

С 9 по 13 августа в г. Сантьяго (Чили) прошла 38я международная научная конференция по информационному поиску ACM SIGIR. Представляем вашему вниманию основные события данного мероприятия и ключевые тренды развития области информационного поиска как с точки зрения академической среды, так и индустрии.
ACM SIGIR — это главный научный форум года, на котором ведущие исследователи в области информационного поиска представляют свои результаты. Все научные работы проходят строгий конкурсный отбор в рамках традиционного процесса рецензирования (в данном случае — double blind, то есть авторы и рецензенты должны соблюдать анонимность). Спонсорами конференции по традиции стали крупнейшие поисковики и другие компании, заинтересованные в развитии поисковых технологий: Baidu, Microsoft, Google, Yahoo, eBay, Facebook, IBM, Yandex.
Место проведения
Конференция проводилась в столице Чили городе Сантьяго в здании Католического Университета. Выбор столь экзотичного места проведения был обусловлен присутствием здесь филиала Yahoo! Labs, а также статусом его главы — известного чилийского исследователя Рикардо Баезы-Йейтса.

Сантьяго — город контрастов: наряду с красивыми историческими зданиями, здесь легко можно встретить в центре города допотопные высотки. Возможным оправданием невыдержанности стиля являются частые землетрясения. Есть в столице и весьма неблагополучные районы, в которых велик риск быть ограбленным. Из-за природных особенностей (город находится в долине, окруженной горной грядой) смог — обычное явление для Сантьяго. Для комфортного общения необходим базовый испанский язык, так как знания английского совершенно не хватает. В сувенирных лавках — дикая мешанина из индейских атрибутов, статуэток моаи с острова Пасхи, портретов коммуниста Альенде и христианских символов. Люди — приветливые и доброжелательные. В целом не покидает ощущение, что ты находишься в типичной Латинской Америке, местами очаровательной, местами не очень.

Туториалы
Конференцию открыли девять кратких обучающих курсов по разным темам информационного поиска. Довольно интересным оказался туториал по длинным поисковым запросам (Information Retrieval with Verbose Queries), прочитанный Манишем Гуптой (Bing) и Михаилом Бендерским (Google). Туториал представлял подходы к разрешению длинных запросов, которые, как правило, ведут к пустым результатам (null queries). Эти запросы не редкость в вопросно-ответных системах (в т.ч. CQA сервисах, таких как Quora или Ответы@Mail.ru), enterprise search, e-commerce search, приложениях голосового поиска (Cortana, Siri, Google Now).
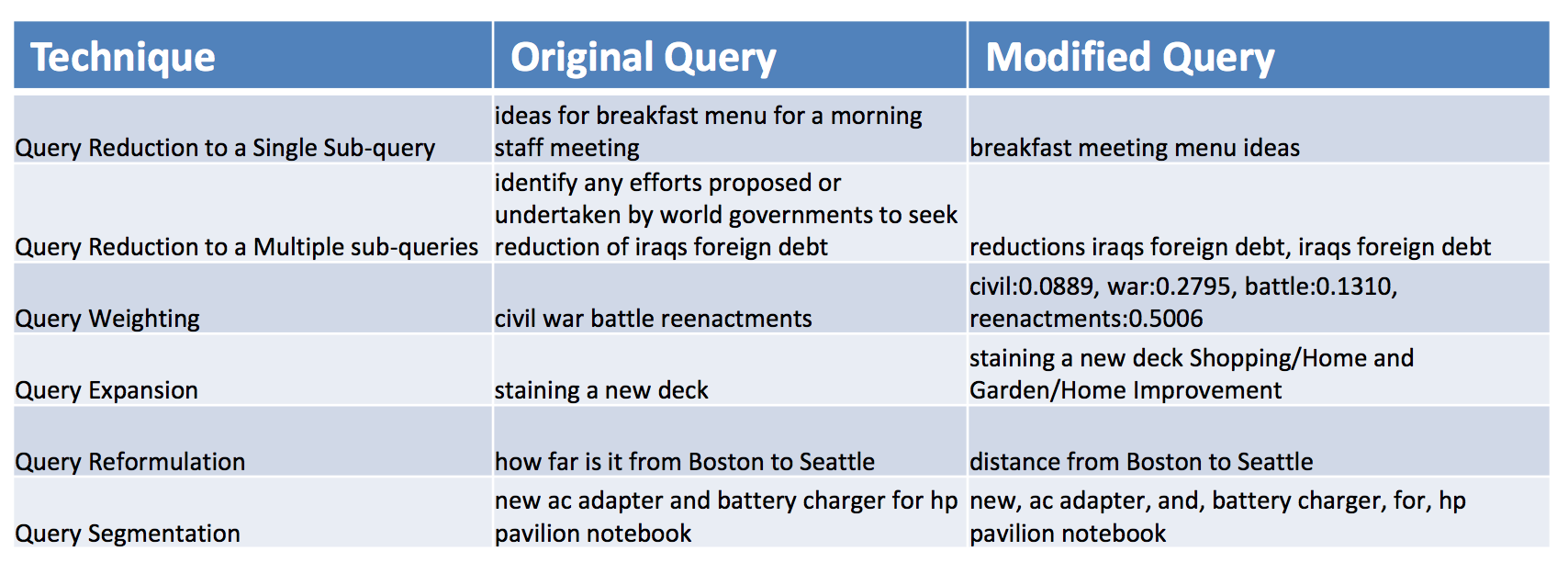
Согласно авторам туториала, основные подходы включают следующие техники:
