
Поговорим о взаимодействии разработчика с ручными и автоматическими тестировщиками. Тимлид команды разработки в Маркете Юрий Акатов yuraaka рассказал о том, как создать платформу модульных автотестов и интегрировать её в процесс релиза, о проблемах нагрузочного тестирования и автоматизации, а также об отладке кода на продакшене и минимизации ущерба от непойманных багов, которые прокрадываются в релиз.

— Всем привет. Меня зовут Юра, я около семи лет работаю в поиске Маркета. Сегодня мы с вами поговорим о нашем опыте, о том, как мы организовали процессы и инструментарий, чтобы быстро разрабатываться и не падать.
В поиске Маркета более тысячи серверов, которые обрабатывают десятки тысяч RPS от пользователей. Ответ формируется из индекса в сотни миллионов документов и приходит пользователю за сотни миллисекунд. При этом мы катаем релизы несколько раз в день. Наш бизнес очень конкурентный, он требует высокой скорости доставки фич. И цена недоступности сервиса чрезвычайно высока. Мой доклад будет разделен на четыре части. В первой поговорим о подходах к функциональному тестированию; во второй — обсудим нагрузочное тестирование; в третьей я расскажу, как устроен наш релизный процесс; в четвертой части поговорим о том, что мы делаем сейчас и что хотим получить в ближайшем будущем.
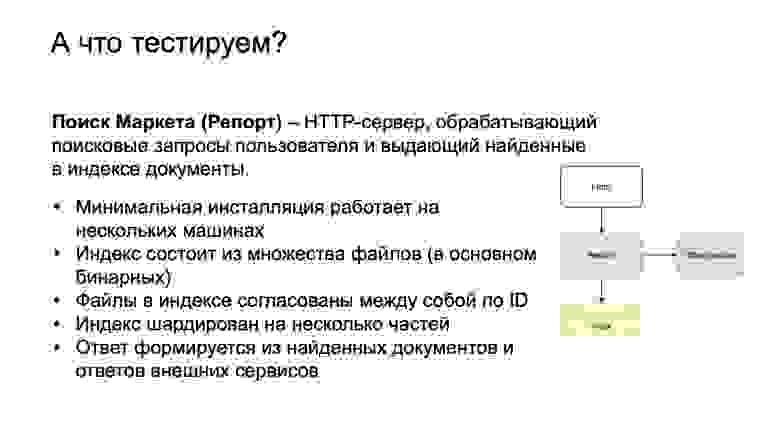
Итак, поехали. Наш компонент — поиск Маркета. Внутри мы его также называем Репорт. Это исторически сложившееся название. Представляет он из себя HTTP-сервер, который обрабатывает поисковые запросы пользователя и выдает найденные документы. В случае Маркета это товарные предложения либо модели.
Справа — упрощенная схема, front — это наш фронтенд. Он посылает запросы в Репорт. Репорт ищет в индексе товарные предложения, офферы. А также обогащает выдачу информацией от сторонних сервисов и выдает все это обратно на front в качестве результата ответа.
Минимальная инсталляция работает на нескольких машинах. То есть это не локальная программа. У нас есть такое понятие, как мини-кластер. Состоит он из нескольких машин. Индекс строится из множества файлов, в основном бинарных. В этих файлах лежит информация о наших бизнес-сущностях, категориях, магазинах, моделях, офферах, которые связаны между собой по идентификаторам. Индекс шардирован на несколько частей, потому что он очень большой и в память одной машины не помещается.

В качестве подхода к функциональному тестированию мы придумали систему под названием LITE — lightweight integration test environment. На самом деле на момент придумки она была системой не интеграционного тестирования, а только модульного, то есть тестировала только один компонент Репорт.
Устроена она следующим образом. Разработчик пишет Test suite, это какая-то настройка тестового окружения и несколько тестов на этом окружении. В настройке окружения он прописывает, индекс какой именно конфигурации и, вообще, какие данные под Репортом он хочет иметь в очень лаконичной и минималистичной форме. Например, вполне валидно будет написать — я хочу в индексе иметь один оффер с тайтлом iPhone. И больше ничего не написать. LITE сам поймет, какие нужно построить сущности помимо этого оффера, свяжет их по автосгенерированным айдишникам, и получится согласованная система данных.
Индекс в бинарную форму, в продакшен-вид, переводит вспомогательная программа — Microindexer. Далее запускается Репорт, в тестах к нему подаются запросы и валидируется ответ. Хорошим тоном считается, когда происходит валидация в тестах только тех сущностей, которые были заданы в тесте, и ничего больше.

Каких успехов мы добились с помощью LITE? Мы полностью сами стали писать автотесты. Частота релизов выросла в среднем до пяти раз в неделю, иногда больше. Тесты стали гораздо стабильнее. Раньше тесты просто гонялись на очень волатильном окружении, где офферы менялись. Соответственно, выдача тестов тоже менялась, и иногда они падали не по делу.
Кроме того, мы внедрили LITE не просто как тест, но как фреймворк для разработки, то есть в помощь разработчику. Мы не заставляли никого писать тесты, это получилось само собой, потому что это дешевле, чем разворачивать инсталляцию Репорта на отдельном окружении. Там может быть до десяти машин, и окружение, понятно, довольно дорогое. Оно одно на многих разработчиков — надо стоять в очереди, ждать. Очень неудобно.
А в LITE можно сделать только то, что относится к разрабатываемой фиче, протестировать и не сломать другие тесты. Еще это будет прогоняться при каждом коммите. На текущий момент написано более 6 тысяч тестов. Они гоняются где-то 10 минут.

Но нам не всё удастся протестировать функциональными тестами, поэтому у нас есть теневой кластер. Работает он следующим образом. На балансере есть логика, которая зеркалирует запросы пользователя на выделенный кластер Репорта. Туда мы можем устанавливать все что угодно. Для Репорта мы устанавливаем туда продакшен-индекс и кастомный репорт, тот, который мы хотим протестировать. Дальше мы можем снимать метрики с этого теневого кластера и сравнивать с аналогичным продакшен-кластером.
Теневой кластер помог нам ускорить исследование инфраструктурных улучшений, которые довольно сложно делаются на живом проде и практически не делаются в тестах, производить сравнение «спина к спине» на одном потоке запросов. Репорт туда доставляется очень быстро.
Дальше у нас есть Стоп-кран. Это механизм быстрого включения и выключения в проде неких функциональных блоков. То есть в коде заводятся флажки, которые можно включать из внешнего сервиса. Как вы видите на схеме, разработчик может указывать значение флага во Flag storage, а также сферу его применимости через LUA выражение, чтобы не на весь прод, а на отдельный кластер, или на один DC, или на какое-нибудь хитрое пересечение.

