
Напишем вместе HTTP-сервис на golang с нуля? Я уверен, что это довольно несложно. Для тех, кто каждую неделю этим занимается, моя статья не будет особенно интересна, но я все равно рекомендую взглянуть и оценить, возможно, ваши комментарии спасут кому-то жизнь. А может кое-какие из моих рассуждений спасут вашу.
Эта статья будет полезна тем, кто некоторое время назад начал осваивать язык программирования golang и уже достиг того момента, когда может попробовать окунуться в полный цикл разработки микросервисов на этом языке. Также она подойдет тем, кто решил сменить профильный язык, и по каким-то причинам его выбор пал на golang. Я не буду останавливаться на очевидных вещах вроде конструкций языка, парадигм конкурентности и прочего, но уделю время архитектуре приложения и постараюсь заострить внимание на моментах, в которых разработчик может допустить ошибку.
Это первая часть. Первые шаги в нашем нелегком пути. И в этой статье мы попробуем достичь следующих целей:
- Выработаем понимание структуры и жизненного цикла приложения.
- Формализуем наше представление жизненного цикла на языке go.
Для достижения поставленной цели мы пройдем следующие этапы:
- Разработаем контроллер runtime и передадим ему управление переходами из одного состояния в другое.
- Разработаем хелпер управления ресурсами приложения, с которым можно будет работать атомарно.
- Соберем все в аккуратную композицию в контексте веб-сервиса (в следующей статье).
По тексту статьи фигурирует терминология, которая не обязательно является общепринятой и не всегда понятно, что она означает в контексте статьи. Для ознакомления прошу под спойлер. Если нашли неточность или заметили в статье термины, которые могут быть неоднозначно истолкованы, прошу сообщить об этом в комментариях.
- Контроллер Runtime — сегодня мы пишем библиотеку, которая просто запускает функцию приложения, а в фоновом режиме контролирует работоспособность ресурсов и сигнал от ОС. Таким образом контролирует некоторые аспекты runtime нашего приложения, только и всего.
- ресурсы и сервисы — может быть в некоторых местах статьи эти термины спутаны между собой, но под ресурсами я имел в виду любые ресурсы приложения, работоспособность которых необходимо контролировать в процессе. Это могут быть коннекты к БД и прочее такое. Как вы понимаете, это все также подпадает под термин "сервис", поэтому я называю ресурсы сервисами в контексте разработки
ServiceKeeperв остальных местах я стараюсь называть это "ресурсами". - контекст — на протяжении всей статьи я имею в виду интерфейс
context.Context - основной поток выполнения — тут точно не имеется в виду никакой поток операционной системы, нить или горутина. Этим термином я называю процесс выполнения основной функции нашего приложения, той самой, которую мы хотим обернуть в наш контроллер runtime.
Жизненный цикл серверного приложения
Давайте попробуем определить жизненный цикл серверного приложения, как последовательность статусов, в которые переходит приложение от момента его запуска до непосредственной выгрузки его из оперативной памяти:
- Инициализация. У нас есть коннекты к базе данных, какие-то удаленные API или любые другие ресурсы, которыми необходимо будет пользоваться в процессе обработки запросов. На этом этапе необходимо выполнить все настройки этих ресурсов и по возможности проверить их работоспособность.
- Старт. Приложение запускает процесс чтения запросов из сети, выполняет их обработку и возвращает результат. Ничего такого — просто рабочий процесс.
- Мягкое завершение. После получения от операционной системы команды о завершении работы наш сервис должен завершить обработку текущих запросов без потерь данных, и не стоит принимать новые запросы в этот момент.
- Деинициализация. Когда все процессы остановлены, нужно корректно освободить все ресурсы, в том числе все соединения с базами данных и другими удаленными серверами.
Хорошо, давайте попробуем написать пакет-helper, который бы понимал эти этапы, контролировал жизненный цикл приложения и принимал решения о переходе от одного состояния к другому. Предлагаю в процедуре main не разбираться особо в том, какие этапы наше приложение проходит и весь контроль runtime отдать на откуп реализации контроллера. Сейчас мы попробуем определить, из чего будет состоять контроллер.
