
Компьютерные игры, обработка аудиосигналов в режиме реального времени и другие подобные приложения низкой задержки требуют, чтобы код был не только корректным. Он также должен исчислять требуемый результат надёжно за детерминированный срок выполнения. В этом докладе head of technology в компании Cradle Тимур Думлер timuraudio рассмотрел, в какой степени стоит использовать стандартную библиотеку С++ для создания приложений с подобными «real-time» ограничениями. Какие инструменты из стандартной библиотеки можно применять с уверенностью, что они не будут блокировать поток, ждать освобождения мьютекса, не будут выделять или освобождать память и совершать другие действия с недетерминированной задержкой? Каких средств из набора стандартной библиотеки следует избегать и почему? По пути Тимур обсудил малоизвестные и неожиданные аспекты этих привычных инструментов.
— Всем привет, меня зовут Тимур Думлер. Хочу сказать, что я обычно делаю доклады на английском языке. Это всего второй раз в жизни, когда я докладываю на русском, мне это немножко непривычно. Спасибо большое, что подключились, сегодня мы поговорим про использование стандартной библиотеки C++ для обработки сигналов в real-time.
Разберёмся сначала, что вообще такое real-time. Второй термин, который часто встречается в этом контексте, — low latency. Как real-time связан с low latency?

Если мы посмотрим на эффективность нашего кода — а это, конечно, в плюсах всех интересует, — то там есть два ортогональных аспекта эффективности. Есть так называемая bandwidth, мне кажется, по-русски это называется пропускная способность. И есть latency — задержка. Грубо говоря, bandwidth — это то, сколько информации наша программа перерабатывает, скажем, в секунду. Значит, если представить себе трубу, то bandwidth определяет, сколько информации через неё течёт. А latency — это примерно сколько времени проходит между запросом и ответом.
И в докладе нас не будет интересовать bandwidth, потому что количество данных, которые мы здесь перерабатываем, достаточно небольшое. Мы интересуемся именно latency. И «real-time» означает, что у нас имеется максимальная верхняя граница допускаемой задержки. Поэтому в первом приближении можно определить понятие real-time так: код считается корректным, если он не только даёт правильный результат, но даёт его в определенный период времени.
В каких юз-кейсах встречается понятие real-time? Это, конечно, высокочастотный трейдинг, компьютерные игры, разные встроенные системы: автомобили, роботы, пылесосы и тому подобное. А также обработка аудиосигналов. Это те области, где плюсы как раз очень популярны.
Моя область — как раз обработка аудиосигналов. Это то, чем я занимаюсь последние десять лет. Хочу просто коротко объяснить, что это за юз-кейсы, чтобы было понятно, какая у нас здесь мотивация.

Если вы занимаетесь обработкой аудиосигналов в real-time, то у вас есть звуковая карта, которая через аудиостек вашей операционной системы вам даёт callback, вызывает вашу функцию, которая может называться process, и даёт вам буфер, в который нужно записать звуковые данные. Когда вы это сделали, буфер идёт через весь этот стек назад в звуковую карту. Там это превращается в аналоговый сигнал и передаётся дальше в колонки, где превращается в звук, который вы можете услышать.

И callback приходит регулярно, в регулярных интервалах на высокоприоритетном потоке, который, вне зависимости от операционной системы, либо выдаёт вам сама ОС, либо создаёте вы сами. Значит, на этом высокоприоритетном real-time-потоке у вас будут такие callback. Причём они будут в регулярных промежутках времени. В зависимости от настроек юзера, например, от размера буфера, частоты дискретизации и всякого такого, время между двумя последующими callback — где-то 1-10 миллисекунд.
Если вы пропустили это окно времени, которое у вас есть, чтобы заполнить буфер данными, то в буфере в момент, когда звук будет воспроизводиться, окажется мусор и в колонках будет такой слышимый щелчок.
Если ваш софт такое делает, никто его покупать не будет. Так что очень важно успеть за этот дедлайн, чтобы всё, что делает ваша функция process, закончилось. В этом смысле аудио немного отличается от других юз-кейсов низкой задержки. Если вы, например, занимаетесь трейдингом, то вам очень важно, займёт ли функция process 100 или 110 микросекунд. Потому что если вы не максимально быстрые, то можете потерять миллион долларов. А если вы интересуетесь пропускной способностью и ваш сервер обрабатывает очень много запросов, то вам, конечно, тоже очень важно минимизировать время, потому что время обработки суммируется.
В аудио, наверное, нас не столько интересует, займёт ли process 100 или 110 микросекунд. Но нас интересует, чтобы функция занимала 110 микросекунд максимум. Она никогда не займёт, например, 1000 микросекунд, даже один раз в миллион. Если это произойдёт, будет щелчок, поскольку мы не успели написать данные. У нас есть такой абсолютный дедлайн для всего, что происходит в этой функции process.
Причём «real-time» — он как бы в кавычках, потому что есть этот дедлайн. Но одновременно мы это делаем на самой обычной операционной системе. Вот если вы программируете для автомобилей или самолётов, то там у вас будет real-time операционная система, специальная, где этот дедлайн физически обеспечивается, и у вас будет real-time kernel. А в случае аудиософта мы в обыкновенной пользовательской операционной системе — Windows, macOS, iOS, Linux, Android. Там физического real-time-ядра нет. Планировщик потоков мы не контролируем. Мы просто используем поток с высоким приоритетом. И надеемся, что операционная система будет всё планировать правильно.
На практике проблем с этим не возникает, поэтому «real-time» мы в этом докладе как бы ставим в кавычки.
Возвращаясь к нашему аудио, callback и к нашей функции process. Нам нужно успеть заполнить буфер звуковыми кадрами в какое-то относительно короткое время.

