
От запуска ознакомительной версии нового улучшенного поиска кода год назад до публичной беты, которую мы выпустили на GitHub Universe в прошлом ноябре, появилась масса инноваций и резких изменений в некоторых основных продуктах GitHub, затрагивающих то, как мы, разработчики, осознаём, читаем код и ориентируемся в нем.
Нам часто задают вопрос о новом поиске по коду: «Как он работает?». В дополнение к моей лекции на GitHub Universe, я в общих чертах отвечу на этот вопрос, а также немного расскажу о системной архитектуре и технических основах данного продукта.
Так как же он работает? Мы создали собственный поисковый движок с нуля на Rust специально для поиска по коду. Наш поисковый движок называется «Blackbird», но прежде чем я стану описывать как он работает, думаю, что нужно понять наши предпосылки. На первый взгляд, создание поискового движка с нуля выглядит спорно. Зачем это делать? Разве уже нет большого количества существующих решений с открытым исходным кодом?
Если честно, на протяжении практически всей истории существования GitHub мы пытались и продолжаем пытаться использовать существующие решения данной проблемы. О нашей работе подробнее говорится в посте Павла Августинова «Краткая история поиска по коду в GitHub», но хотелось бы кое-что подчеркнуть: нам не очень везло с использованием текстового поиска для поддержки поиска по коду. Пользовательский опыт был неудовлетворительным, индексация — медленной, а хостинг — дорогим. Существует ряд новых опенсорсных проектов, нацеленных на код, но в масштабах GitHub такие проекты работать точно не будут. Поэтому мы хотели создать собственное решение:
- У нас была мечта о полностью новом пользовательском опыте. Пользователи должны были получить возможность задавать вопросы о коде и получать ответы с помощью итеративного поиска, просмотра, навигации и чтения кода.
- Мы понимаем, что поиск по коду однозначно отличается от текстового поиска. Код пишется для понимания машинами, а мы должны быть в состоянии воспользоваться преимуществами этой структуры и релевантности. К поиску по коду также предъявляется ряд уникальных требований: нужно искать знаки препинания (к примеру, точку или открытую скобку), выделение корней не требуется, не нужно, чтобы стоп-слова удалялись из запросов, поиск идёт с использованием регулярных выражений.
- Масштаб GitHub делает эту задачу по-настоящему сложной. При первом развёртывании Elasticsearch индексирование всего кода на GitHub (тогда — около 8 миллионов репозиториев) заняло месяцы. Сейчас репозиториев более 200 миллионов, и код в них не неизменен: он постоянно меняется, и с этим поисковым движкам достаточно сложно справиться. В бета-версии доступен поиск по почти 45 миллионам репозиториев, в которых находится 115 Тб кода и 15,5 миллиардов файлов.
Ни одно из имеющихся решений нам не подходило, так что мы построили своё решение с нуля.
Просто используйте grep?
Для начала, давайте рассмотрим грубый метод решения проблемы. Нам часто задают этот вопрос: «Почему бы вам просто не использовать grep?». Чтобы ответить на него, давайте быстренько произведём расчёты для наших 115 Тб данных при помощи ripgrep. На компьютере с восьмиядерным процессором Intel ripgrep может выполнить исчерпывающий запрос с регулярным выражением к тринадцатигигабайтному файлу, кешированному в памяти, за 2,769 секунд или примерно за 0,6 Гб/сек/ядро.
Довольно быстро становится понятно, что такой подход не будет работать при больших объёмах данных. Поиск по коду работает на 64-ядерных кластерах из 32 машин. Даже если нам удастся разместить 115 Тб кода в памяти и безупречно распараллелить работу, потребуется занять 2048 процессорных ядер на протяжении 96 секунд для обработки одного запроса! Выполняться может только один запрос. Всем остальным придётся ждать в очереди. В результате получается 0,01 запросов в секунду (QPS) и удачи в удвоении QPS — забавно будет послушать, как вы объясняете своему начальству счета за инфраструктуру.
Разумного по цене способа масштабировать такой подход для использования со всем кодом и со всеми пользователями на GitHub просто не существует. Даже если выкинуть кучу денег на решение этой проблемы, нужного пользовательского опыта добиться всё равно не получится.
Вы уже понимаете, куда это ведёт: нужно создать индекс.
