
Привет, Хабр!
Меня зовут Вадим Москаленко и я разработчик инновационных технологий Страхового Дома ВСК. В этой статье хочу поделится с вами информацией в области хранения данных.
На сегодняшний день существует огромное количество форматов для хранения данных, и, используя библиотеку Pandas при обработке большого объёма данных, возникает вопрос – а какой формат, с которыми Pandas работает «из коробки», даст наибольшую производительность, при дальнейшем использовании, обработанного DataFrame?
Ремарка: поиск информации по этой теме, привёл меня к репозиторию, за авторством Devforfu (ссылка), но так как информация в нём датируется 2019 годом, а за этот период вышло множество обновлений, я решил написать «свежий» бенчмарк, основываясь на принципах автора – ссылка на обновленный бенчмарк. Отмечу, что из-за слишком большой разницы в полученных результатах, я склоняюсь к тому, что мог совершить ошибку, поэтому далее в статье будет указана информация по оригиналу.
В качестве тестируемых форматов использовались следующие варианты: CSV (как самый популярный текстовый формат), Pickle, Feather, Parquet, Msgpack, HDF. Для сравнения будем использовать следующие метрики: размер сериализованного файла, время загрузки DataFrame из файла, время сохранения DataFrame в файл, потребление оперативной памяти при сохранении и загрузке DataFrame.
Тестовые данные – сгенерированный DataFrame с 1 миллионом строк, 15 столбцами цифр и 15 столбцами строковых значений. Генерация численных данных проводилась с помощью numpy. random.normal, в качестве строчных данных использовались UUID. С появлением в Pandas, категориального типа данных (Categorical data), который использует гораздо меньше памяти и более производительней в обработке (обширный материал для другой статьи), интересно также сравнить насколько изменится производительность форматов, поэтому ещё одним этапом сравнения в тестовых данных стал перевод формата «object» к формату «category».
Бенчмарк
Метрики собирались в течении 20 раундов, после чего группировались в результирующий DataFrame по среднему значению. Посмотрим на результаты:
Формат | RAM, при загрузки файла, Мбайт | Время загрузки, с | RAM, при сохранении файла, Мбайт | Время сохранения, с | Размер файла, Мбайт |
csv | 385.174219 | 7.179108 | -0.166406 | 27.588694 | 771.4420 |
feather | 850.572461 | 1.333151 | 635.453125 | 1.966192 | 665.0205 |
hdf | 2602.573047 | 9.296356 | 1337.336523 | 8.668205 | 1644.7400 |
msgpack | 618.167383 | 3.164023 | 1231.050391 | 4.245394 | 637.7340 |
parquet | 883.852148 | 0.634647 | 662.311523 | 2.439488 | 129.1415 |
pickle | 1211.571289 | 2.853154 | 1543.474805 | 5.329675 | 651.4410 |
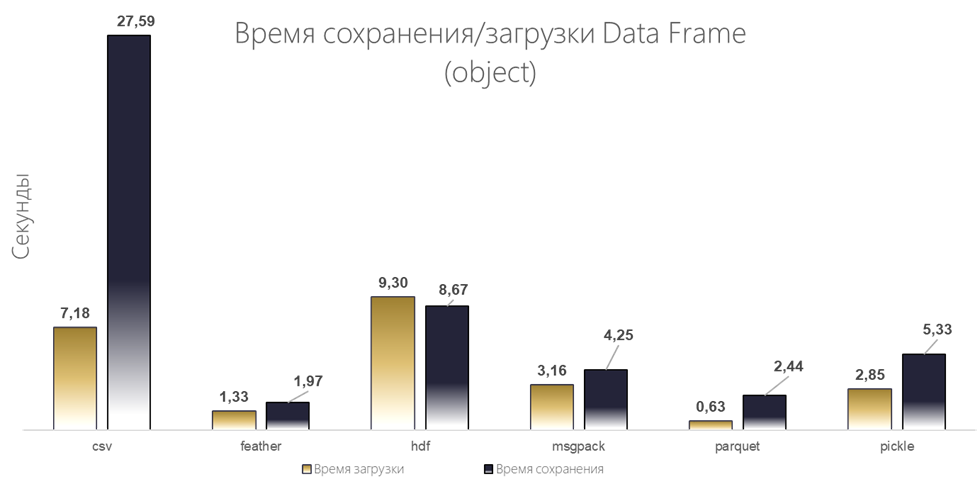


Результаты:
Лидером по скорости сохранения и загрузки является Parquet, за ним на втором месте Feather, аутсайдером выступил формат CSV.