Нам необходимы следующие методы: Run — для того, чтобы запускать приложение и Shutdown — чтобы приложение останавливать. Если мы хотим настоящий graceful shutdown, тогда наш сервис не должен прерывать работу на середине, но должен переходить в такое состояние, при котором все новые запросы будут сразу же получать ответ 503 — сервис недоступен, а все текущие запросы будут корректно выполнены, и только после этого сервер выполнит остановку. Учитывая это, давайте добавим промежуточный метод Halt, который будет переводить наш сервис в это состояние.
Определим причины, по которым наше приложение должно завершить работу. Есть две основные причины:
- Основной поток завершил работу. Это может произойти с приложением, если его рабочий цикл четко определен и конечен. Выполнена работа — завершаем. Однако это не единственный пример.
- Получено сообщение о завершении работы от операционной системы. Нас в этом случае будет интересовать следующие сигналы:
SIGHUP,SIGINT,SIGTERMиSIGQUIT.
Как вариант, возможная третья причина остановки приложения: отсутствие возможности корректно продолжать работу. Такая ситуация может наступить, если наше приложение потеряло какой-то ресурс: соединение с базой данных или любые другие критичные для выполнения запросов вещи. Давайте не исключать возможность такого состояния и сделаем так, чтобы оно обрабатывалось корректно.
Весь механизм контроля времени выполнения мы инкапсулируем в структуру Application и с помощью методов Run, Halt и Shutdown будем управлять процессом, а механика Application в свою очередь будет контролировать инициализацию и главный поток выполнения.
Инициализация
Предварительный этап выполняющийся непосредственно после запуска нашего приложения — это инициализация. Что туда может входить? Парсинг параметров (конфигурация), создание ресурсов и прочее. Чаще всего приложение имеет не один, а несколько ресурсов, которые нужно проинициализировать, и описать все этапы инициализации внутри одной функции — это не самое лучшее решение, даже если у нас на момент запуска нашего приложения всего один или два ресурса. Дело в том, что вероятные доработки в будущем наверняка увеличат это количество, и в какой-то момент функция main будет выглядеть вот так:
. . .
db, err = postgres.New(cfg.Postgres, l).Connect(context.Background())
if err != nil {
log.Fatal("db connection error", err)
}
redisClient = redis.NewUniversalClient(cfg.Redis)
err := redisClient.Ping(context.Background()).Err()
if err != nil {
log.Fatal("redis connection error", err)
}
clickhouse, err = clickhouse.NewClient(cfg.Clickhouse)
if err != nil {
log.Fatal("clickhouse connection error", err)
}
cache, err := cache.New()
if err != nil {
log.Fatal("cache service error", err)
}
rmq, err := queue.New(cfg.RabbitMQ)
if err != nil {
log.Fatal("rmq service error", err)
}
. . .От спагетти-кода нам поможет избавиться еще один хелпер ServiceKeeper. Его тоже придется написать. Давайте создадим структуру, которая будет хранить список ресурсов (назовем их пока сервисами, ведь они являются сервисами для нашего приложения). И напишем пару простых процедур, которые будут управлять этим зоопарком.
В качестве сервиса на данном этапе мы определим вот такой интерфейс. В нем достаточно методов и для инициализации и для проверки здоровья во время выполнения и для завершения работы. И любая структура, обладающая такими методами, может считаться сервисом, жизненный цикл которого будет контролироваться в процессе выполнения нашего приложения.
Service interface {
Init(ctx context.Context) error
Ping(ctx context.Context) error
Close() error
}Чтобы проинициализировать все ресурсы, нам нужно будет последовательно вызвать метод Init всех сервисов из списка и вернуть ошибку, если она возникнет. Т.е. получается максимально простой алгоритм:
type (
ServiceKeeper struct {
Services []Service
state int32 // для контроля этапов выполнения
}
)
func (s *ServiceKeeper) initAllServices(ctx context.Context) error {
for i := range s.Services {
if err := s.Services[i].Init(ctx); err != nil {
return err
}
}
return nil
}Зададимся вопросом, что будет, если мы проинициализируем ресурсы дважды? Ничего хорошего не будет, в лучшем случае мы просто потратим время, но может быть и так, что получим утечку ресурсов или другую серьезную проблему. Уже, наверно, понятно, для чего было добавлено поле state. Давайте используем его для проверки состояния контроллера, чтобы понимать, какие этапы уже прошли и куда можно двигаться дальше.
const (
srvStateInit int32 = iota
srvStateReady
srvStateRunning
srvStateShutdown
srvStateOff
)
func (s *ServiceKeeper) checkState(old, new int32) bool {
return atomic.CompareAndSwapInt32(&s.state, old, new)
}Теперь, используя процедуру checkState, мы можем быть уверены, что выполняем все методы последовательно, не нарушая порядка. Обратите внимание, что если мы используем процедуры пакета atomic, то можем рассчитывать на правильное исполнение конкурентного кода, заручившись поддержкой со стороны процессора. В этом примере используется процедура CompareAndSwapInt32, которая сравнивает текущее значение поля state, и в случае его совпадения с old изменяет значение на new, и все это происходит атомарно, что позволяет нам гарантировать конкурентность.
