
В этой небольшой статье я хотел бы рассказать о средствах мониторинга, использующихся для анализа работы DWH нашего банка. Статья будет интересна всем, кого не устраивают существующие готовые системы мониторинга и кого посещали мысли собрать таковую «под себя» из отдельных кусочков. Большое внимание в статье уделяется дашборду Grafana, который, по моему мнению, незаслуженно обделён вниманием на Хабре. По большинству компонентов системы мониторинга будет вкратце рассмотрен процесс инсталяции (под RedHat).

Тёплый ламповый дашборд
Постановка задачи
На первый взгляд задача довольно проста и банальна: иметь средство, с помощью которого максимально малым числом телодвижений за минимальное время можно по возможности полно оценить состояние всех систем хранилища, а также иметь возможность оповещать отдельных заинтересованных лиц о том или ином событии. Однако здесь стоит кратко рассказать об особенностях систем, за которыми необходим присмотр:
Выбор из существующих
Безусловно, первым делом взор пал на уже существующие системы: Nagios, Zabbix (в большей степени), Munin. Каждая из них по-своему хороша, каждая имеет свои области применения. На Хабре достаточно информации о каждой системе из перечисленных, поэтому перечислю лишь некоторые доводы, по которым мы отказались от готовой системы в принципе:

Рис. 1 График в Zabbix. Во всех рассмотренных готовых системах возможностей для работы с графиками совсем немного.
Также, в случае, если мы хотим строить график некой функции от метрики (например, производную или экспоненту), значение функции придётся вычислять на стороне самописного демона, отсылающего данные.
Кроме того, Zabbix и Nagios используются в банке для более низкоуровневого мониторинга (состояние железа), и кое-какой опыт их использования был. Вкратце – всеми фибрами души чувствовалось, что это не то, что нам нужно.
Graphite
Итак, в процессе поиска системы, способной красиво и доходчиво визуализировать такой разношерстный набор метрик, был обнаружен Graphite. Первые впечатления от описаний были только положительными, плюс весомый вклад в решение развернуть тестовую инсталляцию внесла лекция Яндекса, в которой ребята решали довольно похожую задачу. Так у нас завёлся Graphite.
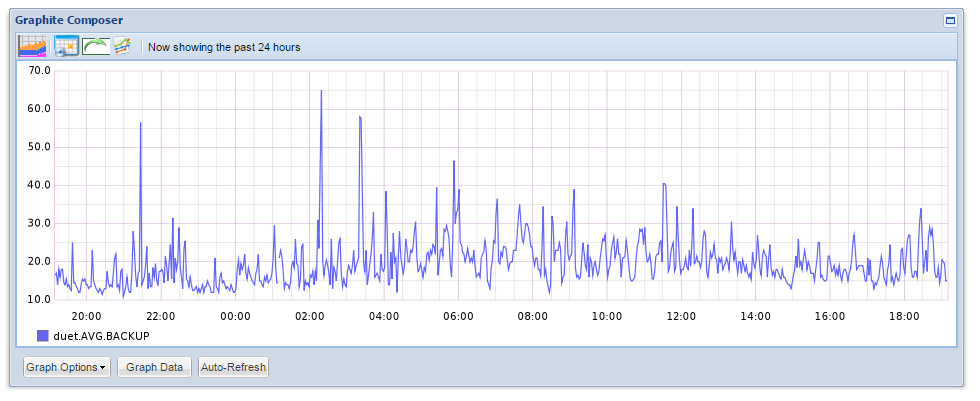
Рис. 2 График в Graphite
Graphite есть ничто иное, как система для онлайн-отрисовки графиков. Упрощённо — он просто принимает метрику по сети и ставит точку на графике, к которому вы в дальнейшем можете обращаться тем или иным способом. Метрики отсылаются в формате «Папка1.Папка2.Название_метрики Значение_метрики Временная_метка». Например, простейшая отсылка метрики Test, которая расположена в директории Folder и на текущий момент времени имеет значение 1, из bash будет выглядеть как-то так:
Просто, не правда ли?
Архитектурно Graphite состоит из трёх компонентов:
Чем Graphite понравился:
Что разочаровало:
Grafana
Итак, какое-то время мы работали с графитом. Появилась тестовая и продуктовая инсталляции, в управляющий код Duet'а были добавлены отсылки метрик, были написаны демоны для мониторинга состояния Greenplum, написано приложение для подсчёта и отсылки в Graphite латентности Attunity. Появилось некое наглядное представление о работе систем, например, по историческим графикам работы Duet'а была выявлена крупная проблема. Оповещения реализовывались сторонним кодом (bash, sas).
Но совершенству нет предела, и через какое-то время нам захотелось большего — так мы вышли на графану.
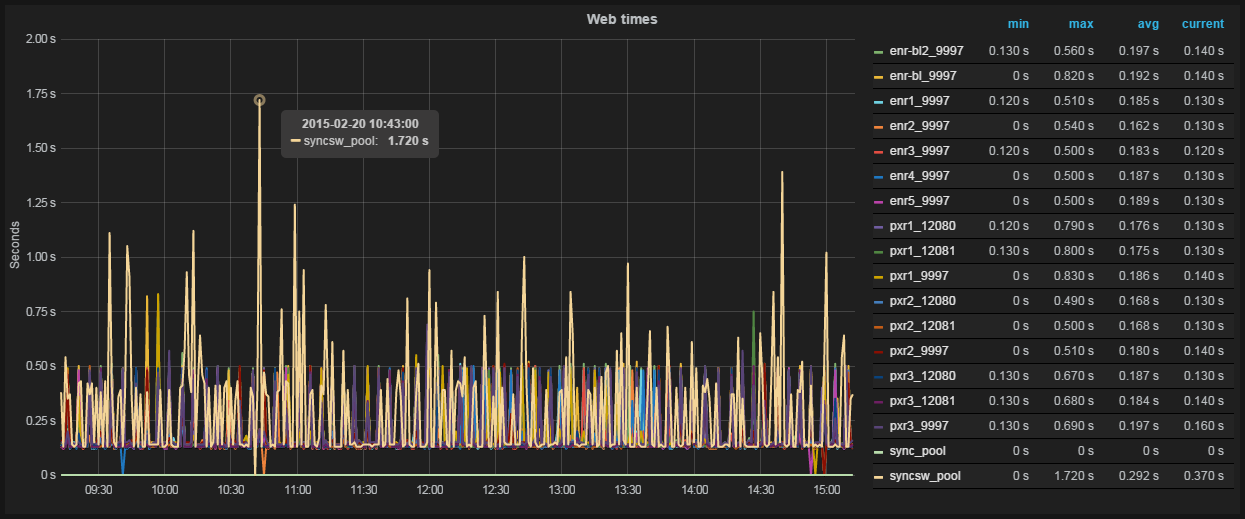
Рис. 3 График и таблица значений в Grafana
Grafana — редактор графиков и дашбордов, базирующийся на данных из Graphite, InfluxDB или OpenTSDB, специализирующийся именно на отображении и анализе информации. Он лёгок, относительно прост в установке, и самое главное — он невероятно красивый. На борту:
Функционально графана представляет собой набор пользовательских дашбордов, разделённых на строки задаваемой пользователем высоты, в которых, в свою очередь, можно создавать функциональные элементы (графики, html-вставки и плашки-триггеры). Строки можно перемещать, переименовывать и вообще всячески над ними издеваться.
