Комментарии 26
Резервные копии рекомендуется сразу скачивать с сервера и сохранять в надежном месте, например, в нашем облачном хранилище.
А можно подключить удаленное хранилище к Proxmox и сразу на него лить бэкап.
2. При клонировании виртуальной машины что бы не играться со сменой айпи на исходной — есть возможность перед включением склонированной виртуальной машины — отключить у неё доступ к сети поставив в настройках сетевого интерфейса виратульной машины галочу Disconnect, загрузиться, через консоль зайти на нее и поменять на нужный iр и после этого вернуть свежей виртуальной машине доступ к сети.
3. С 6ой ветки есть возможность не мучаться с настройкой бэкапа для каждой виртуальной машины в отдельности, а делать бэкапы на основе пулов виртуальных машин, это намного удобней.
А можно подключить удаленное хранилище к Proxmox и сразу на него лить бэкап.С точки зрения безопасности правильнее чтобы не резервируемый закачивал бэкапы на сервер, а сам сервер забирал бэкапы с резервируемого. В первом варианте в случае взлома (или банального rm -rf /, если речь про примонтированное в файловую систему хранилище) можно потерять всё сразу.
А можно подключить удаленное хранилище к Proxmox и сразу на него лить бэкап.
Это оправдано, если удаленное хранилище быстрое. Или не слишком важно время простоя. Ведь в режиме snapshop производительность падает, а в suspend и stop вм вообще простаивает.
Начнем с того, что Proxmox имеет неплохой штатный инструментарий для создания резервных копий виртуальных машин.
Если VM маленькие и их мало — да, неплохой. Как только их размеры начинаются от сотен гигабайт (не говоря уже про терабайты) — то создание резервных копий напрочь убивает производительность (особенно если пытаться сделать дифференциальный бэкап), иногда от нескольких часов до суток.
А теперь возьмите узел с десятком нагруженных VM по 300-400 гиг в каждой, на обычых (не SSD) дисках, попробуйте делать ежедневные бэкапы и начинайте плакать глядя как всё тормозит.
Боюсь предположить, что в предложенном Вами сценарии иные гипервизоры тоже звёзд с неба хватать не будут.
Думаю логичным выходом при наличии таких вводных будет использование внешних хранилищ данных или чего-нибудь другого. Кстати proxmox очень неплохо дружит с ceph. (https://pve.proxmox.com/wiki/Ceph_Server)
Сабж очень хорош контейнерами lxc, а их нарастить до нескольких Тб надо постараться, а, в свою очередь, маленькие контейнеры резервировать описанными автором средствами одно удовольствие
Для Windows VM можно использовать средства которые отслеживают изменения в блоках устройств (Acronis/Macrium/etc), соответственно не пытаясь копировать всё каждый раз.
Проблема с vzdump именно в том что он «тупой» — копирует либо весь блочный файл (если это не Linux), либо сравнивает старый tar с текущим состоянием перед созданием инкрементального бэкапа.
Когда речь заходит об windows — это совсем другая «парафия», где софт от MS и средства его бекапа заточены специально под них и в большинстве случаев за деньги. Потому человеку стоит всегда составить список "+" и "-" за тот или иной инструмент, а потом еще почитать опыт использования, что бы сложилось впечатление и сделать верный выбор.
Proxmox Backup Server использовать не пробовали?
Самая большая проблема это отсутствие энкриментальных и отсутствие нормальной возможности достать один файл.
А раз в год бекап превращающийся в зомби с la 60- святое дело.....
На самом деле это выглядит как инструкция по установке MS Office (например): тысяча параметров, но всем интуитивно понятна.
Лучше б описали тонкости работы, это все же хабр. Например, развертывание ВМ с имеющегося образа, восстановление ВМ из бэкапа другого Proxmox, простейший кластер
Тонкостей нет, т/к прилично багов и нужно тупо разбираться, в конце года у меня группа серверов перегружалась переодически бессимптомно, аля ресет, на форуме кроме обновлений нашли подобное поведение изза ha, lacp и т/д и т/п
Ну и стоит ли говорить что даже без ha если не собрался кворум (короче вылетели 3 ноды) у вас виртуалки не подымутся
Ну и кучу ошибок у проксмокса закрывается фразой решено в следующих релизах, за 5 лет таких багов штук 20 было
Увы, но бекапить таким образом сервера баз данных не получится — данные из памяти будут записаны не полностью на диск.
Такие виртуалки приходится специальным образом приостанавливать.
Для mysql — переводить сервер в режим read-only.
Остальных — просто останавливать.
Плюс тупой бекап в текстовый SQL-файл.
Сам бекап делать в 2 прохода: первый rsync, приостановить БД, ВМ в suspend, второй rsync, ВМ в resume, отпустить БД.
Такое прокатывает с небольшими виртуалками на OpenVZ / LXC.
Как безопасно для данных сворачивать виртуалки в KVM, и тем более с Windows — пока не придумал.
https://github.com/ayufan/pve-patches
Неужели вы обошли стороной эти чудесные патчи?
«Датацентр» ➜ «Хранилище»
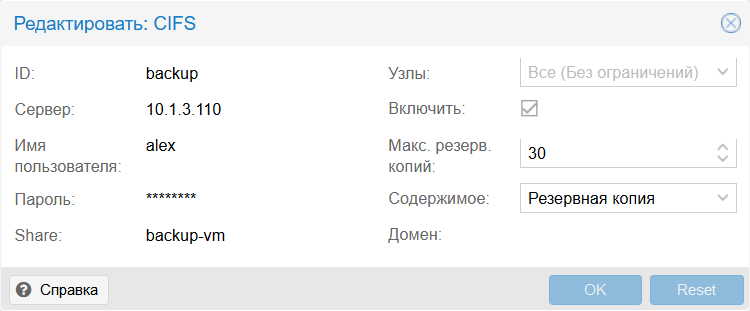
Лично у меня стоит режим «Остановка». Не вижу в этом ничего плохого, а вот битые бэкапы в режиме «Снимок» уже были.
P.S. Мне кажется, что ссылки на официальную WiKi чуть более полезны.
Есть ли способ бекапа vm если на диске есть ошибки чтения? У меня бекап завершается с ошибкой io read error. Команда dd имеет опцию noerror а есть ли что тут подобное? Ошибки возникают только вовремя бекапа. На диске эти данные судя по всему несущественные так как при обычной работе вм ошибок нет
Про бэкапы в Proxmox VE