
В этой статье расскажем о том, как в какой-то момент один из важных продуктовых компонентов превратился в неповоротливого монстра и собрал кучу эскалаций по перформансу от недовольных клиентов. А также о том, какие шаги мы предприняли, чтобы выправить ситуацию и не переписывать все с нуля. Ну или почти все. Статья будет интересна всем, кто разрабатывает сложные приложения с большим количеством вычислений на фронте и одновременно борется как за клиентов, так и за производительность.
Рассказчики и по совместительству как раз такие борцы — Игорь Зубов и Алексей Шаров, фронтенд тимлиды в Wrike.
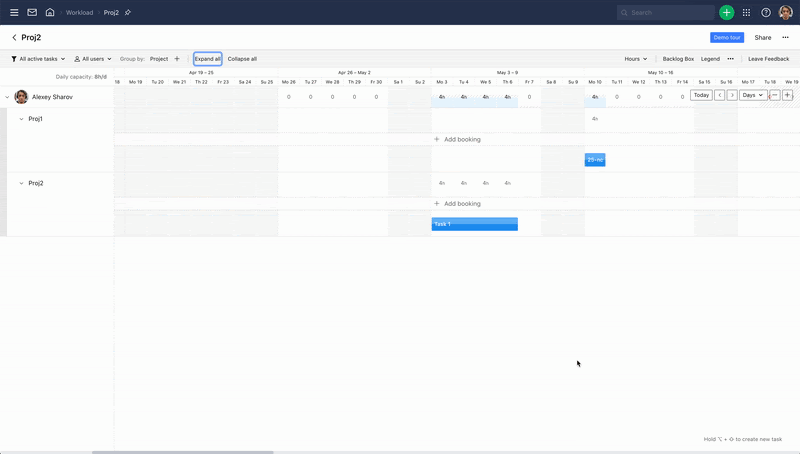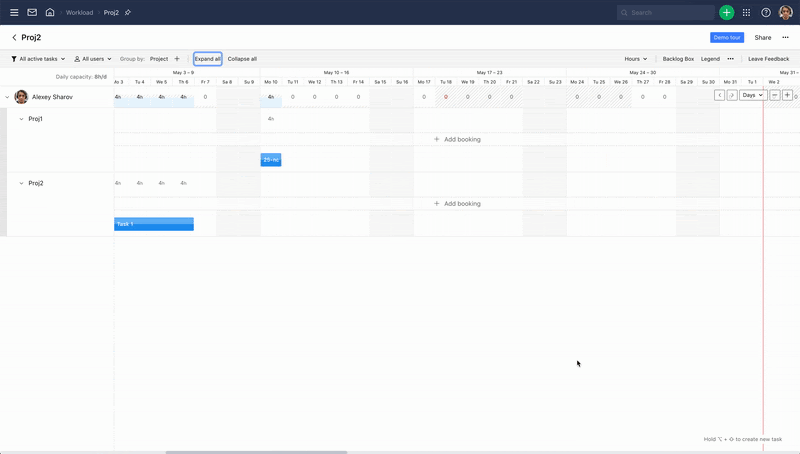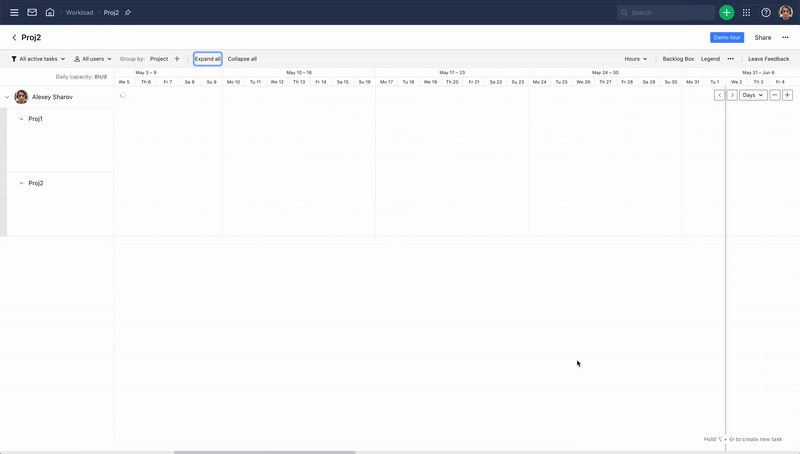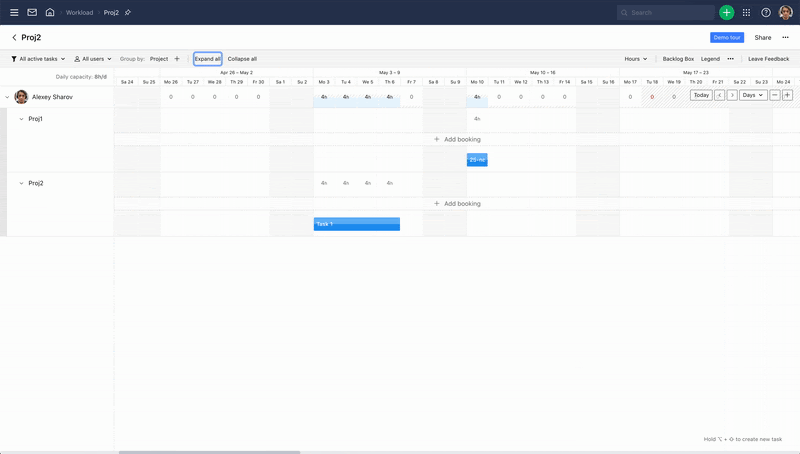
Мы работаем в разных командах одного продуктового юнита — Wrike for Professional Services. Одна из самых сложный частей продукта, за которую отвечает наш юнит, — Workload. Workload — это график, который используют менеджеры разных уровней. На нем они могут видеть загрузку и смотреть, в какие дни сотрудники перегружены задачами, а в какие — недозагружены. Еще менеджер может видеть все задачи проектов, планировать, менять их местами или менять человека, на которого они назначены.

Workload — это не только календарная сетка, но и проекты и задачи:

Мы создали Workload три года назад как простую таблицу. Сейчас это сложный компонент: больше 100 000 строк кода и огромное количество вычислений на стороне фронтенда (многое делается оптимистически: пересчеты расписания, движение задачи).
