
Сегодня мы расскажем о новой поисковой технологии «Королёв», которая включает в себя не только более глубокое применение нейронных сетей для поиска по смыслу, а не по словам, но и значительные изменения в архитектуре самого индекса.

Но зачем вообще понадобились технологии из области искусственного интеллекта, если еще лет двадцать назад мы прекрасно находили в поиске искомое? Чем «Королёв» отличается от прошлогоднего алгоритма «Палех», где также использовались нейронные сети? И как архитектура индекса влияет на качество ранжирования? Специально для читателей Хабра мы ответим на все эти вопросы. И начнем с самого начала.
От частоты слов до нейронных сетей
Интернет на заре своего существования сильно отличался от своего текущего состояния. И дело было не только в количестве пользователей и вебмастеров. Прежде всего, сайтов по каждой отдельной теме было так мало, что первым поисковым сервисам было достаточно вывести список всех страниц, содержащих искомое слово. А даже если сайтов и было много, то достаточно было посчитать количество употреблений слова в тексте, а не заниматься сложным ранжированием. Никакого бизнеса в интернете еще не было, поэтому накруткой никто не занимался.
Со временем сайтов, как и желающих манипулировать выдачей, стало заметно больше. И поисковые компании столкнулись с необходимостью не только искать страницы, но и выбирать среди них наиболее релевантные запросу пользователя. Технологии на рубеже веков еще не позволяли «понимать» тексты страниц и сравнивать их с интересами пользователей, поэтому сначала было найдено более простое решение. Поиск начал учитывать ссылки между сайтами. Чем больше ссылок, тем авторитетнее ресурс. А когда и их перестало хватать, то начал учитывать поведение людей. И именно пользователи Поиска теперь во многом определяют его качество.
В какой-то момент всех этих факторов накопилось настолько много, что человек перестал справляться с написанием формул ранжирования. Конечно, мы все еще могли взять лучших разработчиков, и они написали бы более-менее работающий поисковый алгоритм, но машина справлялась лучше. Поэтому в 2009 году Яндекс внедряет собственный метод машинного обучения Матрикснет, который и по сей день строит формулу ранжирования с учетом всех доступных факторов. Мы долгое время мечтали добавить к этим фактором тот, который отражал бы релевантность страницы не через косвенные признаки (ссылки, поведение, ...), а «понимая» ее контент. И с помощью нейронных сетей нам это удалось.
В самом начале мы говорили о факторе, который учитывает частоту слов в тексте документа. Это крайне примитивный способ определения соответствия страницы запросу. Современные вычислительные мощности позволяют использовать для этого нейронные сети, которые справляются с анализом естественной информации (текст, звук, изображения) лучше, чем любой другой метод машинного обучения. Проще говоря, именно нейросети позволяют машине перейти от поиска по словам к поиску по смыслу. И именно это мы и начали делать в алгоритме «Палех» в прошлом году.
Запрос + Заголовок