У нас есть функция writeFrames, которая пишет туда звуковые кадры. Есть, например, функция applyGain, которая, может быть, меняет громкость этих кадров. Нам нужно задавать себе вопрос: можно ли вызывать эти функции в real-time-потоке без появления щелчков?
У аудиопрограммистов есть понятие real-time safe. Это как раз тот вопрос, который нас интересует.
Можно определить достаточно неформально, что код считается real-time safe, если есть абсолютная верхняя граница времени его исполнения. Код 100% времени не превышает эту верхнюю границу. Она должна быть, конечно, ниже вашего доступного промежутка времени. Если вы вызываете много функций, то сумма верхних границ не должна превышать одной миллисекунды или другого времени, зависит от настройки. Причём если эта верхняя граница в принципе известна, то на практике нам достаточно часто не нужно измерять и бенчмаркить каждую функцию, которую мы вызываем.
Мы можем предположить, что она real-time safe, если она обладает некоторыми свойствами. Что это за свойства?
Конечно, нам нельзя блокировать real-time-поток. В первую очередь потому, что если мы блокируем и ждём другого потока, то не знаем, сколько времени это займёт. Значит, у нас есть это неизвестное время ожидания, нет абсолютно верхней границы. И потом, если другой поток, которого мы ждём, имеет приоритет ниже, чем наш real-time-поток, то ещё возникает вот эта проблема — priority inversion.
Что значит «не блокировать»? Значит, мы не можем пользоваться мьютексами, не можем аллоцировать/деаллоцировать память, не можем заниматься никаким input/output, вообще не можем взаимодействовать с планировщиком потоков и с операционной системой, не можем делать никаких системных вызовов.
Кроме того, даже если мы ничего из этого не делаем, а просто вызываем алгоритмы, то нам нужно знать, когда и в какое время они закончатся. Следовательно, нам в принципе нельзя пользоваться алгоритмами, которые имеют не константную сложность. В том числе, если у нас O(N) и мы не знаем величину N, не знаем, какая у нее верхняя граница времени, то не можем вызывать эту функцию.
Также мы не можем пользоваться алгоритмами амортизированной сложности. Пример классической амортизированной сложности — вставка в хеш-таблицу. У неё почти всегда константная сложность. Но иногда хеш-таблица может решить: а давайте перестроим весь индекс! И если вы это будете делать на real-time-потоке, то, конечно, возникнет проблема. Мы вообще не можем вызывать никакой сторонний код, если не знаем точно, что внутри происходит, нет ли там мьютексов, аллокаций и так далее.
Вы можете найти в интернете достаточно докладов, я и сам их делал, и другие авторы, о том, как программировать в таком стиле. Про это я не буду здесь рассказывать.
Мы, имея такое неформальное определение real-time safe, рассмотрим другой вопрос. У нас, поскольку мы, как и все остальные, пользуемся нормальными ОС и нормальной имплементацией C++, есть стандартная библиотека. Конечно же, было бы удобно, если бы мы могли пользоваться возможностями стандартной библиотеки из коробки. И мы рассмотрим вопрос, какие части именно стандартной библиотеки являются real-time safe. На практике он возникает достаточно часто.
Причём нас, конечно, интересует код во время выполнения, потому что код на этапе компиляции является real-time safe по определению, мы во время рантайма ничего не делаем.
Конечно, мы не сможем перечислить каждую функцию и каждый класс в стандартной библиотеке, время у нас ограничено. Но я расскажу про некоторые популярные, интересные части библиотеки. И главное, я расскажу, как нужно читать текст стандарта, чтобы самому почувствовать, чем можно и чем нельзя пользоваться. Идея в том, что мы хотим писать портабельный код, поэтому обращаемся в стандарт и смотрим, как вещи специфицированы там.
Именно в этом и состоит цель доклада: получить чувство того, как нужно смотреть на стандарт, чтобы понять, является ли real-time safe какая-нибудь конкретная функция или класс стандартной библиотеки.
Посмотрим на стандарт.
Конечно, оказывается, что стандарт C++ вообще не говорит о границах времени выполнения. Понятие верхней границы, времени выполнения, которое нас интересует, в стандарте полностью отсутствует. Также стандарт C++ нигде не говорит, что, например, какая-нибудь функция не аллоцирует память. Но из спецификации стандарта иногда понятно, что аллокации не нужны оптимальной имплементации.
Иногда в стандарте есть полезные фразы — например, вот эта функция инвалидирует итераторы. Тогда мы знаем, что, наверное, она может реаллоцировать элементы вектора и это будет аллокация. Иногда стандарт говорит: если есть достаточно памяти, тогда функция делает это, а иначе — что-то другое. Тогда мы знаем, что функция попытается аллоцировать память.
Также стандарт C++ не говорит, что такой-то класс не употребляет мьютексы. Но иногда есть фраза: нельзя иметь доступ к классу Х из нескольких потоков одновременно. Тогда мы знаем: мьютексов там, наверное, нет. И наоборот, иногда появляется фраза, что данный объект или класс не может вводить условия гонки, в стандарте это написано. Тогда мы знаем: внутри, наверное, есть мьютексы, чтобы обеспечить такое поведение, и в real-time таким классом пользоваться нельзя.
Мы видим: пользоваться стандартной библиотекой для real-time — не точная наука. Нам нужно часто и очень внимательно читать стандарт. Когда мы поняли спецификацию, нужно ещё и доверять качеству имплементации стандартной библиотеки — точно так же, как мы доверяем качеству имплементации нашей ОС.
Посмотрим на конкретные части языка и стандартной библиотеки. В первую очередь нужно сказать, что исключения — не real-time safe. Есть люди, которые стараются это изменить. А конкретно — у Герба Саттера есть такой proposal, который пытается ввести новый механизм исключений в C++. У этого механизма будет свойство real-time safe.

Но, к сожалению, никто не знает, попадет ли когда-нибудь этот proposal в стандарт. А для того, что у нас есть сегодня, главная информация находится прямо здесь, на первой странице proposal. Здесь написано: сегодняшние исключения не имеют верхней границы времени, которая нас интересует и, вообще, аллоцирует память. Поэтому нам в принципе говорить про исключения больше не нужно.
Говорим про алгоритмы по STL, header <algorithm>. Какие STL-алгоритмы считаются real-time safe? Алгоритмов в стандартной библиотеке сейчас уже очень много. Они даже уже не помещаются на один слайд.
Но какие из них real-time safe?
И при этом мы предполагаем, что тип элементов — тоже real-time safe. Например, если тип элементов у вас std::string и вы их копируете, то, конечно, у вас будет аллокация. Или если итератор у вас std::back_insert_iterator<std::vector> или std::ostream_iterator, что-нибудь такое — конечно, это тоже не будет real-time.
Вопрос, который нас здесь интересует: будут ли аллокации внутри самого алгоритма? Конечно, стандарт C++ этого не определяет.
Но почти всегда, почти для всех алгоритмов, оптимальная имплементация этой спецификации в стандарте не требует аллокации памяти. Поэтому мы можем исходить из того, что нормальная имплементация стандартной библиотеки не будет аллоцировать память. Значит, мы можем пользоваться таким алгоритмом.
Это касается не всех из них. Для некоторых алгоритмов существует более быстрая имплементация, если им разрешить аллоцировать временный буфер для промежуточных данных. Для этих алгоритмов стандартная библиотека будет пользоваться именно такой быстрой имплементацией и будет пытаться аллоцировать для нее память.

Хорошая новость в том, что стандарт нам об этом говорит. Для каждого такого алгоритма мы находим в стандарте вот такие волшебные слова. Сложность алгоритма, если у нас достаточно памяти, она, значит, такая. А иначе — такая. Всегда когда мы видим эти волшебные слова в стандарте, мы знаем, что такой алгоритм будет пытаться создать временный буфер, а для этого он будет пытаться аллоцировать память.
Вторая хорошая новость: это свойство имеют всего лишь три алгоритма стандартной библиотеки: stable_sort, stable_partition и inplace_merge. Из них, я бы сказал, stable_sort наиболее часто употребляется. Например, в каком-нибудь сложном звуковом движке. Так что не делайте этого, не употребляйте эти алгоритмы в таком контексте.