Кейс на первый взгляд кажется простым. Но, например, у пользователя может быть свое рабочее расписание: в один день он работает 8 часов, в другой — 3, а в третий — не работает. На одну задачу может быть назначено сразу несколько пользователей с разным расписанием. Изначально мы решили реализовывать всю логику на фронтенде, поэтому вычислений там очень много. Компонент получился сложным.
В начале 2021-го года мы поняли, что все плохо.
Как мы поняли, что все плохо
Когда годами работаешь с тестовыми окружениями и тестовыми аккаунтами, глаз замыливается. Там может быть мало данных или не те данные, которые нужны. Мы обращали внимание на то, что компонент начал немного тормозить. Но, в целом, все было нормально. Нам казалось, что это не критично — обычная цена за стремительное насыщение фичами.
Архитектура компонента, которую мы создавали в 2018-ом году, не была масштабируемой и подходила для клиентов Middle-сегмента. Тогда нам не нужно было обрабатывать большие объемы данных. Пока мы добавляли новые фичи, Wrike как продукт и компания сильно вырос. У нас появилось много клиентов уровня Enterprise. А в таких компаниях больше команд, больше людей и больше данных.
Это привело к тому, что в январе 2021-го к нам пришли первые клиенты, которые жаловались на скорость загрузки Workload. У нас было примерно десять эскалаций. Всего клиентов у компании 20 000+, и кажется, что 10 из 20 000 — совсем небольшая цифра. Но эскалации появились за короткий промежуток времени — 10 за один месяц.