Поисковый индекс — основы
Быстро создавать запросы можно только если осуществляется предварительный расчёт информации в виде индексов. Можете считать их чем-то вроде сопоставления ключей с отсортированными списками идентификаторов документов, где находится этот ключ. Возьмём для примера небольшой индекс языков программирования. Сканируется каждый файл для определения того, на каком языке программирования он написан, файлу присваивается идентификатор, а затем создаётся инвертированный индекс, где язык является ключом, а список идентификаторов документов — значением.
Прямой индекс
| Doc ID | Content |
| 1 | def lim puts “mit” end |
| 2 | fn limits() { |
| 3 | function mits() { |
Инвертированный индекс
| Language | Doc IDs (postings) |
| JavaScript | 3, 8, 12, … |
| Ruby | 1, 10, 13, … |
| Rust | 2, 5, 11, … |
Для поиска по коду нужен особый вид инвертированного индекса под названием n-граммный индекс. Он хорошо ищет подстроки в содержимом. N-грамма — это последовательность из n элементов. К примеру, если мы возьмём n=3 (триграммы), n-граммы, составляющие "limits" — это lim, imi, mit, its. В приведённых выше документах, индекс для этих триграмм выглядел бы следующим образом:
| ngram | Doc IDs (postings) |
| lim | 1, 2, … |
| imi | 2, … |
| mit | 1, 2, 3, … |
| its | 2, 3, … |
Для осуществления поиска мы скрещиваем результаты нескольких поисков и получаем список документов, где есть конкретная строка. С триграммным индексом необходимо четыре поиска lim, imi, mit и its для выполнения запроса limits.
В отличие от хэш-карты, эти индексы слишком велики, чтобы поместиться в память, так что взамен мы создаём итераторы для каждого индекса, к которому нужно получить доступ. Они возвращают отсортированные идентификаторы документов (идентификаторы присваиваются на основе ранжирования каждого документа) и мы скрещиваем и объединяем итераторы (как требует определённый запрос) и производим чтение настолько, чтобы получить запрошенное число результатов.
Индексируем 45 миллионов репозиториев
Следующий вопрос, который необходимо решить — создание такого индекса за разумное время (как вы помните, в первый раз это заняло месяцы). Как это часто бывает, сложность заключается в применении идей к данным, с которыми мы работаем. В нашем случае особенности две: использование контентно-адресуемого хеширования в Git и наличие большое количества дублирующихся данных на Github. Эти особенности привели нас к следующим решениям:
- Шард через идентификатор объекта Blob, при помощи которого можно равномерно распределить документы между шардами, при этом избегая дублирования. Горячих серверов не будет из-за специальных репозиториев, а число шардов при необходимости легко масштабируется.
- Модель индекса как дерева и использование дельта-кодирования для снижения частоты краулинга и оптимизации метаданных в индексе. Здесь метаданные — это, к примеру, список мест, где находится файл (путь, ветка и репозиторий) и информация об этих объектах (имя репозитория, владелец, видимость и т. д.). Объём таких данных для популярного контента может быть весьма большим.
Мы также создали систему, которая обеспечивает согласованность результатов запросов на уровне коммитов. Если вы ищете в репозитории, пока ваш коллега пушит код, результаты поиска не должны включать файлы из нового коммита, пока он полностью не будет обработан системой. В действительности, пока вы получаете результат запроса к репозиторию, кто-то другой может просматривать глобальные результаты и искать иное, предыдущее, но всё ещё согласованное состояние индекса. С другими поисковыми движками добиться такого поведения непросто. Устройство Blackbird позволяет работать на таком уровне согласованности запросов.
Давайте создадим индекс
Вооружившись этими идеями, давайте рассмотрим построение индекса с помощью Blackbird. На этой схеме отображена высокоуровневая общая картина обработки и индексирования в системе.
