Мы в Dropbox считаем, что управление инцидентами — это центральный элемент нашей системы по обеспечению надёжности. И хотя мы также используем проактивные методы, такие как хаос-инжиниринг (сhaos engineering), то, как мы реагируем на инциденты существенное влияет на опыт наших пользователей. Во время потенциального сбоя сайта или проблемы с продуктом на счету каждая минута.
Ключевые компоненты нашего процесса управления инцидентами существуют уже несколько лет, но мы видим возможности для постоянного развития в этой области. Изменения, которые мы внесли с течением времени, включают в себя как технологические, так и организационные, и процедурные улучшения.
В этом посте мы расскажем подробно о нескольких уроках, которые Dropbox вынесли из опыта управления инцидентами. Вероятнее всего, не каждый из пунктов можно найти в методичке по структуре управления инцидентами, и не стоит думать, что эти улучшения универсальны для любой компании. (Полезность этих уроков зависит от вашего технологического стека, размеров организации и других факторов). Вместо этого мы надеемся, что эта статья послужит примером, как вы можете систематически анализировать реакцию на инциденты в вашей компании и улучшать её так, чтобы удовлетворить потребности ваших пользователей.
1. Предпосылки
Базовая структура для управления инцидентами в Dropbox называется SEV'ы (от слова SEVerity — серьёзность), и она похожа на то, что используется в большинстве других SaaS-компаний. (Для тех, кто не очень разбирается, рекомендуем ознакомиться с серией туториалов по этой теме).
SEV'ы доступности, несмотря на то, что это и не единственный тип критических инцидентов, полезно изучить особенно подробно. Ни один из онлайн-сервисов не застрахован от таких инцидентов, включая Dropbox. Критические инциденты доступности часто являются самыми разрушительными для наибольшего числа пользователей — просто вспомните какую-нибудь недавнюю ситуацию, когда один из ваших любимых сайтов или SaaS-приложений упал — и мы считаем, что эти SEV'ы создают самую большую нагрузку на скорость нашей реакции. Успех означает максимальное уменьшение количества минут нашего ответа.
Мы не только тщательно измеряем время воздействия для наших SEV'ов, для этой метрики есть и реальные бизнес-последствия. Каждая минута без нашей реакции на инцидент — это больше недовольных пользователей, увеличение оттока, снижение числа регистраций, а также ущерб для репутации от освещения ситуации в социальных сетях и прессе. Кроме того, в контрактах с некоторыми нашими клиентами, особенно в критически важных отраслях, Dropbox обязуется обеспечить бесперебойный доступ к услугам. Этот показатель определяется на основе общей доступности систем, обслуживающих клиентов, и мы официально объявляем, что "упали", когда уровень доступности становится ниже определенного порога. Чтобы не выходить за рамки 99.9% времени безотказной работы, обговоренного в SLA, у нас есть возможность падать не более чем на на 43 минуты в месяц. Внутри компании мы установили даже более высокую планку — 99.95% (и это 21 минута в месяц).
Чтобы гарантировать такие показатели, мы инвестировали в различные методы предотвращения инцидентов. Некоторые из них — хаос-инжиниринг, оценка рисков, а также валидация требований к системе. Однако, как бы мы ни старались понять наши системы, SEV'ы всё равно будут происходить. И здесь в игру вступает управление инцидентами.
2. Обработка SEV
Этап обработки SEV в Dropbox определяет, как различные специалисты по реагированию на инциденты должны работать вместе чтобы смягчить последствия SEV, и какие шаги следует предпринять, чтобы извлечь из ситуации урок.
Для расследования каждого SEV необходимо определить следующие вещи:
Тип SEV, классифицирующий направление воздействия инцидента; самые знакомые нам — это Доступность, Надёжность, Безопасность и Деградация Функций.
Уровень SEV от 0-3, определяющий критичность. 0 — самый критичный.
IMOC (Incident Manager On Call — Менеджер инцидента), человек, ответственный за быстрое устранение последствий, координирование SEV-специалистов и информировании о статусе инцидента.
