
Привет, меня зовут Борис. Я работаю в Яндексе в отделе тестирования и создаю инструменты, которые позволяют сделать жизнь наших тестировщиков проще и счастливее. Наша команда отчасти исследовательская, поэтому мы можем позволить себе использовать довольно необычные инструменты и эксперименты. Недавно я рассказал своим коллегам об одном из таких экспериментов: Gulp.js. Сегодня я хотел бы поделиться этим опытом с вами.
Для начала немного предыстории, о том, как развивались веб-технологии. В начале не было фронтенда как отдельного понятия, большая часть логики выполнялась на сервере. Поэтому разнообразные задачи по сборке скриптов и стилей, а также подготовка картинок, шрифтов и других ресурсов выполнялись бэкэндом, и их сборщиками, например, Apache Ant или Maven. Фронтенд оказывался в невыгодном положении, инструменты, предоставляемые этими сборщиками не очень подходили для него. Эту проблему начали решать только недавно, когда появился Grunt. Это первый сборщик, написанный на JS. Каждый фронтендер знает JavaScript, поэтому может без проблем писать задачи под Grunt и разбираться в уже написанных. Это и обусловило успех этого сборщика. У Grunt есть куча преимуществ, но есть и недостатки.
Например, вот так выглядит простейший Grunt-файл.
У нас есть задача, для ее выполнения используются плагины. Если нам нужно больше действий, мы подключаем больше плагинов. В результате мы получаем огромную простыню кода, в которой ничего нельзя найти. А поскольку Grunt-файл большой, то и сборка становится непозволительно долгой. И как это ускорить, совершенно непонятно, потому что в архитектуре Grunt не заложено никаких способов для этого.
Поэтому единственный выход — попытаться начать все с начала и зайти с другой стороны. Ну и для начала можно посмотреть, что уже есть полезного в окружающем мире. Например, есть UNIX shell. В ней есть полезное понятие — pipeline — направление выхлопа одного процесса на вход другого процесса, а он может отослать свой следующему и так далее по цепочке.
Таким образом, мы можем выстроить настоящий конвейер, который будет выполнять нашу сборку. Это же чертовски логично, выполнять сборку на конвейере. Это применимо и к задачам фронтенда. Однако если делать это на чистом шелле, могут возникнуть некоторые проблемы. Во-первых, не в каждой операционной системе есть shell, а во-вторых, у нас нет команд, которые, например, сделают преобразование coffee в JS.
Зато это может сделать Gulp. Эта утилита написана на JavaScript. Она использует тот же принцип, что и Shell-скрипт, но тут для пайпинга вместо вертикальной черты используется функция
Т.е. мы можем делать абсолютно то же самое, при этом понятно, что чем занимается, при необходимости можно менять блоки местами, удалять и вообще настраивать свой конвейер как угодно.
Gulp уже достаточно стабилен, развился до третьей версии и нашел своих поклонников. Устанавливается он нашим любимым способом:
Я решил протестировать его на одном из своих проектов и с удивлением обнаружил, что сборка с его помощью проходит немного быстрее, чем с Grunt. И сейчас я постараюсь объяснить, почему.
