
▍ Введение
В эпоху больших языковых моделей (Large Language Model, LLM) и постоянно расширяющейся сферы их применений непрерывно растёт и важность текстовых данных.
Существует множество типов документов, содержащих подобные виды неструктурированной информации, от веб-статей и постов в блогах до рукописных писем и стихов. Однако существенная часть этих данных хранится и передаётся в формате PDF. В частности, выяснилось, что за каждый год в Outlook открывают более двух миллиардов PDF, а в Google Drive и электронной почте ежедневно сохраняют 73 миллионов новых файлов PDF (2).
Поэтому разработка более систематического способа обработки этих документов и извлечения из них информации позволит нам автоматизировать процесс и лучше понять этот обширный объём текстовых данных. И в выполнении этой задачи, разумеется, нашим лучшим другом будет Python.
Но прежде чем начать процесс, нам нужно определиться с различными типами современных PDF, и в частности, с тремя, используемыми наиболее часто:
- Программно генерируемые PDF: эти PDF создаются на компьютере или при помощи технологий W3C (HTML, CSS и Javascript), или при помощи другого ПО, например, Adobe Acrobat. Такой тип файла может содержать различные компоненты, например, изображения, текст и ссылки, по всем ним можно выполнять поиск и легко их редактировать.
- Традиционные отсканированные документы: такие PDF создаются из неэлектронных носителей при помощи сканера или мобильного приложения. Эти файлы являются просто набором изображений, сохранённых вместе в файл PDF. Поэтому элементы на изображениях, например, текст или ссылки, невозможно выбирать или выполнять по ним поиск. По сути, PDF служит контейнером для таких изображений.
- Отсканированные документы с OCR: в этом случае после сканирования документа применяется ПО для оптического распознавания символов (Optical Character Recognition, OCR), распознающее текст в каждом изображении файла и преобразующее его в текст с возможностью поиска по нему и редактирования. Затем ПО добавляет на изображение слой текста, благодаря чему при просмотре файла можно выбирать его как отдельный компонент. (3)
Даже несмотря на то, что сегодня всё больше машин имеет установленные системы OCR для распознавания текста в отсканированных документах, всё равно существуют документы, содержащие страницы в формате изображений. Вероятно, вы сталкивались с ними, когда читая отличную статью и попытавшись выделить предложение, выделяли всю страницу. Это может быть вызвано ограничениями конкретной машины с OCR или его полным отсутствием. Чтобы эта информация не осталась нераспознанной, я решил создать процесс, учитывающий подобные ситуации и извлекающий максимум информации из PDF.
▍ Теоретическое решение
Помня о перечисленных типах файлов PDF и различных составляющих их элементах, важно выполнить первоначальный анализ структуры PDF для определения подходящего инструмента, необходимого для каждого компонента. На основании результатов этого анализа мы будем применять соответствующий способ извлечения текста из PDF, будь то текстовый блок с метаданными, текст в изображениях или структурированный текст в таблицах. В отсканированных документах без OCR основную задачу будет выполнять методика выявления и извлечения текста из изображений. Результатом этого процесса станет словарь Python, содержащий информацию, извлечённую из каждой страницы файла PDF. Каждый ключ в этом словаре будет обозначать номер страницы документа, а соответствующее ему значение будет списком со пятью следующими вложенными списками, содержащими следующие данные:
- Текст, извлечённый из каждого текстового блока корпуса
- Формат текста в каждом текстовом блоке (тип и размер шрифта)
- Текст, извлечённый из изображений на странице
- Текст, извлечённый из таблиц в структурированном формате
- Полное текстовое содержимое страницы

Таким образом мы сможем обеспечить более логичное разделение извлечённого текста по исходным компонентам; к тому же это иногда может помочь нам проще извлекать информацию, обычно встречаемую в конкретном компоненте (например, название компании в изображении логотипа). Кроме того, извлечённые из текста метаданные, например, тип и размер шрифта, можно использовать для упрощения распознавания заголовков текста или важного выделенного текста, что позволит нам ещё сильнее разделить его или выполнять постобработку текста по отдельным блокам. Наконец, сохранение структурированной информации таблиц в понятном для LLM виде существенно повысит качество инференсов, которые модель будет делать о взаимосвязях внутри извлечённых данных. Далее эти результаты можно будет скомбинировать в вывод всей текстовой информации на каждой странице.