Естественно, главными функциональными элементами дашборда являются графики. Создание нового графика-метрики в Графане совершенно не требует каких-либо специальных знаний — всё делается легко и понятно:
1. На график добавляются метрики из Graphite'а — всё происходит в GUI, можно указать все метрики в конкретной папке и т.д.;
2. Если необходимо, на метрики накладываются функции, которые применяются к метрикам перед их отображением. Помимо простых и часто используемых (масштаб, среднее, процентили...) есть и более интересные — например, с помощью функции aliasByNode() графана сама может определить, как именно стоит назвать метрики на графиках. Простой пример, есть две метрики:
Servers.ServerA.cpu
Servers.ServerB.cpu
По умолчанию метрики будут называться одинаково — cpu. Если же воспользоваться вышеприведённой функцией, на графике отобразятся ServerA и ServerB;
3. Редактируем оси (есть автомасштабирование большинства популярных величин — время, размер файлов, скорость), название графика;
4. Подстраиваем стиль отображения (заполнение, линия/столбцы, суммирование метрик, таблица со значениями и т.д.);
График готов. По желанию добавляем html-контент в дашборд и простые плашки-триггеры (привязываются к одной метрике, меняют цвет плашки или текста на ней, если метрика выходит за заданные рамки).
Таким образом можно практически во всех деталях подстроить под себя отображение любых данных.
Преимущества Grafan'ы:
Недостатки:
К слову сказать, в версии графаны 2.0 планируется добавить и авторизацию, и оповещения.
Diamond
Хорошо, скажете вы, мы научились посылать метрики из нужных нам систем и отображать их на графике как нам надо — но если помимо наших супер-уникальных метрик нам хочется лицезреть ещё и такие близкие любому администратору и пользователю Zabbix/Nagios величины, как cpu usage, iops, network usage — для каждой такой метрики тоже придётся писать своего демона на bash и запихивать его в cron?! Конечно же, нет — ведь есть Diamond.
Diamond — демон, написанный на python, который собирает и отправляет системную информацию в graphite и ещё несколько других систем. Функционально он состоит из коллекторов — отдельных демонов-парсеров, которые и добывают информацию из системы. Фактически коллекторами покрыт весь спектр объектов для мониторинга — от cpu до mongoDB.
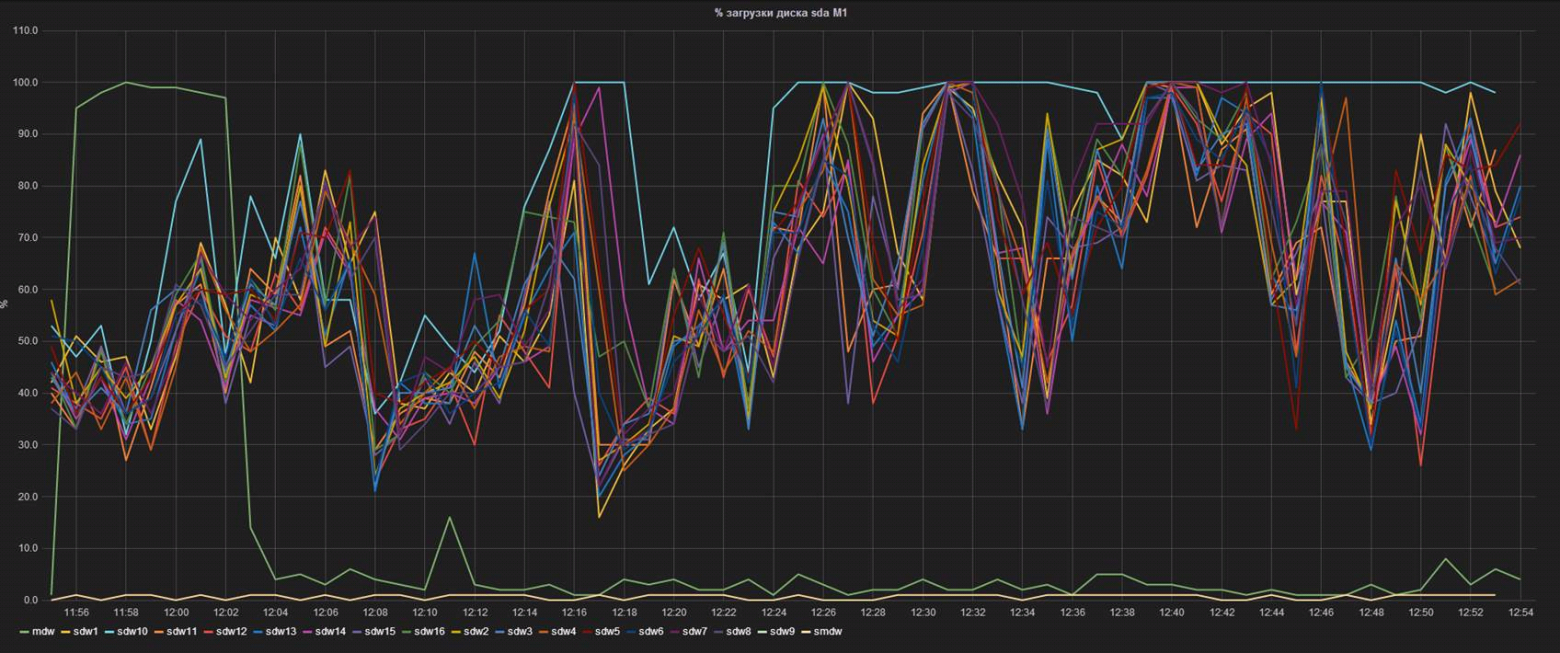
Рис. 4 Производительность одного из серверов-сегментов выбивается из общей кучи
Здесь каждая линия — % загруженности контроллера на одном из серверов-сегментов БД. Видно, что сегмент с именем sdw10, при равных IOPS (видно на соседнем графике), загружен гораздо сильнее. Знание этой особенности позволило нам, во-первых, заранее подготовиться к замене, и во-вторых, начать переговоры с вендором о возможной досрочной замене дисков по факту проседания производительности.