Стало ясно, что проблема есть, и ее нужно решать. Причем мы восприняли это очень серьезно: пришли к продакт оунеру и сказали, что нам нужно понять, почему у нас такие проблемы с перформансом. Мы попросили отложить все релизы на месяц и использовать этот месяц, чтобы разобраться с проблемой и попробовать ее решить.
Возможные причины проблем с перфомансом
Мы начали разбираться и выделили несколько причин, которые теоретически могли повлиять на перформанс.
Количество DOM-элементов на странице. Таблица сделана на DOM. Большое количество данных — огромное количество DOM-элементов на странице. Мы предположили, что уперлись в производительность Angular’а.
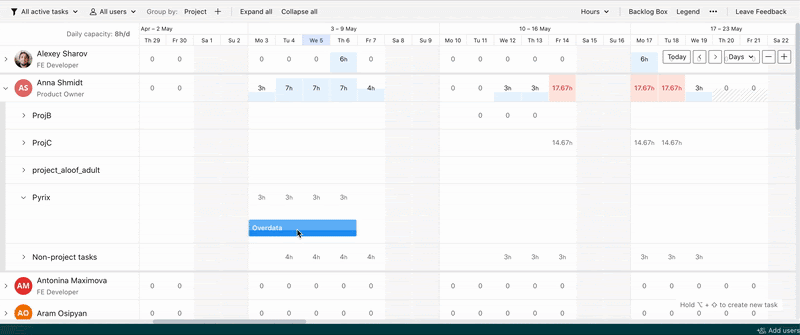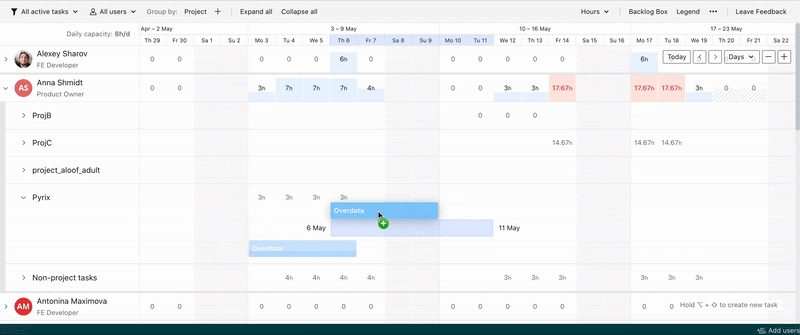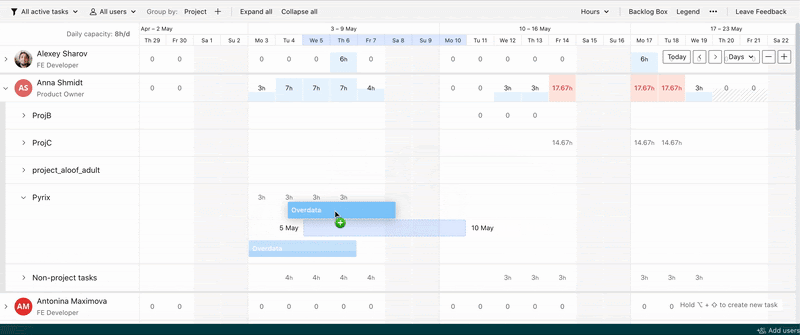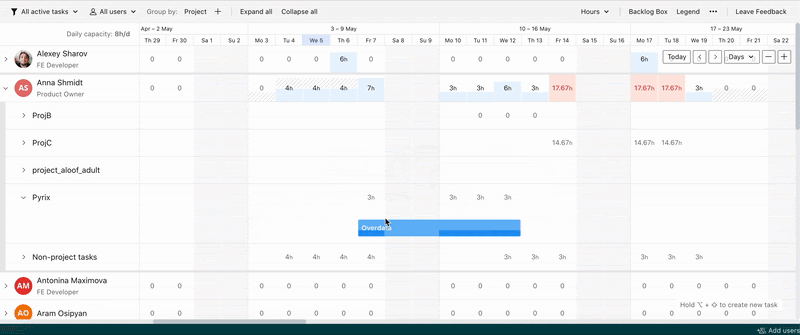
В Workload есть режим compact mode, который увеличивает количество клеток в таблице в два раза:

Каждая маленькая клеточка в таблице — это div, у которого в некоторых случаях стили пересчитываются на лету.