Конечно, реализовать конкурентность можно было и с помощью Mutex, но в данном случае мы имеем алгоритм, который отлично реализуется атомарными функциями. Давайте посмотрим, как должен выглядеть публичный метод Init:
func (s *ServiceKeeper) Init(ctx context.Context) error {
if !s.checkState(srvStateInit, srvStateReady) {
return ErrWrongState
}
return s.initAllServices(ctx)
}Будем считать, что для инициализации приложения нам достаточно инициализировать все сервисы, которые зарегистрированы в ServiceKeeper. Это довольно простой случай, который редко будет встречаться в практике. В реальных условиях нам, скорее всего, нужно будет сначала парсить все параметры, потом передать их каждому ресурсу (ну если у нас один источник параметров), может быть нам для начала нужно будет создать какой-то logger, чтобы сбрасывать туда ошибки, или подключение к opentracing серверу. Да все что угодно, что выходит за рамки шаблона, который мы реализовали, но это все может легко решаться и даже легко ладить с нашими абстракциями.
Выполним ServiceKeeper.Init внутри метода инициализации нашего приложения. При этом, давайте проконтролируем продолжительность инициализации с помощью контекста: добавим в нашу структуру поле InitializationTimeout time.Duration и создадим контекст с таймаутом:
func (a *Application) init() error {
if a.Resources != nil {
ctx, cancel := context.WithTimeout(context.TODO(), a.InitializationTimeout)
defer cancel()
return a.Resources.Init(ctx)
}
return nil
}Старт
Хорошо, давайте попробуем написать процедуру, реализующую жизненный цикл приложения. Учтем опыт предыдущего раздела относительно state приложения. Логика должна быть такая: если приложение находится в состоянии appStateInit, переходим в appStateRunning и запускаем процесс инициализации, если он прошел неудачно, останавливаем выполнение, возвращаем ошибку. Все корректно — запускаем основную процедуру и ждем ее завершения, в фоне делаем две задачи:
- Проверяем работоспособность ресурсов и в случае ошибки немедленно останавливаем выполнение;
- Ожидаем сигнала от операционной системы, в случае получения сигнала, сообщаем основному потоку выполнения об этом, давая ему время на корректное завершение работы.
В любом случае по завершению основной процедуры выполняем освобождение ресурсов и выход из функции Run.
type (
Resources interface {
Init(context.Context) error // чтобы инициализировать
Watch(context.Context) error // чтобы наблюдать
Stop() // остановить наблюдение
Release() error // освободить ресурсы
}
Application struct {
// это будет выполняться основным потоком
MainFunc func(ctx context.Context, holdOn <-chan struct{}) error
// это абстракция, чтобы не усложнять код
Resources Resources
TerminationTimeout time.Duration
InitializationTimeout time.Duration
appState int32
err error
mux sync.Mutex
halt chan struct{}
done chan struct{}
}
)
const (
appStateInit int32 = iota
appStateRunning
appStateHalt
appStateShutdown
)
func (a *Application) Run() error {
if a.MainFunc == nil {
// если у нас не задана эта функция, то и выполнять нечего
return ErrMainOmitted
}
if a.checkState(appStateInit, appStateRunning) {
// сюда дважды не войти
if err := a.init(); err != nil {
a.err = err
a.appState = appStateShutdown
// не сбылась инициализация ресурсов
return err
}
// с помощью servicesRunning мы синхронизируем жизненный цикл ресурсов
// с жизненным циклом приложения
var servicesRunning = make(chan struct{})
if a.Resources != nil {
go func() {
defer close(servicesRunning) // вот сигнал о том, что Watch остановлено
// Shutdown просто остновит a.run(sig), это мы потом увидим
defer a.Shutdown()
a.setError(a.Resources.Watch(context.TODO()))
}()
}
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
// запускаем основной поток выполнения
a.setError(a.run(sig))
// в этом месте программа должна завершиться
if a.Resources != nil {
a.Resources.Stop() // посылаем сигнал ресурсам
<-servicesRunning // ожидаем завершения Watch
a.setError(a.Resources.Release()) // освобождаем ресурсы
}
return a.getError()
}
return ErrWrongState
}Выглядит неплохо. Что мы тут сделали? В первой части (сразу же после checkState) идет инициализация, но тут мы не вызываем инициализацию ресурсов пока, а вызываем собственный метод init. Так будет проще изменять инициализацию и добавлять туда какие-то элементы не связанные с ресурсами. В средней части (вот в этом ветвлении if a.Resources != nil {) запускается горутина, которая будет контролировать жизнеспособность ресурсов, если они есть.