- уменьшение запроса (query reduction) через сведение к одному или нескольким подзапросам за счет: выделения отдельных слов, комбинаций, именных групп, именованных сущностей, слов из персональных логов запросов
- взвешивание некоторых терминов или концептов (см. модель WSD)
- расширение запроса (см модель PCE)
- переформулирование запроса: на основе вероятностных языковых моделей и логов запросов
- сегментация запроса: на основе статистики n-gram.
Основная программа
Следующие три дня были посвящены докладам основной программы конференции. В этом году уровень принятия статей в основную программу составил 20%, то есть была принята каждая пятая статья из отправленных на рецензию. Что является обычным уровнем для конференций класса A+ (по рейтингу CORE).
Кстати, спонсоры оплатили бесплатный доступ к полным текстам статей, и любой желающий может ознакомиться с принятыми работами. Как обычно, было много качественных статей, поэтому в этом обзоре расскажу только о статьях, получивших награды, и отдельно — на секции deep learning.

Приз за лучшую статью получил коллектив ученых из ISTI–CNR, университетов Пизы и Венеции. Они предложили алгоритм QuickScorer, использующий особое бинарное представление для деревьев и побитовые логические операции и, как следствие, ускоряющий (на практике — более чем на 50%) применение обученных аддитивных ансамблей регрессионных деревьев. Это важное достижение, учитывая практическую силу таких моделей, как Lambda-MART и Gradient Boosted Regression Trees (GBRT). Последняя модель, как известно, лежит в основе MatrixNet Яндекса.
Следующий приз — что приятно! — ушел в Россию. Приз за лучшую статью, написанную студентом (Best Student Paper Award), получил коллектив авторов из Яндекса во главе с Евгением Харитоновым (Евгений — аспирант университета Глазго и сотрудник Яндекса). Эта работа показывает то, как можно проводить эксперименты по сравнительному оцениванию качества поиска в сжатые сроки с помощью аппарата статистических тестов. Подход применим как при A/B тестировании, так и для interleaving.
Наконец, остановимся на секции, посвященной такому модному в наши дни направлению, как приложения глубоких нейронных сетей (deep learning). Стоит отметить, что прорывные улучшения производительности, достигнутые с помощью моделей deep learning, объективно имеют место только в областях распознавания изображений и речи, а вот успехи deep learning в обработке естественного языка и информационном поиске все еще менее убедительны. В то же время одно из основных преимуществ deep learning — избавление от ручного моделирования эффективных характеристик для представления данных (feature engineering) — заставляет обращать внимание на эти подходы и в поиске, и в NLP. Тем более, как показывают следующие работы, улучшения и в этих областях становятся все более значительны.