На рисунках ниже показана блок-схема этой методики.

▍ Установка всех необходимых библиотек
Перед началом этого проекта нам установить библиотеки. Будем предполагать, что у вас установлен Python 3.10 или более новая версия. В противном случае можно установить его отсюда. Затем установим следующие библиотеки:
PyPDF2: для считывания файла PDF по пути репозитория.
pip install PyPDF2Pdfminer: для выполнения анализа структуры и извлечения текста и формата из PDF. (Python 3 поддерживает версия .six библиотеки.)
pip install pdfminer.sixPdfplumber: для распознавания таблиц на странице PDF и извлечения информации из них.
pip install pdfplumberPdf2image: для преобразования обрезанного изображения PDF в изображение PNG.
pip install pdf2imagePIL: для чтения изображения PNG.
pip install PillowPytesseract: для извлечения текста из изображений при помощи технологии OCR
Её устанавливать немного сложнее, потому что сначала необходимо установить Google Tesseract OCR — платформу OCR, основанную на модели LSTM, которая занимается распознаванием линий и паттернов символов.
Для установки на машину Mac через Brew достаточно сделать следующее:
brew install tesseractПользователи Windows для установки библиотеки могут воспользоваться этой ссылкой. Затем после скачивания и установки ПО необходимо добавить пути к его исполняемым файлам в переменные окружения компьютера. Или же можно выполнить следующие команды, чтобы напрямую добавить их пути в скрипт Python:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'Затем можно установить библиотеку Python
pip install pytesseractНаконец, мы импортируем все библиотеки в начале нашего скрипта.
# Для считывания PDF
import PyPDF2
# Для анализа структуры PDF и извлечения текста
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
# Для извлечения текста из таблиц в PDF
import pdfplumber
# Для извлечения изображений из PDF
from PIL import Image
from pdf2image import convert_from_path
# Для выполнения OCR, чтобы извлекать тексты из изображений
import pytesseract
# Для удаления дополнительно созданных файлов
import osИтак, теперь всё готово, можно приступать к самому интересному.
▍ Анализ структуры документа при помощи Python

Для предварительного анализа мы воспользовались библиотекой Python PDFMiner, чтобы разделить текст из документа на несколько объектов страниц, а затем разбить и исследовать структуру каждой страницы. В файлах PDF отсутствует структурированная информация (абзацы, предложения и слова, воспринимаемые человеческим глазом). Они понимают только отдельные символы текста и их положение на странице. PDFMiner пытается воссоздать содержимое страницы в отдельных символах и их расположении на в файле. Затем, сравнивая расстояния этих символов от других, он собирает слова, предложения, строки и абзацы текста. (4) Чтобы добиться этого, библиотека:
Разделяет отдельные страницы из файла PDF при помощи высокоуровневой функции extract_pages() и преобразует их в объекты LTPage.
Затем для каждого объекта LTPage, она итеративно обходит каждый элемент сверху вниз и пытается идентифицировать один из соответствующих компонентов:
- LTFigure, обозначающий область PDF, которая может быть изображениями, встроенными в страницу как другой документ PDF.
- LTTextContainer, обозначающий группу текстовых строк в прямоугольной области, которая затем анализируется, превращаясь в список объектов LTTextLine. Каждый из них представляет собой список объектов LTChar, в которых хранятся отдельные символы текста вместе с их метаданными. (5)
- LTRect, обозначающий двухмерный прямоугольник, который можно использовать для задания рамок изображений или для создания таблиц в виде объекта LTPage.
Следовательно, на основании этого воссоздания страницы и классификации её элементов (LTFigure содержит изображения страницы, LTTextContainer содержит текстовую информацию страницы, LTRect является показателем наличия таблицы) мы можем применить соответствующую функцию, чтобы лучше извлекать информацию.
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Итеративно обходим элементы, из которых состоит страница
for element in page:
# Проверяем, является ли элемент текстовым
if isinstance(element, LTTextContainer):
# Функция для извлечения текста из текстового блока
pass
# Функция для извлечения формата текста
pass
# Проверка элементов на наличие изображений
if isinstance(element, LTFigure):
# Функция для преобразования PDF в изображение
pass
# Функция для извлечения текста при помощи OCR
pass
# Проверка элементов на наличие таблиц
if isinstance(element, LTRect):
# Функция для извлечения таблицы
pass
# Функция для преобразования содержимого таблицы в строку
passРазобравшись с аналитической частью процесса, давайте создадим функции, необходимые для извлечения текста из каждого компонента.
