
Модели машинного обучения нужно уметь не только разрабатывать, но и «продавать» заказчику. Если у него не будет понимания, почему предлагается именно такое решение, то всё закончится статьёй в журнале и выступлением на конференции. Директор компании Loginom Алексей Арустамов обращает внимание на ключевые моменты, которые важно отразить в описании модели. Это выступление прошло пару недель назад на конференции Яндекса из серии «Data & Science».
— Меня зовут Алексей Арустамов, я из компании Loginom. Раньше мы назывались BeseGroupLabs. Вещами, связанными с анализом данных, мы занимаемся достаточно давно — наверное, лет 20. Все это время мы ничем, кроме аналитики, не занимались.
Я хотел бы рассказать об опыте, который накопился у нас за это время, и о том, как вести такие проекты, как их суметь сдать.
Для начала остановимся на том, какие задачи чаще всего решаются в системах, в проектах, связанных с машинным обучением. Если обратите внимание, значительная часть задач крутится вокруг этого пула. Вещи, связанные с поиском, различными вариантами рекомендаций, обогащения, чаще всего из социальных сетей, ну и из других источников тоже. Очень много обработки изображений и тому подобного, близкие задачи.
На первый взгляд, это классно, но с другой стороны, мы же говорим о том, что машинное обучение и анализ данных должны приносить пользу бизнесу. Если мы говорим об этом, неплохо было бы понять, где вообще бизнес. Структура российской экономики выглядит приблизительно так:

Это данные Росстата за 2016 год. Структура особо не поменялась, приблизительно то же самое. Как несложно увидеть, 80% всего, что связано с экономикой, связано с традиционными отраслями типа строительства, банков, торговли и т. п.
Если мы обратим внимание на эти отрасли экономики, мы быстро убедимся, что задачи, которые там ставятся, выглядят не как поиск и не «разобрать изображение» или что-то в этом духе. Они звучат приблизительно так.
Задачи, вокруг которых чаще всего все крутится: оптимизация запасов, управление рисками, оптимизация производства, логистика, транспорт, развоз людей и т. п.
Если вы выйдете на улицу и пойдете в другую компанию, спросите, сделано ли у них что-нибудь в этом направлении, то, скорее всего, услышите, что ничего не сделано, ситуация с анализом достаточно плохая. И это звучит странно. Вроде бы вон сколько программистов, сейчас накодим, будет счастье, чего же не взлетает ничего в большинстве случаев?
Что еще странно в этом деле — люди занимаются тем, что давайте мы по лицу угадаем, какое у человека настроение. Классно, только непонятно, какое отношение это имеет к бизнесу. Если вы увеличите оборачиваемость товаров на 1% — я вас уверяю, все эти изображения, весь экономический эффект покрывает их как бык овцу. Эффект ни в какое сравнение не идет.
Казалось бы, у нас есть потребность, люди хотят, все горит синим пламенем, почему же не заводится? Когда даже пробуют все делать, это дело нормально не внедряется.
Чтобы это понять, я бы предложил обратить внимание на это определение Пятецкого-Шапиро, что такое data mining.

Обратите внимание на то, что выделено красным цветом. Делать доступным для интерпретации. Для людей, которые специализируются на data science, — для них, к сожалению, что важно? Взяли данные, зарядили 500 атрибутов, зарядили желательно нейросеть, иначе будет позорище без нейросети, построили модель, которая непонятно что делает для пользователя, но зато это круто, можно рассказать коллегам.
Когда Пятецкий-Шапиро это написал, это была не глупость. Каждое слово. Возможность интерпретировать полученные результаты очень важна.
Если у вас цена ошибки маленькая, то вообще все равно, что там интерпретировать. Дали вы не ту рекомендацию — ну и бог с ней. В поиске что-то вывели — ну и ничего страшного. Но все меняется, когда речь идет о вещах, связанных с большими издержками, где цена ошибки очень большая. И тогда люди не очень любят доверять черному ящику. Это просто здравый смысл. Вы готовы поставить на кон свою машину и сказать, что построите модель, которая предсказывает что-нибудь? Или что-то дорогое. Скорее всего так не получится. Бизнес не хочет это применять, для них риски очень большие. И тогда всякие варианты типа черного ящика не очень-то и заводятся. Они послушают, поцокают языком… Если это делается за чужой счет, они обязательно сделают, они любят поковыряться с чем-то интересным. Но если это ваши деньги, то особого энтузиазма оно не вызовет.

В чем проблема? Почему это не становится массовым, хотя, вроде бы, должно? Основная проблема в доверии.
Каждый раз, когда вы подпихиваете людям черный ящик с неведомой магией внутри, люди не могут ей доверять — в первую очередь потому, что они не понимают, что черный ящик делает. А доверие формируется в первую очередь за счет предсказуемости. Люди должны понимать, почему сделано именно это решение. В противном случае они в нормальном бизнесе это не будут использовать, пока не преодолеют психологический порог по цене. Когда дешево — все хорошо, но где-то есть такая граница, начиная с которой люди не будут все это использовать, потому что боятся.
За счет чего формируется предсказуемость? Мы понимаем ограничения и все промежуточные шаги. Причем желательно, чтобы они были каким-то образом аргументированы и объяснены, чтобы было понятно, почему такое решение было принято, что его обязательно нужно тестировать. Еще одна важная вещь, про которую часто забывают, — поведение в нестандартных ситуациях. Всякие граничные условия и все такое. Это одна из проблем, на которую вы, скорее всего, наткнетесь, как только возьмете реальный проект. Первые же входные данные будут кривые, обязательно что-то будет не так, и что-то грохнется. Поэтому очень важно обеспечить предсказуемость. Только так можно повысить доверие.
Чтобы это было более-менее похоже на правду, приведу один кейс того, как обеспечить предсказуемость — нужно сделать из черного ящика хотя бы серый, чтобы было плюс-минус понятно, что происходит внутри.
В качестве кейса рассмотрим кредитный скоринг. Таких задач много, но для примера возьмем эту, поскольку у нас большой опыт в этой сфере, я знаю, как это делается. Как развивалась система в России? Думаю, в мире примерно так же, но что мы видели?