Их может быть очень много:

Мы предположили, что компонент начинает тормозить, потому что рендерить такое количество элементов сложно.
Усложненные фичи работают медленнее с увеличением объема данных. Мы пытались сделать продукт максимально удобным для пользователей и ввели излишне усложненные фичи: infinite scroll, optimistic calculation, online updates. С увеличением объема данных эти фичи начали работать медленнее.
Большое количество вычислений на стороне фронтенда. С увеличением количества пользовательских данных, их стало слишком много для отрисовки и обработки.
Один из самых популярных сценариев — пересчет длительности задачи согласно календарю пользователя. Когда пользователь собирается переместить задачу с одного дня на другой, мы должны отрисовать специальный плейсхолдер с предполагаемой длительностью задачи и указать день начала и конца. При этом календарь пользователя может быть совершенно произвольным: два через два, сокращенные дни, полставки и полдня. Все это нужно учитывать во время «таскания» задачи по Workload. А еще — добавление или удаление группировок, оно тоже производится на фронтенде.
Но это были только наши предположения — мы не знали, что происходит у пользователей. На тестовых аккаунтах все работало более-менее сносно, подтормаживало совсем немного.
План действий для решения проблемы
Чтобы разобраться, что происходит на самом деле, мы составили план действий на месяц.
Выглядел он так:
Понять, что происходит у клиентов.
Улучшить их жизнь за месяц с помощью быстрых фиксов.
Подумать над изменениями архитектуры, которые будут выполняться в среднесрочной и долгосрочной перспективе. Взять их в план.
Поменять архитектуру так, чтобы увеличение количества пользовательских данных не влияло на перфоманс компонента.
Как мы поняли, что все тормозит именно на стороне клиентов? Ведь Support-тикеты обычно очень лаконичны: там есть минимальное описание проблемы, несколько скриншотов и видео, если повезет.
По поводу каждой эскалации у клиентов были звонки с продакт-менеджерами, и мы стали туда ходить. Это было нужно, чтобы разобраться, что именно происходит у каждого клиента: какие у него данные в таблице, сколько этих данных, как они распределяются между основной таблицей и бэклогом.
На наших тестовых аккаунтах сложно предположить, что в своей таблице может придумать реальный пользователь. Например, один клиент с автосервисом разбивал техосмотр машины на маленькие подзадачи: заменить масло, выкрутить левую свечу, выкрутить правую свечу и так далее. У него было порядка десяти ТО каждый день, а каждый техосмотр — это сотня задач.
Чтобы получить объективную оценку о том, насколько сильно в действительности тормозит наше приложение, мы начали использовать систему Apdex — Application Performance Index.
Performance Tracking и система Apdex
Наверное, многие читатели знакомы с трекингом. Это то, что собирают аналитики. Например, пользователь нажимает на кнопку A — tracking event уходит в аналитику. Аналитики видят, что на кнопку А пользователь нажимает часто, а на кнопку B не нажимает совсем. Мы использовали такой трекинг, чтобы посмотреть, насколько долго выполняются пользовательские действия, фактически создав Performance Tracking.
Пока картинка пользователя статична — все хорошо. Но как только пользователь начинает что-то делать в таблице, он ждет, что действие выполнится за какой-то разумный промежуток времени. Если действие выполняется дольше — это фрустрирует пользователя.
