
В последние 10 лет ВТБ переживает мощный рост вычислительной нагрузки. Каждый год она увеличивалась в полтора раза, а объем учетных данных — в два. Службы поддержки очень старались, но угнаться за этими темпами было непросто: планы запросов отъезжали, дисковое пространство заканчивалось, обновления прикладного кода съедали все ресурсы. В этом посте мы расскажем, как решили проблему без больших трат на еще один IBM System p.

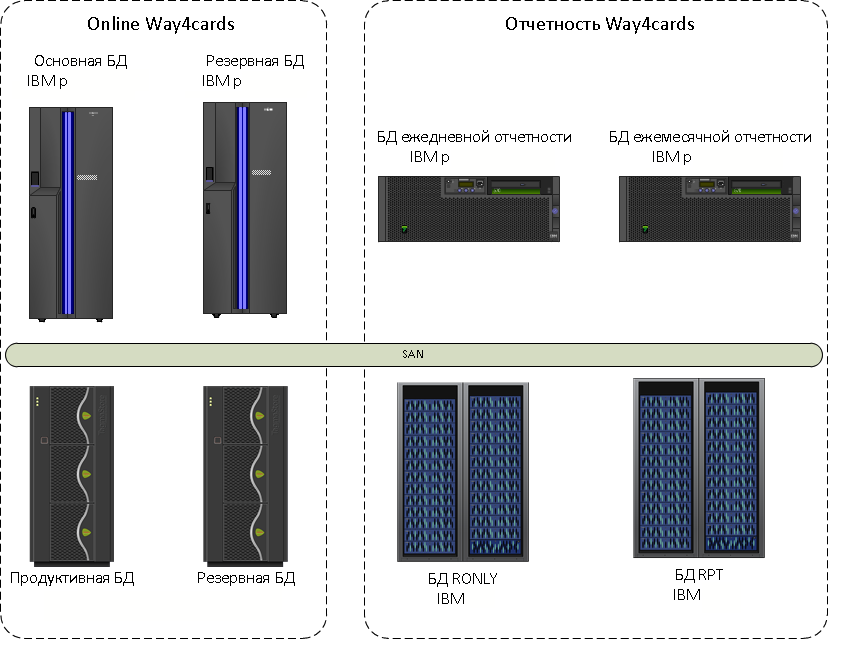
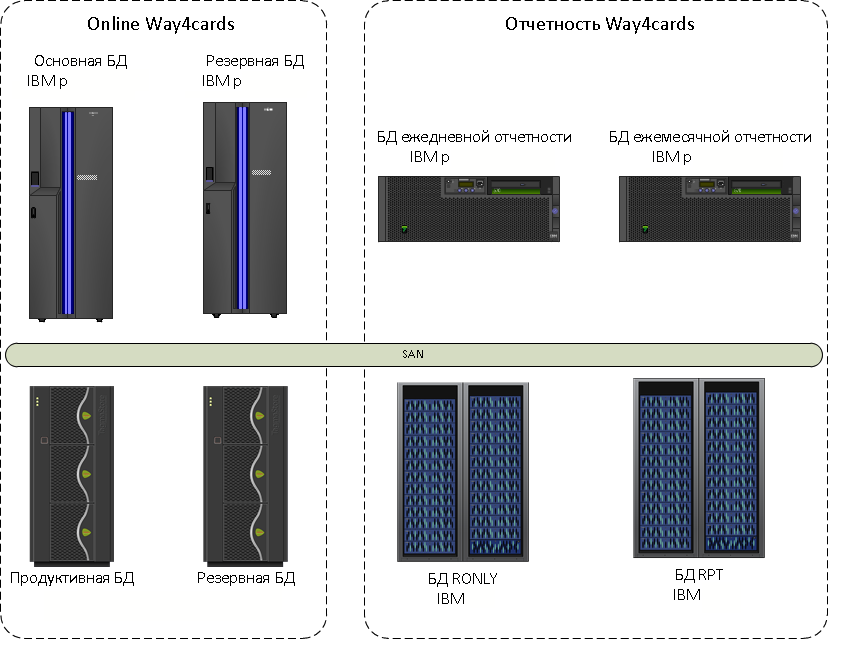
В 2013 году карточный процессинг, тогда еще банка ВТБ24, размещался на одном из самых мощных серверов того времени — IBM System p. Это дополняли реплики для разной отчетности. На дополнительном оборудовании жили реплики для отчетности: еженощно обновляемая база для дневной отчетности, средства для активной реплики Oracle Active Data Guard для оперативной отчетности и БД для отчетности Центробанка, которую мы обновляли ежемесячно.
