Тема виртуальной, дополненной реальности, метавселенных набирает обороты. Но что это такое, как должно выглядеть, как этим пользоваться, никто толком пока не знает. Однако, как в своё время переход от десктопных приложений к мобильным, миграция в VR принесёт и новые паттерны взаимодействия с пользователем. Да, в виртуальной реальности уже можно «потрогать» предметы, но этого недостаточно для полноценного решения пользовательских задач. Кажется, что голосовое управление в VR станет ещё более актуальным, чем в мобильных устройствах — в виде, например, голосовых команд или ввода текстовых данных.
Ниже опишу пошагово, как можно добавить голосовое управление на русском языке в VR-проект.
Но для начала давайте проговорим подробнее, чем полезны технологии распознавания речи в VR:
Уже шесть лет назад исследователи пришли к выводу, что голосовой ввод в три раза быстрее и более точен, чем ручной с помощью клавиатуры смартфона. Для VR-устройств это особенно актуально.
Кроме того, для голосового ввода смартфон не нужно держать в руках и подносить к голове. VR-устройства уже находятся на голове, и голосовой ввод выглядит более естественно.
В VR-проектах мы больше погружены в виртуальный мир. Взаимодействие с этим миром должно быть похоже на наше взаимодействие с реальным. Управление голосом этому способствует больше, чем выбор пунктов меню с помощью игровых контроллеров.
Единые паттерны взаимодействия с пользователем ещё не сформировались. Для людей, только начинающих пользоваться VR-устройствами, наиболее интуитивно понятными могут стать именно голосовые интерфейсы.
Перейдём непосредственно к практике.
Выбор инструментов
Большинство программистов для своих VR-проектов используют Unity. Также есть мнение, что 90% компаний-разработчиков для AR/VR используют C#. Но это какое-то странное заявление, на чём оно основывается, я так и не нашёл. Возможно, это было написано в каком-нибудь древнем пресс-релизе от Unity. Тем не менее, в свежей статье на Forbes указано, что 72% из топ 1000 мобильных приложений сделаны на Unity, что похоже на правду. Ну и вдобавок, там же упоминается AR/VR/XR, Metaverse, Web3, и всё, что сейчас модно.
Со средой разработки определились, теперь нужно выбрать сервис распознавания русской речи для нашего голосового управления. Что нам нужно от сервиса распознавания речи? Прежде всего, распознавание должно быть потоковым. Чтобы не ждать окончания фразы и самим не решать задачу определения конца фразы. И тут к нам на помощь приходит SmartSpeech. Плюсом является и то, что в нём есть и частичное распознавание по ещё не законченной фразе.
Что такое SmartSpeech? Это платформа речевых сервисов, разработанная командой SberDevices. Технологии распознавания речи (ASR) и синтеза речи (TTS) SmartSpeech используются, например, в нашем семействе виртуальных ассистентов Салют, а также в проектах сторонних разработчиков. Протестировать распознавание речи от SmartSpeech можно с помощью телеграм-бота, о котором мы уже писали на Хабре.
Ну и наконец, тестировать наше голосовое управление мы будем с помощью Oculus Quest 2, самой продаваемой VR-гарнитуры в данный момент.
Подключаем сервис распознавания
Прежде всего нужно подключить сервис SmartSpeech. И после получения Client Id и Client Secret, можно протестировать работу сервиса.

Для отправки запросов сервису распознавания речи, сначала получим токен для аутентификации.
Для этого:
Подготовим авторизационные данные — закодируем в Base 64 строку вида:
<Client ID>:<Client Secret>.Cгенерируем RqUID, например:
uuidgen | tr 'A-Z' 'a-z'И пошлём запрос на получение токена от сервиса:
curl --location --request POST "https://salute.online.sberbank.ru:9443/api/v2/oauth" \
--header "Authorization: Basic <Your Base64 encoded credentials>" \
--header "RqUID: <Your RqUID>" \
--header "Content-Type: application/x-www-form-urlencoded" \
--data-urlencode "scope=SBER_SPEECH"Должен прийти json вида: {"access_token":"","expires_at":}
Все готово к работе. Чтобы протестировать распознавание речи, можно послать в сервис файл с аудиозаписью. Для этого нам понадобится подготовленный заранее файл и только что полученный токен для аутентификации.
curl -X POST \
-H "Authorization: Bearer <token>" \
-H "Content-Type: audio/x-pcm;bit=16;rate=16000" \
--data-binary @./audio.pcm \
https://smartspeech.sber.ru/rest/v1/speech:recognizeРаспознавание в Unity
Но нас интересует потоковое распознавание в Unity. Работа с сервисом осуществляется по протоколу gRPC. gRPC — это кроссплатформенная и кроссязыковая система удалённого вызова процедур (RPC). Работает она поверх HTTP/2, в качестве языка описания интерфейса используется Protobuf.
