Единственная причина для существования времени — чтобы все не случилось одновременно.
Альберт Эйнштейн
Привет! Меня зовут Дмитрий, я дата-инженер в SM Lab, и в этом посте хочу рассказать вам о Merlion Framework. В посте мы рассмотрим его архитектуру, полезные функции и отличия от аналогов, разберём пару практических примеров, а также посмотрим, как всё считать и на какие метрики стоит обращать внимание.
В нашем мире время является незаметным четвертым измерением, по оси которого можно упорядочивать разные события.
Временной ряд – это набор данных, описывающих изменения какой-либо переменной во времени.
Задача анализа и предсказания временных рядов остаётся актуальной для бизнеса, ведь для успешного планирования возникает необходимость прогнозирования, например, следующих показателей:
спроса на определенные продукты / услуги
нагрузки на контактный центр или сервера компании
количества новых пользователей / загрузок для приложения
Наиболее популярные подходы для предсказания временных рядов делятся на:
Статистические
ARIMA (AutoRegressive Integrated Moving Average)
ETS (Error, Trend, Seasonal)
Prophet
Exponential Smoother
Основанные на методах машинного обучения
Vector AutoRegressive
DeepAR
Transfromer
RandomForestForecaster
Так какой же метод выбрать для решения задачи?
Преимущество статистических методов заключается в относительной простоте моделей, что делает их более интерпретируемыми и помогает исследовать зависимости между переменными. Однако модели машинного обучения гораздо лучше справляются с описанием динамики более сложных нелинейных процессов.
Почему бы просто не попробовать каждый из этих методов?
Для этого придётся устанавливать много библиотек и по-разному готовить данные для обучения и предсказания каждой модели.
Есть ли какая-то одна библиотека, которая облегчит нам задачу предсказания временных рядов?
Да, такая библиотека уже существует и называется Merlion Framework.
Merlion – это библиотека для анализа временных рядов, написанная на языке Python. Она предоставляет комплексную платформу машинного обучения, которая включает:
загрузку и преобразование данных в удобный формат хранения временных рядов;
построение и обучение моделей для предсказания и детекции аномалий;
простые в использовании ансамбли
распределенные вычисления с использованием Spark
последующую обработку выходных данных модели для уменьшения ошибок и повышения интерпретируемости результатов;
построение пайплайнов для оценки производительности модели
Цель этой библиотеки – предоставить инженерам и исследователям универсальное решение для быстрой разработки моделей и их сравнения.
С полным списком возможностей можно ознакомиться, взглянув на таблицу сравнения с другими библиотеками для анализа временных рядов, взятую из github-репозитория библиотеки. Тут же есть и инструкция по установке.


Сравнительный анализ похожих библиотек по возможностям
По набору возможностей c Merlion могут конкурировать Kats и darts.
Kats предоставляет схожий функционал, но не поддерживает модели архитектуры Transformer, как и возможность использования экзогенных параметров в предсказателях (переменных, которые не объясняются другими переменными в модели, например, погода).
А darts — богатый выбор моделей, возможности для оценки предсказаний, проигрывая разве что в отсутствии функциональности для распознавания change points.
Архитектура и основные структуры данных

Merlion состоит из следующих основных пакетов:
utils – содержит модули, предоставляющие структуру данных для работы с временными рядами
transform – предоставляет функциональность для преобразования временных рядов
models – содержит реализации готовых моделей для предсказания и поиска аномалий
evaluate – хранит метрики для оценки модели
post_process – даёт возможность обработать спрогнозированный временной ряд
spark – связующий модуль для работы с Apache Spark

Начнём работу с библиотекой сразу с практики. Для примера возьмем простой датасет с kaggle. Он содержит информацию о трафике пешеходов и велосипедистов, двигающихся в направлении юга или севера мимо одного и того же светофора в Сиэтле. Информация обновляется с интервалом один час.

В чем проблема датасетов временных рядов?
Для того чтобы скормить такой датасет на обучение какой-нибудь крутой нейросетке, его нужно подготовить. Допустим, мы хотим по двум предыдущим значениям предсказать третье, тогда нам надо пройтись окном размера два по нашей выборке и нарезать её на тренировочные образцы, содержащие по два элемента на вход модели (X) и один элемент как ожидаемое прогнозное значение (y).