Seyren
Итак, основная проблема — визуализация и получение данных — решена. Мы имеем красивые, гибкие дашборды с отображением текущей и исторической информации, умеем отсылать метрики из различных систем и легко добавлять новые системные показатели. Осталось одно — научиться оповещать заинтересованных лиц о том или ином событии. Тут на помощь нам приходит Seyren — небольшой и очень простой дашборд, умеющий оповещать пользователей тем или иным способом, когда одна их метрик переходит в новое состояние. На практике это означает следующее: пользователь создаёт проверку по определённой метрике из Graphite и задаёт в ней два предела — WARN и ERROR-уровни. Затем добавляет подписчиков, указывает канал, с помощью которого их необходимо оповестить (Email, Flowdock, HipChat, HTTP, Hubot, IRCcat, PagerDuty, Pushover, SLF4J, Slack, SNMP, Twilio) и расписание оповещений (например, оповещать только по будням).
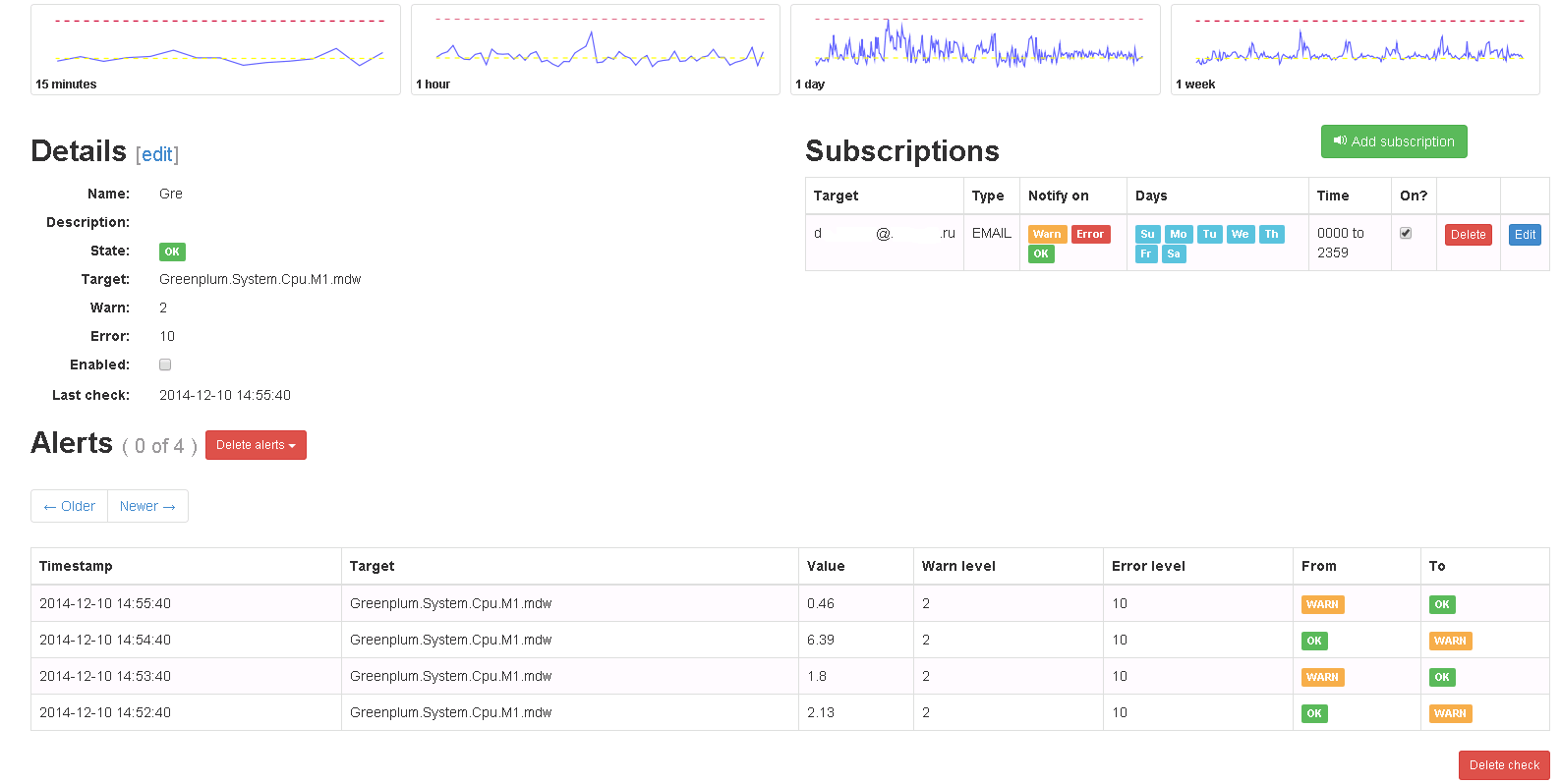
Рис. 5 Проверка в Seyren
В дальнейшем, когда метрика достигает одного из пределов, рассылаются оповещения с указанием критичности. При возврате метрики в прежнее состояние происходит то же самое.
Необходимо отметить один не очевидный момент: чтобы Seyren подцепила метрику из Graphite, необходимо полностью, с учётом регистра, ввести её название при создании проверки.
Как видно, оповещения довольно простые и реагируют только на линейное изменение метрики — в нашем случае этого достаточно. С помощью Seyren не получится создать оповещение, которое, например, реагирует на изменение средней величины за последние полчаса. Тем, кому необходимы проверки такого рода, рекомендую обратить внимание на Cabot — полный аналог Seyren, имеющий возможность создавать проверки на результат применения функций к метрикам Graphite. Cabot распространяется в виде инстанса для AWS или DigitalOcean, здесь же описывается как выполнить bare-metal установку на CentOS.
