Данная статья не претендует на то, чтобы быть универсальным рецептом, мы постараемся в ней описать те проблемы, с которыми мы столкнулись, и их решения в проекте, который нам достался после 3 других команд.
Вначале коротко опишем суть проекта. Есть доктора в клиниках, которые на специальные устройства надиктовывают информацию о пациенте и его визите. Затем эта информация переводится в текстовый вид (за это отвечает специальное подразделение, сотрудники которого слушают и набирают текст), текст проверяется, происходит заполнение шаблона. Потом происходит движение по Workflow, который включает в себя разные стадии с различной бизнес-логикой, потом происходит интеграция с несколькими внешними системами. И, наконец, печатается письмо пациенту и отсылается. А работа через некоторое время архивируется (но при этом она может быть восстановлена по необходимости).
При этом часть Workflow может выполняться на iPad, есть специальная часть для настроек системы и workflow, также есть специальная часть для редактирования и утверждения документов в браузере. Но основная часть работы производится на локальной машине пользователя, которая находится в госпитале.
Также есть обязательное условие, что данные не могут потеряться. Поэтому на локальной машине пользователя все хранится в БД MySQL, данные из которой синхронизируются с основным сервером.
Специфика проекта – область здравоохранения в одной западноевропейской стране. Также этот программный комплект развернут более чем в 10 клиниках, каждая из которых имеет некоторую уникальную специфику. Также, чтобы уговорить клинику на новую версию, надо довольно много времени: сначала надо развернуть на тестовый сервер клиники, потом они тестируют в течение 3х недель, потом происходит разворачивание на живой сервер.
Также в базах данных находится конфиденциальная информация о пациентах, поэтому у каждой клиники свой сервер (и как показала практика, уговорить их купить новый винт – уже проблема).
Что мы получили?
Как вы понимаете, от 3 предыдущих команд отказались не из-за их высокого качества работы. Мы получили примерно 400.000 строк исходного кода на C# (+ еще несколько внешних библиотек). Часть исходных кодов была потеряна. Отсутствие документации. Отсутствие тестов. Отсутствие тестовых данных. Отсутствие человека со стороны заказчика, который знал бы все о системе (человека, который был бы с момента создания проекта). Код был написан так, что покрывать его unit тестами было невозможно. БД примерно из 120 таблиц, Проблемы с производительностью, Использование ADO.NET, Dapper, LINQ, Entity Framework 4 для взаимодействия с БД. База данных MS SQL.
Часть архитектуры приложения:
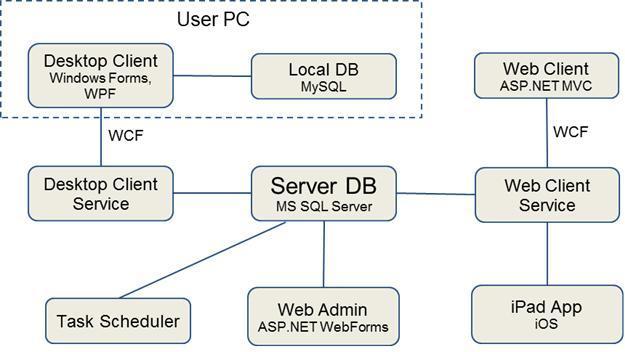
Небольшое пояснение об изображенных частях системы:
Некоторые цифры:
В неделю (полтора года назад) в сумме обрабатывалось 5000 работ. Под обработкой работы понимается прохождение по всем необходимым стадиям, выполнение взаимодействия со всеми внешними сервисами и т.д.
Что у нас есть сейчас (основные достижения через 1,5 года)?
Производительность приложения в некоторых операциях возросла в 10-12 раз, Количество одновременных пользователей увеличилось в 5 раз, количество обрабатываемых работ в неделю достигло 30.000, заказчик стал спокойным
И опишем некоторые проблемы (и то, что мы сделали, что бы их преодолеть), с которыми мы столкнулись.
1 проблема: как доказать заказчику, что все плохо?
Как вы понимаете, заказчик видит, что программа работает, что она может обрабатывать задачи. И доказать, что «под капотом» у этой системы все работает или с костылями, или на пределе – проблематично. И связанная с этим проблема: как показать заказчику, что система улучшается?
Один из вариантов, который в конечном счете выбрали, – использование системы NDepend. Это система статического анализа кода. Причем весьма хорошая. Что особенно в ней понравилось – наличие около 150 стандартных правил.
