
Привет, Хабр! Меня зовут Олег, я работаю с машинным обучением в VK Видео, внедряю нейросети в Клипы ВКонтакте для создания эффектов дополненной реальности. В статье расскажу, как запустить TensorFlow Lite сетку с передачей GPU-буферов — как входного, так и выходного. Этот подход помогает сэкономить на пересылке данных между CPU- и GPU- памятью, когда данные уже находятся в GPU-памяти и модель применяется с помощью GPU-делегата TensorFlow Lite.

Весь процесс покажу на примере реализации для Android, код можно найти в моём GitHub-репозитории.
Проблема
В большинстве эффектов дополненной реальности в Клипах ВКонтакте нам требуется проанализировать при помощи нейросети каждый кадр с камеры. Нейросети используются для определения жестов, поиска фона, анализа лица — например, как на этих картинках.

Оригиналы фото взяты отсюда и отсюда.
Кадры с камеры приходили в виде GPU-данных, так как на GPU получается намного быстрее выполнять многие операции по обработке изображений. Но стандартный Java API TensorFlow Lite из модуля под Android предполагает передачу только CPU-буферов. Если использовать GPU-делегат, то TensorFlow сначала пересылает входные CPU-буферы в память GPU, а потом выходные — обратно из GPU в память CPU.
Схема пересылки данных между GPU и CPU в общем виде выглядит так:

Копирование данных хотелось бы оптимизировать и в идеале избавиться от копирования между CPU и GPU, чтобы схема выглядела так:
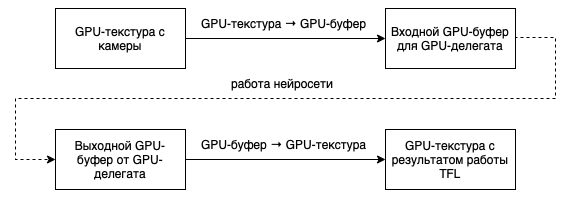
Преобразование GPU-текстуры в GPU-буфер, которое происходит на видеокарте, необходимо, так как GPU-делегат использует GPU-буфер в качестве входного параметра.
Действительно, передача GPU-буферов в TensorFlow возможна с C++ API. Чтобы использовать его на Android, нужно собрать библиотеки TensorFlow Lite и обращаться к ним через JNI-обёртку.
Далее разберём вопросы по сборке библиотек и использованию C++ API для приложения под Android, а также посмотрим на замеры производительности.
Сборка TensorFlow Lite
Инструкцию по сборке можно найти на сайте TensorFlow Lite по ссылкам: tensorflow.org/install/source_windows или tensorflow.org/install/source.
Для сборки необходимо установить Bazel, пару пакетов для Python и во время конфигурации на вопрос «Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]» ответить «Yes».
Понадобится собрать две библиотеки: libtensorflowlite.so и libtensorflowlite_gpu_delegate.so. Первая — это сам TensorFlow Lite, а вторая GPU-делегат.
Команды для сборки выглядят примерно так:
bazel build //tensorflow/lite:libtensorflowlite.so \
--crosstool_top=//external:android/crosstool \
--cpu=arm64-v8a \
--host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
--cxxopt="-std=gnu++14" \
--define=tflite_with_ruy=true \
--verbose_failures \
-c opt
bazel build //tensorflow/lite/delegates/gpu:libtensorflowlite_gpu_delegate.so \
--crosstool_top=//external:android/crosstool \
--cpu=arm64-v8a \
--host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
--cxxopt="-std=gnu++14" \
--verbose_failures \
-c optВ результате библиотеки будут тут:
./bazel-out/${arch}-${lib_suffix}/bin/tensorflow/lite/libtensorflowlite.so
./bazel-out/${arch}-${lib_suffix}/bin/tensorflow/lite/delegates/gpu/libtensorflowlite_gpu_delegate.soВ качестве заголовочных файлов можно взять все .h-файлы из директории tensorflow/tensorflow/lite.
Использование на Android
Пример того, как встраивать TensorFlow Lite GPU с использованием C++ API, можно посмотреть в документации MediaPipe. Наш пример тоже основан на нём и состоит из следующих основных шагов:
1. Инициализация модели и GPU-делегата.
Создаём tflite::gpu::TFLiteGPURunner, передав ему параметры tflite::gpu::InferenceOptions. Затем функцией BuildFromFlatBuffer создаём два графа для OpenGL и OpenCL. Сначала делаем попытку запустить сетку на OpenCL, а если не вышло, то на OpenGL ES. На OpenCL, как правило, работает быстрее, но не на всех телефонах поддерживается.