Более подробно о «Палехе» написано здесь, но в этом посте мы еще раз кратко напомним об этом подходе, потому что именно «Палех» лежит в основе «Королёва».
У нас есть запрос человека и заголовок страницы, которая претендует на попадание в топ выдачи. Нужно понять, насколько они соответствуют друг другу по смыслу. Для этого мы представляем текст запроса и текст заголовка в виде таких векторов, скалярное произведение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы с помощью накопленной поисковой статистики обучаем нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие вектора, а для семантически несвязанных запросов и заголовков вектора должны различаться.
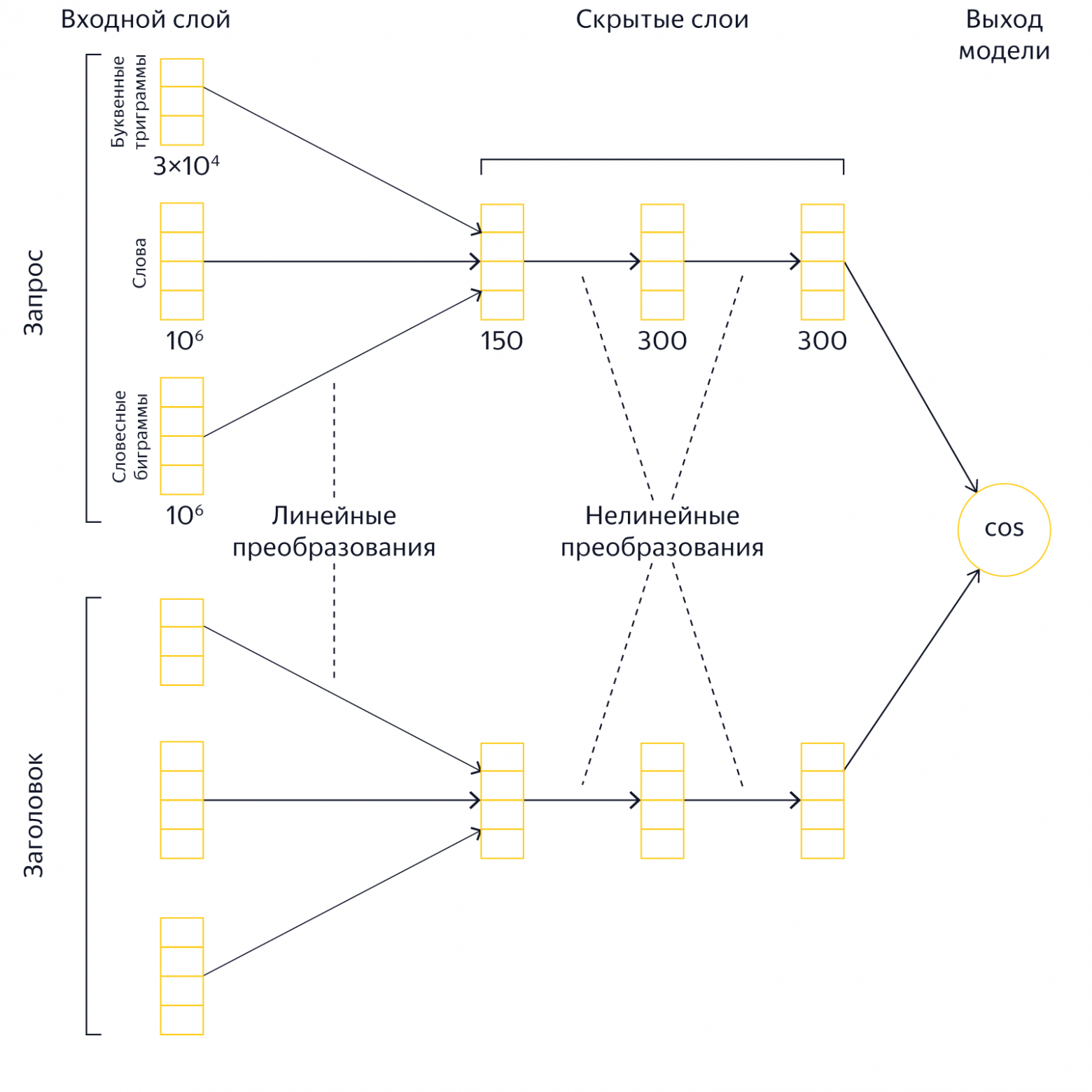
Как только человек вводит запрос в Яндексе, наши сервера в режиме реального времени преобразуют тексты в вектора и сравнивают их. Результаты этого сравнения используются поисковой машиной в качестве одного из факторов. Представляя текст запроса и текст заголовка страницы в виде семантических векторов, модель «Палеха» позволяет уловить достаточно сложные смысловые связи, которые иначе выявить трудно, что в свою очередь сказывается на качестве поиска.
«Палех» хорош, но у него был большой нереализованный потенциал. Но чтобы понять его, нам для начала нужно вспомнить о том, как именно устроен процесс ранжирования.
Стадии ранжирования
Поиск невероятно сложная штука: необходимо за доли секунды найти среди миллионов страниц наиболее релевантные запросу. Поэтому ранжирование в современных поисковых системах обычно осуществляется с помощью целого каскада ранкеров. Иными словами, поисковик использует нескольких стадий, на каждой из которых документы сортируются, после чего нижние документы отбрасываются, а верхушка, состоящая из лучших документов, передается на следующую стадию. На каждой последующей стадии применяются всё более тяжелые алгоритмы ранжирования. Это делается в первую очередь для экономии ресурсов поискового кластера: вычислительно тяжелые факторы и формулы вычисляются только для относительно небольшого количества лучших документов.
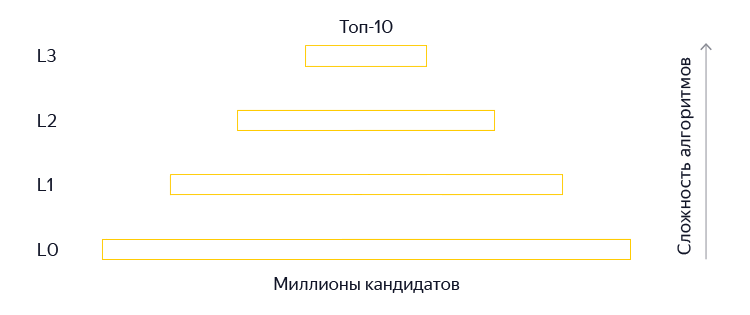
«Палех» – относительно тяжелый алгоритм. Нам нужно перемножить несколько матриц, чтобы получить вектора запроса и документа, а затем еще и их перемножить. Умножение матриц тратит драгоценное процессорное время, и мы не можем позволить себе выполнять эту операцию для слишком большого числа документов. Поэтому в «Палехе» мы применяли наши нейронные модели только на самых поздних стадиях ранжирования (L3) – приблизительно к 150 лучшим документам. С одной стороны, это неплохо. В большинстве случаев все документы, которые нужно показать в десятке, находятся где-то среди этих 150 документов, и нужно лишь правильно их отсортировать. С другой стороны, иногда хорошие документы все же теряются на ранних стадиях ранжирования и не попадают в топ. Это особенно характерно для сложных и низкочастотных запросов. Поэтому было очень заманчиво научиться использовать мощь нейросетевых моделей для ранжирования как можно большего числа документов. Но как это сделать?
