
Что вам кажется привлекательней: сталкиваться с новыми интересными задачами и разрабатывать нетривиальные алгоритмы или переписывать с одного языка на другой уже существующую логику и воевать со странными особенностями конкретных API? Я занимаюсь мобильной разработкой уже лет 8, и, не раздумывая, выбираю первый вариант, но и повоевать с API тоже люблю. Тем, кто со мной согласен, но еще не знает, как заниматься первым и сводить к минимуму второе, будет интересно заглянуть под кат.
В этой статье я поделюсь с вами своими соображениями об общих принципах портирования. Мы не будем влезать в дебри конкретных программных реализаций приложений под Android или iOS. Я просто постараюсь рассказать, как сделать так, чтобы приложение легко переносилось на различные устройства и могло называться кроссплатформенным.
Для начала определим круг задач. В этой статье мы не будем затрагивать встроенные системы, которые, несомненно, тоже работают на благо мобильных технологий. Мы рассмотрим только современные мобильные девайсы: телефоны и планшеты. Первая часть статьи будет посвящена архитектуре современных мобильных процессоров и ограничениям и, наоборот, фичам, которые получает от них мобильный разработчик. Во второй части я расскажу о некоторых базовых приемах, которые необходимы для написания портируемого кода.
Не так давно, еще лет пять назад, было очень много разных фирм, выпускавших мобильные процессоры со своими архитектурами. Однако сейчас основные архитектуры можно пересчитать по пальцам одной руки, и еще останется запас. Прежде всего, это ARM. Помимо него есть MIPS, которые обычно включены в Java NDK, и Intel со своим Atom-ом.
Все методы, о которых пойдет речь дальше, применимы ко всем этим системам. Но для удобства мы рассмотрим их на примере самых распространенных ARM-процессоров. Что нам нужно о них знать?
ARM сама не выпускает процессоры, она продает лицензию на выпуск, а различные фирмы (Samsung, LG, Broadcom, Apple, Qualcomm, Freescale) покупают лицензии и выпускают свои версии процессоров, одноядерные или многоядерные — какие им заблагорассудится.
Что дает лицензирование? Вы не просто берете ядро, вы делаете свой процессор. Вы можете его дорабатывать: улучшать или, наоборот, упрощать – это ваше право. Пример из истории – это известный Intel с процессором XScale. Они купили лицензию на АRМv5TE и серьезно его переработали. На мой взгляд, это самая удачная из существующих пока переработок. Они улучшили работу с памятью, увеличили кэш, и, если сравнивать реализации Intel и Samsung на базе АRМv5TE, то Intel выигрывала раза, наверное, в два. Основной особенностью этого процессора было то, что в нем впервые появился сопроцессор с 40-битный аккумулятором, который позволял за 1 такт перемножать со сложением 4 числа, а старшие подели имели сопроцессор Wireless MMX, предоставляющий мощный набор SIMD инструкций
С точки зрения инженера, что такое система на кристалле? Это маленький микропроцессор, на который ставится куча разных устройств. Вы покупаете лицензию у ARM, ставите туда один, два -сколько хотите ядер. Дополнительные сопроцессоры (графические, DSP и др.), память (ROM, FLASH...) Помимо этого, обычно туда вставляют интерфейсы ввода/вывода: Ethernet, USB, COM-порты, если есть такая необходимость. Для того чтобы заставить все это добро работать, на этот же кристалл добавляются осцилляторы и таймеры, чтобы не выносить дополнительную обвязку отдельными блоками на плату.
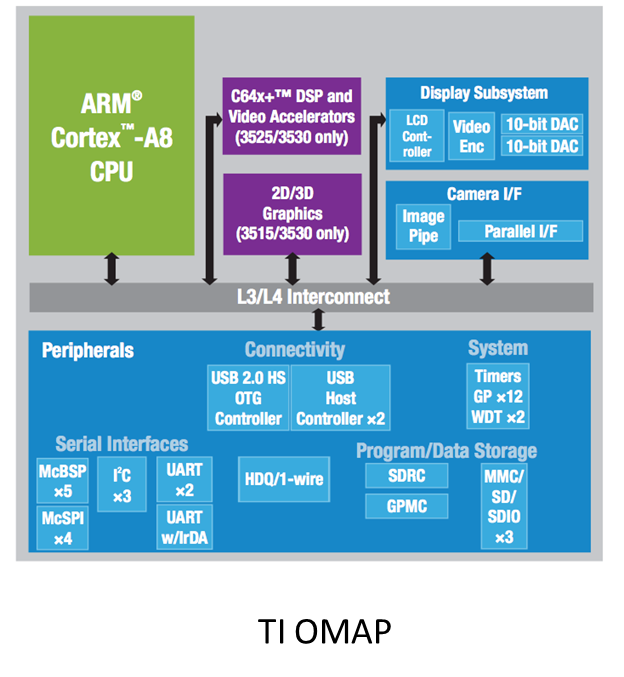
Реализация системы на кристалле стала возможна для ARM, потому что эта система имеет очень мало транзисторов по сравнению с тем же Pentium. Благодаря этому она занимает мало места на кристалле, и технологически получается вместить туда все, что захотят разработчики. Вряд ли у нас бы получилось уместить все эти юниты в Core i5 — хотя бы потому, что он сам по себе большой, да еще и с большим радиатором (поскольку транзисторов много и все они сильно нагреваются).