▍ Определяем функцию извлечения текста из PDF
После этого извлечение текста из контейнера текста становится очень простой задачей.
# Создаём функцию для извлечения текста
def text_extraction(element):
# Извлекаем текст из вложенного текстового элемента
line_text = element.get_text()
# Находим форматы текста
# Инициализируем список со всеми форматами, встречающимися в строке текста
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# Итеративно обходим каждый символ в строке текста
for character in text_line:
if isinstance(character, LTChar):
# Добавляем к символу название шрифта
line_formats.append(character.fontname)
# Добавляем к символу размер шрифта
line_formats.append(character.size)
# Находим уникальные размеры и названия шрифтов в строке
format_per_line = list(set(line_formats))
# Возвращаем кортеж с текстом в каждой строке вместе с его форматом
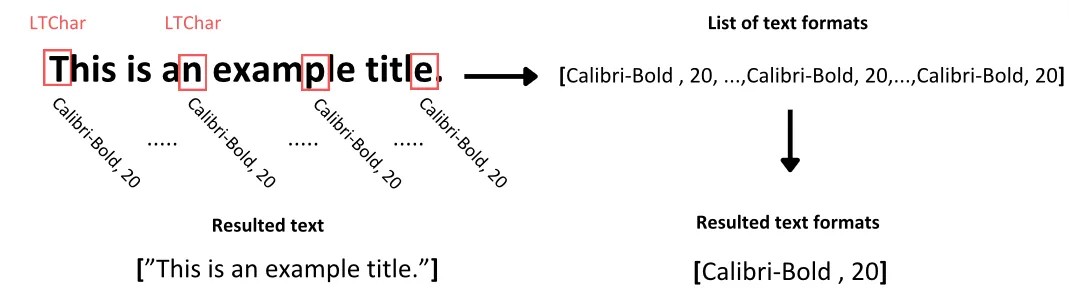
return (line_text, format_per_line)То есть чтобы извлечь текст из контейнера текста, мы просто используем метод get_text() элемента LTTextContainer. Этот метод получает все символы, из которых состоят слова в конкретном прямоугольнике корпуса, сохраняя вывод в список текстовых данных. Каждый элемент в этом списке представляет сырую текстовую информацию, содержащуюся в контейнере.
Теперь для определения формата текста мы итеративно обойдём объект LTTextContainer для получения доступа по отдельности к каждой строке текста в этом корпусе. На каждой итерации создаётся новый объект LTTextLine, обозначающий строку текста в этом блоке корпуса. Затем мы проверяем, содержит ли текст вложенный элемент строки. Если да, то мы получаем доступ к каждому отдельному символу как LTChar, который содержит все метаданные этого символа. Из этих метаданных мы извлекаем два типа форматов и сохраняем их в отдельном списке, расположенном в соответствии с исследуемым текстом:
- Тип шрифта символов, в том числе его полужирность или курсивность
- Размер шрифта символа
В общем случае символы внутри отдельного блока текста обычно имеют согласованное форматирование, если только некоторые из них не выделены полужирным. Чтобы упростить дальнейший анализ, мы находим уникальные значения форматирования текста для всех символов внутри текста и сохраняем их в соответствующий список.
▍ Определяем функцию для извлечения текста из изображений
Здесь всё будет несколько сложнее.
Как обрабатывать текст в изображениях, найденных в PDF?
Во-первых, нам нужно определить, что хранящиеся в PDF элементы изображений не отличаются по формату от файла, например, JPEG или PNG. В таком случае для применения к ним ПО OCR нам сначала нужно будет отделить их от файла, а затем преобразовать их в формат изображения.