Очень полезными из них были правила нахождения мертвого кода – не используемые классы и методы. В 90% случаев они были верны, но были и ошибки. Говорили, что конструкторы по умолчанию не используются и операторы неявного преобразования не нужны. На самом деле они были нужны.
Также положительное впечатление оставила скорость работы – анализ получившихся 40 библиотек проходил в течение 4-6 секунд. Также легкость интеграции с Continuous Integration (хотя этим уже мало кого удивишь). Еще полезным был график зависимостей, который может строить NDepend. Когда его показали заказчику, это было очень хорошим обоснованием времени, которого потребовалось на реализацию одной из фич.
Еще любопытная фича NDepend – создание своих правил для анализа кода. Хотя лично нам она не пригодилась, стандартных правил хватает. В то же время из-за того, что проект был унаследованным, мы изменили стандартные правила (так, чтобы они проходили), сделали их критическими (если они нарушаются, что Continious Integration тогда выдает сообщение об этом). А потом постепенно повышали порог «качества» кода.
Еще очень полезная функция – сравнение с предыдущими результатами анализа и нахождение разницы.
Какие выводы сделали по этой проблеме: NDepend имеет очень хорошие возможности, строит много красивых графиков, расширяем. После того, как заказчик стал видеть графики, он стал более спокойным: он видел прогресс.
2 проблема: конфиденциальность данных.
Клиники работают с реальными пациентами, и данные о них являются конфиденциальными. Более того, они находятся на серверах клиник. В эти данные включались аудио файлы с диктовками докторов, официальные документы и т.д.
Для более качественного тестирования нам необходима была копия этой БД. Но из-за конфиденциальных данных госпитали не горели желанием отдавать эти данные.
Поэтому была написана программа анонимизации, которая заменяет все буквы в документах на единицы, заменяет все содержимое аудио на массив из нулей, заменяет все имена на Name 1, Name 2 и т.д.
Реализация этой программы заняла примерно 3 дня. После этого была создана копия живой БД, которая подверглась анонимизации.
В чем была ошибка? Не учли, что она будет долгой (как оказалась, чистое время анонимизации было около 5 дней). Анонимизация создавала доп. нагрузку на тот же самый физический диск, на котором была живая БД, что создало проблемы. К счастью, мы на всякий случай мониторили и при получении первых признаков большой очереди на чтение с диска остановили программу анонимизации.
После этого добавили в нее функции, чтобы она могла продолжать анонимизацию БД после прерывания и стали запускать только ночью.
Какие выводы сделали по этой проблеме: конфиденциальные данные – очень большая проблема. Как показало дальнейшее использование, выгоды от такого решения были не особо большими, потому что у разных госпиталей были разные бизнес-процессы и структура данных иногда сильно отличалась. Хотя несомненно, использование анонимизированной БД дало кратковременные плюсы и частично успокоило заказчика, потому что он понимал, что это была копия реальных данных, и это было хорошим доказательством того, что новые модули будут работать с предсказуемой скоростью на реальных данных.
3 проблема: код, который написан не для тестирования.
Унаследованный код, который надо расширять, при этом не поломав? Казалось бы, что проще – использовать unit тесты и радоваться жизни. Однако качество унаследованного кода было очень низкое. И как показала практика, этот код не был написан для тестирования (синглетоны, использование старой Entity Framework, которая не подходит для тестирования). Но в то же время, необходимо было создавать для него тесты. И мы выбрали путь создания интеграционных тестов. А новые фичи старались писать так, чтобы их можно было покрывать unit-тестами.
Для написания интеграционных тестов мы создали одну доп. утилиту и функцию восстановления БД. Т.о. программисту надо было привести программу перед тестируемым действием, потом запустить утилиту сохранения данных. А потом вызвать в начале теста восстановление БД с указанием пути к восстановленным данным. Утилита сохранения данных просто проходилась по всем таблицам, которые есть в БД, и сохраняла данные из них в XML. После этого функция восстановления динамически создавала новую БД, восстанавливала данные в ней и изменяла строки подключения так, чтобы тесты видели эту новую БД. Для восстановления данных использовали формирование команды вставки и использование ADO.NET для выполнения команды, что дало нам независимость от Entity Framework и т.д. Как положительное следствие – теперь эту утилиту легко перенести на любой другой язык.