Обратите тут внимание на два момента:
defer a.Shutdown()— сразу же, как только будет остановлен контроль жизнеспособности ресурсов, выполняется немедленная остановка приложения. Для приложения нет смысла дальше выполнять запросы, если что-то работает неправильно. Правда есть тут тоже нюансы, но пока мы о них не будем говорить.defer close(servicesRunning)— это синхронизация. Гарантирует, что вызовыResources.WatchиResources.Releaseне пересекутся, иначе возможно состояние гонки и прочие пакости.
В третьей части просим рантайм go передать нам управление обработкой сигналов о завершении от операционной системы (вот этоsignal.Notify) и запускаем основную функцию (опять инкапсулируем запуск внутриrun). В этом месте выполнение функции должно блокироваться до завершения выполнения основной функции, которая в идеале может работать бесконечно.
Далее, если были ресурсы, мы передаем сигналы о том, что ресурсы больше не нужны в таком порядке:
Resources.Stop— это просто сигнал о том, что выполнение функцииResources.Watchдолжно быть прервано.<-servicesRunning— кто знает как работают каналы, понимает, что тут мы будем ждать завершение работы горутины, которая запускалаResources.Watch. Тут возможно зависания приложения, если функцияResources.Watchникогда не вернет управление. Но я думаю, что вы тут и без меня справитесь.Resources.Release— эта процедура должна выполнять освобождение ресурсов. ВсеClose(), которые должны быть выполнены для всех ресурсов, должны быть выполнены внутри нее.
Я пока ничего не сказал о странном методе a.setError, я его нарочно обошел, чтобы оставить напоследок. Встречаем мы его тут три раза — он поглощает результат выполнения Resources.Watch, a.run(sig) и Resources.Release. На самом деле, все эти функции выполняются в тот момент, когда мы можем назвать состояние приложения как "выполняется", и любая ошибка в этих трех процедурах должна иметь право стать результатом вызова метода Run в целом. Т.е. метод Run должен вернуть ошибку, если таковая была в процессе выполнения. Мне показалось удобным добавить поле err error в структуру Application, и в случае возникновения ошибок в разных потоках выполнения, мы можем заполнять это поле первой попавшейся ошибкой и даже инициировать остановку всего приложения.
func (a *Application) setError(err error) {
if err == nil {
return
}
a.mux.Lock()
if a.err == nil {
a.err = err
}
a.mux.Unlock()
a.Shutdown()
}
func (a *Application) getError() error {
var err error
a.mux.Lock()
err = a.err
a.mux.Unlock()
return err
}Да, я здесь использую мьютекс в качестве синхронизации и устанавливаю ошибку единожды.
На самом деле, в правильном go редко встретите такую конструкцию, когда функция принимающая error получает в качестве аргумента вызов функции, которая возвращает error. Это затрудняет чтение кода, поэтому лучше написать что-то вроде этого:
if err := a.run(sig); err != nil {
a.setError(err)
}Однако, я позволил себе это сделать по следующим причинам: все три вызова a.setError располагаются в пределах одной функции и не планируется поддержка этого кода никем, кроме меня. Так себе причины, но как уж есть.
Контролируем runtime
Давайте напишем процедуру Application.run(<-chan os.Signal), которая будет выполнять следующие функции:
- Запускать основной поток выполнения. Т.е. запускать
MainFunc. И контролировать возврат из нее. - Контролировать сигналы операционной системы и в случае необходимости сообщать основному потоку выполнения о том, что нужно завершить работу.