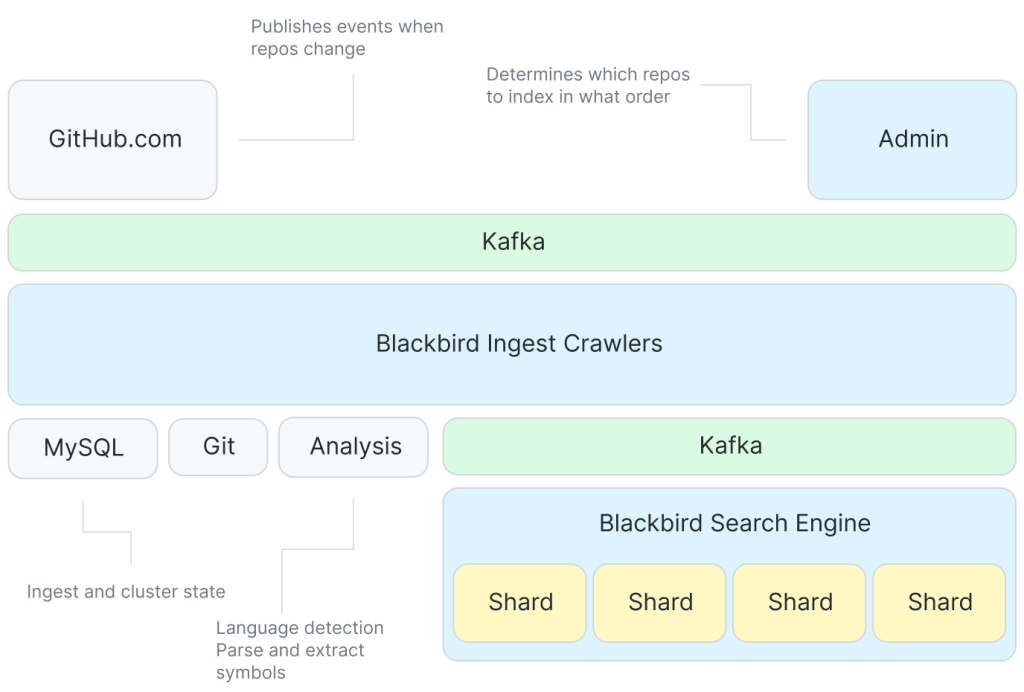
Kafka сообщает о событиях, которые говорят о необходимости что-то проиндексировать. Существует множество краулеров, взаимодействующих с Git и сервисом для извлечения символов из кода. Затем, чтобы каждый шард обрабатывал файлы для индексирования в своём ритме, снова используется Kafka.
Хотя система обычно просто отвечает на события, такие, как git push, для краулинга изменившегося содержимого необходимо проделать определённую работу для обработки всех репозиториев в первый раз. Ключевая особенность системы — это оптимизация порядка, в котором происходит эта первичная обработка, для максимально эффективного использования дельта-кодирования. Используется новая вероятностная структура данных, представляющая сходство репозиториев и определяющая порядок загрузки из обхода порядка уровней минимального остовного дерева графа сходства репозиториев[1].
Используя оптимизированный порядок обработки, каждый репозиторий краулится путём сопоставления его с родителем в созданном нами дельта-дереве. Это означает, что нужно краулить только блобы, уникальные для этого репозитория, а не весь репозиторий. Краулинг включает в себя получение содержимого блоба из Git, его анализ для извлечения символов и создание файлов, которые станут вводными данными для индексирования.
Эти файлы затем публикуются в другой теме Kafka. Там мы разделяем 2 данные между шардами. Каждый шард использует один раздел Kafka в топике. Индексирование отделено от краулинга при помощи Kafka. Согласованность запросов достигается упорядочиванием сообщений в Kafka.
Затем шарды индексатора получают эти файлы и создают их индексы: происходит токенизация для создания n-граммных индексов3 (для содержимого, символов и путей) и других нужных индексов (языков, владельцев, репозиториев и т. д.) перед сериализацией и сбросом на диск, когда накопится достаточно работы.
Наконец, шарды запускают сжатие для создания больших индексов из малых. Такие индексы более эффективны при запросах и их легче перемещать (к примеру, в реплику чтения или в резервные копии). Сжатие также использует k-образный алгоритм слияния для списков по баллам, так что релевантные файлы имеют более низкие идентификаторы и ленивые итераторы возвращают их первыми. При первоначальной обработке сжатие откладывается до большого прогона в конце, но затем, поскольку индекс не отстает от инкрементных изменений, мы выполняем сжатие с более коротким интервалом, ведь именно здесь обрабатывается, к примеру, удаления документа.