Конечно, std::array на стеке, поэтому он real-time safe по определению, кроме функции at, которая бросает исключение. Но если это происходит — наверное, у вас есть более серьезные проблемы.
Все остальные STL-контейнеры употребляют динамическую память, значит, они из коробки не real-time safe.
Что же делать, если нам все равно нужен динамический контейнер на real-time-потоке, что встречается достаточно часто?
Есть один метод, который я часто видел на практике. Многие аудиопрограммисты делают вот это.
Они пользуются так называемым variable-length array. Это значит — массив, где размер определяется во время рантайма. Отлично работает в C, на Clang и на GCC. Но это не стандартный C++, это extension стандарта. И на Windows это не собирается, вы получите вот такую ошибку.
Был, кстати, такой случай, когда я работал с библиотекой, со специализированными аудиоалгоритмами. Автор обещал, что всё портабельно. А потом я попытался собрать на винде, и всё развалилось, потому что везде были эти variable-length array. Пришлось всё переписывать. Было печально.
Второй метод, который достаточно часто можно увидеть, — это когда люди пишут от руки вот такой вектор с максимальной вместимостью. При желании внутри есть аллоцированный буфер с максимальной вместимостью. Вокруг него мы пишем такой интерфейс для вектора, и он работает как нормальный вектор. Но когда кончается буфер, который у нас заранее аллоцирован, то вектор бросает исключение или делает что-нибудь ещё, выдаёт какую-нибудь другую ошибку.
Опять же, очень многие люди делают это на практике. Например, в компьютерных играх такой класс можно увидеть очень часто. Но, во-первых, это нужно писать от руки. Во-вторых, что если нам нужна другая динамическая структура данных? Например, нам нужно std::map, std::set или что-то такую?
Написать самому такую структуру данных, да еще так, чтобы она была real-time safe — конечно, очень сложно. Но, как мы знаем, можно использовать структуру данных из стандарта с кастомным аллокатом. Об этом говорили в других докладах конференции.
Какой самый простой аллокатор можно написать, чтобы он работал на real-time-потоке?
Нам нужен аллокатор, который работает только на этом потоке, не имеет внутри никаких мьютексов, ничего такого, существует только в то время, пока мы делаем этот process, и вообще не является аллокатором, потому что он не аллоцирует память.
Вместо этого мы ему даём буфер, который заранее аллоцирован, memory pool. Что делает аллокатор? Он просто берёт куски из этого заранее аллоцированного буфера, пока буфер не кончится. А потом он бросает bad_alloc, или вызывает terminate, или делает что-нибудь такое. А deallocate у такого аллокатора вообще ничего не делает.
Это самый простой real-time-аллокатор. Тогда его можно просто использовать как шаблонный аргумент для всех STL-контейнеров, и он будет работать. Начиная с C++17 даже не нужно писать самим, мы можем всё собрать из частей стандартной библиотеки. Это будет выглядеть примерно так.
Опять memory pool, заранее аллоцированный буфер. На сей раз мы уже не пишем свой аллокатор, а используем аллокатор из стандартной библиотеки — std::pmr::monotonic_buffer_resource, длинное сложное слово. Что он делает? Как раз то, о чём мы сказали на предыдущем слайде: берёт заранее аллоцированный буфер, наш memory pool и просто берёт куски из буфера, пока тот не кончится. deallocate вообще ничего не делает.
Когда буфер кончится, monotonic_buffer_resource вызывает другой аллокатор — upstream resource и берёт память уже оттуда. Это третий аргумент в конструкторе. Мы ему даём std::pmr::null_memory_resource — тоже класс из стандартной библиотеки, которая появилась в 17-м стандарте.
А null_memory_resource, как вы уже можете догадаться, вообще ничего не делает — сразу бросает std::bad_alloc, как только вы попытаетесь у неё взять память. Как раз такое поведение нам в данном случае и нужно. Мы здесь уже ничего сами имплементировать не должны, это весь код, он соберется вот так.
Я прочитал историю инструментов std::pmr в стандартной библиотеке. У меня сложилось впечатление, что это не совсем тот юз-кейс, для которого они были добавлены в стандарт. Я сам ещё не пользовался этими классами в продакшене, но когда я смотрю на спецификацию, мне кажется, это как раз более-менее то, что надо. Наверное, можно этим пользоваться.
Как насчёт других утилит, которые есть в стандарте? Есть std::pair/std::tuple, на стеке, поэтому они снова real-time safe по определению. Есть std::optional, просто значение и bool на стеке. Это тоже real-time safe, там никаких аллокаций не будет. Некоторые функции std::optional бросают исключение std::optional_access, так что этими функциями не надо пользоваться. Ещё есть std::variant, обёртка вокруг union.

Казалось бы, это тоже real-time safe. Но вариант, кстати, интересный: у него свойство, является ли оно real-time safe, очень сильно зависит от спецификации. Очень хороший пример, именно за такими деталями нужно следить: оказывается, boost::variant, которым тоже многие люди до сих пор пользуются, — не real-time safe. Потому что у него есть сильная гарантия исключений.
Значит, если мы присваиваем варианту новое значение, а в это время у нас бросается исключение, то boost::variant, имея вот эту сильную гарантию, откатывает присваивание назад. Например, у std::vector::push_back такая гарантия тоже есть. И boost::variant снова как бы восстановит значение, которое у него было раньше. Он делает это с помощью временного буфера, где мы кешируем старое значение, а в случае исключения можем его оттуда восстановить. Чтобы создать временный буфер, нам нужна аллокация памяти. Поэтому boost::variant — не real-time safe.
Спецификация с std::variant немного отличается. Там этой сильной гарантии исключений нет. Если во время присваивания новому значению std::variant бросается исключение, то std::variant вообще не будет иметь значения — приобретет специальное значение valueless_by_exception.
Поэтому нам не надо кешировать старое значение. Этот временный буфер нам не нужен, и аллокация тоже. Я очень рад, что комитет решил именно так специфицировать вариант в стандарте, потому что это значит, что он real-time safe.
Пошли дальше. Все, что употребляет type erasure в стандарте, — конечно, не real-time safe. Это касается таких классов, как std::any, std::function, которые делают type erasure. Потому что для этого нам в принципе нужна динамическая аллокация. Конечно, у них есть так называемое small object optimization, но это не портабельно, полагаться на это не стоит.