Рассмотрим особенности архитектуры, которые важны для разработчиков.

Как развивалось и прогрессировало семейство ARM:
Хотелось бы отдельно остановиться на последней строке таблицы из предыдущего пункта. Что такое Thumb? Изначально это был набор упакованных ARM-инструкций. Если между быстродействием и компактностью кода мы выбираем второе, то короткие 16-битные инструкции с ограниченным функционалом – отличное решение.
Thumb2 – это эволюция Thumb. Она включает в себя часть инструкций ARM, и состоит из набора 16-битных и 32-битных инструкций, призванных обеспечить плотность кода как в Thumb и при этом сохранить производительность полноценного ARM.
Возьму на себя смелость дать определение кроссплатформенности: «Кроссплатформенным кодом можно считать код, для которого затраты по переносу на другую систему намного меньше, чем затраты на написание этого кода с нуля». То есть мы не называем портированием ситуации «у меня есть какой-то алгоритм, я хочу такой же сделать на iOS — соответственно, я должен такой же написать для этой платформы». Это не портирование, это написание заново. Чтобы портировать алгоритм, он должен отвечать условиям кроссплатформенности.
Принципы написания кроссплатформенного кода я определяю как «разделение и унификация». Постараюсь объяснить, что это такое. Эти пункты не являются постулатами, это мое видение.
Остановимся на каждом пункте подробнее.
Что я имею в виду под единой типизацией? Вы просто определяете свои типы. В приведенном примере описан stdint. Он определен для компилятора Microsoft и для Linux. Если вы хотите большего контроля, вы можете написать «мой_любимый_int8», «мой_любимый_int16» и затем использовать эти типы в своей программе. Это очень помогает, например, если вы работаете с сетью: вы всегда уверены, что все пакеты у вас int16, расстояние между ними 0, смещение такое и никак иначе. Ведь если вы определите все через char, который внезапно станет двухбайтовым, все поедет куда-то не туда.
Так же для упрощения чтения и написания кода зависимого от платформы/компилятора/версии языка очень полезно вводить собственные унифицированные дефайны. типа таких:
В моей практике было очень много тяжелых алгоритмов, таких как голосовые и видеокодеки. Для простоты портирования желательно, чтобы алгоритм не использовал никаких системных функций, а еще лучше вообще обойтись и без системных библиотек.
Один из основных принципов написания портируемого и управляемого кода – не использовать malloc внутри алгоритмов. Ваш алгоритм должен определять, сколько ему потребуется памяти, передавать это значение вашему менеджеру памяти, который уже выделяет память и дает ссылку на выделенный кусок при инициализации. Алгоритм этим куском пользуется. Счастье и гармония.
Что происходит, когда ваш алгоритм сам выделяет память? Если вы часто создаете и убиваете процессы, и еще алгоритмов много, они начинают выделять и освобождать память хаотично, то начинается фрагментация памяти. Это приводит к тому, что в какой-то момент вы просто не сможете выделить необходимое количество памяти, даже если суммарный объем свободной память больше чем вам нужно. Оперативная память все еще довольно дорогой ресурс, особенно на мобильных девайсах.
По этому же принципу желательно выделять и другие системные функции.
Под базовыми операциями подразумевается выделение таких неспецифических операций, которых нет в С, но которые вы используете часто.