Механика будет следующая: мы запустим обработчики этих функций в двух параллельных горутинах, предоставив каждой из них собственный канал error, в который можно будет отправить ошибку или просто закрыть этот канал при выходе из горутины, а сама функция будет ждать в состоянии чтения из этих каналов.
func (a *Application) run(sig <-chan os.Signal) error {
defer a.Shutdown() // при выходе просто установит поле state в значение appStateShutdown
var errRun = make(chan error, 1) // канал для сигнала от основного потока
go func() {
defer close(errRun)
// halt для основного потока - это сигнал о завершении работы
if err := a.MainFunc(a, a.halt); err != nil {
errRun <- err
}
}()
var errHld = make(chan error, 1) // канал для сигнала от потока слушающего chan os.Signal
go func() {
defer close(errHld)
select {
// ожидаем сигнала операционной системы
case <-sig:
a.Halt() // вызов этой процедуры просто закроет канал a.halt
// это и будет наш Graceful Shutdown воркфлоу
// нам нужно дождаться завершения основного потока или выйти по таймауту
select {
case <-time.After(a.TerminationTimeout):
// это выход по таймауту
errHld <- ErrTermTimeout
case <-a.done: // a.Shutdown закрывает этот канал
// ok
}
case <-a.done: // a.Shutdown закрывает этот канал
// сюда попадем, если завершение работы произошло без участия ОС
}
}()
// на этом месте выполнение процедуры будет блокировано
// пока не произойдет одно из следующих событий
select {
// получим ошибку от основного потока выполнения или закроется канал errRun
case err, ok := <-errRun:
if ok && err != nil {
return err
}
// получим ошибку от рутины, слушающей сигналы ОС или закроется ее канал
case err, ok := <-errHld:
if ok && err != nil {
return err
}
// это жесткий путь - кто-то вызвал процедуру Shutdown()
case <-a.done:
// shutdown
}
return nil
}Выглядит хорошо — мы даем какое то время на корректное завершение работы основного потока и в то же время контролируем это время с помощью таймаута <-time.After. После завершения этой процедуры, state приложения должно быть установлено в appStateShutdown. И даже если основной поток по какой-то причине завершится сам, это приведет к выходу из процедуры и корректному завершению приложения.
Теперь давайте уделим немного времени методам Halt и Shutdown, что они такое и для чего они нужны мы определили в самом начале статьи. Одной из причин завершения работы является сигнал от операционной системы, и он может возникнуть в любой момент, даже тогда, когда наше приложение находится в состоянии при котором велика вероятность потери данных. Попробуем реализовать правильный метод "мягкого завершения работы". А как основной поток поймет, что нужно все завершить и не набирать новых задач? Я реализую это с помощью канала, который закрывается сразу же, как мы получаем сигнал от ОС. Это делает функция Halt.
func (a *Application) Halt() {
if a.checkState(appStateRunning, appStateHalt) {
close(a.halt)
}
}Обратите внимание на то, что тут выполняется синхронизация с текущим статусом нашего приложения: если state установлено в appStateRunning, мы переводим его в appStateHalt и закрываем канал, сигнализируя основному потоку о том, что необходимо начать процесс остановки.
func (a *Application) Shutdown() {
a.Halt()
if a.checkState(appStateHalt, appStateShutdown) {
close(a.done)
}
}В самом начале этой функции мы вызовем Halt, это необходимо потому, что есть два разрешенных статуса при которых мы можем вызывать эту функцию: appStateRunning и appStateHalt. Поэтому если сигнал основному потоку еще не был передан, мы сделаем и это. Это "жесткий" способ завершить работу и все будет остановлено, даже если основной поток еще не закончил работу. Фактически канал a.done это то, чего ждет процедура run выход из которой инициирует выгрузку ресурсов и выход из процедуры Run.
У нас вырисовывается следующая последовательность смены статусов приложения: appStateInit -> appStateRunning -> appStateHalt -> appStateShutdown.
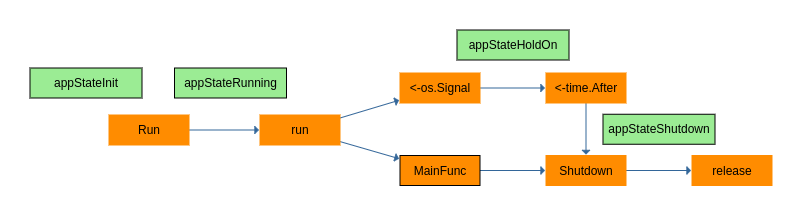
Хочу обратить ваше внимание на то, что вызов Shutdown существует в трех местах:
setError— если мы детектировали критическую ошибку, останавливаем все и выходим.defer a.Shutdown— в горутине, которая контролирует жизнеспособность ресурсов. Тут все просто — сбой критически важных ресурсов останавливает приложение, потому, что работать в такой обстановке невозможно.- выход из
run— для смены статуса.
