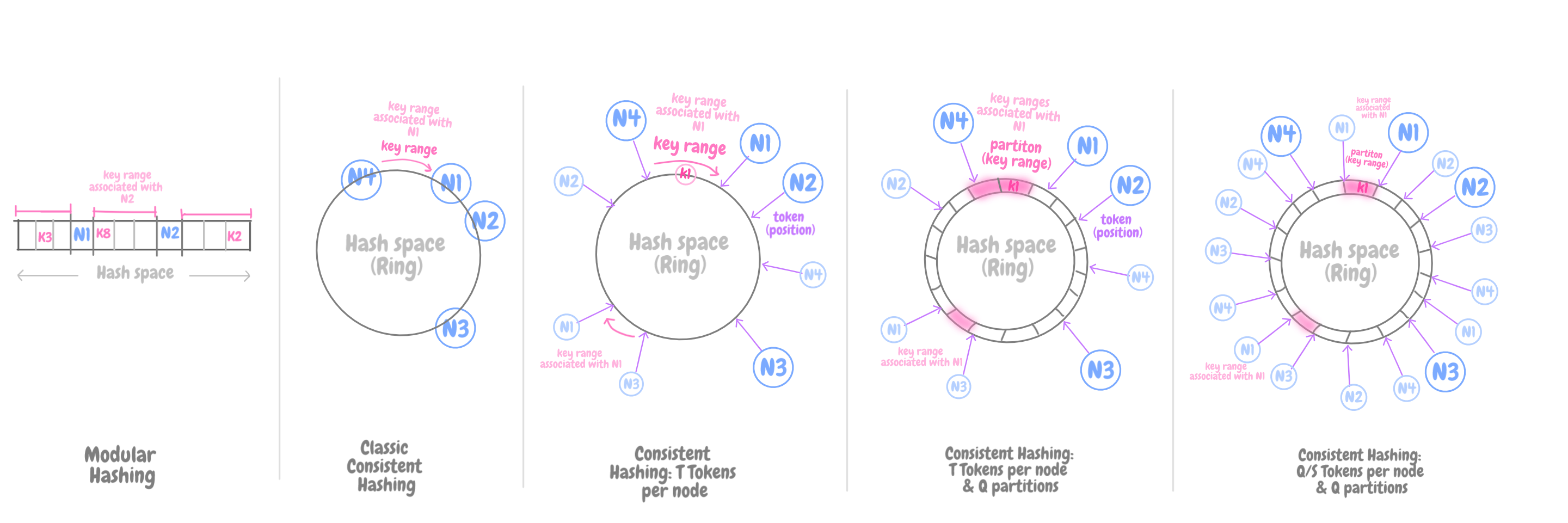
Классический алгоритм согласованного хеширования решает проблемы, присущие алгоритму модульного хеширования, где хеш-функция (позиция ключа K) привязана к числу элементов хранилища – и, соответственно, при масштабировании как вверх, так и вниз, требуется перераспределение всех этих ключей.
# модульное хеширование
hash = key % N of nodesВ свою очередь, при согласованном хешировании хеширующая функция не зависит от количества узлов хранения. Поэтому можно динамически секционировать данные по мере добавления или удаления узлов, тем самым масштабируясь поступательно.
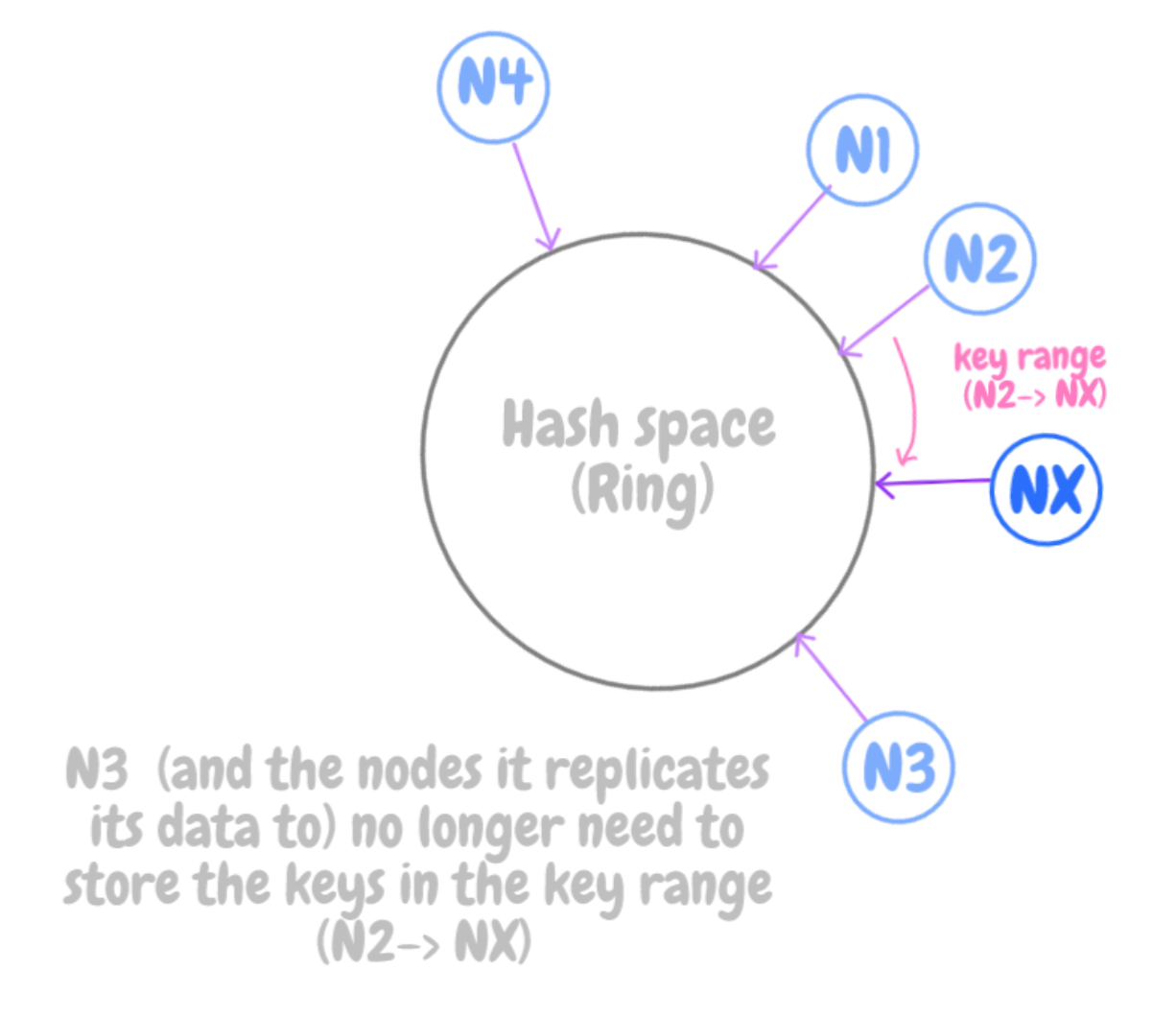
Пространство хеш-таблицы огромное, и его размер не меняется. Часто его называют «кольцом». Каждому узлу хранилища в рамках этого кольцевого пространства присваивается случайный номер.