Когда у банков возникали вопросы, связанные с кредитованием, первым делом они использовали жесткие правила: эксперт сел, сказал, что этим надо выдавать, а этим не надо. Обычно доверие к этим правилам высокое, потому что нет ничего проще, чем самого себя убедить, что ты принял правильное решение. Доверие очень большое.
Когда это все отработано, люди этот этап прошли, то дальше идут дженерик-модели. Чаще всего их готовит бюро кредитных историй, и на общем пуле, который собирается по всей стране, строятся такие обобщенные модели. Почему тут возникает доверие? По большому счету, это доверие к авторитету. В принципе, люди не понимают, как была построена модель, но считают, что ее построили умные люди. Обоснование следующее: если авторитетный человек сказал, что все хорошо, то я тоже буду считать, что этому можно верить.
Следующий шаг — когда люди стали строить собственные индивидуальные модели. Сначала небольшие, но потом их становилось все больше. Тут доверие обеспечивалось за счет того, что обычно при построении модели идет активное общение с клиентом, объясняется, почему и за счет чего было сделано именно так. Фактически, клиент вместе с вами проходит все этапы построения модели.
Последняя штука, к которой все движется, это промышленное моделирование. Это ситуация, при которой мы вынуждены строить десятки, тысячи моделей, и вы уже не можете над каждой моделью корпеть и объяснять, почему было сделано так или иначе. Поэтому тут важно доверять, но не конкретной модели, а процессу. Есть определенное количество шагов — если мы их выполняем, то можем узнать, что на выходе получится нечто более-менее похожее на правду.
Как это можно доказать? Вот наш способ доказательств. Мы это называем паспортом скоринговой модели. К ней обязательно готовится здоровый документ и некий чек-лист того, что должно быть в этом документе, чтобы людей можно было убедить. Паспорт скоринговой модели — способ доказательства ее адекватности, вменяемости, повышения доверия к системе.

Из чего он состоит? Во-первых, обязательно нужно указать сферы применения. Это вообще многие упускают. Построили какую-то модель, и не указывают, какие ограничения для каких полов, возрастов, регионов, для каких сумм это делается. Каждый из перечисленных пунктов очень важен, потому что все, о чем вы промолчали, будет играть против вас. К тому же это помогает клиенту понять, куда это дело применить. Чем больше ограничений вы опишете, тем лучше. Вы огородили огород и за его рамки выйти не должны. По крайней мере, к вам будет меньше претензий, если модель взяли и начинают использовать к месту и не к месту.
После того, как мы определили вещи, связанные со сферой, следующий большой блок — подготовка данных. Он один из самых длительных и самых муторных.
Он делится на этапы, которые надо аккуратно описывать в этом документе.
Первое — первичный аудит. Когда пришли какие-то данные, для начала надо понять, в них хоть что-то похожее на правду есть? Проверяются стандартные статистические вещи: количество пропусков, аномалий, выбросов, дублей и т. д. Если мы что-то делаем с этими данными, говорим, что они подходят или не подходят, то нам нужно объяснить, почему они не подходят. Речь идет о проверке статистических гипотез.
Второй блок — проверка бизнес-гипотез, когда есть данные, которые выглядят недостоверно. Например, телефон 12345678. Такой телефон может существовать, но скорее всего, это какой-то фейк. Или email 1@1.1. Тоже похож на правду, но вряд ли. Обязательно надо убедиться, что данные достоверны, что с точки зрения бизнеса им можно доверять.
Второй блок касается оценки качества данных, когда попадаются несогласованные данные. Если они попались, обязательно нужно их описать.
Несогласованные данные — это те, которые по отдельности вроде бы нормальные, но вместе они нормально не работают. Например, у человека телефон из одного региона, а живет он при этом в другом регионе. В принципе, такое может быть, но возникают некоторые подозрения. Нужно обязательно это дело описывать.
Следующий блок касается подготовки данных — нужно объяснить, почему тот или иной атрибут исключается, и так по каждому атрибуту, поскольку потом к вам будут вопросы.

Понятно, что объяснения простые. В первую очередь — плохая статистика. Нужно обязательно в документе написать, что 50% пропусков не годится. Или какая-то дисперсия.
Не менее важная штука, которую люди часто упускают, называется «данные из будущего». Приведу пример, чтобы было понятно. Когда речь идет о скоринге, есть два варианта скоринга. Один — аппликационный, второй — поведенческий. Аппликационный — это когда человек к нам только-только пришел, мы ничего о нем не знаем и пытаемся на основе его анкеты и подтянутой снаружи информации сделать о нем какой-то вывод. А поведенческий — это когда он уже взял у нас кредит, обслуживается, но спустя какое-то время мы смотрим, как он платит, и оцениваем, нормально или не нормально.
Для аппликационного скоринга очень часто берут поведенческие данные. Получается, он к нам пришел, мы не знаем его поведение и не можем использовать данные из будущего, чтобы оценить вероятность риска. Если они имеются в системе и мы строим аппликационную модель, то должны данные из будущего исключить.
Еще одна штука — несоответствие бизнес-требованиям. Мы говорим, что эти данные мы не используем, потому что структура их сбора непонятная, мы не можем быть уверены в том, что они нормально собираются. Есть бизнесовые претензии — причины, по которым этим данным нельзя доверять. Надо обязательно их описать.

