активных возможностей в user namespace несмотря на то, что программа была запущена от непривилегированного пользователя. Однако в родительском user namespace возможностей у него никаких нет. Причина в том, что каждый раз, когда создается user namespace, первый процесс получает все возможности, чтобы смочь полноценно инициализировать среду пространства имен до создания в нем любых других процессов. Это сыграет важную роль в последнем разделе статьи, где мы займемся совмещением почти всех пространств имен с целью изоляции процесса.
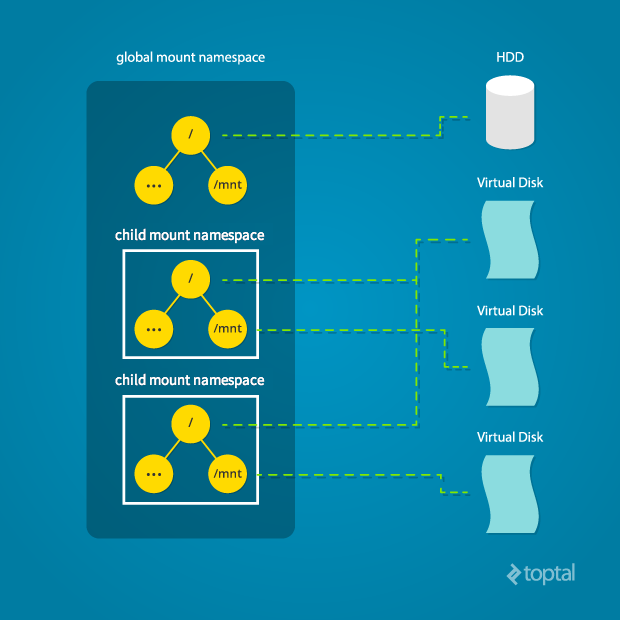
MNT namespace
Пространства имен mount (MNT) позволяют создавать деревья файловых систем под отдельные процессы, тем самым создавая представления корневой файловой системы. Linux поддерживает структуру данных для всех различных файловых систем, смонтированных в системе. Эта структура является индивидуальной для каждого процесса, а также пространства имен. В нее входит информация о том, какие разделы дисков смонтированы, где они смонтированы и тип монтирования (RO/RW).
cryptonite@cryptonite:~ $cat /proc/$$/mounts
sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
...Пространства имен в Linux дают возможность копировать эту структуру данных и передавать копию разным процессам. Таким образом, эти процессы могут изменять данную структуру (монтировать и размонтировать), не влияя на точки монтирования друг друга. Предоставляя разные копии структуры файловой системы, ядро изолирует список точек монтирования, видимых процессу в пространстве имен.
Определение mount namespace также позволяет процессу изменять свой корень, то есть проявлять поведение, аналогичное системному вызову
chroot. Разница здесь в том, что chroot привязан к текущей структуре файловой системы, и все изменения (монтирование, размонтирование) в среде с измененным корнем влияют на всю файловую систему. В случае с пространствами имен такое невозможно, поскольку вся структура виртуализирована, тем самым обеспечивая полную изоляцию исходной файловой системы для монтирования/размонтирования.# находим ID пространства имен текущего процесса оболочки
cryptonite@cryptonite:~ $readlink /proc/$$/ns/mnt
mnt:[4026531840]Схема устройства mount namespace:
Схема оформлена Махмудом Ридваном из Toptal
Попробуем!
# создаем новое namespace и входим в него
cryptonite@cryptonite:~ $sudo unshare -m /bin/bash
root@cryptonite:/home/cryptonite# mount -t tmpfs tmpfs /mnt
root@cryptonite:/home/cryptonite# touch /mnt/hello
# во втором терминале <=> в отдельном mount namespace
cryptonite@cryptonite:~ $ls -al /mnt
total 8
drwxr-xr-x 2 root root 4096 Feb 9 19:47 .
drwxr-xr-x 20 root root 4096 Jun 8 23:24 .
# изменения не отразили другое mount namespaceЗдесь мы видим, что процессы в изолированном mount namespace могут создавать под собой различные точки монтирования и файлы, не отражая родительское mount namespace.