Каждый элемент данных присваивается некоторому узлу путем хеширования ключа этого элемента, чтобы впоследствии по этому ключу можно было узнать его положение в кольце. Затем, обходя кольцо по часовой стрелке, можно найти первый узел, чья позиция больше, чем у исходного элемента.
Таким образом, каждый узел отвечает за область кольца между собой и предшествующим узлом. Следовательно, при добавлении или удалении узлов требуется перераспределять только те ключи, что попадают в затронутый регион, а не все ключи, как при модульном хешировании.
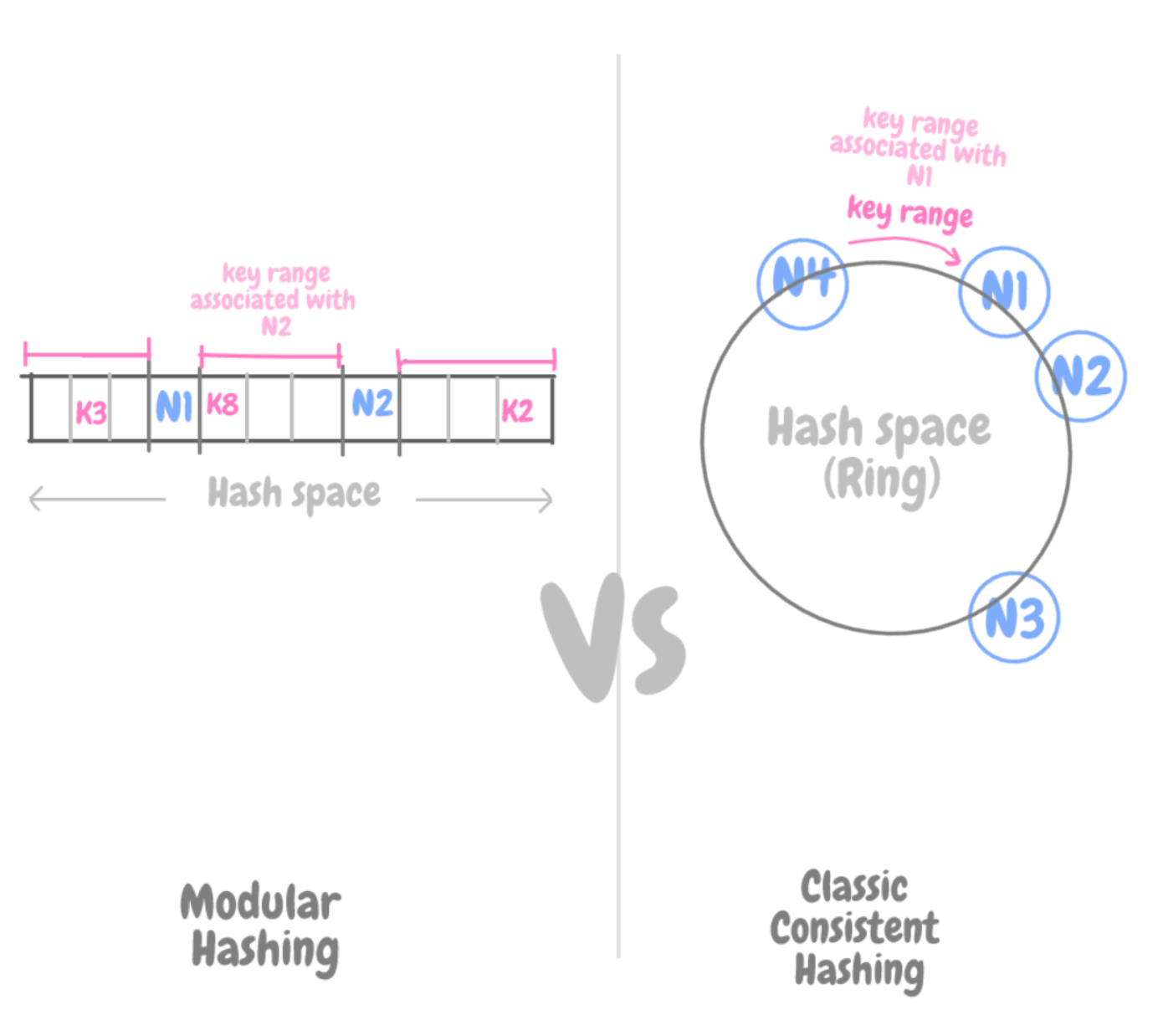
Сравнение модульного и согласованного хеширования
Вот и все. Хотя, не совсем…
При согласованном хешировании возникают некоторые вызовы. Самый очевидный из них связан со случайным присваиванием позиций узлов в кольце, что приводит к неравномерному распределению данных и нагрузки. Более того, при удалении или добавлении узла, некоторые данные приходится копировать, извлекая набор ключей из отдельных узлов, а этот процесс обычно неэффективный и медленный.