Дальше процесс Репорта постоянно полит этот Flag storage, вычитывает выражение LUA, запускает его и определяет, нужно ли ему обрабатывать пришедшее значение флага. Если не нужно — выбрасывает, если нужно — включает его в приоритет обработки. Соответственно, время раскатки — это единицы секунд флага. Но есть и оборотная сторона: можно сломать весь прод без релизов, просто так взведя неудачный флаг. С этим мы боремся через инструкции. Мы составили правила, как можно включать флаги Стоп-крана, запретили включать какой-либо флаг на весь прод сразу, только постепенно. Смотрим на мониторинг и аккуратно двигаемся.

Наш компонент сервиса нагрузочного тестирования называется Market Kombat. Работает он по следующему принципу. Есть задача — нам нужно понять, нет ли регресса производительности между двумя релизами Репорта. Один релиз Репорта — это который крутится в проде, и мы знаем, что он хороший, потому что он там уже долго крутится и все метрики продакшена говорят, что все хорошо. Второй релиз — это тот, который хочет выкатиться в прод.
Разработчик через command line tool делает task. Task — это такое protobuf-сообщение, в котором он указывает, что именно он хочет протестировать: какие виды Репорта, индекса, запросов. Компонент, создающий нагрузку на сервер, называется Танк, а сами запросы называются «патроны», это у нас такой жаргонизм. Движок на Kombat-сервере разгребает эти task-и, настраивает окружение соответствующим образом. Достает патроны, индексы и Репорты, заказанные в task-е. Проводит сравнение и публикует отчет в Трекер в красивой форме.
То есть раньше разработчик страдал, пользуясь множеством скриптов. Все это было нестабильно, постоянно ломалось, окружение кто-то портил. С Kombat такой проблемы нет. Разработчик делает задачу, забывает, и через какое-то время ему приходит результат.
Также Kombat поддерживает не только тесты на деградацию, но и capacity по офферам (сколько офферов может влезть в индекс и не просадить наши SLA), а также максимально возможный RPS на мини-кластер. Это позволяет нам планировать заказ железа на будущее.
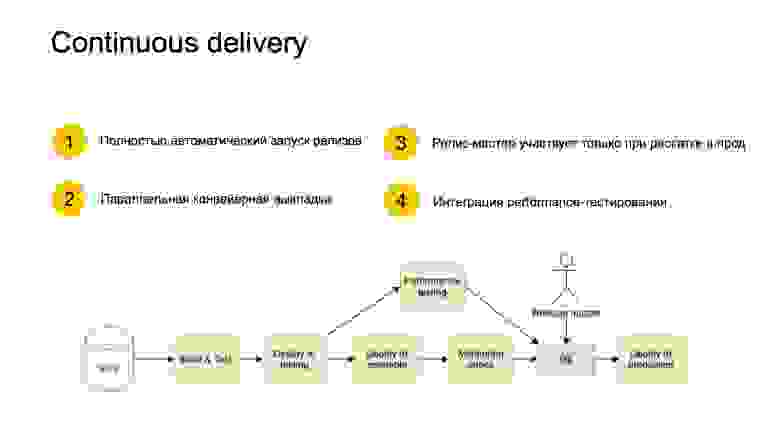
Теперь поговорим о том, как же устроен релизный процесс. Мы используем подход continuous delivery. У нас существует множество пайплайнов для выкатки сервисов. Репорт выкатывается по следующему принципу.
Разработчик коммитит в систему контроля версий. Дальше система continuous delivery замечает этот коммит. У нее есть условия, она может реагировать не на каждый коммит, а на пачку коммитов, чтобы зря не греть железо. Дальше она берет ревизию, назначает ее релизной и собирает на основе нее проект. Запускает тесты, деплоит тестовое окружение. Параллельно запускает перформанс-стрельбы, то есть делает запросы в Kombat, который мы только что обсудили. Пока стрельбы проходят, а они могут час проходить, деплой идет в prestable. Prestable — это такая маленькая часть продакшен-окружения. Там уже работают некие мониторинги. Мы смотрим, как новый релиз в prestable себя ведет, все ли хорошо. Когда все это закончилось, релиз-мастер принимает решение, можно ли раскатывать этот релиз в прод. Это единственное ручное вмешательство релиз-мастера.