Заключение
Итого, на выходе мы имеем практически готовую систему мониторинга, по многим параметрам превосходящую существующие «цельные» решения. Кроме того, интеграция новых сервисов в такую систему будет намного более гибкой (хотя в чём-то, может быть, и более трудоёмкой), а расширяемость, с учётом количества ПО, работающего с Graphite, практически безграничной.
Ссылки
Graphite
Graphite — как построить миллион графиков — запись с Yet another conference 2013
Grafana
Diamond
Seyren
Cabot
Инструкция по установке Cabot на CentOS
Наша статья про disaster recovery для Greenplum
Наша статья про Attunity CDC

Тёплый ламповый дашборд
Постановка задачи
На первый взгляд задача довольно проста и банальна: иметь средство, с помощью которого максимально малым числом телодвижений за минимальное время можно по возможности полно оценить состояние всех систем хранилища, а также иметь возможность оповещать отдельных заинтересованных лиц о том или ином событии. Однако здесь стоит кратко рассказать об особенностях систем, за которыми необходим присмотр:
- MPP RDBMS Greenplum – 4 кластера по 10-18 (в зависимости от назначения) машин в каждом. Из всех машин в кластере только две машины (мастер и standby-мастер) имеют доступ во внешнюю сеть, остальные состоят только во внутренней изолированной сети-интерконнекте;
- Dual-ETL (Duet) – более подробно про этот проект можно прочитать в соседней статье. С точки зрения мониторинга проект интересен тем, что необходимые метрики генерируются в большом количестве разных сред: bash-скриптах, SAS-коде, БД Oracle и Greenplum;
- Attunity CDC – подробности также можно найти в соседней статье. Ключевой показатель этой системы – латентность, то есть время, прошедшее между появлением/изменением записи в БД-источнике (Oracle) и аналогичным событием в приёмнике (Greenplum);
- ETL-процессы и используемое в них железо – необходимо максимально полно осветить процессы загрузки и преобразования данных;
- 18 веб-сервисов различного назначения – наиболее простая задача. Заказчику хотелось иметь представление о времени ответа сервиса и о времени его доступности;
- Несколько других несложных метрик.
Выбор из существующих
Безусловно, первым делом взор пал на уже существующие системы: Nagios, Zabbix (в большей степени), Munin. Каждая из них по-своему хороша, каждая имеет свои области применения. На Хабре достаточно информации о каждой системе из перечисленных, поэтому перечислю лишь некоторые доводы, по которым мы отказались от готовой системы в принципе:
- Метрики, которые бы мы хотели мониторить, довольно «узкоспециальные», и с типичными областями применения готовых систем (загрузка железа, пропускная способность сети и т. д.) имеют мало общего. Это означает, что в любом случае для каждой из систем пришлось бы писать своих демонов, отправляющих данные в мастер-систему, а это ломает всю концепцию готовых систем мониторинга;
- Основное назначение таких систем – оповещать о проблемах, для нас же главное – визуализация работы компонент, и уже вторая задача — оповещения;
- Да простят меня фанаты вышеупомянутых систем, но они… некрасивые. Их не хочется открывать на двух мониторах, подбирать разные стили отображения, вычислять средние, производные, печатать и обсуждать, масштабировать и «драг-н-дропать», накладывать графики друг на друга и искать скрытый смысл.
Рис. 1 График в Zabbix. Во всех рассмотренных готовых системах возможностей для работы с графиками совсем немного.
Также, в случае, если мы хотим строить график некой функции от метрики (например, производную или экспоненту), значение функции придётся вычислять на стороне самописного демона, отсылающего данные.
Кроме того, Zabbix и Nagios используются в банке для более низкоуровневого мониторинга (состояние железа), и кое-какой опыт их использования был. Вкратце – всеми фибрами души чувствовалось, что это не то, что нам нужно.
Graphite
Итак, в процессе поиска системы, способной красиво и доходчиво визуализировать такой разношерстный набор метрик, был обнаружен Graphite. Первые впечатления от описаний были только положительными, плюс весомый вклад в решение развернуть тестовую инсталляцию внесла лекция Яндекса, в которой ребята решали довольно похожую задачу. Так у нас завёлся Graphite.
Рис. 2 График в Graphite
Graphite есть ничто иное, как система для онлайн-отрисовки графиков. Упрощённо — он просто принимает метрику по сети и ставит точку на графике, к которому вы в дальнейшем можете обращаться тем или иным способом. Метрики отсылаются в формате «Папка1.Папка2.Название_метрики Значение_метрики Временная_метка». Например, простейшая отсылка метрики Test, которая расположена в директории Folder и на текущий момент времени имеет значение 1, из bash будет выглядеть как-то так:
echo "Folder.Test 1 $(date +%s)" |nc graphite_host 2003Просто, не правда ли?
Архитектурно Graphite состоит из трёх компонентов:
- Graphite-Web, Django web-оболочка, он же рендер графиков, в своей работе также использует mysql;
- Carbon, демон получения, кеширования и записи в Whisper входящих метрик;
- Whisper, файловая БД для хранения исторических данных о метриках. Таким образом, метрики хранятся в отдельных файлах – по файлу на метрику, что позволяет довольно удобно этими метриками управлять (переносить между инсталяциями, удалять и тд)
Чем Graphite понравился:
- все графики в одном месте, рассортированы по папкам на усмотрение пользователя, а не по названию серверов или групп серверов (привет Zabbix’у);
- временная метка для каждой метрики задаётся произвольно, то есть точки на графике можно ставить как в прошлом, так и в будущем времени – в некоторых компонентах хранилища это важно;
- на данные графиков можно накладывать функции;
- несколько симпатичных графических плюшек – заполнение, отображение столбцами и прочее;
- чуть более удобное масштабирование.
Что разочаровало:
- довольно скудные возможности по созданию дашборда;
- во многих нюансах сильно не хватает интерактивности;
- функционала оповещения нет в принципе;
- нет возможности посмотреть таблицу значений метрик.