Теперь немного по поводу ServiceKeeper и его метода Watch. Вызов Watch должен быть блокирующий, ведь в нашем коде Application мы вызываем его только раз, и после его выполнения происходит немедленное завершение работы через вызов Shutdown. Что требуется от реализации этого метода:
- С некоторой периодичностью выполнять
Pingресурсов, которые зарегистрированы внутриServiceKeeper. - Прекращать циклическое выполнение
Pingпри обнаружении критической ошибки и возвращатьerror. - Прекращать циклическое выполнение
Pingи возвращатьnil, если был вызван методStop.
Вот реализация этих функций с учетом перехода по статусам:
func (s *ServiceKeeper) Watch(ctx context.Context) error {
if !s.checkState(srvStateReady, srvStateRunning) {
return ErrWrongState
}
if err := s.cycleTestServices(ctx); err != nil && err != ErrShutdown {
return err
}
return nil
}
func (s *ServiceKeeper) Stop() {
if s.checkState(srvStateRunning, srvStateShutdown) {
close(s.stop)
}
}Тут следует обратить внимание на обработку полученной от cycleTestServices ошибки. Т.к. все это выполняется асинхронно с основным потоком приложения, у нас есть небольшая вероятность того, что в какой то момент контекст вернет нам ошибку, которую мы зарегистрировали в поле err структуры Application. Каким образом это произойдет? Я собираюсь имплементировать все методы интерфейса context.Context в структуре Application и передавать ее в качестве контекста вместо context.TODO. Далее в имплементации cycleTestServices будет понятно, как ошибка основного приложения будет влиять на результаты выполнения метода Watch.
В реализации цикличного выполнения проверки ресурсов достаточно сделать бесконечный цикл с конструкцией select внутри и следующими вариантами выхода:
<-s.stop— закрытие этого канала говорит нам о нормальном завершении работы<-time.After(s.PingPeriod)— получая такой сигнал выполняем пинг всех ресурсов и при получении ошибки выходим, передавая ее в качестве результата<-ctx.Done()— если контекст был отменен, то выходим с ошибкойctx.Err(). В этом месте мы можем получить флешбэк от основного приложения, ведь наш контекст будет реализован структуройApplication, и в качестве параметраctxу нас будет ссылка на основное приложение.
Небольшие улучшения
Контекст
Немного о контексте. В коде несколько раз проскакивал context.TODO() обычно это используют, когда еще не определились, что будет за контекст и оставили решение на потом. Для того, чтобы определиться, нам нужно понять контекст. Что это такое? Фактически контекст — это абстракция, которую можно передавать от одной функции к другой. Она иерархична — мы можем вкладывать контекст, который получили в качестве аргумента в другой контекст, который только что сами создали.
Но я не буду запутывать читателя дальше, давайте просто представим, что контекст — это переменная, передающая состояние времени выполнения. И в качестве состояния выступают: таймаут выполнения, возможность отмены процесса или какие то любые значения, которые вы можете положить внутрь контекста, если знаете, как это делать. Не будем рассматривать последнее, пока ограничимся только таймаутом и отменой.
Контекст с таймаутом создать просто, сигнатура вот этой функции подсказывает нам, что вы можете передать любой контекст (в качестве базового подойдет context.Background()) и какой-то time.Duration в функцию WithTimeout и получить контекст с таймаутом:
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}Такая же история с WithCancel и WithDeadline. Но только не нужно думать, что это какая то магия и что чудесный go-runtime это все сразу осознает и далее все работает само, а вам ничего делать не надо. Недостаточно создать контекст, его нужно еще правильно понимать. Все родные go-библиотеки и go-функции, которые принимают контекст в качестве аргумента умеют работать с контекстом и поймут все таймауты и отмены, то же самое касается сторонних библиотек, если они написаны хорошо. Но вот ваш код, если вы не научите, как работать с контекстом, будет этот контекст игнорировать, поскольку тут нет никакой магии, тут просто абстракция.