TLOC (Tech Lead On Call — Технический специалист), руководящий исследованием инцидента и принимающий технические решения.
В обработке SEVов, которые касаются непосредственно пользователей, также участвует BMOC (Business Manager On Call — Управляющий делами), который занимается не-инженерными вопросами, обеспечивая необходимые внешние оповещения. В зависимости от ситуации это могут быть обновления страницы состояния, прямое общение с клиентами и, в редких случаях, с регулирующими органами.
Мы в Dropbox создали свой собственный инструмент для управления инцидентами: DropSEV. Любой сотрудник может зарегистрировать SEV, что инициирует назначение вышеописанных ролей и создаёт набор каналов связи для обработки инцидента. К ним относятся канал в Slack для совместной работы в реальном времени, email-тред для более общих обновлений, тикет в Jira для сбора артефактов, а также предзаполненный документ для постмортема, который пригодится на ретроспективе. Также можно подписаться на канал в Slack или email-рассылку с уведомлениями о новых SEVах. На картинке — пример создания заявки о незначительном нарушении доступности мобильного приложения.

Как только заявка в DropSEV создана, начинается процесс обработки.

Обнаружение: время, необходимое для выявления проблемы и оповещения ответственных за исправление (респондентов на инцидент)
Диагностика: время, необходимое респондентам для выявления первопричины проблемы и/или поиска её решения
Восстановление: время, необходимое для устранения проблемы для пользователей
Помните о нашем ограничении в 21 минуту в месяц? Не очень-то много, чтобы обнаружить, продиагностировать и восстановить работу после сложных неполадок. Мы были вынуждены оптимизировать каждый из трёх этапов, чтобы уложиться в ограничение.
3. Обнаружение
время, необходимое для выявления проблемы и оповещения ответственных за исправление
Надежная и эффективная система мониторинга
