Статистика вокруг нас
Статистика и анализ данных пронизывают практически любую современную область знаний. Все сложнее становится провести границу между современной биологией, математикой и информатикой. Экономические исследования и регрессионный анализ уже практически неотделимы друг от друга. Один из известных методов проверки распределения на нормальность — критерий Колмогорова-Смирнова. А вы знали, что именно Колмогоров внес огромный вклад в развитие математической лингвистики?
Еще будучи студентом психологического факультета СПбГУ, я заинтересовался когнитивной психологией. Кстати, Иммануил Кант не считал психологию наукой, так как не видел возможности применять в ней математические методы. Мои текущие исследования посвящены моделированию психических процессов, и я надеюсь, что такие направления в современной когнитивной психологии, как вычислительные и коннективисткие модели, смягчили бы его отношение!
Конечно, статистика применяется далеко за пределами научных лабораторий: в рекламе, маркетинге, бизнесе, медицине, образовании и т.д. Но, что самое интересное, базовые знания анализа данных крайне полезны и в повседневной жизни. Например, думаю, все вы знакомы с понятием среднего арифметического. Среднее значение очень часто используется в СМИ при обсуждении различных социально-экономических показателей — доходов, уровня безработицы и т.д. В 2005 году британские СМИ писали о том, что средний уровень дохода населения не только не возрос, но снизился на 0,2 % по сравнению с предыдущим годом. Мелькали заголовки «Доходы населения снизились впервые с 1990 года». Некоторые политики даже использовали этот факт, критикуя действующее правительство. Однако, важно понимать, что среднее арифметическое — хороший показатель, когда наш признак имеет симметричное распределение (богатых столько же, сколько бедных). Реальное же распределение доходов имеет скорее следующий вид:
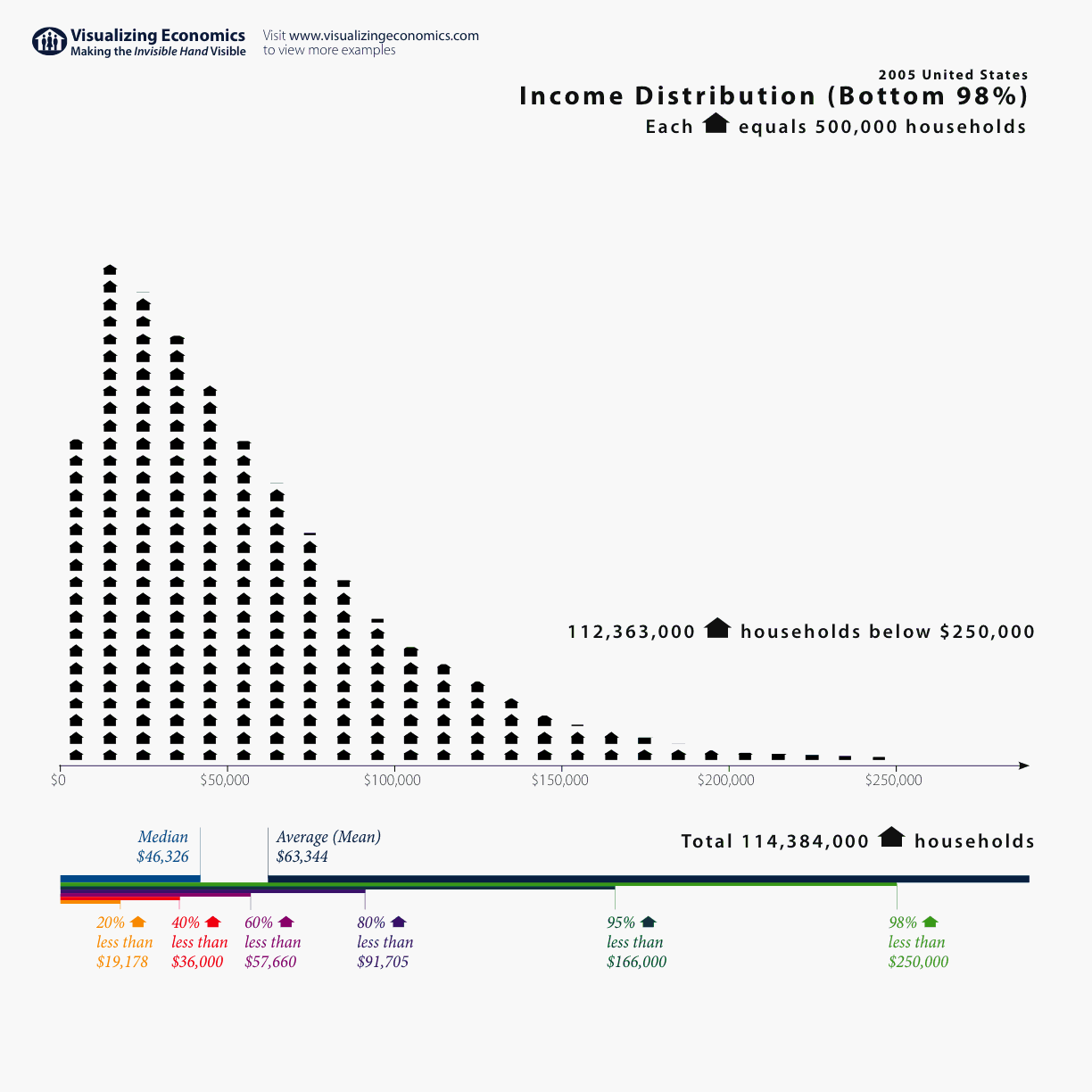
Распределение имеет явно выраженную асимметрию: очень состоятельных людей заметно меньше, чем представителей среднего класса. Это приводит к тому, что в данном случае банкротство одного из миллионеров может значительно повлиять на этот показатель. Гораздо информативнее использовать значение медианы для описания таких данных. Медиана — это значение зарплаты, которое находится в самой середине распределения доходов (50% всех наблюдений меньше медианы, 50% — больше). И, как ни удивительно, медиана дохода в 2005 году в Великобритании, в отличие от среднего значения, продолжила свой рост. Таким образом, если вы знаете о различных типах распределения и различных мерах центральной тенденции (среднее и медиана), то вас не так просто ввести в заблуждение в таких случаях, как описаны в примере.
Черный ящик статистического анализа
Как мы уже выяснили, чем бы вы ни планировали заниматься, вероятность столкнуться с курсом «математическая статистика в вашей области» постепенно приближается к единице. Однако, часто занятия по введению в статистику не вызывают восторга у студентов нетехнических факультетов. Через несколько занятий выясняется, что такие базовые понятия, как, например, корреляция представляют собой нечто следующее:
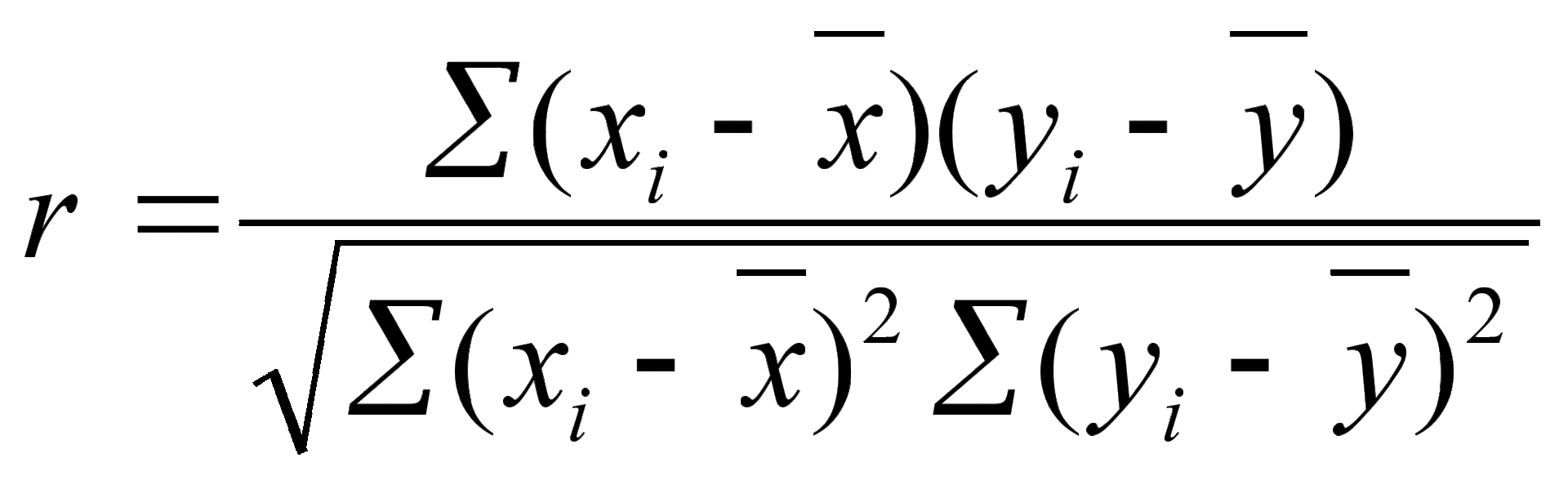
И, отчаявшись досконально разобраться с происхождением этих сумм и квадратных корней, студент может начать воспринимать статистику следующим образом: «если r > 0, то положительная связь, а если меньше 0, то отрицательная»; «если p уровень значимости меньше 0.05 — то хорошо, если от 0.05 до 0.1 — то не очень хорошо, а если больше 0.1 — то плохо». Помогая студентам готовиться к экзамену, не раз сталкивался с такими заклинаниями! Также, разумеется, никто не рассчитывает все эти показатели вручную, и используя, например, SPSS, можно за секунду загуглить пошаговую инструкцию «как сравнить два средних».