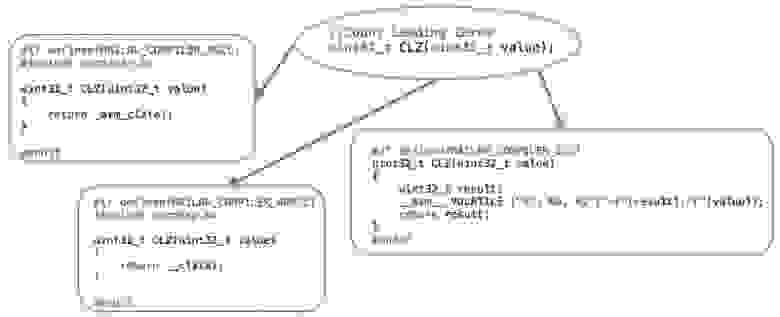
Рассмотрим простую операцию CLZ (Count Leading Zeros). Такой операции в С нет, и при необходимости можно написать алгоритм подсчета нулей. Фишка в том, что в некоторых процессорах, в частности в ARM он реализован на аппаратном уровне. В этих случаях мы спокойно пользуемся тем, что есть. Для этого компилятор может иметь интринсик-функцию. Если же компилятор такую функцию не реализует (как в нашем примере реализация GCC), можно поставить ассемблерную операцию. Для тех процессоров, в которых эта операция не реализована, придется уже писать отдельный код. Тем не менее, это все еще базовая операция. Чем это хорошо? Вы пишете базовую операцию один раз, вызываете ее в своем коде, и, если вам надо портировать, вы просто пишете юнит тест, портируете эту операцию, проверяете результат юнит-тестом. Если все OK, значит, код, который вы используете, тоже будет OK.
Чтобы продемонстрировать необходимость выделения базовых операций, приведу, казалось бы, простой пример: сдвиг для int64. В принципе, эта команда есть в С, но может быть реализована по-разному, поскольку это не стандартный int, а int64. Int64 в разных системах по-разному называются, но это полбеды. Самая большая беда в том, что выполняться они тоже могут по-разному.
Рассмотрим базовую операцию под названием logical shift right. Есть какое-то число, которое надо сдвинуть на 63 и на 64. Это граничные значения. Как известно, именно граничные значения приносят больше всего неприятностей. Что же будет в res63 и res64? По идее должны быть нули. Но на самом деле все не так просто.

В зависимости от разрядности платформы мы получаем разные результаты, хотя все делается основательно и по правилам. Именно поэтому лучше выделять спорные вещи в базовые операторы и при портировании отдельно делать на них тесты.
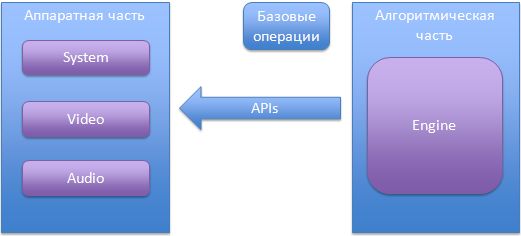
Аппаратно-зависимые части мобильного приложения обладают следующими особенностями:
Для того чтобы как-то унифицировать работу с аппаратно-зависимыми частями кода, хорошей практикой будет выделять набор базовых врапперов. Предложу свой вариант списка врапперов.
В зависимости от того, что делает устройство, вам могут понадобиться дополнительные врапперы. Вот краткий список аппаратных частей, которые делают обязательным применение врапперов (они необходимы для того, чтобы портирование прошло гладко).
Следуя всем вышеописанным рекомендациям, мы получаем алгоритм, который написан через единые типы, которые вы переносите. Этот алгоритм не требует вообще никакого вмешательства. По идее он должен скомпилироваться и заработать сразу. Лучше иметь к нему юнит-тесты. Если алгоритм скомпилировался и прошел проверки, скорее всего, все будет хорошо. Базовые операции тоже портируются, но их может и не быть.
Аппаратные части уже требуют портирования. И лучше, чтобы они имели как можно более близкий к системе интерфейс. Их будет легче проверить, и они быстрее портируются.
Наконец, я хотел бы привести некоторые общие рекомендации: на что следует обратить внимание при написании портируемого кода.
Если вы хотите посмотреть хороший пример реализации кроссплатформенного кода, я советую обратить внимание на libjingle. Там выполняются почти все постулаты, о которых шла речь в этой статье.
Если же вы знаете, как сделать портирование кода еще проще или хотите подробнее обсудить какие-то из изложенных мной пунктов, я с удовольствием пообщаюсь с вами в комментариях.