Обычно на этом этапе возникает путаница с датами и размерами. К тому же, если в результате экспериментов мы захотим предсказывать не по двум предыдущим значениям, а по трём, придётся заново подготавливать данные и подгонять датасет под ожидаемые моделью размеры.
Merlion решает эту проблему просто, предоставляя свою структуру для хранения временных рядов, которая заточена под работу с интерфейсом предсказательных моделей.
Создаём временные ряды
UnivariateTimeSeries наследует pd.Series и является основным строительным блоком в Merlion. Это специальная структура данных для хранения одномерного временного ряда и работы с ним.

Как создать?
UnivariateTimeSeries легко инициализировать из pd.Series или pd.Dataframe, в котором индекс единственной колонки(все таки создаем одномерный временной ряд) должен указывать время наблюдения.
from merlion.utils import UnivariateTimeSeries
uts = UnivariateTimeSeries.from_pd(df["BGT North of NE 70th Total"])
uts.head()
Что еще может UnivariateTimeSeries?
Помимо всех унаследованных стандартных функций pd.Series, UnivariateTimeSeries предоставляет следующие фишки:
Разбить ряд на два по временной метке функцией bisect()
#предположим что мы хотим поделить выборку на тренировочную и тестовую по времени
train, test = uts.bisect("2017-01-06 00:00:00", t_in_left=False)
train.tail()
test.head()
выбрать строки датасета в промежутке между датами
uts.window("2014-01-01 00:00:00", "2014-01-01 06:00:00")
Bisect и window облегчают выборку по времени, заменяя более громоздкие конструкции из pandas.
# pandas way
selected_rows = df.query("'2014-01-01 00:00:00' <= Date <= '2014-01-01 06:00:00'")
selected_rows = df.loc[(df['Date'] >= '2014-01-01 00:00:00') & (df['Date'] <= '2014-01-01 06:00:00')]
selected_rows = df[df['Date'].between('2014-01-01 00:00:00', '2014-01-01 06:00:00')]А как хранить многомерный временной ряд?
TimeSeries предоставляет функционал для работы с многомерными временными рядами и объединяет в себе несколько UnivariateTimeSeries.
Создать такую структуру можно из готового pd.Dataframe (как со множеством колонок, так и с единственной). Однако возникает ситуация, когда у нас есть несколько одномерных временных рядов с разной частотой наблюдений, которые надо как-то объединить.
Для этого существует конструктор, принимающий словарь из UnivariateTimeSeries.
uts_total = UnivariateTimeSeries.from_pd(df["BGT North of NE 70th Total"])
uts_ped_south = UnivariateTimeSeries.from_pd(df.iloc[1::2]["Ped South"])
uts_bike_south = UnivariateTimeSeries.from_pd(df["Bike North"]).bisect("2014-01-01 04:00:00")[1]
ts = TimeSeries(univariates=OrderedDict([("total", uts_total.copy()),
("ped_south", uts_ped_south.copy()),
("bike_south", uts_bike_south.copy())]))
ts
Функция Align поможет выровнять наши одномерные ряды, предоставляя разработчику выбор стратегий объединения наблюдений и заполнения пропусков.
from merlion.utils.resample import *
ts.align(remove_non_overlapping=True, # начинаем наблюдения с момента пересечения всех параметров
missing_value_policy = MissingValuePolicy.FFill) #заполняем пропущенные значения предыдущими
ts = ts.align(alignment_policy=AlignPolicy.InnerJoin) #делаем inner join для всех параметров
Работа с моделями для предсказания
Merlion содержит богатый набор моделей под общим интерфейсом ModelBase, который пригодится для непосредственной работы с моделью:
сохранение весов модели в файл
загрузка и инициализация из файла
получение информации о последнем обучении
получение информации о конфигурации модели
Модели Merlion используются для двух типов задач временных рядов: обнаружение аномалий и предсказание.