В этой статье, написанной под впечатлением от работы с AWS DynamoDB, рассмотрены вызовы, связанные с классическим согласованным хешированием. Здесь мы коснемся различных аспектов масштабирования, как то доступность, согласованность, производительность и надежность. Также здесь поговорим о версионировании и сверке данных, о принадлежности узлов, обнаружении и устранении отказов. Но в этой статье не ставится цель объяснить, как работает DynamoDB; скорее, в ней обобщены универсальные идеи и авторские заметки со ссылками на статью о AWS DynamoDB. DynamoDB – хранилище ключей и значений от Amazon, характеризующееся высокой доступностью.
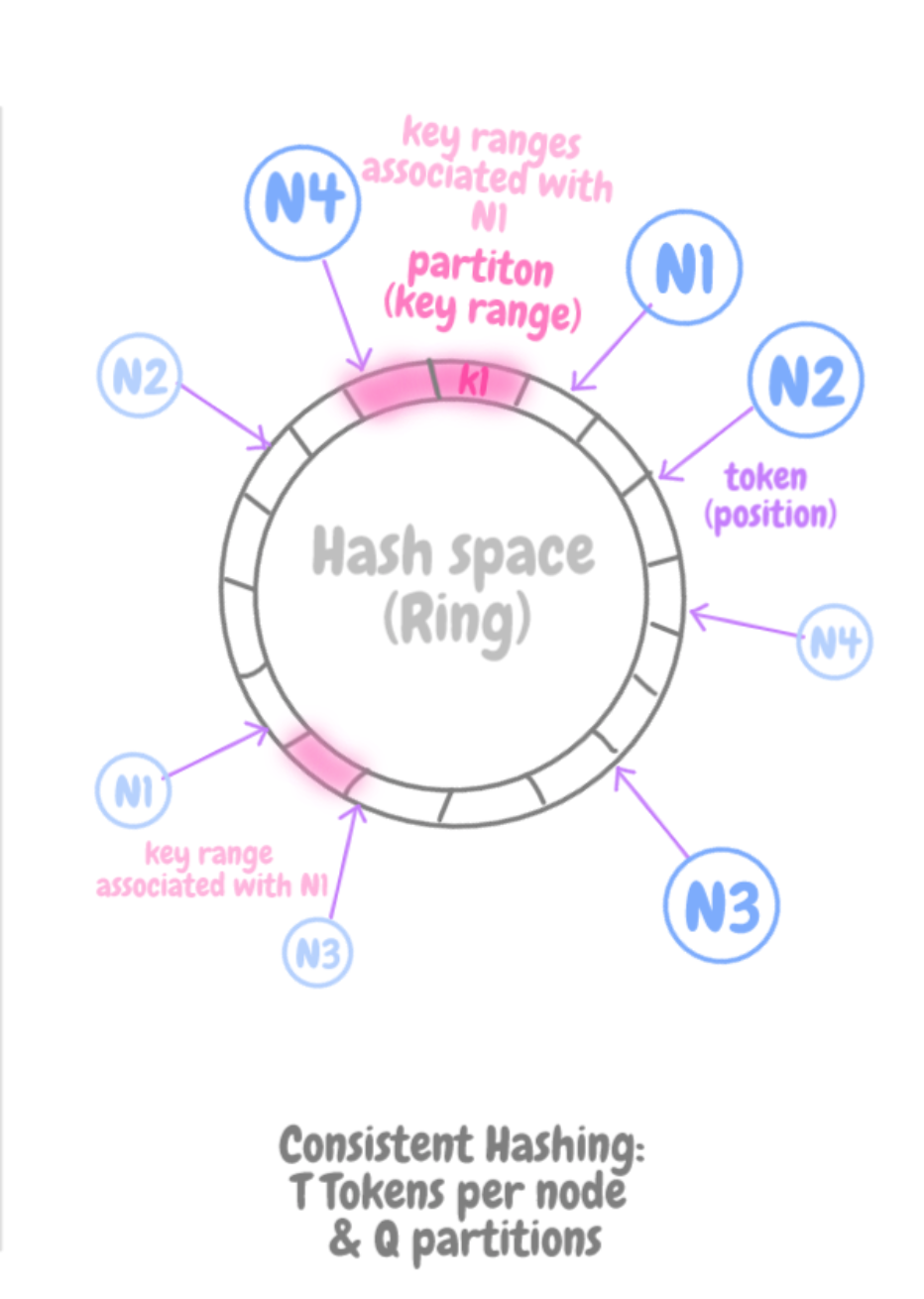
Отображение узла на T-токены
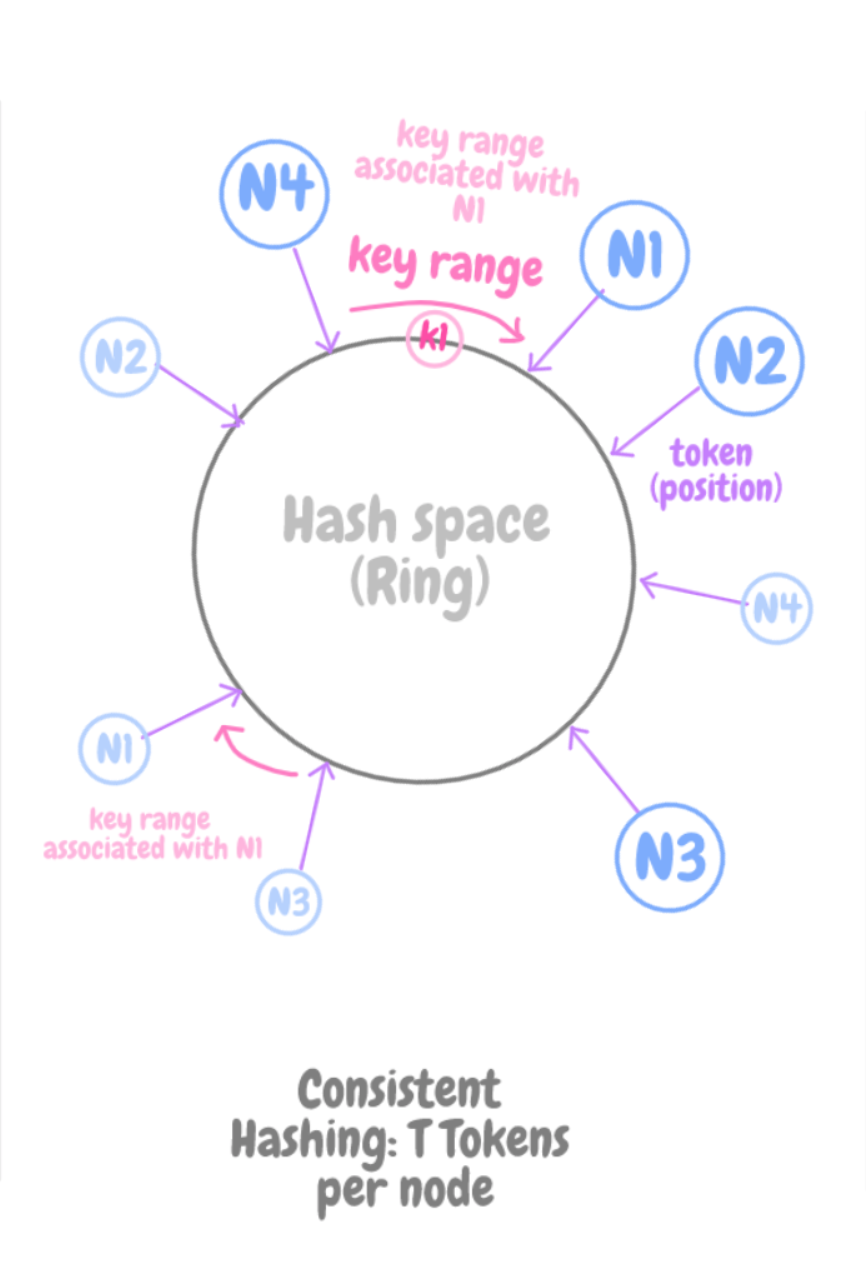
T-токены на узел
Чтобы решить при помощи классического согласованного хеширования проблему неоднородного распределения нагрузки и данных, можно отобразить каждый из узлов на T позиции в кольце. Назовем эти позиции «токенами». Когда добавляется новый узел, ему присваиваются T-позиции, случайным образом рассеянные в кольце. У такого подхода следующие достоинства:
- На момент добавления узла его нагрузка примерно такая же, как и у уже имеющихся доступных узлов.
- Когда узел добавляется или становится недоступен из-за отказов, та нагрузка, что обрабатывалась этим узлом, перераспределяется в рамках обратного процесса. Фактически, она в равных долях раздается оставшимся доступным узлам.
Доступность
— Репликация
Репликация данных на множестве узлов – фактор, критически важный для достижения высокой доступности. Каждый элемент данных реплицируется на N узлах. Узел, координирующий запросы на запись, отвечает за репликацию тех элементов данных, что относятся к его диапазону. Он захватывает по часовой стрелке N-1 последующих позиций (токенов) в кольце. Возможно, что первые из последующих позиций ради большей случайности определяется другой хеш-функцией, а сами данные для повышения доступности распределяются по разным дата-центрам.
Некоторые полезные определения:
N – это количество реплик для каждого элемента данных, типичное значение 3; R – это количество реплик для обмена пакетами ack / reply при операции считывания; W – это количество реплик для обмена пакетами ack / presist при операции записи; S – это количество узлов в системе; T – количество токенов (позиций), соответствующих физическому узлу в кольце; ключевой диапазон – это набор ключей, расположенных в кольце и ассоциированных с токеном (а токеном владеет узел).
— Всегда доступно под запись
Общеизвестно, что в мире распределенных систем, где нередко случаются отказы сети и конфликты данных, невозможно достичь высокой согласованности и доступности данных одновременно.