Мы активно кастомизировали функциональность систем — большую часть прикладного кода занимали внутренние доработки. При этом данные разрастались очень стремительно. В результате план запросов по четырем базам регулярно ухудшался. Фронтальные системы работали медленно. В техническом ракурсе была еще одна сложность: OLTP-нагрузка карточных транзакций смешивалась с DWH/DSS-нагрузкой кастомизированной функциональности и отчетности.
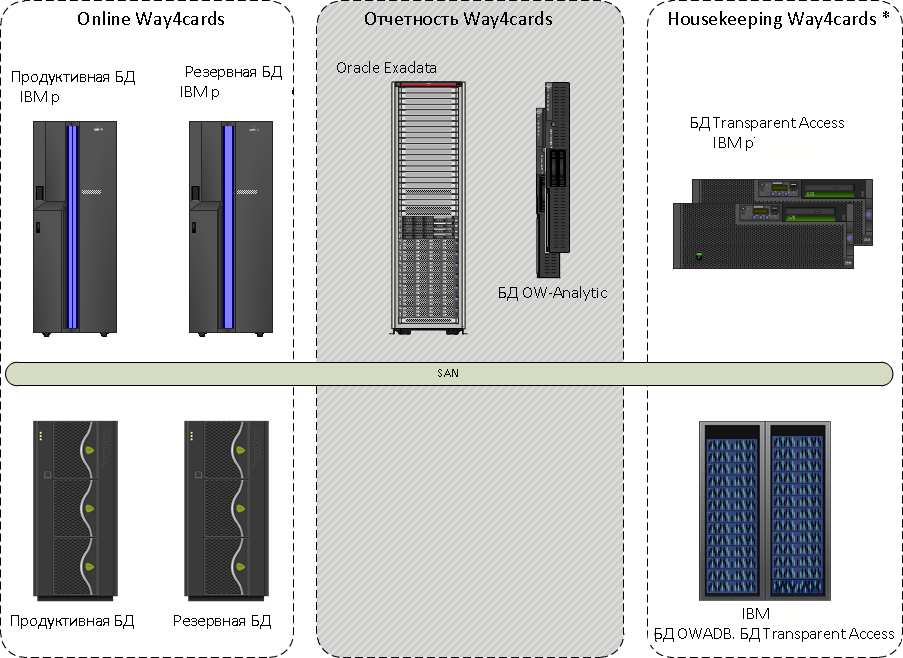
Стандартный выход из этого положения: докинуть ресурсов и перейти на более крутую подсистему хранения данных. Мы придумали более интересный вариант — взяли для отчетных реплик два оптимизированных для работы БД программно-аппаратных комплекса Oracle Exadata.