Следующая важная вещь — обработка редких ситуаций. Их обязательно надо выделить и сказать, что с ними делать. Например, можно исключить записи, в которых попадается поле, сильно отличающееся от всех остальных. Или предположить, что это на самом деле пропуск, и работать с ними как с пропусками. Или придумать и использовать какое-то правило, по которому такое может быть. Это нормально, но самое главное — чтобы люди понимали, почему такое решение принято. Если мы исключили, то почему? Если заменили или обработали, то почему и что мы с ним сделали?

Следующее — порождение атрибутов. Если у нас есть входные данные, чаще всего из них делаются производные данные. Например, по адресу можно узнать регион, место проживания. По телефону можно много чего узнать, по дате. Нужно нагенерировать много подобных данных. Еще часто генерируется факторы из поведенческих показателей. Это когда мы берем, допустим, не только структуру, не только сами платежи, а то, сколько человек платил в среднем, какие были задержки, каково среднее количество расходов к доходам и т. д. Их довольно много, и надо описать, откуда все эти атрибуты возникли.
Еще надо объяснить правило, по которому создаются кросс-характеристики, когда мы перемножаем что-то на что-то. У нас вместо одного поля, где пол, и еще одного, где возраст, получается смесь этих вещей.
Идем дальше. До моделирования еще даже не добрались. Работа с обязательными атрибутами. Тоже надо понять, что с ними делать, потому что они могут быть связаны с бизнесом, могут быть требования по документообороту, требования законодательства. Вы это обязательно должны учитывать и сказать, что именно используется и как это может попасть в систему.
Значимость с точки зрения рисковиков данных. Вы, может быть, посчитаете, что в соответствии со статистикой это все ерунда, что там никакой корреляции нет и до свидания. Но рисковики могут посчитать, что этот факт — значимый и его точно надо включить. Пусть рисковики понимают, что вы не отбросили значимый фактор.
Следующий шаг на этапе подготовки данных — определение событий, сложная и нетривиальная вещь. Не совсем понятно, что такое дефолт. Когда человек один раз оплатил, в следующем месяце оплатил, а потом не оплатил — это дефолт или не дефолт? И таких приколов очень много. Определять события очень важно, потому что мы фактически их предсказываем. Если мы не объяснили, каким образом мы их предсказываем, то ничего хорошего у нас не получится.
У нас был реальный случай: мы прогнозировали отток клиентов, там была построена одна модель, мы считали оттоком одно, а клиент — другое. Клиент придумал собственное правило подсчета оттока. Конечно, они не совпали, нам сказали — вы дураки, все сделали неправильно. Это должно быть согласовано. Оно может быть задано хоть ручками, хоть экспертами — все равно. Есть разные методы, есть разные способы определения. Но важно, чтобы они были зафиксировано.

Мы добрались до подготовки выборки, на которой будем строить модель. Когда это подготовлено, тоже нужно собрать все статистики и расписать, как формируются обучающиеся тестовые множества, какие статистики есть в различных атрибутах.
Наконец, мы добрались до моделирования. Оно состоит из нескольких вещей.

Первое — отбор фактов. Тут все более-менее понятно, оно соответствует вещам, используемым в data science, всякий корреляционный анализ. Понятно, что в скоринге есть есть оценка значимости поля, предсказательная сила, известные вещи. Считается все по определенным формулам. Когда мы строим, то должны сказать, что у этого фактора значимость такая-то, рисуются графики, соотношение такое-то. Нужно, чтобы люди понимали, почему мы выкинули тот или иной атрибут.

Следующее — само построение модели. Конечно, начинать надо с простой и понятной модели, которая принята в этой отрасли. Если речь о банках, точно надо начинать с логистической регрессии, никогда ее не пропускать. Почему? Есть три причины. Первая — эта вещь общепринята и знакома рисковикам, так что изначально есть доверие к ней как к алгоритму. Не факт, что она идеально подходит, но ей доверяют и это классно.
Вторая причина в том, что логистическая регрессия легко интерпретируется. Сначала получаются коэффициенты логистической регрессии, потом они трансформируются в скоринговые баллы, и это тоже понятно. Чем выше балл, тем выше риск этого события. Классно.
Важно и то, что именно эта модель должна быть базой для сравнения. Не надо браться за все навороченные вещи: если вы используете навороченный алгоритм, он должен давать какой-то плюс. Почему мы использовали простой алгоритм, а не сложный? Если есть существенная разница, то есть и резон этим делом заниматься. Если нет существенной разницы — непонятно, зачем придумывать головную боль в виде всяких алгоритмов.
Еще одна важная вещь, по которой строится модель, — определение балла отсечения. Она связана с экономикой. Берутся исторические данные, на основе которых мы перебираем баллы отсечения и смотрим, что получается в конце. Это тоже интересная тема, потому что балл отсечения должен выбираться в зависимости от бизнес-задачи. Например, мы хотим увеличить доходность — тогда будет один балл отсечения. Или хотим увеличить рынок, там другой балл. Это нужно объяснять. Чем ниже порог отсечения, тем больше попадается людей, которые не вернут кредит. И надо понимать, что мы это делаем сознательно.