Мы хотим изменить архитектуру Репорта в направлении микросервисов. Проблема в том, что Репорт — очень большой монолит со всеми вытекающими проблемами. Можно делать быстрее и лучше то, что сейчас в принципе и так неплохо делается. Отладка, деплой, тестирование и, вообще, развитие. Сейчас сложно переиспользовать подходы и технологии в Репорте, потому что он идет своим путем, потому что он очень большой, требует много железа и особого обращения в облаке. Под него выделяются целые железные машины. Ни о каком переиспользовании не идет речи.
Микросервисы в Яндексе принято делать на основе системы Apphost. Она хорошо описана на Хабре, вы можете о ней почитать. Суть в том, что сама логика сервисов разбивается на кучу мелких сервисов, которые пассивны по отношению к системе. Они сами никого никуда не вызывают, а просто сидят и слушают, пока их не вызовет Apphost. А в Apphost зашит график обхода. Пользователь задает, какие сервисы надо обходить и в каком порядке.
Но есть сложность с поиском: у нас есть некий слой бизнес-логики, который сидит очень глубоко в поиске и обрабатывает множество документов. Пока не очень понятно, как ее разделить на сервисы, но мы думаем над этим.
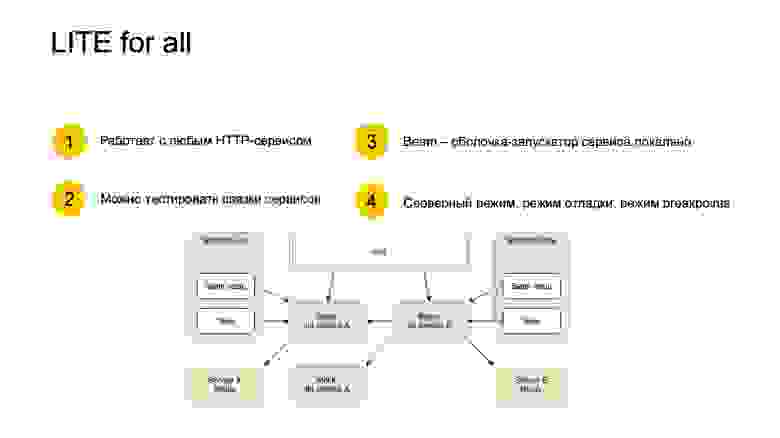
Также, чтобы успешно перейти на миросервисы, нам нужна платформа. И мы адаптировали систему тестирования LITE для работы с любым HTTP- и gRPS-сервисом. Мы внедрили Beam, оболочку-запускатор сервиса локально, которая требует zero configuration. То есть вы можете просто найти в какой-то директории и запустить Python-файл service.py, ничего не указывая, никаких аргументов. Он сам все сконфигурирует, выдаст минимальную конфигурацию и поднимет вам сервис. Вы можете пощупать его руками, посмотреть, что он выдает. Это такой пользовательский опыт — сервис легкий, его можно поднять.
Beam используется в Test suite. Таким образом мы можем поднимать внешние сервисы и сделать связку из них. На картинке мы, например, хотим тестировать сервис B, который ходит в сервис A в одном тесте. А в другом тесте мы не хотим тестировать честную связку, потому что на то, чтобы поднять сервис A и сервис B, все-таки уходит время. Мы можем вместо Beam сделать Mock, и это будет прозрачно, Beam сервиса B никак не изменится. И тестируются реальные бинарники, тут все по-честному.
Кроме того, LITE поддерживает серверный режим. Это значит, что если вы даете флажок -s, тест стартует в режиме сервера. Он подготавливает все данные, которые тест описал в секции prepare, и просто ждет запросов, а не прогоняет тесты по-настоящему.
Режим отладки — это когда вы стартуете тесты под GDB. GDB сразу запускается, когда вы Python-файл запускаете. Вы можете расставить breakpoint и продолжить выполнение. Режим breakpoints — это когда тест у вас спрашивает явные действия — например, нажать Enter перед каждым запросом. Вы можете посмотреть: если тест работает неправильно и вы не понимаете, почему, вы можете таким образом пошагово пройтись и посмотреть, на каком шаге тест ломается. Это прежде всего помогает в разработке.
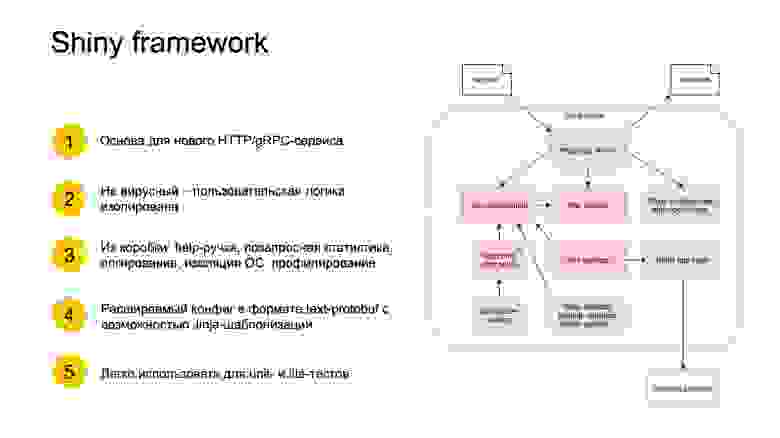
Чтобы разворачивать сервисы эффективно, нам нужна болванка для сервисов, чтобы мы могли прийти и начать писать ровно то, что нужно, то есть бизнес-логику, не думая обо всяких протоколах взаимодействия, логирования и прочей рутине.
Поэтому мы придумали так называемый Shiny framework. Он лежит в основе наших HTTP- и gRPC-сервисов. У нас есть такой инфраструктурный сервис — «сервис по кнопке». Это мастер, вы можете прокликать по кнопочкам, и для вас из шаблона поднимется сервис. Shiny предоставляет некий шаблон сервиса с одной ручкой, который запустится в облаке.
Shiny framework — не вирусный, то есть не заставляет вас и дальше его использовать. Вы можете быстро с него начать, но потом бизнес-логику легко очень вынуть в какой-нибудь другой фреймворк.
Вы из коробки получаете Help handler. Это, собственно, HTTP handler, который пишет вывод о том, какие еще ручки есть. Документация генерирутся автоматически. А дальше он собирает статистику по запросу, интегрирует сервер в наши внутренние системы мониторинга. Логирование, изоляция ОС для удобного написания юнит-тестов и профилирование. Мы используем два вида профилирования, это перф и наш собственный инструментированный профилировщик — макросами расставляем функции, чтобы потом красиво рисовался html.
Shiny имеет расширяемый конфиг в формате текст-protobuf с возможностью Jinja-шаблонизации, чтобы можно было, например, задавать разные параметры для разных окружений. Все это работает в одной экосистеме. Когда вы создаете сервис на основе Shiny, в нем сразу появляются и lite-тесты. Все очень удобно.
Примерная схема представлена справа. Красными квадратиками отмечено то, что должен написать пользователь, а зеленым — то, что предоставляет система и как происходит интеграция.
Дальше, поскольку мы все-таки на митапе по C++, я хочу вам показать немножко кода из Shiny.

Я взял пример простого HTTP+gRPC-сервера с одной ручкой-handler. Сначала мы должны указать функцию main. Создается daemon. User environment хранит глобальные сервисы пользователя, которые существуют на протяжении жизни всей программы. Дальше мы макросами оборачиваем интерфейс gRPC, потому что я, если честно, не додумался, как это сделать не макросами. Кто работал с gRPC, знает: чтобы его использовать, нужно наследоваться от тех интерфейсов, которые он предоставляет. Shiny добавляет вокруг gRPC-методов, которые описал пользователь, различную диагностику. Этот макрос под капотом содержит какую-то Shiny-имплементацию, где есть логирование, метрики и так далее. И затем мы регистрируем наш handler, о котором пойдет речь дальше, в gRPC и HTTP, то есть по пути hello метода GET. Дальше запускаем сервис и ожидаем на этом месте.

Посмотрим, как выглядит handler. Этот класс, как видите, ни от кого не наследуется, принимает некое окружение в конструктор. Под окружением имеется в вижу пользовательское окружение с предыдущего слайда. Там могут быть сервисы пользователя.
Template нужен для того, чтобы не завязываться на типы. Особенно это важно в тестах. То есть если вам для тестов необходимо два сервиса, а в реальном окружении их десять тысяч, то зачем платить?
Метод Describe служит для того, чтобы интегрировать данный handler в help-ручку, чтобы предоставить его описание. Метод Run принимает request и выдает response. Из request мы вынимаем уже распаршенные значения. В response мы тоже кладем, уже независимо от формата выдачи, значения, которые хотим показать.
Сейчас я вам расскажу, что из себя представляет request.

В данном случае request является той точкой, где соединяются gRPC и HTTP. Если мы идем через gRPC-протокол, то вызывается конструктор, куда передается protobuf-месседж, gRPC request-месседж, который парсится. А Declare вызывается при HTTP. Точнее, он вызывается заранее, чтобы сформировать некую метадату.
Как парсить HTTP-запросы? Если CGI-параметр name приходит в HTTP-ручку, которую мы зарегистрировали, то вызывается вот такая функция. Shiny еще проверяет, чтобы этот параметр обязательно был, на это указывает слово «required». Другими словами, есть required-параметр, общие параметры, repeated-параметры по аналогии с protobuf и еще некоторые. Все это в конечном итоге складывается в месседж Data. Можно и в любую другую структуру сложить, в какую удобно.

Response тоже представляет собой структуру, которая выставляет несколько методов. На самом деле вы вольны выбирать. Можете, например, не выставлять текст — тогда у вас не будет выдачи в текстовом виде. Он тоже ни от чего не наследуется, там работает шаблонная магия по угадыванию, какие методы есть, а каких нет. AsProto используется для gRPC. Если AsProto не указывается, код у вас не скомпилится. А JSON используется для HTTP.