Жизненный цикл запроса
Теперь у нас есть индекс. Интересно отследить путь запроса в системе. Мы будем наблюдать за запросом-регулярным выражением к Rails organization, который ищет код, написанный на языке программирование Ruby: /arguments?/ org:rails lang:Ruby. Высокоуровневая архитектура запроса выглядит как-то так:
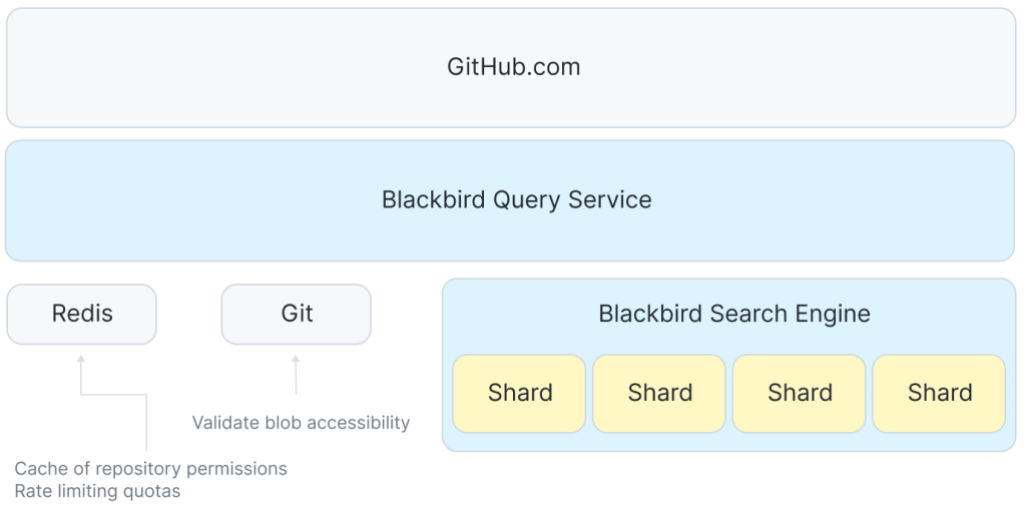
Между GitHub.com и шардами находится сервис, координирующий приём запросов пользователей и распределяющая запросы к каждому хосту в поисковом кластере. Для управления квотами и кеширования некоторых данных контроля доступа мы используем Redis.
Фронтенд принимает запрос пользователя и передаёт его в службу запросов Blackbird, где происходит запрос разбирается в абстрактное синтаксическое дерево. Затем происходит переписывание запроса, резолвинг, к примеру, языков в их канонические идентификаторы языков Linguist. Для разрешений и контекстов используются дополнительные условия. В этом случае, можно увидеть, как переписывание запроса гарантирует получение результатов из публичных репозиториев или любых доступных частных репозиториев.
And(
Owner("rails"),
LanguageID(326),
Regex("arguments?"),
Or(
RepoIDs(...),
PublicRepo(),
),
)n параллельных запросов распределяются и отправляются: по одному к каждому шарду в поисковом кластере. Из-за стратегии разделения нужно отправлять запрос к каждому шарду в кластере.
Затем в каждом отдельном шарде запрос преобразуется для поиска информации в индексах. Здесь можно увидеть, что регулярное выражение становится сериями запросов подстрок на n-граммных индексах.
and(
owners_iter("rails"),
languages_iter(326),
or(
and(
content_grams_iter("arg"),
content_grams_iter("rgu"),
content_grams_iter("gum"),
or(
and(
content_grams_iter("ume"),
content_grams_iter("ment")
)
content_grams_iter("uments"),
)
),
or(paths_grams_iter…)
or(symbols_grams_iter…)
),
…
)Если вы хотите узнать больше о том, как регулярные выражения становятся запросами подстрок, обратитесь к статье Расса Кокса о сопоставлении регулярных выражений с триграммным индексом. Мы используем другой алгоритм и динамические размеры грамм, а не триграммы (см. ниже 3). В данном случае движок использует следующие граммы: arg,rgu, gum, а затем либо ume и ment, либо 6-грамму uments.
Из каждого условия запускаются итераторы: and — это пересечение, or — объединение. В результате получается список файлов. Необходимо перепроверить каждый файл (чтобы подтвердить совпадения и определить их диапазоны) перед оценкой, сортировкой и возвратом запрошенного числа результатов.
В сервисе запросов мы соединяем результаты из всех шардов, заново сортируем их по оценке, фильтруем (для повторной проверки разрешений) и возвращаем топ-100. Фронтенд GitHub.com затем проводит подсветку синтаксиса и терминов, разбиение по страницам и, в конце концов, отображает результаты на странице.