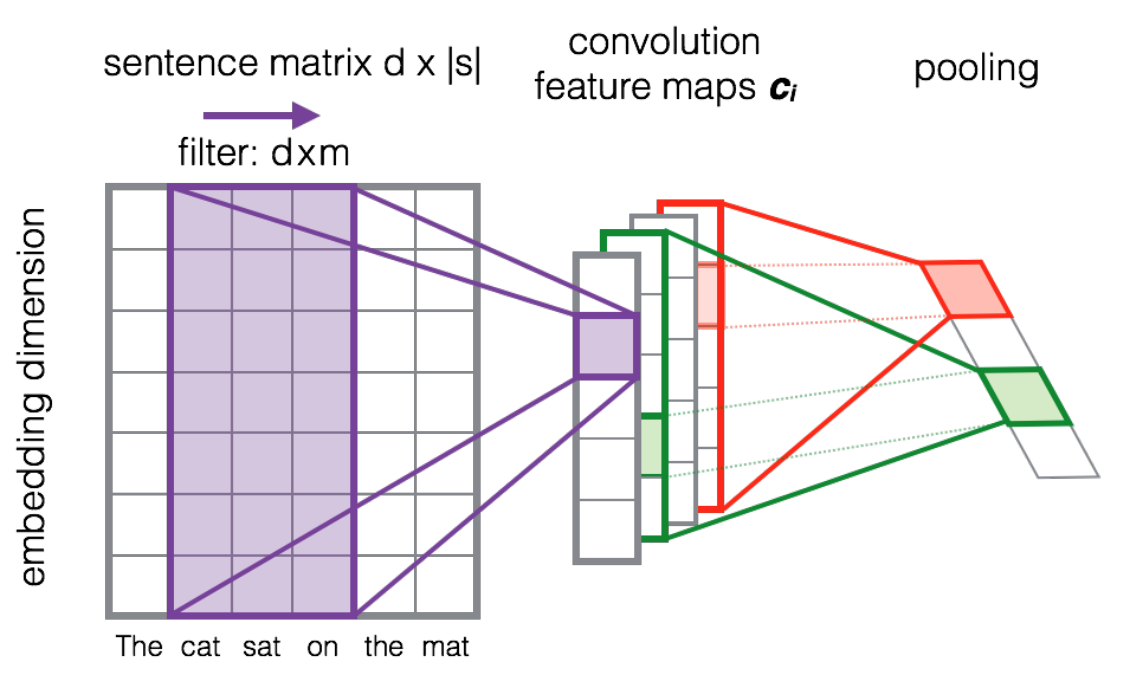
Выясняется, что сверточные нейронные сети (convolutional neural nets), традиционно используемые для распознавания изображений, получили неожиданное развитие для задач обработки текста (первые работы появились буквально в прошлом году). Они дают способ представления исходных предложений в векторном пространстве меньшей размерности при сохранении синтаксических и семантических характеристик. Таким образом, на вход сети (см. рисунок) подается матрица, составленная по столбцам из векторов в скрытом пространстве (embeddings) слов в предложении. В качестве последних можно взять word embeddings из word2vec. Следующий этап — свертка матриц предложений, т.е. поэлементное произведение вертикальных слоев матрицы предложения и фильтрационной матрицы (в случае deep learning используется множество фильтрационных векторов) и агрегирование этих результатов суммированием. Далее, результат пропускается через нелинейную функцию активации (в этом случае — ReLU). Операция объединения (pooling) — обычный максимум.
Алиаксей Северин (Google) и Алессандро Мосчитти (University of Trento, QCRI) в работе Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks показали то, как расширить эту архитектуру для задачи ранжирования коротких текстов в вопросно-ответной системе. При этом и запрос, и документ переводятся в единое представление (общий вектор), а взаимодействия его компонентов моделируются через дополнительный скрытый слой в нейронной сети.
В работе Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings показано то, как расширить модель word embeddings на случай выравненных корпусов для задачи межъязыкового поиска (cross-language information retrieval). Примеры таких корпусов — статьи в Википедии на разных языках. Основная идея — смешивание опорных слов и контекстов из выравненных документов для обучения стандартной skip-gram модели Миколова, предсказывающей контекст по опорным словам в предложении. Предложенная модель релевантности основана на косинусной мере близости векторов запроса и документов, построенных по принципу линейной комбинации word embeddings.
