Легко написать код, который компилируется, компонуется и нормально работает на x86, но не работает на других процессорах, например Power. Обычно причина в том, что такой код изначально не был предназначен для платформ, отличных от x86. В статье разбираем отличия x86 и Power, которые могут нарушить сборку или снизить производительность. Делимся инструментами, которые помогут выявить и устранить проблемы.

Размер строки кэша

Какой бы быстрой ни была оперативная память, процессор всегда работает быстрее. Несмотря на разную скорость работы, процессор не простаивает и не ожидает, пока оперативная память «выдаст» или «примет» данные — практически всегда он работает на максимальной скорости. И всё благодаря кэш-памяти.
Кэш-память — небольшая по объёму, но супербыстрая память. Она встроена в процессор и представляет собой некий буфер, который сглаживает перебои в обмене данными с более медленной оперативной памятью. В большинстве процессоров используется многоуровневая система кэша. Кэш-память первого уровня или L1 считается самой маленькой и самой быстрой (с наименьшей задержкой). Последующие уровни (L2, L3 и др.) имеют все более высокие задержки и внушительный размер.
Иерархия кэш-памяти:
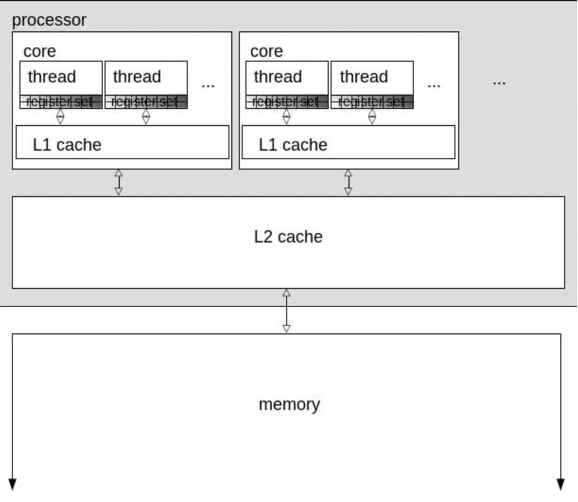
Обратите внимание, что в приведённом примере SMT-потоки внутри ядра совместно используют кэш-память первого уровня (L1), а ядра внутри процессора — кэш-память второго уровня (L2).
Существуют протоколы перемещения данных:
между уровнями иерархии кэша;
между кэшами, выделенными одному ядру, в кэши, выделенные другому ядру.
Протоколы нужны, чтобы обеспечить согласованное представление памяти всех процессоров в системе. Если какие-либо данные в строке кэша изменяются на одном ядре, а другое ядро пытается получить доступ к этим данным, вся строка кэша должна быть скопирована в иерархию кэша этого второго ядра.
Строка кэша — наименьшая единица памяти, которую извлекает процессор. Размер строки кэша на процессорах x86 составляет 64 байта; на процессорах Power — 128 байт. Эта разница не влияет на корректность работы программ, но может сказаться на их производительности в некоторых сценариях. Проблемы с производительностью возникают, когда два или более ядра конкурируют друг с другом за данные в одной строке кэша, даже если соответствующие диапазоны памяти не перекрываются.
Представьте массив из шестнадцати 64-битных целых чисел, выровненных по границе строки кэша. Задача, работающая на одном ядре, часто обращается к 8-му целому числу или изменяет его, а задача, работающая на другом ядре, часто обращается или изменяет 9-е целое число. Кажется, что конфликта для двух непересекающихся местоположений данных нет. В системе с 64-байтными строками кэша 8-е целое число находится в конце первой строки кэша, а 9-е целое число — в начале второй строки кэша, поэтому между ядрами нет конкуренции за их соответствующие значения.
Однако в системе со 128-байтовыми строками кэша и 8-е, и 9-е целое число будут находиться в одной и той же строке кэша. Протоколы когерентности кэша должны гарантировать, что представление памяти будет согласованным между двумя ядрами. То есть, любое изменение на одном ядре должно отражаться на другом ядре путем копирования строки кэша в иерархию кэша для другого ядра перед его следующим доступом. Это может значительно увеличить задержку при доступе к памяти, даже если за данные нет явной конкуренции.
Устранение проблем такого типа требует изоляции часто используемых и близко расположенных, но специфичных для ядра данных в независимых строках кэша. Сюда могут входить массивы мьютексов, счётчики для каждого ядра, мьютексы со смежными данными и др. Один из способов добиться статического выравнивания — использовать атрибут:
struct {
int count attribute ((aligned(128)));
} counts[N_CPUS];В современном ядре и glibc есть программные возможности для определения размера строки кэша процессора:
unsigned long cache_line_size;
unsigned long cache_geometry = getauxval(AT_L2_CACHEGEOMETRY);
cache_line_size = cache_geometry & 0xFFFF;Более простой (и предпочтительный) способ:
long cache_line_size;
cache_line_size = sysconf(_SC_LEVEL2_CACHE_LINESIZE);Затем нужно сделать так, чтобы данные каждого процессора находились в своих собственных строках кэша:
#define ROUND_UP(a,b) ((((a) + (b) ‑ 1) / (b)) * (b))
// calculate the size of each counter (int) when each is aligned to a cache line
unsigned long stride = ROUND_UP(sizeof(int),cache_line_size);
// get Number of CONFigured PROCESSORS
long cpus = sysconf(_SC_NPROCESSORS_CONF);
// allocate an array of counters, one per CONFigured PROCESSOR
// such that each counter is on its own cacheline
void *counters = calloc(cpus,stride);
long cpu = cpus ‑ 1; // pick a cpu (the last one)
// increment the counter for PROCESSOR #<cpu>
(*(int *)(counters + cpu * stride)) ++;Размер страницы