Установка Graphite
#
#Прошу учесть, что здесь и далее при изменении конфигов приведены не полные конфиги, а только блоки, нуждающиеся в редактировании
#
#Graphite использует для своих нужд mysql – в данном случае она ставится на тот же хост, что и сам Graphite
yum --nogpgcheck install graphite-web graphite-web-selinux mysql mysql-server MySQL-python python-carbon python-whisper
service mysqld start
/usr/bin/mysql_secure_installation
#говорим графиту, как именно ему надо ходить в mysql - редактируем /etc/graphite-web/local_settings.py:
DATABASES = {
'default': {
'NAME': 'graphite',
'ENGINE': 'django.db.backends.mysql',
'USER': 'graphite',
'PASSWORD': 'your_pass',
'HOST': 'localhost',
'PORT': '3306',
}
}
mysql -e "CREATE USER 'graphite'@'localhost' IDENTIFIED BY 'your_pass';" -u root -p #создаём пользователя, указанного в конфиге выше
mysql -e "GRANT ALL PRIVILEGES ON graphite.* TO 'graphite'@'localhost';" -u root -p #даём пользователю права
mysql -e "CREATE DATABASE graphite;" -u root -p #создаём БД
mysql -e 'FLUSH PRIVILEGES;' -u root -p #применяем изменения
/usr/lib/python2.6/site-packages/graphite/manage.py syncdb
service carbon-cache start
service httpd start
#Идём на 80-й порт и наблюдаем девственный Graphite. По желанию в файле /etc/carbon/storage-schemas.conf можно настроить динамический интервал хранения метрик (хранить меньше (реже) старых точек и больше (чаще) новых)
Grafana
Итак, какое-то время мы работали с графитом. Появилась тестовая и продуктовая инсталляции, в управляющий код Duet'а были добавлены отсылки метрик, были написаны демоны для мониторинга состояния Greenplum, написано приложение для подсчёта и отсылки в Graphite латентности Attunity. Появилось некое наглядное представление о работе систем, например, по историческим графикам работы Duet'а была выявлена крупная проблема. Оповещения реализовывались сторонним кодом (bash, sas).
Но совершенству нет предела, и через какое-то время нам захотелось большего — так мы вышли на графану.
Рис. 3 График и таблица значений в Grafana
Grafana — редактор графиков и дашбордов, базирующийся на данных из Graphite, InfluxDB или OpenTSDB, специализирующийся именно на отображении и анализе информации. Он лёгок, относительно прост в установке, и самое главное — он невероятно красивый. На борту:
- полноценные дашборды с графиками, тригерами, html-вставками и прочими плюшками;
- скроллинг, зумминг и прочий -инг;
- сортируемые таблицы значений (min, max, avg, current, total);
- поддержка всех функций графита.
Функционально графана представляет собой набор пользовательских дашбордов, разделённых на строки задаваемой пользователем высоты, в которых, в свою очередь, можно создавать функциональные элементы (графики, html-вставки и плашки-триггеры). Строки можно перемещать, переименовывать и вообще всячески над ними издеваться.
Естественно, главными функциональными элементами дашборда являются графики. Создание нового графика-метрики в Графане совершенно не требует каких-либо специальных знаний — всё делается легко и понятно:
1. На график добавляются метрики из Graphite'а — всё происходит в GUI, можно указать все метрики в конкретной папке и т.д.;