В этой статье я поделюсь с вами своими соображениями об общих принципах портирования. Мы не будем влезать в дебри конкретных программных реализаций приложений под Android или iOS. Я просто постараюсь рассказать, как сделать так, чтобы приложение легко переносилось на различные устройства и могло называться кроссплатформенным.
План действий
Для начала определим круг задач. В этой статье мы не будем затрагивать встроенные системы, которые, несомненно, тоже работают на благо мобильных технологий. Мы рассмотрим только современные мобильные девайсы: телефоны и планшеты. Первая часть статьи будет посвящена архитектуре современных мобильных процессоров и ограничениям и, наоборот, фичам, которые получает от них мобильный разработчик. Во второй части я расскажу о некоторых базовых приемах, которые необходимы для написания портируемого кода.
Процессор
Не так давно, еще лет пять назад, было очень много разных фирм, выпускавших мобильные процессоры со своими архитектурами. Однако сейчас основные архитектуры можно пересчитать по пальцам одной руки, и еще останется запас. Прежде всего, это ARM. Помимо него есть MIPS, которые обычно включены в Java NDK, и Intel со своим Atom-ом.
Все методы, о которых пойдет речь дальше, применимы ко всем этим системам. Но для удобства мы рассмотрим их на примере самых распространенных ARM-процессоров. Что нам нужно о них знать?
- с коммерческой точки зрения: лицензирование ядра. Вы можете купить лицензию и создать свой процессор
- с технологической точки зрения: система на кристалле (System On Chip). Все модули собраны в одном месте
- с точки зрения разработчика софта: мощная RISC-архитектура
Лицензирование
ARM сама не выпускает процессоры, она продает лицензию на выпуск, а различные фирмы (Samsung, LG, Broadcom, Apple, Qualcomm, Freescale) покупают лицензии и выпускают свои версии процессоров, одноядерные или многоядерные — какие им заблагорассудится.
Что дает лицензирование? Вы не просто берете ядро, вы делаете свой процессор. Вы можете его дорабатывать: улучшать или, наоборот, упрощать – это ваше право. Пример из истории – это известный Intel с процессором XScale. Они купили лицензию на АRМv5TE и серьезно его переработали. На мой взгляд, это самая удачная из существующих пока переработок. Они улучшили работу с памятью, увеличили кэш, и, если сравнивать реализации Intel и Samsung на базе АRМv5TE, то Intel выигрывала раза, наверное, в два. Основной особенностью этого процессора было то, что в нем впервые появился сопроцессор с 40-битный аккумулятором, который позволял за 1 такт перемножать со сложением 4 числа, а старшие подели имели сопроцессор Wireless MMX, предоставляющий мощный набор SIMD инструкций
System On Chip
С точки зрения инженера, что такое система на кристалле? Это маленький микропроцессор, на который ставится куча разных устройств. Вы покупаете лицензию у ARM, ставите туда один, два -сколько хотите ядер. Дополнительные сопроцессоры (графические, DSP и др.), память (ROM, FLASH...) Помимо этого, обычно туда вставляют интерфейсы ввода/вывода: Ethernet, USB, COM-порты, если есть такая необходимость. Для того чтобы заставить все это добро работать, на этот же кристалл добавляются осцилляторы и таймеры, чтобы не выносить дополнительную обвязку отдельными блоками на плату.

Реализация системы на кристалле стала возможна для ARM, потому что эта система имеет очень мало транзисторов по сравнению с тем же Pentium. Благодаря этому она занимает мало места на кристалле, и технологически получается вместить туда все, что захотят разработчики. Вряд ли у нас бы получилось уместить все эти юниты в Core i5 — хотя бы потому, что он сам по себе большой, да еще и с большим радиатором (поскольку транзисторов много и все они сильно нагреваются).
RISC-архитектура
Рассмотрим особенности архитектуры, которые важны для разработчиков.
- Прежде всего, это load/store-архитектура. Все операции совершаются с регистрами: загрузили – посчитали – выгрузили, и никак иначе. Нельзя сделать операцию с операндом в памяти.
- Для обеспечения работы с регистрами ядро имеет большой регистровый файл – 16 регистров по 32 бита. Они, в принципе, равнозначны. У некоторых, разумеется, есть специализированные названия, которые как бы намекают на их назначение, но вам доступны все операции применительно к любому регистру.
- Фиксированная длина команд. В ARM-режиме это обычно 32 бита: 1 команда – 1 слово, друг за другом. Конвейер этому факту, безусловно, рад, потому что ничего не меняется, все предсказуемо.