Когда в Dropbox дело доходит до обнаружения проблем, наши системы мониторинга являются ключевым компонентом. За годы работы мы построили и усовершенствовали несколько систем, на которые инженеры полагаются во время инцидента. Первая и самая важная — это Vortex, система метрик и оповещений на стороне сервера. Vortex гарантирует, что задержка при получении данных будет измеряться в секундах, частоту дискретизации 10 секунд и простой интерфейс для создания персональных уведомлений для конкретных сервисов.
Эти функции — основные для задачи сокращения времени обнаружения проблем в продакшене. В предыдущем посте мы рассказывали про архитектуру приложения, вспомним о ней здесь.
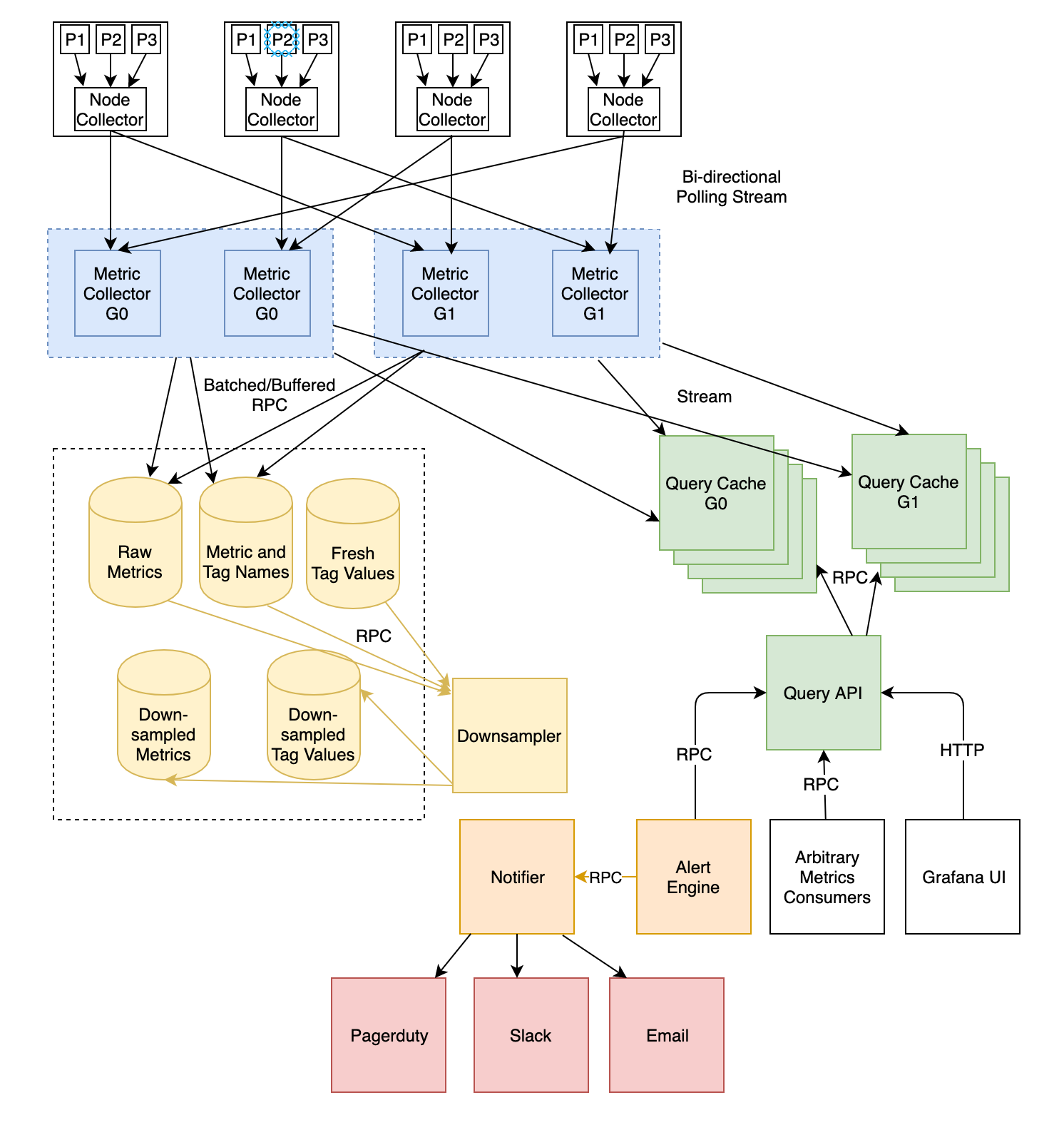
В 2018 году мы модернизировали эту систему, что стало основой наших усилий по обеспечению надёжности. Чтобы понять почему, вспомните о "правиле 21 минуты", которое мы ввели внутри компании. Нам важно было быть уверенными, что в течение первых десяти секунд после происшествия Vortex оповестит о нём всех ответственных респондентов через PagerDuty. Если бы Vortex был ненадёжным или слишком медленным, наша реакция на инцидент была бы заторможена уже до того как мы начали заниматься им.
Вашей компании не обязательно использовать самодельную систему мониторинга, как у нас, однако спросите себя: как быстро вы получаете информацию о том, что инцидент произошёл, чтобы начать реагировать?
Оптимизация метрик и уведомлений
Vortex — главный в быстром оповещении об авариях, однако он бесполезен без четко определённых метрик, о которых следует оповещать. Во многих смыслах это сложная проблема, поскольку для каждого отдельного случая обязательно будут использоваться отдельные метрики, которые команде придётся добавлять вручную.
Мы постарались снизить нагрузку на владельцев сервисов, предоставив им большое количество бесплатных метрик приложения, времени выполнения и хоста. Эти метрики встроены в наш RPC-фреймворк Courier, а также в инфраструктуру на уровне хоста. Вдобавок к множеству стандартных метрик, Courier так же обеспечивает распределенную трассировку и профилирование, что ещё больше упрощает сортировку инцидентов. Набор метрик в Courier доступен для всех языков, которые мы используем в Dropbox (Go, Python, Rust, C++, Java).