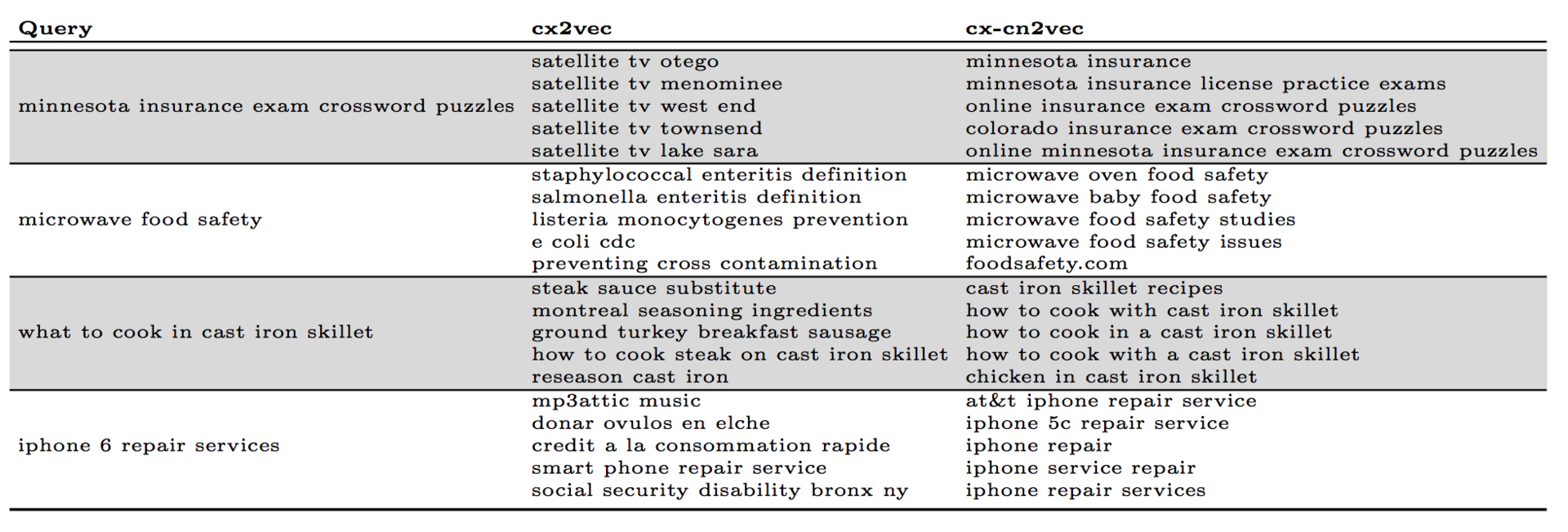
Коллектив исследователей из Yahoo! Labs предложил новые модели получения word embeddings, адаптированных для задачи показа рекламных объявлений в спонсированном поиске (основная проблема сопоставить рекламное объявление запросам, для которых нет точного сопоставления по терминам): context2vec, content2vec, context-content2vec. Context2vec применяет ту же skip-gram модель, только в качестве «слов» рассматриваются запросы, а «предложений» — пользовательские сессии из логов поисковой системы. В случае content2vec авторы возвращаются к более традиционному представлению, когда «слова» — термины из запроса, «предложения» — текст запроса. Последняя модель — комбинация этих двух. Примеры работы моделей:
Наконец, Гуочинг и Каллан (Университет Карнеги-Меллон) исследовали применение word embeddings для взвешивания терминов в классических моделях — языковых моделях, SDM и BM25. Показанный прирост производительности — до 9% (по MAP) для BM25 и до 22% для языковых моделей на стандартных TREC коллекциях.
Из инструментов, используемых для реализации глубоких нейронных сетей, в основном используют Theano за большую гибкость. Torch рассматривается как более высокоуровневая библиотека и больше подходит для индустрии, хотя и сложнее для кастомизации.
Наш научный вклад
Это совместная работа коллектива авторов из Университета Уэйна (США), Казанского федерального университета и Textocat. Мы представили новую модель ранжирования для структурированных документов FSDM, которая является обобщением известной модели смеси языковых моделей (mixture of language models, MLM), учитывающей веса полей документа, и модели последовательной зависимости терминов из запроса (sequential dependence model, SDM), выводимой на основе теории марковских случайных полей. Формула ранжирования выглядит следующим образом:
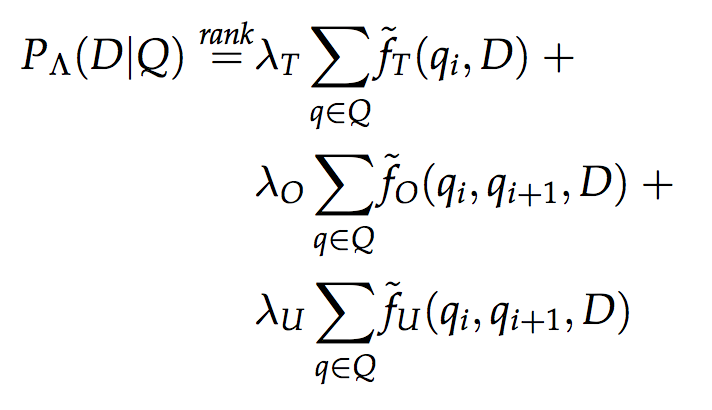
где пометка T используются для обозначения терминов, последовательных биграм (O) и биграм в рамках окна (U) из поискового запроса. А f — оценка появления терминов (или биграм) из запроса в документе на основе смеси языковых моделей полей документа:
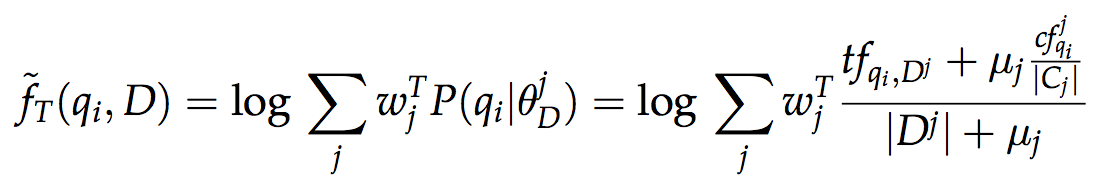
Параметры модели (веса полей w и веса λ) могут быть выставлены вручную (например, в некоторой схеме документов из двух полей: w(title)=0.8, w(body)=0.2, и стандартными весами для SDM: λ=(0.8,0.1,0.1)), а при наличии тренировочного множества могут обучаться простым двухступенчатым алгоритмом на основе метода координатного подъема (coordinate ascent), оптимизирующим непосредственно целевую меру оценивания качества поиска (например, MAP), как предложено в статье.