- Одной из особенностей ARM является возможность не просто обращаться со смещением к памяти, но и читать и загружать из памяти с преинкрементом, постинкрементом со смещением в регистре или непосредственно в числовом виде. Мощные адресные команды – одна из самых главных особенностей ARM
- Все операции стремятся выполниться за 1 такт. Может быть больше или меньше – это уже нюансы для разных ядер.
- Еще одна классная фишка ARM – условное выполнение. Когда вы пишете инструкцию (арифметическую, или просто проверяете флаг), у вас остаются флаги, и следующие операции выполняются только при соблюдении условия. Соответственно, вам не нужно совершать больших переходов. Это очень удобно: не сбрасывает конвейер, при этом повышается производительность.
- Быстрый сдвиг. ARM позволяет выполнять арифметические операции со сдвигом: вы можете записать a += (j << 2); в одну команду, которая выполнится за один такт.
Семейство ARM
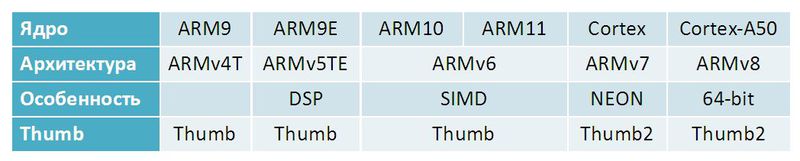
Как развивалось и прогрессировало семейство ARM:
- ARM9 будем считать базовой. Это уже прошлое, хотя и используется, но не в современных телефонах.
- ARM9E до сих пор встречается в Android, и это надо учитывать. В ARM9E появились DSP-инструкции, которые позволили сильно ускорить алгоритмы обработки голоса.
- Ядро ARM10 прошло практически незамеченным.
- На базе ARM11 выходили различные устройства, но самым знаковым девайсом был первый iPhone. Нововведением здесь стало появление SIMD-инструкций, хоть и более слабых, чем интеловские Wireless MMX в XScale.
- Cortex – самое распространенное на сегодняшний день ядро. Это может быть многоядерная система Cortex A9 или одноядерная Cortex A8, но архитектура у них одинаковая – ARMv7. Здесь ARM совершила небольшую революцию под названием NEON. Это отдельный сопроцессор, которого может и не быть на кристалле, хоть он и включен в архитектуру ARMv7. Особенностью NEONа является наличие 64-битных и 128-битных команд, обеспечивающих параллельное сложение, вычитание, сдвиги и насыщение. Именно здесь у ARM появляется полноценный SIMD, обеспечивающий ускорение при обработке цифровых сигналов.
- Компания ARM анонсировала «наше светлое будущее» – 64-битное ядро Cortex-A50 с архитектурой ARMv8. Они обещают полную совместимость со всем, что было до этого в отдельном в 32-битном режиме.
Thumb
Хотелось бы отдельно остановиться на последней строке таблицы из предыдущего пункта. Что такое Thumb? Изначально это был набор упакованных ARM-инструкций. Если между быстродействием и компактностью кода мы выбираем второе, то короткие 16-битные инструкции с ограниченным функционалом – отличное решение.
Thumb2 – это эволюция Thumb. Она включает в себя часть инструкций ARM, и состоит из набора 16-битных и 32-битных инструкций, призванных обеспечить плотность кода как в Thumb и при этом сохранить производительность полноценного ARM.
Кроссплатформенность
Возьму на себя смелость дать определение кроссплатформенности: «Кроссплатформенным кодом можно считать код, для которого затраты по переносу на другую систему намного меньше, чем затраты на написание этого кода с нуля». То есть мы не называем портированием ситуации «у меня есть какой-то алгоритм, я хочу такой же сделать на iOS — соответственно, я должен такой же написать для этой платформы». Это не портирование, это написание заново. Чтобы портировать алгоритм, он должен отвечать условиям кроссплатформенности.
Принципы написания кроссплатформенного кода я определяю как «разделение и унификация». Постараюсь объяснить, что это такое. Эти пункты не являются постулатами, это мое видение.
- Прежде всего, единая типизация – важно писать код в своих единых типах, так как на разных платформах встроенные native-типы могут различаться
- Разделение кода на алгоритмическую и неалгоритмическую часть. Из алгоритмов вытаскиваются системные вызовы и базовые операции
- Аппаратно-зависимая часть: мы разделяем программу на алгоритмическую часть (математику) и на то, что зависит от системы
Остановимся на каждом пункте подробнее.