Как показала практика, если правильно подготовить БД, то восстановление занимает 1 секунду. А с учетом того, что в CI были ночные тесты, это была приемлемая величина.
А потом еще эта утилита прижилась у тестировщиков, когда они начали делать тестирование с помощью Ranorex – добавили аргументы командной строки и начали использовать для восстановления БД и там.
Какие выводы мы сделали по этой проблеме:
4 проблема: счетчики производительности на целевой машине.
Также актуален вопрос, который у нас возник в течение года – как показать состояние системы, которая была унаследована, и то, что она постепенно начинает не выдерживать нагрузок? Одно из самых эффективных средств – собирать счетчики производительности с интервалом в неделю. Счетчиков реально много, они дают хорошие графики, их можно экспортировать в Excel, производить анализ и т.д. Жалко только, что мы не делали это с самого начала, когда было 5000 работ в неделю.
Также плюсом этого подхода является то, что заказчика очень легко уговорить на это – это встроенная возможность Windows, поэтому уговаривать даже почти не пришлось на запуск сбора статистики.
Какие выводы мы сделали: надо было снять счетчики производительности в самом начале проекта. Хотя и сейчас сравнивать их с интервалом в один месяц – довольно интересно.
5 проблема: не доверяйте конвертерам из RFH в HTML.
В унаследованном коде документы хранились в форме RTF. Заказчик попросил доработать возможность редактирования документов в web клиенте. У заказчика была лицензия на TxTextControl v 19, поэтому редактор реализован был с использованием этого компонента. Однако позже выяснилось, что форматирование (которое требует преобразования из RTF в HTML и обратно) приводит к проблемам. Иногда 10й размер шрифта становится 10,5 после преобразования и много-много других мелких косячков. При этом служба тех. поддержки рекомендовала обновиться до 20й версии. Но при более подробном исследовании оказалось, что в 20й версии есть другие косяки, которые нам тоже не подходят.
Выводы, которые мы сделали по этой проблеме:
6 проблема: восстановление потерянной части для IOS.
Кроме web части также существует развернутая часть для использования приложения на IPad. Как оказалось, исходные коды от нее были потеряны. После некоторых поисков мы попробовали восстановить исходные коды с помощью декомпиляции (это можно делать с помощью Developer Bundle от RedGate, в состав которого входит Ants Profiler). В целом качество декомпиляции очень хорошее, после анализа мы смогли в течение 2х часов найти, как происходила аутентификация для IOS в WCF сервере и восстановить её в последней версии программы.
Выводы: Developer Bundle от RedGate реально нас выручил в той ситуации.
7 проблема – профилировщик.
Мы также столкнулись с одной проблемой производительности: через 40 минут работы на клиенте начинались задержки при печати. Мы проверили все, что можно с точки зрения сервера, но там ничего плохого не нашли.
К счастью, в тому времени мы решили попробовать Ants Profiler. У него есть очень хорошее преимущество – действительно легкий в использовании, но требует администраторских прав на установку на локальной машине. Запустить под ним программу – буквально действие в 3 клика. Еще радует триальный полнофункциональный период в 14 дней – если надо разово запустить на конечной машине, то это самый подходящий выбор.
После того, как запустили клиента на 40 минут под профилировщиком, найти проблему оказалось делом 3 минут (в одном месте было накопление списка сокращений, и при каждом наборе символа проводилась проверка на сокращение, которая и вызывала задержки).
Еще одно из преимуществ – очень хорошие отчеты, которые весьма наглядны (пример отчета представлен ниже) + может логировать SQL запросы, обращения к диску, сетевые запросы.
Минус – на самом высоком уровне детализации профилирования плохо работает с COM объектами (как минимум). Но после некоторых экспериментов мы нашли, что детализация на уровне процедур ничего не изменяет, и уже более года пользуемся этим хорошим инструментом.
8 проблема – производительность БД на уровне снапшотов.
Как уже говорилось, за счет того, что мы работаем в здравоохранении, у нас довольно долгий процесс обновления. Примерно полгода назад, когда количество работ возросло до 20.000 работ в неделю, у заказчика появились проблемы, связанные с тем, что система не успевала обрабатывать очередь задач, и они с точки зрения пользователя не шли по рабочему workflow. Проблема проявилась из-за того, что во время чтения из таблицы она блокировалась, и поэтому команды обновления таблиц выполнялись не так быстро, как хотелось бы.