Кстати, std::function знает про аллокаторы, и у std::function есть специальный конструктор с tag-type std::allocator_arg_t. Поэтому std::function можно передать кастомный аллокатор. Например, этот псевдоаллокатор, который на самом деле ничего не аллоцирует, мы его видели ранее. Это, наверное, работает. Но я должен сказать, что в практике, в коде, я еще не видел такого, потому что есть альтернатива. Мы можем всегда пользоваться лямбдами. Лямбды всегда будут real-time safe, если, опять-таки, у вас захваты лямбды — real-time safe, если вы не будете, например, захватывать стринг по значению. Тогда сама по себе лямбда, определение лямбды не будет аллоцировать память. Это всё будет на стеке. В стандарте точно описано, как это поведение определено и что там происходит. И это всё — real-time safe.
Так что лямбда — хороший вариант. Конечно, если вы потом будете передавать эту лямбду как параметр дальше, вашему алгоритму, и ваша функция возьмёт её как std::function, то это вам не поможет: снова будет аллокация в конструкторе std::function.
Вам нужно написать шаблон с этими функциями, шаблонным параметром и передать эту лямбду туда, как это делают std-алгоритмы. Тогда все будет хорошо. В самом новом стандарте C++20, кроме лямбд, появились еще корутины — нечто вроде другого варианта функций. Корутины, к сожалению, не real-time safe, потому что в данном случае создание такого coroutine frame требует динамической аллокации, это стоит иметь в виду.
В некоторых случаях компилятор умеет оптимизировать аллокацию. Но на это полагаться, к сожалению, нельзя.
Посмотрим, какие еще есть классы в стандартной библиотеке. Есть, конечно, очень много инструментов для синхронизации потоков, разные варианты мьютексов, condition_variable. В 20-м стандарте появились другие примитивы синхронизаций: semaphore, latch, barrier. Они все очень полезные.
К сожалению, ни один из них не является real-time safe, потому что каждый из них требует взаимодействия системы с планировщиком потоков в какой-либо форме. Получается, что пользоваться ими на real-time-потоке мы не можем. Многие не совсем это понимают. Я видел, например, такой код.
Есть объект, shared_object, который нам нужен в real-time-потоке и, может быть, ещё в каком-нибудь потоке. Вокруг него есть мьютекс. Программист говорит: конечно, ждать мьютекса на real-time-потоке мы не можем, но можем вызвать std::try_to_lock. Он пытается приобрести мьютекс, потом мы можем делать с ним наш process. А если мьютекс занят другим потоком, тогда try_to_lock ничего не ждет, сразу возвращает false. Тогда мы можем идти по другой ветке и делать, например, fallback strategy: просто заполнить наш буфер нулями, будет тишина.

Это правда, что вызов try_to_lock — real-time safe. Проблема в этой скобочке. Если мы получили мьютекс и сделали наш process, а в это время другой поток захочет завладеть этим мьютексом, начнет блокировать и его ждать, то по достижении этой скобки нам нужно будет в нашем real-time-потоке этот другой поток разбудить. А это системный вызов. Нам нужно в какой-то форме взаимодействовать с планировщиком потоков. Так нельзя.
Поэтому всё просто. Плюсы имеют один только real-time safe механизм для синхронизации потоков: std::atomic. Только им мы можем пользоваться, чтобы синхронизировать real-time-поток с другими потоками.

Std::atomic можно пользоваться самим по себе, как переменной, если у нас одна переменная, разделяемая между real-time-потоком и другим потоком. На основе atomic можно написать разные lock-free--структуры данных.
Например, самая популярная, которая используется везде, — lock-free_queue. Причём я не рекомендую это имплементировать самим: это, оказывается, очень сложно. А потом с помощью atomic мы тоже можем написать spinlocks, а он, кстати, позволяет написать операцию try_lock, которую мы видели в предыдущем слайде, так, чтобы она была real-time safe.
Spinlocks можно написать либо наивным способом, либо есть более эффективная имплементация. На прошлогодней конференции у меня был доклад только на эту тему: как имплементировать такой spinlock.
Важно иметь в виду: atomic и lock-free — тоже разные понятия. То, что нам здесь нужно, — именно lock-free. Это значит, что наш поток не будет ждать других потоков, не будет блокировать.
Слово atomic само по себе значит только то, что ваша переменная не может вести состояние гонки. А lock-free значит, что архитектура вашего компьютера имеет нативные CPU-инструкции для atomic-load, atomic-store, atomic-compare-exchange, для вот этого типа «Т», которым вы пользуетесь. Тогда мьютексы не нужны.
Если тип «Т» у вас, например, bool или int — конечно, на современной архитектуре всё будет в порядке. А если что-нибудь другое, то уже нужно быть осторожным.
Предположим, вы хотите использовать complex, сложное число в atomic. Это уже интересно. Тогда, чтобы быть уверенным, что ваш atomic — lock-free, нужно всегда писать такой static_assert. Ели это выражение у вас пройдет — все хорошо. А если оно ложное, значит, для этого типа lock-free-инструкции на вашей архитектуре нет. Atomic только гарантирует, что у вас не будет состояния гонки. В таком случае, чтобы это обеспечить, компилятор будет вставлять мьютексы, а это как раз нам не нужно. Поэтому надо писать этот static_assert. И это сильно зависит от машины. Например, конкретно этот static_assert с complex на моём MacBook проходит. А вот на PC, на другом моём компьютере, уже нет.
Мы поговорили про atomic. Теперь поговорим ещё об одной области стандартной библиотеки — генерации случайных чисел.
Если вы занимаетесь обработкой сигналов в real-time, это может вам понадобиться. Очень часто в аудио встречается кейс: например, у вас есть буфер и вы хотите наполнить его белым шумом.
Значит, наполняем случайными числами между минус единицей и единицей. Или в данном случае ещё проще: между нулём и единицей. Мы просто создаём последовательность случайных чисел между нулём и единицей, пишем их в буфер, и у нас будет такой случайный белый шум.
Я очень часто вижу, как люди пишут вот такой код. Здесь есть баг: промежуток у нас полуоткрытый, а этот код может возвратить единицу. Но намного хуже, что люди до сих пор пользуются такой функцией — rand.

На мой взгляд, это совершенно бесполезная функция. И не потому, что у неё плохое качество случайностей, а потому, что мы не занимаемся криптографией. Мы просто генерируем шум. Поэтому нам здесь такая криптографическая точность и высококачественные случайные числа не нужны.

Но есть ещё, как минимум, две причины, почему rand пользоваться нельзя. Посмотрим стандарт, посмотрим на спецификации этой функции. Там, в первую очередь, написано, что rand не портабельный, так что последовательность чисел будет разная на разных платформах. Из-за этого будет сложнее писать тесты.
Намного хуже, что в стандарте есть такая фраза:

Фраза говорит, что ей разрешается имплементировать rand из стандартной библиотеки так, чтобы он не вводил в состояние гонки. И это именно те фразы в стандарте, на которые нужно обращать особое внимание.
Если где-то написана подобная фраза, а она встречается в нескольких местах в стандарте, значит, там могут быть мьютексы и любая такая функция — не real-time safe. Значит, нужно пользоваться плюсовыми генераторами случайных чисел, которые у нас есть. Как минимум, mersenne_twister_engine, linear_congruential_engine и subtract_with_carry_engine. Из них mersenne_twister — наверное, самый популярный.
Что насчёт них? Посмотрим в стандарте.

Там написано, что у любого генератора случайных чисел, который соответствует стандарту, эта функция, вызов, генерация нового числа имеет амортизированную константную сложность. Значит, это опять не real-time safe.
Я пытался понять, почему так. Я не специалист по генерации случайных чисел, и у меня какое-то время назад в Твиттере был такой разговор.

Я задал вопрос: что делать? Оказалось, что, действительно, если вызывать mersenne_twister, обычно он вам просто сгенерирует новое число. Но иногда он может решить: давайте пересчитаем всё наше внутреннее состояние. Это нам в real-time совсем не надо.