# Создаём функцию для вырезания элементов изображений из PDF
def crop_image(element, pageObj):
# Получаем координаты для вырезания изображения из PDF
[image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1]
# Обрезаем страницу по координатам (left, bottom, right, top)
pageObj.mediabox.lower_left = (image_left, image_bottom)
pageObj.mediabox.upper_right = (image_right, image_top)
# Сохраняем обрезанную страницу в новый PDF
cropped_pdf_writer = PyPDF2.PdfWriter()
cropped_pdf_writer.add_page(pageObj)
# Сохраняем обрезанный PDF в новый файл
with open('cropped_image.pdf', 'wb') as cropped_pdf_file:
cropped_pdf_writer.write(cropped_pdf_file)
# Создаём функцию для преобразования PDF в изображения
def convert_to_images(input_file,):
images = convert_from_path(input_file)
image = images[0]
output_file = "PDF_image.png"
image.save(output_file, "PNG")
# Создаём функцию для считывания текста из изображений
def image_to_text(image_path):
# Считываем изображение
img = Image.open(image_path)
# Извлекаем текст из изображения
text = pytesseract.image_to_string(img)
return textЧтобы добиться этого, мы выполняем следующий процесс:
- Применяем метаданные из объекта LTFigure, обнаруженного из PDFMiner, чтобы обрезать прямоугольник изображения, используя его координаты в структуре страницы. Затем сохраняем его как новый PDF в нашу папку при помощи библиотеки PyPDF2.
- Затем используем функцию convert_from_file() из библиотеки pdf2image для преобразования всех файлов PDF в папке в список изображений, сохраняя их в формат PNG.
- Наконец, теперь, когда у нас есть файлы изображений, мы считываем их в нашем скрипте при помощи пакета Image модуля PIL и реализуем функцию image_to_string() библиотеки pytesseract, чтобы извлечь текст из изображений при помощи движка OCR tesseract.
В результате этот процесс возвращает нам текст из изображений, который мы сохраняем в третий список в выходном словаре. Этот список содержит текстовую информацию, извлечённую из изображений на исследуемой странице.
▍ Определяем функцию для извлечения текста из таблиц
В этом разделе мы будем извлекать более логически структурированный текст из таблиц на странице PDF. Это чуть более сложная задача, чем извлечение текста из корпуса, потому что нам нужно учитывать дробность информации и взаимосвязи между примерами данных, представленными в таблице.
Хотя существует множество библиотек для извлечения из PDF табличных данных (самая популярная из них — это Tabula-py), мы выявили в их функциональности определённые ограничения.
На наш взгляд, самое очевидное из них — это то, что библиотека помечает разные строки в таблице при помощи специальным символом разрыва строки \n в тексте таблицы. В большинстве случаев это работает достаточно неплохо, но не позволяет распознать таблицу правильно, когда текст в ячейке разделён на две или более строки, что приводит к добавлению ненужных пустых строк и потере контекста извлечённой ячейки.
Ниже показан пример этого при попытке извлечения данных из таблицы при помощи tabula-py:

Кроме того, извлечённая информация выводится в Pandas DataFrame, а не в строку. В большинстве случаев этот формат может быть предпочтительным, но в случае трансформеров, работающих с текстом, перед отправкой в модель эти результаты необходимо преобразовывать.
Поэтому для выполнения этой задачи мы использовали библиотеку pdfplumber. Во-первых, она создана на основе pdfminer.six, которую мы уже использовали для предварительного анализа, то есть она содержит схожие объекты. Кроме того, её методика распознавания таблиц основана на элементах строк и их пересечениях, составляющих ячейку, содержащую текст, а затем и саму таблицу. Благодаря этому после определения ячейки таблицы мы можем извлечь только содержимое внутри ячейки, не перенося информацию о том, сколько строк должно рендериться. Получим содержимое таблицы, мы сформатируем его в напоминающую таблицу строку и сохраним в соответствующий список.
# Извлечение таблиц из страницы
def extract_table(pdf_path, page_num, table_num):
# Открываем файл pdf
pdf = pdfplumber.open(pdf_path)
# Находим исследуемую страницу
table_page = pdf.pages[page_num]
# Извлекаем соответствующую таблицу
table = table_page.extract_tables()[table_num]
return table
# Преобразуем таблицу в соответствующий формат
def table_converter(table):
table_string = ''
# Итеративно обходим каждую строку в таблице
for row_num in range(len(table)):
row = table[row_num]
# Удаляем разрыв строки из текста с переносом
cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row]
# Преобразуем таблицу в строку
table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n')
# Удаляем последний разрыв строки
table_string = table_string[:-1]
return table_stringЧтобы сделать это, мы создали две функции, extract_table() для извлечения содержимого таблицы в список списков, и table_converter(), для объединения содержимого этих списков напоминающую таблицу строку.
