

Часто при построении высоконагруженных проектов задействуют несколько хранилищ. При этом нередко одновременно используют как SQL-, так и NoSQL-базы данных. Такая реализация оправдана, но для её корректной работы надо правильно настроить репликацию данных в одну из сторон.
Меня зовут Александр Горякин, я разработчик высоконагруженных систем хранения данных в пресейле Tarantool. Не так давно наша команда столкнулась с необходимостью репликации между SQL- и NoSQL-базами данных и успешно решила эту задачу. Я расскажу, что нам нужно было от репликации, какие механизмы и инструменты мы рассматривали, с какими проблемами столкнулись и что получили в итоге.
Статья написана по моему выступлению на HighLoad++ 2022. Вы можете посмотреть его здесь.
Задачи и исходные требования
Перед нами стояла задача переливки данных между разными хранилищами в разных конфигурациях — как SQL, так и NoSQL. При этом у нас были высокие требования к репликации. В том числе:
- Низкий лаг. Было важно, чтобы между попаданием записи в источник и в приёмник было не больше 40-50 мс.
- Низкая нагрузка на БД-источник. Большинство наших клиентов Enterprise-уровня. Они используют высоконагруженные системы, и дополнительная нагрузка на источник часто недопустима с точки зрения отказоустойчивости.
- Устойчивость к высоким нагрузкам. Даже при пике нагрузки важно, чтобы лаг репликации был постоянным или имел минимальные отклонения.
- Отказоустойчивость при сбоях. В случае падения сети или перезапуска виртуальной машины с продуктом, после устранения сбоя репликация должна продолжить выполняться в штатном режиме.
Варианты интеграции баз данных: ETL, CT, CDC
Есть несколько основных вариантов интеграции баз данных:
- ETL (Extract Transform Load).
- CT (Change Tracking).
- CDC (Change Data Capture).
Extract Transform Load
ETL — универсальное решение, которое можно реализовать на любой базе данных. При этой модели репликации вся информация из БД-источника с помощью стека инструментов выгружается в человекочитаемый формат (CSV или JSON), а потом с помощью другого стека загружается в БД-приемник.
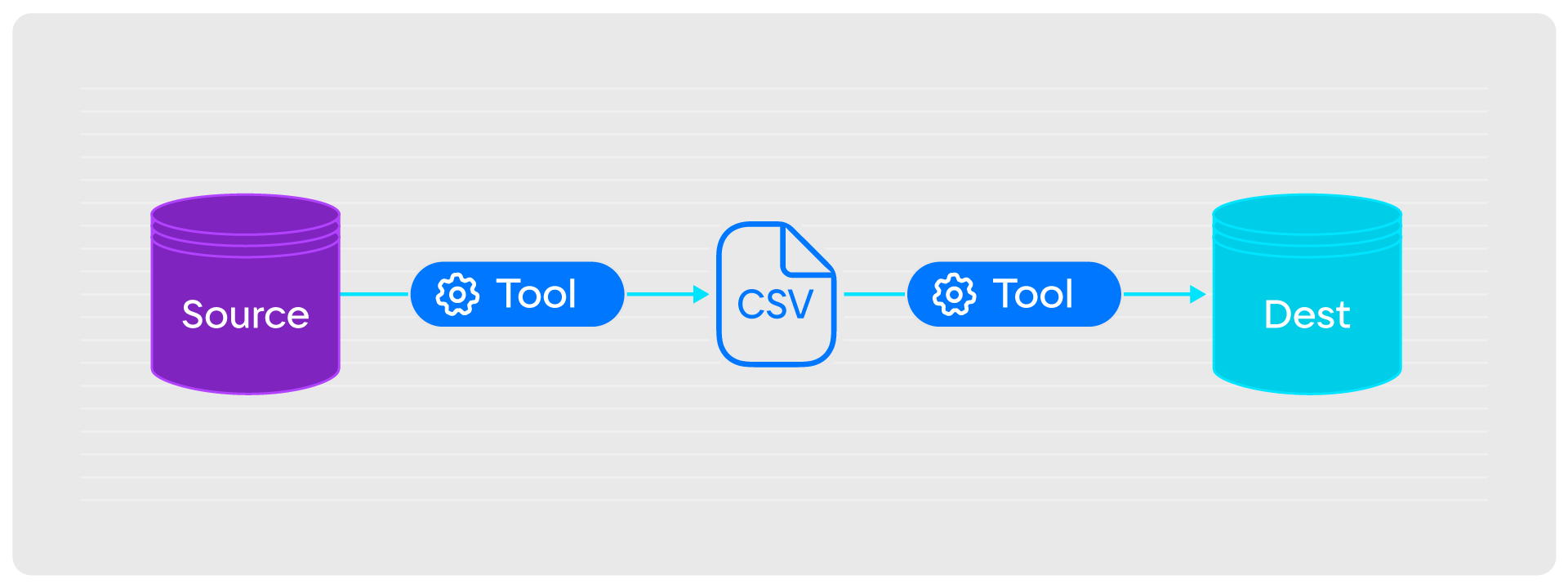
У такого механизма два преимущества:
- Универсальность. ETL позволяет выбирать все записи в любом хранилище.