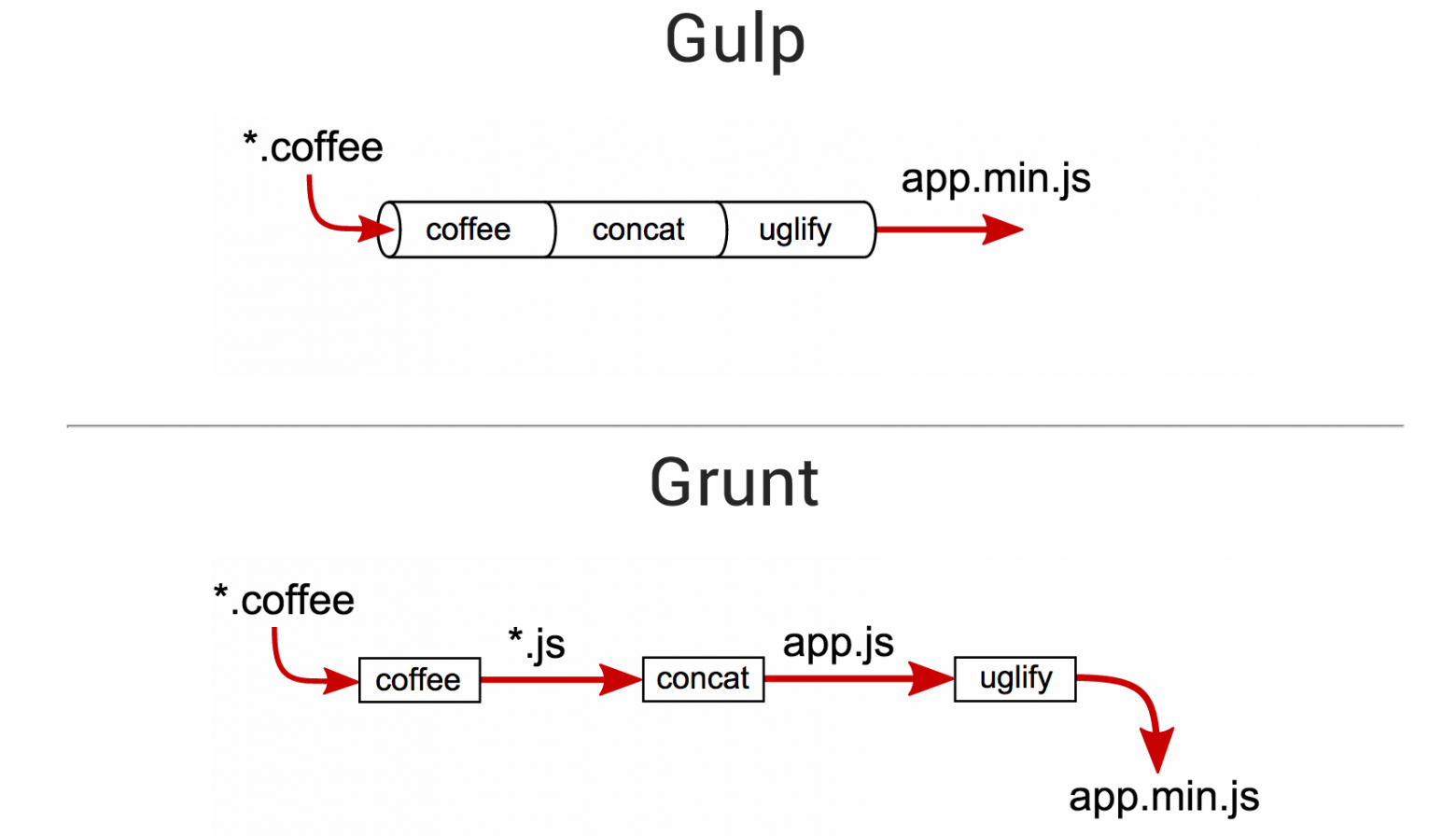
Все дело в том, что самая дорогая операция во время сборки — обращение к файловой системе: сборка происходит в процессоре, файловая система где-то далеко, к ней нужно ходить, и это занимает какое-то время. На схеме красными стрелками как раз отображены эти операции. Видно, что в Gulp их всего две (прочли на входе, записали на выходе), а в Grunt — четыре: каждый плагин читает и пишет. Ну а раз все работает быстрее, то почему бы не перейти на Gulp. Но для начала я решил все тщательно проверить. Я подготовил тест-кейс, в котором собираются и пакуются coffee-файлы и стили, описал эту задачу для Grunt и Gulp, запустил их по очереди и увидел, что прирост действительно есть, gulp быстрее примерно на четверть: 640 мс против 850. Также я подготовил еще один тест, чуть посложнее. В нем нам нужно еще слегка запрепроцессиить стили. Больше всего стилей, конечно, в бутстрапе. Попытаемся собрать его из исходных less-файлов, а затем, чтобы уменьшить его размер, пройдемся CSSO. В Gulp это делается довольно легко: есть плагин как для
Grunt-файл получается побольше.