По росту потребления памяти лидирует текстовый формат CVS, хорошая дельта во время загрузки файла у Msgpack, но высокая при сохранении, поэтому второе место занимает Feather, а на третьем месте Parquet.
По размеру сериализованного файла, с огромным отрывом побеждает Parquet.
Далее, посмотрим на результаты с категориальным типом данных:
Формат | RAM, при загрузки файла, Мбайт | Время загрузки, с | RAM, при сохранении файла, Мбайт | Время сохранения, с | Размер файла, Мбайт |
csv | 385.174219 | 7.179108 | -0.166406 | 27.588694 | 771.4420 |
feather | 10.669531 | 0.044231 | 0.652148 | 0.179261 | 130.5660 |
hdf | 327.377148 | 1.134490 | 8.731445 | 0.909780 | 1269.0565 |
msgpack | 195.321094 | 0.250950 | 175.532813 | 0.332355 | 128.7790 |
parquet | 920.664258 | 0.617414 | 83.697852 | 1.936816 | 128.8640 |
pickle | 135.969922 | 0.118571 | 198.686523 | 0.286379 | 128.7785 |

Так как CSV, на фоне остальных, сильно проигрывает, приведём график без него, для наглядности.
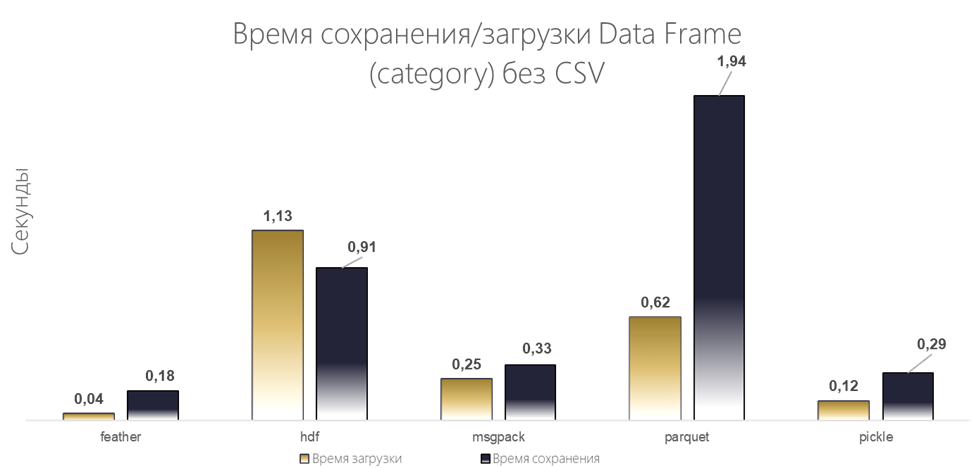

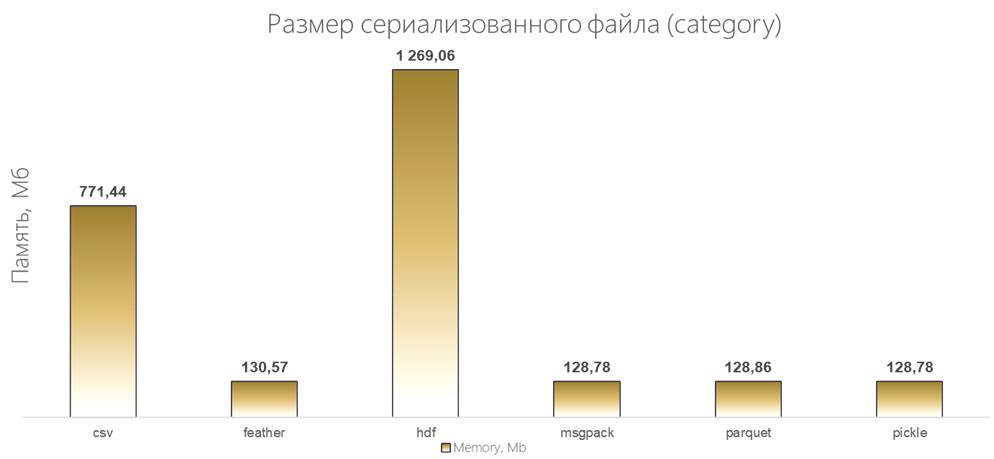
Результаты:
Лидер по скорости изменился и им стал Feather, за ним на втором месте Pickle.