Поэтому нам была поставлена задача оптимизации приложения без изменения приложения на сервере.
Логично предположить, что если надо оптимизировать без изменения кода, то надо оптимизировать не приложение, а базу данных. При этом индексы в базе данных уже были созданы.
После недельного анализа мы решили попробовать перевести базу данных в snapshot mode. Неожиданно это дало необычайно хорошие результаты – очередь с 400 работ сократилась до 12 работ (но это уже было в пределах нормы).
Выводы, которые мы сделали по этой проблеме: в дополнение к созданию индексов не надо забывать о таком механизме, который есть в MS SQL
9 проблема – отчеты.
Также с точки зрения производительности существовала еще одна проблема: была админка, которая позволяла строить различные типы отчетов. Но в то же время эти отчеты были написаны не оптимально и их вычисление через некоторое время стало занимать 40 минут. Например, в эти отчеты входило вычисление производительности наборщиков текста. При этом часто эти отчеты приводили к локам таблиц (и это было до решения производительности БД на уровне снапшотов). По бизнес-логике эти отчеты показывали информацию за прошедший день и сотрудники в начале рабочего дня запускали его генерацию через админку, после чего файл появлялся на сетевом диске и все его смотрели. При этом из-за лока таблиц периодически останавливались все операции обновления и удаления из БД.
Эта проблема была решена очень просто – мы просто создали консольную утилиту и поставили её не выполнение с помощью планировщика задач Windows, а из админки убрали. Таким образом, мы сохранили бизнес логику (к началу рабочего дня отчет готов) и избежали проблем с локом.
Выводы по этой проблеме: хорошо, что мы проанализировали, с какой частотой создаются отчеты и к какому сроку отчет должен быть готов.
Мы перечислили некоторые проблемы, с которыми мы столкнулись при работе с унаследованным проектом. Были ли наши решения идеальными? Вряд ли.
Но они позволили удержать проект, развить его и сделать его устойчивым, и заказчик остался с нами.
Спасибо за внимание!
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
Вначале коротко опишем суть проекта. Есть доктора в клиниках, которые на специальные устройства надиктовывают информацию о пациенте и его визите. Затем эта информация переводится в текстовый вид (за это отвечает специальное подразделение, сотрудники которого слушают и набирают текст), текст проверяется, происходит заполнение шаблона. Потом происходит движение по Workflow, который включает в себя разные стадии с различной бизнес-логикой, потом происходит интеграция с несколькими внешними системами. И, наконец, печатается письмо пациенту и отсылается. А работа через некоторое время архивируется (но при этом она может быть восстановлена по необходимости).
При этом часть Workflow может выполняться на iPad, есть специальная часть для настроек системы и workflow, также есть специальная часть для редактирования и утверждения документов в браузере. Но основная часть работы производится на локальной машине пользователя, которая находится в госпитале.
Также есть обязательное условие, что данные не могут потеряться. Поэтому на локальной машине пользователя все хранится в БД MySQL, данные из которой синхронизируются с основным сервером.
Специфика проекта – область здравоохранения в одной западноевропейской стране. Также этот программный комплект развернут более чем в 10 клиниках, каждая из которых имеет некоторую уникальную специфику. Также, чтобы уговорить клинику на новую версию, надо довольно много времени: сначала надо развернуть на тестовый сервер клиники, потом они тестируют в течение 3х недель, потом происходит разворачивание на живой сервер.
Также в базах данных находится конфиденциальная информация о пациентах, поэтому у каждой клиники свой сервер (и как показала практика, уговорить их купить новый винт – уже проблема).
Что мы получили?
Как вы понимаете, от 3 предыдущих команд отказались не из-за их высокого качества работы. Мы получили примерно 400.000 строк исходного кода на C# (+ еще несколько внешних библиотек). Часть исходных кодов была потеряна. Отсутствие документации. Отсутствие тестов. Отсутствие тестовых данных. Отсутствие человека со стороны заказчика, который знал бы все о системе (человека, который был бы с момента создания проекта). Код был написан так, что покрывать его unit тестами было невозможно. БД примерно из 120 таблиц, Проблемы с производительностью, Использование ADO.NET, Dapper, LINQ, Entity Framework 4 для взаимодействия с БД. База данных MS SQL.