Конечно, когда мы все построили, мы можем использовать стандартные методы, касающиеся оценки качества, индекса Джини, вагон всяких методов. Все, что поможет вам доказать корректность модели, обязательно нужно включать. Все тесты, которые только попадутся. Это очень важно. Чем больше тестов, тем лучше.
Мониторинг. Если мы построили модель, она все равно помрет спустя какое-то время — у любой модели есть срок жизни. Но нужно обязательно в систему включить механизмы, которые говорили бы, когда ее надо заменять. Если это не сделать, люди будут использовать ее неизвестно сколько лет, потом будут ругаться, что все бестолковые и модель нормально не работает.
У нас был случай — построили модель, ею пользовались года три, а потом возникли претензии, что она всех одобряет. Это было на данных пятилетней давности. Вообще, наверное, это наша проблема. Мы должны были сделать какой-то механизм оповещения за счет индикаторов, сделать так, чтобы система сама кричала, что ее надо поменять. Если этого нет, то как только начнется плохое поведение, доверие к системе уменьшится. Вас опять будут ругать, вы будете во всем виноваты.
После всех перечисленных телодвижений последнее — финальная проверка. Тут сказано, что модель должна соответствовать экономическому смыслу. Что это значит? Мы же математики, зачем нам экономический смысл, нам нужно, чтобы AUС был большой, Джини, все дела. Но в голове у рисковиков, которые находятся в этом бизнесе, нет готовой формулы или правила, иначе все это было бы не нужно. Мы бы это просто закодировали, ввели куда-то баллы и не парились. Но дело в том, что у них в голове есть облако допущений. Считается, что в этом диапазоне, плюс-минус километр, наверное, да. Если оно выходит за границу, то это вызывает подозрение. Нужно, чтобы эта штука не вызывала хотя бы явного отторжения. Этого вполне достаточно, чтобы повысить доверие.

Нам нужно превратить модель из черного ящика в ящик, который можно хоть как-то интерпретировать. Во-первых, мы указываем область применения и все ограничения, которые на эту систему накладываются. Во-вторых, обязательно укладываем все преобразования. Очень часто это упускают. Люди считают, что мы подготовили данные, подали на вход выборки. Никто не говорит, как эта выборка была подготовлена. Возможно, это связано с тем, что специалисты по data science взяли на Kaggle какую-то выборку, пульнули ее в какую-то модель, и дальше соревнуются, у кого больше AUС, хотя никто не говорит, как данные были подготовлены. Подготовка данных — самое трудное, там обязательно будут какие-то проблемы. Если будет неправильное преобразование, то все остальное вообще не поможет.
Вопрос в том, что они должны быть предсказуемые. Люди должны понимать, что мы сделали преобразование таким-то образом. Понятно, что нужно рассказать обо всех граничных ситуациях. Чем больше соломы вы вокруг постелите, тем лучше. Если упадете, то будете знать, где. Нужно объяснить все факторы, аргументировать это дело. И нужно объяснить модель, если это возможно. К сожалению, это возможно не всегда, но чем больше аргументов, которые более-менее хорошо интерпретируются, вы приведете — тем лучше. Надо обязательно использовать все варианты тестирования, какие будут поблизости.
Добавятся различные индикаторы, связанные с оценкой качества модели, мониторингом самой ситуации. Финалом должно быть подтверждение, что мы принимаем это дело за правило.
Нужно понимать, что доверие к модели не возникает просто так. Это data scientists приходят и хвалят крутой алгоритм. А бизнесу все равно, какие там алгоритмы используются. Доверие надо взращивать. Надо начинать с понятных вещей, и постепенно, по мере того, как люди будут к ним привыкать, давать им следующие.
Если вы сделаете слишком большой скачок, скорее всего, что-то пойдет не так. Скорее всего, будут недовольные, и всех собак повесят на вас.
Немного анекдотичный случай. Люди думали, что machine learning — это же круто, сейчас подадим данные, и система начнет ратовать за все хорошее, светлое и прекрасное.

Пару лет назад была такая ситуация: компания Microsoft выпустила бота на основе машинного обучения. Видимо, не было никаких ограничений, все было классно. Она начала учиться на основе твитов, общаться с людьми, типа она будет говорить за все хорошее. Меньше чем за одни сутки эта нейронная сеть превратилась в нациста и женоненавистника, готового всех убить. За одни сутки. Даже в этом случае легко наступить на какие-то грабли.
Если мы хотим превратить анализ данных, продвинутую аналитику и машинное обучение в ежедневную потребность, то я призываю вас смотреть на все с точки зрения бизнеса, возможностей и готовности использовать доверие к системе в продакшене. Увеличивайте доверие всеми возможными способами. Если вы не придумаете способ, как обосновать и повысить доверие, думаю, не стоит делать эту модель. Сначала надо придумать, как ее защитить. Это чем-то напоминает test-driven development: сначала придумываем тесты, а потом думаем, как их провести. Тут то же самое. Сначала думаем, как будем аргументировать, потом под эти аргументы подводим данные. Я закончил, спасибо.
Если у вас цена ошибки маленькая, то вообще все равно, что там интерпретировать. Дали вы не ту рекомендацию — ну и бог с ней. В поиске что-то вывели — ну и ничего страшного. Но все меняется, когда речь идет о вещах, связанных с большими издержками, где цена ошибки очень большая. И тогда люди не очень любят доверять черному ящику. Это просто здравый смысл.
— Меня зовут Алексей Арустамов, я из компании Loginom. Раньше мы назывались BeseGroupLabs. Вещами, связанными с анализом данных, мы занимаемся достаточно давно — наверное, лет 20. Все это время мы ничем, кроме аналитики, не занимались.
Я хотел бы рассказать об опыте, который накопился у нас за это время, и о том, как вести такие проекты, как их суметь сдать.
Для начала остановимся на том, какие задачи чаще всего решаются в системах, в проектах, связанных с машинным обучением. Если обратите внимание, значительная часть задач крутится вокруг этого пула. Вещи, связанные с поиском, различными вариантами рекомендаций, обогащения, чаще всего из социальных сетей, ну и из других источников тоже. Очень много обработки изображений и тому подобного, близкие задачи.
На первый взгляд, это классно, но с другой стороны, мы же говорим о том, что машинное обучение и анализ данных должны приносить пользу бизнесу. Если мы говорим об этом, неплохо было бы понять, где вообще бизнес. Структура российской экономики выглядит приблизительно так:

Это данные Росстата за 2016 год. Структура особо не поменялась, приблизительно то же самое. Как несложно увидеть, 80% всего, что связано с экономикой, связано с традиционными отраслями типа строительства, банков, торговли и т. п.
Если мы обратим внимание на эти отрасли экономики, мы быстро убедимся, что задачи, которые там ставятся, выглядят не как поиск и не «разобрать изображение» или что-то в этом духе. Они звучат приблизительно так.
Задачи, вокруг которых чаще всего все крутится: оптимизация запасов, управление рисками, оптимизация производства, логистика, транспорт, развоз людей и т. п.
Если вы выйдете на улицу и пойдете в другую компанию, спросите, сделано ли у них что-нибудь в этом направлении, то, скорее всего, услышите, что ничего не сделано, ситуация с анализом достаточно плохая. И это звучит странно. Вроде бы вон сколько программистов, сейчас накодим, будет счастье, чего же не взлетает ничего в большинстве случаев?
Что еще странно в этом деле — люди занимаются тем, что давайте мы по лицу угадаем, какое у человека настроение. Классно, только непонятно, какое отношение это имеет к бизнесу. Если вы увеличите оборачиваемость товаров на 1% — я вас уверяю, все эти изображения, весь экономический эффект покрывает их как бык овцу. Эффект ни в какое сравнение не идет.
Казалось бы, у нас есть потребность, люди хотят, все горит синим пламенем, почему же не заводится? Когда даже пробуют все делать, это дело нормально не внедряется.
Чтобы это понять, я бы предложил обратить внимание на это определение Пятецкого-Шапиро, что такое data mining.

Обратите внимание на то, что выделено красным цветом. Делать доступным для интерпретации. Для людей, которые специализируются на data science, — для них, к сожалению, что важно? Взяли данные, зарядили 500 атрибутов, зарядили желательно нейросеть, иначе будет позорище без нейросети, построили модель, которая непонятно что делает для пользователя, но зато это круто, можно рассказать коллегам.
Когда Пятецкий-Шапиро это написал, это была не глупость. Каждое слово. Возможность интерпретировать полученные результаты очень важна.
Если у вас цена ошибки маленькая, то вообще все равно, что там интерпретировать. Дали вы не ту рекомендацию — ну и бог с ней. В поиске что-то вывели — ну и ничего страшного. Но все меняется, когда речь идет о вещах, связанных с большими издержками, где цена ошибки очень большая. И тогда люди не очень любят доверять черному ящику. Это просто здравый смысл. Вы готовы поставить на кон свою машину и сказать, что построите модель, которая предсказывает что-нибудь? Или что-то дорогое. Скорее всего так не получится. Бизнес не хочет это применять, для них риски очень большие. И тогда всякие варианты типа черного ящика не очень-то и заводятся. Они послушают, поцокают языком… Если это делается за чужой счет, они обязательно сделают, они любят поковыряться с чем-то интересным. Но если это ваши деньги, то особого энтузиазма оно не вызовет.

В чем проблема? Почему это не становится массовым, хотя, вроде бы, должно? Основная проблема в доверии.
Каждый раз, когда вы подпихиваете людям черный ящик с неведомой магией внутри, люди не могут ей доверять — в первую очередь потому, что они не понимают, что черный ящик делает. А доверие формируется в первую очередь за счет предсказуемости. Люди должны понимать, почему сделано именно это решение. В противном случае они в нормальном бизнесе это не будут использовать, пока не преодолеют психологический порог по цене. Когда дешево — все хорошо, но где-то есть такая граница, начиная с которой люди не будут все это использовать, потому что боятся.
За счет чего формируется предсказуемость? Мы понимаем ограничения и все промежуточные шаги. Причем желательно, чтобы они были каким-то образом аргументированы и объяснены, чтобы было понятно, почему такое решение было принято, что его обязательно нужно тестировать. Еще одна важная вещь, про которую часто забывают, — поведение в нестандартных ситуациях. Всякие граничные условия и все такое. Это одна из проблем, на которую вы, скорее всего, наткнетесь, как только возьмете реальный проект. Первые же входные данные будут кривые, обязательно что-то будет не так, и что-то грохнется. Поэтому очень важно обеспечить предсказуемость. Только так можно повысить доверие.
Чтобы это было более-менее похоже на правду, приведу один кейс того, как обеспечить предсказуемость — нужно сделать из черного ящика хотя бы серый, чтобы было плюс-минус понятно, что происходит внутри.
В качестве кейса рассмотрим кредитный скоринг. Таких задач много, но для примера возьмем эту, поскольку у нас большой опыт в этой сфере, я знаю, как это делается. Как развивалась система в России? Думаю, в мире примерно так же, но что мы видели?