В традиционных алгоритмах принято жертвовать доступностью данных в сценариях отказа, так что доступ к данным закрывается до тех пор, пока не будет абсолютной уверенности в их корректности.
Напротив, можно повысить доступность, учитывая при работе неопределенность корректности ответа, допуская распространение изменений по репликам в фоновом режиме, а также соглашаясь на конкурентную обработку, даже в условиях отсутствия связи.
Проблема с данным подходом – в том, что он может приводить к конфликтующим изменениям, такие изменения потребуется обнаруживать и разбираться с ними. Такой процесс разрешения конфликтов ставит перед нами две проблемы: когда их разрешать, и кто будет их разрешать.
Согласованность
— Разрешение конфликтов: когда
Нужно определиться, когда заниматься разрешением конфликтов – в ходе чтения или в ходе записи. Во многих традиционных хранилищах данных конфликты разрешаются в ходе записи, благодаря чему сложность операций чтения остается низкой. Это достигается за счет отклонения операций записи, если хранилище данных не может достучаться до W узлов, из-за чего, фактически, снижается доступность системы.
Перенося разрешение конфликтов на операции чтения, мы гарантируем, что операции записи никогда отклоняться не будут. Операции чтения не будут отклоняться при обнаружении конфликта между версиями данных. Теперь остается решить, кто и как будет разрешать конфликты?
— Разрешение конфликтов: кто
Этим может заниматься само хранилище данных или приложение-клиент.
Клиенту известна как схема данных, так и бизнес-логика, соответственно, он может судить о том, как разрешить конфликт. Возьмем, к примеру, корзину заказов. Когда пользователь хочет добавить туда товар (или удалить товар из корзины), а последняя версия корзины заказов недоступна, этот товар добавляется в старую версию корзины (или удаляется оттуда), и сверка данных между расходящимися версиями производится позже. Это изменение все равно значимо и должно быть сохранено. Когда конфликтующие версии обнаруживаются при чтении, приложение-клиент может решить, что лучше эти версии «объединить» и вернуть одну унифицированную корзину с заказами.
С другой стороны, если обработкой конфликтов занято хранилище данных, то набор решений довольно ограничен. В таком случае могут использоваться только простые политики, например логика сверки на основе временных меток, «последняя запись берет верх» (то есть, корректной считается та версия элемента, на которой проставлена наиболее актуальная метка). Хороший пример такого варианта использования – сервис, поддерживающий информацию о пользовательских сеансах.