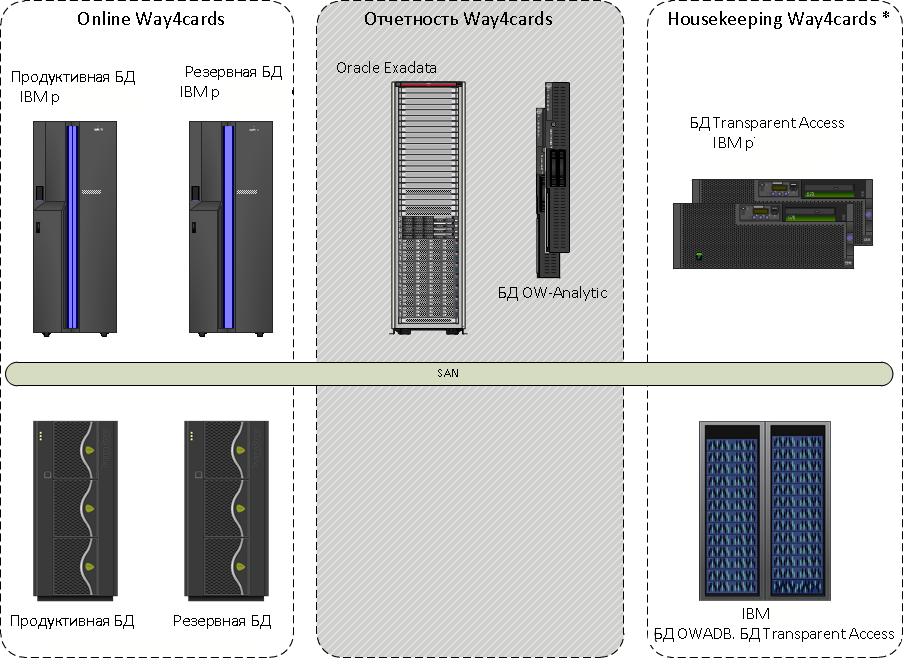
Комплекс процессинга разделили на «теплую» и «горячую» зоны. «Горячая» зона никуда с IBM System p не переехала, и в ней сохранилась только ее база данных. «Теплая» зона представляла собой копию основной БД на Exadata. Здесь была вся отчетность и кастомизированная функциональность. Реплицировали данные с помощью Oracle GoldenGate.
Провели тесты реплики на Exadata: в среднем, отчетность стала формироваться в пять раз быстрее благодаря архитектуре и фичам ПО Oracle Exadata Storage — smartscans, storage indexes, bloom filters и т.д. Время подготовки отчетности для ЦБ сократилось в десятки раз и сейчас некоторые отчеты готовятся менее чем за 1 час. Главное, что нужно было сделать для оптимизации запросов при переносе на Exadata — это удалить хинты, которые ранее помогали работать на старой платформе.
Мы провели технико-экономическое обоснование, сопоставив по разным параметрам варианты с обычным расширением текущих систем и с привлечением двух комплексов Exadata.
Поначалу уязвимым местом оказалась репликация на GoldenGate: в случае длинных транзакций на источнике она отставала. Мы решили это с помощью обновлений и переработки некоторых прикладных процессов. После этого работа с Exadata открывала нам лишь преимущества.
Мы ввели кастомные индексы и партиционирование, что позволило увеличить производительность кастомных функций. IBM такую оптимизацию не разрешает.
Перенос аналитической отчетности на «тёплую» зону позволил уменьшить глубину хранения исторических данных «горячей» зоны. Это сократило расходы на дорогостоящую СХД. Удалось ускорить вставку в индексы. Удаления данных посредством модуля housekeeping'а фильтровались на уровне GoldenGate, в результате на реплике имелись свежие данные и вся история;
Exadata использует гибридное колоночное сжатие (HCC), и это существенно экономит дисковое пространство. Данные старше одного года сжимаются методом «archive low», старше одного месяца — методом «advanced compression», более новые данные для повышения скорости не сжимаем.
Что касается апгрейда, то наиболее эффективно заменять в Exadata целые ячейки хранения (storage cell) на ячейки с более емкими дисками и производительными процессорами. Но можно использовать внутри одной системы ячейки хранения разных версий — Oracle это разрешает.
Отчетность карточного процессинга, реализованная на технологиях Oracle Exadata и Database, прекрасно работает до сих пор, и по такому же принципу строятся новые системы банка.

В 2013 году карточный процессинг, тогда еще банка ВТБ24, размещался на одном из самых мощных серверов того времени — IBM System p. Это дополняли реплики для разной отчетности. На дополнительном оборудовании жили реплики для отчетности: еженощно обновляемая база для дневной отчетности, средства для активной реплики Oracle Active Data Guard для оперативной отчетности и БД для отчетности Центробанка, которую мы обновляли ежемесячно.
Мы активно кастомизировали функциональность систем — большую часть прикладного кода занимали внутренние доработки. При этом данные разрастались очень стремительно. В результате план запросов по четырем базам регулярно ухудшался. Фронтальные системы работали медленно. В техническом ракурсе была еще одна сложность: OLTP-нагрузка карточных транзакций смешивалась с DWH/DSS-нагрузкой кастомизированной функциональности и отчетности.