Королёв: вычисления в обмен на память
Если нельзя сделать сложный алгоритм простым, то можно хотя бы перераспределить потребление ресурсов. И в данном случае мы можем выгодно обменять процессорное время на память. Вместо того, чтобы брать заголовок документа и во время исполнения запроса вычислять его семантический вектор, можно предвычислить этот вектор и сохранить его в поисковой базе. Другими словами, мы можем проделать существенную часть работы заранее, а именно — перемножить матрицы для документа и сохранить результат. Тогда во время выполнения запроса нам будет нужно только достать вектор документа из поискового индекса и выполнить скалярное умножение с вектором запроса. Это существенно быстрее, чем вычислять вектор динамически. Разумеется, при этом нам потребуется место для хранения предвычисленных векторов.
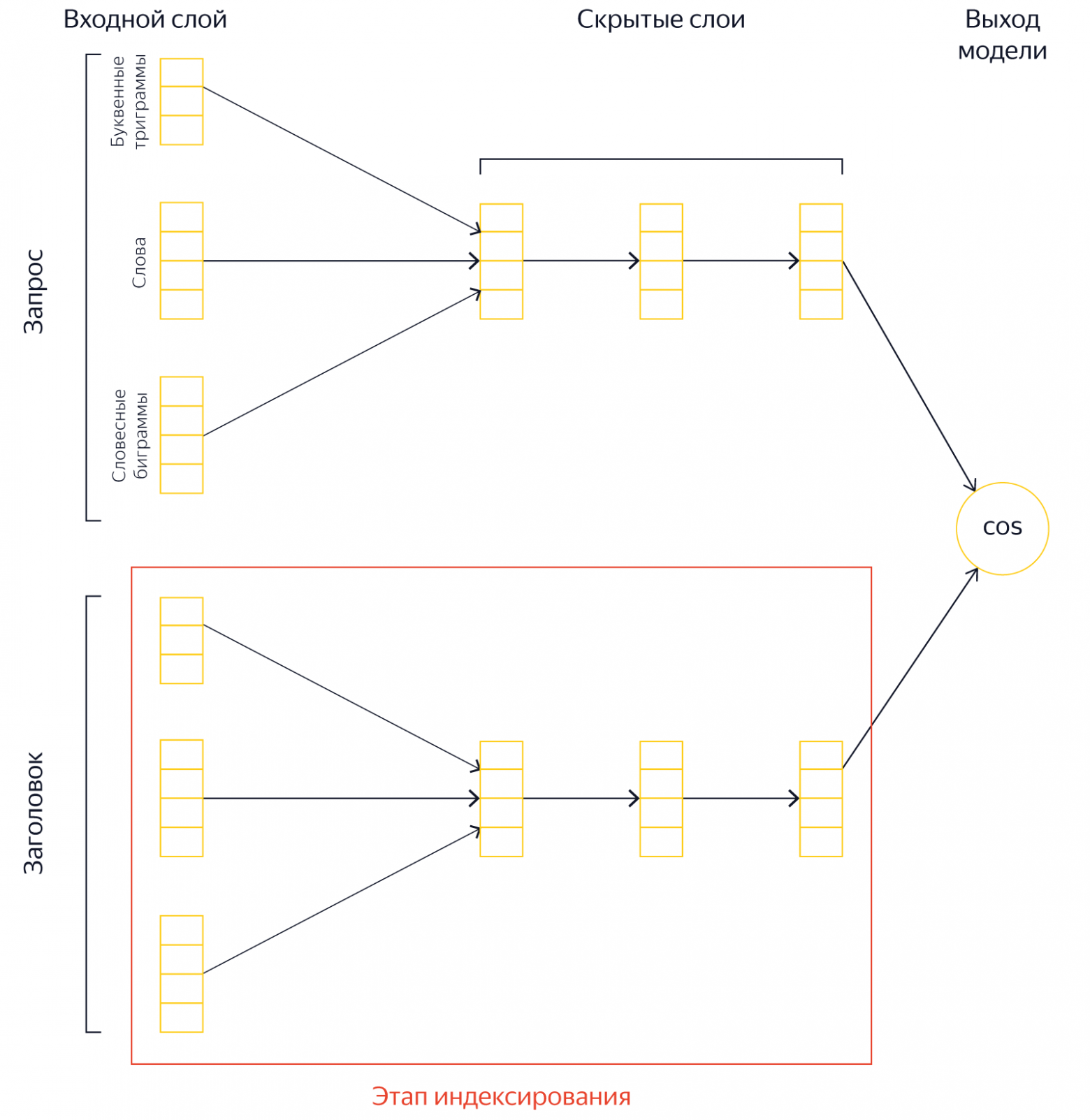
Подход на основе предвычисленных векторов позволил радикально увеличить глубину топа (L3, L2, L1), к которому применяются нейронные модели. Новые модели «Королёва» вычисляются на фантастическую глубину в 200 тыс. документов на запрос. Это позволило получить крайне полезный сигнал на ранних стадиях ранжирования.
Но и это еще не все. Успешный опыт предварительного вычисления векторов и их хранения в памяти расчистил перед нам дорогу к новой модели, о которой раньше мы могли только мечтать.
Королёв: запрос + документ
В «Палехе» на вход модели подавался только заголовок страницы. Обычно заголовок является важной частью документа, кратко описывающей его содержание. Тем не менее в теле страницы также содержится информация, которая чрезвычайно полезна для эффективного определения семантического соответствия документа запросу. Так почему же мы изначально ограничили себя заголовком? Дело в том, что на практике реализация полнотекстовых моделей сопряжена с рядом технических трудностей.