В этой статье мы рассмотрим задачу предсказания и, соответственно, будем работать с моделями под интерфейсом ForecasterBase, который предоставляет следующие основные функции:
train – обучить модель на входных данных
forecast – получить предсказание
plot_forecast – изобразить на графике сравнение между предсказанным временным рядом и тестовыми данными
и другие.
Чтобы создать Forecaster с какой-либо моделью внутри, необходимо создать соответствующий экземпляр Config, который будет передан в конструктор.
from merlion.models.forecast.arima import Arima, ArimaConfig
forecast_steps = 48
config1 = ArimaConfig(max_forecast_steps=48, order=[20, 1, 5])
model1 = Arima(config1)В данном случае ArimaConfig принимает параметры, влияющие на обучение модели. А экземпляр класса Arima предоставляет методы для запуска процесса обучения и построения прогноза.
#обучим модель
train_pred, train_err = model1.train(train, train_config={"enforce_stationarity": True,
"enforce_invertibility": True})
#визуализируем предсказания на обучающей выборке
train.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
train_pred.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
Предсказание модели на обучающей выборке. График синего цвета отображает обучающую выборку, оранжевого – полученные предсказания.
#получим отметки времени из тестовой выборки
time_stamps = test.time_stamps
#построим прогноз
forecast1, stderr1 = model1.forecast(time_stamps=time_stamps[:forecast_steps])
#рассчитаем метрику MAE
smape1 = ForecastMetric.MAE.value(ground_truth=test[:forecast_steps], predict=forecast1)
print(f"{type(model1).__name__} MAE is {smape1:.3f}")
#визуализируем предсказание на тестовой выборке, параметр #plot_forecast_uncertainty отвечает за отображение межквартильного диапазона
fig, ax = model1.plot_forecast(time_series=test[:forecast_steps],
plot_forecast_uncertainty=True)
plt.show()
График предсказания модели Arima на тестовой выборке. Синяя область визуализирует межквартильный диапазон (interquartile range).
Если мы хотим взять принципиально другой метод для предсказания, например, градиентный бустинг, мы также легко сможем это сделать, просто инициализировав другую модель. Остальной код, который в последующем можно обернуть в функцию, останется без изменений, в этом и прелесть интерфейсов.
from merlion.models.forecast.trees import LGBMForecasterConfig
from merlion.models.forecast.trees import LGBMForecaster
modelConfig = LGBMForecasterConfig(ts_encoding="h", max_forecast_steps=48, n_past=48, n_estimators=150)
model2 = LGBMForecaster(modelConfig)
forecast2, stderr2 = model2.train(train)
#визуализируем предсказания на обучающей выборке
train.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
train_pred.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
#получим отметки времени из тестовой выборки
time_stamps = test.time_stamps
#построим прогноз
forecast2, stderr2 = model2.forecast(time_stamps=time_stamps[:forecast_steps])
#рассчитаем метрику MAE
smape2 = ForecastMetric.MAE.value(ground_truth=test, predict=forecast2)
print(f"{type(model2).__name__} MAE is {smape2:.3f}")
#визуализируем предсказание на тестовой выборке
fig, ax = model2.plot_forecast(time_series=test[:forecast_steps],
plot_forecast_uncertainty=True)
plt.show()
Предсказание на тестовой выборке
Что делать, если я хочу использовать модель, реализации которой нет в библиотеке?
Архитектура Merlion располагает возможностями к добавлению собственных моделей.