Стандартный выход из этого положения: докинуть ресурсов и перейти на более крутую подсистему хранения данных. Мы придумали более интересный вариант — взяли для отчетных реплик два оптимизированных для работы БД программно-аппаратных комплекса Oracle Exadata.
Комплекс процессинга разделили на «теплую» и «горячую» зоны. «Горячая» зона никуда с IBM System p не переехала, и в ней сохранилась только ее база данных. «Теплая» зона представляла собой копию основной БД на Exadata. Здесь была вся отчетность и кастомизированная функциональность. Реплицировали данные с помощью Oracle GoldenGate.
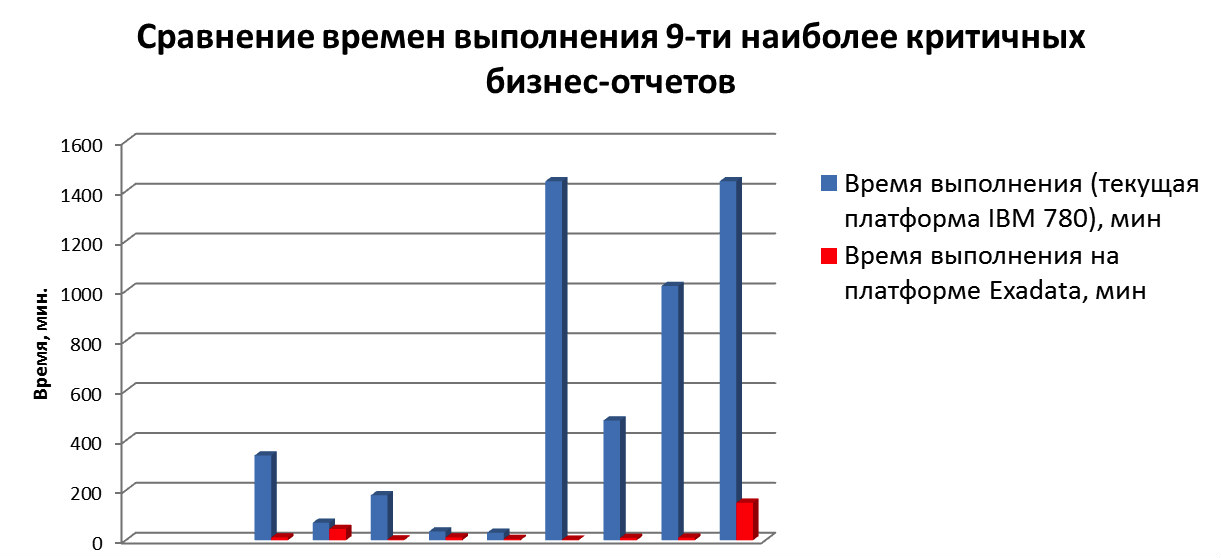
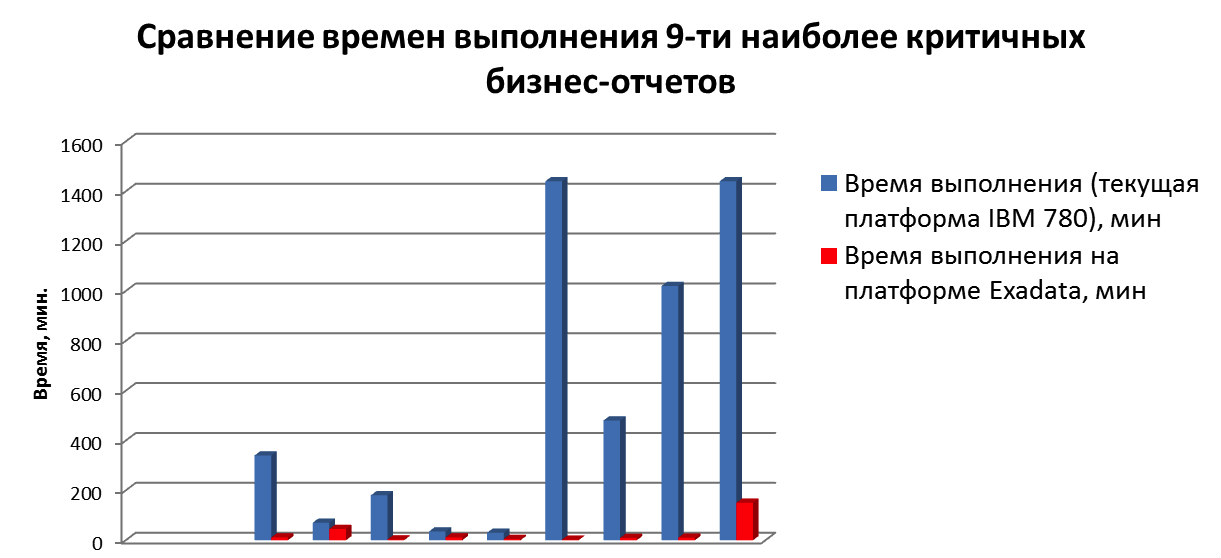
Провели тесты реплики на Exadata: в среднем, отчетность стала формироваться в пять раз быстрее благодаря архитектуре и фичам ПО Oracle Exadata Storage — smartscans, storage indexes, bloom filters и т.д. Время подготовки отчетности для ЦБ сократилось в десятки раз и сейчас некоторые отчеты готовятся менее чем за 1 час. Главное, что нужно было сделать для оптимизации запросов при переносе на Exadata — это удалить хинты, которые ранее помогали работать на старой платформе.
Мы провели технико-экономическое обоснование, сопоставив по разным параметрам варианты с обычным расширением текущих систем и с привлечением двух комплексов Exadata.
- Производительность. 40 тыс IOPS против 400 тыс IOPS у Exadata. Решение Oracle заточено на большие объемы данных, полное сканирование таблиц проходит гораздо быстрее.
- Возможности кастомизации. В стандартном решении мы не можем изменить структуру объектов без изменений в продуктивной БД, это запрещено вендором. В Exadata мы можем удалить ненужные индексы, добавить необходимые и улучшить отклик системы.
- Масштабирование. Exadata дает линейный рост производительности при сравнительно меньших затратах.