Следующий сервис, о котором я хотел бы рассказать, мы назвали Market Access. Он выполняет задачу распространения файловых ресурсов, изолирует publisher от subscriber — это некий pub/sub.
Когда мы начали задумываться, как же нам разделить наш большой монолит на много сервисов, мы столкнулись с проблемой, как под них переносить данные? Потому что у Репорта, понятное дело, все настроено, и люди ходили писать код в Репорт только потому, что там уже есть все ресурсы. А тащить их под какой-то другой сервис очень неудобно. Market Access должен решить эту задачу.
Как он работает? Publisher может пойти двумя способами. Он может напрямую запушить новую версию ресурса в Access-сервер, то есть зарегистрировать его в Access-сервере. Это некий сервер, который работает с базой мета-информации. Он знает, какие есть ресурсы, какие версии у этих ресурсов и какие существуют консьюмеры.
Либо вы можете просто залить свой ресурс в облачную базу данных, которую будет пуллить компонент Access Puller. Если это, как обычно, уже сложившийся пайплайн, и ни у кого времени не хватает на то, чтобы подключить пуш-метод, тогда мы просто сбоку регистрируем уже написанный Puller, который пуллит наличие новых версий.
С другой стороны, есть множество нодов рабочего сервиса, workload user application, к которым в контейнер в качестве sidecar устанавливается Access-агент, который начинает поллить Access-сервер при запросе этого пользовательского приложения.
То есть здесь отличие от различных динамических ресурсов (таких как Kubernetes или внутренних облаков) в том, что не ресурсы управляют пользовательским приложением, вызывают у него handler, а само приложение. Пока оно не захочет ресурсов, они к нему не поедут. Прямо в C++-коде вызывается метод, об этом я расскажу подробнее. Ресурсы версии версионируемые, могут зависеть от других ресурсов и обеспечивать консистентное обновление.

Как выглядит сервис, использующий Access? Здесь первое, что он должен сделать, — сконфигурировать агента. Access-агент, напомню, — это sidecar, который работает локально в том же контейнере, то есть достаточно порта, чтобы к нему обратиться, и имени консьюмера, чтобы он начинал поллить обновления именно по этому консьюмеру.
Дальше мы строим объект Updater, ресурс Updater на основе этого конфига, в котором уже регистрируем различные ресурсы по типу. В данном случае это ShopList. Дальше, если, например, ресурс критичен для запуска нашего сервиса и бессмысленно стартовать без него сервис, то мы можем wait-титься на нем, то есть ShopList представляет из себя future. А можем не wait-титься, и тогда обновление будет происходить в бэкграунде.
Дальше приходит request, мы можем обратиться к этому ресурсу и, собственно, поискать, вынуть из него те данные, которые обновились. Ресурс выглядит следующим образом.