— Разрешение конфликтов: как
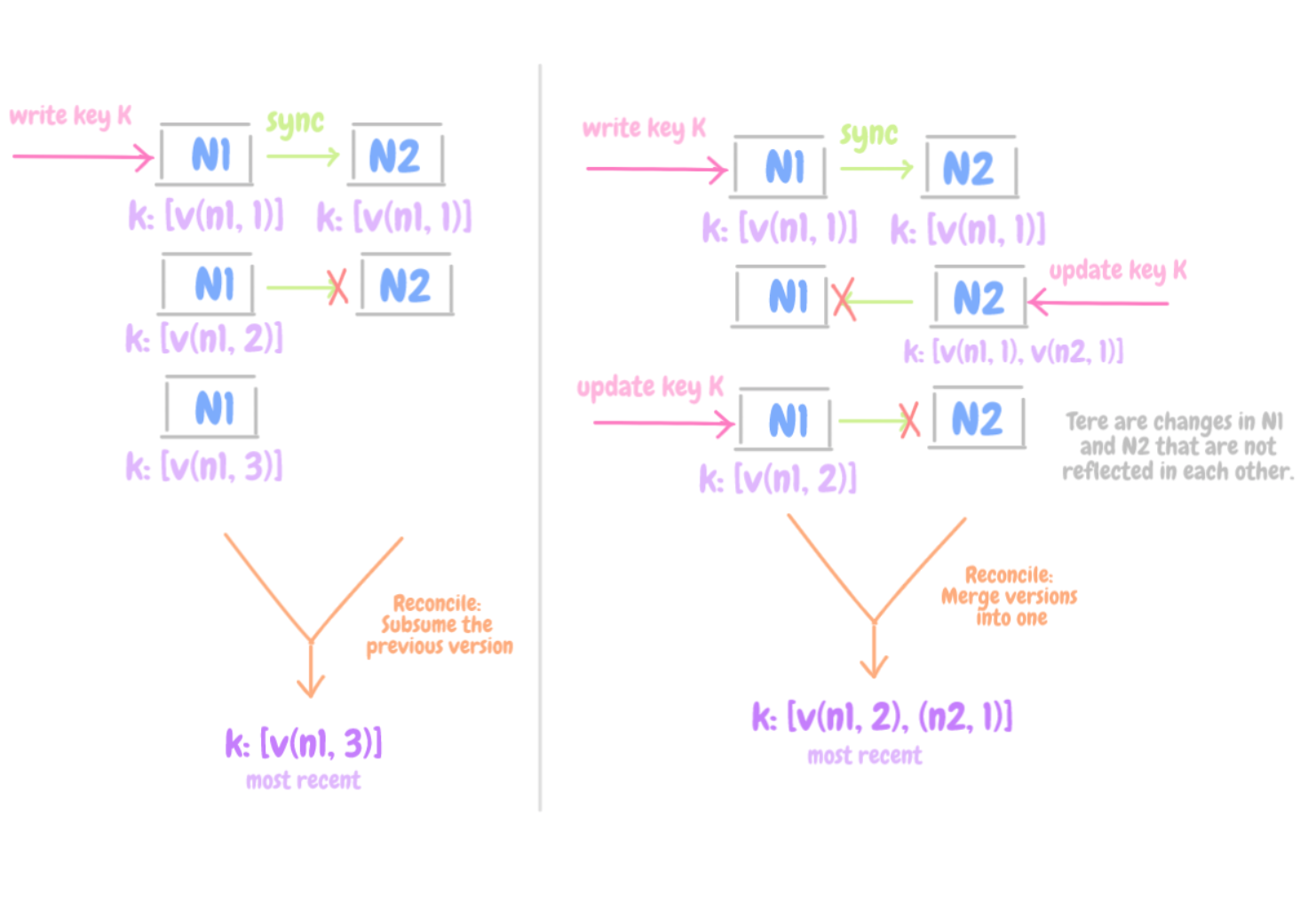
Разрешение конфликта данных
При помощи версионирования данных удается обнаруживать противоречивые версии и улаживать конфликты между ними – следовательно, обеспечивать согласованность данных. Каждое обновление, выполняемое узлом, расценивается как новая и неизменяемая версия данных. Версия состоит из пар (узел, счетчик), т.e. [(N, c), …], где N – узел, координирующий запрос на запись.
Как правило, новые версии вбирают старые, и хранилище данных может само определить ту версию, что верна на настоящий момент.
Однако на фоне отказов в сочетании с конкурентными версиями (параллельное) ветвление версий может приводить к возникновению конкурирующих вариантов одного и того же элемента. В данном случае множество веток данных сливаются в одну. Типичный пример, рассмотренный ранее – «объединение» различных версий пользовательской корзины заказов, выполняемое приложением-клиентом.
Проиллюстрируем потоки задач при чтении и записи:
Чтение
- Узел, координирующий запрос на чтение, запросит имеющиеся версии элемента, получив его ключ со всех N узлов.
- Затем он дожидается, пока ответят R узлов из имеющихся N.
- Возвращается результат. Если обнаруживается конфликт версий, а именно, в хранилище данных не состыкуются сверяемые параллельные ветки, то конфликтующие элементы вместе с контекстной информацией об их версиях передаются обратно клиенту. Согласовав расходившиеся ранее версии путем объединения веток, клиент выполняет обновление.
Записи
- Узел, координирующий запрос на запись, сохранит ее на локальном носителе, сгенерирует новую версию и реплицирует на N-1 позициях (токенах). Клиент должен указать, какую именно версию обновляет. Это делается путем передачи контекста, полученного им от выполненной ранее операции чтения.
- Как только ответят W узлов из имеющихся N, считается, что запрос на запись выполнен успешно.
Производительность
Обеспечение стабильно высокой производительности для операций чтения и записи – сложная задача, так как общая производительность будет не выше, чем у самой медленной ® из имеющихся W реплик.