В плюсах есть ещё два генератора случайных чисел. Один из них — linear_congruential_engine. Здесь всё вроде бы лучше. В стандарте написано, что именно он делает. Мне кажется, это вполне можно имплементировать с константной сложностью. Наверное, нормальная имплементация этого генератора будет иметь константную, а не амортизированную константную сложность. Но стандарт не даёт такой гарантии. Он не уточняет сложность каждого генератора, а просто говорит, что у них у всех амортизированная константная сложность. Но стандарт говорит, что этот генератор делает, и там вроде бы всё нормально.
Я этим генератором пользовался в аудиокоде, и проблем на практике не возникло. Конечно, он не самый эффективный для нашего юз-кейса.

Самый эффективный, лучший генератор, который я нашел для обработки сигналов в real-time, — это Xorshift. Его в стандарте нет. У него нет свойства cryptographically secure, но нас оно не интересует. Он крайне быстрый, крайне эффективный и real-time safe. Рекомендую пользоваться именно им.
Предположим, у нас есть имплементация, их можно найти несколько, и она соответствует стандартному интерфейсу.
Значит, теперь у нас есть наша xorshift_rand_engine. Как мы теперь будем генерировать случайные числа между нулём и единицей прямо по правилам современного C++? Получится такой код. Оказывается, если мы хотим в современных плюсах сгенерировать случайные числа с таким равномерным распределением между нулём и единицей, то для этого есть специальный кластер в стандарте.

Конкретно для float есть uniform_real_distribution. Тогда нам нужно обернуть наш генератор случайных чисел в такой объект, который нам даёт желаемое равномерное распределение.
Но, конечно, опять возникает вопрос: какова сложность этой операции? Является ли она real-time safe? Такой вопрос нас ждёт прямо на каждом шагу, если мы в нашем real-time-коде хотим пользоваться стандартной библиотекой.

Если мы посмотрим в стандарт, то увидим: для этих равномерных распределений написано следующее. Оказывается, в плюсах они имеют сразу два неудачных свойства.
Первое свойство: их алгоритм не определён. Это, мне кажется, не очень удачно: получается, если вы берёте просто голый плюсовый генератор случайных чисел, он вам даст одинаковую последовательность на каждой платформе.
Но если вы обернёте этот генератор в стандартное распределение и запустите это на Clang, GCC и Microsoft Visual C++, вы получите три разные последовательности. Писать тесты, опять-таки, будет сложнее.
Второй момент: стандарт вообще ничего не говорит о таких сложностях. Нам нужно самим разобраться, что эти распределения делают в стандарте.

Оказывается, эти uniform_*_distribution в стандарте имеют амортизированную сложность, потому что если берут случайное число, то могут от него отказаться и запросить новое. Сколько раз они это будут делать, теорией не ограничено.

Опять я полез в Твиттер, чтобы пытаться понять, в чем же дело. И Питер Бинделс (Peter Bindels) мне всё объяснил. Оказалось, что, действительно, равномерное распределение можно либо имплементировать так, чтобы полностью отсутствовал bias, а значит, у каждого возможного числа будет абсолютно одинаковая вероятность, либо получить константную сложность. Но иметь и то и другое, к сожалению, невозможно. А в стандарте написано, что у этих распределений отсутствует bias — значит, сложность у них не константная.
Наверное, на практике проблем не будет, но в теории они могут вызывать генератор неограниченное количество раз. Наверное, на практике это произойдёт, только если генератор случайных чисел у вас какой-то такой:

dilbert.com/strip/2001-10-25
Или, например, такой:

xkcd.com/221
Тогда у вас будет кейс, при котором ваше распределение в худшем случае будет просто идти бесконечно и никогда не вернётся.
Ещё раз: на практике это, наверное, не проблема. Но чтобы перестраховаться, быть уверенным в сложности моего кода, я решил не пользоваться этими стандартными распределениями, а написать код вот так, быстро и грязно.
В таком распределении, конечно, нет полного отсутствия bias. Чисто математически распределение не стопроцентно равномерное. Но на практике для моих юз-кейсов этого вполне достаточно. Все тесты проходят. Сложность константная. Такой вызов занимает абсолютно одинаковое время каждый раз, если даёт результат в этом полуоткрытом интервале.
Если нужно распределение чисел с плавающей точкой, как здесь, то обычно у нас будет деление. Если нужно распределение целых чисел, то обычно где-нибудь будет оператор modulus. Но главное, что всё это — real-time safe.
Слайды закончились, мы дошли до конца. Я надеюсь, что вы составили впечатление о том, как пользоваться стандартной библиотекой для обработки сигналов в real-time, за чем нужно следить и как читать стандарт.

Хочу поблагодарить многих людей, которые помогли мне всё это понять. С этими pmr-аллокаторами и равномерными распределениями мне особенно помогли Фэбиен Ренн-Джайлс (Fabian Renn-Giles) и Питер Бинделс (Peter Bindels).
— Всем привет, меня зовут Тимур Думлер. Хочу сказать, что я обычно делаю доклады на английском языке. Это всего второй раз в жизни, когда я докладываю на русском, мне это немножко непривычно. Спасибо большое, что подключились, сегодня мы поговорим про использование стандартной библиотеки C++ для обработки сигналов в real-time.
Разберёмся сначала, что вообще такое real-time. Второй термин, который часто встречается в этом контексте, — low latency. Как real-time связан с low latency?

Если мы посмотрим на эффективность нашего кода — а это, конечно, в плюсах всех интересует, — то там есть два ортогональных аспекта эффективности. Есть так называемая bandwidth, мне кажется, по-русски это называется пропускная способность. И есть latency — задержка. Грубо говоря, bandwidth — это то, сколько информации наша программа перерабатывает, скажем, в секунду. Значит, если представить себе трубу, то bandwidth определяет, сколько информации через неё течёт. А latency — это примерно сколько времени проходит между запросом и ответом.
И в докладе нас не будет интересовать bandwidth, потому что количество данных, которые мы здесь перерабатываем, достаточно небольшое. Мы интересуемся именно latency. И «real-time» означает, что у нас имеется максимальная верхняя граница допускаемой задержки. Поэтому в первом приближении можно определить понятие real-time так: код считается корректным, если он не только даёт правильный результат, но даёт его в определенный период времени.
В каких юз-кейсах встречается понятие real-time? Это, конечно, высокочастотный трейдинг, компьютерные игры, разные встроенные системы: автомобили, роботы, пылесосы и тому подобное. А также обработка аудиосигналов. Это те области, где плюсы как раз очень популярны.
Моя область — как раз обработка аудиосигналов. Это то, чем я занимаюсь последние десять лет. Хочу просто коротко объяснить, что это за юз-кейсы, чтобы было понятно, какая у нас здесь мотивация.