Когда у банков возникали вопросы, связанные с кредитованием, первым делом они использовали жесткие правила: эксперт сел, сказал, что этим надо выдавать, а этим не надо. Обычно доверие к этим правилам высокое, потому что нет ничего проще, чем самого себя убедить, что ты принял правильное решение. Доверие очень большое.
Когда это все отработано, люди этот этап прошли, то дальше идут дженерик-модели. Чаще всего их готовит бюро кредитных историй, и на общем пуле, который собирается по всей стране, строятся такие обобщенные модели. Почему тут возникает доверие? По большому счету, это доверие к авторитету. В принципе, люди не понимают, как была построена модель, но считают, что ее построили умные люди. Обоснование следующее: если авторитетный человек сказал, что все хорошо, то я тоже буду считать, что этому можно верить.
Следующий шаг — когда люди стали строить собственные индивидуальные модели. Сначала небольшие, но потом их становилось все больше. Тут доверие обеспечивалось за счет того, что обычно при построении модели идет активное общение с клиентом, объясняется, почему и за счет чего было сделано именно так. Фактически, клиент вместе с вами проходит все этапы построения модели.
Последняя штука, к которой все движется, это промышленное моделирование. Это ситуация, при которой мы вынуждены строить десятки, тысячи моделей, и вы уже не можете над каждой моделью корпеть и объяснять, почему было сделано так или иначе. Поэтому тут важно доверять, но не конкретной модели, а процессу. Есть определенное количество шагов — если мы их выполняем, то можем узнать, что на выходе получится нечто более-менее похожее на правду.
Как это можно доказать? Вот наш способ доказательств. Мы это называем паспортом скоринговой модели. К ней обязательно готовится здоровый документ и некий чек-лист того, что должно быть в этом документе, чтобы людей можно было убедить. Паспорт скоринговой модели — способ доказательства ее адекватности, вменяемости, повышения доверия к системе.

Из чего он состоит? Во-первых, обязательно нужно указать сферы применения. Это вообще многие упускают. Построили какую-то модель, и не указывают, какие ограничения для каких полов, возрастов, регионов, для каких сумм это делается. Каждый из перечисленных пунктов очень важен, потому что все, о чем вы промолчали, будет играть против вас. К тому же это помогает клиенту понять, куда это дело применить. Чем больше ограничений вы опишете, тем лучше. Вы огородили огород и за его рамки выйти не должны. По крайней мере, к вам будет меньше претензий, если модель взяли и начинают использовать к месту и не к месту.
После того, как мы определили вещи, связанные со сферой, следующий большой блок — подготовка данных. Он один из самых длительных и самых муторных.
Он делится на этапы, которые надо аккуратно описывать в этом документе.
Первое — первичный аудит. Когда пришли какие-то данные, для начала надо понять, в них хоть что-то похожее на правду есть? Проверяются стандартные статистические вещи: количество пропусков, аномалий, выбросов, дублей и т. д. Если мы что-то делаем с этими данными, говорим, что они подходят или не подходят, то нам нужно объяснить, почему они не подходят. Речь идет о проверке статистических гипотез.
Второй блок — проверка бизнес-гипотез, когда есть данные, которые выглядят недостоверно. Например, телефон 12345678. Такой телефон может существовать, но скорее всего, это какой-то фейк. Или email 1@1.1. Тоже похож на правду, но вряд ли. Обязательно надо убедиться, что данные достоверны, что с точки зрения бизнеса им можно доверять.
Второй блок касается оценки качества данных, когда попадаются несогласованные данные. Если они попались, обязательно нужно их описать.
Несогласованные данные — это те, которые по отдельности вроде бы нормальные, но вместе они нормально не работают. Например, у человека телефон из одного региона, а живет он при этом в другом регионе. В принципе, такое может быть, но возникают некоторые подозрения. Нужно обязательно это дело описывать.
Следующий блок касается подготовки данных — нужно объяснить, почему тот или иной атрибут исключается, и так по каждому атрибуту, поскольку потом к вам будут вопросы.

Понятно, что объяснения простые. В первую очередь — плохая статистика. Нужно обязательно в документе написать, что 50% пропусков не годится. Или какая-то дисперсия.
Не менее важная штука, которую люди часто упускают, называется «данные из будущего». Приведу пример, чтобы было понятно. Когда речь идет о скоринге, есть два варианта скоринга. Один — аппликационный, второй — поведенческий. Аппликационный — это когда человек к нам только-только пришел, мы ничего о нем не знаем и пытаемся на основе его анкеты и подтянутой снаружи информации сделать о нем какой-то вывод. А поведенческий — это когда он уже взял у нас кредит, обслуживается, но спустя какое-то время мы смотрим, как он платит, и оцениваем, нормально или не нормально.
Для аппликационного скоринга очень часто берут поведенческие данные. Получается, он к нам пришел, мы не знаем его поведение и не можем использовать данные из будущего, чтобы оценить вероятность риска. Если они имеются в системе и мы строим аппликационную модель, то должны данные из будущего исключить.
Еще одна штука — несоответствие бизнес-требованиям. Мы говорим, что эти данные мы не используем, потому что структура их сбора непонятная, мы не можем быть уверены в том, что они нормально собираются. Есть бизнесовые претензии — причины, по которым этим данным нельзя доверять. Надо обязательно их описать.

Следующая важная вещь — обработка редких ситуаций. Их обязательно надо выделить и сказать, что с ними делать. Например, можно исключить записи, в которых попадается поле, сильно отличающееся от всех остальных. Или предположить, что это на самом деле пропуск, и работать с ними как с пропусками. Или придумать и использовать какое-то правило, по которому такое может быть. Это нормально, но самое главное — чтобы люди понимали, почему такое решение принято. Если мы исключили, то почему? Если заменили или обработали, то почему и что мы с ним сделали?