2. Если необходимо, на метрики накладываются функции, которые применяются к метрикам перед их отображением. Помимо простых и часто используемых (масштаб, среднее, процентили...) есть и более интересные — например, с помощью функции aliasByNode() графана сама может определить, как именно стоит назвать метрики на графиках. Простой пример, есть две метрики:
Servers.ServerA.cpu
Servers.ServerB.cpu
По умолчанию метрики будут называться одинаково — cpu. Если же воспользоваться вышеприведённой функцией, на графике отобразятся ServerA и ServerB;
3. Редактируем оси (есть автомасштабирование большинства популярных величин — время, размер файлов, скорость), название графика;
4. Подстраиваем стиль отображения (заполнение, линия/столбцы, суммирование метрик, таблица со значениями и т.д.);
Несколько примеров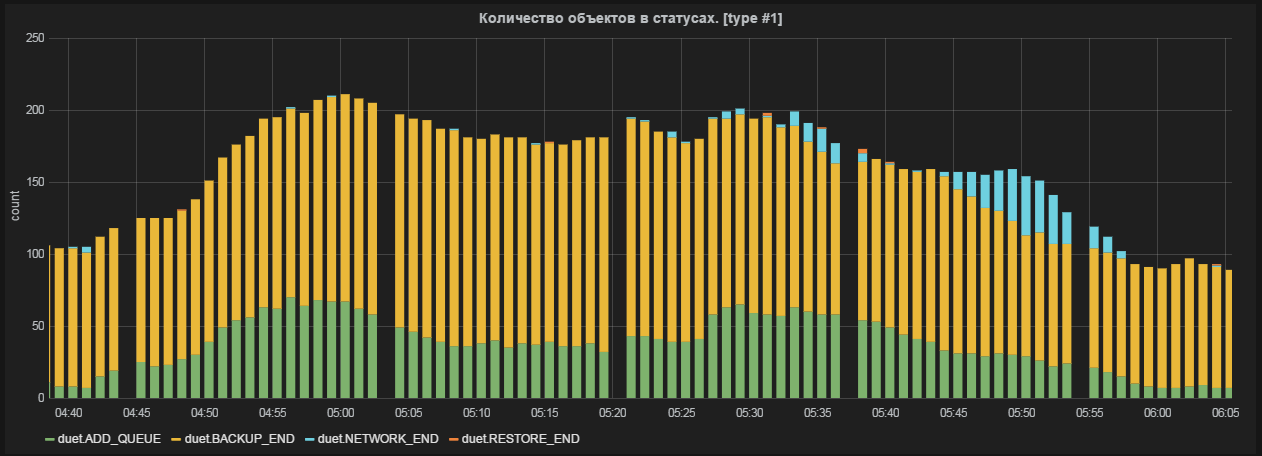
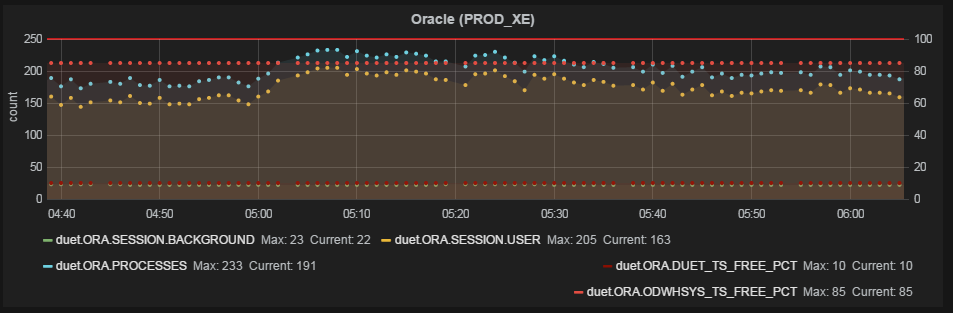
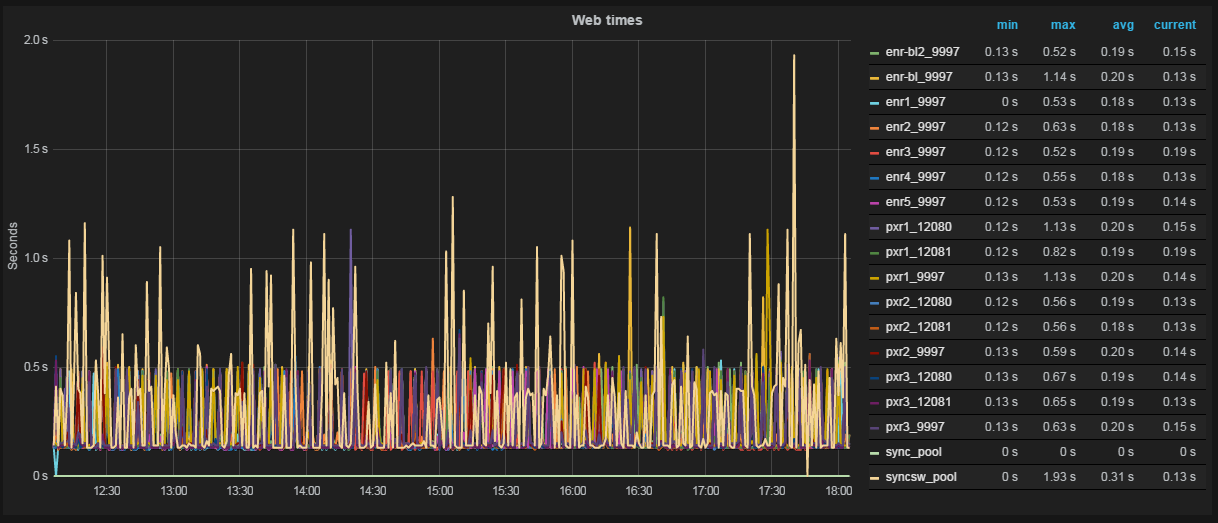

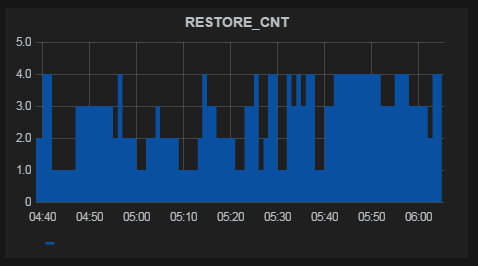
График готов. По желанию добавляем html-контент в дашборд и простые плашки-триггеры (привязываются к одной метрике, меняют цвет плашки или текста на ней, если метрика выходит за заданные рамки).
Таким образом можно практически во всех деталях подстроить под себя отображение любых данных.
Преимущества Grafan'ы:
- гибкость — настраивается всё и вся;
- usability — она удобна настолько же, насколько и красива;
- перед отображением метрики можно применять к ней математические/статистические функции;
- обсчёт графиков происходит на стороне клиента (хотя в некоторых ситуациях это можно отнести к недостаткам);
Недостатки:
- нет авторизации — любой может изменить ваши графики и дашборды;
- нет оповещений;
К слову сказать, в версии графаны 2.0 планируется добавить и авторизацию, и оповещения.
Установка grafana
#Скачать:
elasticsearch-1.1.1 #http://www.elasticsearch.org/downloads/1-1-1/
grafana-1.9.1.tar #http://grafana.org/download/, актуальная на момент написания статьи версия
nohup ./elasticsearch & #запускаем в фоне elasticsearch из папки, которую только что скачали
mkdir /opt/grafana
cp grafana-1.9.1/* /opt/grafana
cp config.sample.js config.js
vi config.js
#для установки grafana на ту же машину, что и graphite, модифицируем блок:
graphite: {
type: 'graphite',
url: "http://"+window.location.hostname+":80",
default: true
},
vi /etc/httpd/conf.d/graphite-web.conf:
Header set Access-Control-Allow-Origin "*"
Header set Access-Control-Allow-Methods "GET, OPTIONS"
Header set Access-Control-Allow-Headers "origin, authorization, accept"
vi /etc/httpd/conf.d/grafana.conf:
Listen 8080
<VirtualHost *:8080>
DocumentRoot /opt/grafana/
</VirtualHost>
service httpd restart
Diamond
Хорошо, скажете вы, мы научились посылать метрики из нужных нам систем и отображать их на графике как нам надо — но если помимо наших супер-уникальных метрик нам хочется лицезреть ещё и такие близкие любому администратору и пользователю Zabbix/Nagios величины, как cpu usage, iops, network usage — для каждой такой метрики тоже придётся писать своего демона на bash и запихивать его в cron?! Конечно же, нет — ведь есть Diamond.
Diamond — демон, написанный на python, который собирает и отправляет системную информацию в graphite и ещё несколько других систем. Функционально он состоит из коллекторов — отдельных демонов-парсеров, которые и добывают информацию из системы. Фактически коллекторами покрыт весь спектр объектов для мониторинга — от cpu до mongoDB.
