

Этим летом мы научили нейронную сеть определять, присутствует ли на изображении документ, и если да — то какой именно.
Для чего это понадобилось
Чтобы разгрузить сотрудников и обезопасить людей от мошенников. Мы применяем новую нейросеть в двух сферах: когда пользователь восстанавливает доступ к странице и для скрытия личных документов из общего поиска.
Восстановление доступа к страницам. Фотографии документов помогают вернуть аккаунты их настоящим владельцам. Например, пользователь мог потерять доступ к своему номеру телефона или же на странице подключена двухэтапная аутентификация, а возможности получить одноразовый код для подтверждения входа уже нет. Новая разработка ускоряет рассмотрение обращений: модераторам больше не приходится каждый раз возвращать неправильно оформленные заявки. Система просто не даёт посетителю отправить форму без нужных изображений и просит заменить случайную картинку на документ. Конечно, вернуть доступ к самой странице мы по-прежнему можем только если на ней есть настоящие фотографии владельца. Речь идёт о безопасности учётных записей и сохранности личных данных — значит, промахов и случайностей быть просто не может.
Фильтрация результатов поиска по разделу «Документы». Все документы, которые пользователи загружают в этот раздел или отправляют через личные сообщения, по умолчанию скрыты от чужих глаз и не попадают в поисковую выдачу. Но уровень приватности можно настроить вручную самому — для каждого отдельного файла. До появления нейросети можно было найти по ключевым словам приличное количество документов с чувствительными данными. Владельцы этих файлов сами меняли настройки приватности. Мы обезопасили пользователей и начали убирать из публичного поиска фотографии, на которых можем определить наличие документа.
Как мы решали задачу
Кажется, что самый простой способ определить документы на изображении — настроить нейросеть или обучить её с нуля на большой выборке. Но не всё так просто.
Выборка должна быть репрезентативной. Сложно найти достаточное количество реальных семплов на каждый вариант: каких-либо публичных баз с настоящими документами в открытом доступе нет.
Есть много систем, которые распознают и парсят документы. Обычно они направлены на получение конкретной информации с фотографии и предполагают идеальное качество исходного изображения. Например, от пользователя могут требовать выровнять паспорт по краям шаблона, как это работает на портале Госуслуг.
Для наших задач такие системы не подходят. Мы отдельно уточняем, что при обращении к нам за восстановлением доступа пользователь может закрыть на документе все данные, кроме фотографии, имени, фамилии и печати. При этом нам всё равно нужно определять документ — даже если на нём скрыты серия и номер, если паспорт снят вместе с окружающей обстановкой или, наоборот, на изображении оказалась только часть документа с фотографией. Ещё нужно учитывать разное освещение и ракурсы. Все такие материалы нейросеть должна принять. Вопрос в том, как её этому обучить.

Есть и другие сложности. Например, паспорт тяжело отделить от других видов документов, а также от различных рукописных и печатных бумаг.
Попытка пойти по простому пути оказалась не очень успешной. Получившийся классификатор оказался слабым, с маленькой ошибкой первого рода и большой ошибкой второго. Например, были интересные случаи, когда человек от руки написал имя и фамилию, пририсовал фотографию, обложку паспорта — и система беспечно принимала такой документ.
К чему мы пришли
В нашей ситуации лучшим решением задачи оказалось использование ансамбля сеток и детекторов лиц, чтобы распознавать документ и определять его тип. Мы также добавили дифференциальный классификатор, в который включён кодировщик для выделения характерных признаков, и классификатор формы, позволяющий отличать изображения документов от нерелевантных файлов. В дополнение к этому происходит предварительная кластеризация обучающей выборки с целью нормализации датасета. Из архитектур лучше всего себя зарекомендовали VGG и ResNet.