- Удобство. С выгружаемыми из источника данными легко работать.
Но есть и недостатки:
- Дополнительная нагрузка. При ETL проводится полное сканирование источника, поэтому нагрузка на систему кратно увеличивается.
- Низкая скорость. Из-за нескольких промежуточных звеньев и операций у репликации через ETL огромный временной лаг.
- Нужно много места. Для хранения данных, которые выгружаются из источника в промежуточном формате, нужен большой объём диска. Чем больше, тем сложнее обеспечить инфраструктуру.
Учитывая недостатки, ETL для высоконагруженных систем не подходит.
Change Tracking
CT — метод, при котором изменения в источнике попадают в журнальную таблицу, которую вычитывают инструментом и, в случае обнаружения изменений, передают данные в БД-приемник.

Плюс такого механизма — в стриминге из источника: при попадании записи об изменениях в журнальную таблицу данные сразу реплицируются. Как результат, скорость высокая, а лаг — низкий.
Но есть и недостатки:
- Изменения приходят в виде дельты. Нельзя получить данные до и после изменения, только изменённые фрагменты.
- Ограниченная поддержка. Не все базы данных «из коробки» поддерживают репликацию через Change Tracking.
- Дополнительная нагрузка на источник и приёмник. Из-за выгрузки из промежуточной журнальной таблицы нагрузка на узлы системы увеличивается.
- Отсутствие общих гарантий. Гарантии консистентности и инструментарий уникальны для каждого отдельного кейса. Это связано с тем, что источники, промежуточные таблицы и приёмники в разных проектах различаются.
Под наши задачи механизм Change Tracking подходил только частично — нам было важно реализовать репликацию без дополнительной нагрузки на источник и приёмник. С Change Tracking сделать это нельзя.
Change Data Capture
Механизм CDC подразумевает, что все изменения в базе данных фиксируются в журнале опережающей записи (WAL). С помощью стека инструментов записи из журнала читают и загружают в приёмник. Причём читать журнал опережающей записи можно напрямую или по репликационному протоколу.

У Change Data Capture есть несколько ключевых преимуществ:
- Изменения приходят полностью. Это удобно — известно, как выглядела запись до изменений и какой вид имеет сейчас.
- Работа через WAL. Чтение записей выполняется через WAL, который выступает промежуточным звеном. Благодаря этому, нагрузка на источник не увеличивается, достигается высокая скорость репликации и низкий лаг.
- Гарантированная консистентность данных. Согласованность достигается за счет использования репликационных протоколов баз данных.
Из недостатков Change Data Capture только рост нагрузки на БД-приёмник. Но это неизбежный «побочный эффект» — загрузить данные в приёмник, не увеличивая количество запросов, просто невозможно.
В итоге мы остановились на механизме CDC.
Решения на основе CDC
Change Data Capture — принцип репликации, а не сам инструмент. Его нам предстояло выбрать. При этом надо было учесть, что у большинства наших клиентов основу стека формирует Oracle и Java. Исходя из этого было несколько вариантов.
Oracle GoldenGate. Решение, с помощью которого можно извлекать изменения из redo-логов баз данных Oracle. Также в Oracle GoldenGate пишет библиотека userexit, которая позволяет «переливать» изменения в приемник.
Это быстрый инструмент, но он очень сложен в настройке и дорогой: цена лицензии превышает несколько десятков тысяч долларов. Кроме того, GoldenGate работает в основном с Oracle.