В некоторых приложениях высокая производительность обязательна, и ради нее можно пожертвовать производительностью (напр. R=1, W=1). Для этого каждый узел хранилища данных поддерживает у себя в памяти буфер объектов. Каждая операция записи сохраняется в буфере, и оттуда записи периодически переносятся в долговременное хранилище. При каждой операции считывания сначала проверяется, присутствует ли в буфере запрошенный ключ. Если да – то объект считывается из буфера, а не из подсистемы хранения.
В результате удается многократно сократить задержки, но приходится пожертвовать надежностью. Сервер может отказать из-за того, что будут пропущены какие-то записи, стоявшие в очереди в буфере.
Надежность
Чтобы снизить риски, связанные с ненадежностью, тот узел, что координирует запрос на запись, выбирает одну из N-1 реплик, чтобы затем записать информацию в постоянное хранилище данных. А поскольку координирующий узел ожидает только W ответов, производительность операции записи не страдает.
В принципе, если увеличить количество узлов, от которых требуется подтвердить, что операция прошла успешно, то долговечность возрастает, но надежностью приходится жертвовать. Запросы на запись могут отклоняться, если в системе не хватает активных узлов, которые могли бы ответить.
Важно, что репликация элементов данных происходит в разных дата-центрах одновременно. Это повышает выживаемость данных при отказах из-за перебоев с электропитанием, сетевых отказах и природных катастрофах.
Принадлежность узлов
Когда узлы объединены протоколом, действующим по принципу передачи сплетен, этот протокол распространяет изменения в принадлежности узлов (сообщает, присоединился ли узел к кольцу или покинул его) и поддерживает согласованное в конечном счете представление о такой принадлежности.
Каждый узел ежесекундно подключается к случайно выбранному другому узлу того же ранга, и два этих узла, фактически, согласуют свои долговременные истории внесенных в них изменений.
Следовательно, каждый узел, хранящий данные, осведомлен в том, какие токены обрабатываются другими узлами его же ранга. Поэтому каждому узлу позволено напрямую переадресовать набор операций чтения/записи по ключу именной той группе узлов, которая за эти операции отвечает.
Поэтому исчезает необходимость поддерживать централизованное глобально согласованное представление о состоянии отказа.
Обнаружение и обработка отказов
Обнаруживая отказы и обрабатывая их, удается обходить без неудачных попыток чтения или записи, при которых доступность и надежность страдали бы даже в условиях простейших отказов.
— Временные отказы: направленная отправка
Узел A может счесть, что узел B временно отказал, если узел B не отвечает на сообщения узла A. После этого узел A выполняет запрос через альтернативные узлы, а также периодически повторяет попытки достучаться до B, чтобы проверить, не восстановился ли тот.
При отсутствии клиентских запросов, которые гоняли бы трафик между двумя узлами, ни один из узлов в самом деле не нуждается в информации, достижим ли другой узел и отвечает ли он на запросы.
Чтобы справиться с такой ситуацией, тот элемент данных, который обычно размещался бы на B, теперь отправляется на узел X (это временная реплика B). В метаданных того элемента, что отправлен на X, будет подсказано, какой именно узел задумывался как адресат этой реплики (в данном случае, B).
Узлы, получающие элементы данных с такими подсказками, хранят их в отдельной локальной базе данных, которая периодически просматривается. Как только X обнаружит, что B восстановился, X попытается доставить данные на B. Как только такая передача закончится успешно, X удалит конкретный элемент данных из своего локального хранилища.
При использовании направленной отправки мы гарантированно страхуемся от потенциально неуспешных операций записи, которые могли бы не пройти из-за временных отказов узлов и сети.
— Долгосрочные отказы: синхронизация реплики
В определенных условиях, например, при отказах узлов, узел B может надолго остаться недоступным, и снабженные подсказками элементы данных могут даже не вернуться к нему.
Чтобы справиться с этой проблемой, применяется реплика протокола синхронизации, использующая дерево Меркла. Благодаря этому протоколу достигается синхронизация реплик и обнаруживаются несогласованности.
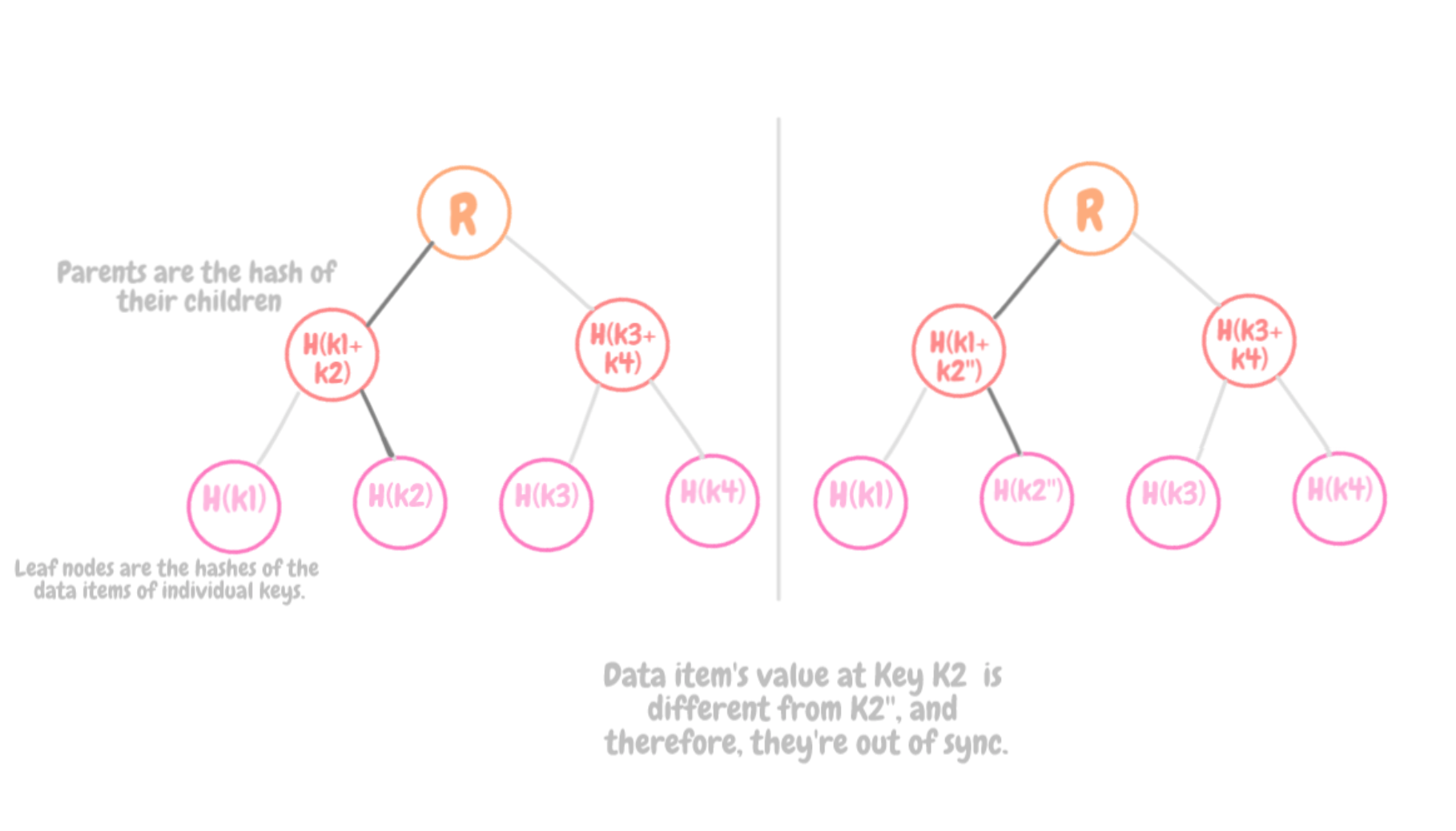
Обход дерева Меркла
