
«У нас есть свой поиск!»
Два года подряд все свои выступления на конференциях я начинал этой фразой, ведь даже не все специалисты по поиску знали о том, что их запросы, заданные в поисковой строке Mail.Ru с большой долей вероятности обрабатывались не лицензированным сторонним движком, а внутренней разработкой компании.
Сейчас я вижу, что ситуация изменилась: многие знают и принимают наш поисковик. Однако вопросы или сомнения всё равно остаются – ну как так, Mail.Ru Group и пишет свой поиск? Mail.Ru Group — это почта, это социальные сети, развлечения… Что за поисковик они могут написать? Вот чтобы развеять эти сомнения, я и хочу рассказать о нашем поиске, о том, как мы его делаем, какие технологии используем, что хотим получить в итоге. Я надеюсь, что предлагаемая статья будет познавательной и интересной; более того, мы собираемся продолжить рассказ о наших технологиях уже более детально, и в следующих постах поговорить о машинном обучении, спайдере, антиспаме и т.п.
GoGo.Ru
Поисковая система Mail.Ru начала разрабатываться в 2004 году Михаилом Костиным, бывшим руководителем поисковой системы aport.ru. В 2007 году поисковик был представлен под именем GoGo на домене gogo.ru.

Уже тогда GoGo обладал довольно интересными свойствами: он мог ограничивать область поиска коммерческими и информационными сайтами, а также форумами и блогами. Через некоторое время в нём появился поиск по картинкам и первый в рунете поиск по видео.
Много внимания в нём было уделено ранжированию и оптимизации времени выполнения поисковых запросов. Например, формула текстового ранжирования GoGo участвовала в конкурсе РОМИП (Российского семинара по оценке методов информационного поиска), где показала лучшие результаты среди всех участников (см. www.romip.ru/romip2005/09_mailru.pdf ).
От GoGo — к Go.Mail.Ru
Всё это время запросы, которые вводятся на главной странице портала Mail.Ru, выполнял лицензированный поисковый движок; сначала это был движок Google, потом — Яндекса. Но в 2009 году контракт с Яндексом закончился, и было решено c 1 января 2010 года попробовать свой собственный поисковик.
Позже мы заключили партнерство с поисковым движком Google на следующих условиях: часть запросов обрабатывает Google, другую — мы. Но это произошло только в августе 2010 года, и в течение восьми месяцев Поиск работал полностью на собственном движке.
С точки зрения разработчиков это означало совершенно иные требования к поиску: если раньше gogo.ru обслуживал сотни тысяч запросов в день, то теперь ему нужно было обслуживать десятки миллионов. Предполагаемый рост нагрузки на два порядка требовал новых архитектурных решений. Самым значительным изменением был подъём обратного индекса в оперативную память: раньше он лежал на жёстком диске, что не давало возможности уложиться в требуемое время ответа до 300 миллисекунд на запрос. И на все изменения у команды разработчиков было всего несколько месяцев, 1 января 2010 года новый поисковик должен был работать и обслуживать запросы пользователей портала Mail.Ru.
Такая задача относится к классу «mission impossible», но разработчики совершили трудовой подвиг и с ней успешно справились: переключение на новый поисковик произошло в 0:00 1 января 2010 года. Первый коммит в репозиторий Поиска, исправляющий одну из свежеобнаруженных проблем, произошёл уже в три часа новогодней ночи. И после этого, пока большая часть страны находилась на новогодних каникулах, команда Поиска, что называется, «держала небо», постоянно находя и исправляя самые разные баги.
Проблемы со стабильностью Поиска возникали и решались в течение всего года, но первые три месяца были самыми напряжёнными и требующими максимальной отдачи от всех разработчиков поисковой системы. При этом окончательно потушить пожар смогли, наверное, только к августу 2010 года. После этого Поиск наконец-то зажил нормальной жизнью, и разработчики смогли переключаться на более долгосрочные задачи, чем исправление очередной критической проблемы. В частности, можно было задуматься о том, насколько вообще текущая архитектура Поиска соответствует стоящим перед нами задачам.