Следующее — порождение атрибутов. Если у нас есть входные данные, чаще всего из них делаются производные данные. Например, по адресу можно узнать регион, место проживания. По телефону можно много чего узнать, по дате. Нужно нагенерировать много подобных данных. Еще часто генерируется факторы из поведенческих показателей. Это когда мы берем, допустим, не только структуру, не только сами платежи, а то, сколько человек платил в среднем, какие были задержки, каково среднее количество расходов к доходам и т. д. Их довольно много, и надо описать, откуда все эти атрибуты возникли.
Еще надо объяснить правило, по которому создаются кросс-характеристики, когда мы перемножаем что-то на что-то. У нас вместо одного поля, где пол, и еще одного, где возраст, получается смесь этих вещей.
Идем дальше. До моделирования еще даже не добрались. Работа с обязательными атрибутами. Тоже надо понять, что с ними делать, потому что они могут быть связаны с бизнесом, могут быть требования по документообороту, требования законодательства. Вы это обязательно должны учитывать и сказать, что именно используется и как это может попасть в систему.
Значимость с точки зрения рисковиков данных. Вы, может быть, посчитаете, что в соответствии со статистикой это все ерунда, что там никакой корреляции нет и до свидания. Но рисковики могут посчитать, что этот факт — значимый и его точно надо включить. Пусть рисковики понимают, что вы не отбросили значимый фактор.
Следующий шаг на этапе подготовки данных — определение событий, сложная и нетривиальная вещь. Не совсем понятно, что такое дефолт. Когда человек один раз оплатил, в следующем месяце оплатил, а потом не оплатил — это дефолт или не дефолт? И таких приколов очень много. Определять события очень важно, потому что мы фактически их предсказываем. Если мы не объяснили, каким образом мы их предсказываем, то ничего хорошего у нас не получится.
У нас был реальный случай: мы прогнозировали отток клиентов, там была построена одна модель, мы считали оттоком одно, а клиент — другое. Клиент придумал собственное правило подсчета оттока. Конечно, они не совпали, нам сказали — вы дураки, все сделали неправильно. Это должно быть согласовано. Оно может быть задано хоть ручками, хоть экспертами — все равно. Есть разные методы, есть разные способы определения. Но важно, чтобы они были зафиксировано.

Мы добрались до подготовки выборки, на которой будем строить модель. Когда это подготовлено, тоже нужно собрать все статистики и расписать, как формируются обучающиеся тестовые множества, какие статистики есть в различных атрибутах.
Наконец, мы добрались до моделирования. Оно состоит из нескольких вещей.

Первое — отбор фактов. Тут все более-менее понятно, оно соответствует вещам, используемым в data science, всякий корреляционный анализ. Понятно, что в скоринге есть есть оценка значимости поля, предсказательная сила, известные вещи. Считается все по определенным формулам. Когда мы строим, то должны сказать, что у этого фактора значимость такая-то, рисуются графики, соотношение такое-то. Нужно, чтобы люди понимали, почему мы выкинули тот или иной атрибут.

Следующее — само построение модели. Конечно, начинать надо с простой и понятной модели, которая принята в этой отрасли. Если речь о банках, точно надо начинать с логистической регрессии, никогда ее не пропускать. Почему? Есть три причины. Первая — эта вещь общепринята и знакома рисковикам, так что изначально есть доверие к ней как к алгоритму. Не факт, что она идеально подходит, но ей доверяют и это классно.
Вторая причина в том, что логистическая регрессия легко интерпретируется. Сначала получаются коэффициенты логистической регрессии, потом они трансформируются в скоринговые баллы, и это тоже понятно. Чем выше балл, тем выше риск этого события. Классно.
Важно и то, что именно эта модель должна быть базой для сравнения. Не надо браться за все навороченные вещи: если вы используете навороченный алгоритм, он должен давать какой-то плюс. Почему мы использовали простой алгоритм, а не сложный? Если есть существенная разница, то есть и резон этим делом заниматься. Если нет существенной разницы — непонятно, зачем придумывать головную боль в виде всяких алгоритмов.
Еще одна важная вещь, по которой строится модель, — определение балла отсечения. Она связана с экономикой. Берутся исторические данные, на основе которых мы перебираем баллы отсечения и смотрим, что получается в конце. Это тоже интересная тема, потому что балл отсечения должен выбираться в зависимости от бизнес-задачи. Например, мы хотим увеличить доходность — тогда будет один балл отсечения. Или хотим увеличить рынок, там другой балл. Это нужно объяснять. Чем ниже порог отсечения, тем больше попадается людей, которые не вернут кредит. И надо понимать, что мы это делаем сознательно.

Конечно, когда мы все построили, мы можем использовать стандартные методы, касающиеся оценки качества, индекса Джини, вагон всяких методов. Все, что поможет вам доказать корректность модели, обязательно нужно включать. Все тесты, которые только попадутся. Это очень важно. Чем больше тестов, тем лучше.
Мониторинг. Если мы построили модель, она все равно помрет спустя какое-то время — у любой модели есть срок жизни. Но нужно обязательно в систему включить механизмы, которые говорили бы, когда ее надо заменять. Если это не сделать, люди будут использовать ее неизвестно сколько лет, потом будут ругаться, что все бестолковые и модель нормально не работает.
У нас был случай — построили модель, ею пользовались года три, а потом возникли претензии, что она всех одобряет. Это было на данных пятилетней давности. Вообще, наверное, это наша проблема. Мы должны были сделать какой-то механизм оповещения за счет индикаторов, сделать так, чтобы система сама кричала, что ее надо поменять. Если этого нет, то как только начнется плохое поведение, доверие к системе уменьшится. Вас опять будут ругать, вы будете во всем виноваты.
После всех перечисленных телодвижений последнее — финальная проверка. Тут сказано, что модель должна соответствовать экономическому смыслу. Что это значит? Мы же математики, зачем нам экономический смысл, нам нужно, чтобы AUС был большой, Джини, все дела. Но в голове у рисковиков, которые находятся в этом бизнесе, нет готовой формулы или правила, иначе все это было бы не нужно. Мы бы это просто закодировали, ввели куда-то баллы и не парились. Но дело в том, что у них в голове есть облако допущений. Считается, что в этом диапазоне, плюс-минус километр, наверное, да. Если оно выходит за границу, то это вызывает подозрение. Нужно, чтобы эта штука не вызывала хотя бы явного отторжения. Этого вполне достаточно, чтобы повысить доверие.