Во-первых, это дорого по памяти. Для применения нейронной модели к тексту во время выполнения запроса необходимо иметь этот текст «под рукой», то есть в оперативной памяти. И если положить в оперативку короткие тексты вроде заголовков было вполне реально на имеющихся в нашем распоряжении мощностях, то сделать это с полными текстами документов уже не получится.
Во-вторых, это дорого по CPU. Начальный этап расчета модели состоит в проецировании документа в первый скрытый слой нейронной модели. Для этого нам нужно сделать один проход по тексту. Фактически на данном этапе мы должны выполнить n*m умножений, где n – количество слов в документе, а m – размер первого слоя модели. Таким образом, количество процессорного времени, необходимого для применения модели, линейно зависит от длины текста. Это не проблема, когда речь идет о коротких заголовках. Но средняя длина тела документа существенно больше.
Всё это звучит так, будто внедрить модель с использованием полных текстов нельзя без радикального увеличения размера поискового кластера. Но мы обошлись без этого.
Ключом к решению проблемы стали те же самые предвычисленные вектора, которые мы уже испытали для модели на заголовках. На самом деле нам не нужен полный текст документа – достаточно хранить лишь относительно небольшой массив чисел с плавающей точкой. Мы можем взять полный текст документа на этапе его индексации, применить к нему череду операций, заключающихся в последовательном умножении нескольких матриц, и получить в результате веса в последнем внутреннем слое нашей нейронной модели. Причем размер слоя фиксирован и не зависит от размера документа. Более того, подобное перераспределение нагрузок с процессоров на память позволил нам по-новому взглянуть на архитектуру нейронной сети.
Королёв: архитектура слоев
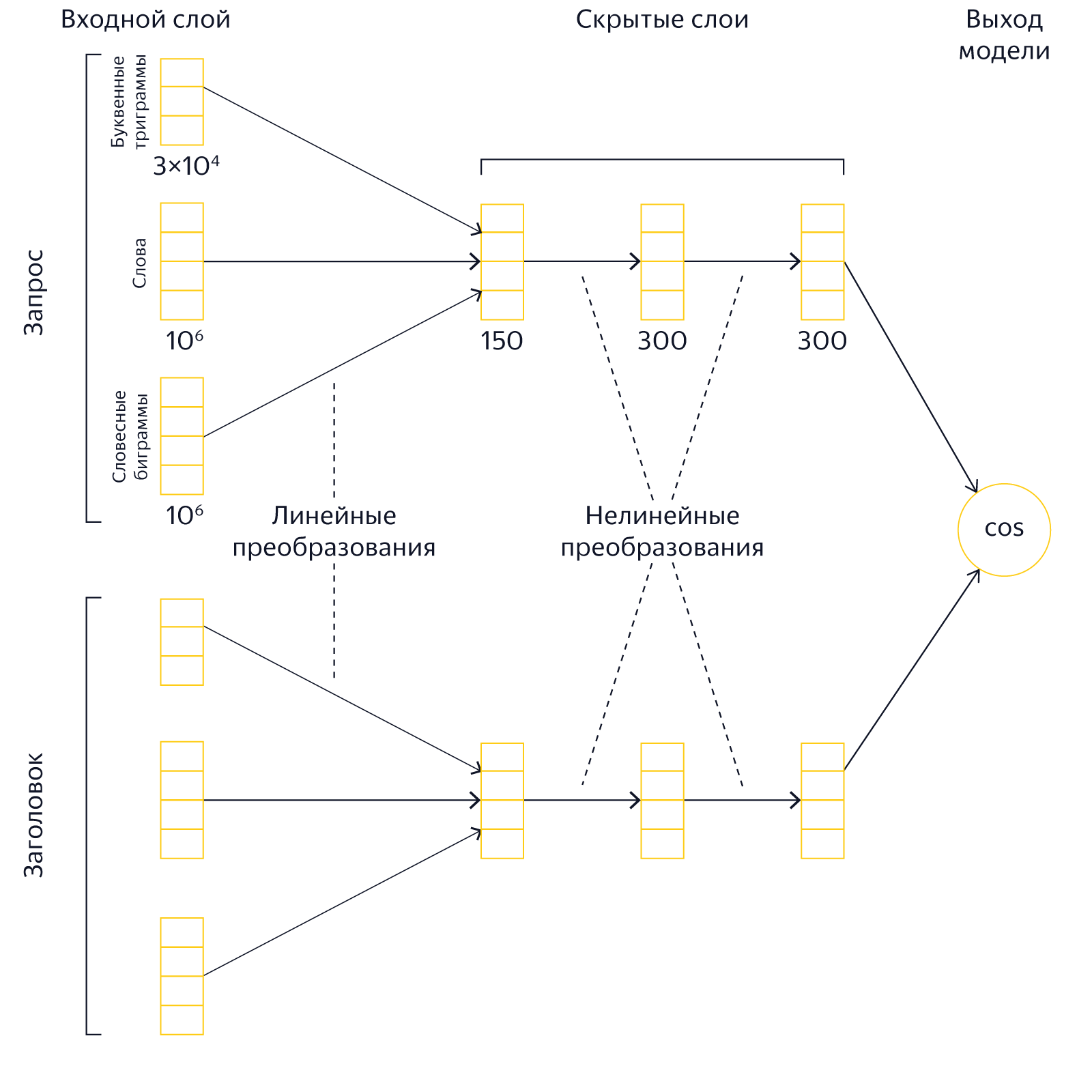
В старых моделях «Палеха» имелось 3 скрытых слоя размером на 150, 300 и 300 нейронов. Такая архитектура была обусловлена необходимостью экономии вычислительных ресурсов: перемножать большие матрицы во время выполнения запроса дорого. Кроме того, для хранения самой модели также требуется оперативная память. Особенно сильно размер модели зависит от размера первого скрытого слоя, поэтому в «Палехе» он был относительно небольшим — 150 нейронов. Уменьшение первого скрытого слоя позволяет существенно уменьшать размер модели, но при этом снижает её выразительную способность.
