
Ускорить доставку элементов фронтенда на устройство пользователя можно несколькими способами. Разработчик Артём Белов из самарского офиса норвежской компании Cxense попробовал самые многообещающие: HTTP/2, Server Push, Service Worker, а также оптимизацию в процессе сборки и на стороне клиента. Итак, что же нужно сделать, чтобы сократить время отклика приложения до минимума?
— Всем привет. Спасибо, что пришли. Я хочу рассказать историю про то, как у нас получилось сделать фронтенд «быстрорастворимым».
Для начала представлюсь, чтобы хоть как-то поднять доверие к себе в столь опасной теме. Я фронтендер из норвежской компании Cxense. Никто толком не может произнести название корректно. Хорошо, что через семь лет после основания выпустили видео о том, как правильно произносить Cxense. «Си-сэнс».
Мы доставляем людям то, что они хотят, по следующим срезам: рекламе и статьям. Вот у бэкенда получается доставлять данные быстро. Неудивительно, у бэкендеров из норвежского офиса Линус Торвальдс был одноклассником. А вот мы на их фоне как-то… Проблема зародилась примерно так: мы не можем доставлять фронтенд быстро.
Когда я слышал споры про то, как должен «доставляться» фронтенд, как нужно его грузить и ускорять, мне это напомнило статью уважаемого человека, 61 параграф — «Краткий самоучитель по быстрорастворимому креативу» для дизайнеров.

Там были описаны примеры про то, как дизайнер думает, а вообще-то надо сделать по-другому. И во фронтенде порой нужно выходить за рамки. Вы сами можете поймать себя на мысли, что порой народ думает совсем не в том направлении и все упирается в микрооптимизации.
Отлично, мы тоже серьезные ребята и начали путь оптимизации по следующему списку:

Мы установили source-map-explorer. Мы настолько хипстеры, что используем bundle-buddy, выпущенный месяц назад. Проанализировали бандл и убрали дубликаты. Поняли, что приложение должно быть одним бандлом, а его необходимо разбить на чанки, и еще загружать только при переходе на необходимую страницу. Установили расширение import-cost, чтобы знать? в каком размере мы подгружаем зависимости в VS Code. Установили динамические импорты, нашли им одно применение в коде. Но вот как-то грустно на душе, а тут еще и осень… И все, что ты хочешь, это идти домой.
А потом прийти в офис и сказать дефолтную фразу: «Ребята, помогите мне переписать фронтенд!».
Но вот незадача. Фраза «давайте перепишем на React» была озвучена два года назад и переписывать больше нечего. Отсюда и начинается моя нехитрая история.
Про что я вам расскажу?

Часть любой успешной презентации — графики, но их тут не будет. Я буду использовать цифры. Есть серьезное, хорошее, двухгодичной выдержки приложение, и его изначальная скорость после ранее упомянутых оптимизаций — 100%. Все результаты, о которых я буду говорить, были проверены следующим CLI-иструментом от проект-менеджера.

Pwmetrics. Его сделал Пол Айриш — пожалуй, самый уважаемый проект-менеджер на этой планете. Учитывая, что это легко встраивается в CI, и я не боюсь vim, я просто перезагружаю компьютер…
Pwmetrics очень быстрый и за считанные секунды дает мне четыре главные метрики: время до интерактива, когда наконец-то наши клики не «проглатываются», speed index от Google, видимую прокраску и полную прокраску приложения.

Почему не Lighthouse? Потому что я настолько стар, как и вы, что использовал его, еще когда он был долгий и не встроен в таб audits. Поехали!
Началось все с того, что благодаря агрессивным намекам от Google мы перешли на HTTPS. Конечно, это было еще очень здорово подано такими вещами, как certbot. Теперь мы покупаем SSL-сертификат не за 7 долларов, а за 0. Но это грустно, несмотря на, что не успокаивает теория, что трафик по HTTPS не проверяется. Ведь это все тормозит. И действительно, HTTPS заставляет «побегать» по весьма простой формуле.

Рассмотрим на примере Google. Handshake с Google происходит за 50 мс, после чего на каждый запрос накидывается еще 20 мс. Я не буду прикладывать тесты из нашего приложения, но можете посмотреть, какие цифры у вас. Вы огорчитесь. Вообще, все началось с этим переходом на HTTPS. Надо отбивать время, ведь он нас еще сильнее замедлил. Но боль заканчивается, потому что HTTPS открывает суперспособности. И действительно — все, что я буду рассказывать, без HTTPS не работает. Thanks Google.

Это HTTP/2, новый бинарный протокол, который решает наиболее актуальные проблемы в современном вебе, где куча картинок, запросов. В HTTP 1 у нас шесть однонаправленных соединений: либо туда файл идет, либо обратно. HTTP/2 открывает всего одно соединение и создает там неограниченное количество двунаправленных потоков. И что это нам дает?

Спешу напомнить, что HTTP 1 в DevTools waterfall выглядит ступенчато из-за этих ограничений на соединения, в то время как HTTP/2 загружает приложение в одну итерацию.

И потом смотришь успешные истории людей, видишь эти скриншоты телефонов, где полные LTE и Wi-Fi, и думаешь, что уже пора наконец-то настроить модуль на nginx, чтобы поддерживался HTTP/2 для статики. Но вспоминаешь, в какой ты стране. И решаешь сделать условия реальнее.

Команду brew install simplehttp2server не так-то сложно было сделать. До нашего самого далекого клиента задержка 600 мс. И как он там отрабатывает? Реально мощно. В два раза лучше, чем HTTP 1.

Но я не забанен в Google…
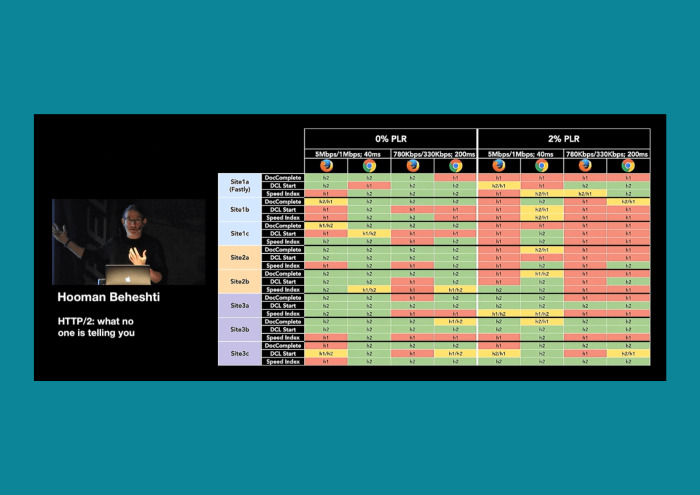
Есть легендарные презентации. К примеру, выходит CTO какого-нибудь CDN и рассказывает, «Что вам не расскажут про HTTP/2». И ты смотришь на эту статистику, в которой зеленое — это где выиграл HTTP/2, а красное — это где выиграл HTTP 1. «Скорость интернета», «задержка» — это я понимаю, но почему в правой колонке так много тестов выиграл HTTP 1? PLR? Гуглишь и понимаешь: это то, что так от нас прячется. Потому что в Devtools в табе Network нет packet loss rate. Это количество пакетов, которое потеряется.
Устанавливаю packet loss 2%, среднюю задержку, и да, как-то не получилось. HTTP/2 все еще быстрее. Проводишь еще один тест… и вот другие цифры. Все дело упирается в чистый эксперимент. Боюсь, его мало кто может провести. Надо садиться в маршрутку с телефоном, ехать, переключаться между станциями, понимать, что твой packet loss динамический, и делать замеры. Остановило ли меня это, учитывая, что я во фронтенде, а наша целевая аудитория не работает на мобильных устройствах? Нет.
Что я сделал? Есть же webpack-merge. Конечно же, я сделал сборку как для HTTP 1, так и для HTTP/2 в одном проекте. Все бы ничего, можно было бы закончить, если бы не существовали такие гении, как Илья Григорик, который говорит: «Те паттерны, которые вы используете для HTTP 1, являются антипаттернами для HTTP/2».
Можно сделать reverse и понять, что это работает и для HTTP/2. В HTTP/2 бьешь все свое приложение на кучу файлов и загружаешь их в одну итерацию. Потому что они идут параллельно, потому что зачем тащить один бандл? И наоборот. Существует множестов тактик. Возможно, у кого-то установлена асинхронная загрузка CSS, JS и прочего, но async defer не всегда спасает. И мы, в некоторых случаях распространяясь как решение SaaS, используем такую схему: для одних клиентов одно, для других другое. И в общем-то, ничего не разбивая, я получил прирост в 21%. Просто добавил модуль для nginx.