Единая типизация
#if defined(_MSC_VER)
typedef signed char int8_t;
typedef signed short int16_t;
typedef signed int int32_t;
typedef signed __int64 int64_t;
typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef unsigned __int64 uint64_t;
#elif defined(LINUX_ARM)
typedef signed char int8_t;
typedef signed short int16_t;
typedef signed int int32_t;
typedef signed long long int64_t;
typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
#else
#include <stdint.h>
#endif
Что я имею в виду под единой типизацией? Вы просто определяете свои типы. В приведенном примере описан stdint. Он определен для компилятора Microsoft и для Linux. Если вы хотите большего контроля, вы можете написать «мой_любимый_int8», «мой_любимый_int16» и затем использовать эти типы в своей программе. Это очень помогает, например, если вы работаете с сетью: вы всегда уверены, что все пакеты у вас int16, расстояние между ними 0, смещение такое и никак иначе. Ведь если вы определите все через char, который внезапно станет двухбайтовым, все поедет куда-то не туда.
struct NetworkStatistics
{
uint16_t currentBufferSize;
uint16_t preferredBufferSize;
uint16_t currentPacketLossRate;
uint16_t currentDiscardRate;
uint16_t currentExpandRate;
uint16_t currentPreemptiveRate;
uint16_t currentAccelerateRate;
};
Так же для упрощения чтения и написания кода зависимого от платформы/компилятора/версии языка очень полезно вводить собственные унифицированные дефайны. типа таких:
#if defined(__APPLE__)
# ifdef TARGET_OS_IPHONE
# define MAILRU_OS_IOS
# elif defined(TARGET_IPHONE_SIMULATOR)
# define MAILRU_OS_IOS
# define MAILRU_OS_IOS_SIMULATOR
# elif defined(TARGET_OS_MAC) || defined (__OSX__)
# define MAILRU_OS_MACOSX
# else
# define MAILRU_OS_MACOSX
# endif
#elif defined(_WIN64)
# define MAILRU_OS_WIN64
# define MAILRU_OS_WINDOWS
#elif _WIN32
# define MAILRU_OS_WIN32
# define MAILRU_OS_WINDOWS
#elif ANDROID
# define MAILRU_OS_ANDROID
#else
# error Unsupported OS target!
#endif
#if defined(_M_X64) || defined(__x86_64__)
# define MAILRU_ARCH_X86_FAMILY
# define MAILRU_ARCH_64_BIT
#elif defined(__ARMEL__) || defined(__arm) || defined(_M_ARM_FP)
# define MAILRU_ARCH_ARM_FAMILY
# define MAILRU_ARCH_32_BIT
#elif defined(__ppc__)
# define MAILRU_ARCH_PPC_FAMILY
# define MAILRU_ARCH_32_BIT
#else
# error Please add support for your architecture in typedefs.h
#endif
Алгоритмы
В моей практике было очень много тяжелых алгоритмов, таких как голосовые и видеокодеки. Для простоты портирования желательно, чтобы алгоритм не использовал никаких системных функций, а еще лучше вообще обойтись и без системных библиотек.
Системные вызовы
Один из основных принципов написания портируемого и управляемого кода – не использовать malloc внутри алгоритмов. Ваш алгоритм должен определять, сколько ему потребуется памяти, передавать это значение вашему менеджеру памяти, который уже выделяет память и дает ссылку на выделенный кусок при инициализации. Алгоритм этим куском пользуется. Счастье и гармония.
// Interface
int32 MyAlgorithm_GetMemSizeNeed()
int32 MyAlgorithm_Init(void *memory)
void *MyAlgorithm_Destroy()
// Using
{
void *m = MyManager_GetMem(MyAlgorithm_GetMemSizeNeed());
MyAlgorithm_init(m);
//...
m = MyAlgorithm_Destroy();
MyManager_FreeMem(m);
}
Что происходит, когда ваш алгоритм сам выделяет память? Если вы часто создаете и убиваете процессы, и еще алгоритмов много, они начинают выделять и освобождать память хаотично, то начинается фрагментация памяти. Это приводит к тому, что в какой-то момент вы просто не сможете выделить необходимое количество памяти, даже если суммарный объем свободной память больше чем вам нужно. Оперативная память все еще довольно дорогой ресурс, особенно на мобильных девайсах.
По этому же принципу желательно выделять и другие системные функции.
Базовые операции
Под базовыми операциями подразумевается выделение таких неспецифических операций, которых нет в С, но которые вы используете часто.