В новых же моделях «Королёва» узким местом является лишь размер последнего скрытого слоя. При использовании предвычисленных векторов ресурсы тратятся только на хранение последнего слоя в индексе и на его скалярное умножение на вектор запроса. Таким образом, разумным шагом было бы придать новым моделям более «клиновидную» форму, когда первые скрытые слои увеличиваются, а последний слой наоборот уменьшается. Эксперименты показали, что можно получить хороший выигрыш по качеству, если сделать размеры скрытых слоев равными 500, 500 и 40 нейронам. В результате увеличения первых внутренних слоев выразительная сила модели заметно возросла, тогда как последний слой можно уменьшать до пары десятков нейронов почти без просадки качества.
Тем не менее, несмотря на всю нашу оптимизацию, столь глубокое применение нейронных сетей в поиске требует значительных вычислительных мощностей. И кто знает, сколько бы еще потребовалось времени на внедрение, если бы не другой проект, который позволил высвободить ресурсы для их применения, хотя решали мы с его помощью совсем другую проблему.
Королёв: дополнительный индекс
Когда мы получаем пользовательский запрос, то среди миллионов страниц индекса начинаем поэтапно выбирать лучшие страницы. Начинается все со стадии L0, которая фактически является фильтрующей. На ней отфильтровывается большая часть нерелеватных документов, а основным ранжированием занимаются уже другие стадии.
В классической модели поиска мы решаем эту задачу с помощью инвертированных индексов. По каждому слову хранятся все документы, в которых оно встречается, а когда приходит запрос, пытаемся эти документы пересечь. Основная проблема – частотные слова. Слово «Россия», например, может встречаться на каждой десятой странице. В результате мы должны пройти каждый десятый документ, чтобы не потерять ничего нужного. Но с другой стороны нас ждет пользователь, который только что ввел свой запрос и ожидает увидеть ответ в то же мгновение, поэтому фильтрующий этап жестко ограничен по времени. Мы не могли себе позволить обойти все документы для частотных слов и использовали разные эвристики: сортировали документы по некоторому значению индифферентной запросу релевантности или прекращали поиск, когда нам казалось, что нашлось достаточное количество хороших документов. В целом такой подход работал хорошо, но иногда терялись полезные документы.
С новым подходом все иначе. В его основе лежит гипотеза: если к запросу из нескольких слов взять не очень большой список из самых релевантных документов по каждому слову или словосочетанию, то среди них найдутся документы, релевантные одновременно всем словам. На практике это значит вот что. Для всех слов и популярных пар слов формируется дополнительный индекс со списком страниц и их предварительной релевантностью запросу. То есть мы выносим часть работы из этапа L0 на этап индексирования. Что нам это дает?
Жесткие ограничения вычислений по времени связаны с простым фактом – нельзя заставлять пользователя ждать. Но если эти вычисления можно произвести заранее и в офлайне (т.е. не в момент ввода запроса), то таких ограничений уже нет. Мы можем позволить машине обойти все документы из индекса, и ни одна страница не будет потеряна.
Полнота поиска – это важно. Но не менее важен тот факт, что ценой потребления оперативной памяти мы значительно разгрузили момент построения выдачи, высвободив вычислительные ресурсы для тяжелых нейросетевых моделей запрос+заголовок и запрос+документ. И не только для них.
Королёв: запрос + запрос
Когда мы начинали работать над новым поиском, у нас ещё не было уверенности в том, какое направление окажется наиболее перспективным. Поэтому мы выделили для исследований нейронных моделей две команды. До некоторых пор они работали независимо, развивая свои собственные идеи, и даже до некоторой степени конкурировали между собой. Одна из них работала над подходом с запросом и документом, о котором мы уже рассказали выше. Вторая же команда подошла к проблеме совсем с другой стороны.
Для любой страницы в интернете можно придумать более одного запроса. Тот же «ВКонтакте» можно искать с помощью запросов [вконтакте], [вконтакте вход] или [вконтакте социальная сеть]. Запросы разные, а смысл, который скрывается за ними, один. И это можно использовать. Коллеги из второй команды придумали сравнивать семантические вектора запроса, который только что ввел пользователь, и другого запроса, для которого мы точно знаем лучший ответ. И если вектора (а значит, смыслы запросов) оказываются достаточно близки, то и результаты поиска должны быть схожи.
В итоге оказалось, что оба подхода дают хорошие результаты, и наши команды объединили усилия. Это позволило достаточно быстро завершить исследования и внедрить новые модели в поиске Яндекса. К примеру, если сейчас ввести запрос [ленивая кошка из монголии], то именно нейронные сети помогают вытащить в топ информацию о мануле.