Общие поддеревья
Монтирование и размонтирование каталогов отражает файловую систему ОС. В классической ОС Linux эта система представлена в виде дерева. Как видно из схемы выше, создание различных пространств имен технически приводит к созданию виртуальных структур деревьев для каждого процесса. Так вот, эти структуры могут быть общими.
Из документации Linux:
«Ключевое преимущество общих поддеревьев заключается в возможности автоматического, управляемого распространения событий монтирования и размонтирования между пространствами имен. Это означает, к примеру, что монтирование оптического диска в одном mount namespace может запустить монтирование этого диска во всех пространствах имен».
Основной составляющей поддеревьев являются теги для каждой точки монтирования, сообщающие, что произойдет при добавлении/удалении точек монтирования, присутствующих в разных mount namespace. Добавление/удаление точек монтирования запускает событие, которое распространяется в так называемых одноранговых группах. Одноранговая группа – это набор
vfsmounts (точек монтирования виртуальной файловой системы), которые распространяют события монтирования и размонтирования между собой. Точки монтирования бывают четырех видов:
MS_SHARED: разделяет события монтирования/размонтирования с другими точками монтирования, входящими в ее «одноранговую группу». Когда под этой точкой монтирования добавляется/удаляется другая точка, это изменение распространяется на всю группу, в результате чего монтирование/размонтирование также происходит под каждой из одноранговых точек. Распространение также происходит и в обратном направлении, в следствии чего события монтирования/размонтирования в однорангововых точках монтирования распространяются на эту точку.MS_PRIVATE: противоположна общей точке монтирования, то есть не распространяет события на одноранговых соседей и не получает аналогичные события от них.MS_SLAVE: находится между общим видом и закрытым. Подчиненная точка монтирования имеет мастера – общую группу пиров, чьи члены распространяют события монтирования/размонтирования на подчиненную точку. Однако такая точка, в свою очередь, на мастер-группу пиров события не распространяет.MS_UNBINDABLE– не получает и не передает никакие события распространения и роль привязки монтирования выполнять не может.
Состояние точки монтирования является индивидуальным для каждой такой точки. То есть, если у вас есть, например,
/ и boot, то вам нужно отдельно применить нужное состояние для каждой точки монтирования. Предлагаю немного поэкспериментировать.# создаем точку монтирования и описываем ее как общую для пиров (дочерних пространств # имен)
cryptonite@cryptonite:~ $mkdir X
cryptonite@cryptonite:~ $sudo mount --make-shared -t tmpfs tmpfs X/
# входим в новое mount namespace
cryptonite@cryptonite:~ $sudo unshare --mount /bin/bash
root@cryptonite:/home/cryptonite#
# теперь создадим еще одну точку монтирования в родительском mount namespace
cryptonite@cryptonite:~ $mkdir Y; mount --make-shared -t tmpfs tmpfs Y/
# возвращаемся в оболочку внутри mount namespace
root@cryptonite:/home/cryptonite/X# mount | grep Y
tmpfs в /home/cryptonite/X/Y type tmpfs (rw,relatime)
# так, мы видим, что между этими двумя пространствами имен происходит
# распространение.
# Точка монтирования была помечена как shared => изменения отражаются во всех членах
# одноранговой группы.
# возвращаемся в корневое mount namespace
cryptonite@cryptonite:~ $mkdir Z; sudo mount --make-private -t tmpfs tmpfs Z
cryptonite@cryptonite:~ $mount | grep Z
tmpfs on /home/cryptonite/test/Z type tmpfs (rw,relatime)
# возвращаемся в дочернее mount namespace
root@cryptonite:/home/cryptonite/test# mount | grep Z
# ничего --> точка монтирования, помеченная как private, из родительского пространства # имен в дочернем mount namespace отсутствуетИнформацию о разных видах монтирования в пространстве имен текущего процесса можно найти в
/proc/self/mountinfo.╭─cryptonite@cryptonite ~
╰─$ cat /proc/self/mountinfo | head -n 3
24 31 0:22 / /sys rw,nosuid,nodev,noexec,relatime shared:7 - sysfs sysfs rw
25 31 0:23 / /proc rw,nosuid,nodev,noexec,relatime shared:15 - proc proc rw
26 31 0:5 / /dev rw,nosuid,noexec,relatime shared:2 - devtmpfs udev rw,size=8031108k,nr_inodes=2007777,mode=755UTS namespace
Пространство имен UTS изолирует имя хоста системы для определенного процесса.