Кстати, я наврал. HTTP/2 нельзя просчитать заранее. Ведь вы все успешно забыли про preload, который выстрелил два года назад. И еще существует такая вещь, как Server Push.
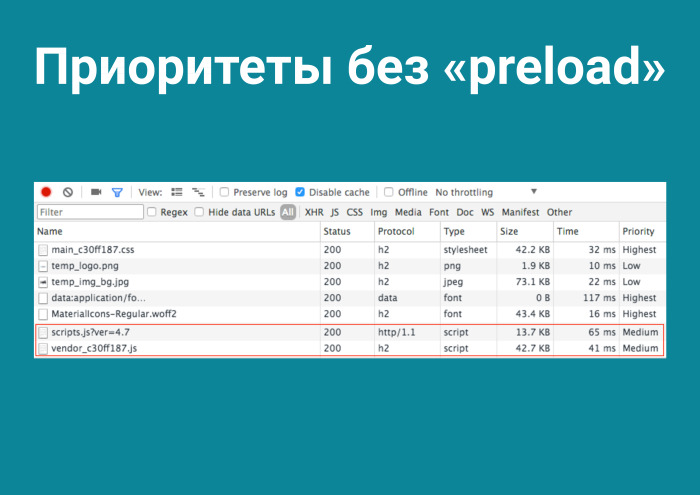
Я решил их проверить. Приоритеты без preload, разумеется. Благодаря тому, что мы размещаем наши бандлы перед закрывающимся тегом <body>, они загружаются последними, в то время как благодаря <link rel=“preload”> вы можете сами сказать браузеру: «Уважаемый, загрузи это первым, мне это понадобится». И это прокачивает загрузку приложения на 0%. Но и тут я наврал. Потому что уменьшилось время до интерактива. Нужные файлы пришли, распарсились, и пользователь получил первую прокраску приложения намного быстрее. А что там с HTTP Server Push?
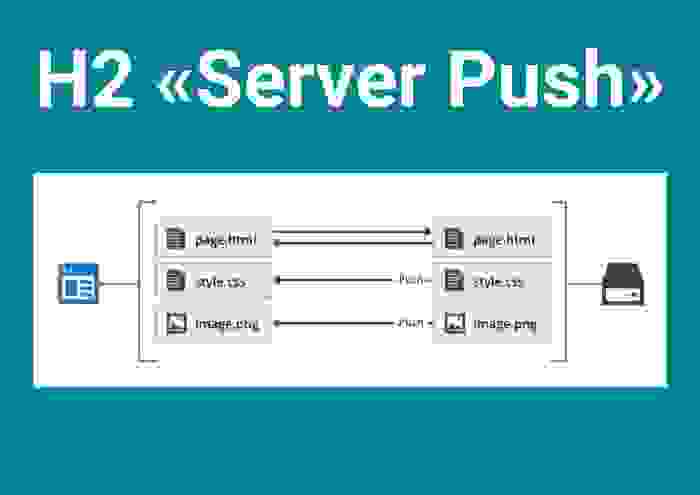
Дословно, это когда сервер пушит вам вообще все, чего бы вы ни хотели. То есть вы открываете соединение с сервером, а там установлен Server Push и он смотрит, по какому адресу вы пришли, а потом попросту пушит вам файлы. Логика того, какие именно файлы пушить, заложена, разумеется, на сервере. Выглядит это примерно так.
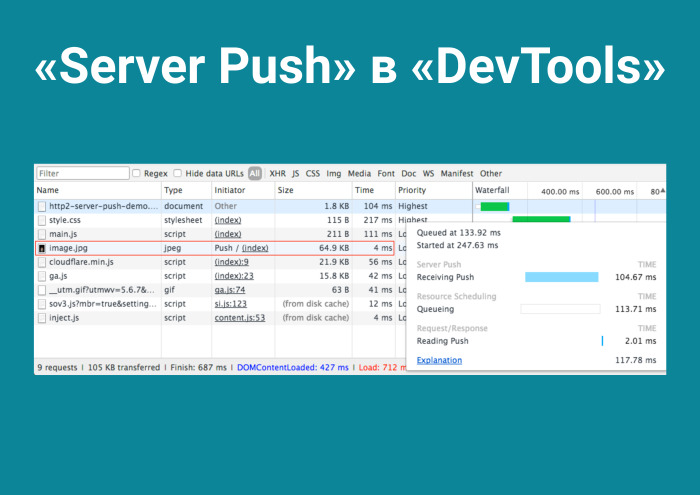
Вы открываете соединение с сервером, и без какого-либо запроса получаете image.jpg за 4 мс. Вы все знакомы с компанией Akamai, ведь все же хостят фотки в Instagram. Akamai в своих каких-то проектах используют Server Push для «hero images», для первых экранов. Но у меня нет растра в проекте — думаю, как и у вас. Я использую SVG. Думаю: наверное, Server Push будет мне интересен за счет того, что есть PRPL.
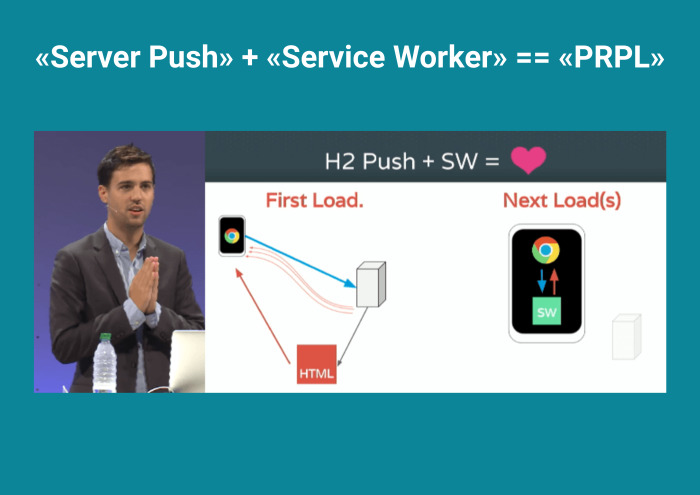
Смотрю Google Dev Summit. PRPL. Происходит первая загрузка, сервер пушит файлы, а последующие загрузки хранятся в Service Worker. Читаю про этот паттерн, и подготовка выглядит следующим образом.

Если вы хотите это использовать, вам нужно разбить ваш бандл помодульно. Переходите на один route — один бандл, на другой route — другой. Я его настроил.

Кстати, мне в статьях очень нравятся нерабочие примеры на Node.js. Сразу видно, что технология обкатана. Настроив это, я получаю прирост 61%. Неплохо, учитывая, что у нас клиенты, оказывается, по срезу сидят на последнем Chrome. Класс! Но не тут-то было. Почему-то Server Push нестабилен. Он дает настолько подробные trace route, что сразу понятно, где проблема.

Вообще вся эта история про PRPL непонятна. Я думал, с Serivice Worker проблема, а тут уже на первом этапе ничего не работает.

Не хочется ни уменьшать хэш в CSS-модулях, ни вырезать глифы, ни вот динамические импорты… А, им мы нашли одно применение.
И с грусти переходишь на блоги успешных компаний. Это Dropbox. Смотрю, заголовок такой: «Мы на 60% уменьшили объемы нашего хранилища, сэкономили миллиарды долларов».