По росту потребления памяти также есть изменения: на первом месте feather, второе делят между собой Pickle/Msgpack и аутсайдером при загрузке файла выступил Parquet.
По размеру сериализованного файла, у Parquet уже нет безоговорочного лидерства.
Файл или База данных?
Получив данные по форматам, стало интересно сравнение производительности с базами данных (далее по тексту – БД). Тут нужно учесть, что основное преимущество хранения в БД — это конкурентный доступ. В случаях, когда он не требуется, хранение данных в файлах обеспечит более прямой и очевидный доступ.
Такое сравнение, с использованием Microsoft SQL Server, привелось в статье – architecture-performance. Краткая выжимка результатов: по скорости чтения БД отстаёт от файлового хранения, а самым быстрым драйвером является Turbodbc.
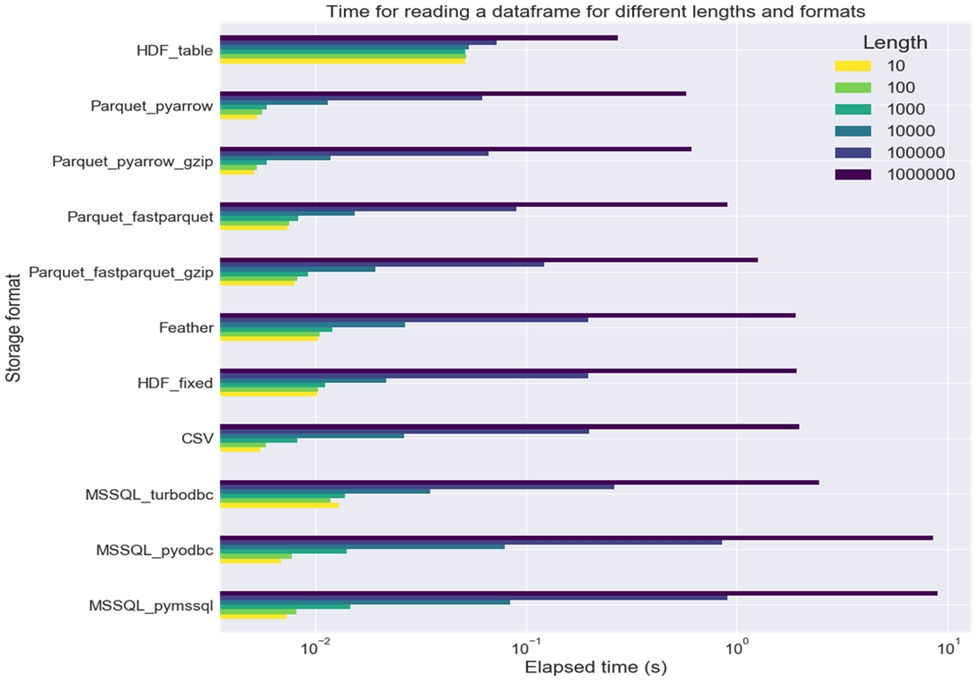
Итоги
Так как, в одной из первых строк документации Pickle, указано предупреждение о том, что формат небезопасен, можно выделить двух лидеров бенчмарка: Feather и Parquet.
Тип данных | Object | Category | ||||
Формат | feather | parquet | % | feather | parquet | % |
Время сохранения, с | 1,97 | 2,44 | 24,07% | 0,18 | 1,94 | 980,44% |
Время загрузки, с | 1,33 | 0,63 | 52,39% | 0,04 | 0,62 | 1295,89% |
Рост потребления памяти при загрузки, Мбайт | 850,57 | 883,85 | 3,91% | 10,67 | 920,66 | 8528,91% |
Рост потребления памяти при сохранении, Мбайт | 635,45 | 662,31 | 4,23% | 0,65 | 83,70 | 12734,18% |
Размер сериализованного файла, Мбайт | 665,02 | 129,14 | 80,58% | 130,57 | 128,86 | 1,30% |
Если в DataFrame не используется категориальный тип данных Pandas, то для долгосрочного хранения больших данных, лучше всего подойдёт формат «Parquet», за счёт минимального размера сериализованного файла. В остальных случаях, формат «Feather» будет самым оптимальным вариантом и позволит с большей скоростью обрабатывать данные, потребляя при этом меньше ресурсов.