Мы решили замерить эти действия и получить временные промежутки для каждого: первоначальная загрузка страницы, раскрытие проекта, движение задачи и т.д.
Для замера мы отправляли два трекинг ивента. Первый — в тот момент, когда пользователь выполнил действие:
{"event":"row__expand","datetime":"2021-05-01T17:40:43.758","group":"performance","value":{"workload_id":"81451","members_cnt":1,"zoom_level":"dayDense","tasks":6,"grouping":"jobRoleGrouping/user/project","performance_uuid":"972438e0-aa93-11eb-a8f9-557874958202","performance_timestamp":1619883643758,"performance_event_type":"start"},"version":"2021-03-12"}
Второй — когда действие, которое выполнил пользователь, закончило отрисовываться:
{"event":"row__expand","fraction":"1/1","datetime":"2021-05-01T17:40:43.953","group":"performance",,"value":{"performance_uuid":"972438e0-aa93-11eb-a8f9-557874958202","performance_timestamp":1619883643953,"performance_event_type":"finish"}
По разнице между метками мы можем понять, сколько времени выполняется каждое действие. В нашем примере получается: 1619883643953 - 1619883643758 = 195ms.
Возникает резонный вопрос: а 195 миллисекунд — это много или нормально? Ответить на него нам помогла система Apdex.
Методика Apdex — это открытый международный стандарт, разработанный с целью формирования объективной оценки показателей производительности информационных систем. Индекс — это число от 0 до 1: значение 1 означает, что приложение работает идеально, 0 — приложение не работает совсем.
Чтобы получить это число, нужно выполнить ряд действий:
Подготовить список операций, которые нужно отслеживать. Мы открыли Workload и начали думать о том, какие операции обычно совершают пользователи: поскроллить, кликнуть и отобразить tooltip с задачей, открыть бэклог.
Задать для каждой операции целевое время: какой промежуток считать хорошим, приемлемым и неприемлемым. Действия разные, поэтому для каждого нужно определить свой промежуток. Первоначальная загрузка может выполняться несколько секунд: это может удивить пользователя, но после открытия таблицы он забудет о том, что ему пришлось подождать две секунды. А если будет тормозить процесс движения задачи — это плохо, потому что такое действие пользователь выполняет часто. Для первоначальной загрузки хорошее и приемлемое время — 1-2 секунды, для движения задачи — 200-500 миллисекунды.
Разбить события по приоритетам: high, mid, low. Первоначальной загрузке, скорее всего, не стоит ставить высокий приоритет, потому что она выполняется один раз. А вот постоянные действия должны быть в высоком приоритете.
Включить счетчик замера производительности для всех операций из списка и накопить статистику.
Для каждой операции мы получили время ее выполнения, которое попадает в определенный промежуток.

Apdex считается по формуле:

Получившееся значение индекса оценивается по таблице:

Мы собрали статистику по нашим ивентам в Tableau:

Нам удалось выяснить, что индекс зависит от количества строк в Workload — количества пользователей, которые отображаются на странице:

Наша гипотеза подтвердилась: увеличение количества данных негативно влияет на скорость загрузки.
Как мы решаем проблему с перформансом: быстрые фиксы и долгосрочные планы
После того, как мы разобрались в причинах и нашли инструмент для оценки перформанса, мы перешли ко второму пункту плана — улучшить жизнь пользователей за месяц с помощью быстрых фиксов. Параллельно мы начали думать над среднесрочными и долгосрочными решениями, с помощью которых собирались поменять архитектуру.
К быстрым фиксам мы отнесли следующие попытки.
Оптимизировали количество вычислений. Мы предположили, что вычисления на фронтенде, которых очень много на разные действия пользователей, можно оптимизировать. Изначально с точки зрения вычислений все было написано достаточно грамотно: мы везде использовали кэширующие селекторы, ничего не пересчитывалось лишний раз, если это было не нужно. Мы мало что могли улучшить, но получилось ускорить в среднем на 10%. Но этого было недостаточно.