Выясняется, что алгоритмы сжатия существуют уже давно. Это произошло где-то в июне — видимо, где-то над Самарой пролетал метеорит и идея проверить новые алгоритмы сжатия, Zopfli и Brotli, пришла мне и парню из соседней компании. Больше чем уверен, вы читали его статью, это Александр Субботин. Статья разошлась на Medium, и он известен, а я нет.
В опенсорсе любят хвастаться — 3 КБ gzipped. В общем, можете писать: Zopfli на 10% меньше сжимает. Потому что Zopfli является обратно совместимым для gzip. Что это? Повторюсь, новый алгоритм сжатия Zopfli на 2–8% эффективнее gzip. А поддерживается он в 100% браузеров, ровно как gzip.
И Brotli, который не особо старый, но поддерживается в 80% браузеров.
Как это работает? У вас на сервере, в частности для Brotli — для Zopfli уже по дефолту — стоят разрешения, которые берут файлы и на сервере кодируют по определенному алгоритму. То есть в случае с gzip он берет main.js и создает main.js.gz.
В случае Zopfli он создает все то же самое, только сжатое — в моем случае — на 2% эффективнее.
В случае с Brotli устанавливаешь модуль для nginx, и если твой браузер поддерживает Brotli, это дает реально фееричный прирост. Нельзя не радоваться, когда приходится грузить меньше фронтенда. И благодаря таким людям, как немецкий специалист по шрифтам Брам Штайн, есть brew-формула webfonttools. Интересна она тем, что предоставляет два интересных инструмента. Один пережимает WOFF-шрифты при помощи Zopfli и в данном случае экономит… У нас material UI, попадаем на Roboto, на целую гарнитуру. Он сэкономил 3 КБ. А WOFF — 2 КБ. Brotli, видимо, пережимает с большей степенью сжатия и экономит 1 КБ. Все-таки приятно. Это всего лишь brew install webfonttools. Вот чего вам это стоит.
В нашем случае прирост такой: Zopfli — плюс 7%, Brotli — плюс 23%.
Я забыл о главном. Судил людей, которые занимаются микрооптимизацией в JS, а забыл, что творится в DevTools.
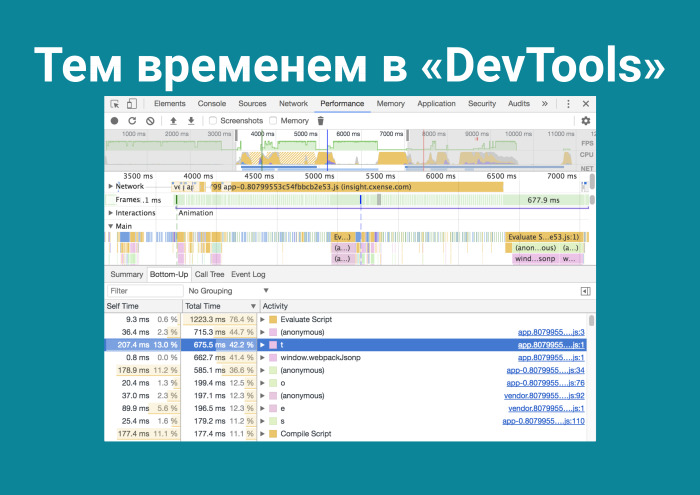
Захожу и понимаю, что Evaluate Script на первом месте. На третьем месте какая-то функция t() — но это не я писал, git blame проверю. И Compile Script. Они занимают много времени. А как это уменьшить? Почему после того, как я запушил фронтенд, клиент еще должен парсить этот код? А потому что V8 так работает.

Благодаря таким людям, как Эдди Османи, мы понимаем, что JS приходит в виде текста, после чего парсится, после чего преобразовывается в Abstract Syntax Tree, генерируется байт-код и оптимизируется.
И тут я вспоминаю, что все новое — это хорошо забытое старое.

Optimize-js — он же берет и оборачивает всё в самовызывающиеся функции. Смотрю по console.time(), это дает прирост в 0,01 мс. Но наверное, я просто не запомнил код функции. Подключаю webpack plugin, и прирост составляет уже 0,1%. Вообще там в readme используется… неважно. Вышел 62-й Chrome, и в release notes сказано, что V8 уже хорош. Так что этот трюк с optimize-js с каждым днем будет все менее и менее эффективен. Но стоит лишь зайти в Твиттер, и ты узнаешь, что существует такая вещь, как prepack.

Потому что она от Facebook. Вообще, выглядит прикольно. То есть в случае с Фибоначчи… Да, неплохо, но для инициализации переменной явно нужно меньше времени.
Смотришь, что число Фибоначчи считается 0,5 мс и что переменная в памяти оказывается за 0,02 мс. Подключаешь prepack — у тебя все падает, отключаешь source maps — у тебя все падает, отключаешь Math.random() — у тебя все… Ладно. Залезаешь в документацию, отключаешь все, что можно, потому что Math.random считается и все это не очень красиво получается. Потом понимаешь, что твой бандл стал больше, поскольку там всего лишь цикл на сотню for, где происходит генерация строк для названий наших модулей. Отключаешь ее. И это дает прирост в 1%.
Надо было в бэкендеры идти…
Но на самом деле за этим будущее. Оно наступит, видимо, не сегодня. Если в случае с optimize-js понятно, там убывающая, то в случае с prepack — возрастающая. И мне кажется, ребята придут к успеху. А уже повезло ребятам, которые делают приложения про PWA, Progressive Web Apps, которые продают Windows Store, для которых APK автоматом генерируется на Android. Там вообще есть офлайн и нативное осязание приложения, но меня это не особо интересует. А еще есть высокая производительность. Хорошо, в чем ее секрет? В Service Worker. Что Safari не будет поддерживать Service Worker — это шутки. Поддержка будет.

Я начал искать эту тему и пробовать. Ведь зачем вообще грузить фронтенд два раза, запрашивать его? Лирическое отступление. У нас в приложение можно заходить вообще на разные роуты, и это очень частый случай. И все очень грустно. Все это загружается по сто раз. И я думаю — закэширую на клиенте. К тому же все разбито. И тут начинается моя любимая рубрика в программировании. Потому что у тебя не получится!
Ну и как пел Public Enemy: «Harder than you think is a beautiful thing». Но почему это вообще произошло?

Ты регистрируешь его всего одной строчкой кода.
А потому что, не поняв, что это и как это работает, ты сразу в бой. Пока идет загрузка, я вам расскажу, как это выглядит.

Зарегистрировал sw.js, что-то сделал и все упало — поскольку ты в принципе не понимаешь, что это такое. Определение из Википедии: Service Worker — проксификатор, встроенный в ваш браузер и на данный момент имеющий поддержку в 81% браузеров. Он может только смотреть, что пользователь пересылает, перехватывать запросы и, если запрос именно тот, который ему нужен, проверять в sw.js, заложена ли там логика под него. И — делать изложенную там логику.
Чтобы заложить эту логику, вам нужно ответить на два вопроса.

В первую очередь — какую кэш-стратегию вы выбираете? Она существует cache-first, то есть загрузил, сохранил в кэш, а потом оттуда берешь, пока не поступит обновление. Либо network-first: все время дергать сервер и брать из кэша, только если сервер не ответил.
Что кэшировать? Давайте кэшировать всё.
Мы живем в золотое время. Как сказал Штефан Джудис: «Just celebrate». Мы можем брать все что угодно: sw-precache, offline-plugin — не ошибетесь. Они работают замечательно. Да и все эти sw.js — 300 строк одного и того же. В разрезе он выглядит примерно так. Это map с вашими файлами и хэшмапы: функции для работы со стратегиями кэширования, функции по работе с файлами, с кэшем — если вы не прослушивали лекции и знаете, что такое «нормализация».
Какие-то eventlisteners и управление состоянием. Но это нужно ребятам из PWA, а я всего лишь хочу фронтенд лишний раз не загружать.

Service Worker не в деле. Статистика примерна такова: 22 запроса, 2 МБ и финиш через 4 секунды. Я подключаю Service Worker с требованием «Закэшируй всё» и получаю прирост в минус 200%. Что-то пошло не так.