IBM Infosphere CDC. Аналог Oracle GoldenGate для для IBM DB2. Он быстрый, но сложный, дорогой и с ограниченной поддержкой: только для IBM DB2.
Самописный CDC-tool. Можно было самим разработать нужное решение — например, взять библиотеки pglogrepl и pgproto, которые позволяют парсить протоколы PostgreSQL и логической репликации, и на их основе реализовать приложение.
Самописная реализация хороша тем, что полностью понятен принцип работы инструмента и можно адаптировать его под конкретную задачу. Но для разработки полноценного решения нужно много времени и ресурсов, а «на выходе» можно получить узкоспециальный продукт, который сложно поддерживать.
Debezium. Сервис для захвата изменений в базах данных (Change Data Capture) и отправки их на обработку в другие системы. У Debezium есть Source-корректоры к БД-источникам — изначально они работают поверх Apache Kafka Connect, но с помощью библиотеки Debezium Embedded коннектор можно встроить в приложение без Kafka. Также есть Debezium Server, готовое приложение для организации обмена данными при их миграции или модернизации существующих систем. В свою очередь в Debezium Server доступны Sink-коннекторы, с помощью которых можно передавать информацию в целевые приёмники: Redis, Kafka, Apache Pulsar и другие. Более того, Debezium написан на Java, то есть он подходит под стек наших заказчиков.
Мы выбрали этот вариант.
Работа с Debezium: с чего мы начали
Изначально нам казалось, что сделать решение на Debezium можно быстро и легко — достаточно изучить документацию и получится заменить Oracle GoldenGate, который к тому моменту был у нас основным. Так мы приступили к разработке приложения Debezium Embedded. В процессе разработки мы обнаружили, что коннектор хорошо справляется с чтением redo-логов с помощью LogMiner и изменений с помощью XStream API, но использовать его очень сложно.
Причины крылись в задействованных инструментах:
- LogMiner нестабилен: в любой момент он может прислать сообщение, которое коннектор не может распарсить, что приведёт к сбою всего решения.
- LogMiner deprecated: в последних версиях Oracle LogMiner не умеет передавать данные потоково.
- Спецификация LogMiner меняется от версии к версии.
- XStream API работает по лицензии Oracle GoldenGate, переход на него не решает проблему высокой стоимости.
Это была наша первая ошибка. Но в результате мы получили прототип, хоть и не нашли для него применения.
От сложного к простому: доработка прототипа
Через полгода мы решили доработать прототип, но использовать более понятный и простой инструмент, вроде PostgreSQL, и обеспечить универсальность решения. На выходе мы получили монолитное приложение, которое содержит в себе несколько коннекторов и позволяет потоково передавать данные из PostgreSQL в Tarantool. Но даже после замены инструмента лаг репликации оказался высоким — до нескольких минут — и рос пропорционально количеству записей. Одновременно с этим мы узнали и о других проблемах, которые надо было решить.
Высокий лаг репликации
Выявленный в Debezium Embedded лаг решили уменьшить несколькими способами.
- Организовали асинхронную загрузку данных. Мы начали отправлять данные в приёмник и не дожидаясь ответа о применении изменений. Но при изучении логов Tarantool оказалось, что данные приходят без сохранения порядка отправки, в итоге данные в целевой БД получаются неконсистентными.
- Перешли от JSON к Kafka SourceRecord. На парсинг JSON надо много времени. Мы решили заменить его на Kafka SourceRecord — это бинарный, нативный формат Kafka, на парсинг которого надо в разы меньше времени. Изменение помогло, но только частично: лаг репликации уменьшился, но всё равно достигал нескольких минут.
- Применили батчинг. Данные посылались из того же потока, в котором приходили из приёмника, и изначально отправлялись по одной записи. Мы решили собирать данные в батч и в таком виде отправлять их в приёмник. Благодаря этому лаг репликации уменьшился в 1,5-2 раза, но всё равно оставался высоким.
- Разделили потоки данных. Мы разнесли поток приёма из источника и поток отправки в приёмник на разные операции. Между потоками добавили трансфер (очередь или канал), который позволял сформировать батч нужного размера. В результате разделения лаг репликации уменьшился до 40-50 мс.
Низкая отказоустойчивость
Следующая проблема, с которой мы столкнулись — отказоустойчивость. Debezium хранит оффсеты — отметки о прочтении записей — в файле, который легко удалить, или в Kafka, которая может быть недоступна. Если оффсеты будут недоступны, то решение начнёт повторно перечитывать все изменения из источника, что неизбежно увеличит нагрузку на всю систему.