В результате Gulp снова выиграл: 2 секунды против 2.3. Grunt потратил 300 миллисекунд на чтение и запись ненужных файлов.
Плагинов для Gulp не так много, как для Grunt, но тех 400, что есть, вполне достаточно для типичных задач. Ну а если вам чего-то все же не хватает, всегда можно написать свой. Основная идея Gulp — это потоки. Они уже есть в ядре node.js, для этого не нужно ничего подключать. Рассмотрим небольшой пример: плагин, который будет всех приветствовать. Мы ему слово, а он нам приветствие:
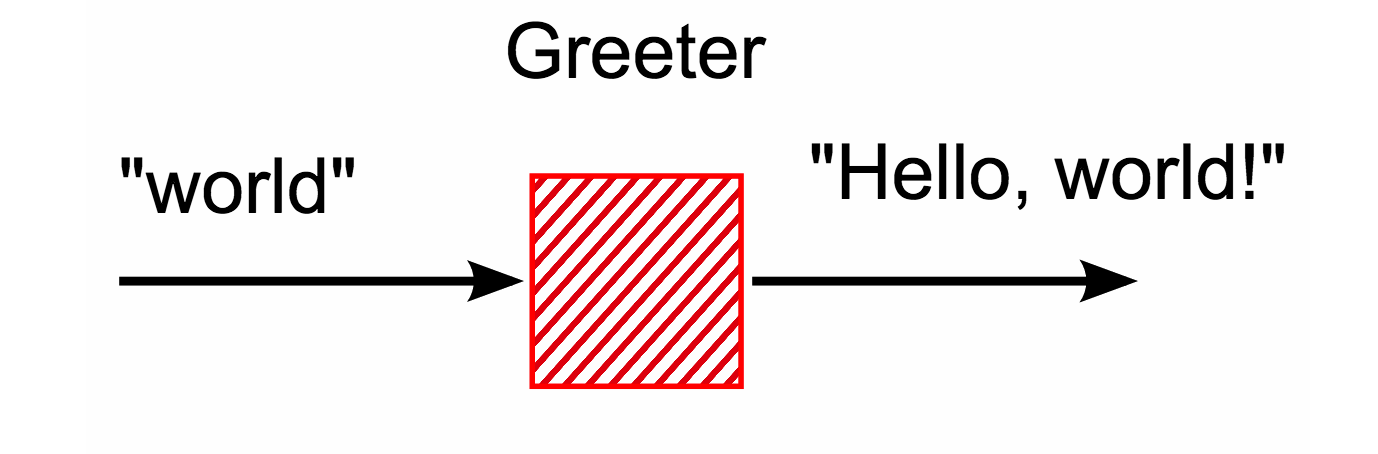
Вот так это будет выглядеть на JavaScript:
У нас есть готовый нативный объект, в котором мы должны определить метод
Этим занимается каждый плагин, например, gulp-freeze, написанный мной специально для для того, чтобы показать как это просто. Он предназначен для заморозки статики. В Gulp это все делается очень просто: у нас есть контент, мы вычисляем из него md5-хэш и говорим, что это имя файла. Потом мы записываем файл дальше в поток. Все, остальные операции Gulp сделает за нас: прочитает файлы, отдаст их нашему плагину, затем передаст дальше остальным плагинам и в конце концов запишет в файловую систему. А мы пишем только самое интересное, свой плагин.