Мы определяем три метода. GetName возвращает константу, под которой ресурс зарегистрирован в системе. Дальше мы определяем два метода — Load и Unload. Это обязательные методы, которые загружают ресурсы и выгружают их из памяти. Data — это пользовательский интерфейс. Он ничем не ограничен. Здесь можно писать все что угодно, чтобы реализовать интерфейс-чтение для ресурса.
Резюмируя, что мы сделали и что нам это дало?
Мы также проговорили о наработках, которые позволят нам достичь микросервисной архитектуры, и верим, что все-таки ее достигнем. Всем спасибо.
— Всем привет. Меня зовут Юра, я около семи лет работаю в поиске Маркета. Сегодня мы с вами поговорим о нашем опыте, о том, как мы организовали процессы и инструментарий, чтобы быстро разрабатываться и не падать.
В поиске Маркета более тысячи серверов, которые обрабатывают десятки тысяч RPS от пользователей. Ответ формируется из индекса в сотни миллионов документов и приходит пользователю за сотни миллисекунд. При этом мы катаем релизы несколько раз в день. Наш бизнес очень конкурентный, он требует высокой скорости доставки фич. И цена недоступности сервиса чрезвычайно высока. Мой доклад будет разделен на четыре части. В первой поговорим о подходах к функциональному тестированию; во второй — обсудим нагрузочное тестирование; в третьей я расскажу, как устроен наш релизный процесс; в четвертой части поговорим о том, что мы делаем сейчас и что хотим получить в ближайшем будущем.
Функциональное тестирование
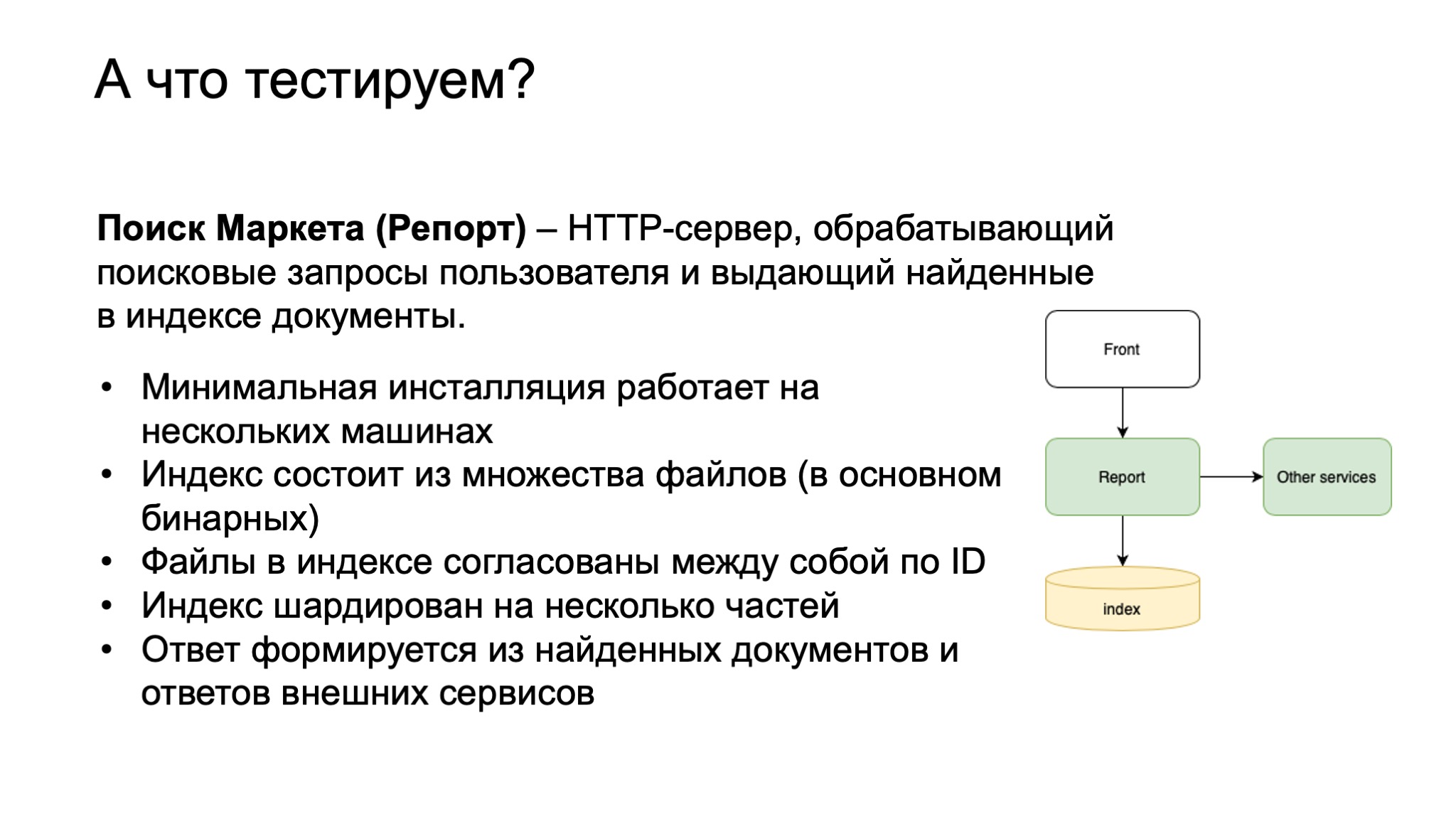
Итак, поехали. Наш компонент — поиск Маркета. Внутри мы его также называем Репорт. Это исторически сложившееся название. Представляет он из себя HTTP-сервер, который обрабатывает поисковые запросы пользователя и выдает найденные документы. В случае Маркета это товарные предложения либо модели.
Справа — упрощенная схема, front — это наш фронтенд. Он посылает запросы в Репорт. Репорт ищет в индексе товарные предложения, офферы. А также обогащает выдачу информацией от сторонних сервисов и выдает все это обратно на front в качестве результата ответа.
Минимальная инсталляция работает на нескольких машинах. То есть это не локальная программа. У нас есть такое понятие, как мини-кластер. Состоит он из нескольких машин. Индекс строится из множества файлов, в основном бинарных. В этих файлах лежит информация о наших бизнес-сущностях, категориях, магазинах, моделях, офферах, которые связаны между собой по идентификаторам. Индекс шардирован на несколько частей, потому что он очень большой и в память одной машины не помещается.
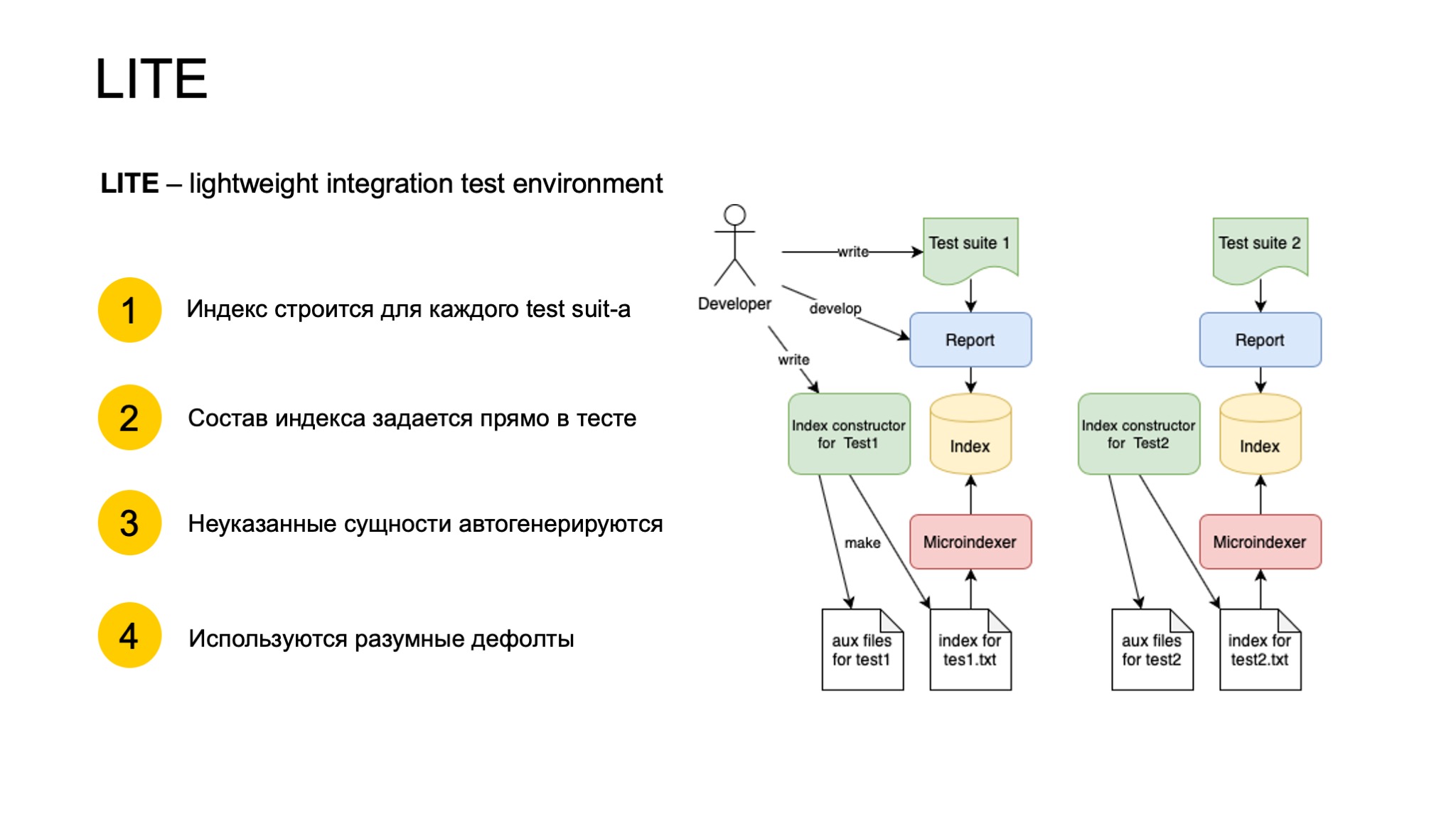
В качестве подхода к функциональному тестированию мы придумали систему под названием LITE — lightweight integration test environment. На самом деле на момент придумки она была системой не интеграционного тестирования, а только модульного, то есть тестировала только один компонент Репорт.
Устроена она следующим образом. Разработчик пишет Test suite, это какая-то настройка тестового окружения и несколько тестов на этом окружении. В настройке окружения он прописывает, индекс какой именно конфигурации и, вообще, какие данные под Репортом он хочет иметь в очень лаконичной и минималистичной форме. Например, вполне валидно будет написать — я хочу в индексе иметь один оффер с тайтлом iPhone. И больше ничего не написать. LITE сам поймет, какие нужно построить сущности помимо этого оффера, свяжет их по автосгенерированным айдишникам, и получится согласованная система данных.
Индекс в бинарную форму, в продакшен-вид, переводит вспомогательная программа — Microindexer. Далее запускается Репорт, в тестах к нему подаются запросы и валидируется ответ. Хорошим тоном считается, когда происходит валидация в тестах только тех сущностей, которые были заданы в тесте, и ничего больше.

