В прошлый раз я рассказывал о теореме Байеса и приводил простой пример – наивный байесовский классификатор. В этот раз мы перейдём к более сложной теме, которая развивает и продолжает дело наивного байеса: мы научимся выделять темы при помощи модели LDA (latent Dirichlet allocation), а также применим это к рекомендательным системам.

Модель LDA решает классическую задачу анализа текстов: создать вероятностную модель большой коллекции текстов (например, для information retrieval или классификации). Мы уже знаем наивный подход: скрытой переменной является тема, и слова получаются при фиксированной теме независимо по дискретному распределению. Аналогично работают и подходы, основанные на кластеризации. Давайте чуть усложним модель.
Очевидно, что у одного документа может быть несколько тем; подходы, которые кластеризуют документы по темам, никак этого не учитывают. LDA — это иерархическая байесовская модель, состоящая из двух уровней:
Вот граф модели (картинка взята из википедии):
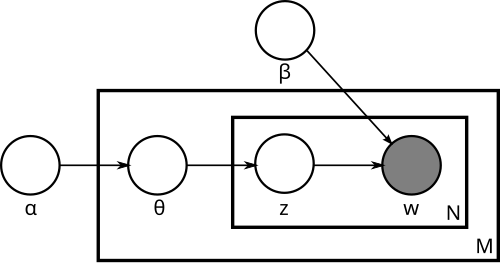
Сложные модели часто проще всего понимать так – давайте посмотрим, как модель будет генерировать новый документ:
Для простоты мы фиксируем число тем k и будем считать, что β – это просто набор параметров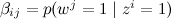 , которые нужно оценить, и не будем беспокоиться о распределении на N. Совместное распределение тогда выглядит так:
, которые нужно оценить, и не будем беспокоиться о распределении на N. Совместное распределение тогда выглядит так:
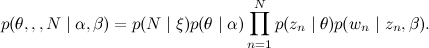
В отличие от обычной кластеризации с априорным распределением Дирихле или обычного наивного байеса, мы тут не выбираем кластер один раз, а затем накидываем слова из этого кластера, а для каждого слова сначала выбираем по распределению θ тему, а уже потом набрасываем это слово по этой теме.
На выходе после обучения модели LDA получаются векторы θ, показывающие, как распределены темы в каждом документе, и распределения β, показывающие, какие слова более вероятны в тех или иных темах. Таким образом, из результатов LDA легко получить для каждого документа список встречающихся в нём тем, а для каждой темы – список характерных для неё слов, т.е. фактически описание темы. Заметьте: всё это обучение без учителя (unsupervised learning), датасет из текстов размечать не надо!
Что же до того, как это всё работает, признаюсь честно – я не думаю, что в кратком хабрапосте можно доступно рассказать о том, как был организован вывод в исходной работе об LDA; он был основан на поиске вариационных приближений к распределению модели (мы упрощаем структуру модели, разрывая связи, но добавляя свободные переменные, по которым оптимизируем). Однако вскоре были разработаны гораздо более простые подходы, основанные на сэмплировании по Гиббсу; возможно, когда-нибудь я вернусь к этой теме, когда буду вести разговор о сэмплинге, но сейчас и для этого поля слишком узки. Давайте я просто оставлю здесь ссылку на MALLET – самую популярную и, насколько я могу судить, самую лучшую готовую реализацию LDA. MALLET’а вам хватит практически на все случаи жизни, разве что если захотите выделять темы из всего интернета целиком – на кластере MALLET, кажется, не умеет работать.
А я расскажу вам о том, как можно применить LDA в рекомендательной системе; этот метод особенно хорошо подходит для ситуации, когда «рейтинги» заданы не на длинной шкале из звёздочек, а просто бинарным «выражением одобрения», как like в Surfingbird. Идея достаточно простая: давайте рассматривать пользователя как документ, состоящий из понравившихся ему продуктов. При этом продукты становятся для LDA «словами», пользователи – «документами», а в результате выделяются «темы» предпочтений пользователей. Кроме того, можно оценить, какие продукты наиболее характерны для той или иной темы – то есть выделить группу продуктов, максимально релевантных для соответствующей группы пользователей, а также ввести из распределений на темах расстояния как на пользователях, так и на продуктах.
Мы применили такой анализ к базе данных Surfingbird.ru. и получили массу интересных тем – оказалось, что почти во всех случаях действительно выделяются группы сайтов, объединённые одной темой и достаточно похожие друг на друга. На картинках ниже я нарисовал статистику слов, часто встречающихся на страницах некоторых из тем, полученных при помощи LDA (при этом сам LDA работал не с текстами страниц, а только с предпочтениями пользователей!); ссылки на сами страницы я всё-таки на всякий случай вырезал.

