Разработчикам, только начинающим работать с Async/await, бывает довольно сложно разобраться в главной его особенности — неблокировании потоков. Из-за этого возникает непонимание, чем работа с потоками в Grand Central Dispatch (GCD) отличается от работы в Async/await, какие преимущества есть у Async/await перед GCD, а также когда их стоит использовать.
Я — Светлана Гладышева, iOS-разработчик компании Surf. В статье разберемся, что же такое неблокирование потоков и как оно работает. Сравним работу с потоками в GCD и в Async/await. На практике увидим, какие преимущества даёт Async/await при работе с большим количеством задач.
Что такое неблокирование потоков
Когда поток не блокируется, он не простаивает в ожидании, а выполняет другую задачу. Например, может делать что-то полезное, пока ждёт ответ от сервера. Реализуется это с помощью continuations.
Continuation — это специальный легковесный объект, который создается в Async/await для каждой выполняемой задачи. В момент, когда задача приостанавливается, continuation этой задачи внутри потока заменяется на continuation другой задачи: она начнёт выполняться в этом же потоке. Таким образом поток не ждёт и не простаивает, а продолжает работать.
Значения переменных и прочие данные, необходимые для продолжения работы, хранятся внутри continuation. Поэтому они легко восстанавливаются, когда задача продолжает выполняться.

Предположим, мы отправляем запрос на сервер. Когда начинается ожидание ответа, происходит приостановка: в поток передается другой continuation, который начинает выполняться. Когда приходит ответ с сервера, приостановленный continuation снова продолжает работать. Тут важно отметить, что поток, в котором продолжится выполнение, не обязательно будет тем же самым, в котором код выполнялся до прерывания.
Пример неблокирования потоков
Допустим, мы хотим запустить задачу 1000 раз. Давайте рассмотрим код, написанный с использованием GCD:
func run1000Tasks() {
for i in 0 ..< 1000 {
DispatchQueue.global().async {
sleep(1)
print(i)
}
}
}Если мы его выполним, увидим, что результат в консоли появляется постепенно. Задачи запускаются по мере того, как завершаются предшествующие.

При моём запуске этого кода использовалось 64 потока. Каждый из них ждал 1 секунду, а затем печатал цифру в консоль. Потом эти 64 потока освобождались и выполняли следующую задачу: снова ждали 1 секунду и печатали цифру в консоль. И так далее. В итоге для выполнения 1000 задач понадобилось 13 секунд.
Поток блокирует операция sleep. Поэтому каждому потоку приходится простаивать в ожидании и только потом браться за следующую задачу.
Давайте рассмотрим похожий код, но с использованием Async/await:
func run1000Tasks() {
for i in 0 ..< 1000 {
Task {
try? await Task.sleep(nanoseconds: 1_000_000_000)
print(i)
}
}
}Если запустить этот код, приблизительно через секунду весь результат будет в консоли.
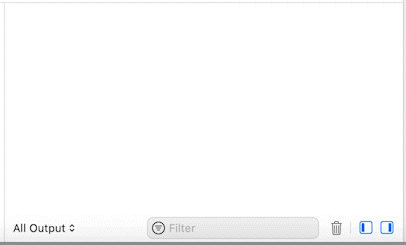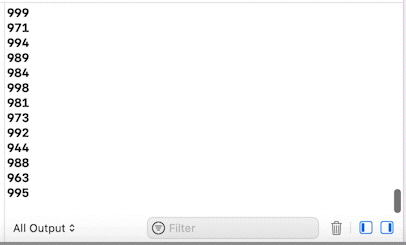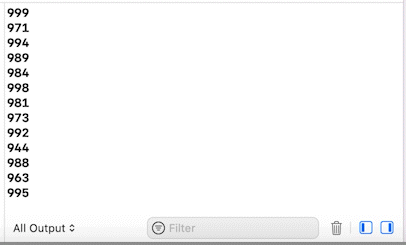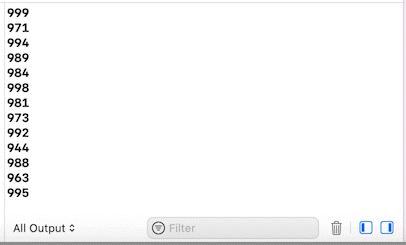
В этом случае при моём запуске использовалось всего 6 потоков. Но поскольку Task.sleep — операция, которая не блокирует поток, то каждый поток не ждал 1 секунду, а сразу же брал следующую задачу. Таким образом, из-за неблокирования потоков тысяча задач выполнилась намного быстрее.