Рассмотрим простую операцию CLZ (Count Leading Zeros). Такой операции в С нет, и при необходимости можно написать алгоритм подсчета нулей. Фишка в том, что в некоторых процессорах, в частности в ARM он реализован на аппаратном уровне. В этих случаях мы спокойно пользуемся тем, что есть. Для этого компилятор может иметь интринсик-функцию. Если же компилятор такую функцию не реализует (как в нашем примере реализация GCC), можно поставить ассемблерную операцию. Для тех процессоров, в которых эта операция не реализована, придется уже писать отдельный код. Тем не менее, это все еще базовая операция. Чем это хорошо? Вы пишете базовую операцию один раз, вызываете ее в своем коде, и, если вам надо портировать, вы просто пишете юнит тест, портируете эту операцию, проверяете результат юнит-тестом. Если все OK, значит, код, который вы используете, тоже будет OK.
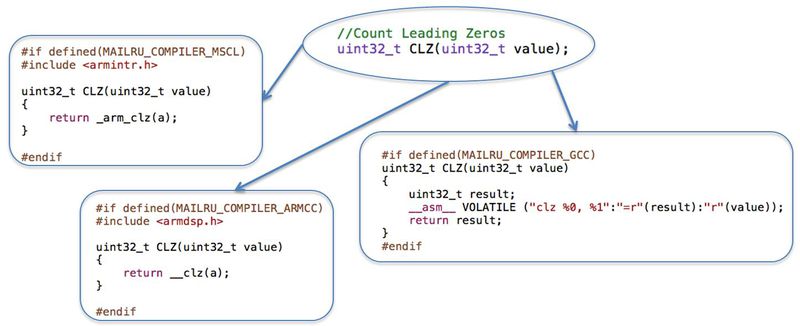
Непредвиденные обстоятельства
Чтобы продемонстрировать необходимость выделения базовых операций, приведу, казалось бы, простой пример: сдвиг для int64. В принципе, эта команда есть в С, но может быть реализована по-разному, поскольку это не стандартный int, а int64. Int64 в разных системах по-разному называются, но это полбеды. Самая большая беда в том, что выполняться они тоже могут по-разному.
Пример: uint64>>n
uint64_t LogicalShiftRigth(uint64_t number, int shift)
{
return number >> shift;
}
uint64_t test = 0x1234567812345678;
uint64_t res63 = LogicalShiftRigth(test, 63);
uint64_t res64 = LogicalShiftRigth(test, 64);
Рассмотрим базовую операцию под названием logical shift right. Есть какое-то число, которое надо сдвинуть на 63 и на 64. Это граничные значения. Как известно, именно граничные значения приносят больше всего неприятностей. Что же будет в res63 и res64? По идее должны быть нули. Но на самом деле все не так просто.

В зависимости от разрядности платформы мы получаем разные результаты, хотя все делается основательно и по правилам. Именно поэтому лучше выделять спорные вещи в базовые операторы и при портировании отдельно делать на них тесты.
Аппаратно-зависимые части
Аппаратно-зависимые части мобильного приложения обладают следующими особенностями:
- Сильно зависят от API-фреймворков, будь то Android, iOS или что-то еще.
- Часто используют ненативные средства. Например, код, который использует видео, в Android может иметь такой алгоритм: движок написан на С. Он через JNI вызывает Java, которая потом в свою очередь обратно через JNI отдает результат.
- Используют менее переносимые языки. К менее переносимым языкам я отношу, например, Objective C и Java. Несмотря на то, что Java считается кроссплатформенным языком, по сравнению с С универсальности ей явно недостает.
Базовые врапперы
Для того чтобы как-то унифицировать работу с аппаратно-зависимыми частями кода, хорошей практикой будет выделять набор базовых врапперов. Предложу свой вариант списка врапперов.
- Системный лог. Обычный printf() очень помогает при разработке. У каждой платформы существуют свои фреймворки; например, для iOS это может быть NSLog, для Android – Logcat.
- Менеджер памяти. Как мы уже выяснили, лучше иметь свой менеджер памяти, который делает malloc/free. Помимо этого, можно научить его искать утечки памяти.
- Мьютексы / атомарные операции также имеют разные реализации в различных системах.
- Менеджер потоков – надстройка над мьютексами и основной API для создания многопоточного приложения.
- Системная информация может оказаться полезной, если вы что-то меняете в runtime. Если ваш код оптимизирован для нескольких процессоров, вы можете в runtime узнать, что это за система, и подключить нужную часть.