Вот же скриншот, все в решетках, 65 запросов, 16 Мб, и финишировало за 7,6 секунд. Но я не наврал, приложение большое. А всё почему? Service Worker загрузил пользователя до отказа. Это же проксификатор, и чтобы что-то сохранять в себе, ему требуется время. Вы даже к нему делаете запрос и он может отрабатывать полсекунды!

Чтобы достучаться до вещи, которая в браузере, нужно полсекунды. Неплохо. Нажимаешь в DevTools на explanation, а там инструкция, как читать flame charts. Необъяснимо, но факт: когда я залез в DevTools, я не обнаружил compile-времени. Как бы вы думали, что это? Внимательный слушатель вспомнит, что V8 работает примерно так.
Так получилось, что я случайно выяснил: Service Worker хранит в себе преподготовленный кэш. Я вижу, что у меня Evaluate script упал с 1400 мс до 1000 мс в табе bottom-up и compile-время упало в два раза. Поэтому я его и «не увидел» — оно опустилось вниз списка.
Почему? С этим вопросом я направился в сеть интернет и, проведя там сутки, ничего не нашел. А помог мне issue на GitHub к уважаемому Дэну Абрамову. Там был примерно такой заголовок: «Зачем ты добавил Service Worker в create-react-app?» И куча комментариев. И Эдди Османи в последнем своем абзаце дает мне ответ, очень скромно: «Знаете, ребят, а Service Worker вообще-то хранит в преподготовленном состоянии кэш уже в распарсенном виде, вам не нужно компайлить второй раз». Я понимаю, что это мой шанс, и что все вокруг вообще не в курсе про это. Но зачем вставлять это в пресс-релиз? Действительно, лучше покопаться на GitHub, всего-то 34 комментарий с конца.
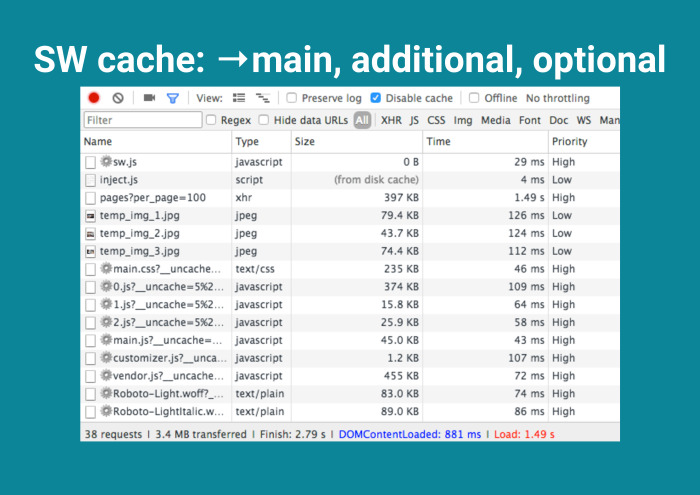
И дальше, как говорил Павел Дуров, отличаю главное от неглавного. Вместо кэширования всего делаю следующее: выделяю main-секцию — ядро, без которого приложение не запустится. Выделяю добавочное, шрифты. Они тяжелые, лучше их хранить на клиенте. И опционально, Service Worker, сохрани всё, что по сети гуляет. Было бы неплохо.
Как это происходит? Первая загрузка у пользователя.
Его Service Worker нагружает не сильно, но FPS проседает, трафик увеличивается. Отлично, появились решетки рядом с жизненно важными файлами. Потом при следующей загрузке — additional cache.

И затем optional.
И тут ты достигаешь конечной станции, потому что не загрузил ни байта. По большому счету, Service Worker отнимает, отнимает, а потом все-таки докидывает сверху с лихвой. Почему Эдди Османи об этом молчит? Я не знаю.

Соавтор многих post-CSS-модулей MoOx говорит, что успех всех опенсорсных пакетов заключается в маркетинге. Почему в данном случае это скрывается? Не знаю.
Вот простая тактика, которую высказал тот же самый золотой человек Эдди Османи.

Потом я сделал это правильно, потому что использовать cache all для SW было плохой идеей. А затем, сделав это лучше, совместив, я получит фронтенд, который приходит как рассыпчатый сахар и быстро растворяется в браузере клиента.

Итого. Используйте сеть эффективно. Помните, как это работает в других протоколах. Помните про эти шесть соединений, но их мало, фронтенд расширяется. Относитесь к сборке скрупулезней. Очень важно понимать, что webpack несовершенен. Хотя там такие гении работают, что скоро он будет совершенен. Не перекладывайте на пользователя многое. Он же не всегда сидит на последнем макбуке.
И настало время остановиться. Спасибо за внимание.
Выясняется, что алгоритмы сжатия существуют уже давно. Это произошло где-то в июне — видимо, где-то над Самарой пролетал метеорит и идея проверить новые алгоритмы сжатия, Zopfli и Brotli, пришла мне и парню из соседней компании. Больше чем уверен, вы читали его статью, это Александр Субботин. Статья разошлась на Medium, и он известен, а я нет.
— Всем привет. Спасибо, что пришли. Я хочу рассказать историю про то, как у нас получилось сделать фронтенд «быстрорастворимым».
Для начала представлюсь, чтобы хоть как-то поднять доверие к себе в столь опасной теме. Я фронтендер из норвежской компании Cxense. Никто толком не может произнести название корректно. Хорошо, что через семь лет после основания выпустили видео о том, как правильно произносить Cxense. «Си-сэнс».
Мы доставляем людям то, что они хотят, по следующим срезам: рекламе и статьям. Вот у бэкенда получается доставлять данные быстро. Неудивительно, у бэкендеров из норвежского офиса Линус Торвальдс был одноклассником. А вот мы на их фоне как-то… Проблема зародилась примерно так: мы не можем доставлять фронтенд быстро.
Когда я слышал споры про то, как должен «доставляться» фронтенд, как нужно его грузить и ускорять, мне это напомнило статью уважаемого человека, 61 параграф — «Краткий самоучитель по быстрорастворимому креативу» для дизайнеров.

Там были описаны примеры про то, как дизайнер думает, а вообще-то надо сделать по-другому. И во фронтенде порой нужно выходить за рамки. Вы сами можете поймать себя на мысли, что порой народ думает совсем не в том направлении и все упирается в микрооптимизации.
Отлично, мы тоже серьезные ребята и начали путь оптимизации по следующему списку:

Мы установили source-map-explorer. Мы настолько хипстеры, что используем bundle-buddy, выпущенный месяц назад. Проанализировали бандл и убрали дубликаты. Поняли, что приложение должно быть одним бандлом, а его необходимо разбить на чанки, и еще загружать только при переходе на необходимую страницу. Установили расширение import-cost, чтобы знать? в каком размере мы подгружаем зависимости в VS Code. Установили динамические импорты, нашли им одно применение в коде. Но вот как-то грустно на душе, а тут еще и осень… И все, что ты хочешь, это идти домой.
А потом прийти в офис и сказать дефолтную фразу: «Ребята, помогите мне переписать фронтенд!».
Но вот незадача. Фраза «давайте перепишем на React» была озвучена два года назад и переписывать больше нечего. Отсюда и начинается моя нехитрая история.
Про что я вам расскажу?

Часть любой успешной презентации — графики, но их тут не будет. Я буду использовать цифры. Есть серьезное, хорошее, двухгодичной выдержки приложение, и его изначальная скорость после ранее упомянутых оптимизаций — 100%. Все результаты, о которых я буду говорить, были проверены следующим CLI-иструментом от проект-менеджера.