Если вы занимаетесь обработкой аудиосигналов в real-time, то у вас есть звуковая карта, которая через аудиостек вашей операционной системы вам даёт callback, вызывает вашу функцию, которая может называться process, и даёт вам буфер, в который нужно записать звуковые данные. Когда вы это сделали, буфер идёт через весь этот стек назад в звуковую карту. Там это превращается в аналоговый сигнал и передаётся дальше в колонки, где превращается в звук, который вы можете услышать.
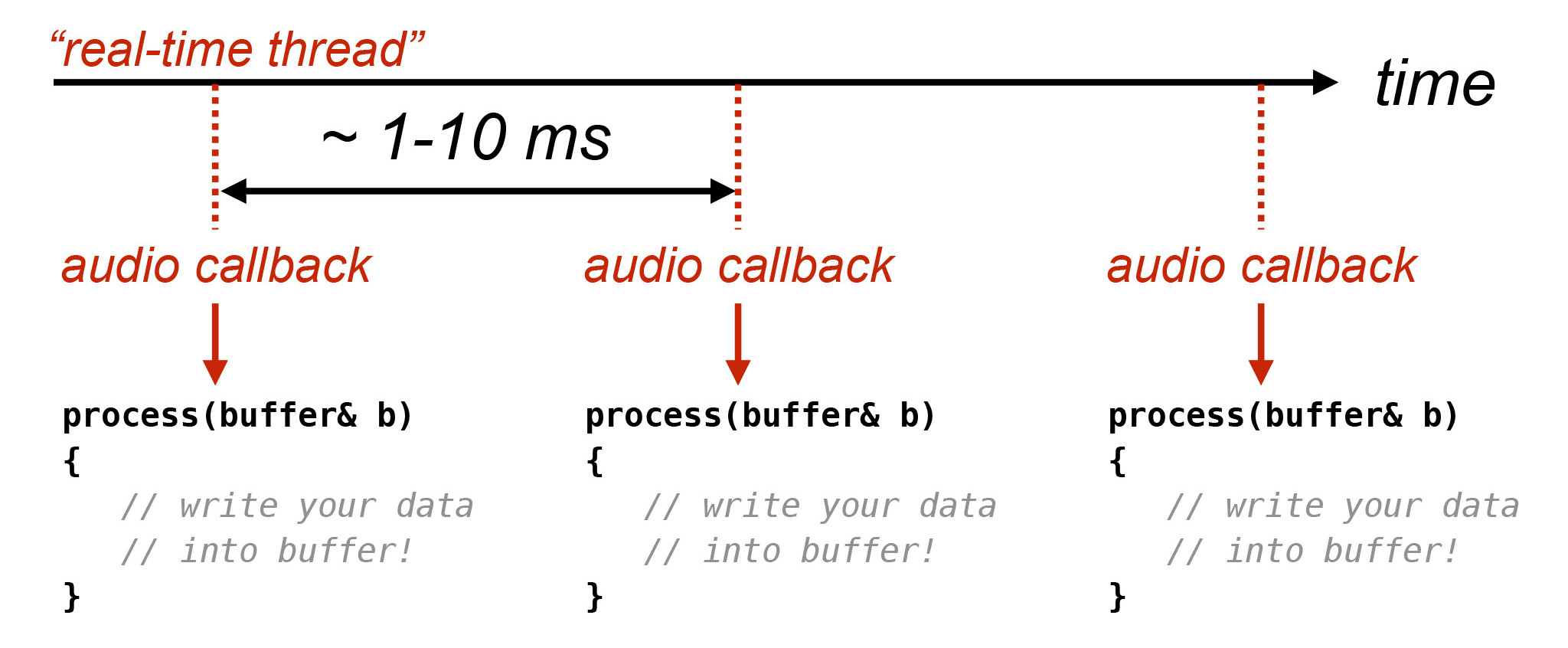
И callback приходит регулярно, в регулярных интервалах на высокоприоритетном потоке, который, вне зависимости от операционной системы, либо выдаёт вам сама ОС, либо создаёте вы сами. Значит, на этом высокоприоритетном real-time-потоке у вас будут такие callback. Причём они будут в регулярных промежутках времени. В зависимости от настроек юзера, например, от размера буфера, частоты дискретизации и всякого такого, время между двумя последующими callback — где-то 1-10 миллисекунд.
Если вы пропустили это окно времени, которое у вас есть, чтобы заполнить буфер данными, то в буфере в момент, когда звук будет воспроизводиться, окажется мусор и в колонках будет такой слышимый щелчок.
Если ваш софт такое делает, никто его покупать не будет. Так что очень важно успеть за этот дедлайн, чтобы всё, что делает ваша функция process, закончилось. В этом смысле аудио немного отличается от других юз-кейсов низкой задержки. Если вы, например, занимаетесь трейдингом, то вам очень важно, займёт ли функция process 100 или 110 микросекунд. Потому что если вы не максимально быстрые, то можете потерять миллион долларов. А если вы интересуетесь пропускной способностью и ваш сервер обрабатывает очень много запросов, то вам, конечно, тоже очень важно минимизировать время, потому что время обработки суммируется.
В аудио, наверное, нас не столько интересует, займёт ли process 100 или 110 микросекунд. Но нас интересует, чтобы функция занимала 110 микросекунд максимум. Она никогда не займёт, например, 1000 микросекунд, даже один раз в миллион. Если это произойдёт, будет щелчок, поскольку мы не успели написать данные. У нас есть такой абсолютный дедлайн для всего, что происходит в этой функции process.
Причём «real-time» — он как бы в кавычках, потому что есть этот дедлайн. Но одновременно мы это делаем на самой обычной операционной системе. Вот если вы программируете для автомобилей или самолётов, то там у вас будет real-time операционная система, специальная, где этот дедлайн физически обеспечивается, и у вас будет real-time kernel. А в случае аудиософта мы в обыкновенной пользовательской операционной системе — Windows, macOS, iOS, Linux, Android. Там физического real-time-ядра нет. Планировщик потоков мы не контролируем. Мы просто используем поток с высоким приоритетом. И надеемся, что операционная система будет всё планировать правильно.
На практике проблем с этим не возникает, поэтому «real-time» мы в этом докладе как бы ставим в кавычки.
Возвращаясь к нашему аудио, callback и к нашей функции process. Нам нужно успеть заполнить буфер звуковыми кадрами в какое-то относительно короткое время.