- Трасинг / логирование – это уже не просто системный лог; это отладка ошибок, и здорово, если она едина для всех платформ.
- Работа с файлами подразумевает ввод/вывод файлов, .pсm dump’ы и так далее. Очень удобно иметь вывод через единый интерфейс.
- Средства профилирования. Если у вас тяжелый код, стандартными средствами не всегда можно быстро выяснить, что и где теряется. Можно, конечно, использовать нативные средства каждой определенной платформы, а можно написать свои кроссплатформенные clock, log и так далее, и вызывать в коде их.
Дополнительные врапперы
В зависимости от того, что делает устройство, вам могут понадобиться дополнительные врапперы. Вот краткий список аппаратных частей, которые делают обязательным применение врапперов (они необходимы для того, чтобы портирование прошло гладко).
- Сокеты/работы с сетью
- Аудиоустройства
- Видеоустройства
- Устройство ввода
Промежуточный итог
Следуя всем вышеописанным рекомендациям, мы получаем алгоритм, который написан через единые типы, которые вы переносите. Этот алгоритм не требует вообще никакого вмешательства. По идее он должен скомпилироваться и заработать сразу. Лучше иметь к нему юнит-тесты. Если алгоритм скомпилировался и прошел проверки, скорее всего, все будет хорошо. Базовые операции тоже портируются, но их может и не быть.
Аппаратные части уже требуют портирования. И лучше, чтобы они имели как можно более близкий к системе интерфейс. Их будет легче проверить, и они быстрее портируются.
Attention!
Наконец, я хотел бы привести некоторые общие рекомендации: на что следует обратить внимание при написании портируемого кода.
- Память данных/кода. Запомните, в мобильных девайсах памяти много не бывает. Ее всегда мало, и та, что есть, постоянно пытается куда-то улизнуть, стоит дать ей волю. Поэтому лучше иметь собственный менеджер памяти, чтобы избегать фрагментации. Кроме того, желательно, чтобы код был маленький: если для вас не критичны специфические для ARM операции, лучше использовать Thumb2.
- Выравнивание данных. До ARMv7 архитектуры ARM не поддерживали обращение к невыровненным данным. Но даже после того, как такое поведение стало возможным, эта операция вызывает дополнительный простой в работе процессора. Так что лучше выравнивать память по границе int, а еще лучше – по границе кэша: это обеспечит вам быструю загрузку.
- Оптимизация под процессор. Если у вас тяжелые алгоритмы, особенно голосовые и видео, без оптимизации у вас ничего работать не будет. А если вдруг взлетит, то будет быстро сжирать всю батарейку.
- Плавающая точка. По умолчанию плавающей точки на ARM нет. Сейчас в Cortex появился блок NEON, он реализует операции с плавающей точкой, но, опять же, не во всех девайсах. Если про смартфоны под управлением iOS известно, что там всегда есть плавающая точка, то производители Android-девайсов могут в целях экономии от нее отказаться. Поэтому в случае с Android нам на помощь придет Get CPU Features, где есть проверка на плавающую точку.
- Целочисленное деление. С ним дела обстоят так же, как и с плавающей точкой: поделить int на int могут далеко не все ядра, и об этом стоит помнить.
- Многопоточность и MainThread. Если у вас приложение не многопоточное – сделайте его многопоточным. Загрузка UI в мобильных приложениях – страшная вещь: при однопоточной реализации возможен широкий спектр эффектов, от тормозов до крэша приложения. Если же у вас уже многопоточная система, обратите внимание на MainThread, потому что многие вещи должны исполняться только из него.
Небольшой итог
- Первое: понимание архитектуры процессора улучшает качество портирования.
- Второе: залог успешного портирования – это хороший кроссплатформенный код. То есть чем меньше вы тратите времени на то, чтобы переписать существующий код, тем лучше, быстрее и дешевле. Все будут рады, особенно менеджер.
- И третье: простоту переносимости кода определяет продуманность архитектуры. Так что если вы пишете новое приложение, задумайте его кроссплатформенным изначально. Даже если вы не планируете его переносить, может быть, этим придется заниматься кому-то другому.
Если вы хотите посмотреть хороший пример реализации кроссплатформенного кода, я советую обратить внимание на libjingle. Там выполняются почти все постулаты, о которых шла речь в этой статье.
Если же вы знаете, как сделать портирование кода еще проще или хотите подробнее обсудить какие-то из изложенных мной пунктов, я с удовольствием пообщаюсь с вами в комментариях.