Pwmetrics. Его сделал Пол Айриш — пожалуй, самый уважаемый проект-менеджер на этой планете. Учитывая, что это легко встраивается в CI, и я не боюсь vim, я просто перезагружаю компьютер…
Pwmetrics очень быстрый и за считанные секунды дает мне четыре главные метрики: время до интерактива, когда наконец-то наши клики не «проглатываются», speed index от Google, видимую прокраску и полную прокраску приложения.
Почему не Lighthouse? Потому что я настолько стар, как и вы, что использовал его, еще когда он был долгий и не встроен в таб audits. Поехали!
Началось все с того, что благодаря агрессивным намекам от Google мы перешли на HTTPS. Конечно, это было еще очень здорово подано такими вещами, как certbot. Теперь мы покупаем SSL-сертификат не за 7 долларов, а за 0. Но это грустно, несмотря на, что не успокаивает теория, что трафик по HTTPS не проверяется. Ведь это все тормозит. И действительно, HTTPS заставляет «побегать» по весьма простой формуле.

Рассмотрим на примере Google. Handshake с Google происходит за 50 мс, после чего на каждый запрос накидывается еще 20 мс. Я не буду прикладывать тесты из нашего приложения, но можете посмотреть, какие цифры у вас. Вы огорчитесь. Вообще, все началось с этим переходом на HTTPS. Надо отбивать время, ведь он нас еще сильнее замедлил. Но боль заканчивается, потому что HTTPS открывает суперспособности. И действительно — все, что я буду рассказывать, без HTTPS не работает. Thanks Google.
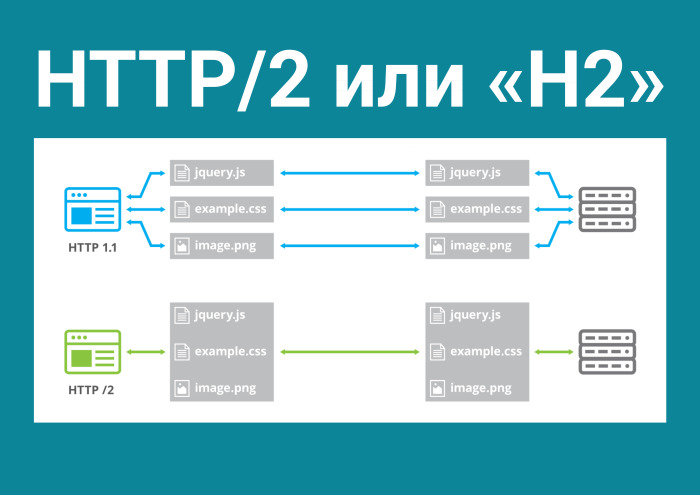
Это HTTP/2, новый бинарный протокол, который решает наиболее актуальные проблемы в современном вебе, где куча картинок, запросов. В HTTP 1 у нас шесть однонаправленных соединений: либо туда файл идет, либо обратно. HTTP/2 открывает всего одно соединение и создает там неограниченное количество двунаправленных потоков. И что это нам дает?
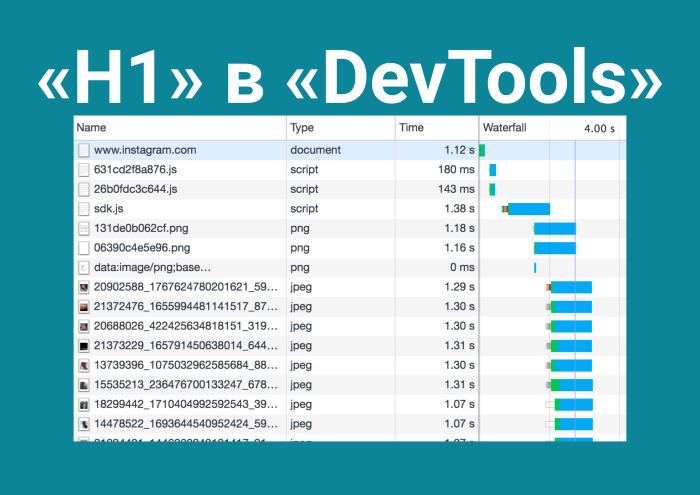
Спешу напомнить, что HTTP 1 в DevTools waterfall выглядит ступенчато из-за этих ограничений на соединения, в то время как HTTP/2 загружает приложение в одну итерацию.

И потом смотришь успешные истории людей, видишь эти скриншоты телефонов, где полные LTE и Wi-Fi, и думаешь, что уже пора наконец-то настроить модуль на nginx, чтобы поддерживался HTTP/2 для статики. Но вспоминаешь, в какой ты стране. И решаешь сделать условия реальнее.

Команду brew install simplehttp2server не так-то сложно было сделать. До нашего самого далекого клиента задержка 600 мс. И как он там отрабатывает? Реально мощно. В два раза лучше, чем HTTP 1.

Но я не забанен в Google…

Есть легендарные презентации. К примеру, выходит CTO какого-нибудь CDN и рассказывает, «Что вам не расскажут про HTTP/2». И ты смотришь на эту статистику, в которой зеленое — это где выиграл HTTP/2, а красное — это где выиграл HTTP 1. «Скорость интернета», «задержка» — это я понимаю, но почему в правой колонке так много тестов выиграл HTTP 1? PLR? Гуглишь и понимаешь: это то, что так от нас прячется. Потому что в Devtools в табе Network нет packet loss rate. Это количество пакетов, которое потеряется.
Устанавливаю packet loss 2%, среднюю задержку, и да, как-то не получилось. HTTP/2 все еще быстрее. Проводишь еще один тест… и вот другие цифры. Все дело упирается в чистый эксперимент. Боюсь, его мало кто может провести. Надо садиться в маршрутку с телефоном, ехать, переключаться между станциями, понимать, что твой packet loss динамический, и делать замеры. Остановило ли меня это, учитывая, что я во фронтенде, а наша целевая аудитория не работает на мобильных устройствах? Нет.
Что я сделал? Есть же webpack-merge. Конечно же, я сделал сборку как для HTTP 1, так и для HTTP/2 в одном проекте. Все бы ничего, можно было бы закончить, если бы не существовали такие гении, как Илья Григорик, который говорит: «Те паттерны, которые вы используете для HTTP 1, являются антипаттернами для HTTP/2».
Можно сделать reverse и понять, что это работает и для HTTP/2. В HTTP/2 бьешь все свое приложение на кучу файлов и загружаешь их в одну итерацию. Потому что они идут параллельно, потому что зачем тащить один бандл? И наоборот. Существует множестов тактик. Возможно, у кого-то установлена асинхронная загрузка CSS, JS и прочего, но async defer не всегда спасает. И мы, в некоторых случаях распространяясь как решение SaaS, используем такую схему: для одних клиентов одно, для других другое. И в общем-то, ничего не разбивая, я получил прирост в 21%. Просто добавил модуль для nginx.

Кстати, я наврал. HTTP/2 нельзя просчитать заранее. Ведь вы все успешно забыли про preload, который выстрелил два года назад. И еще существует такая вещь, как Server Push.
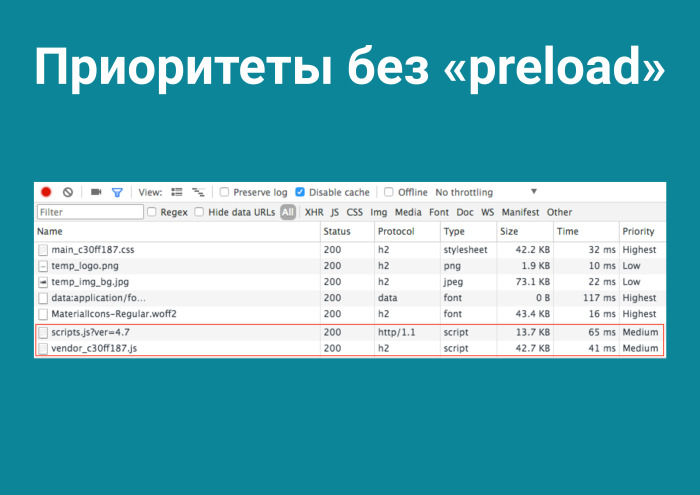
Я решил их проверить. Приоритеты без preload, разумеется. Благодаря тому, что мы размещаем наши бандлы перед закрывающимся тегом <body>, они загружаются последними, в то время как благодаря <link rel=“preload”> вы можете сами сказать браузеру: «Уважаемый, загрузи это первым, мне это понадобится». И это прокачивает загрузку приложения на 0%. Но и тут я наврал. Потому что уменьшилось время до интерактива. Нужные файлы пришли, распарсились, и пользователь получил первую прокраску приложения намного быстрее. А что там с HTTP Server Push?