Наше время отклика p99 от отдельных шардов составляет порядка 100 мс, но общее время отклика немного больше из-за соединения ответов, проверки разрешений и других факторов, таких, как подсветка синтаксиса. Запрос занимает 100 мс на одном ядре процессора на сервере индексации, поэтому верхняя граница 64-ядерных хостов составляет примерно 640 запросов в секунду. По сравнению с grep (0,01 QPS) это невероятно быстро. Система масштабируется. Возможно осуществление большого числа одновременных пользовательских запросов.
Заключение
После рассмотрения работы системы целиком, давайте снова обратимся к масштабу задачи. Пайплайн обработки может публиковать около 120 000 файлов в секунду, так что проход через все 15,5 миллиардов файлов займёт около 36 часов. Но дельта-индексирования сокращает число файлов, которые необходимо краулить, более, чем на 50%, что позволяет нам снова проиндексировать весь объём данных примерно за 18 часов.
Также мы добились значительного уменьшения размера индекса. Напомню, что сначала у нас было 115 Тб контента. Устранение дублей в контенте и дельта-индексирование позволило снизить размер примерно до 28 Тб уникального контента. А сам индекс занимает всего 25 Тб, и сюда включены не только все индексы (в том числе и n-граммы), но также и сжатая копия всего уникального контента. Это означает, что общий размер индекса и контента составляет около четверти размера исходных данных!
Если вы ещё не участвуйте в бета-тестировании, обязательно записывайтесь и попробуйте новый поиск по коду. Расскажите нам о своих ощущениях! Мы постоянно добавляем новые репозитории и устраняем недостатки, основываясь на обратной связи от пользователей — таких, как вы.
Примечания
Чтобы определить оптимальный порядок загрузки, нам нужен способ сказать, насколько один репозиторий похож на другой (с точки зрения их содержимого), поэтому мы изобрели новую вероятностную структуру данных, чтобы определять подобие в том же классе структур данных, что MinHash и HyperLogLog. Эта структура данных, которую мы называем геометрическим фильтром, позволяет вычислять сходство множеств и симметричную разницу между множествами с логарифмическим пространством. В этом случае множества, которые мы сравниваем, представляют собой содержимое каждого репозитория в кортежах (path, blob_sha). Вооружившись этими знаниями, мы можем построить граф, в котором вершины являются репозиториями, а ребра взвешены с помощью этой метрики сходства. Вычисление минимального остовного дерева этого графа (со сходством в качестве стоимости графа), а затем выполнение обхода дерева в порядке уровней дает нам порядок приема, в котором мы можем наилучшим образом применить дельта-кодирование. На самом деле этот граф огромен (миллионы узлов, триллионы ребер), поэтому наш алгоритм MST вычисляет приближение, это вычисление занимает всего несколько минут и дает 90% преимуществ дельта-сжатия, к которым мы стремимся.
Индекс сегментируется Git blob SHA. Шардинг означает распределение проиндексированных данных по нескольким серверам; его нужно выполнить, чтобы легко масштабироваться горизонтально для чтения (интересует количество запросов в секунду), для хранения (где основное внимание уделяется дисковому пространству) и для времени индексирования, ограниченного ЦП и памятью на отдельных хостах).
Используемые нами индексы ngram особенно интересны. Триграммы — лакомый кусочек в смысле архитектуры; как заметил Расс Кокс и другие: биграммы недостаточно избирательны, а квадрограммы занимают слишком много места; но триграммы вызывают некоторые проблемы в нашем масштабе.
Для обычных грамм, вроде for, триграммы недостаточно избирательны. Мы получаем слишком много ложных срабатываний, а это означает медленные запросы. Пример ложного срабатывания — это что-то вроде поиска документа, в котором есть каждая отдельная триграмма, но не рядом друг с другом. Вы не сможете понять, что оно ложное, пока не получите содержимое документа и дважды не проверите, в какой момент проделали большую работу, от которой нужно отказаться. Мы попробовали ряд стратегий, чтобы исправить это, например, добавление масок следования, которые для символа (в основном на полпути к квадрограммам) после триграммы используют битовые маски, но они слишком быстро насыщаются, чтобы быть полезными.
Мы называем решение «разреженными граммами», и оно работает следующим образом. Предположим, у вас есть некоторая функция, которая при задании биграммы дает вес. Пример — строка chester. Каждому биграмму присваиваем вес: 9 для «ch», 6 для «he», 3 для «es» и так далее.

А полезная теория и ещё больше практики с погружением в среду IT ждут вас на курсах SkillFactory:

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
А также