В функции extract_table():
- Мы открываем файл PDF.
- Переходим к исследуемой странице файла PDF.
- Из списка таблиц, найденных на странице библиотекой pdfplumber, мы выбираем нужную нам.
- Извлекаем содержимое таблицы и выводим его в список вложенных списков, представляющих собой каждую строку таблицы.
В функции table_converter():
- Мы итеративно обходим каждый вложенный список и очищаем его содержимое от ненужных разрывов строк, возникающих из-за текста с переносами.
- Объединяем каждый элемент строки таблицы, разделяя их символом | для создания структуры ячейки таблицы.
- Наконец, мы добавляем разрыв строки в конце, чтобы перейти к следующей строке таблицы.
В результате этого мы получаем строку текста, описывающую содержимое таблицы без потери дробности представленных в ней данных.
▍ Соединяем всё вместе
Теперь, когда все компоненты кода готовы, давайте объединим их, чтобы получить полнофункциональный код. Можете скопировать код отсюда или найти его с примером PDF в моём репозитарии Github здесь.
# Находим путь к PDF
pdf_path = 'OFFER 3.pdf'
# создаём объект файла PDF
pdfFileObj = open(pdf_path, 'rb')
# создаём объект считывателя PDF
pdfReaded = PyPDF2.PdfReader(pdfFileObj)
# Создаём словарь для извлечения текста из каждого изображения
text_per_page = {}
# Извлекаем страницы из PDF
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Инициализируем переменные, необходимые для извлечения текста со страницы
pageObj = pdfReaded.pages[pagenum]
page_text = []
line_format = []
text_from_images = []
text_from_tables = []
page_content = []
# Инициализируем количество исследованных таблиц
table_num = 0
first_element= True
table_extraction_flag= False
# Открываем файл pdf
pdf = pdfplumber.open(pdf_path)
# Находим исследуемую страницу
page_tables = pdf.pages[pagenum]
# Находим количество таблиц на странице
tables = page_tables.find_tables()
# Находим все элементы
page_elements = [(element.y1, element) for element in page._objs]
# Сортируем все элементы по порядку нахождения на странице
page_elements.sort(key=lambda a: a[0], reverse=True)
# Находим элементы, составляющие страницу
for i,component in enumerate(page_elements):
# Извлекаем положение верхнего края элемента в PDF
pos= component[0]
# Извлекаем элемент структуры страницы
element = component[1]
# Проверяем, является ли элемент текстовым
if isinstance(element, LTTextContainer):
# Проверяем, находится ли текст в таблице
if table_extraction_flag == False:
# Используем функцию извлечения текста и формата для каждого текстового элемента
(line_text, format_per_line) = text_extraction(element)
# Добавляем текст каждой строки к тексту страницы
page_text.append(line_text)
# Добавляем формат каждой строки, содержащей текст
line_format.append(format_per_line)
page_content.append(line_text)
else:
# Пропускаем текст, находящийся в таблице
pass
# Проверяем элементы на наличие изображений
if isinstance(element, LTFigure):
# Вырезаем изображение из PDF
crop_image(element, pageObj)
# Преобразуем обрезанный pdf в изображение
convert_to_images('cropped_image.pdf')
# Извлекаем текст из изображения
image_text = image_to_text('PDF_image.png')
text_from_images.append(image_text)
page_content.append(image_text)
# Добавляем условное обозначение в списки текста и формата
page_text.append('image')
line_format.append('image')
# Проверяем элементы на наличие таблиц
if isinstance(element, LTRect):
# Если первый прямоугольный элемент
if first_element == True and (table_num+1) <= len(tables):
# Находим ограничивающий прямоугольник таблицы
lower_side = page.bbox[3] - tables[table_num].bbox[3]
upper_side = element.y1
# Извлекаем информацию из таблицы
table = extract_table(pdf_path, pagenum, table_num)
# Преобразуем информацию таблицы в формат структурированной строки
table_string = table_converter(table)
# Добавляем строку таблицы в список
text_from_tables.append(table_string)
page_content.append(table_string)
# Устанавливаем флаг True, чтобы избежать повторения содержимого
table_extraction_flag = True
# Преобразуем в другой элемент
first_element = False
# Добавляем условное обозначение в списки текста и формата
page_text.append('table')
line_format.append('table')
# Проверяем, извлекли ли мы уже таблицы из этой страницы
if element.y0 >= lower_side and element.y1 <= upper_side:
pass
elif not isinstance(page_elements[i+1][1], LTRect):
table_extraction_flag = False
first_element = True
table_num+=1
# Создаём ключ для словаря
dctkey = 'Page_'+str(pagenum)
# Добавляем список списков как значение ключа страницы
text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]
# Закрываем объект файла pdf
pdfFileObj.close()
# Удаляем созданные дополнительные файлы
os.remove('cropped_image.pdf')
os.remove('PDF_image.png')
# Удаляем содержимое страницы
result = ''.join(text_per_page['Page_0'][4])
print(result)Приведённый выше скрипт выполняет следующие действия:
Импортирует необходимые библиотеки.