Внушительный полный список коллекторов
Каждый коллектор, в свою очередь, обрабатывает и отсылает в систему-приёмник (в нашем случае Graphite) несколько метрик. Например, в случае network-коллектора для каждого сетевого интерфейса отсылается аж 18 метрик. Таким образом, в нашей системе мониторинга покрывается, как мне кажется, главная функциональность Zabbix'а и Nagios'а — добавление новых системных метрик в один-два клика. В частности, небольшой, но яркий опыт администрирования Greenplum подсказывал, что крайне важным параметром работы БД является нагрузка на дисковую подсистему на серверах-сегментах. Был создан отдельный дашборд с графиками iops, % загруженности, await и service time RAID-контроллеров серверов-сегментов (использует /proc/diskstats). Недолгое наблюдение выявило интересную закономерность: перед тем, как диск в контроллере отдавал концы и утилита контроля состояния RAID-контроллера сообщала о необходимой замене диска, производительность всего массива сильно проседала:AmavisCollector
ApcupsdCollector
BeanstalkdCollector
BindCollector
CPUCollector
CassandraJolokiaCollector
CelerymonCollector
CephCollector
CephStatsCollector
ChronydCollector
ConnTrackCollector
CpuAcctCgroupCollector
DRBDCollector
DarnerCollector
DiskSpaceCollector
DiskUsageCollector
DropwizardCollector
DseOpsCenterCollector
ElasticSearchCollector
ElbCollector
EndecaDgraphCollector
EntropyStatCollector
ExampleCollector
EximCollector
FilesCollector
FilestatCollector
FlumeCollector
GridEngineCollector
HAProxyCollector
HBaseCollector
HTTPJSONCollector
HadoopCollector
HttpCollector
HttpdCollector
IODriveSNMPCollector
IPCollector
IPMISensorCollector
IPVSCollector
IcingaStatsCollector
InterruptCollector
JCollectdCollector
JbossApiCollector
JolokiaCollector
KSMCollector
KVMCollector
KafkaCollector
LMSensorsCollector
LibvirtKVMCollector
LoadAverageCollector
MemcachedCollector
MemoryCgroupCollector
MemoryCollector
MemoryDockerCollector
MemoryLxcCollector
MongoDBCollector
MonitCollector
MountStatsCollector
MySQLCollector
MySQLPerfCollector
NagiosPerfdataCollector
NagiosStatsCollector
NetAppCollector
NetscalerSNMPCollector
NetworkCollector
NfsCollector
NfsdCollector
NginxCollector
NtpdCollector
NumaCollector
OneWireCollector
OpenLDAPCollector
OpenVPNCollector
OpenstackSwiftCollector
OpenstackSwiftReconCollector
OssecCollector
PassengerCollector
PgbouncerCollector
PhpFpmCollector
PingCollector
PostfixCollector
PostgresqlCollector
PostqueueCollector
PowerDNSCollector
ProcessResourcesCollector
ProcessStatCollector
PuppetAgentCollector
PuppetDBCollector
PuppetDashboardCollector
RabbitMQCollector
RedisCollector
ResqueWebCollector
S3BucketCollector
SNMPCollector
SNMPInterfaceCollector
SNMPRawCollector
ServerTechPDUCollector
SidekiqWebCollector
SlabInfoCollector
SmartCollector
SockstatCollector
SoftInterruptCollector
SolrCollector
SqsCollector
SquidCollector
SupervisordCollector
TCPCollector
TokuMXCollector
UDPCollector
UPSCollector
UnboundCollector
UptimeCollector
UserScriptsCollector
UsersCollector
VMSDomsCollector
VMSFSCollector
VMStatCollector
VarnishCollector
WebsiteMonitorCollector
XENCollector
ZookeeperCollector
ApcupsdCollector
BeanstalkdCollector
BindCollector
CPUCollector
CassandraJolokiaCollector
CelerymonCollector
CephCollector
CephStatsCollector
ChronydCollector
ConnTrackCollector
CpuAcctCgroupCollector
DRBDCollector
DarnerCollector
DiskSpaceCollector
DiskUsageCollector
DropwizardCollector
DseOpsCenterCollector
ElasticSearchCollector
ElbCollector
EndecaDgraphCollector
EntropyStatCollector
ExampleCollector
EximCollector
FilesCollector
FilestatCollector
FlumeCollector
GridEngineCollector
HAProxyCollector
HBaseCollector
HTTPJSONCollector
HadoopCollector
HttpCollector
HttpdCollector
IODriveSNMPCollector
IPCollector
IPMISensorCollector
IPVSCollector
IcingaStatsCollector
InterruptCollector
JCollectdCollector
JbossApiCollector
JolokiaCollector
KSMCollector
KVMCollector
KafkaCollector
LMSensorsCollector
LibvirtKVMCollector
LoadAverageCollector
MemcachedCollector
MemoryCgroupCollector
MemoryCollector
MemoryDockerCollector
MemoryLxcCollector
MongoDBCollector
MonitCollector
MountStatsCollector
MySQLCollector
MySQLPerfCollector
NagiosPerfdataCollector
NagiosStatsCollector
NetAppCollector
NetscalerSNMPCollector
NetworkCollector
NfsCollector
NfsdCollector
NginxCollector
NtpdCollector
NumaCollector
OneWireCollector
OpenLDAPCollector
OpenVPNCollector
OpenstackSwiftCollector
OpenstackSwiftReconCollector
OssecCollector
PassengerCollector
PgbouncerCollector
PhpFpmCollector
PingCollector
PostfixCollector
PostgresqlCollector
PostqueueCollector
PowerDNSCollector
ProcessResourcesCollector
ProcessStatCollector
PuppetAgentCollector
PuppetDBCollector
PuppetDashboardCollector
RabbitMQCollector
RedisCollector
ResqueWebCollector
S3BucketCollector
SNMPCollector