Хотя эти готовые метрики бесценны, бесконечное число оповещений тоже является частой проблемой, затрудняя определение, где действительно случилось что-то страшное. Мы предлагаем несколько инструментов для облегчения этой боли. Самая мощная — это система зависимостей уведомлений, с помощью которой владельцы сервисов могут связать свои уведомления со сторонними, и отключить оповещение если проблема связана с какой-то общей зависимостью. Это позволяет командам избежать уведомления о проблемах, которые не находятся в зоне их ответственности, и больше внимания уделять истинным проблемам.
Исключение человеческого фактора из регистрации инцидентов
Наши команды получают множество уведомлений в PagerDuty о состоянии сервисов, однако не каждое из них "достойно SEVа". Раньше это означало, что первый респондент, получивший оповещение об инциденте, должен был побеспокоиться не только о самом происшествии, но и о том, достойно ли оно заполнения SEVа и запуска формального процесса управления инцидентами.
Не всегда отличия очевидны, особенно для тех, у кого не так много опыта работы в команде реагирования. Чтобы облегчить принятие решения, мы переработали DropSEV (инструмент управления инцидентами, описанный выше) так, чтобы он отображал описания SEVов непосредственно для пользователей. Например, если вы выбрали "Доступность" как тип SEVа в DropSEV, он выведет таблицу вроде этой, чтобы помочь вам сопоставить степень глобального влияния на доступность с уровнями SEV.

Это был шаг вперёд, однако мы поняли, что принятие решения "нужно ли здесь регистрировать SEV?" по-прежнему замедляет наших респондентов. Представьте, вы дежурите по фронтенд-компоненту Magic Pocket, нашей собственной мультиэкзабайтной системы хранения данных, которая отвечает за обработку запросов Get и Put для блоков данных. Когда приходит уведомление об аварии, вам приходится задавать себе следующие вопросы:
снижается ли доступность?
насколько?
влияет ли это на глобальную доступность? (и где, блин, дэшборд, на котором это посмотреть)
насколько? как это соотносится с таблицей SEV?
Не самая простая процедура, если только вы не высококвалифицированный специалист по реагированию на инциденты и видели уже тонну SEVов до этого. И даже если так, это заняло бы у вас пару минут — из тех драгоценных двадцати одной. Пару раз SEVы просто не регистрировались, то есть мы упустили возможность привлечь IMOC и BMOC, пока техническая группа работала над восстановлением доступности.
Поэтому этим летом мы начали автоматически регистрировать все SEVы, связанные с доступностью. Владелец сервиса по-прежнему получает свои системные оповещения, однако DropSEV обнаружит влияние на доступность, достойное SEVа, и автоматически запустит процесс реагирования на инцидент. Владельцам сервиса больше не придется отвлекаться на заполнение форм, а у нас появилась бОльшая уверенность, что все роли, ответственные за реагирование на инцидент, будут задействованы в процессе. И что особенно важно, мы сэкономили себе еще несколько минут для каждого SEVа доступности.
А где вы можете исключить принятие решения человеком в вашем собственном процессе реагирования на инциденты?
4. Диагностика
время, необходимое респондентам для выявления корня проблемы и/или определения подхода к её устранению
Общие стандарты дежурства
На этапе диагностики нам часто необходимо привлекать дополнительных людей на помощь к изначально назначенным на событие людям. Мы добавили кнопку "Вызвать на помощь" в нашу внутреннюю директорию, чтобы человек мог при необходимости эффективно связываться с другой командой. Это ещё один способ использования PageDuty за несколько лет работы.
Наша техническая директория включает в себя ссылки на другие дежурные команды и кнопки для быстрой связи с ними в экстренных случаях.