Большая часть взаимодействия с хостом выполняется через IP-адрес и номер порта. Однако для человеческого восприятия все сильно упрощается, когда у процесса есть хоть какое-то имя. К примеру, выполнять поиск по файлам журналов гораздо проще, когда определено имя хоста. Не в последнюю очередь это связано с тем, что в динамической среде IP могут изменяться.
По аналогии можно сравнить имя хоста с названием многоэтажного жилого здания. Сказать таксисту, что мы живем в City Palace, часто будет эффективнее, чем сообщать фактический адрес. Наличие нескольких имен хостов на одном физическом хосте существенно помогает в обширных контейнеризованных средах.
Итак, пространство имен UTS предоставляет разделение имен хостов среди процессов. Таким образом, становится проще взаимодействовать со службами в закрытой сети и инспектировать их логи на хосте.
cryptonite@cryptonite:~ $sudo unshare -u /bin/bash
root@cryptonite:/home/cryptonite# hostname
cryptonite
root@cryptonite:/home/cryptonite# hostname test
root@cryptonite:/home/cryptonite# hostname
test
# тем временем во втором терминале
cryptonite@cryptonite:~ $hostname
cryptoniteIPC namespace
Пространство имен IPC предоставляет изоляцию для механизмов взаимодействия процессов, таких как семафоры, очереди сообщений, разделяемая память и т.д. Обычно, когда процесс ответвляется, он наследует все IPC, открытые его родителем. Процессы внутри IPC namespace не могут видеть или взаимодействовать с ресурсами IPC вышестоящего пространства имен. Вот краткий пример, где используются разделяемые сегменты памяти:
cryptonite@cryptonite:~ $ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 32769 cryptonite 600 4194304 2 dest
0x00000000 6 cryptonite 600 524288 2 dest
0x00000000 13 cryptonite 600 393216 2 dest
0x00000000 16 cryptonite 600 524288 2 dest
0x00000000 32785 cryptonite 600 32768 2 dest
cryptonite@cryptonite:~ $sudo unshare -i /bin/bash
root@cryptonite:/home/cryptonite#
------ Shared Memory Segments --------
key shmid owner perms bytes nattch statusCGROUP namespace
Cgroup (контрольная группа) — это технология, контролирующая потребляемый процессом объем аппаратных ресурсов (RAM, HDD, блок ввода-вывода).
По умолчанию CGroup создаются в виртуальной файловой системе
/sys/fs/cgroup. Создание другого CGroup namespace, по сути, перемещает корневой каталог CGroup. Если CGroup размещалось, например, в /sys/fs/cgroup/mycgroup, то новое CGroup namespace могло использовать его в качестве корневого каталога. Хост может видеть /sys/fs/cgroup/mycgroup/{group1,group2,group3}, но создание нового CGroup namespace будет означать, что новое namespace увидит только {group1,group2,group3}.Итак, пространства имен CGroup виртуализируют другие виртуальные файловые системы в виде PID namespace. Но в чем вообще цель предоставления изоляции для данной системы? Выдержка из мануала:
«Это предотвращает утечку информации при том, что в противном случае пути каталогов cgroup вне контейнера будут видимы для процессов в контейнере. Подобные утечки могут, к примеру, раскрыть контейнеризованным приложениям информацию о структуре контейнера».