Сами .proto-файлы, как и примеры для работы со SmartSpeech на других языках программирования, можно взять в документации.
Для начала нужно сгенерировать клиентский код на C# для работы по gRPC. Например, про помощи утилиты protoc:
mkdir -p grpc/client
protoc -I ./smartspeech-master/recognition/v1/ \
-I ./smartspeech-master/task/v1/ \
--csharp_out=grpc/client \
--grpc_out=grpc/client \
--plugin=protoc-gen-grpc=/usr/local/bin/grpc_csharp_plugin \
recognition.proto {storage,task}.protoДалее для Unity нужно скачать необходимые библиотеки, например, из проекта gRPC.io. Правда, поддержка Unity там обозначена как «experimental».
На странице загрузок находим нужный нам пакет для Unity. В нашем случае это grpc_unity_package.2.47.0-dev202204190851. Файлы библиотеки, как и сгенерированный клиентский код для gRPC переносим в свой Unity проект:
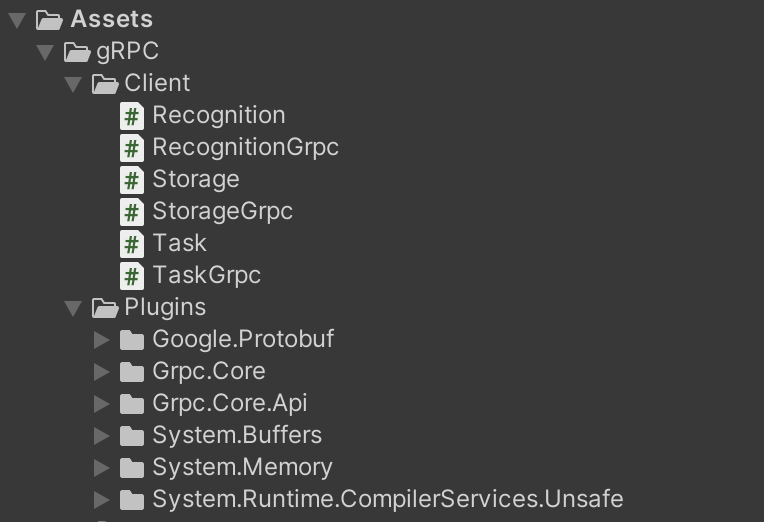
И наконец нужно написать клиентский код, который будет передавать данные в SmartSpeech по gRPC. Весь пример кода можно скачать по ссылке. Здесь же отметим основные моменты.
Подключаем необходимые библиотеки:
using Grpc.Core;
using Smartspeech.Recognition.V1;Объекты, которые используются для взаимодействия по gRPC:
Channel _channel =
new Channel(address,
ChannelCredentials.Create(new SslCredentials(), credentials));
SmartSpeech.SmartSpeechClient _client =
new SmartSpeech.SmartSpeechClient(_channel);
RecognitionOptions _options = new RecognitionOptions();
_options.SampleRate = _sampleRate;
_options.AudioEncoding = RecognitionOptions.Types.AudioEncoding.PcmS16Le;Токен для аутентификации мы просто получаем по http. Данные же для распознавания мы забираем с микрофона и передаём по gRPC. Причём, прежде чем начать отправку данных, нужно первым запросом послать опции распознавания:
var call = _client.Recognize();
var streamRequest = new RecognitionRequest();
streamRequest.Options = _options;
await call.RequestStream.WriteAsync(streamRequest);И затем уже в цикле данные с микрофона:
audioSource.clip.GetData(samples, curDataIndex);
curDataIndex += bufferSize;
if (curDataIndex >= audioSource.clip.samples)
curDataIndex = 0;
buffer = GetSamplesWaveData(samples, bufferSize);
streamRequest.AudioChunk = Google.Protobuf.ByteString.CopyFrom(buffer);
await call.RequestStream.WriteAsync(streamRequest);Асинхронно забираем результаты распознавания:
var response = call.ResponseStream.Current;
bool eou = response.Eou;
var results = response.Results;
string text = results[0].Text;
string normalizedText = results[0].NormalizedText;Готовое приложение
В результате у нас должно получиться что-то похожее на видео. Демо-проект в Unity под Oculus Quest 2 можно скачать по ссылке.
Регистрируйтесь в сервисе SmartSpeech, пробуйте, создавайте свои приложения. Если у вас есть какие-нибудь вопросы, оставляйте в комментариях, постараемся оперативно на них ответить.
Возможно, внимание, которое привлекает сейчас тема метавселенных и виртуальной реальности, слишком раздуто. Тем не менее, всё больше и больше компаний начинает этим заниматься. Международная консалтинговая компания выпустила отчёт, в котором отмечает большой потенциал концепции метавселенной. Она прогнозирует, что к 2030 году рынок будет оцениваться в $5 трлн. Так что можно уже сейчас начинать идти в этом направлении.