Правда, мы обнаружили критический момент, который делал невозможным постоянное поддержание время простоя менее 21 минуты: как настроен PagerDuty конкретной команды? В течение всего времени разные команды в Dropbox принимали совершенно разные решения по вопросам вроде:
Из какого количества уровней должна состоять наша политика эскалации?
Сколько времени проходит между эскалациями? Сколько занимает весь процесс эскалации?
Как дежурные получают уведомления от PagerDuty? Нужны ли им пуши, SMS, звонки, или их комбинация?
После устранения этих несоответствий в нескольких SEV-ах, мы ввели набор проверок для дежурных команд, с помощью которых оценивали соответствие настроек PagerDuty всех команд с основными правилами. Мы создали внутренний сервис, который ходит к PagerDuty API, запускает нашу логику по проверке и связывается с командой, если находит нарушения.
Мы приняли трудное решение проверять на соответствие строго всех, без каких-либо исключений. Сделать это было непросто, ведь команды привыкли к определенной свободе и гибкости, однако согласованность в ответах на вопросы выше открыла гораздо большую предсказуемость в нашем реагировании на инциденты. После первоначальной сборки было уже легко добавлять дополнительные проверки, а позже мы нашли способы сделать базовую настройку более тонкой (позволяющей использовать разные стандарты в зависимости от критичности сервиса вашей команды). В свою очередь, ваши собственные инструкции по дежурству должны зависеть от требований бизнеса относительно реагирования на инциденты в вашей организации.
На момент написания этого поста (январь 2021), PagerDuty выпустили On-Call Readiness Report(Отчёт о готовности к дежурству), который позволяет совершать некоторые похожие проверки на своей платформе. И хотя покрытие не идентично тому, что мы построили внутри Dropbox, это всё ещё хороший вариант для начала, если вы хотите быстро добиться определённой согласованности.
Панели управления сортировкой проблем
Для большинства наших критичных сервисов, таких как приложение которое управляет сайтом dropbox.com, мы создали серию панелей мониторинга, которые собирают все высокоуровневые метрики и предоставляют ряд способов сузить фокус расследования проблемы. Для этих критичных систем уменьшение времени, затрачиваемого на сортировку, является главным приоритетом. Эти панели позволили сократить усилия, необходимые для перехода от общего уведомления о недоступности системы к обнаружению конкретной неисправности.
Готовые панели управления для распространённых причин аварий
Хотя не существует двух идентичных инцидентов, случившихся на бэкенде, мы знаем, что определённые данные оказываются важными для респондентов из раза в раз. Например:
Частота ошибок на клиентской и серверной стороне
Задержка RPC
Тенденции исключений
Запросы в секунду (QPS)
Нестандартные хосты (например, те, у которых более высокий процент ошибок)
Основные клиенты
Чтобы сократить время диагностики, нам необходимо, чтобы эти метрики были доступны для каждой команды в момент, когда они необходимы, чтобы сотрудникам не приходилось тратить драгоценные минуты на поиски информации, которая укажет им на корень проблемы. С этой целью мы создали внутреннюю панель управления, которая покрывает и все описанные выше метрики, и множество других. От нового владельца сервиса не требуется прикладывать никаких усилий для настройки, за исключением добавления страницы в закладки. (Мы также рекомендуем владельцам сервисов создавать более подробные панели управления для отслеживания метрик, специфичных для их команды).

Преимущества наличия такой общей платформы — вы можете легко добавлять новые метрики с течением времени. Обнаружили новую модель первопричин инцидентов? Отлично — можно добавить панель на общий дэшборд, на которой будут отображаться эти данные. Мы также вложили средства в добавление аннотаций в Grafana, которые сопоставляют основные события (пуш кода, DRT, и тд) с метриками, чтобы помочь инженерам с корреляцией. Каждое из таких дополнений немного сокращает время диагностики в компании.