У нас есть функция writeFrames, которая пишет туда звуковые кадры. Есть, например, функция applyGain, которая, может быть, меняет громкость этих кадров. Нам нужно задавать себе вопрос: можно ли вызывать эти функции в real-time-потоке без появления щелчков?
У аудиопрограммистов есть понятие real-time safe. Это как раз тот вопрос, который нас интересует.
Можно определить достаточно неформально, что код считается real-time safe, если есть абсолютная верхняя граница времени его исполнения. Код 100% времени не превышает эту верхнюю границу. Она должна быть, конечно, ниже вашего доступного промежутка времени. Если вы вызываете много функций, то сумма верхних границ не должна превышать одной миллисекунды или другого времени, зависит от настройки. Причём если эта верхняя граница в принципе известна, то на практике нам достаточно часто не нужно измерять и бенчмаркить каждую функцию, которую мы вызываем.
Мы можем предположить, что она real-time safe, если она обладает некоторыми свойствами. Что это за свойства?
- Не блокировать real-time-поток
(Неизвестное время ожидания + priority inversion!)
- Не пытаться завладеть мьютексом
- Не аллоцировать / деаллоцировать память
- Не делать I/O
- Не взаимодействовать с планировщиком потоков
- Не делать никаких других системных вызовов
- Не пользоваться аглоритмами сложности > O(1)
- Не пользоваться аглоритмами амортизированной сложности
- Не вызывать никакого стороннего кода
Конечно, нам нельзя блокировать real-time-поток. В первую очередь потому, что если мы блокируем и ждём другого потока, то не знаем, сколько времени это займёт. Значит, у нас есть это неизвестное время ожидания, нет абсолютно верхней границы. И потом, если другой поток, которого мы ждём, имеет приоритет ниже, чем наш real-time-поток, то ещё возникает вот эта проблема — priority inversion.
Что значит «не блокировать»? Значит, мы не можем пользоваться мьютексами, не можем аллоцировать/деаллоцировать память, не можем заниматься никаким input/output, вообще не можем взаимодействовать с планировщиком потоков и с операционной системой, не можем делать никаких системных вызовов.
Кроме того, даже если мы ничего из этого не делаем, а просто вызываем алгоритмы, то нам нужно знать, когда и в какое время они закончатся. Следовательно, нам в принципе нельзя пользоваться алгоритмами, которые имеют не константную сложность. В том числе, если у нас O(N) и мы не знаем величину N, не знаем, какая у нее верхняя граница времени, то не можем вызывать эту функцию.
Также мы не можем пользоваться алгоритмами амортизированной сложности. Пример классической амортизированной сложности — вставка в хеш-таблицу. У неё почти всегда константная сложность. Но иногда хеш-таблица может решить: а давайте перестроим весь индекс! И если вы это будете делать на real-time-потоке, то, конечно, возникнет проблема. Мы вообще не можем вызывать никакой сторонний код, если не знаем точно, что внутри происходит, нет ли там мьютексов, аллокаций и так далее.
Вы можете найти в интернете достаточно докладов, я и сам их делал, и другие авторы, о том, как программировать в таком стиле. Про это я не буду здесь рассказывать.
Мы, имея такое неформальное определение real-time safe, рассмотрим другой вопрос. У нас, поскольку мы, как и все остальные, пользуемся нормальными ОС и нормальной имплементацией C++, есть стандартная библиотека. Конечно же, было бы удобно, если бы мы могли пользоваться возможностями стандартной библиотеки из коробки. И мы рассмотрим вопрос, какие части именно стандартной библиотеки являются real-time safe. На практике он возникает достаточно часто.
Причём нас, конечно, интересует код во время выполнения, потому что код на этапе компиляции является real-time safe по определению, мы во время рантайма ничего не делаем.
Конечно, мы не сможем перечислить каждую функцию и каждый класс в стандартной библиотеке, время у нас ограничено. Но я расскажу про некоторые популярные, интересные части библиотеки. И главное, я расскажу, как нужно читать текст стандарта, чтобы самому почувствовать, чем можно и чем нельзя пользоваться. Идея в том, что мы хотим писать портабельный код, поэтому обращаемся в стандарт и смотрим, как вещи специфицированы там.
Именно в этом и состоит цель доклада: получить чувство того, как нужно смотреть на стандарт, чтобы понять, является ли real-time safe какая-нибудь конкретная функция или класс стандартной библиотеки.
Посмотрим на стандарт.
- Стандарт C++ не говорит о границах времени выполнения
- Стандарт C++ не говорит “f не аллоцирует память”
- Из спецификации иногда понятно, что аллокации не нужны
- Иногда есть полезные фразы вроде “f might invalidate iterators”, “If there is enough memory, f does X, otherwise...”
- Стандарт C++ не говорит “X не употребляет мьютексы”
- Иногда есть фраза “X may not be accessed from multiple threads simultaneously”
- Иначе, иногда есть фраза “X may not introduce data races”
Конечно, оказывается, что стандарт C++ вообще не говорит о границах времени выполнения. Понятие верхней границы, времени выполнения, которое нас интересует, в стандарте полностью отсутствует. Также стандарт C++ нигде не говорит, что, например, какая-нибудь функция не аллоцирует память. Но из спецификации стандарта иногда понятно, что аллокации не нужны оптимальной имплементации.
Иногда в стандарте есть полезные фразы — например, вот эта функция инвалидирует итераторы. Тогда мы знаем, что, наверное, она может реаллоцировать элементы вектора и это будет аллокация. Иногда стандарт говорит: если есть достаточно памяти, тогда функция делает это, а иначе — что-то другое. Тогда мы знаем, что функция попытается аллоцировать память.
Также стандарт C++ не говорит, что такой-то класс не употребляет мьютексы. Но иногда есть фраза: нельзя иметь доступ к классу Х из нескольких потоков одновременно. Тогда мы знаем: мьютексов там, наверное, нет. И наоборот, иногда появляется фраза, что данный объект или класс не может вводить условия гонки, в стандарте это написано. Тогда мы знаем: внутри, наверное, есть мьютексы, чтобы обеспечить такое поведение, и в real-time таким классом пользоваться нельзя.
Мы видим: пользоваться стандартной библиотекой для real-time — не точная наука. Нам нужно часто и очень внимательно читать стандарт. Когда мы поняли спецификацию, нужно ещё и доверять качеству имплементации стандартной библиотеки — точно так же, как мы доверяем качеству имплементации нашей ОС.
Посмотрим на конкретные части языка и стандартной библиотеки. В первую очередь нужно сказать, что исключения — не real-time safe. Есть люди, которые стараются это изменить. А конкретно — у Герба Саттера есть такой proposal, который пытается ввести новый механизм исключений в C++. У этого механизма будет свойство real-time safe.