Для инициализации GPU-контекста для OpenGL или OpenCL выполняем следующие команды:
OpenGL:
MP_RETURN_IF_ERROR(
NewInferenceEnvironment(env_options, &gl_environment_, &properties).ok());
MP_RETURN_IF_ERROR(gl_environment_->NewInferenceBuilder(std::move(*graph_gl_),
gl_options, builder).ok());OpenCL:
MP_RETURN_IF_ERROR(cl::NewInferenceEnvironment(env_options, &cl_environment_, &properties).ok());
MP_RETURN_IF_ERROR(cl_environment_->NewInferenceBuilder(
cl_options, std::move(*graph_cl_), builder).ok());Обратите внимание, что инициализировать GPU и нейросеть нужно в том потоке, где активен OpenGL ES контекст, которому будут принадлежать входные и выходные GPU-буферы.
После задаём описание входов и выходов:
for (int flow_index = 0; flow_index < input_shapes_.size(); ++flow_index) {
MP_RETURN_IF_ERROR(builder->SetInputObjectDef(
flow_index, GetSSBOObjectDef(input_shapes_[flow_index].c)).ok());
}
for (int flow_index = 0; flow_index < output_shapes_.size(); ++flow_index) {
MP_RETURN_IF_ERROR(builder->SetOutputObjectDef(
flow_index, GetSSBOObjectDef(output_shapes_[flow_index].c)).ok());
}И создаём InferenceRunner:
return builder->Build(&runner_).ok();2. Подготовка входных данных.
На вход и выход GPU-делегат принимает SSBO (Shader Storage Buffer Object) — то есть наши текстуры необходимо преобразовать в этот буфер. Для этого компилируем вычислительный шейдер, который преобразует текстуру в буфер с тремя каналами цвета:
#version 310 es
layout(local_size_x = 8, local_size_y = 8) in;
layout(binding = 0) uniform sampler2D u_Texture0;
layout(std430) buffer;
layout(binding = 1) buffer Output { float elements[]; } output_data;
uniform int u_width;
uniform int u_height;
void main()
{
ivec2 gid = ivec2(gl_GlobalInvocationID.xy);
if (gid.x >= u_width || gid.y >= u_height) return;
vec3 pixel = texelFetch(u_Texture0, gid, 0).xyz;
int linear_index = 3 * (gid.y * u_width + gid.x);
output_data.elements[linear_index + 0] = pixel.x;
output_data.elements[linear_index + 1] = pixel.y;
output_data.elements[linear_index + 2] = pixel.z;
//output_data.elements[linear_index + 3] = 0.0;
}Чтобы передать четыре канала, нужно раскомментировать последнюю строку и поменять «3» на «4» в строке: int linear_index = 3 * (gid.y * u_width + gid.x);.
Затем устанавливаем выходные параметры и запускаем вычислительный шейдер:
GLES31.glActiveTexture(GLES31.GL_TEXTURE0 + 0);
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, textureId);
GLES31.glBindBufferRange(GLES31.GL_SHADER_STORAGE_BUFFER, 1, bufferId, 0, bufferSize);
GLES31.glDispatchCompute(texWidth / 8, texHeight / 8, 1);
GLES31.glBindBuffer(GLES31.GL_SHADER_STORAGE_BUFFER, 0);
GLES31.glBindTexture(GLES31.GL_TEXTURE_2D, 0);
GLES31.glMemoryBarrier(GLES31.GL_ALL_BARRIER_BITS);Последней строкой синхронизируем вычисления, чтобы до начала работы TensorFlow все данные записались в буфер.
После этого биндим входные и выходные буферы:
nativeRunner!!.bindInput(0, inputBuffer)
nativeRunner!!.bindOutput(0, outputBuffer)Если используете одни и те же буферы, то биндить можно один раз.
3. Запуск сетки.
Просто вызываем runner_->Run().
4. Использование выходных данных.
В выходном буфере будет содержаться результат работы нейросети. Его можно преобразовать в текстуру или как-то обработать вычислительным шейдером, чтобы уменьшить количество данных, если вы хотите их скопировать в CPU-память.
Пример кода и замеры производительности
Пример кода можно найти по ссылке на GitHub. Это изменённый пример TensorFlow, в который я добавил переключатель для запуска нейросети на GPU через Java API (с CPU-буферами) или C++ API (с GPU-буферами). Примеры кода для этой статьи взяты из класса ImageSegmentationModelExecutorGPUPass и из C++ классов.