Отслеживание исключений
Один из наиболее эффективных инструментов диагностики в Dropbox — инфраструктура отслеживания исключений. Она позволяет любому сервису в Dropbox отправлять стектрейсы в центральное хранилище вместе с полезными метаданными. Интерфейс позволяет разработчикам с лёгкостью видеть и изучать тенденции исключений в их сервисах. Эта возможность углубиться в данные об исключениях и анализировать тенденции особенно полезна при диагностике проблем в наших крупных python-приложениях.

Роль Менеджера Инцидентов: устранение отвлекающих факторов
Во время перебоя в доступности или другого критического инцидента в процесс вовлекаются многие другие участники проекта, помимо SEV-команды, работающей над устранением проблемы.
Команды, работающие с клиентами, которым нужно предоставлять обновления по ситуации и ETA для решения.
Владельцы сервисов в зоне поражения интересуются техническими деталями.
Руководители высшего звена, ответственные за надёжность и бизнес-цели, пытаются донести мысль о срочности.
Старшие технические руководители порой закатывают рукава и тоже присоединяются к диагностике.
Ещё хуже стало в 2020 году, когда респонденты начали работать из дома и перестали взаимодействовать лично, отчего количество переписок в Slack-каналах сильно выросло.
Мы наблюдали, как всё вышеперечисленное происходит во время инцидентов. И иногда было достаточно трудно достичь главной цели Менеджера инцидентов: оградить SEV-команду от этих отвлекающих факторов. Благодаря обучению, которое они проходят, Менеджеры инцидентов в целом представляют процесс SEV, связанную с ним терминологию и инструменты, а также ожидания от пост—мортемов и ревью инцидентов. Но не всегда они точно знали, как управлять оперативным центов и оптимизировать эффективность реагирования на SEV. Мы слышали отзывы от наших инженеров о том, что Менеджеры инцидентов не предоставляют им необходимую поддержку, отчего отвлекающие факторы замедляют процесс диагностики проблемы.
Мы осознали, что эти аспекты роли Менеджера инцидентов остались неявными, и знания о том, "что такое хороший Менеджер инцидентов", передавались "фольклором" и со временем утерялись. Первым шагом стало обновление нашей образовательной программы, делая упор на обозначение уровня срочности, избавление от отвлекающих факторов и консолидацию общения в одном месте. Сейчас мы работаем над игровыми (тренировочными) сценариями SEV, где Менеджер инцидента может попрактиковать эти аспекты перед выходом на первую смену. Наконец, мы планируем увеличить количество упражнений, с участием большего количества Менеджеров, чтобы группа могла оценить свою общую готовность.
Кроме того, мы создали Резервную Группу Реагирования, состоящую из Менеджеров инцидента и Технических специалистов высшего уровня, которые могли бы быть задействованы в самых серьёзных инцидентах. Мы предоставили им чёткую схему действий для оценки состояния инцидента и определения с помощью текущих Менеджера инцидента и Технического специалиста, нужно ли им передать "бразды правления". Предоставление этим старшим игрокам чёткой, хорошо известной роли, сделало их ценной структурой поддержки, а не источником дополнительного шума в Slack.
Ключевой урок: обратите внимание на отличия между тем, как ваш процесс реагирования на инциденты выглядит на бумаге, и что происходит на практике.
5. Восстановление
время, необходимое для устранения симптомов проблемы для пользователя, с тех пор как у нас появилось решение
Сценарии смягчения последствий
Сперва может казаться, что найти "серебряную пулю" на стадии восстановления очень сложно. Как оптимизировать эту часть процесса, когда разные инциденты требуют разных стратегий? Для этого необходимо глубокое понимание того, как работают и ведут себя ваши системы, и четкое представление, какие шаги следует предпринять респондентам в самых худших (но решаемых) случаях
Поскольку Dropbox обещает аптайм 99.9% времени по SLA, мы начали проводить ежеквартальную оценку рисков надёжности. Это был процесс мозгового штурма по восходящей по каждой из наших инфраструктурных команд и других, чьи системы вероятнее всего могут быть задействованы в SEVах. Зная, что нам нужно оптимизировать время восстановления, мы предложили командам сфокусироваться на простом вопросе: "Для устранения каких инцидентов в ваших системах понадобится более 20 минут?"