Мы решили организовать хранение оффсетов в БД-приёмнике. В таком случае при отправке батча в Tarantool автоматически сохраняется оффсет для каждой записи, который при запуске можно прочитать. Для считывания оффсетов мы написали отдельный класс для Debezium, который читает оффсеты при старте и стартует с последнего полученного.
Также на отказоустойчивость изначально влияли ошибки записи в БД-приёмник. Так, если приёмник шардированный, то часть изменений может не применяться, даже если записи поступают исправно. Debezium Embedded «из коробки» не распознаёт эту проблему — он уведомляет, что изменение применено, если даже по факту это не так.
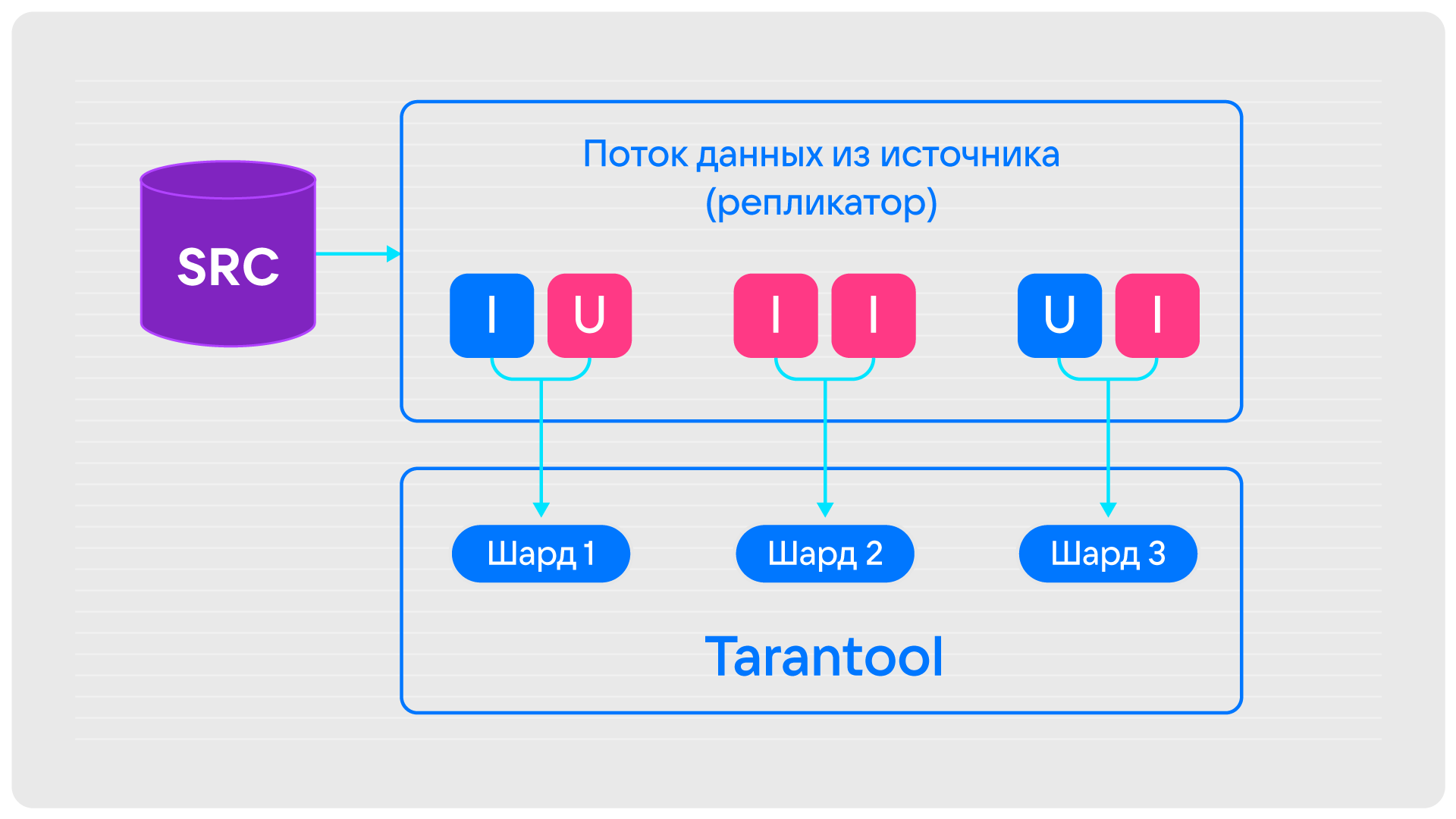
Чтобы устранить этот баг, мы настроили повторные попытки записи батча — если изменение не применено, LSN-записи возвращаются и батч отправляется повторно. Это позволяет гарантировать консистентность данных в БД-приёмнике.