Каких успехов мы добились с помощью LITE? Мы полностью сами стали писать автотесты. Частота релизов выросла в среднем до пяти раз в неделю, иногда больше. Тесты стали гораздо стабильнее. Раньше тесты просто гонялись на очень волатильном окружении, где офферы менялись. Соответственно, выдача тестов тоже менялась, и иногда они падали не по делу.
Кроме того, мы внедрили LITE не просто как тест, но как фреймворк для разработки, то есть в помощь разработчику. Мы не заставляли никого писать тесты, это получилось само собой, потому что это дешевле, чем разворачивать инсталляцию Репорта на отдельном окружении. Там может быть до десяти машин, и окружение, понятно, довольно дорогое. Оно одно на многих разработчиков — надо стоять в очереди, ждать. Очень неудобно.
А в LITE можно сделать только то, что относится к разрабатываемой фиче, протестировать и не сломать другие тесты. Еще это будет прогоняться при каждом коммите. На текущий момент написано более 6 тысяч тестов. Они гоняются где-то 10 минут.

Но нам не всё удастся протестировать функциональными тестами, поэтому у нас есть теневой кластер. Работает он следующим образом. На балансере есть логика, которая зеркалирует запросы пользователя на выделенный кластер Репорта. Туда мы можем устанавливать все что угодно. Для Репорта мы устанавливаем туда продакшен-индекс и кастомный репорт, тот, который мы хотим протестировать. Дальше мы можем снимать метрики с этого теневого кластера и сравнивать с аналогичным продакшен-кластером.
Теневой кластер помог нам ускорить исследование инфраструктурных улучшений, которые довольно сложно делаются на живом проде и практически не делаются в тестах, производить сравнение «спина к спине» на одном потоке запросов. Репорт туда доставляется очень быстро.
Дальше у нас есть Стоп-кран. Это механизм быстрого включения и выключения в проде неких функциональных блоков. То есть в коде заводятся флажки, которые можно включать из внешнего сервиса. Как вы видите на схеме, разработчик может указывать значение флага во Flag storage, а также сферу его применимости через LUA выражение, чтобы не на весь прод, а на отдельный кластер, или на один DC, или на какое-нибудь хитрое пересечение.

Дальше процесс Репорта постоянно полит этот Flag storage, вычитывает выражение LUA, запускает его и определяет, нужно ли ему обрабатывать пришедшее значение флага. Если не нужно — выбрасывает, если нужно — включает его в приоритет обработки. Соответственно, время раскатки — это единицы секунд флага. Но есть и оборотная сторона: можно сломать весь прод без релизов, просто так взведя неудачный флаг. С этим мы боремся через инструкции. Мы составили правила, как можно включать флаги Стоп-крана, запретили включать какой-либо флаг на весь прод сразу, только постепенно. Смотрим на мониторинг и аккуратно двигаемся.
Нагрузочное тестирование

Наш компонент сервиса нагрузочного тестирования называется Market Kombat. Работает он по следующему принципу. Есть задача — нам нужно понять, нет ли регресса производительности между двумя релизами Репорта. Один релиз Репорта — это который крутится в проде, и мы знаем, что он хороший, потому что он там уже долго крутится и все метрики продакшена говорят, что все хорошо. Второй релиз — это тот, который хочет выкатиться в прод.
Разработчик через command line tool делает task. Task — это такое protobuf-сообщение, в котором он указывает, что именно он хочет протестировать: какие виды Репорта, индекса, запросов. Компонент, создающий нагрузку на сервер, называется Танк, а сами запросы называются «патроны», это у нас такой жаргонизм. Движок на Kombat-сервере разгребает эти task-и, настраивает окружение соответствующим образом. Достает патроны, индексы и Репорты, заказанные в task-е. Проводит сравнение и публикует отчет в Трекер в красивой форме.
То есть раньше разработчик страдал, пользуясь множеством скриптов. Все это было нестабильно, постоянно ломалось, окружение кто-то портил. С Kombat такой проблемы нет. Разработчик делает задачу, забывает, и через какое-то время ему приходит результат.
Также Kombat поддерживает не только тесты на деградацию, но и capacity по офферам (сколько офферов может влезть в индекс и не просадить наши SLA), а также максимально возможный RPS на мини-кластер. Это позволяет нам планировать заказ железа на будущее.
Релизный процесс

Теперь поговорим о том, как же устроен релизный процесс. Мы используем подход continuous delivery. У нас существует множество пайплайнов для выкатки сервисов. Репорт выкатывается по следующему принципу.
Разработчик коммитит в систему контроля версий. Дальше система continuous delivery замечает этот коммит. У нее есть условия, она может реагировать не на каждый коммит, а на пачку коммитов, чтобы зря не греть железо. Дальше она берет ревизию, назначает ее релизной и собирает на основе нее проект. Запускает тесты, деплоит тестовое окружение. Параллельно запускает перформанс-стрельбы, то есть делает запросы в Kombat, который мы только что обсудили. Пока стрельбы проходят, а они могут час проходить, деплой идет в prestable. Prestable — это такая маленькая часть продакшен-окружения. Там уже работают некие мониторинги. Мы смотрим, как новый релиз в prestable себя ведет, все ли хорошо. Когда все это закончилось, релиз-мастер принимает решение, можно ли раскатывать этот релиз в прод. Это единственное ручное вмешательство релиз-мастера.
Будущее...

Мы хотим изменить архитектуру Репорта в направлении микросервисов. Проблема в том, что Репорт — очень большой монолит со всеми вытекающими проблемами. Можно делать быстрее и лучше то, что сейчас в принципе и так неплохо делается. Отладка, деплой, тестирование и, вообще, развитие. Сейчас сложно переиспользовать подходы и технологии в Репорте, потому что он идет своим путем, потому что он очень большой, требует много железа и особого обращения в облаке. Под него выделяются целые железные машины. Ни о каком переиспользовании не идет речи.
Микросервисы в Яндексе принято делать на основе системы Apphost. Она хорошо описана на Хабре, вы можете о ней почитать. Суть в том, что сама логика сервисов разбивается на кучу мелких сервисов, которые пассивны по отношению к системе. Они сами никого никуда не вызывают, а просто сидят и слушают, пока их не вызовет Apphost. А в Apphost зашит график обхода. Пользователь задает, какие сервисы надо обходить и в каком порядке.
Но есть сложность с поиском: у нас есть некий слой бизнес-логики, который сидит очень глубоко в поиске и обрабатывает множество документов. Пока не очень понятно, как ее разделить на сервисы, но мы думаем над этим.