Часть архитектуры приложения:

Небольшое пояснение об изображенных частях системы:
- Desktop client – большая часть функций системы выполняется на нем – это рабочее приложение доктора
- Desktop Client Service – сервис, который используют все Desktop Clients
- Task Scheduler – модуль системы, который отвечает за перевод работ на следующую стадию и другие периодические операции
- iPad App iOS – приложение для докторов на iPad
- Web Admin – web часть для настройки рабочих процессов, прав доступа к устройствам и т.д.
- Web Client — web часть для докторов, которая имеет довольно ограниченный список возможных функций
Некоторые цифры:
В неделю (полтора года назад) в сумме обрабатывалось 5000 работ. Под обработкой работы понимается прохождение по всем необходимым стадиям, выполнение взаимодействия со всеми внешними сервисами и т.д.
Что у нас есть сейчас (основные достижения через 1,5 года)?
Производительность приложения в некоторых операциях возросла в 10-12 раз, Количество одновременных пользователей увеличилось в 5 раз, количество обрабатываемых работ в неделю достигло 30.000, заказчик стал спокойным
И опишем некоторые проблемы (и то, что мы сделали, что бы их преодолеть), с которыми мы столкнулись.
1 проблема: как доказать заказчику, что все плохо?
Как вы понимаете, заказчик видит, что программа работает, что она может обрабатывать задачи. И доказать, что «под капотом» у этой системы все работает или с костылями, или на пределе – проблематично. И связанная с этим проблема: как показать заказчику, что система улучшается?
Один из вариантов, который в конечном счете выбрали, – использование системы NDepend. Это система статического анализа кода. Причем весьма хорошая. Что особенно в ней понравилось – наличие около 150 стандартных правил.
Очень полезными из них были правила нахождения мертвого кода – не используемые классы и методы. В 90% случаев они были верны, но были и ошибки. Говорили, что конструкторы по умолчанию не используются и операторы неявного преобразования не нужны. На самом деле они были нужны.
Также положительное впечатление оставила скорость работы – анализ получившихся 40 библиотек проходил в течение 4-6 секунд. Также легкость интеграции с Continuous Integration (хотя этим уже мало кого удивишь). Еще полезным был график зависимостей, который может строить NDepend. Когда его показали заказчику, это было очень хорошим обоснованием времени, которого потребовалось на реализацию одной из фич.
Еще любопытная фича NDepend – создание своих правил для анализа кода. Хотя лично нам она не пригодилась, стандартных правил хватает. В то же время из-за того, что проект был унаследованным, мы изменили стандартные правила (так, чтобы они проходили), сделали их критическими (если они нарушаются, что Continious Integration тогда выдает сообщение об этом). А потом постепенно повышали порог «качества» кода.
Еще очень полезная функция – сравнение с предыдущими результатами анализа и нахождение разницы.
Какие выводы сделали по этой проблеме: NDepend имеет очень хорошие возможности, строит много красивых графиков, расширяем. После того, как заказчик стал видеть графики, он стал более спокойным: он видел прогресс.
2 проблема: конфиденциальность данных.
Клиники работают с реальными пациентами, и данные о них являются конфиденциальными. Более того, они находятся на серверах клиник. В эти данные включались аудио файлы с диктовками докторов, официальные документы и т.д.
Для более качественного тестирования нам необходима была копия этой БД. Но из-за конфиденциальных данных госпитали не горели желанием отдавать эти данные.
Поэтому была написана программа анонимизации, которая заменяет все буквы в документах на единицы, заменяет все содержимое аудио на массив из нулей, заменяет все имена на Name 1, Name 2 и т.д.
Реализация этой программы заняла примерно 3 дня. После этого была создана копия живой БД, которая подверглась анонимизации.
В чем была ошибка? Не учли, что она будет долгой (как оказалась, чистое время анонимизации было около 5 дней). Анонимизация создавала доп. нагрузку на тот же самый физический диск, на котором была живая БД, что создало проблемы. К счастью, мы на всякий случай мониторили и при получении первых признаков большой очереди на чтение с диска остановили программу анонимизации.
После этого добавили в нее функции, чтобы она могла продолжать анонимизацию БД после прерывания и стали запускать только ночью.