Управление виртуальной памятью в большинстве операционных систем включает сегментирование на блоки, которые называют страницами. Каждый раз, когда программа обращается к данным в памяти, их адрес сопоставляется со страницей памяти. Этим сопоставлением управляет таблица страниц.
PTE (page table entry) — запись в таблице страниц.
Перевод — сопоставление адреса со страницей.
Скорость перевода имеет решающее значение. Современные процессоры содержат вспомогательные средства для перевода — TLB (Translation Lookaside Buffer) и другие механизмы. Размер буферов ограничен, поэтому целесообразно ограничивать количество страниц, активно используемых программой. Если перевод не удается разрешить в TLB (TLB miss), нужно получить прямой доступ к таблице страниц, что значительно медленнее.
Размер страниц памяти можно изменить путем перекомпиляции ядра, хотя обычно это не рекомендуется, поскольку операционная система настроена на размер страницы по умолчанию. Системы x86 чаще всего используют страницы памяти размером 4096 байт (4 КБ). PowerPC — страницы памяти размером 65536 байт (64 КБ). Кроме того, во многих современных системах память может быть разделена между группами процессоров (узлами). Программа, запущенная на одном узле и обращающаяся к памяти на другом узле, будет ожидать намного дольше (более высокая задержка), чем программа, обращающаяся к памяти на том же узле, на котором запущена. Этот эффект называется неравномерным доступом к памяти (NUMA).
Современные ядра могут пытаться переносить страницы памяти на узлы, с которых к ним будет получен доступ. Это называется автоматической балансировкой NUMA. Она бывает как полезной, так и вредной в зависимости от характеристик рабочей нагрузки.
Может быть выгодно гарантировать, что программа, использующая несколько ядер одновременно, не будет часто обращаться к одной и той же странице с разных узлов. Очевидный метод предотвращения совместного использования страниц — изоляция данных.
Программа, желающая изолировать данные на странице, должна знать размер страницы. Многие программы могут определять размер страницы в 4 КБ (как в системах x86) и выравнивать свои данные таким образом. Изоляция, к которой они стремятся, не будет реализована в системах на базе процессоров Power.
Существуют программные возможности для определения размера страницы памяти:
unsigned long page_size = getauxval(AT_PAGESZ);
или
long page_size = sysconf(_SC_PAGE_SIZE);
Выделить память с выравниванием по страницам просто:
void *data;
size_t data_size = (size_of_data);
posix_memalign(&data, page_size, data_size);Векторная обработка: одна инструкция, несколько данных (SIMD)

Многие современные процессоры обладают возможностью одновременной обработки набора данных. Это можно использовать для повышения производительности. К сожалению, инструкции низкоуровневого процессора и соответствующие API-интерфейсы C/C++ несовместимы. Появляются новые подходы к добавлению совместимых реализаций векторных встроенных функций x86 для Power. Подробнее в разделе Porting x86 vector intrinsics code to Linux on Power in a hurry.
Одновременная многопоточность