Монолитная архитектура
Монолитная архитектура также стала для нас проблемой. Конечно, при такой реализации все коннекторы доступны «из коробки» и сам монолит легко настраивать: достаточно указать профиль конфигурации и описать подключение к источнику и приёмнику в конфигурационных файлах. Но в нашем случае монолитная архитектура не подходила по ряду причин:
- Сложность масштабирования. У нас два потока данных, и при такой архитектуре нельзя масштабировать приложение на несколько ReplicaSet — надо только запускать новые инстансы.
- Невозможность адаптации. В монолите любое изменение внутреннего компонента приводит к необходимости переработки всего приложения. Это сложно и дорого.
Для перехода с монолитной архитектуры мы решили использовать Debezium Server, который:
- содержит в себе source-коннекторы для подключения к БД-источникам;
- имеет sink-коннекторы для подключения к БД-приёмникам;
- реализует функциональность, которую мы сделали для Debezium Embedded.

Кроме архитектуры, Debezium Server привлёк нас и преимуществами:
- Есть готовые сборки — все дистрибутивы можно просто скачать с сайта.
- Легко добавить новые source-коннекторы, в том числе работать с собственными.
- Конфигурация очень простая: достаточно в конфигурационном файле указать БД-источник, БД-приёмник и параметры подключения.
- Инструмент позиционируют как решение для Kubernetes, поэтому его легко масштабировать с помощью k8s.
- Позволяет добавлять своё хранилище оффсетов, что мы и сделали в Debezium Embedded.
Но у него есть и недостатки:
- Сложность добавления своего sink-коннектора: надо указывать зависимости и вносить изменения в конфигурационный файл.
- При каждом изменении sink-коннектора надо пересобирать дистрибутив или коннектор.
- Из коробки оффсеты хранятся в файле, в Kafka или в Redis — как и в случае с прототипом это не лучший вариант.
В нашем случае преимущества оказались важнее недостатков, поэтому Debezium Server стал нашим основным решением.
Решения для работы с распределёнными источниками
БД-источник может быть шардированной, как, например, Tarantool. Каждый из инструментов работает с такими БД по-разному.
- Debezium Embedded. Масштабирование выполняется по шардам и вручную, оффсеты хранятся в приёмнике для каждого шарда.
- Debezium Server. Масштабирование выполняется по шардам с помощью Kubernetes. Оффсеты хранят в файле, Kafka, Redis, приемнике для каждого шарда.
- Kafka-connect. Масштабирование выполняется по шардам с помощью тасков Kafka-connect — для каждого ReplicaSet запускается отдельный таск, который будет считывать данные. Оффсеты для каждого шарда хранятся в Kafka.
Главное из нашего опыта
- Зачастую к репликации высокие требования. Нам были важны скорость, отказоустойчивость, отсутствие дополнительной нагрузки. Исходя из этих требований мы выбрали механизм Change Data Capture, который удовлетворял всем основным критериям.
- Инструмент надо выбирать с учётом стека конечных пользователей. Наши заказчики часто работают с Java, поэтому, чтобы обеспечить совместимость решения, в качестве основы стека мы выбрали Java и Debezium.
- Монолитные приложения не всегда хороши. Debezium Embedded было сложно масштабировать и конфигурировать, поэтому мы перешли на Debezium Server. Это универсальное не монолитное решение, которое позволяет добавлять свои коннекторы и масштабироваться с помощью Kubernetes.
- Ошибки при создании инструмента для репликации неизбежны. Мы столкнулись с рядом проблем: высокий лаг, низкая отказоустойчивость, сложная архитектура. Каждый из недостатков нам пришлось устранять отдельно. Но тщательная доработка помогла нам получить инструмент, с помощью которого можно переливать данные из PostgreSQL в Tarantool с низким лагом репликации и сохранением консистентности.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