Какие выводы сделали по этой проблеме: конфиденциальные данные – очень большая проблема. Как показало дальнейшее использование, выгоды от такого решения были не особо большими, потому что у разных госпиталей были разные бизнес-процессы и структура данных иногда сильно отличалась. Хотя несомненно, использование анонимизированной БД дало кратковременные плюсы и частично успокоило заказчика, потому что он понимал, что это была копия реальных данных, и это было хорошим доказательством того, что новые модули будут работать с предсказуемой скоростью на реальных данных.
3 проблема: код, который написан не для тестирования.
Унаследованный код, который надо расширять, при этом не поломав? Казалось бы, что проще – использовать unit тесты и радоваться жизни. Однако качество унаследованного кода было очень низкое. И как показала практика, этот код не был написан для тестирования (синглетоны, использование старой Entity Framework, которая не подходит для тестирования). Но в то же время, необходимо было создавать для него тесты. И мы выбрали путь создания интеграционных тестов. А новые фичи старались писать так, чтобы их можно было покрывать unit-тестами.
Для написания интеграционных тестов мы создали одну доп. утилиту и функцию восстановления БД. Т.о. программисту надо было привести программу перед тестируемым действием, потом запустить утилиту сохранения данных. А потом вызвать в начале теста восстановление БД с указанием пути к восстановленным данным. Утилита сохранения данных просто проходилась по всем таблицам, которые есть в БД, и сохраняла данные из них в XML. После этого функция восстановления динамически создавала новую БД, восстанавливала данные в ней и изменяла строки подключения так, чтобы тесты видели эту новую БД. Для восстановления данных использовали формирование команды вставки и использование ADO.NET для выполнения команды, что дало нам независимость от Entity Framework и т.д. Как положительное следствие – теперь эту утилиту легко перенести на любой другой язык.
Как показала практика, если правильно подготовить БД, то восстановление занимает 1 секунду. А с учетом того, что в CI были ночные тесты, это была приемлемая величина.
А потом еще эта утилита прижилась у тестировщиков, когда они начали делать тестирование с помощью Ranorex – добавили аргументы командной строки и начали использовать для восстановления БД и там.
Какие выводы мы сделали по этой проблеме:
- Для унаследованного кода изобретать маленькие велосипеды – почти неизбежно.
- Если вы только подумали об интеграционных тестах, сразу думайте о ночных тестах
- Восстановление БД на самом деле может быть очень удобно
- Не надо хранить данные для восстановления БД в проекте тестов, лучше выкинуть их в zip архиве на drop box и в архиве хранить ссылку на них
- Положительным побочным эффектом восстановления оказалась проверка корректности изменения структуры БД, которую нам периодически приходится делать.
4 проблема: счетчики производительности на целевой машине.
Также актуален вопрос, который у нас возник в течение года – как показать состояние системы, которая была унаследована, и то, что она постепенно начинает не выдерживать нагрузок? Одно из самых эффективных средств – собирать счетчики производительности с интервалом в неделю. Счетчиков реально много, они дают хорошие графики, их можно экспортировать в Excel, производить анализ и т.д. Жалко только, что мы не делали это с самого начала, когда было 5000 работ в неделю.
Также плюсом этого подхода является то, что заказчика очень легко уговорить на это – это встроенная возможность Windows, поэтому уговаривать даже почти не пришлось на запуск сбора статистики.
Какие выводы мы сделали: надо было снять счетчики производительности в самом начале проекта. Хотя и сейчас сравнивать их с интервалом в один месяц – довольно интересно.
5 проблема: не доверяйте конвертерам из RFH в HTML.
В унаследованном коде документы хранились в форме RTF. Заказчик попросил доработать возможность редактирования документов в web клиенте. У заказчика была лицензия на TxTextControl v 19, поэтому редактор реализован был с использованием этого компонента. Однако позже выяснилось, что форматирование (которое требует преобразования из RTF в HTML и обратно) приводит к проблемам. Иногда 10й размер шрифта становится 10,5 после преобразования и много-много других мелких косячков. При этом служба тех. поддержки рекомендовала обновиться до 20й версии. Но при более подробном исследовании оказалось, что в 20й версии есть другие косяки, которые нам тоже не подходят.
Выводы, которые мы сделали по этой проблеме:
- Не надо надеяться, что, имея лицензию на web редактор, тех. поддержка решит все проблемы.
- Конвертация из rtf в HTML и обратно при более внимательном изучении принесла очень много проблем.
6 проблема: восстановление потерянной части для IOS.