Короче, интерфейс context.Context нам предоставляет следующие методы, которые мы должны понимать:
Done()иErr()— вызовите методDone, чтобы получить канал, когда канал закроется, контекст достиг дедлайна или таймаута, или его попросту отменили — выходите из функции и возвращайтеcontext.Err()в качестве ошибки.Deadline()— вернет вам дедлайн, если контекст содержит таймаут или дедлайн.Value(interface{})— это предоставит вам доступ к переменным, которые скрыты в контексте.
Типичный пример "понимания" контекста реализован у нас в процедуре cycleTestServices
func (s *ServiceKeeper) cycleTestServices(ctx context.Context) error {
for {
select {
case <-s.stop:
return nil
case <-time.After(s.PingPeriod):
if err := s.testServices(ctx); err != nil {
return err
}
case <-ctx.Done(): // вот тут
return ctx.Err()
}
}
}Давайте имплементируем методы интерфейса context.Context, чтобы можно было передавать приложение в качестве контекста:
type AppContext struct{}
func (a *Application) Deadline() (deadline time.Time, ok bool) {
return time.Time{}, false
}
func (a *Application) Done() <-chan struct{} {
return a.done
}
func (a *Application) Err() error {
if err := a.getError(); err != nil {
return err
}
// даже если никакой ошибки нет, мы должны вернуть не nil, когда наше приложение остановлено
// просто потому, что канал Done() закрыт и от Err() будут ожидать причину этого
if atomic.LoadInt32(&a.appState) == appStateShutdown {
return ErrShutdown
}
return nil
}
func (a *Application) Value(key interface{}) interface{} {
// таким способом можно получить структуру Application из контекста
var appContext = AppContext{}
if key == appContext {
return a
}
return nil
}Теперь в init мы сможем заменить context.TODO() на указатель приложения
if a.Resources != nil {
ctx, cancel := context.WithTimeout(a, a.InitializationTimeout)
defer cancel()
return a.Resources.Init(ctx)
}Таймауты для всего
С учетом таймаутов на инициализацию и ожидания завершения работы структура Application теперь выглядит вот так:
type (
Application struct {
MainFunc func(ctx context.Context, holdOn <-chan struct{}) error
Resources Resources
TerminationTimeout time.Duration
InitializationTimeout time.Duration
appState int32
mux sync.Mutex
err error
holdOn chan struct{}
done chan struct{}
}
)Тогда, чтобы таймауты не были нулевыми и нам не приходилось их каждый раз указывать, добавим проверку на ноль и установку значения по умолчанию в init:
const (
defaultTerminationTimeout = time.Second
defaultInitializationTimeout = time.Second * 15
)
func (a *Application) init() error {
if a.TerminationTimeout == 0 {
a.TerminationTimeout = defaultTerminationTimeout
}
if a.InitializationTimeout == 0 {
a.InitializationTimeout = defaultInitializationTimeout
}
a.holdOn = make(chan struct{})
a.done = make(chan struct{})
if a.Resources != nil {
ctx, cancel := context.WithTimeout(a, a.InitializationTimeout)
defer cancel()
return a.Resources.Init(ctx)
}
return nil
}Далее немного таких же улучшений в абстракции, которая реализует контроллер ресурсов.