Это породило множество теоретических инцидентов с различной степенью вероятности, что они произойдут. Если что-то из этого произойдёт, скорее всего, мы не уложимся в установленные рамки по времени недоступности. Передав результаты оценки рисков руководству, мы согласовали, в какие из них стоит вкладываться, и определили несколько команд, которые будут работать над этими сценариями. Пара примеров:
Наш монолитный бэкенд-сервис поднимался более двадцати минут. Владельцы сервиса оптимизировали пайплайн деплоя, так чтобы он проходил за меньшее время, и начали проводить регулярные DRT, чтобы гарантировать, что время запуска не увеличится.
Активация резервных реплик базы данных могло занимать более двадцати минут, если мы потеряли достаточное количество основных реплик при отказе целой стойки. Наша команда метаданных увеличила разнесённость наших баз данных по стойкам, и улучшила инструменты, которые используются для активации БД.
Экспериментальные изменения было достаточно сложно отследить, и основные команды не смогут быстро откатить их в экстренной ситуации, так что скорее всего инцидент, связанный с экспериментами, не получится разрешить быстрее, чем за двадцать минут. Так что наша команда по экспериментам поработала над улучшением видимости изменений, обеспечив определение четкого владельца каждой экспериментальной фичи, а также предоставила возможности отката и инструкцию для центральных команд реагирования.
Приняв меры относительно этих и других сценариев, мы увидели, что количество инцидентов доступности, занимающих много времени, резко снизилось. Мы продолжаем использовать "правило 20 минут" как мерку для новых сценариев, и возможно, в будущем даже ужесточим этот порог.
Вы можете использовать аналогичную методологию в вашей организации или команде. Напишите список потенциальных инцидентов, которые потребуют больше всего времени для решения, расположите их в порядке убывания вероятности и улучшите процессы, касающиеся первых. Затем проверьте, как сценарий будет разворачиваться на самом деле, с помощью DRT или упражнений для ваших респондентов. Сократили ли улучшения время восстановления до уровня, приемлемого для вашего бизнеса?
Удерживаем фронт на 99.9
С жёстким SLA у нас не так много времени на реагирование, когда всё идёт не так, а наш технологический стек постоянно меняется. Где возникнет следующий риск и на чём мы сосредоточим свои усилия?
В дополнение к упомянутым выше изменениям в процессе, чтобы держать оборону, мы создали авторитетные источники данных в двух областях:
Единый источник истины для нашего SLA, и список инцидентов, повлиявших на него
Панель мониторинга для отслеживания относительное влияние сервисов друг на друга во время прохождения критического пути.
Наличие единого источника истины для SLA упрощает планирование. Это гарантирует отсутствие путаницы в отношении того, как вклад каждой команды влияет на гарантии, данные клиентам.

Мы также отслеживаем влияние сервисов на критическом пути с помощью распределённой трассировки. Инфраструктура трассировки используется для вычисления веса каждого сервиса. Этот вес является приблизительным показателем того, насколько важен сервис как часть Dropbox в целом. Когда вес сервиса превышает пороговое значение, вводятся дополнительные требования для обеспечения строгости в работе с ним.
Эти веса (и автоматизация вокруг них) служат двум целям. Первая — действовать как еще одна точка данных в нашем процессе оценки рисков; зная относительную важность сервисов позволяет лучше понимать, как сравнивать риски в разных системах. Вторая — обеспечить уверенность, что нас не застанет врасплох появление сервиса на критическом пути. С системой размера Dropbox очень сложно отслеживать каждый новый сервис, поэтому автоматический трекинг критического пути гарантирует, что мы уловим всё.
Оценка воздействия на пользователя
"Насколько болезненен этот SEV для наших клиентов?" Ответ на этот вопрос не ускорит восстановление, но позволит нам проактивно коммуницировать с пользователями и Быть Достойными Доверия, что является главной ценностью нашей компании. Опять же, во время инцидента у пользователей каждая минута на счету.