Что было у нас: историческая справка за 2010 год
В 2010 году внутренняя презентация об архитектуре Поиска схематично показывала его примерно таким образом:
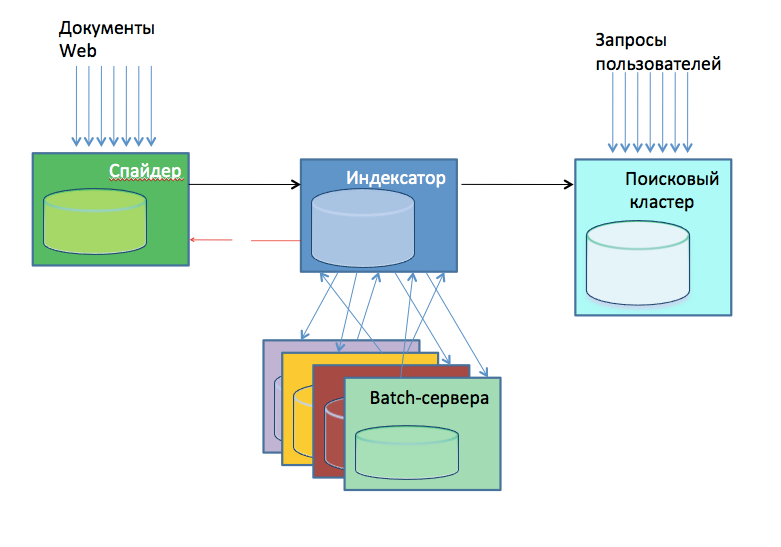
- Спайдер, качает веб. Это 24 сервера, обкачивающие каждый свою часть веба. Какую часть обкачивать, определялось хешем от имени домена. Спайдеры содержали внутри себя базу скачанных страниц, и сами определяли, что нужно качать, а что — нет.
- Индексаторы, создают готовые индексы баз. Их тоже было порядка 30 штук на конец 2010 года. Кроме непосредственно индексации, они выполняли анализ поступающих страниц на спам, порнографию и т.п., выделяли интересующие данные для обсчёта, например, ссылки для последующего построения индекса цитирования.
- Batch-серверы (около 20 штук), выполняющие обсчёты внешних данных, того же ИЦ. Расчёты были самые разнообразные: некоторые — быстрые, некоторые — медленные.
- Поисковый кластер, полторы сотни серверов. Принимали базы от индексаторов и непосредственно выполняли поисковые запросы пользователей.
В 2010 году стало понятно, что в организации хранения и обработки данных есть довольно много архитектурных изъянов: Поиск быстро развился от состояния «несколько десятков серверов» до «несколько сотен серверов», количество обрабатываемых данных и требования к скорости их обработки стали возрастать, и старые методы уже не удовлетворяли насущным требованиям к качеству работы. Например, расчёт индекса цитирования производился на одном сервере и теперь работал месяц. Если сервер за это время перезагружался или процессу не хватало памяти, то приходилось начинать всё заново; таким образом, индекс цитирования в какой-то момент времени просто перестал обновляться.
Множество исходных данных, размещаемых в индексе, рассчитывалось на разных серверах, под разными пользователями и доставлялись в индекс какими-то уникальными для данного вида данных путями. В итоге разработчики путались в том, откуда что берётся: несколько раз мы обнаруживали, что те или иные факторы по какой-то причине «отвалились» от индекса ещё месяц назад, и никто до сих пор этого не замечал.
Разработчики часто решали одни и те же задачи: как «распилить» входные данные таким образом, чтобы можно было бы распараллелить их обсчёт по нескольким дискам, а потом и по нескольким серверам. Все решения были в чём-то похожи, но в чём-то и отличались друг от друга, а кроме того, часто разработчики повторяли один и тот же тернистый путь построения системы распределённых вычислений с нуля, что явно не способствовало эффективной разработке.
Большую проблему составляло наличие двух баз документов: одна — у спайдера, другая – у индексатора. Это приводило к размытию решения относительно судьбы одного и того же документа — например, анализ спамности на индексаторе мог принять решение выкинуть документ из индекса, а спайдер продолжал бы его качать. Или, наоборот, спайдер мог выкинуть документ из своей базы по каким-то причинам, но команда на удаление документа из индекса могла из-за технического сбоя не дойти до индексатора, так что документ оставался в индексе надолго, до очередной чистки мусора.
Стало ясно, что для того, чтобы продолжать разработку поиска, нужен иной, новый подход: нам не хватало единой платформы для распределённого выполнения задач, высокопроизводительной базы данных. Предстояло сделать выбор между самостоятельной разработкой и готовым решением, и, во втором случае — найти вариант, который устраивал бы нас в плане стабильности и быстро работал бы на наших нагрузках.
В следующих постах я расскажу о том, как мы вырабатывали и реализовывали этот подход, а также о том, как работают другие поисковые системы.
Андрей Калинин,
Руководитель разработчиков Поиска Mail.ru