type(
ServiceKeeper struct {
Services []Service
PingPeriod time.Duration
PingTimeout time.Duration
ShutdownTimeout time.Duration
stop chan struct{}
state int32
}
)
const (
defaultPingPeriod = time.Second * 5
defaultPingTimeout = time.Millisecond * 1500
defaultShutdownTimeout = time.Millisecond * 15000
)
func (s *ServiceKeeper) Init(ctx context.Context) error {
if !s.checkState(appStateInit, appStateReady) {
return ErrWrongState
}
if err := s.initAllServices(ctx); err != nil {
return err
}
s.stop = make(chan struct{})
if s.PingPeriod == 0 {
s.PingPeriod = defaultPingPeriod
}
if s.PingTimeout == 0 {
s.PingTimeout = defaultPingTimeout
}
if s.ShutdownTimeout == 0 {
s.ShutdownTimeout = defaultShutdownTimeout
}
return nil
}Типовые error
По коду есть возврат ошибок константами, вот тут их код:
type appError string
const (
ErrWrongState appError = "wrong application state"
ErrMainOmitted appError = "main function is omitted"
ErrShutdown appError = "application is in shutdown state"
ErrTermTimeout appError = "termination timeout"
)
func (e appError) Error() string {
return string(e)
}Освобождение ресурсов
Попробуем реализовать параллельное освобождение ресурсов с учетом таймаута, код представлен ниже
func (s *ServiceKeeper) release() error {
// создадим контекст, его магия поможет нам ограничить выполнение функций Close
shCtx, cancel := context.WithTimeout(context.Background(), s.ShutdownTimeout)
defer cancel()
var errCh = make(chan error, len(s.Services))
var wg sync.WaitGroup // для синхронизации будем использовать вот это
wg.Add(len(s.Services)) // сразу говорим wg, сколько сигналов будем ожидать
for i := range s.Services {
// все Close() выполняем одновременно в разных горутинах
go func(service Service) {
defer wg.Done() // синхронизация
// наверно правильно было бы передавать в процедуру Close контекст
// для того, чтобы затянувшаяся процедура получила информацию о том, что мы ее уже не ждем
// но вот в процессе освобождения ресурсов критичность в таком сигнале отпадает
// мы же все равно сейчас все вырубим - не прерывать же Close ...
if err := service.Close(); err != nil {
errCh <- err
}
}(s.Services[i])
}
go func() {
// ждем завершения всех запущенных Close
wg.Wait()
close(errCh)
}()
select {
case err, ok := <-errCh:
if ok {
// сюда попадем, если была ошибка
return err
}
// норм, все без ошибок, сработал wg.Wait()
return nil
case <-shCtx.Done():
// превышено время ожидания, тут сработал таймаут контекста
return shCtx.Err()
}
}
func (s *ServiceKeeper) Release() error {
if s.checkState(srvStateShutdown, srvStateOff) {
return s.release()
}
return ErrWrongState
}Для тех, кому сложно понимать комментарии по коду, я объясню словами. Мы создаем контекст с таймаутом в самом начале для того, чтобы ограничить время выполнения процедуры release, мы же не хотим, чтобы наше приложение завершалось вечно (зависло). Далее в цикле запускаем метод Close для всех зарегистрированных ресурсов и ждем их выполнения. Синхронизацию тут обеспечивает WaitGroup, мы задали число потоков методом wg.Add и этот счетчик будет откручиваться обратно с каждым вызовом wg.Done и только, когда счетчик станет равным нулю метод wg.Wait позволит пройти дальше и закрыть канал errCh.
В конце функции блокировка выполнена с помощью select конструкции, и у нас всего два варианта завершения функции: или сработает таймаут контекста shCtx.Done или что-то произойдет с каналом errCh.
Как заключение
В статье не представлен полный код библиотеки, которую мы с вами написали. Код, представленный выше, является черновым вариантом и работать не будет, если вы его скопируете и вставите в свою IDE. Весь код представлен на моем github. Кроме того, там уже готово тестовое приложение, которое я собираюсь описать в следующей статье.
Если что-то в этой статье показалось "туманным", задавайте вопросы в комментариях. Если что-то показалось неправильным, пишите в комментариях свои претензии, пообщаемся.
Я искренне надеюсь, что из этой статьи понятно, каким образом реализован сигнал о завершении работы для основного потока. Более того, я согласен, если кто-то из вас считает, что нужно было сделать сигнатуру основной функции идеоматичной, т.е. func (context.Context) error и при получении сигнала от ОС просто выполнять отмену контекста, но тут свои проблемы: в этом случае захочется передать этот контекст во все внутренние функции и отмена контекста приведет не к "мягкому завершению", а к "жесткому", а мы условились на том, чтобы выполнять завершение работы в два этапа: корректное завершение текущих работ и выход из основного потока, а это уже никак не разделить в простом контексте. В моем же случае отмена контекста наступает, когда выполнено Shutdown, а это уже правильно и разумно.
Возможно, есть такие, кто уже понимает, как пользоваться этим кодом и как его применить в своих проектах, но представленного материала мало для того, чтобы это было понятно массе. Поэтому прошу пока освоить материал и подождать выхода следующей статьи, в которой я расскажу, как с помощью этой библиотеки построить веб-приложение и при этом уделить внимание логике приложения, а не внешним проблемам вроде обработки сигнала завершения работы.
Новости, обзоры продуктов и конкурсы от команды Timeweb.Cloud — в нашем Telegram-канале ↩