Также, чтобы успешно перейти на миросервисы, нам нужна платформа. И мы адаптировали систему тестирования LITE для работы с любым HTTP- и gRPS-сервисом. Мы внедрили Beam, оболочку-запускатор сервиса локально, которая требует zero configuration. То есть вы можете просто найти в какой-то директории и запустить Python-файл service.py, ничего не указывая, никаких аргументов. Он сам все сконфигурирует, выдаст минимальную конфигурацию и поднимет вам сервис. Вы можете пощупать его руками, посмотреть, что он выдает. Это такой пользовательский опыт — сервис легкий, его можно поднять.
Beam используется в Test suite. Таким образом мы можем поднимать внешние сервисы и сделать связку из них. На картинке мы, например, хотим тестировать сервис B, который ходит в сервис A в одном тесте. А в другом тесте мы не хотим тестировать честную связку, потому что на то, чтобы поднять сервис A и сервис B, все-таки уходит время. Мы можем вместо Beam сделать Mock, и это будет прозрачно, Beam сервиса B никак не изменится. И тестируются реальные бинарники, тут все по-честному.
Кроме того, LITE поддерживает серверный режим. Это значит, что если вы даете флажок -s, тест стартует в режиме сервера. Он подготавливает все данные, которые тест описал в секции prepare, и просто ждет запросов, а не прогоняет тесты по-настоящему.
Режим отладки — это когда вы стартуете тесты под GDB. GDB сразу запускается, когда вы Python-файл запускаете. Вы можете расставить breakpoint и продолжить выполнение. Режим breakpoints — это когда тест у вас спрашивает явные действия — например, нажать Enter перед каждым запросом. Вы можете посмотреть: если тест работает неправильно и вы не понимаете, почему, вы можете таким образом пошагово пройтись и посмотреть, на каком шаге тест ломается. Это прежде всего помогает в разработке.

Чтобы разворачивать сервисы эффективно, нам нужна болванка для сервисов, чтобы мы могли прийти и начать писать ровно то, что нужно, то есть бизнес-логику, не думая обо всяких протоколах взаимодействия, логирования и прочей рутине.
Поэтому мы придумали так называемый Shiny framework. Он лежит в основе наших HTTP- и gRPC-сервисов. У нас есть такой инфраструктурный сервис — «сервис по кнопке». Это мастер, вы можете прокликать по кнопочкам, и для вас из шаблона поднимется сервис. Shiny предоставляет некий шаблон сервиса с одной ручкой, который запустится в облаке.
Shiny framework — не вирусный, то есть не заставляет вас и дальше его использовать. Вы можете быстро с него начать, но потом бизнес-логику легко очень вынуть в какой-нибудь другой фреймворк.
Вы из коробки получаете Help handler. Это, собственно, HTTP handler, который пишет вывод о том, какие еще ручки есть. Документация генерирутся автоматически. А дальше он собирает статистику по запросу, интегрирует сервер в наши внутренние системы мониторинга. Логирование, изоляция ОС для удобного написания юнит-тестов и профилирование. Мы используем два вида профилирования, это перф и наш собственный инструментированный профилировщик — макросами расставляем функции, чтобы потом красиво рисовался html.
Shiny имеет расширяемый конфиг в формате текст-protobuf с возможностью Jinja-шаблонизации, чтобы можно было, например, задавать разные параметры для разных окружений. Все это работает в одной экосистеме. Когда вы создаете сервис на основе Shiny, в нем сразу появляются и lite-тесты. Все очень удобно.
Примерная схема представлена справа. Красными квадратиками отмечено то, что должен написать пользователь, а зеленым — то, что предоставляет система и как происходит интеграция.
Дальше, поскольку мы все-таки на митапе по C++, я хочу вам показать немножко кода из Shiny.

Я взял пример простого HTTP+gRPC-сервера с одной ручкой-handler. Сначала мы должны указать функцию main. Создается daemon. User environment хранит глобальные сервисы пользователя, которые существуют на протяжении жизни всей программы. Дальше мы макросами оборачиваем интерфейс gRPC, потому что я, если честно, не додумался, как это сделать не макросами. Кто работал с gRPC, знает: чтобы его использовать, нужно наследоваться от тех интерфейсов, которые он предоставляет. Shiny добавляет вокруг gRPC-методов, которые описал пользователь, различную диагностику. Этот макрос под капотом содержит какую-то Shiny-имплементацию, где есть логирование, метрики и так далее. И затем мы регистрируем наш handler, о котором пойдет речь дальше, в gRPC и HTTP, то есть по пути hello метода GET. Дальше запускаем сервис и ожидаем на этом месте.

Посмотрим, как выглядит handler. Этот класс, как видите, ни от кого не наследуется, принимает некое окружение в конструктор. Под окружением имеется в вижу пользовательское окружение с предыдущего слайда. Там могут быть сервисы пользователя.
Template нужен для того, чтобы не завязываться на типы. Особенно это важно в тестах. То есть если вам для тестов необходимо два сервиса, а в реальном окружении их десять тысяч, то зачем платить?
Метод Describe служит для того, чтобы интегрировать данный handler в help-ручку, чтобы предоставить его описание. Метод Run принимает request и выдает response. Из request мы вынимаем уже распаршенные значения. В response мы тоже кладем, уже независимо от формата выдачи, значения, которые хотим показать.
Сейчас я вам расскажу, что из себя представляет request.

В данном случае request является той точкой, где соединяются gRPC и HTTP. Если мы идем через gRPC-протокол, то вызывается конструктор, куда передается protobuf-месседж, gRPC request-месседж, который парсится. А Declare вызывается при HTTP. Точнее, он вызывается заранее, чтобы сформировать некую метадату.
Как парсить HTTP-запросы? Если CGI-параметр name приходит в HTTP-ручку, которую мы зарегистрировали, то вызывается вот такая функция. Shiny еще проверяет, чтобы этот параметр обязательно был, на это указывает слово «required». Другими словами, есть required-параметр, общие параметры, repeated-параметры по аналогии с protobuf и еще некоторые. Все это в конечном итоге складывается в месседж Data. Можно и в любую другую структуру сложить, в какую удобно.

Response тоже представляет собой структуру, которая выставляет несколько методов. На самом деле вы вольны выбирать. Можете, например, не выставлять текст — тогда у вас не будет выдачи в текстовом виде. Он тоже ни от чего не наследуется, там работает шаблонная магия по угадыванию, какие методы есть, а каких нет. AsProto используется для gRPC. Если AsProto не указывается, код у вас не скомпилится. А JSON используется для HTTP.