А поскольку у нас нет ничего лишнего, то и тест получается довольно простым. Создадим тестовый поток, в который мы кладем фейковые данные, а файловой системой можем даже не пользоваться. Если мы пишем большой плагин, и для него будет настроен CI, например, Travis, то мы будем приятно удивлены скоростью билда. На все тестовые случаи можно сгенерировать виртуальные файлы, написать их в поток и слушать выход. Если на выходе правильные данные, все хорошо, тест пройден, если нет — у нас ошибка, идем ее исправлять.
Иногда даже необязательно писать плагин. Некоторые функции можно вставлять прямо в поток. Например, Gulp-плагина для шаблонизатора Yate пока никто не написал. Но мы можем вызвать его напрямую:
Есть и более экзотичные применения такой системы. Например, этим сборщиком можно заменить Jekyll. Допустим, у нас есть статьи в markdown, а мы из них собираем веб-страницы в HTML. Эта схема идеально ложится в идеологию Gulp, с его помощью можно собирать Jekyll-шаблоны. Для этого нужно просто прочитать наши посты, обработать их, возможно придется написать пару мелких плагинов, и в результате получить полноценный порт Jekyll на node.js. Очень удобно. Мне кажется, в Grunt сделать такое невозможно в принципе.
P.S. Доклад рассказывался весной 2014 года, за прошедшие полгода инструменты развивались, что-то могло измениться, но основная идея остается той же.
Для начала немного предыстории, о том, как развивались веб-технологии. В начале не было фронтенда как отдельного понятия, большая часть логики выполнялась на сервере. Поэтому разнообразные задачи по сборке скриптов и стилей, а также подготовка картинок, шрифтов и других ресурсов выполнялись бэкэндом, и их сборщиками, например, Apache Ant или Maven. Фронтенд оказывался в невыгодном положении, инструменты, предоставляемые этими сборщиками не очень подходили для него. Эту проблему начали решать только недавно, когда появился Grunt. Это первый сборщик, написанный на JS. Каждый фронтендер знает JavaScript, поэтому может без проблем писать задачи под Grunt и разбираться в уже написанных. Это и обусловило успех этого сборщика. У Grunt есть куча преимуществ, но есть и недостатки.
Например, вот так выглядит простейший Grunt-файл.
Gruntfile.js
module.exports = function (grunt) {
"use strict";
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
jshint: {
files: ['<%= pkg.name %>.js']
},
concat: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
main: {
src: ['<%= pkg.name %>.js'],
dest: 'build/<%= pkg.name %>.js'
}
},
uglify: {
main: {
src: 'build/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
}
});
grunt.loadTasks('tasks/');
grunt.registerTask('default', ['jshint', 'concat', 'uglify']);
return grunt;
};
У нас есть задача, для ее выполнения используются плагины. Если нам нужно больше действий, мы подключаем больше плагинов. В результате мы получаем огромную простыню кода, в которой ничего нельзя найти. А поскольку Grunt-файл большой, то и сборка становится непозволительно долгой. И как это ускорить, совершенно непонятно, потому что в архитектуре Grunt не заложено никаких способов для этого.