В примере CPU-буфер специально копируется в текстуру и обратно — чтобы замерить, сколько времени занимают эти операции. В реальной программе данные должны сразу приходить в виде текстур.
Для более точных замеров времени нужно синхронизировать GPU- и CPU-потоки выполнения, используя glFinish(спасибо @mizabrik, что указал на недочёт). Иначе на замерах выполнение нейросети через C++ API GPU-делегат будет в разы быстрее, чем копирование текстуры из GPU в CPU. Почему получается такой результат: после выхода из функции расчёта нейросети она продолжает выполняться параллельно на видеокарте, а синхронизация происходит только при копировании текстуры из GPU в CPU. Такое параллельное выполнение может быть полезно в определённых ситуациях, но для более точного замера времени мы используем принудительную синхронизацию СPU и GPU.
Рассмотрим запуски сетки через Java API (с CPU-буферами) и через C++ API (с GPU-буферами).

В первую очередь нас интересует Model execution time:
API | Время Model execution time (мс) |
Java | 120 |
C++ | 85 |
Получаем, что время выполнения уменьшилось примерно на 30%.
Для GPU-примера мы замерили время пересылки данных из CPU в GPU и обратно (Manual push data GPU time и Manual pull data from GPU time). Прибавим его ко времени выполнения модели — и получим для C++ API суммарное время уже в 108 мс. Это уже довольно близко ко времени выполнения через Java API. Больше всего времени мы сэкономили на копировании данных из GPU в CPU. Этому есть две причины. Первая — размер выходного буфера в 5 Мбайт: буфер содержит маски для каждого из двадцати одного предмета поиска. Вторая причина в том, что операция копирования из GPU в CPU медленная.
Если вы используете рекуррентную нейросеть, то прямая передача GPU-буферов должна ещё значительнее улучшить производительность. Рекуррентные данные можно будет скопировать прямо на видеокарте для следующего анализа.
Если нейросеть из нашего примера запустить на CPU, то получим такие результаты:
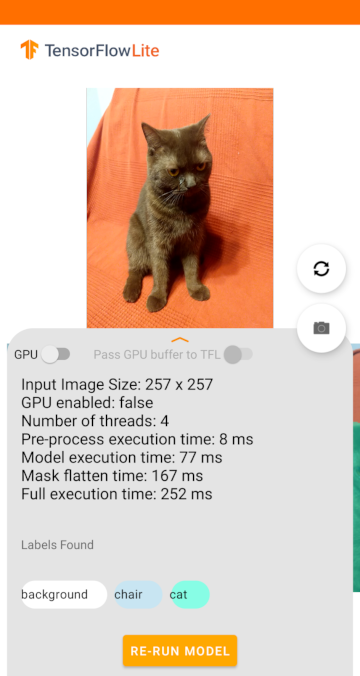
Model execution time равно 77 мс, что немного быстрее выполнения нейросети на видеокарте, даже без пересылки данных между CPU и GPU. Но не стоит удивляться такому поведению: некоторые нейросети могут выполняться на CPU так же быстро, как на GPU, или даже быстрее (на телефонах определённых моделей). Но есть нейросети, которые намного оперативнее работают на GPU, чем на CPU.
Небольшой бонус
Инициализация GPU-делегата занимает значительное время: на некоторых (в основном старых) телефонах может доходить и до 10 секунд, хотя на современных около секунды. Но если GPU-делегат использует OpenCL в качестве бэкенда, то можно с помощью кеша ускорять время повторной загрузки в 2–3 раза. Получить и загрузить кеш можно, применяя следующий метод из примера:
void SetSerializedBinaryCache(std::vector<uint8_t>&& cache);
std::vector<uint8_t> GetSerializedBinaryCache();Отмечу, что кеш индивидуален для телефона и при обновлении нейросети его необходимо сбрасывать.
Что с iOS?
Судя по коду в MediaPipe под iOS, там необходимо напрямую передавать Metal-буферы. Более подробная реализация есть на GitHub.
Выводы
Использование C++ API — один из удобных и эффективных путей для оптимизации приложений, использующих TensorFlow Lite. Этот интерфейс даёт больше возможностей, чем Java API, так как позволяет передавать GPU-буферы напрямую в TensorFlow и экономить время на пересылку данных между CPU- и GPU-памятью. А с использованием кеша для OpenCL можно ускорить ещё и старт нейросетей на GPU.
Так что если хотите ускорить работу нейросетей в вашем Android-приложении, то переход на TensorFlow Lite C++ API поможет сделать это быстро и гарантированно принесёт положительный результат.
Пример кода из статьи можно посмотреть на GitHub.