Дословно, это когда сервер пушит вам вообще все, чего бы вы ни хотели. То есть вы открываете соединение с сервером, а там установлен Server Push и он смотрит, по какому адресу вы пришли, а потом попросту пушит вам файлы. Логика того, какие именно файлы пушить, заложена, разумеется, на сервере. Выглядит это примерно так.

Вы открываете соединение с сервером, и без какого-либо запроса получаете image.jpg за 4 мс. Вы все знакомы с компанией Akamai, ведь все же хостят фотки в Instagram. Akamai в своих каких-то проектах используют Server Push для «hero images», для первых экранов. Но у меня нет растра в проекте — думаю, как и у вас. Я использую SVG. Думаю: наверное, Server Push будет мне интересен за счет того, что есть PRPL.

Смотрю Google Dev Summit. PRPL. Происходит первая загрузка, сервер пушит файлы, а последующие загрузки хранятся в Service Worker. Читаю про этот паттерн, и подготовка выглядит следующим образом.
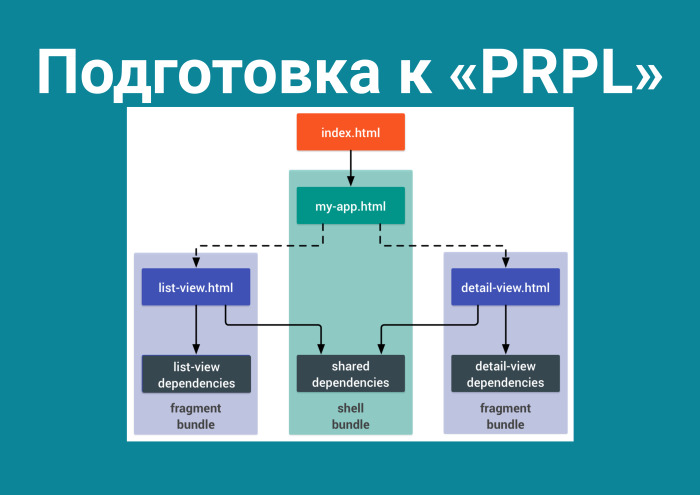
Если вы хотите это использовать, вам нужно разбить ваш бандл помодульно. Переходите на один route — один бандл, на другой route — другой. Я его настроил.

Кстати, мне в статьях очень нравятся нерабочие примеры на Node.js. Сразу видно, что технология обкатана. Настроив это, я получаю прирост 61%. Неплохо, учитывая, что у нас клиенты, оказывается, по срезу сидят на последнем Chrome. Класс! Но не тут-то было. Почему-то Server Push нестабилен. Он дает настолько подробные trace route, что сразу понятно, где проблема.
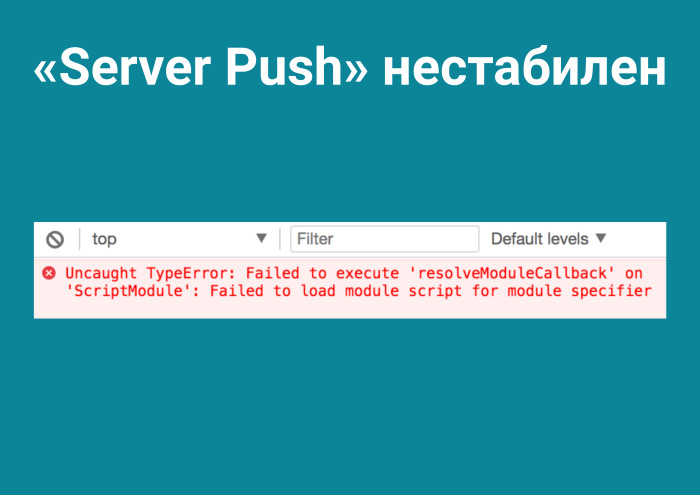
Вообще вся эта история про PRPL непонятна. Я думал, с Serivice Worker проблема, а тут уже на первом этапе ничего не работает.

Не хочется ни уменьшать хэш в CSS-модулях, ни вырезать глифы, ни вот динамические импорты… А, им мы нашли одно применение.
И с грусти переходишь на блоги успешных компаний. Это Dropbox. Смотрю, заголовок такой: «Мы на 60% уменьшили объемы нашего хранилища, сэкономили миллиарды долларов».

Выясняется, что алгоритмы сжатия существуют уже давно. Это произошло где-то в июне — видимо, где-то над Самарой пролетал метеорит и идея проверить новые алгоритмы сжатия, Zopfli и Brotli, пришла мне и парню из соседней компании. Больше чем уверен, вы читали его статью, это Александр Субботин. Статья разошлась на Medium, и он известен, а я нет.
В опенсорсе любят хвастаться — 3 КБ gzipped. В общем, можете писать: Zopfli на 10% меньше сжимает. Потому что Zopfli является обратно совместимым для gzip. Что это? Повторюсь, новый алгоритм сжатия Zopfli на 2–8% эффективнее gzip. А поддерживается он в 100% браузеров, ровно как gzip.
И Brotli, который не особо старый, но поддерживается в 80% браузеров.
Как это работает? У вас на сервере, в частности для Brotli — для Zopfli уже по дефолту — стоят разрешения, которые берут файлы и на сервере кодируют по определенному алгоритму. То есть в случае с gzip он берет main.js и создает main.js.gz.
В случае Zopfli он создает все то же самое, только сжатое — в моем случае — на 2% эффективнее.
В случае с Brotli устанавливаешь модуль для nginx, и если твой браузер поддерживает Brotli, это дает реально фееричный прирост. Нельзя не радоваться, когда приходится грузить меньше фронтенда. И благодаря таким людям, как немецкий специалист по шрифтам Брам Штайн, есть brew-формула webfonttools. Интересна она тем, что предоставляет два интересных инструмента. Один пережимает WOFF-шрифты при помощи Zopfli и в данном случае экономит… У нас material UI, попадаем на Roboto, на целую гарнитуру. Он сэкономил 3 КБ. А WOFF — 2 КБ. Brotli, видимо, пережимает с большей степенью сжатия и экономит 1 КБ. Все-таки приятно. Это всего лишь brew install webfonttools. Вот чего вам это стоит.
В нашем случае прирост такой: Zopfli — плюс 7%, Brotli — плюс 23%.
Я забыл о главном. Судил людей, которые занимаются микрооптимизацией в JS, а забыл, что творится в DevTools.
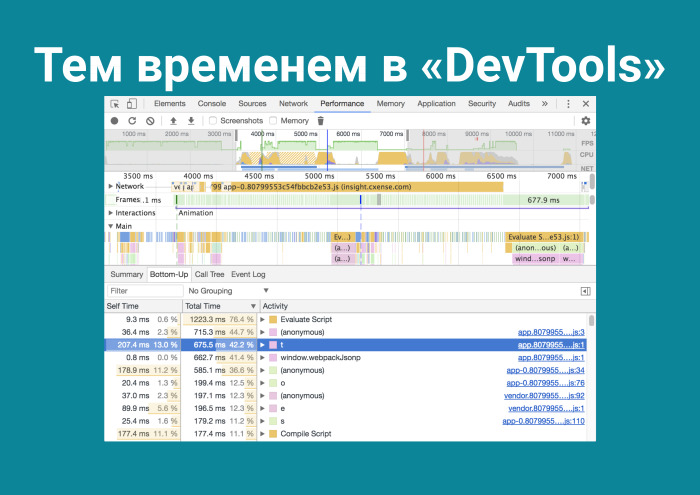
Захожу и понимаю, что Evaluate Script на первом месте. На третьем месте какая-то функция t() — но это не я писал, git blame проверю. И Compile Script. Они занимают много времени. А как это уменьшить? Почему после того, как я запушил фронтенд, клиент еще должен парсить этот код? А потому что V8 так работает.
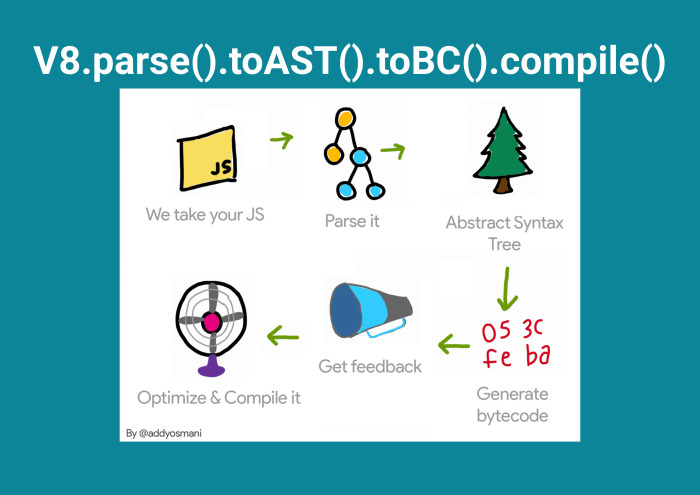
Благодаря таким людям, как Эдди Османи, мы понимаем, что JS приходит в виде текста, после чего парсится, после чего преобразовывается в Abstract Syntax Tree, генерируется байт-код и оптимизируется.
И тут я вспоминаю, что все новое — это хорошо забытое старое.