Этот вопрос оказался особенно сложным в отношении SEVов доступности в Dropbox. Как вы, возможно, заметили выше, наши определения уровня SEV начинаются с несколько наивного предположения, что более низкая доступность более серьёзна. Это определение обеспечивало некоторую простоту по мере развития компании, но в конечном счёте не помогло нам. Мы встречали SEVы с резким снижением доступности, но почти без влияния на пользователей; мы встречали небольшие неполадки которые не дотягивали даже до SEV, но делали dropbox.com совершенно бесполезным. Последний случай заставил нас работать ночь напролёт, потому что мы рисковали сильно подвести пользователей.
В качестве тактического решения мы сосредоточили внимание на нашем сайте, трафик которого меньше, чем у десктоп- и мобильных приложений (что означает, что проблемы с доступностью веб-сайтов могут быть меньше в цифрах). Мы работали с командами инженеров, чтобы определить ~20 веб-маршрутов, соответствующих ключевым страницам и компонентам. Мы начали мониторить доступность для каждого из этих маршрутов, добавляя метрики на дэшборды, уведомления, и SEV-критерии. Мы обучили менеджеров инцидента и управляющих как интерпретировать эти данные, сопоставить падение доступности с конкретным воздействием и общаться с клиентами — и мы отрабатывали это в упражнениях. В результате во время последующих инцидентов, влияющих на вебсайт, мы быстро определяли, затронуты ли ключевые рабочие процессы пользователей, и использовали эту информацию для взаимодействия с клиентами.
Мы считаем, что нам всё еще есть над чем поработать в этой области. Мы изучаем множество других способов перейти от измерения "девяток" к измерению пользовательского опыта, и мы предвкушаем задачи, которые это повлечёт за собой:
Можем ли мы классифицировать по критичности все маршруты на разных платформах, чтобы давать эту информацию команде реагирования?
Как использовать прямые сигналы о влиянии на пользователей (например, трафик на страница со статусом или поддержкой, поток заявок от клиентов, реакция в социальных сетах) для ускорения вызова инженерного ответа?
В нашем масштабе, как эффективно оценить количество уникальных пользователей, затронутых инцидентом доступности в реальном времени? Как получить более точные данные о группах пострадавших — по региону, услуге и тд, — после инцидента?
Где мы получим наибольшую выгоду от инструментирования на стороне клиента для измерения пользовательского опыта от и до?
6. Постоянное совершенствование
Dropbox не идеален в управлении инцидентами — никто не идеален. Мы начали с SEV процессов, которые работали отлично в тот момент, но с ростом компании, систем и количества пользователей нам приходится постоянно развиваться. Уроки, которые мы описали в этом посте дались нам не просто так; часто приходилось пережить SEV или два, чтобы понять, где не хватало нашей реакции на инциденты.
Вот почему очень важно извлекать уроки из своих неудач при каждом обзоре инцидента. Вы не сможете полностью предотвратить критические инциденты, но можете предотвратить повторение ошибок.
В Dropbox мы начали с культуры "необвинения" в обзорах инцидентов. Если респондент совершает ошибку, мы не виним его. Мы спрашиваем, где мы просели в защите от человеческого фактора, какого обучения не хватило, чтобы респондент был готов к этой ситуации, и поможет ли вообще здесь автоматизация. Эта культура позволяет всем сторонам чувствовать себя комфортно, сталкиваясь с трудными уроками, которые SEVы преподносят нам.
Также как мы не виним отдельных людей за SEVы, никто не может взять на себя единственную ответственность по улучшениям, которые мы внесли в управление инцидентами. Для усвоения этих уроков потребовался вклад каждого из компании. Но хочется выделить и поблагодарить некоторых из них — нынешних и бывших сотрудников команд структур надёжности, телеметрии, метаданных, прикладных сервисов и экспериментов — за темы, затронутые в этой статье.