Что дальше?
«Королёв» – это не одна конкретно взятая модель, а целый комплект технологий более глубокого применения нейронных сетей в поиске Яндекса. Это еще один важный шаг в сторону будущего, в котором Поиск будет ориентироваться на семантическое соответствие запросов и страниц не хуже, чем человек. Или даже лучше.
Все вышеописанное уже работает, а некоторые другие идеи ждут своего часа. К примеру, мы бы хотели попробовать применить нейросети на стадии поиска L0, чтобы семантические вектора помогали нам находить документы, близкие по смыслу к запросу, но вовсе не содержащие слов запроса. Еще мы хотели добавить персонализацию (представьте себе еще один вектор, который будет соответствовать интересам человека). Но на все это требуется не только время и знания, но и память и вычислительные ресурсы, и здесь без нового дата-центра не обойтись. И у Яндекса такой уже есть. Но это уже другая история, о которой мы обязательно расскажем в ближайшем будущем. Следите за публикациями.

Но зачем вообще понадобились технологии из области искусственного интеллекта, если еще лет двадцать назад мы прекрасно находили в поиске искомое? Чем «Королёв» отличается от прошлогоднего алгоритма «Палех», где также использовались нейронные сети? И как архитектура индекса влияет на качество ранжирования? Специально для читателей Хабра мы ответим на все эти вопросы. И начнем с самого начала.
От частоты слов до нейронных сетей
Интернет на заре своего существования сильно отличался от своего текущего состояния. И дело было не только в количестве пользователей и вебмастеров. Прежде всего, сайтов по каждой отдельной теме было так мало, что первым поисковым сервисам было достаточно вывести список всех страниц, содержащих искомое слово. А даже если сайтов и было много, то достаточно было посчитать количество употреблений слова в тексте, а не заниматься сложным ранжированием. Никакого бизнеса в интернете еще не было, поэтому накруткой никто не занимался.
Со временем сайтов, как и желающих манипулировать выдачей, стало заметно больше. И поисковые компании столкнулись с необходимостью не только искать страницы, но и выбирать среди них наиболее релевантные запросу пользователя. Технологии на рубеже веков еще не позволяли «понимать» тексты страниц и сравнивать их с интересами пользователей, поэтому сначала было найдено более простое решение. Поиск начал учитывать ссылки между сайтами. Чем больше ссылок, тем авторитетнее ресурс. А когда и их перестало хватать, то начал учитывать поведение людей. И именно пользователи Поиска теперь во многом определяют его качество.
В какой-то момент всех этих факторов накопилось настолько много, что человек перестал справляться с написанием формул ранжирования. Конечно, мы все еще могли взять лучших разработчиков, и они написали бы более-менее работающий поисковый алгоритм, но машина справлялась лучше. Поэтому в 2009 году Яндекс внедряет собственный метод машинного обучения Матрикснет, который и по сей день строит формулу ранжирования с учетом всех доступных факторов. Мы долгое время мечтали добавить к этим фактором тот, который отражал бы релевантность страницы не через косвенные признаки (ссылки, поведение, ...), а «понимая» ее контент. И с помощью нейронных сетей нам это удалось.
В самом начале мы говорили о факторе, который учитывает частоту слов в тексте документа. Это крайне примитивный способ определения соответствия страницы запросу. Современные вычислительные мощности позволяют использовать для этого нейронные сети, которые справляются с анализом естественной информации (текст, звук, изображения) лучше, чем любой другой метод машинного обучения. Проще говоря, именно нейросети позволяют машине перейти от поиска по словам к поиску по смыслу. И именно это мы и начали делать в алгоритме «Палех» в прошлом году.
Запрос + Заголовок
Более подробно о «Палехе» написано здесь, но в этом посте мы еще раз кратко напомним об этом подходе, потому что именно «Палех» лежит в основе «Королёва».
У нас есть запрос человека и заголовок страницы, которая претендует на попадание в топ выдачи. Нужно понять, насколько они соответствуют друг другу по смыслу. Для этого мы представляем текст запроса и текст заголовка в виде таких векторов, скалярное произведение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы с помощью накопленной поисковой статистики обучаем нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие вектора, а для семантически несвязанных запросов и заголовков вектора должны различаться.
Как только человек вводит запрос в Яндексе, наши сервера в режиме реального времени преобразуют тексты в вектора и сравнивают их. Результаты этого сравнения используются поисковой машиной в качестве одного из факторов. Представляя текст запроса и текст заголовка страницы в виде семантических векторов, модель «Палеха» позволяет уловить достаточно сложные смысловые связи, которые иначе выявить трудно, что в свою очередь сказывается на качестве поиска.
«Палех» хорош, но у него был большой нереализованный потенциал. Но чтобы понять его, нам для начала нужно вспомнить о том, как именно устроен процесс ранжирования.
Стадии ранжирования
Поиск невероятно сложная штука: необходимо за доли секунды найти среди миллионов страниц наиболее релевантные запросу. Поэтому ранжирование в современных поисковых системах обычно осуществляется с помощью целого каскада ранкеров. Иными словами, поисковик использует нескольких стадий, на каждой из которых документы сортируются, после чего нижние документы отбрасываются, а верхушка, состоящая из лучших документов, передается на следующую стадию. На каждой последующей стадии применяются всё более тяжелые алгоритмы ранжирования. Это делается в первую очередь для экономии ресурсов поискового кластера: вычислительно тяжелые факторы и формулы вычисляются только для относительно небольшого количества лучших документов.