Optimize-js — он же берет и оборачивает всё в самовызывающиеся функции. Смотрю по console.time(), это дает прирост в 0,01 мс. Но наверное, я просто не запомнил код функции. Подключаю webpack plugin, и прирост составляет уже 0,1%. Вообще там в readme используется… неважно. Вышел 62-й Chrome, и в release notes сказано, что V8 уже хорош. Так что этот трюк с optimize-js с каждым днем будет все менее и менее эффективен. Но стоит лишь зайти в Твиттер, и ты узнаешь, что существует такая вещь, как prepack.

Потому что она от Facebook. Вообще, выглядит прикольно. То есть в случае с Фибоначчи… Да, неплохо, но для инициализации переменной явно нужно меньше времени.
Смотришь, что число Фибоначчи считается 0,5 мс и что переменная в памяти оказывается за 0,02 мс. Подключаешь prepack — у тебя все падает, отключаешь source maps — у тебя все падает, отключаешь Math.random() — у тебя все… Ладно. Залезаешь в документацию, отключаешь все, что можно, потому что Math.random считается и все это не очень красиво получается. Потом понимаешь, что твой бандл стал больше, поскольку там всего лишь цикл на сотню for, где происходит генерация строк для названий наших модулей. Отключаешь ее. И это дает прирост в 1%.
Надо было в бэкендеры идти…
Но на самом деле за этим будущее. Оно наступит, видимо, не сегодня. Если в случае с optimize-js понятно, там убывающая, то в случае с prepack — возрастающая. И мне кажется, ребята придут к успеху. А уже повезло ребятам, которые делают приложения про PWA, Progressive Web Apps, которые продают Windows Store, для которых APK автоматом генерируется на Android. Там вообще есть офлайн и нативное осязание приложения, но меня это не особо интересует. А еще есть высокая производительность. Хорошо, в чем ее секрет? В Service Worker. Что Safari не будет поддерживать Service Worker — это шутки. Поддержка будет.
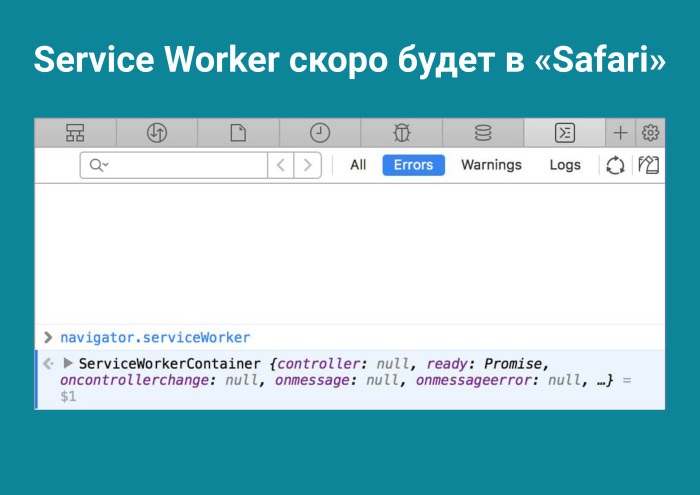
Я начал искать эту тему и пробовать. Ведь зачем вообще грузить фронтенд два раза, запрашивать его? Лирическое отступление. У нас в приложение можно заходить вообще на разные роуты, и это очень частый случай. И все очень грустно. Все это загружается по сто раз. И я думаю — закэширую на клиенте. К тому же все разбито. И тут начинается моя любимая рубрика в программировании. Потому что у тебя не получится!
Ну и как пел Public Enemy: «Harder than you think is a beautiful thing». Но почему это вообще произошло?

Ты регистрируешь его всего одной строчкой кода.

А потому что, не поняв, что это и как это работает, ты сразу в бой. Пока идет загрузка, я вам расскажу, как это выглядит.
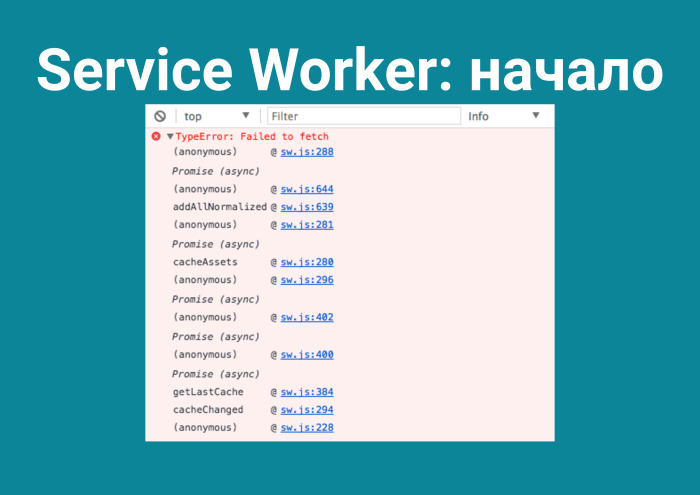
Зарегистрировал sw.js, что-то сделал и все упало — поскольку ты в принципе не понимаешь, что это такое. Определение из Википедии: Service Worker — проксификатор, встроенный в ваш браузер и на данный момент имеющий поддержку в 81% браузеров. Он может только смотреть, что пользователь пересылает, перехватывать запросы и, если запрос именно тот, который ему нужен, проверять в sw.js, заложена ли там логика под него. И — делать изложенную там логику.
Чтобы заложить эту логику, вам нужно ответить на два вопроса.

В первую очередь — какую кэш-стратегию вы выбираете? Она существует cache-first, то есть загрузил, сохранил в кэш, а потом оттуда берешь, пока не поступит обновление. Либо network-first: все время дергать сервер и брать из кэша, только если сервер не ответил.
Что кэшировать? Давайте кэшировать всё.
Мы живем в золотое время. Как сказал Штефан Джудис: «Just celebrate». Мы можем брать все что угодно: sw-precache, offline-plugin — не ошибетесь. Они работают замечательно. Да и все эти sw.js — 300 строк одного и того же. В разрезе он выглядит примерно так. Это map с вашими файлами и хэшмапы: функции для работы со стратегиями кэширования, функции по работе с файлами, с кэшем — если вы не прослушивали лекции и знаете, что такое «нормализация».
Какие-то eventlisteners и управление состоянием. Но это нужно ребятам из PWA, а я всего лишь хочу фронтенд лишний раз не загружать.

Service Worker не в деле. Статистика примерна такова: 22 запроса, 2 МБ и финиш через 4 секунды. Я подключаю Service Worker с требованием «Закэшируй всё» и получаю прирост в минус 200%. Что-то пошло не так.