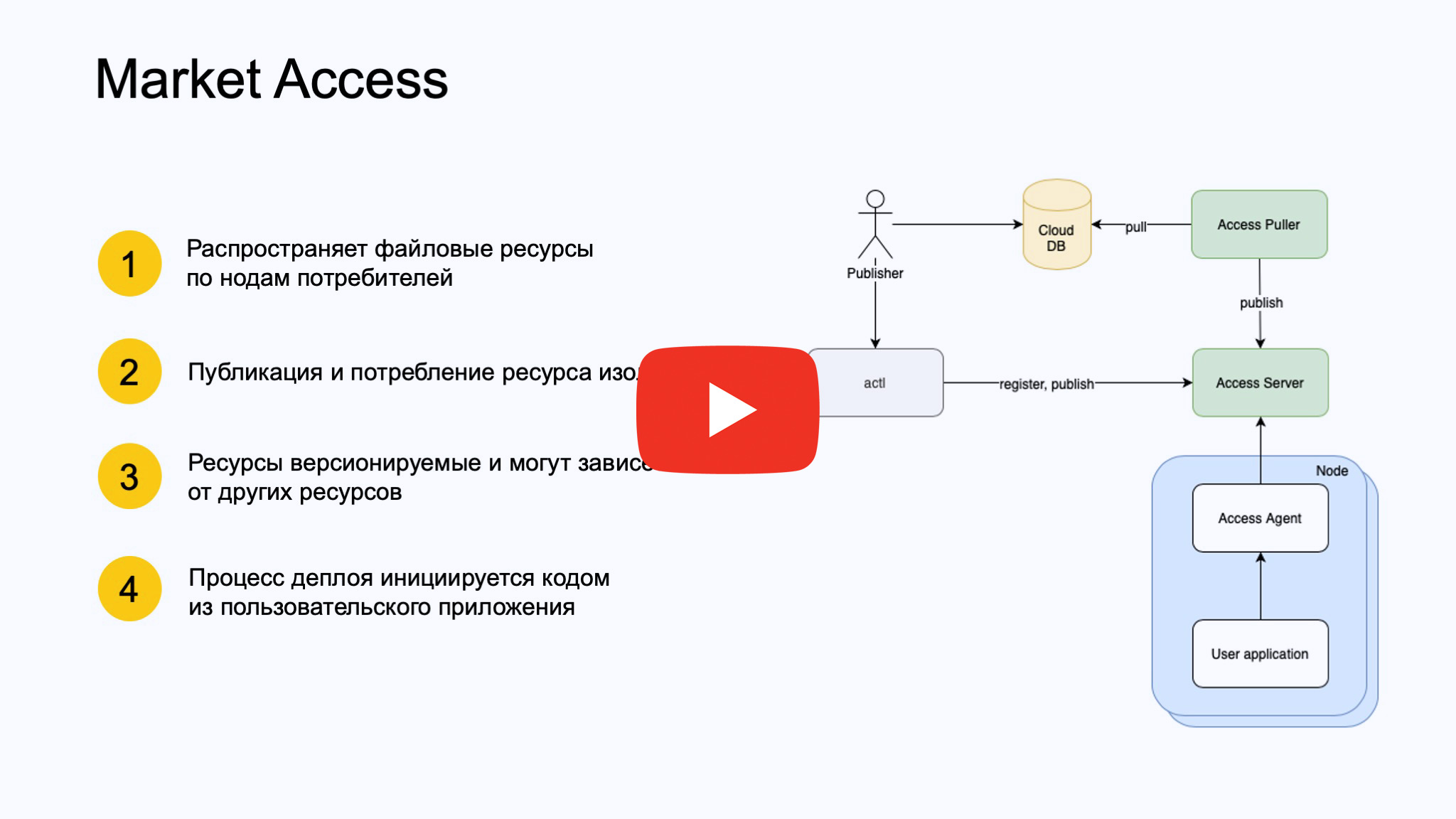
Следующий сервис, о котором я хотел бы рассказать, мы назвали Market Access. Он выполняет задачу распространения файловых ресурсов, изолирует publisher от subscriber — это некий pub/sub.
Когда мы начали задумываться, как же нам разделить наш большой монолит на много сервисов, мы столкнулись с проблемой, как под них переносить данные? Потому что у Репорта, понятное дело, все настроено, и люди ходили писать код в Репорт только потому, что там уже есть все ресурсы. А тащить их под какой-то другой сервис очень неудобно. Market Access должен решить эту задачу.
Как он работает? Publisher может пойти двумя способами. Он может напрямую запушить новую версию ресурса в Access-сервер, то есть зарегистрировать его в Access-сервере. Это некий сервер, который работает с базой мета-информации. Он знает, какие есть ресурсы, какие версии у этих ресурсов и какие существуют консьюмеры.
Либо вы можете просто залить свой ресурс в облачную базу данных, которую будет пуллить компонент Access Puller. Если это, как обычно, уже сложившийся пайплайн, и ни у кого времени не хватает на то, чтобы подключить пуш-метод, тогда мы просто сбоку регистрируем уже написанный Puller, который пуллит наличие новых версий.
С другой стороны, есть множество нодов рабочего сервиса, workload user application, к которым в контейнер в качестве sidecar устанавливается Access-агент, который начинает поллить Access-сервер при запросе этого пользовательского приложения.
То есть здесь отличие от различных динамических ресурсов (таких как Kubernetes или внутренних облаков) в том, что не ресурсы управляют пользовательским приложением, вызывают у него handler, а само приложение. Пока оно не захочет ресурсов, они к нему не поедут. Прямо в C++-коде вызывается метод, об этом я расскажу подробнее. Ресурсы версии версионируемые, могут зависеть от других ресурсов и обеспечивать консистентное обновление.

Как выглядит сервис, использующий Access? Здесь первое, что он должен сделать, — сконфигурировать агента. Access-агент, напомню, — это sidecar, который работает локально в том же контейнере, то есть достаточно порта, чтобы к нему обратиться, и имени консьюмера, чтобы он начинал поллить обновления именно по этому консьюмеру.
Дальше мы строим объект Updater, ресурс Updater на основе этого конфига, в котором уже регистрируем различные ресурсы по типу. В данном случае это ShopList. Дальше, если, например, ресурс критичен для запуска нашего сервиса и бессмысленно стартовать без него сервис, то мы можем wait-титься на нем, то есть ShopList представляет из себя future. А можем не wait-титься, и тогда обновление будет происходить в бэкграунде.
Дальше приходит request, мы можем обратиться к этому ресурсу и, собственно, поискать, вынуть из него те данные, которые обновились. Ресурс выглядит следующим образом.

Мы определяем три метода. GetName возвращает константу, под которой ресурс зарегистрирован в системе. Дальше мы определяем два метода — Load и Unload. Это обязательные методы, которые загружают ресурсы и выгружают их из памяти. Data — это пользовательский интерфейс. Он ничем не ограничен. Здесь можно писать все что угодно, чтобы реализовать интерфейс-чтение для ресурса.
Резюмируя, что мы сделали и что нам это дало?
- LITE снизил риск функционального регресса за счет внедрения в культуру разработки и включения в CI. Он удобен для разработчика.
- Kombat позволил отлавливать деградации производительности автоматически до продакшена. Кроме того, мы запускаем его ночью для различных тестов на capacity.
- Теневой кластер помог нам в исследовательской деятельности инфраструктурных улучшений и в отладке на продакшен-процессах.
- Стоп-кран позволяет купировать инциденты за секунды, отключая проблемную функциональность.
- Ну а Continuous Delivery ускорило доставку фич в продакшен и связало сервисы тестирования воедино с релизным процессом.
Мы также проговорили о наработках, которые позволят нам достичь микросервисной архитектуры, и верим, что все-таки ее достигнем. Всем спасибо.