«Палех» – относительно тяжелый алгоритм. Нам нужно перемножить несколько матриц, чтобы получить вектора запроса и документа, а затем еще и их перемножить. Умножение матриц тратит драгоценное процессорное время, и мы не можем позволить себе выполнять эту операцию для слишком большого числа документов. Поэтому в «Палехе» мы применяли наши нейронные модели только на самых поздних стадиях ранжирования (L3) – приблизительно к 150 лучшим документам. С одной стороны, это неплохо. В большинстве случаев все документы, которые нужно показать в десятке, находятся где-то среди этих 150 документов, и нужно лишь правильно их отсортировать. С другой стороны, иногда хорошие документы все же теряются на ранних стадиях ранжирования и не попадают в топ. Это особенно характерно для сложных и низкочастотных запросов. Поэтому было очень заманчиво научиться использовать мощь нейросетевых моделей для ранжирования как можно большего числа документов. Но как это сделать?
Королёв: вычисления в обмен на память
Если нельзя сделать сложный алгоритм простым, то можно хотя бы перераспределить потребление ресурсов. И в данном случае мы можем выгодно обменять процессорное время на память. Вместо того, чтобы брать заголовок документа и во время исполнения запроса вычислять его семантический вектор, можно предвычислить этот вектор и сохранить его в поисковой базе. Другими словами, мы можем проделать существенную часть работы заранее, а именно — перемножить матрицы для документа и сохранить результат. Тогда во время выполнения запроса нам будет нужно только достать вектор документа из поискового индекса и выполнить скалярное умножение с вектором запроса. Это существенно быстрее, чем вычислять вектор динамически. Разумеется, при этом нам потребуется место для хранения предвычисленных векторов.

Подход на основе предвычисленных векторов позволил радикально увеличить глубину топа (L3, L2, L1), к которому применяются нейронные модели. Новые модели «Королёва» вычисляются на фантастическую глубину в 200 тыс. документов на запрос. Это позволило получить крайне полезный сигнал на ранних стадиях ранжирования.
Но и это еще не все. Успешный опыт предварительного вычисления векторов и их хранения в памяти расчистил перед нам дорогу к новой модели, о которой раньше мы могли только мечтать.
Королёв: запрос + документ
В «Палехе» на вход модели подавался только заголовок страницы. Обычно заголовок является важной частью документа, кратко описывающей его содержание. Тем не менее в теле страницы также содержится информация, которая чрезвычайно полезна для эффективного определения семантического соответствия документа запросу. Так почему же мы изначально ограничили себя заголовком? Дело в том, что на практике реализация полнотекстовых моделей сопряжена с рядом технических трудностей.
Во-первых, это дорого по памяти. Для применения нейронной модели к тексту во время выполнения запроса необходимо иметь этот текст «под рукой», то есть в оперативной памяти. И если положить в оперативку короткие тексты вроде заголовков было вполне реально на имеющихся в нашем распоряжении мощностях, то сделать это с полными текстами документов уже не получится.
Во-вторых, это дорого по CPU. Начальный этап расчета модели состоит в проецировании документа в первый скрытый слой нейронной модели. Для этого нам нужно сделать один проход по тексту. Фактически на данном этапе мы должны выполнить n*m умножений, где n – количество слов в документе, а m – размер первого слоя модели. Таким образом, количество процессорного времени, необходимого для применения модели, линейно зависит от длины текста. Это не проблема, когда речь идет о коротких заголовках. Но средняя длина тела документа существенно больше.
Всё это звучит так, будто внедрить модель с использованием полных текстов нельзя без радикального увеличения размера поискового кластера. Но мы обошлись без этого.
Ключом к решению проблемы стали те же самые предвычисленные вектора, которые мы уже испытали для модели на заголовках. На самом деле нам не нужен полный текст документа – достаточно хранить лишь относительно небольшой массив чисел с плавающей точкой. Мы можем взять полный текст документа на этапе его индексации, применить к нему череду операций, заключающихся в последовательном умножении нескольких матриц, и получить в результате веса в последнем внутреннем слое нашей нейронной модели. Причем размер слоя фиксирован и не зависит от размера документа. Более того, подобное перераспределение нагрузок с процессоров на память позволил нам по-новому взглянуть на архитектуру нейронной сети.
Королёв: архитектура слоев
В старых моделях «Палеха» имелось 3 скрытых слоя размером на 150, 300 и 300 нейронов. Такая архитектура была обусловлена необходимостью экономии вычислительных ресурсов: перемножать большие матрицы во время выполнения запроса дорого. Кроме того, для хранения самой модели также требуется оперативная память. Особенно сильно размер модели зависит от размера первого скрытого слоя, поэтому в «Палехе» он был относительно небольшим — 150 нейронов. Уменьшение первого скрытого слоя позволяет существенно уменьшать размер модели, но при этом снижает её выразительную способность.