Открывает файл PDF при помощи библиотеки pyPDF2.
Извлекает каждую страницу в PDF и итеративно выполняет следующие этапы.
Определяет, есть ли на странице таблицы и создаёт их список при помощи pdfplumner.
Находит все вложенные в страницу элементы и сортирует в порядке их нахождения в структуре страницы.
Затем для каждого элемента:
Проверяет, текстовый ли это контейнер, и не встречается ли он в табличном элементе. Затем использует функцию text_extraction() для извлечения текста с его форматом, в противном случае пропускает этот текст.
Проверяет, изображение ли это, и использует функцию crop_image() для вырезания компонента изображения из PDF, преобразует его в файл изображения при помощи convert_to_images() и извлекает из него текст при помощи OCR функцией image_to_text().
Проверяет, прямоугольный ли это элемент. Если да, то проверяет, является ли первый прямоугольник частью таблицы на странице, и если да, то переходит к следующим этапам:
- Находит ограничивающий прямоугольник таблицы, чтобы не извлекать этот текст заново при помощи функции text_extraction().
- Извлекает содержимое таблицы и преобразует его в строку.
- Добавляет двоичный параметр, чтобы указать, что мы извлекаем текст из таблицы.
- Этот процесс завершится после последнего LTRect, относящегося к ограничивающему прямоугольнику таблицы, когда следующий элемент в структуре страницы не является прямоугольным объектом. (Все остальные объекты, составляющие таблицу, будут пропущены)
Результаты процесса сохраняются в 5 списков на каждую итерацию, а именно:
- page_text: содержит текст, взятый из текстовых контейнеров в PDF (если текст был извлечён из другого элемента, здесь будет сохранено условное обозначение)
- line_format: содержит форматы извлечённого выше текста (если текст извлечён из другого элемента, здесь будет сохранено условное обозначение)
- text_from_images: содержит тексты, извлечённые из изображений на странице
- text_from_tables: содержит напоминающую таблицу строку с содержимым таблиц
- page_content: содержит в списке элементов весь текст, рендерящийся на странице
Все списки сохраняются под ключами в словаре, описывающими номер страницы, исследуемой каждый раз.
Затем мы закрываем файл PDF и удаляем все дополнительные файлы, созданные в процессе работы.
Наконец, мы можем отобразить содержимое страницы, объединив элементы в списке page_content.
▍ Заключение
Мне кажется, эта методика использует наилучшие характеристики многих библиотек и делает процесс адаптируемым к различным типам PDF и видам встречаемых элементов, однако основную часть работы выполняет PDFMiner. Кроме того, информация о формате текста может помочь нам в выявлении возможных заголовков, которые разделяют текст на отдельные логические блоки, а не просто содержимого страницы, и идентифицировать текст повышенной важности.
▍ Ссылки:
- https://www.techopedia.com/12-practical-large-language-model-llm-applications
- https://www.pdfa.org/wp-content/uploads/2018/06/1330_Johnson.pdf
- https://pdfpro.com/blog/guides/pdf-ocr-guide/#:~:text=OCR technology reads text from, a searchable and editable PDF.
- https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#id1
- https://github.com/pdfminer/pdfminer.six
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх 🕹️