SNMPInterfaceCollector
SNMPRawCollector
ServerTechPDUCollector
SidekiqWebCollector
SlabInfoCollector
SmartCollector
SockstatCollector
SoftInterruptCollector
SolrCollector
SqsCollector
SquidCollector
SupervisordCollector
TCPCollector
TokuMXCollector
UDPCollector
UPSCollector
UnboundCollector
UptimeCollector
UserScriptsCollector
UsersCollector
VMSDomsCollector
VMSFSCollector
VMStatCollector
VarnishCollector
WebsiteMonitorCollector
XENCollector
ZookeeperCollector
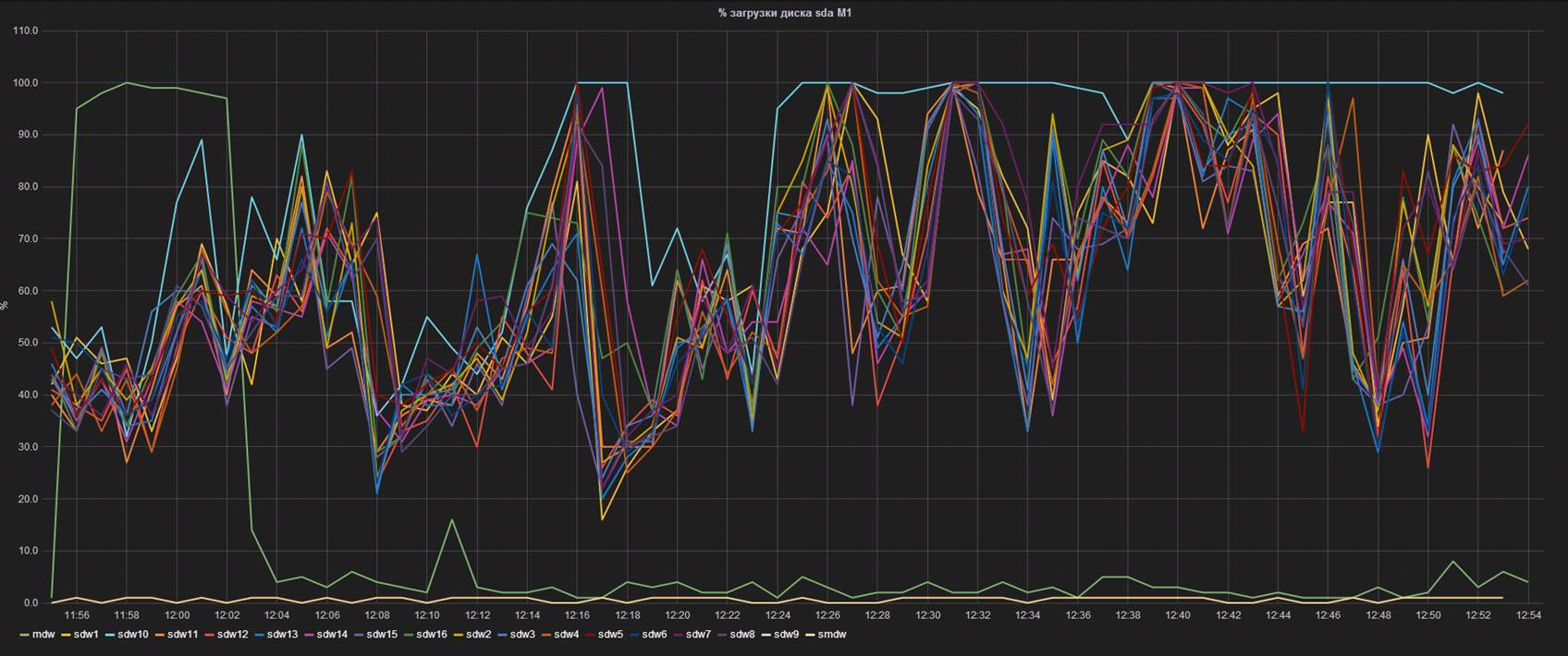
Рис. 4 Производительность одного из серверов-сегментов выбивается из общей кучи
Здесь каждая линия — % загруженности контроллера на одном из серверов-сегментов БД. Видно, что сегмент с именем sdw10, при равных IOPS (видно на соседнем графике), загружен гораздо сильнее. Знание этой особенности позволило нам, во-первых, заранее подготовиться к замене, и во-вторых, начать переговоры с вендором о возможной досрочной замене дисков по факту проседания производительности.
Установка Diamond
yum install build-essentials python-dev python python-devel psutil python-configobj
#Скачиваем https://github.com/python-diamond/Diamond, разархивируем, переходим в папку, затем
make install #собираем, ставим
cp /etc/diamond/diamond.conf.example /etc/diamond/diamond.conf #копируем пример конфига
vi /etc/diamond/diamond.conf #указываем хост и порт grahit'а, частоту отсылки метрик и префикс/постфикс названия метрик, чтобы в структуре папок graphite метрики лежали так, как нам хочется, остальное по желанию
#из /usr/share/diamond/collectors/ убираем ненужные коллекторы, оставляем те, от которых хотим получать метрики
diamond-setup #интерактивно настраиваем коллекторы, большинство можно оставить по умолчанию
/etc/init.d/diamond start #поехали
Seyren
Итак, основная проблема — визуализация и получение данных — решена. Мы имеем красивые, гибкие дашборды с отображением текущей и исторической информации, умеем отсылать метрики из различных систем и легко добавлять новые системные показатели. Осталось одно — научиться оповещать заинтересованных лиц о том или ином событии. Тут на помощь нам приходит Seyren — небольшой и очень простой дашборд, умеющий оповещать пользователей тем или иным способом, когда одна их метрик переходит в новое состояние. На практике это означает следующее: пользователь создаёт проверку по определённой метрике из Graphite и задаёт в ней два предела — WARN и ERROR-уровни. Затем добавляет подписчиков, указывает канал, с помощью которого их необходимо оповестить (Email, Flowdock, HipChat, HTTP, Hubot, IRCcat, PagerDuty, Pushover, SLF4J, Slack, SNMP, Twilio) и расписание оповещений (например, оповещать только по будням).
Рис. 5 Проверка в Seyren
В дальнейшем, когда метрика достигает одного из пределов, рассылаются оповещения с указанием критичности. При возврате метрики в прежнее состояние происходит то же самое.
Необходимо отметить один не очевидный момент: чтобы Seyren подцепила метрику из Graphite, необходимо полностью, с учётом регистра, ввести её название при создании проверки.
Установка Seyren
#Для работы Seyren требует MongoDB, а потому
sudo yum install mongodb-org
sudo service mongod start
#Скачать https://github.com/scobal/seyren/releases/download/1.1.0/seyren-1.1.0.jar
mkdir /var/log/seyren #Создаём папку для логов
export SEYREN_LOG_PATH=/var/log/seyren/ #Параметры конфигурации seyren берёт прямо из переменных окружения. Здесь задаём путь до папки с логами
export GRAPHITE_URL="http://grahite_host:80" #Где искать graphite
export SMTP_FROM=seyren@domain.com #От кого слать почтовые алерты
nohup java -jar seyren-1.1.0.jar & #Запускаем в фоне
Как видно, оповещения довольно простые и реагируют только на линейное изменение метрики — в нашем случае этого достаточно. С помощью Seyren не получится создать оповещение, которое, например, реагирует на изменение средней величины за последние полчаса. Тем, кому необходимы проверки такого рода, рекомендую обратить внимание на Cabot — полный аналог Seyren, имеющий возможность создавать проверки на результат применения функций к метрикам Graphite. Cabot распространяется в виде инстанса для AWS или DigitalOcean, здесь же описывается как выполнить bare-metal установку на CentOS.
Заключение
Итого, на выходе мы имеем практически готовую систему мониторинга, по многим параметрам превосходящую существующие «цельные» решения. Кроме того, интеграция новых сервисов в такую систему будет намного более гибкой (хотя в чём-то, может быть, и более трудоёмкой), а расширяемость, с учётом количества ПО, работающего с Graphite, практически безграничной.
Ссылки
Graphite
Graphite — как построить миллион графиков — запись с Yet another conference 2013
Grafana
Diamond
Seyren
Cabot
Инструкция по установке Cabot на CentOS
Наша статья про disaster recovery для Greenplum
Наша статья про Attunity CDC