Вот же скриншот, все в решетках, 65 запросов, 16 Мб, и финишировало за 7,6 секунд. Но я не наврал, приложение большое. А всё почему? Service Worker загрузил пользователя до отказа. Это же проксификатор, и чтобы что-то сохранять в себе, ему требуется время. Вы даже к нему делаете запрос и он может отрабатывать полсекунды!
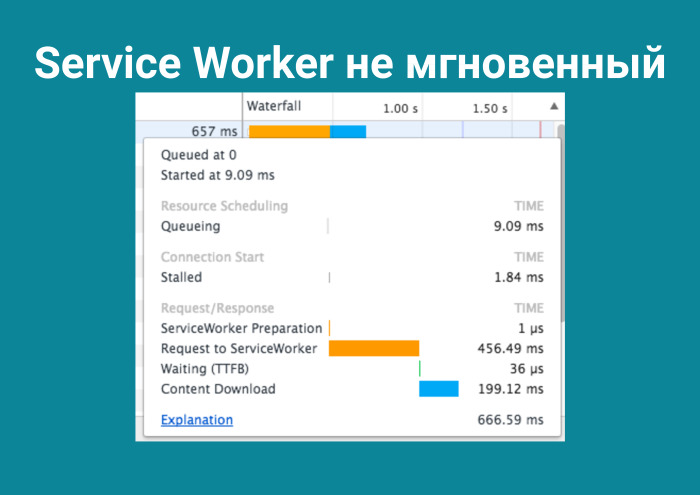
Чтобы достучаться до вещи, которая в браузере, нужно полсекунды. Неплохо. Нажимаешь в DevTools на explanation, а там инструкция, как читать flame charts. Необъяснимо, но факт: когда я залез в DevTools, я не обнаружил compile-времени. Как бы вы думали, что это? Внимательный слушатель вспомнит, что V8 работает примерно так.
Так получилось, что я случайно выяснил: Service Worker хранит в себе преподготовленный кэш. Я вижу, что у меня Evaluate script упал с 1400 мс до 1000 мс в табе bottom-up и compile-время упало в два раза. Поэтому я его и «не увидел» — оно опустилось вниз списка.
Почему? С этим вопросом я направился в сеть интернет и, проведя там сутки, ничего не нашел. А помог мне issue на GitHub к уважаемому Дэну Абрамову. Там был примерно такой заголовок: «Зачем ты добавил Service Worker в create-react-app?» И куча комментариев. И Эдди Османи в последнем своем абзаце дает мне ответ, очень скромно: «Знаете, ребят, а Service Worker вообще-то хранит в преподготовленном состоянии кэш уже в распарсенном виде, вам не нужно компайлить второй раз». Я понимаю, что это мой шанс, и что все вокруг вообще не в курсе про это. Но зачем вставлять это в пресс-релиз? Действительно, лучше покопаться на GitHub, всего-то 34 комментарий с конца.
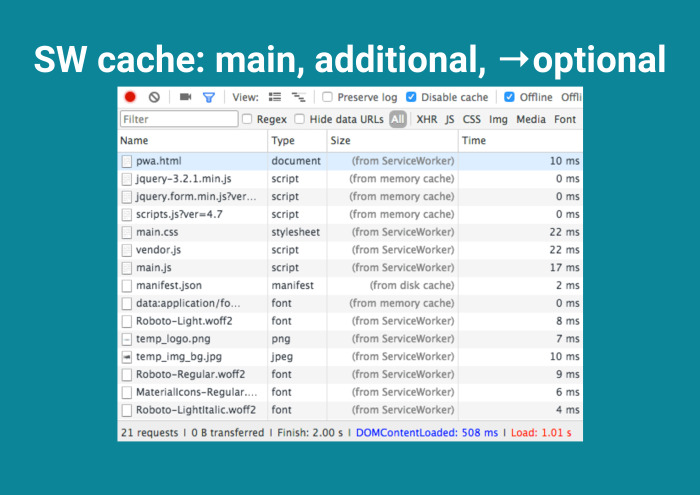
И дальше, как говорил Павел Дуров, отличаю главное от неглавного. Вместо кэширования всего делаю следующее: выделяю main-секцию — ядро, без которого приложение не запустится. Выделяю добавочное, шрифты. Они тяжелые, лучше их хранить на клиенте. И опционально, Service Worker, сохрани всё, что по сети гуляет. Было бы неплохо.
Как это происходит? Первая загрузка у пользователя.
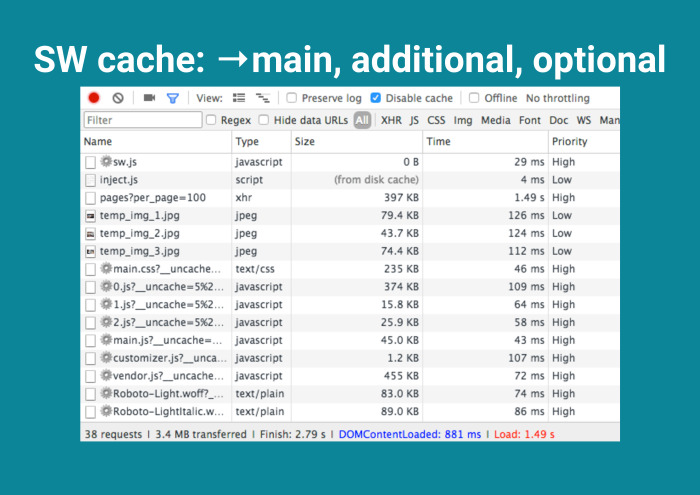
Его Service Worker нагружает не сильно, но FPS проседает, трафик увеличивается. Отлично, появились решетки рядом с жизненно важными файлами. Потом при следующей загрузке — additional cache.

И затем optional.
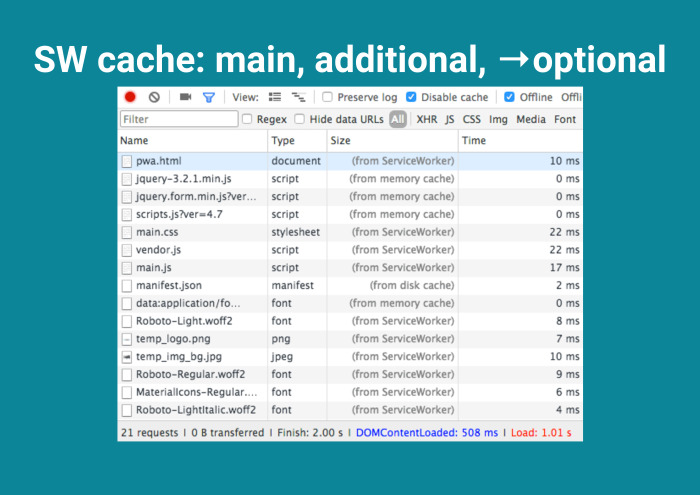
И тут ты достигаешь конечной станции, потому что не загрузил ни байта. По большому счету, Service Worker отнимает, отнимает, а потом все-таки докидывает сверху с лихвой. Почему Эдди Османи об этом молчит? Я не знаю.

Соавтор многих post-CSS-модулей MoOx говорит, что успех всех опенсорсных пакетов заключается в маркетинге. Почему в данном случае это скрывается? Не знаю.
Вот простая тактика, которую высказал тот же самый золотой человек Эдди Османи.

Потом я сделал это правильно, потому что использовать cache all для SW было плохой идеей. А затем, сделав это лучше, совместив, я получит фронтенд, который приходит как рассыпчатый сахар и быстро растворяется в браузере клиента.

Итого. Используйте сеть эффективно. Помните, как это работает в других протоколах. Помните про эти шесть соединений, но их мало, фронтенд расширяется. Относитесь к сборке скрупулезней. Очень важно понимать, что webpack несовершенен. Хотя там такие гении работают, что скоро он будет совершенен. Не перекладывайте на пользователя многое. Он же не всегда сидит на последнем макбуке.
И настало время остановиться. Спасибо за внимание.