Модель LDA решает классическую задачу анализа текстов: создать вероятностную модель большой коллекции текстов (например, для information retrieval или классификации). Мы уже знаем наивный подход: скрытой переменной является тема, и слова получаются при фиксированной теме независимо по дискретному распределению. Аналогично работают и подходы, основанные на кластеризации. Давайте чуть усложним модель.
Очевидно, что у одного документа может быть несколько тем; подходы, которые кластеризуют документы по темам, никак этого не учитывают. LDA — это иерархическая байесовская модель, состоящая из двух уровней:
- на первом уровне – смесь, компоненты которой соответствуют «темам»;
- на втором уровне – мультиномиальная переменная с априорным распределением Дирихле, которое задаёт «распределение тем» в документе.
Вот граф модели (картинка взята из википедии):
Сложные модели часто проще всего понимать так – давайте посмотрим, как модель будет генерировать новый документ:
- выбрать длину документа N (этого на графе не нарисовано – это не то чтобы часть модели);
- выбрать вектор
 — вектор «степени выраженности» каждой темы в этом документе;
— вектор «степени выраженности» каждой темы в этом документе; - для каждого из N слов w:
- выбрать тему
 по распределению
по распределению  ;
; - выбрать слово
 с вероятностями, заданными в β.
с вероятностями, заданными в β.
- выбрать тему
 — вектор «степени выраженности» каждой темы в этом документе;
— вектор «степени выраженности» каждой темы в этом документе; по распределению
по распределению  ;
; с вероятностями, заданными в β.
с вероятностями, заданными в β.Для простоты мы фиксируем число тем k и будем считать, что β – это просто набор параметров
, которые нужно оценить, и не будем беспокоиться о распределении на N. Совместное распределение тогда выглядит так: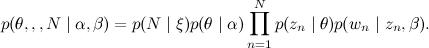
В отличие от обычной кластеризации с априорным распределением Дирихле или обычного наивного байеса, мы тут не выбираем кластер один раз, а затем накидываем слова из этого кластера, а для каждого слова сначала выбираем по распределению θ тему, а уже потом набрасываем это слово по этой теме.
На выходе после обучения модели LDA получаются векторы θ, показывающие, как распределены темы в каждом документе, и распределения β, показывающие, какие слова более вероятны в тех или иных темах. Таким образом, из результатов LDA легко получить для каждого документа список встречающихся в нём тем, а для каждой темы – список характерных для неё слов, т.е. фактически описание темы. Заметьте: всё это обучение без учителя (unsupervised learning), датасет из текстов размечать не надо!
Что же до того, как это всё работает, признаюсь честно – я не думаю, что в кратком хабрапосте можно доступно рассказать о том, как был организован вывод в исходной работе об LDA; он был основан на поиске вариационных приближений к распределению модели (мы упрощаем структуру модели, разрывая связи, но добавляя свободные переменные, по которым оптимизируем). Однако вскоре были разработаны гораздо более простые подходы, основанные на сэмплировании по Гиббсу; возможно, когда-нибудь я вернусь к этой теме, когда буду вести разговор о сэмплинге, но сейчас и для этого поля слишком узки. Давайте я просто оставлю здесь ссылку на MALLET – самую популярную и, насколько я могу судить, самую лучшую готовую реализацию LDA. MALLET’а вам хватит практически на все случаи жизни, разве что если захотите выделять темы из всего интернета целиком – на кластере MALLET, кажется, не умеет работать.
А я расскажу вам о том, как можно применить LDA в рекомендательной системе; этот метод особенно хорошо подходит для ситуации, когда «рейтинги» заданы не на длинной шкале из звёздочек, а просто бинарным «выражением одобрения», как like в Surfingbird. Идея достаточно простая: давайте рассматривать пользователя как документ, состоящий из понравившихся ему продуктов. При этом продукты становятся для LDA «словами», пользователи – «документами», а в результате выделяются «темы» предпочтений пользователей. Кроме того, можно оценить, какие продукты наиболее характерны для той или иной темы – то есть выделить группу продуктов, максимально релевантных для соответствующей группы пользователей, а также ввести из распределений на темах расстояния как на пользователях, так и на продуктах.
Мы применили такой анализ к базе данных Surfingbird.ru. и получили массу интересных тем – оказалось, что почти во всех случаях действительно выделяются группы сайтов, объединённые одной темой и достаточно похожие друг на друга. На картинках ниже я нарисовал статистику слов, часто встречающихся на страницах некоторых из тем, полученных при помощи LDA (при этом сам LDA работал не с текстами страниц, а только с предпочтениями пользователей!); ссылки на сами страницы я всё-таки на всякий случай вырезал.
 |
 |
 |
 |
 |
 |