Изменили логику попадания задач в бэклог. Во время созвонов с клиентами мы заметили, что backlog box с тысячами задач вешает браузер. Тогда мы решили изменить логику попадания задач в бэклог.
Бэклог — это нижняя панель в Workload. Она отображает задачи, которые не назначены на исполнителей:
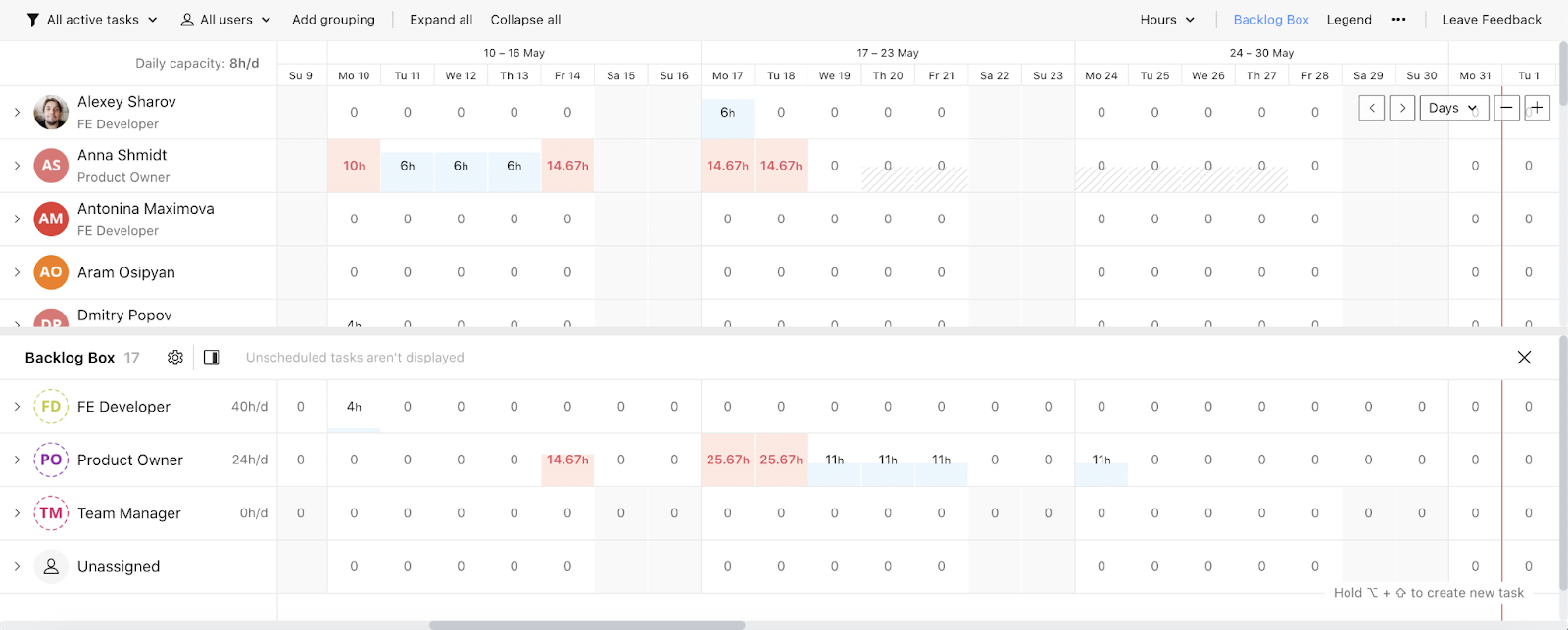
У некоторых пользователей с большими аккаунтами в бэклоге лежали две-три тысячи задач, в которых они сами путались. Так происходило, потому что во время создания компонента продакты посчитали, что в бэклоге должно лежать вообще все.