В традиционной иерархии
CGroup существует возможность того, что вложенное CGroup сможет получить доступ к своему предку. Это означает, что процесс в /sys/fs/cgroup/mycgroup/group1 потенциально может считывать и/или управлять чем-угодно, вложенным в mycgroup.Объединение изученного
Теперь мы используем пройденный материал, чтобы создать для процесса полностью изолированную среду. Сделаем мы это шаг за шагом, используя обертку
unshare. Доказательство концепции этой статьи написано на Си с использованием системного вызова clone() и находится здесь.# Сначала скачиваем минимальный образ файловой системы,
# который будет находиться в новой корневой файловой системе изолированного процесса
cryptonite@cryptonite:~ $wget http://dl-cdn.alpinelinux.org/alpine/v3.10/releases/x86_64/alpine-minirootfs-3.10.1-x86_64.tar.gz
cryptonite@cryptonite:~ $mkdir rootfs_alpine; tar -xzf alpine-minirootfs-3.10.1-x86_64.tar.gz -C rootfs_alpine
cryptonite@cryptonite:~ $ls rootfs_alpine
bin etc hostfs_root media opt root sbin sys usr
dev home lib mnt proc run srv tmp varХорошо, теперь у нас есть каталог, чье содержимое совпадает с классическим корневым каталогом Linux. Важно отметить порядок обертывания пространства имен, поскольку некоторые операции (например, создание пространств имен PID, UTC, IPC) требуют наличия расширенных привилегий в текущем пространстве имен. Приведенный ниже алгоритм иллюстрирует необходимый порядок действий:
- Создать USER namespace
- Переотобразить
UIDпроцесса в новое USER namespace - Создать UTC namespace
- Изменить имя хоста в новом UTC namespace
- Создать IPC/CGROUP namespaces
- Создать NET namespace
- Создать и настроить пару
veth - Создать PID namespace
- Создать MNT namespace
- Изменить корень процесса
- Смонтировать
/procв новом корне - Размонтировать старый корень
- Поместить процесс в его новый корневой каталог
Поробуем!
# создаем привилегированное user namespace, чтобы иметь возможность
# создавать пространства имен, требующие права администратора
cryptonite@cryptonite:~ $unshare -U --kill-child /bin/bash
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
# пробуем создать новые пространства имен
nobody@cryptonite:~$ unshare -iu /bin/bash
unshare: unshare failed: Operation not permitted
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)Пользователь в user namespace не может создавать новые пространства имен, поскольку не обладает
eUID=0. Чтобы это исправить, нам нужно дать ему рут-права с помощью переотображения. Как уже говорилось, это переотображение должно происходить из процесса в вышестоящем user namespace. Однако из соображений безопасности мы выполним переотображение в непривилегированного пользователя вне этого namespace (eUID=0 -> eUID!=0).# в другом терминале; получаем PID процесса в пространстве имен.
# Затем переотображаем корневого пользователя внутри этого пространства имен в
# непривилегированного.
# В вышестоящем пространстве имен:
cryptonite@cryptonite:~ $ps aux | grep /bin/bash
crypton+ 26739 0.2 0.0 19516 5040 pts/0 S+ 18:04 0:00 /bin/bash
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/26739/uid_map
0 1000 65335
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/26739/gid_map
0 1000 65335
# возвращаемся к процессу в user namespace
nobody@cryptonite:~/test$ id
uid=0(root) gid=0(root) groups=0(root),65534(nogroup)Теперь можно переходить к созданию пространств имен IPC и UTS.
#создаем пространства имен IPC и UTC
nobody@cryptonite:~$ unshare --ipc --uts --kill-child /bin/bash
root@cryptonite:~/test# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
root@cryptonite:~# hostname isolated
root@cryptonite:~# hostname
isolatedДалее с помощью виртуальных интерфейсов создадим net namespace.
# возвращаемся в первый терминал,
# чтобы создать пару виртуальных интерфейсов
cryptonite@cryptonite:~ $sudo ip link add veth0 type veth peer name ceth0
# активируем одну из виртуальных сторон и присваиваем ей IP-адрес
cryptonite@cryptonite:~ $sudo ip link set veth0 up
cryptonite@cryptonite:~ $sudo ip addr add 172.12.0.11/24 dev veth0
# создаем net namespace
root@cryptonite:~# unshare --net --kill-child /bin/bash
root@isolated:~# sleep 30
# находим PID изолированного процесса
cryptonite@cryptonite:~ $ps -fC sleep
UID PID PPID C STIME TTY TIME CMD
crypton+ 78625 78467 0 11:44 pts/0 00:00:00 sleep 30
# помещаем другую сторону в net namespace этого процесса
cryptonite@cryptonite:~ $sudo ip link set ceth0 netns /proc/78467/ns/net
# Вернемся к процессу в пространстве имен,
# активируем вторую сторону veth и также присваиваем ей IP-адрес
root@isolated:~# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: ceth0@if10: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 76:8d:bb:61:1b:f5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@isolated:~# ip link set lo up
root@isolated:~# ip link set ceth0 up
root@isolated:~# ip addr add 172.12.0.12/24 dev ceth0
# проверяем соединение
root@isolated:~# ping -c 1 172.12.0.11
PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data.