Gruntfile.js
module.exports = function (grunt) {
"use strict";
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
karma: {
options: {
configFile: 'karma.conf.js'
},
unit: {},
travis: {
browsers: ['Firefox']
}
},
jshint: {
files: ['<%= pkg.name %>.js']
},
concat: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
main: {
src: ['<%= pkg.name %>.js'],
dest: 'build/<%= pkg.name %>.js'
}
},
uglify: {
main: {
src: 'build/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
},
copy: {
main: {
expand: true,
cwd: 'docs/',
src: ['**', '!**/*.tpl.html'],
dest: 'build/'
}
},
buildcontrol: {
options: {
dir: 'build',
connectCommits: false,
commit: true,
push: true,
message: 'Built %sourceName% from commit %sourceCommit% on branch %sourceBranch%'
},
pages: {
options: {
remote: 'git@github.com:just-boris/angular-ymaps.git',
branch: 'gh-pages'
}
}
}
});
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-concat');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-karma');
grunt.loadNpmTasks('grunt-contrib-copy');
grunt.loadNpmTasks('grunt-build-control');
grunt.registerTask('test', 'Run tests on singleRun karma server', function() {
if (process.env.TRAVIS) {
//this task can be executed in Travis-CI
grunt.task.run('karma:travis');
} else {
grunt.task.run('karma:unit');
}
});
grunt.registerTask('build', ['jshint', 'test', 'concat', 'uglify']);
grunt.registerTask('default', ['build', 'demo']);
grunt.registerTask('build-gh', ['default', 'buildcontrol:pages']);
return grunt;
};
Поэтому единственный выход — попытаться начать все с начала и зайти с другой стороны. Ну и для начала можно посмотреть, что уже есть полезного в окружающем мире. Например, есть UNIX shell. В ней есть полезное понятие — pipeline — направление выхлопа одного процесса на вход другого процесса, а он может отослать свой следующему и так далее по цепочке.
$ cat *.coffee \
| coffee \
| concat \
| uglify \
> build/app.min.js
Таким образом, мы можем выстроить настоящий конвейер, который будет выполнять нашу сборку. Это же чертовски логично, выполнять сборку на конвейере. Это применимо и к задачам фронтенда. Однако если делать это на чистом шелле, могут возникнуть некоторые проблемы. Во-первых, не в каждой операционной системе есть shell, а во-вторых, у нас нет команд, которые, например, сделают преобразование coffee в JS.
Зато это может сделать Gulp. Эта утилита написана на JavaScript. Она использует тот же принцип, что и Shell-скрипт, но тут для пайпинга вместо вертикальной черты используется функция
pipe(). gulp.src('*.coffee')
.pipe(coffee())
.pipe(concat())
.pipe(uglify())
.pipe(gulp.dest('build/'))
Т.е. мы можем делать абсолютно то же самое, при этом понятно, что чем занимается, при необходимости можно менять блоки местами, удалять и вообще настраивать свой конвейер как угодно.
Gulp уже достаточно стабилен, развился до третьей версии и нашел своих поклонников. Устанавливается он нашим любимым способом:
npm install -g gulp
Я решил протестировать его на одном из своих проектов и с удивлением обнаружил, что сборка с его помощью проходит немного быстрее, чем с Grunt. И сейчас я постараюсь объяснить, почему.

Все дело в том, что самая дорогая операция во время сборки — обращение к файловой системе: сборка происходит в процессоре, файловая система где-то далеко, к ней нужно ходить, и это занимает какое-то время. На схеме красными стрелками как раз отображены эти операции. Видно, что в Gulp их всего две (прочли на входе, записали на выходе), а в Grunt — четыре: каждый плагин читает и пишет. Ну а раз все работает быстрее, то почему бы не перейти на Gulp. Но для начала я решил все тщательно проверить. Я подготовил тест-кейс, в котором собираются и пакуются coffee-файлы и стили, описал эту задачу для Grunt и Gulp, запустил их по очереди и увидел, что прирост действительно есть, gulp быстрее примерно на четверть: 640 мс против 850. Также я подготовил еще один тест, чуть посложнее. В нем нам нужно еще слегка запрепроцессиить стили. Больше всего стилей, конечно, в бутстрапе. Попытаемся собрать его из исходных less-файлов, а затем, чтобы уменьшить его размер, пройдемся CSSO. В Gulp это делается довольно легко: есть плагин как для
less, так и для csso. var gulp = require('gulp');
var csso = require('gulp-csso');
var less = require('gulp-less');
gulp.task('default', function() {
return gulp.src('bower_components/bootstrap/less/bootstrap.less')
.pipe(less())
.pipe(csso())
.pipe(gulp.dest('dest/'));
});
Grunt-файл получается побольше.