В новых же моделях «Королёва» узким местом является лишь размер последнего скрытого слоя. При использовании предвычисленных векторов ресурсы тратятся только на хранение последнего слоя в индексе и на его скалярное умножение на вектор запроса. Таким образом, разумным шагом было бы придать новым моделям более «клиновидную» форму, когда первые скрытые слои увеличиваются, а последний слой наоборот уменьшается. Эксперименты показали, что можно получить хороший выигрыш по качеству, если сделать размеры скрытых слоев равными 500, 500 и 40 нейронам. В результате увеличения первых внутренних слоев выразительная сила модели заметно возросла, тогда как последний слой можно уменьшать до пары десятков нейронов почти без просадки качества.
Тем не менее, несмотря на всю нашу оптимизацию, столь глубокое применение нейронных сетей в поиске требует значительных вычислительных мощностей. И кто знает, сколько бы еще потребовалось времени на внедрение, если бы не другой проект, который позволил высвободить ресурсы для их применения, хотя решали мы с его помощью совсем другую проблему.
Королёв: дополнительный индекс
Когда мы получаем пользовательский запрос, то среди миллионов страниц индекса начинаем поэтапно выбирать лучшие страницы. Начинается все со стадии L0, которая фактически является фильтрующей. На ней отфильтровывается большая часть нерелеватных документов, а основным ранжированием занимаются уже другие стадии.
В классической модели поиска мы решаем эту задачу с помощью инвертированных индексов. По каждому слову хранятся все документы, в которых оно встречается, а когда приходит запрос, пытаемся эти документы пересечь. Основная проблема – частотные слова. Слово «Россия», например, может встречаться на каждой десятой странице. В результате мы должны пройти каждый десятый документ, чтобы не потерять ничего нужного. Но с другой стороны нас ждет пользователь, который только что ввел свой запрос и ожидает увидеть ответ в то же мгновение, поэтому фильтрующий этап жестко ограничен по времени. Мы не могли себе позволить обойти все документы для частотных слов и использовали разные эвристики: сортировали документы по некоторому значению индифферентной запросу релевантности или прекращали поиск, когда нам казалось, что нашлось достаточное количество хороших документов. В целом такой подход работал хорошо, но иногда терялись полезные документы.
С новым подходом все иначе. В его основе лежит гипотеза: если к запросу из нескольких слов взять не очень большой список из самых релевантных документов по каждому слову или словосочетанию, то среди них найдутся документы, релевантные одновременно всем словам. На практике это значит вот что. Для всех слов и популярных пар слов формируется дополнительный индекс со списком страниц и их предварительной релевантностью запросу. То есть мы выносим часть работы из этапа L0 на этап индексирования. Что нам это дает?
Жесткие ограничения вычислений по времени связаны с простым фактом – нельзя заставлять пользователя ждать. Но если эти вычисления можно произвести заранее и в офлайне (т.е. не в момент ввода запроса), то таких ограничений уже нет. Мы можем позволить машине обойти все документы из индекса, и ни одна страница не будет потеряна.
Полнота поиска – это важно. Но не менее важен тот факт, что ценой потребления оперативной памяти мы значительно разгрузили момент построения выдачи, высвободив вычислительные ресурсы для тяжелых нейросетевых моделей запрос+заголовок и запрос+документ. И не только для них.
Королёв: запрос + запрос
Когда мы начинали работать над новым поиском, у нас ещё не было уверенности в том, какое направление окажется наиболее перспективным. Поэтому мы выделили для исследований нейронных моделей две команды. До некоторых пор они работали независимо, развивая свои собственные идеи, и даже до некоторой степени конкурировали между собой. Одна из них работала над подходом с запросом и документом, о котором мы уже рассказали выше. Вторая же команда подошла к проблеме совсем с другой стороны.
Для любой страницы в интернете можно придумать более одного запроса. Тот же «ВКонтакте» можно искать с помощью запросов [вконтакте], [вконтакте вход] или [вконтакте социальная сеть]. Запросы разные, а смысл, который скрывается за ними, один. И это можно использовать. Коллеги из второй команды придумали сравнивать семантические вектора запроса, который только что ввел пользователь, и другого запроса, для которого мы точно знаем лучший ответ. И если вектора (а значит, смыслы запросов) оказываются достаточно близки, то и результаты поиска должны быть схожи.
В итоге оказалось, что оба подхода дают хорошие результаты, и наши команды объединили усилия. Это позволило достаточно быстро завершить исследования и внедрить новые модели в поиске Яндекса. К примеру, если сейчас ввести запрос [ленивая кошка из монголии], то именно нейронные сети помогают вытащить в топ информацию о мануле.
Что дальше?
«Королёв» – это не одна конкретно взятая модель, а целый комплект технологий более глубокого применения нейронных сетей в поиске Яндекса. Это еще один важный шаг в сторону будущего, в котором Поиск будет ориентироваться на семантическое соответствие запросов и страниц не хуже, чем человек. Или даже лучше.
Все вышеописанное уже работает, а некоторые другие идеи ждут своего часа. К примеру, мы бы хотели попробовать применить нейросети на стадии поиска L0, чтобы семантические вектора помогали нам находить документы, близкие по смыслу к запросу, но вовсе не содержащие слов запроса. Еще мы хотели добавить персонализацию (представьте себе еще один вектор, который будет соответствовать интересам человека). Но на все это требуется не только время и знания, но и память и вычислительные ресурсы, и здесь без нового дата-центра не обойтись. И у Яндекса такой уже есть. Но это уже другая история, о которой мы обязательно расскажем в ближайшем будущем. Следите за публикациями.