Дерево Меркла – это дерево хешей, где листья являются хешами значений отдельных ключей. Родительские узлы, расположенные выше по дереву, являются хешами соответствующих дочерних узлов. Важнейшее достоинство дерева Меркла заключается в том, что все его ветки можно проверять независимо друг от друга и при этом параллельно. Более того, дерево Меркла позволяет сократить объем данных, которые необходимо передавать, а также количество операций чтения с диска. Два узла могут обходить каждый свое дерево Меркла, выполняя поиск по общим для них диапазонам ключей, тем самым определяя, есть ли между ними какая-либо разница.
Каждый из узлов поддерживает отдельное дерево Меркла для отдельного диапазона ключей (множества ключей, ассоциированных с токеном), расположенного на этом узле. Благодаря этому узлы могут сравнивать, насколько актуальны ключи в некотором диапазоне ключей.
Освежим материал
Итак, давайте резюмируем, какие потоки задач выполняются при удалении и добавлении узлов, а также при операциях чтения и записи:
Добавление узла
- Когда ко множеству присоединяется узел X, он выбирает в кольце множество случайных токенов.
- Для каждого диапазона ключей, присвоенного узлу X, может существовать некоторое количество узлов, которые в настоящее время обязаны обрабатывать ключи, попадающие в соответствующий диапазон токенов. Поскольку для X выделяются диапазоны ключей, имеющимся узлам более не приходится хранить эти ключи, и узлы передают эти ключи на X.
- Согласуются истории изменения принадлежности узлов, а также поддерживается согласованное в конечном счете представление о принадлежности узлов. При этом информация передается по протоколу, работающему по принципу сплетен (он описан выше).
Удаление узла
- Если узел будет удален или окажется недоступен из-за отказов, он списывается навсегда. Следовательно, изменения в принадлежности узлов распространяются с целью уведомить другие узлы о том, что один из узлов был удален.
- Что касается диапазонов ключей, которые обрабатывались удаленным узлом, эти диапазоны случайным образом распределяются по оставшимся узлам. Следовательно, нагрузка распределяется по оставшимся узлам равномерно.
Операции чтения
- Клиентские запросы равномерно присваиваются узлам в кольце; это делает балансировщик нагрузки. При запросе на операцию чтения любой узел может выступить в качестве координатора.
- Узел, координирующий запрос на чтение, отправит запрос всем N узлам с ключом K и будет ждать ответа от R из N узлов.
- Собираем данные, определяем, требуется ли их сверка (как обсуждалось выше). Этот процесс называется «чтение с исправлением» (read repair), поскольку исправляет реплики, пропустившие недавние обновления и снимает эту нагрузку с протокола синхронизации реплик.
Операции записи
- В отличие от запросов на чтение, запросы на запись координируются одной из реплик узла, содержащего элемент данных с ключом K. Если узел, получивший запрос, не является такой репликой, то он переадресует запрос одной из N реплик, обладающих заданным ключом K. Такое ограничение возникает потому, что такие предпочтительные узлы дополнительно обременены: им нужно создавать метки для новых версий. Если схема версионирования основана на физических метках, то любой узел может скоординировать запрос на запись.
- Дожидаемся, пока ответят W узлов из N.
Библиотека клиента-приложения может обладать информацией о секционировании диска и напрямую перенаправлять запросы к тем координирующим узлам, которые за эти запросы отвечают. В таком случае удается снизить задержку, поскольку экономится лишний сетевой переход – его приходилось бы преодолевать, если бы балансировщик нагрузки присваивал запрос узлу, выбираемому случайным образом.
Сложности
- Поскольку токены в кольце выбираются случайным образом, их диапазоны варьируются по размеру. По мере того, как узлы присоединяются к системе и покидают ее, набор токенов меняется и, соответственно, меняются диапазоны. Поэтому стратегия «отображаем узел на T токенов» представляет для нас следующие вызовы:
- Когда новый узел присоединяется к системе, те узлы, что обрабатывают данные из ключевых диапазонов, которые должны быть поручены новому узлу, должны просканировать свои локальные персистентные хранилища и извлечь соответствующий набор элементов данных. Такие операции сканирования очень ресурсоемкие, и их необходимо выполнять в фоновом режиме, так, чтобы у пользователя не возникло никаких проблем с производительностью. Более того, когда задача начальной загрузки выполняется с минимальным приоритетом, сам процесс начальной загрузки серьезно замедляется и в пиковые часы становится обременительным.