Всегда ли потоки не блокируются
Бывают ситуации, когда потоки в Async/await всё же будут заблокированы: это зависит от того, что мы используем в async-задачах.
Вернёмся к предыдущему примеру, но заменим в нём строку try? await Task.sleep(nanoseconds: 1_000_000_000) на sleep(1):
func run1000Tasks() {
for i in 0 ..< 1000 {
Task {
sleep(1)
print(i)
}
}
}Запустив код, мы увидим, что потоки блокируются: результат в консоли появляется постепенно, как было в примере с использованием GCD. Только в этом случае используется меньше потоков, поэтому итоговый результат получим ещё медленнее.
Пример: как неблокирование потоков может существенно ускорить работу приложения
Рассмотрим более сложный пример. Предположим, что есть очень большое количество фотографий и нужно их обработать. Результат обработки фотографии сохраним в базу данных.
Введём два условия. Первое: сохранение — это долгий процесс. Второе: наша работа с базой данных не потокобезопасна, а значит, сохранение нескольких результатов не может выполняться одновременно.
На GCD код для обработки будет выглядеть так:
func processPhotos(photos: [Photo], completion: @escaping () -> Void) {
let group = DispatchGroup()
for photo in photos {
group.enter()
concurrentQueue.async { [weak self] in
guard let self = self else { return }
let processedPhoto = self.processPhoto(photo)
self.serialQueue.async {
self.savePhoto(photo: processedPhoto)
group.leave()
}
}
}
group.notify(queue: .main) {
completion()
}
}Здесь используются два метода, код которых я не привожу: processPhoto — для обработки картинки, savePhoto — для сохранения картинки. Для сохранения используется последовательная очередь, поскольку операция сохранения не потокобезопасна.
На Async/await код для обработки фотографий будет выглядеть так:
func processPhotos(photos: [Photo]) async {
await withTaskGroup(of: Void.self) { group -> Void in
for photo in photos {
group.addTask { [weak self] in
guard let self = self else { return }
let processedPhoto = self.processPhoto(photo)
await self.savePhoto(photo: processedPhoto)
}
}
}
}Метод processPhoto здесь такой же, как и в примере с GCD. А метод savePhoto — другой, неблокирующий. В нём должен быть вызван async-метод для сохранения в базу данных. Например, если используем Core Data, это будет метод perform из класса NSManagedObjectContext, который появился в iOS 15.
Кроме того, в методе savePhoto нужно сделать что-то, чтобы сохранение не могло выполняться параллельно. Просто actor для этих целей не подойдет: при приостановке задачи внутри метода actor может начать выполнять этот же метод, вызванный из другой задачи. Можно использовать семафор, написанный специально для Async/await и не блокирующий потоки. Например, AsyncSemaphore из github.com/groue/Semaphore.
Если запустить код примера, увидим, что сохранение выполняется только после обработки всех фотографий. Так происходит потому, что задача на обработку попадает в очередь на выполнение раньше, а приоритет у них одинаковый. Если мы хотим, чтобы сохранение результата запускалось сразу же после обработки фото, нужно установить приоритет выше, чем у обработки. Например, вот так:
func processPhotos(photos: [Photo]) async {
await withTaskGroup(of: Void.self) { group -> Void in
for photo in photos {
group.addTask { [weak self] in
guard let self = self else { return }
let processedPhoto = self.processPhoto(photo)
let savingTask = Task(priority: .high) {
await self.savePhoto(photo: processedPhoto)
}
try await savingTask.value
}
}
}
}При этом Task, в котором запускается processPhotos, должен иметь приоритет ниже, чем savingTask.
Давайте теперь сравним код на GCD и код на Async/await. Если запустим оба варианта, увидим, что вариант с Async/await выполняется намного быстрее. То, насколько быстрее, зависит от количества фотографий и от реализации методов processPhoto и savePhoto. В варианте с GCD используется намного больше потоков, но многие из этих потоков блокируются, когда ждут сохранения результата. В варианте с Async/await используется мало потоков, которые не ждут, когда закончится сохранение, а продолжают работать.
Таким образом, на более сложном примере мы увидели, что неблокирование потоков может существенно ускорить работу приложения.
Почему используется разное количество потоков в GCD и Async/await
В примерах выше мы увидели, что при запуске кода с использованием GCD и кода с использованием Async/await используется разное количество потоков. Давайте разберёмся, почему так происходит.