Схема зависимости DeepForecaster от nn.Module ( базовый модуль для построения нейронных систем во фреймворке PyTotch)
Как мы видим, DeepForecaster является предком torch.nn.Module, что даёт нам возможность реализовывать нейронные сети в PyTorch и оборачивать их в удобную обертку DeepForecaster.
Ансамблирование
Ансамблирование – это метод в машинном обучении, цель которого объединить разные модели, обученные для решения одной и той же задачи. Полученные предсказания каждой модели обычно усредняются, и такая комбинированная оценка часто оказывается лучше предсказания каждой модели по отдельности.
Merlion позаботился об ансамблировании за вас и предоставляет два варианта того, как вы можете скомбинировать модели:
ensemble — агрегирует предсказания каждой из моделей (медиана, среднее, максимум, средневзвешенное)
selector — выбирает лучшую модель, основываясь на заданной метрике
ForecasterEnsemble наследует класс ForecasterBase, что даёт нам возможность использовать его точно так же, как и обычные модели выше.
from merlion.evaluate.forecast import ForecastMetric
from merlion.models.ensemble.combine import Mean, Median, ModelSelector
from merlion.models.ensemble.forecast import ForecasterEnsemble, ForecasterEnsembleConfig
ensemble_config = ForecasterEnsembleConfig(
combiner=Median(), models=[model1, model2])
ensemble = ForecasterEnsemble(config=ensemble_config)
selector_config = ForecasterEnsembleConfig(
combiner=ModelSelector(metric=ForecastMetric.MAE))
selector = ForecasterEnsemble(
config=selector_config, models=[model1, model2])
forecast_sel, stderr_sel = ensemble.train(train)
#визуализируем предсказания на обучающей выборке
train.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
forecast_sel.univariates["BGT North of NE 70th Total"].plot(figsize=(20,7))
#получим отметки времени из тестовой выборки
time_stamps = test.time_stamps
#построим прогноз
forecast_sel, stderr_sel = ensemble.forecast(time_stamps=time_stamps[:forecast_steps])
#рассчитаем метрику MAE
smape1 = ForecastMetric.MAE.value(ground_truth=test[:forecast_steps], predict=forecast_sel)
print(f"{type(ensemble).__name__} MAE is {smape1:.3f}")
#визуализируем предсказание на тестовой выборке
fig, ax = ensemble.plot_forecast(time_series=test[:forecast_steps],
plot_forecast_uncertainty=True)
plt.show()
Результаты предсказаний на тестовой выборке ансамбля selector
Как видно, простое ансамблирование двух моделей Arima и LGBM помогло снизить MAE с 9.617 и 10.501 до 9.105.
Оценка
Расчёт метрик качества предсказаний средствами фреймворка
Класс ForecastMetric содержит следующие метрики:
Mean Absolute Error (MAE)
Mean Absolute Ranged Relative Error (MARRE)
Root Mean Squared Error (RMSE)
symmetric Mean Absolute Percentage Error (sMAPE)
Root Mean Square Percent Error
Mean Absolute Scaled Error (MASE)
Mean Scaled Interval Score (MSIS)
Выше мы уже оценивали точность прогноза, но делали это только на части тренировочной выборки. Это не даёт нам уверенности в том, что при дообучении модели новыми данными, точность не упадёт. Поэтому в Merlion был реализован класс ForecastEvaluator, позволяющий проводить Rolling Cross Validation.
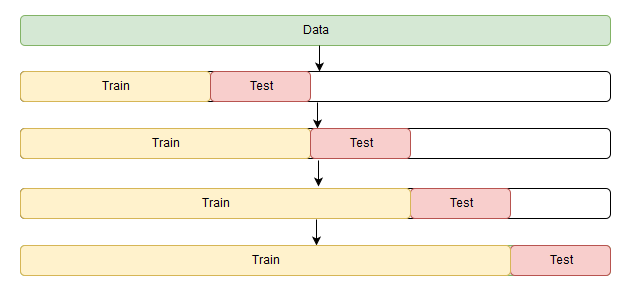
Это проверка, суть которой в постоянном расширении обучающей выборки за счёт старой тестовой, что позволяет убедиться, что модель не просто обучилась единожды подгонять прогноз под тестовую выборку, но и способна выдерживать дальнейшие обучения без сильной потери в точности уже на новых данных.
from merlion.evaluate.forecast import ForecastEvaluator, ForecastEvaluatorConfig,
ForecastMetric
def create_evaluator(model):
model.reset()
evaluator = ForecastEvaluator(
model=model, config=ForecastEvaluatorConfig(
horizon="48h", retrain_freq="24h")
)
return evaluator
ensemble_evaluator = create_evaluator(model1)
ensemble_train_result, ensemble_test_result = ensemble_evaluator.get_predict(train_vals=train,
test_vals=test[:240])
mae = ensemble_evaluator.evaluate(
ground_truth=test[:240],
predict=ensemble_test_result,
metric=ForecastMetric.MAE)
print(f"{type(ensemble).__name__} MAE: {mae:.3f}")В ForecastEvaluatorConfig мы задали частоту переобучения 24 часа, также можно задать и другие параметры, например, ограничить максимальный размер тренировочной выборки (в случае, если мы не захотим проверять на совсем старых значениях) или задать, как часто мы будем делать предсказания для проверки (что влияет на количество тренировок и, конечно же, на общее время выполнения).
Получается, что мы не единожды обучили на тренировочной выборке и проверили, а разбили тренировочную на несколько частей и оценивали каждый раз как меняются метрики, что позволило собрать больше данных о результате обучения.
В данном случае такая проверка показала, что в результате переобучения на новых данных точность по метрике MAE падает c 9.105 до 16.197.
Вывод
В этой статье был проведён лишь поверхностный анализ возможностей Merlion, полностью описать которые сложно даже за несколько статей. Мы убедились, что данное решение помогает упростить работу с временными рядами и предсказательными моделями. Нам становится неважно, работаем мы с нейронной сетью или простой ARIMA-моделью, Merlion даёт возможность быстро попробовать разные варианты, при этом экономя драгоценное время на подготовку данных.
Библиотека развивается в упрощении работы с временными рядами, например появлением графического интерфейса со встроенными no-code autoML решениями. Набор возможностей покрывает все остальные фреймворки.
Благодарю за прочтение, код из статьи вы сможете найти на github.