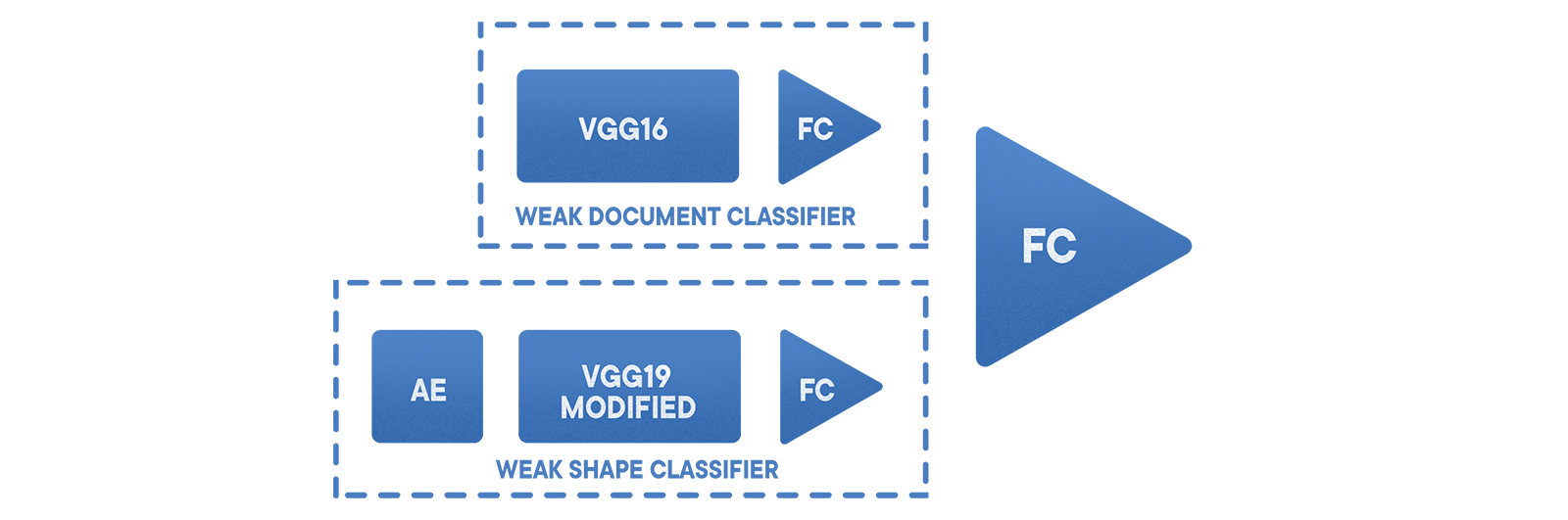
Базовый классификатор «документ/не документ» работает на основе настроенного VGG с 19 слоями и районированной выборкой. Поверх него используется комбинированный ансамбль классификаторов, которые уменьшают ошибку второго рода и дифференцируют результат. Сначала идёт stratified sampling, затем кодировщик для извлечения околоконтурной информации, потом изменённая VGG и напоследок единая сетка. Такой подход позволил минимизировать ошибки первого рода до уровня примерно 0,002. Вероятность false negative при этом зависит от выбранного датасета и конкретной области применения.
Сейчас мы научились автоматически определять наличие на снимке паспортов и водительских прав. Распознавание успешно происходит под любым углом, с любым фоном, даже при плохом освещении — главное, чтобы на изображении была часть документа с фотографией и именем. Впрочем, для идентификации других видов документов потребуются лишь соответствующие датасеты. Мы обучаем сеть на собственных данных, размер выборки документов от пяти до десяти тысяч (но она не репрезентативная). Для других изображений выборка произвольная, но и там, и там идёт априорная кластеризация.
С технической точки зрения система написана на python / keras / tensorflow / glib / opencv. Для практического применения новой системы достаточно интегрировать её в python-обработчики инфраструктуры машинного обучения. На этом же этапе добавляется детектор изменения фотографии в графических редакторах, но эта тема заслуживает отдельной статьи.
Что в итоге
Теперь 6% заявок на восстановление доступа автоматически возвращаются автору с просьбой добавить или заменить фотографию документа, а 2,5% заявок — отклоняются. Если смотреть на анализ изображений в целом, включая эвристики и поиск лица на снимке, то он автоматизирует до 20% работы отдела.
После запуска нейросети мы также смогли подсчитать количество паспортов, которые загружаются в раздел «Документы». Выяснилось, что в общей поисковой выдаче каждый день оказывались около двух тысяч удостоверений личности. Теперь вероятность, что они попадут в посторонние руки, минимальна.
Нейросети уже помогают нам бороться со спамом и разного вида мошенничеством. Мы не прекращаем эксперименты и продолжим рассказывать о них в нашем блоге.