64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.079 ms
...Теперь создадим отдельные пространства имен PID и MNT, а затем отделим корневую файловую систему.
// создаем новые пространства имен PID и MNT
root@cryptonite:~/test# unshare --pid --mount --fork --kill-child /bin/sh
#
# mount | grep ext4
/dev/mapper/vgcryponite-lvcryptoniteroot on / type ext4 (rw,relatime,errors=remount-ro)
// у нас есть копия точки монтирования rootfs в mount namespace,
// делаем корневую файловую систему alpine монтируемой
# mount --bind rootfs_alpine rootfs_alpine
# cd rootfs_alpine
# pwd
/home/cryptonite/test/rootfs_alpine
# mkdir hostfs_root
# ls
bin dev etc home hostfs_root lib media mnt opt proc root run sbin srv sys tmp usr var
// изменяем точку монтирования текущей корневой файловой системы
# pivot_root . hostfs_root
# ls hostfs_root
bin dev lib libx32 mnt root snap tmp
boot etc lib32 lost+found opt run srv usr
cdrom home lib64 media proc sbin sys var
// на данном этапе у нас есть связывающая точка монтирования файловой системы хоста в новом mount namespace
# touch hostfs_root/home/cryptonite/test/hello
cryptonite@cryptonite:~ $ls hello -l
-rw-rw-r-- 1 cryptonite cryptonite 0 Jul 6 13:45 hello
# ps
PID USER TIME COMMAND
// так, вывода нет – дело в том, что новую procfs мы ищем в пустом каталоге proc образа alpine.
// Давайте смонтируем относительную procfs в каталог /proc файловой системы alpine
# mount -t proc proc /proc
# ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
12 root 0:00 psТеперь нам нужно полностью изолировать процесс внутри текущего каталога
alpine.// размонтируем старую корневую систему в процессе из mount namespace
# umount -l hostfs_root
# mount | wc -l
2
// у нас три точки монтирования – проверим верхнее mount namespace
cryptonite@cryptonite:~ $mount | wc -l
59
# cd /
# pwd
/
# whoami
root
# ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
20 root 0:00 ps
# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
# hostname
isolated
# ls hostfs_root/
// пустой каталог
# rmdir hostfs_root
# ls
bin etc lib mnt proc run srv tmp var
dev home media opt root sbin sys usrМы изолировали процесс, используя почти все пространства имен. Иными словами, мы создали очень примитивный контейнер. Однако в нем нет ограничения на использование ресурсов, которое устанавливается с помощью контрольных групп.
Заключение
Пространства имен – это очень мощный принцип ядра Linux, обеспечивающий изоляцию системных ресурсов. Это один из основных принципов, стоящих за созданием контейнеров, таких как известные Docker или LXC. Он обеспечивает ортогональность – то есть, все возможности, предоставляемые пространствами имен, могут использоваться независимо. Тем не менее пространства имен не устанавливают ограничения на использование процессом аппаратных ресурсов, это делается с помощью контрольных групп. Совмещение пространств имен, контрольных групп и возможностей позволяет нам создавать полностью изолированную среду.
Ссылки
- www.toptal.com/linux/separation-anxiety-isolating-your-system-with-linux-namespaces
- lwn.net/Articles/259217
- www.redhat.com/sysadmin/pid-namespace
- byteplumbing.net/2018/01/inspecting-docker-container-network-traffic
- opensource.com/article/19/10/namespaces-and-containers-linux
- iximiuz.com/en/posts/container-networking-is-simple
- ops.tips/blog/using-network-namespaces-and-bridge-to-isolate-servers
- www.cloudsavvyit.com/742/what-are-linux-namespaces-and-what-are-they-used-for
- lwn.net/Articles/532593
- lwn.net/Articles/689856
- www.redhat.com/sysadmin/7-linux-namespaces
- www.redhat.com/sysadmin/mount-namespaces
- ifeanyi.co/posts/linux-namespaces-part-3