module.exports = function(grunt) {
require('time-grunt')(grunt);
grunt.loadNpmTasks('grunt-contrib-less');
grunt.loadNpmTasks('grunt-csso');
grunt.initConfig({
less: {
compile: {
src: 'bower_components/bootstrap/less/bootstrap.less',
dest: 'dest/bootstrap.css'
}
},
csso: {
compile: {
src: 'dest/bootstrap.css',
dest: 'dest/bootstrap.min.css'
}
}
});
grunt.registerTask('default', ['less', 'csso']);
};
В результате Gulp снова выиграл: 2 секунды против 2.3. Grunt потратил 300 миллисекунд на чтение и запись ненужных файлов.
Плагинов для Gulp не так много, как для Grunt, но тех 400, что есть, вполне достаточно для типичных задач. Ну а если вам чего-то все же не хватает, всегда можно написать свой. Основная идея Gulp — это потоки. Они уже есть в ядре node.js, для этого не нужно ничего подключать. Рассмотрим небольшой пример: плагин, который будет всех приветствовать. Мы ему слово, а он нам приветствие:
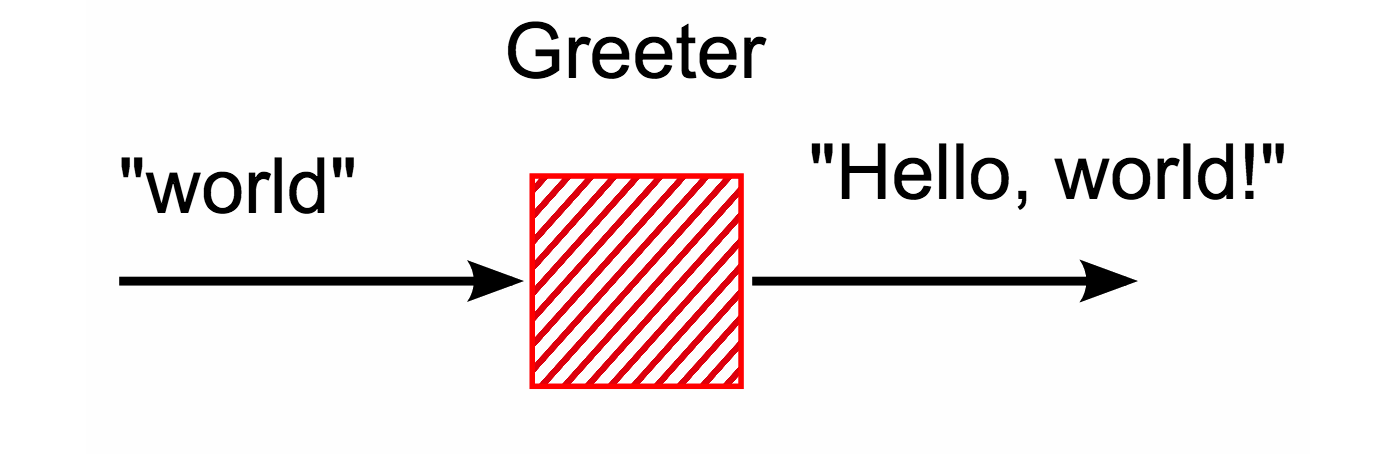
Вот так это будет выглядеть на JavaScript:
var stream = require('stream'),
greeterStream = new stream.Transform({objectMode: true});
greeterStream._transform = function(str) {
this.push('Hello, '+str+'!');
};
greeterStream.pipe(process.stdout)
greeterStream.write('world'); // Hello, world!
greeterStream.write('uncle Ben'); // Hello, uncle Ben!