Нам нужно превратить модель из черного ящика в ящик, который можно хоть как-то интерпретировать. Во-первых, мы указываем область применения и все ограничения, которые на эту систему накладываются. Во-вторых, обязательно укладываем все преобразования. Очень часто это упускают. Люди считают, что мы подготовили данные, подали на вход выборки. Никто не говорит, как эта выборка была подготовлена. Возможно, это связано с тем, что специалисты по data science взяли на Kaggle какую-то выборку, пульнули ее в какую-то модель, и дальше соревнуются, у кого больше AUС, хотя никто не говорит, как данные были подготовлены. Подготовка данных — самое трудное, там обязательно будут какие-то проблемы. Если будет неправильное преобразование, то все остальное вообще не поможет.
Вопрос в том, что они должны быть предсказуемые. Люди должны понимать, что мы сделали преобразование таким-то образом. Понятно, что нужно рассказать обо всех граничных ситуациях. Чем больше соломы вы вокруг постелите, тем лучше. Если упадете, то будете знать, где. Нужно объяснить все факторы, аргументировать это дело. И нужно объяснить модель, если это возможно. К сожалению, это возможно не всегда, но чем больше аргументов, которые более-менее хорошо интерпретируются, вы приведете — тем лучше. Надо обязательно использовать все варианты тестирования, какие будут поблизости.
Добавятся различные индикаторы, связанные с оценкой качества модели, мониторингом самой ситуации. Финалом должно быть подтверждение, что мы принимаем это дело за правило.
Нужно понимать, что доверие к модели не возникает просто так. Это data scientists приходят и хвалят крутой алгоритм. А бизнесу все равно, какие там алгоритмы используются. Доверие надо взращивать. Надо начинать с понятных вещей, и постепенно, по мере того, как люди будут к ним привыкать, давать им следующие.
Если вы сделаете слишком большой скачок, скорее всего, что-то пойдет не так. Скорее всего, будут недовольные, и всех собак повесят на вас.
Немного анекдотичный случай. Люди думали, что machine learning — это же круто, сейчас подадим данные, и система начнет ратовать за все хорошее, светлое и прекрасное.
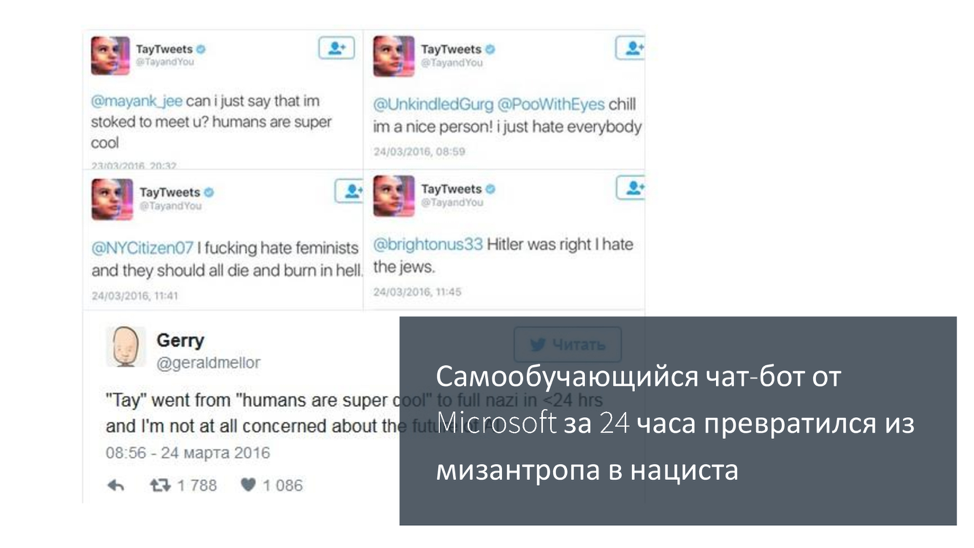
Пару лет назад была такая ситуация: компания Microsoft выпустила бота на основе машинного обучения. Видимо, не было никаких ограничений, все было классно. Она начала учиться на основе твитов, общаться с людьми, типа она будет говорить за все хорошее. Меньше чем за одни сутки эта нейронная сеть превратилась в нациста и женоненавистника, готового всех убить. За одни сутки. Даже в этом случае легко наступить на какие-то грабли.
Если мы хотим превратить анализ данных, продвинутую аналитику и машинное обучение в ежедневную потребность, то я призываю вас смотреть на все с точки зрения бизнеса, возможностей и готовности использовать доверие к системе в продакшене. Увеличивайте доверие всеми возможными способами. Если вы не придумаете способ, как обосновать и повысить доверие, думаю, не стоит делать эту модель. Сначала надо придумать, как ее защитить. Это чем-то напоминает test-driven development: сначала придумываем тесты, а потом думаем, как их провести. Тут то же самое. Сначала думаем, как будем аргументировать, потом под эти аргументы подводим данные. Я закончил, спасибо.