Тогда мы решили ограничить бэклог только теми задачами, которые находятся в рамках проекта. Это решение было удачным — стало гораздо меньше ненужной информации, и клиенты перестали путаться в тысячах задач. Мы получили хорошие отзывы об этом изменении.
Отключили отображение информации в таблице во время скролла (неудачно). При нескольких десятках пользователей и сотнях задач начинал сильно тормозить горизонтальный скролл. Мы используем не браузерный скролл, а собственный, потому что отслеживаем, вышел ли текущий скролл за пределы загруженного тайм-фрейма.
Мы решили провести эксперимент и отключили отображение информации на чарте в тот момент, когда пользователь начинает скроллить таблицу. Мы действительно очищали DOM от всех элементов и пользователи не видели ни дней, ни расписания, ни задач во время скролла, только шапку с днями недели.
Мы включили новую функциональность нескольким клиентам. Скорость загрузки значительно улучшилась, но клиентам не понравилось — оказалось, что им важно видеть задачи во время скролла. Эксперимент получился неудачным.
Отключили апдейты, приходящие в фоновом режиме (тоже получилось не очень). Дальше мы предположили, что на общую производительность на больших аккаунтах влияют постоянно приходящие в фоновом режиме апдейты, которые вызывают перерисовку. Мы в Wrike используем Wrike: у нас один из самых больших аккаунтов среди наших клиентов. Поэтому мы провели эксперимент на нашем аккаунте и подтвердили гипотезу.
Раскатывать на клиентов отключение онлайн-апдейтов мы не стали, потому что помнили про неудачный эксперимент с горизонтальным скроллом. Онлайн-апдейты очень важны для поддержания консистентности данных. Так как Workload относится к основным частям продукта, то пользователи обычно открывают его один раз во время начала рабочего дня, если вообще закрывали. Это значит, что информация может устареть, если не обновлять ее на лету: действия всех пользователей, которые отображаются в Workload, приводят к изменению картины о задачах. Отключить онлайн-апдейты было невозможно — это ключевая фича Workload.
Начали считать и отрисовывать только то, что видит пользователь. Мы поняли, что основная проблема кроется в количестве текущих элементов в DOM, которые нужно пересчитывать и перерисовывать. Тогда мы сделали максимально жесткую виртуализацию и начали отрисовывать и считать только то, что видит пользователь.
Нам удалось значительно уменьшить количество элементов на странице. Загружаться все стало в разы быстрее — скорость некоторых операций увеличилась в 100 раз.
Для среднесрочных и долгосрочных решений мы придумали два выхода:
Запрототипировали и запланировали перевод продукта с DOM на Canvas. Прототип показал, что на Canvas работать все будет значительно быстрее.
Запланировали уход от горизонтального Infinite scroll. Мы решили использовать обычный браузерный скролл и загружать данные по запросу. Когда пользователь упрется в границу загруженного time frame, то сможет подгрузить новые данные. Во многих похожих продуктах на рынке используется тот же механизм. Видимо, они что-то узнали раньше нас.
Эти два решения должны позволить нам на ближайшие год-два решить все проблемы с отрисовкой.
Результаты и вывод
После фиксов значение Apdex поменялось:

График индекса в зависимости от количества пользователей:

Поток эскалаций от клиентов прекратился: мы не получали ни одной жалобы с середины марта. Бизнес доволен, релизы разблокированы. Сейчас мы работаем над тем, чтобы имплементировать среднесрочные и долгосрочные решения.
Главный вывод, который мы сделали после этой ситуации — перформанс на первом месте. Банальная прописная истина: инженер должен следить за тем, чтобы не срезались углы. Если есть подозрения, что будет работать медленно, то задача инженеров — сигнализировать и говорить об этом бизнесу.
Надеемся, что наш кейс поможет кому-то из читателей избежать подобных проблем или быстрее найти способы их решения. Делитесь в комментариях своими историями о том, как у вас все стало плохо и как вы с этим справлялись.