У нас есть готовый нативный объект, в котором мы должны определить метод
_transform. Ему на вход подается строка, чтобы мы ее обработали и вернули. Мы в него пишем, а он преобразует. Ничего подключать не нужно, это нативный API node.js. Чтобы посмотреть, как как все это встраивается в Gulp, снимем с него крышку и заглянем внутрь. Там мы увидим два модуля: Orchestrator и Vinyl fs. Orchestrator дирижирует потоками, выстраивает их в очереди, старается выполнять их с максимальной параллельностью и вообще заботится, чтобы все работало как оркестр. С Vinyl все немного интереснее. Поток — это набор данных, а мы собираем файлы. Это нечто большее, чем просто данные, это еще имя, расширение и другие атрибуты. Хотелось бы как-то отдельно разделять непрерывный поток на отдельные файлы. Всем этим занимается Vinyl. По сути это обертка над файлами: мы получаем не просто данные, а объекты. Vinyl же проставляет туда все необходимые поля. Мы можем их модифицировать и управлять ими. var coffeeFile = new File({
cwd: "/",
base: "/test/",
path: "/test/file.coffee"
contents: new Buffer("test = 123")
});
Этим занимается каждый плагин, например, gulp-freeze, написанный мной специально для для того, чтобы показать как это просто. Он предназначен для заморозки статики. В Gulp это все делается очень просто: у нас есть контент, мы вычисляем из него md5-хэш и говорим, что это имя файла. Потом мы записываем файл дальше в поток. Все, остальные операции Gulp сделает за нас: прочитает файлы, отдаст их нашему плагину, затем передаст дальше остальным плагинам и в конце концов запишет в файловую систему. А мы пишем только самое интересное, свой плагин.
var through = require('through2');
module.exports = function() {
return through.obj(function(/**Vinyl*/file, enc, callback) {
var content = file.contents.toString('utf-8'),
checksum = createMD5(content),
file.path = checksum;
this.push(file);
callback();
});
};
А поскольку у нас нет ничего лишнего, то и тест получается довольно простым. Создадим тестовый поток, в который мы кладем фейковые данные, а файловой системой можем даже не пользоваться. Если мы пишем большой плагин, и для него будет настроен CI, например, Travis, то мы будем приятно удивлены скоростью билда. На все тестовые случаи можно сгенерировать виртуальные файлы, написать их в поток и слушать выход. Если на выходе правильные данные, все хорошо, тест пройден, если нет — у нас ошибка, идем ее исправлять.
var freeze = require('./index.js')
var testStream = freeze()
testStream.on('data', function(file) {
//assert here
});
testStream.write(fakeFile);
Иногда даже необязательно писать плагин. Некоторые функции можно вставлять прямо в поток. Например, Gulp-плагина для шаблонизатора Yate пока никто не написал. Но мы можем вызвать его напрямую:
var map = require('vinyl-map');
var yate = require('yate');
gulp.src('*.yate')
.pipe(map(function(code, filename) {
// здесь может быть любое ваше что угодно
return yate.compile(code.toString('utf-8')).js;
}))
.pipe(gulp.dest('dist/'))
Есть и более экзотичные применения такой системы. Например, этим сборщиком можно заменить Jekyll. Допустим, у нас есть статьи в markdown, а мы из них собираем веб-страницы в HTML. Эта схема идеально ложится в идеологию Gulp, с его помощью можно собирать Jekyll-шаблоны. Для этого нужно просто прочитать наши посты, обработать их, возможно придется написать пару мелких плагинов, и в результате получить полноценный порт Jekyll на node.js. Очень удобно. Мне кажется, в Grunt сделать такое невозможно в принципе.
gulp.task('jekyll', function() {
return gulp.src('_posts/**')
.pipe(liquid.collectMeta()) //собираем метаданные из постов
.pipe(post()) //генерируем ссылку на пост
.pipe(gulp.src('!_*/?*')) //добавляем остальные файлы
.pipe(markdown()) //конвертируем в html, если нужно
.pipe(liquid.template()) //шаблонизируем
.pipe(gulp.dest('_site/')); //записываем результат
});
P.S. Доклад рассказывался весной 2014 года, за прошедшие полгода инструменты развивались, что-то могло измениться, но основная идея остается той же.