Кроме web части также существует развернутая часть для использования приложения на IPad. Как оказалось, исходные коды от нее были потеряны. После некоторых поисков мы попробовали восстановить исходные коды с помощью декомпиляции (это можно делать с помощью Developer Bundle от RedGate, в состав которого входит Ants Profiler). В целом качество декомпиляции очень хорошее, после анализа мы смогли в течение 2х часов найти, как происходила аутентификация для IOS в WCF сервере и восстановить её в последней версии программы.
Выводы: Developer Bundle от RedGate реально нас выручил в той ситуации.
7 проблема – профилировщик.
Мы также столкнулись с одной проблемой производительности: через 40 минут работы на клиенте начинались задержки при печати. Мы проверили все, что можно с точки зрения сервера, но там ничего плохого не нашли.
К счастью, в тому времени мы решили попробовать Ants Profiler. У него есть очень хорошее преимущество – действительно легкий в использовании, но требует администраторских прав на установку на локальной машине. Запустить под ним программу – буквально действие в 3 клика. Еще радует триальный полнофункциональный период в 14 дней – если надо разово запустить на конечной машине, то это самый подходящий выбор.
После того, как запустили клиента на 40 минут под профилировщиком, найти проблему оказалось делом 3 минут (в одном месте было накопление списка сокращений, и при каждом наборе символа проводилась проверка на сокращение, которая и вызывала задержки).
Еще одно из преимуществ – очень хорошие отчеты, которые весьма наглядны (пример отчета представлен ниже) + может логировать SQL запросы, обращения к диску, сетевые запросы.
Минус – на самом высоком уровне детализации профилирования плохо работает с COM объектами (как минимум). Но после некоторых экспериментов мы нашли, что детализация на уровне процедур ничего не изменяет, и уже более года пользуемся этим хорошим инструментом.
8 проблема – производительность БД на уровне снапшотов.
Как уже говорилось, за счет того, что мы работаем в здравоохранении, у нас довольно долгий процесс обновления. Примерно полгода назад, когда количество работ возросло до 20.000 работ в неделю, у заказчика появились проблемы, связанные с тем, что система не успевала обрабатывать очередь задач, и они с точки зрения пользователя не шли по рабочему workflow. Проблема проявилась из-за того, что во время чтения из таблицы она блокировалась, и поэтому команды обновления таблиц выполнялись не так быстро, как хотелось бы.
Поэтому нам была поставлена задача оптимизации приложения без изменения приложения на сервере.
Логично предположить, что если надо оптимизировать без изменения кода, то надо оптимизировать не приложение, а базу данных. При этом индексы в базе данных уже были созданы.
После недельного анализа мы решили попробовать перевести базу данных в snapshot mode. Неожиданно это дало необычайно хорошие результаты – очередь с 400 работ сократилась до 12 работ (но это уже было в пределах нормы).
Выводы, которые мы сделали по этой проблеме: в дополнение к созданию индексов не надо забывать о таком механизме, который есть в MS SQL
9 проблема – отчеты.
Также с точки зрения производительности существовала еще одна проблема: была админка, которая позволяла строить различные типы отчетов. Но в то же время эти отчеты были написаны не оптимально и их вычисление через некоторое время стало занимать 40 минут. Например, в эти отчеты входило вычисление производительности наборщиков текста. При этом часто эти отчеты приводили к локам таблиц (и это было до решения производительности БД на уровне снапшотов). По бизнес-логике эти отчеты показывали информацию за прошедший день и сотрудники в начале рабочего дня запускали его генерацию через админку, после чего файл появлялся на сетевом диске и все его смотрели. При этом из-за лока таблиц периодически останавливались все операции обновления и удаления из БД.
Эта проблема была решена очень просто – мы просто создали консольную утилиту и поставили её не выполнение с помощью планировщика задач Windows, а из админки убрали. Таким образом, мы сохранили бизнес логику (к началу рабочего дня отчет готов) и избежали проблем с локом.
Выводы по этой проблеме: хорошо, что мы проанализировали, с какой частотой создаются отчеты и к какому сроку отчет должен быть готов.
Мы перечислили некоторые проблемы, с которыми мы столкнулись при работе с унаследованным проектом. Были ли наши решения идеальными? Вряд ли.
Но они позволили удержать проект, развить его и сделать его устойчивым, и заказчик остался с нами.
Спасибо за внимание!
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