- Жмем сюда
- Снимаем/ставим галочки тут
- p < 0.05 —> profit
Статистический анализ начинает напоминать черный ящик: на вход подаются данные, на выход — таблица основных результатов и значение p-уровня значимости (p-value), который и расставит все точки над i.
О чем нам, собственно, говорит p-value?
Предположим, мы решили выяснить, существует ли взаимосвязь между пристрастием к кровавым компьютерным играм и агрессивностью в реальной жизни. Для этого были случайным образом сформированы две группы школьников по 100 человек в каждой (1 группа — фанаты стрелялок, вторая группа — не играющие в компьютерные игры). В качестве показателя агрессивности выступает, например, число драк со сверстниками. В нашем воображаемом исследовании оказалось, что группа школьников-игроманов действительно заметно чаще конфликтует с товарищами. Но как нам выяснить, насколько статистически достоверны полученные различия? Может быть, мы получили наблюдаемую разницу совершенно случайно? Для ответа на эти вопросы и используется значение p-уровня значимости (p-value) — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет. Иными словами, это вероятность получить такие или еще более сильные различия между нашими группами, при условии, что, на самом деле, компьютерные игры никак не влияют на агрессивность. Звучит не так уж и сложно. Однако, именно этот статистический показатель очень часто интерпретируется неправильно.
А теперь несколько примеров про p-value

Итак, мы сравнили две группы школьников между собой по уровню агрессивности при помощи стандартного t-теста (или непараметрического критерия Хи — квадрат более уместного в данной ситуации) и получили, что заветный p-уровень значимости меньше 0.05 (например 0.04). Но о чем в действительности говорит нам полученное значение p-уровня значимости? Итак, если p-value — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет, то какое, на ваш взгляд, верноеутверждение:
- Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
- Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
- Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
- Вероятность случайно получить такие различия равняется 0.04.
- Все утверждения неверны.
Если вы выбрали пятый вариант, то абсолютно правы! Но, как показывают многочисленные исследования, даже люди со значительным опытом в анализе данных часто некорректно интерпретируют значение p-value (например, можно посмотреть эту интересную статью).
Давайте разберем все ответы по порядку:
- Первое утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
- Это уже более интересное утверждение. Все дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
- А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
- Это напрямую связано с самим определением p-value. 0.04 — это вероятность получить такие или еще более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Онлайн-курс по основам статистики: сложные формулы несложным языком
Сейчас я пишу диссертацию на факультете психологии СПбГУ и преподаю статистику биологам в Институте биоинформатики. Основываясь на курсе читаемых лекций и собственного исследовательского опыта, возникла идея создать онлайн-курс по введению в статистику на русском языке для всех желающих, необязательно биоинформатиков или биологов.
Существует много хороших онлайн-курсов по анализу данных и статистике (например, такой, такой, или такой), но практически все они на английском языке. Надеюсь, что курс будет полезен для тех, кто только знакомится с основами статистики. В нем я стараюсь в максимально доступной форме разобрать основные идеи и методы анализа данных, уделяя особое внимание самой идее статистической проверки гипотез и интерпретации получаемых результатов. В качестве примеров будут задачи из различных областей: от биоинформатики до социологии. Курс бесплатный и все его материалы останутся открытыми после окончания, начинается 15 февраля.
Полезные материалы
Если вы знаете какие-либо полезные курсы или материалы по введению в статистику — делитесь в комментариях!