- Формирование отчетности. Скорость формирования отчетности с комплексом Exadata увеличивается в 5 раз, а с масштабированием имеющихся систем — в 1,5.
- Обслуживание. В инфраструктуре Oracle единая техподдержка, единая система обновлений для серверов, дисковых подсистем и сетевой инфраструктуры. При обычном масштабировании нужно работать с разными вендорами — и простоев больше, и всяких других неудобств.
- Стоимость. Exadata здесь выигрывает.
Поначалу уязвимым местом оказалась репликация на GoldenGate: в случае длинных транзакций на источнике она отставала. Мы решили это с помощью обновлений и переработки некоторых прикладных процессов. После этого работа с Exadata открывала нам лишь преимущества.
Мы ввели кастомные индексы и партиционирование, что позволило увеличить производительность кастомных функций. IBM такую оптимизацию не разрешает.
Перенос аналитической отчетности на «тёплую» зону позволил уменьшить глубину хранения исторических данных «горячей» зоны. Это сократило расходы на дорогостоящую СХД. Удалось ускорить вставку в индексы. Удаления данных посредством модуля housekeeping'а фильтровались на уровне GoldenGate, в результате на реплике имелись свежие данные и вся история;
Exadata использует гибридное колоночное сжатие (HCC), и это существенно экономит дисковое пространство. Данные старше одного года сжимаются методом «archive low», старше одного месяца — методом «advanced compression», более новые данные для повышения скорости не сжимаем.
Что касается апгрейда, то наиболее эффективно заменять в Exadata целые ячейки хранения (storage cell) на ячейки с более емкими дисками и производительными процессорами. Но можно использовать внутри одной системы ячейки хранения разных версий — Oracle это разрешает.
Отчетность карточного процессинга, реализованная на технологиях Oracle Exadata и Database, прекрасно работает до сих пор, и по такому же принципу строятся новые системы банка.