Чтобы более эффективно использовать доступные ресурсы, современные процессоры позволяют запускать несколько потоков на одном ядре. Это называется одновременной многопоточностью (SMT). Очевидное преимущество такого подхода состоит в меньшем числе компонентов ядра, простаивающих во время обработки. Недостаток — в том, что между одновременно активными потоками может возникнуть конкуренция за ресурсы процессора. Как правило, большее количество потоков обеспечивает более высокую пропускную способность ядра, тогда как меньшее количество потоков обеспечивает более высокую однопоточную производительность и меньшую задержку.
Системы x86 могут поддерживать до двух потоков на ядро. IBM Power8® поддерживает до восьми потоков на ядро. Процессоры IBM Power9 и Power10 поддерживают до восьми потоков на ядро.
Однопоточные рабочие нагрузки лучше всего работают с отключенным SMT. В системах x86 это можно сделать, изменив настройки BIOS. В системах на базе процессоров Power вы можете перевести каждое ядро системы в однопоточный режим (ST, или SMT=off, или SMT=1), выполнив следующую команду:
# ppc64_cpu –smt=1
Поскольку производительность многопоточных приложений с SMT зависит от рабочей нагрузки, рекомендуется протестировать репрезентативную рабочую нагрузку, чтобы определить оптимальную конфигурацию. В Power вы можете аналогичным образом изменить режим SMT, используя следующую команду:
# ppc64_cpu –smt=n
Для сложных рабочих нагрузок, когда может потребоваться изменить режим SMT на разных ядрах, можно отключить отдельные потоки:
# echo 0 > /sys/devices/system/cpu/cpu0/online
Команда отключит cpu0, первый поток (CPU) на первом ядре. Echo 1 включит CPU.
Таким образом, можно:
включить все потоки на первом ядре;
перевести ядра с 1 по 4 в режим SMT = 2, чтобы обеспечить баланс между задержкой и пропускной способностью для подходящей рабочей нагрузки;
перевести оставшиеся ядра в режим SMT =1 для обеспечения низкой задержки, высокой производительности, однопоточной многоядерной рабочей нагрузки.
Как определить потоки для каждого ядра и сопоставить {ядро, поток} с процессором:
#include <stdio.h>
#include <unistd.h>
static int thread_enumeration_contiguous = ‑1;
int max_smt() {
static int max_smt_save = 0;
if (max_smt_save) return max_smt_save;
FILE *f = fopen("/sys/devices/system/cpu/cpu0/topology/thread_siblings","r");
if (!f) {
max_smt_save = 1;
return 1;
}
int c, b = 0, inarow = 0, maxinarow = 0;
while ((c = fgetc(f)) != EOF) {
int v = 0, last = 0, bit;
if (c >= '0' && c <= '9')
v = c – '0';
if (c >= 'a' && c <= 'f')
v = c ‑ 'a' + 10;
for (bit = 0x1; bit <= 0x8; bit <<= 1) {
if (v & bit) {
b++;
if (last == 1) inarow++;
else inarow = 1;
if (inarow > maxinarow) maxinarow = inarow;
last = 1;
} else {
last = 0;
inarow = 0;
}
}
}
thread_enumeration_contiguous = (maxinarow > 1) ? 1 : 0;
max_smt_save = b;
return b;
}
int core_thread_to_cpu(int core, int thread) {
int smt = max_smt();
int cpus = sysconf(_SC_NPROCESSORS_CONF);
int cores = cpus / smt;
if (thread >= smt) return ‑1;
if (core >= cores) return ‑1;
if (thread_enumeration_contiguous)
return core * smt + thread;
else
return core + thread * cores;
}
int main(int argc, const char * const argv[]) {
int smt = max_smt();
printf("%d %s\n",smt,thread_enumeration_contiguous ? "contiguous" : "non‑contiguous");
int core, thread;
for (core = 0; core < 5; core++) {
for (thread = 0; thread < 10; thread++) {
printf("core %d thread %d is CPU%d\n",core,thread,core_thread_to_cpu(core,thread));
}
}
return 0;
}Огромное количество процессоров
По мере того как всё больше масштабируются современные системы, увеличивается число CPU. Система на базе процессора Power10 может иметь 240 ядер. С восемью потоками на ядро такая система имеет 1920 процессоров! Приложения, которые пытаются масштабироваться между несколькими CPU, часто не готовы к такому уровню масштабируемости в целом, и, в частности, к влиянию NUMA второго порядка, когда некоторые области памяти имеют более высокую задержку, чем другие по отношению к данному CPU.
Некоторые стратегии повышения масштабируемости включают:
иерархические или многоуровневые схемы блокировки (на ядро, на узел, на CEC);
алгоритмы без блокировки;
тщательное размещение и привязку задач;
тщательное распределение памяти и сегментов совместно используемой памяти;
автоматическую балансировку NUMA;
внимание к непреднамеренному совместному использованию строк кэша и страниц.
Напоследок
В статье разобрали ключевые отличия x86 и Power, которые могут негативно влиять на производительность. Надеемся перечисленные советы, как выявить и устранить проблемы при переносе и на другие платформы, помогут вам в работе.
Aдминистрирование Linux Mega
Курс «Aдминистрирование Linux Mega» системного инженера Платона Платонова поможет разобраться не только во всех «фишках» контроля прав, но повысить владение Linux до уровня «бог» за 5 недель. Это самая хардовая и самая «прикладная» программа в духе Слерм + Southbridge: 12 часов теории, 48 часов практики на стендах, 9 масштабных тем и несчитанное количество реальных кейсов.
Документ о прохождении курса получит каждый участник. А те, кто выполнит финальный итоговый проект на стенде, добавят к своему портфолио специальный номерной сертификат. Цель нашего хардового финального тестирования — проверить полученные знания выпускников совокупно, поэтому мы включим каждую изученную тему.