- Когда узел присоединяется к системе или покидает ее, меняются диапазоны ключей, обрабатываемые некоторыми другими узлами; в результате требуется пересчитывать деревья Меркла для новых диапазонов, а в продакшене такая операция нетривиальна.
- Наконец, нельзя просто так взять и сделать мгновенный снимок целого пространства ключей, поскольку пространства ключей по определению случайны. Именно поэтому процесс архивации в данном случае осложнен. В данном случае, чтобы заархивировать целое пространство ключей, это пространство требует извлекать ключи с каждого узла отдельно, что очень неэффективно.
Фундаментальная проблема данной стратегии заключается во взаимозависимости между секционированием данных (по токенам) и размещением данных (на узлах для их хранения). Таким образом, невозможно добавить или удалить узлы, не затронув при этом сегментирование данных.
Отображение узла на T токенов и равновеликих Q-разделов
T токены на узел и равновеликие Q-разделы
При такой стратегии хеш-пространство делится на Q равновеликих разделов фиксированного размера (они же – диапазоны ключей), и каждому узлу присваивается T случайных токенов. В данном случае не токены определяют, каким будет секционирование, поэтому два последовательных токена не задают ни диапазон ключей, ни раздел (они определяют только позиции узлов в кольце).
У данной стратегии следующие достоинства:
- Секционирование открепляется от размещения разделов. Элемент данных отображается на один из Q-разделов, в зависимости от ключа K этого элемента, тогда как узел, отвечающий за хранение этого элемента данных, выбирается путем обхода кольца по часовой стрелке, начиная с конца раздела, содержащего ключ K. Как только на этом пути попадается первый токен, отыскивается и соответствующий ему узел-хранилище.
- Мы получаем возможность менять схему размещения прямо во время выполнения. Добавление или удаление узла никак не влияет на принадлежность элемента данных к тому или иному разделу (диапазону ключей).
Q обычно задается так, чтобы Q > S*T, где S – количество узлов в системе.
Правда, степень случайности присвоенных T-токенов и, следовательно, диапазонов ключей, по-прежнему является дилеммой. Узлы, передающие данные другим узлам, сканируют собственные локальные персистентные хранилища, что замедляет начальную загрузку. Приходится заново рассчитывать деревья Меркла, а мгновенные снимки делать не так просто.
Отображение узла на Q/S токены и равновеликие Q-разделы
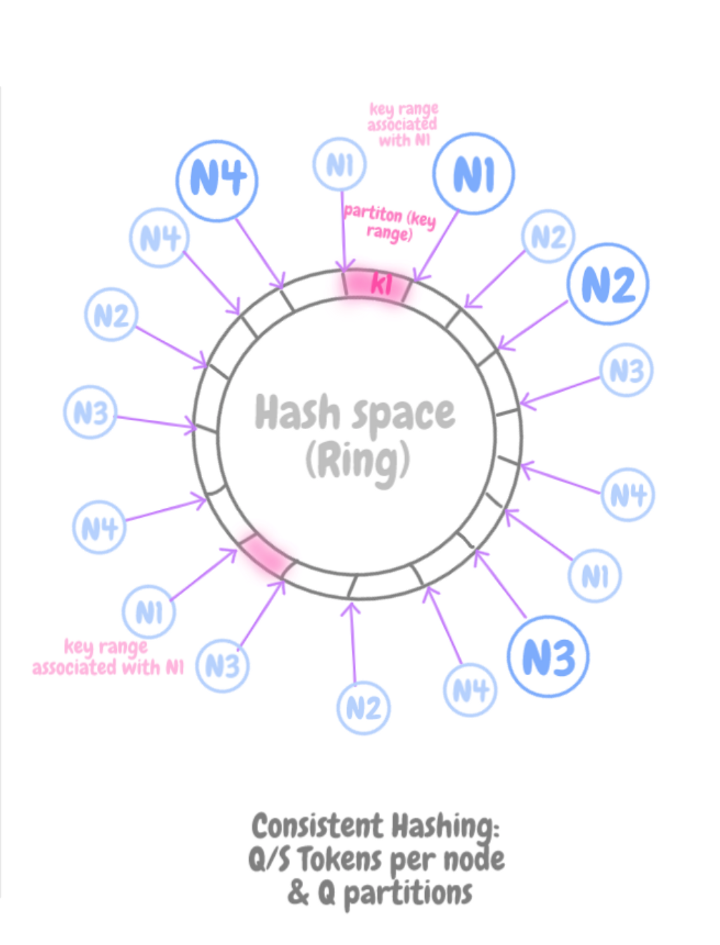
Q/S токены на узел и равновеликие Q-разделы
При такой стратегии, как и при стратегии 2, хеш-пространство делится на Q равновеликих размеров, и размещение данных открепляется от секционирования данных.
Кроме того, каждому узлу присваивается Q/S токенов (т.e. T = Q/S).
Количество токенов изменяется по мере добавления или удаления узлов.
Когда узел покидает систему, его токены случайным образом перераспределяются между оставшимися узлами, с сохранением имевшихся свойств. Аналогично, когда к системе присоединяется новый узел, он отбирает токены у других узлов системы так, чтобы все свойства системы сохранились.
У этой стратегии есть следующие достоинства:
- Ускоряется начальная загрузка и восстановление. Поскольку диапазоны ключей в разделах являются фиксированными, они могут храниться в отдельных файлах, и, следовательно, раздел можно перемещать как модуль, просто пересылая файл. Так исключается случайный доступ при попытках найти конкретные элементы.
- Легкость архивации: файлы разделов можно архивировать отдельно друг от друга. Напротив, при рассмотренных выше стратегиях выбор токенов случаен, и для архивации сохраненных данных требуется извлекать ключи из каждого узла отдельно. Обычно такой подход неэффективный и медленный.
Недостаток этой стратегии в том, что, добавляя и удаляя узлы, требуется сохранять свойства системы (т. e. T = Q/S).