Для начала вспомним, как происходит работа с потоками в GCD. У GCD есть определенный пул потоков, и всё управление потоками он делает за нас. Когда задача помещается в очередь, GCD для её выполнения берёт поток из своего пула.
Если нужно выполнять много задач, GCD будет сначала использовать столько потоков, сколько есть ядер в системе. Но если поток по каким-то причинам заблокируется, GCD может выделить ещё один поток. Если ещё один поток заблокируется, GCD выделит ещё один — и так далее.
Недостаток такого подхода в том, что потоков в итоге может стать слишком много. Вполне возможны ситуации, когда в приложении используется несколько сотен потоков. Переключение между потоками — context switch — довольно долгая и затратная операция, поэтому большого количества context switch нужно избегать. А если потоков очень много, большое количество переключений между ними сильно увеличит время выполнения.
Что же нужно для максимально эффективной работы? Нам нужно столько потоков, сколько есть ядер в системе. Если их будет больше, придётся тратить время на context switch между потоками. Также нужно избегать блокирования потоков, чтобы не тратить время на пустое ожидание.
Всё это возможно в Async/await. Так как в Async/await потоки могут не блокироваться, пул потоков сделали таким образом, что количество потоков не может превышать количество ядер. Такой подход минимизирует количество context switch и оптимизирует работу с потоками.
Важно помнить, что главный поток — не часть этого пула потоков, поэтому переключения между потоками и context switch всё равно возможны. Для максимально эффективной работы таких переключений следует избегать.
Пример с большим количеством переключений
Давайте теперь на примере посмотрим, как большое количество потоков может влиять на производительность.
Предположим, нужно реализовать лог, в который можно записывать все события в приложении. Будем считать, что запись в лог не потокобезопасна, поэтому нужно сделать так, чтобы не могло сохраняться более одной строки одновременно.
Для наглядности эксперимента создадим 50 тысяч задач. В каждой из них будем писать строку в лог.
Так выглядит код с использованием GCD:
func writeManyStringsToLog(completion: @escaping () -> Void) {
let group = DispatchGroup()
for _ in 0 ..< 50000 {
group.enter()
concurrentQueue.async { [weak self] in
self?.logger.write(string: "Some string") {
group.leave()
}
}
}
group.notify(queue: .main) {
completion()
}
}
Запись в лог выглядит вот так:
func write(string: String, completion: @escaping () -> Void) {
serialQueue.async { [weak self] in
self?.writeToLog(string)
DispatchQueue.main.async {
completion()
}
}
}Здесь writeToLog — метод, в котором происходит сама запись в лог.
Давайте теперь посмотрим на код с использованием Async/await:
func writeManyStringToLog() async {
await withTaskGroup(of: Void.self) { group in
for _ in 0 ..< 50000 {
group.addTask { [weak self] in
await self?.logger.write(string: "Some string")
}
}
}
}
Здесь запись в лог выглядит вот так:
actor Logger {
func write(string: String) async {
writeToLog(string)
}
} Actor тут используется для того, чтобы сделать запись в лог потокобезопасной. Метод writeToLog используется тот же самый, что и в коде выше.
Запускаем оба примера: вариант с использованием GCD выполняется заметно дольше, чем вариант с Async/await. Так происходит из-за того, что в GCD используется очень много потоков. При моем запуске кода использовалось более 220 потоков, а само выполнение заняло около 36 секунд. Большое количество context switch при таком количестве потоков занимает действительно много времени.
В варианте с Async/await выполнение кода у меня заняло около 30 секунд. В этом случае используется ограниченное количество потоков, поэтому проблемы не возникает.
Async/await позволяет оптимально использовать потоки: можно существенно ускорить обработку больших данных, а также выполнение большого количества задач. Но поскольку Async/await использует ограниченное количество потоков, их легко занять задачами, которые блокируют поток. Поэтому для задач, блокирующих поток, лучше использовать GCD.
Сравнивая код на GCD и на Async/await, вы наверняка заметили, что код на Async/await занимает меньше строк кода и его проще читать. В нем не используются колбэки, поэтому код становится более последовательным. Это ещё одно важное преимуществом Async/await по сравнению с GCD.
Больше полезного про iOS — в нашем телеграм-канале Surf iOS Team. Публикуем кейсы, лучшие практики, новости и вакансии Surf. Присоединяйтесь >>
Больше кейсов команды Surf ищите на сайте >>