Новая модель показала свою эффективность в сценарии поиска сущностей (entity search) в Вебе данных (в т.ч. по сравнению с широко известной моделью BM25F), и в то же время ее применимость распространяется на любые приложения поиска по структурированным документам с несколькими полями (multi-fielded documents). Примерами таких приложений являются email сообщения (заголовок, тело письма) и описания товаров в e-commerce (наименование, категория, аннотация, вендор). Открыты полный текст статьи, исходный код и файлы запусков на GitHub и слайды презентации.
Постеры
Постер-сессия — отдельный интересный формат представления результатов, которые еще не доведены до полной статьи. И в этом году могу выделить сразу несколько запоминающихся работ. В первую очередь, это продолжение работы Карстена Эйхоффа (сейчас — ETH, ранее — Delft University of Technology) по применению копул для информационного поиска. В работе «Modelling Term Dependence with Copulas» Карстен и его научный руководитель Арьен де Врис показывают, что копулы могут эффективно использоваться для выделения зависимостей в появлениях терминов в документе, что полезно при определении значимых биграм из поискового запроса. Кроме того, выделю работы Twitter Sentiment Analysis with Deep Convolutional Neural Networks (упомянутые Северин и Мосчитти применяют рассмотренные сверточные нейронные сети для задачи анализа тональности), Relevance-aware Filtering of Tuples Sorted by an Attribute Value via Direct Optimization of Search Quality Metrics (подход к ранжированию по релевантности при фильтрации по атрибуту — важная задача для e-commerce поиска).
Индустрия
В индустриальном треке были доклады от Microsoft по краудсорсингу и использованию геолокаций в коммерческом поиске; Yahoo о трудностях вертикального поиска (новостей, e-commerce); Яндекса об аспектах онлайн оценивания качества поиска; Bloomberg о том, как компания применяет обработку естественного языка, машинное обучение ранжированию, краудсорсинг в области финансовых приложений; Booking.com о персонализации при рекомендации туристических направлений и LinkedIn об устройстве поиска в самой большой профессиональной социальной сети.

Представители Microsoft Research продемонстрировали возможности поисковика Bing по контекстуализации поиска сущностей (у Microsoft есть своя knowledge base — Satori) в рамках пользовательской сессии. Цепочка запросов выглядела следующим образом: «том круз», «жена тома круза?», «каков ее рост». А также они аннонсировали WSDM Cup Challenge, соревнование по оценке важности научных публикаций в графе академической предметной области Microsoft Academic Graph. Смысл задачи — предложить более нетривиальные характеристики, чем обычное количество цитат, используя доступную семантическую информацию.
Заключение
ACM SIGIR становится все более индустриальной конференцией (в этом году 41% статей от представителей индустрии!). Это оказывает существенное влияние на распределение тем для исследования: наблюдается больший уклон в сторону исследований поведения пользователей и оценивания поиска. Кроме того, под влиянием развития теории и инструментов deep learning все большее распространение получают модели поиска на основе адаптированных word embeddings. Наконец, несмотря на развитие баз знаний (Wikidata, DBpedia, Freebase, Google Knowledge Graph, Satori, Facebook Graph), в дефиците работы, предлагающие новые модели использования баз знаний для улучшения качества поиска.