Но, к сожалению, никто не знает, попадет ли когда-нибудь этот proposal в стандарт. А для того, что у нас есть сегодня, главная информация находится прямо здесь, на первой странице proposal. Здесь написано: сегодняшние исключения не имеют верхней границы времени, которая нас интересует и, вообще, аллоцирует память. Поэтому нам в принципе говорить про исключения больше не нужно.
Говорим про алгоритмы по STL, header <algorithm>. Какие STL-алгоритмы считаются real-time safe? Алгоритмов в стандартной библиотеке сейчас уже очень много. Они даже уже не помещаются на один слайд.
Открыть список алгоритмов
all_of
any_of
none_of
for_each
for_each_n
count
count_if
mismatch
find
find_if
find_if_not
find_end
find_first_of
adjacent_find
search
search_n
starts_with
ends_with
copy
copy_if
copy_n
copy_backward
move
move_backward
fill
fill_n
transform
generate
generate_n
remove
remove_if
remove_copy
remove_copy_if
replace
replace_if
replace_copy
replace_copy_if
swap
swap_ranges
iter_swap
reverse
reverse_copy
rotate
rotate_copy
shift_left
shift_right
shuffle
sample
unique
unique_copy
is_partitioned
partition
partition_copy
stable_partition
partition_point
is_sorted
is_sorted_until
sort
partial_sort
partial_sort_copy
stable_sort
nth_element
lower_bound
upper_bound
binary_search
equal_eange
merge
inplace_merge
includes
set_difference
set_intersection
set_symmetric_difference
set_union
is_heap
is_heap_until
make_heap
push_heap
pop_heap
sort_heap
max_element
min
min_element
minmax
minmax_element
clamp
equal
lexicographical_compare
lexicographical_compare_three_way
is_permutation
next_permutation
prev_permutation
iota
accumulate
inner_product
adjacent_difference
partial_sum
reduce
exclusive_scan
inclusive_scan
transform_reduce
transform_exclusive_scan
transform_inclusive_scan
uninitialized_copy
uninitialized_copy_n
uninitialized_fill
uninitialized_fill_n
uninitialized_move
uninitialized_move_n
uninitialized_default_construct
uninitialized_default_construct_n
uninitialized_value_construct
uninitialized_value_construct_n
destroy
destroy_n
destroy_at
construct_at
any_of
none_of
for_each
for_each_n
count
count_if
mismatch
find
find_if
find_if_not
find_end
find_first_of
adjacent_find
search
search_n
starts_with
ends_with
copy
copy_if
copy_n
copy_backward
move
move_backward
fill
fill_n
transform
generate
generate_n
remove
remove_if
remove_copy
remove_copy_if
replace
replace_if
replace_copy
replace_copy_if
swap
swap_ranges
iter_swap
reverse
reverse_copy
rotate
rotate_copy
shift_left
shift_right
shuffle
sample
unique
unique_copy
is_partitioned
partition
partition_copy
stable_partition
partition_point
is_sorted
is_sorted_until
sort
partial_sort
partial_sort_copy
stable_sort
nth_element
lower_bound
upper_bound
binary_search
equal_eange
merge
inplace_merge
includes
set_difference
set_intersection
set_symmetric_difference
set_union
is_heap
is_heap_until
make_heap
push_heap
pop_heap
sort_heap
max_element
min
min_element
minmax
minmax_element
clamp
equal
lexicographical_compare
lexicographical_compare_three_way
is_permutation
next_permutation
prev_permutation
iota
accumulate
inner_product
adjacent_difference
partial_sum
reduce
exclusive_scan
inclusive_scan
transform_reduce
transform_exclusive_scan
transform_inclusive_scan
uninitialized_copy
uninitialized_copy_n
uninitialized_fill
uninitialized_fill_n
uninitialized_move
uninitialized_move_n
uninitialized_default_construct
uninitialized_default_construct_n
uninitialized_value_construct
uninitialized_value_construct_n
destroy
destroy_n
destroy_at
construct_at
Но какие из них real-time safe?
И при этом мы предполагаем, что тип элементов — тоже real-time safe. Например, если тип элементов у вас std::string и вы их копируете, то, конечно, у вас будет аллокация. Или если итератор у вас std::back_insert_iterator<std::vector> или std::ostream_iterator, что-нибудь такое — конечно, это тоже не будет real-time.
Вопрос, который нас здесь интересует: будут ли аллокации внутри самого алгоритма? Конечно, стандарт C++ этого не определяет.
Но почти всегда, почти для всех алгоритмов, оптимальная имплементация этой спецификации в стандарте не требует аллокации памяти. Поэтому мы можем исходить из того, что нормальная имплементация стандартной библиотеки не будет аллоцировать память. Значит, мы можем пользоваться таким алгоритмом.
Это касается не всех из них. Для некоторых алгоритмов существует более быстрая имплементация, если им разрешить аллоцировать временный буфер для промежуточных данных. Для этих алгоритмов стандартная библиотека будет пользоваться именно такой быстрой имплементацией и будет пытаться аллоцировать для нее память.

Хорошая новость в том, что стандарт нам об этом говорит. Для каждого такого алгоритма мы находим в стандарте вот такие волшебные слова. Сложность алгоритма, если у нас достаточно памяти, она, значит, такая. А иначе — такая. Всегда когда мы видим эти волшебные слова в стандарте, мы знаем, что такой алгоритм будет пытаться создать временный буфер, а для этого он будет пытаться аллоцировать память.
Вторая хорошая новость: это свойство имеют всего лишь три алгоритма стандартной библиотеки: stable_sort, stable_partition и inplace_merge. Из них, я бы сказал, stable_sort наиболее часто употребляется. Например, в каком-нибудь сложном звуковом движке. Так что не делайте этого, не употребляйте эти алгоритмы в таком контексте.

Конечно, std::array на стеке, поэтому он real-time safe по определению, кроме функции at, которая бросает исключение. Но если это происходит — наверное, у вас есть более серьезные проблемы.
Все остальные STL-контейнеры употребляют динамическую память, значит, они из коробки не real-time safe.
Что же делать, если нам все равно нужен динамический контейнер на real-time-потоке, что встречается достаточно часто?
Есть один метод, который я часто видел на практике. Многие аудиопрограммисты делают вот это.
void process(buffer& b)
{
float vla[b.size()]; // variable-length array (VLA)
}Они пользуются так называемым variable-length array. Это значит — массив, где размер определяется во время рантайма. Отлично работает в C, на Clang и на GCC. Но это не стандартный C++, это extension стандарта. И на Windows это не собирается, вы получите вот такую ошибку.
void process(buffer& b)
{
float vla[b.size()]; // MSVC: error C2131:
} // expression did not evaluate to a constantБыл, кстати, такой случай, когда я работал с библиотекой, со специализированными аудиоалгоритмами. Автор обещал, что всё портабельно. А потом я попытался собрать на винде, и всё развалилось, потому что везде были эти variable-length array. Пришлось всё переписывать. Было печально.
template <typename T, std::size_t capacity = 1024>
struct fixed_capacity_vector
{
// implement vector interface...
private:
std::array<T, capacity> data;
};
void process(buffer& b)
{
fixed_capacity_vector<float> v(b.size());
}Второй метод, который достаточно часто можно увидеть, — это когда люди пишут от руки вот такой вектор с максимальной вместимостью. При желании внутри есть аллоцированный буфер с максимальной вместимостью. Вокруг него мы пишем такой интерфейс для вектора, и он работает как нормальный вектор. Но когда кончается буфер, который у нас заранее аллоцирован, то вектор бросает исключение или делает что-нибудь ещё, выдаёт какую-нибудь другую ошибку.
Опять же, очень многие люди делают это на практике. Например, в компьютерных играх такой класс можно увидеть очень часто. Но, во-первых, это нужно писать от руки. Во-вторых, что если нам нужна другая динамическая структура данных? Например, нам нужно std::map, std::set или что-то такую?
Написать самому такую структуру данных, да еще так, чтобы она была real-time safe — конечно, очень сложно. Но, как мы знаем, можно использовать структуру данных из стандарта с кастомным аллокатом. Об этом говорили в других докладах конференции.
Какой самый простой аллокатор можно написать, чтобы он работал на real-time-потоке?
std::array<float, 1024> memory_pool;
template <typename T>
struct safe_allocator
{
using value_type = T;
safe_allocator(std::span<T> buffer);
T* allocate(std::size_t n); // use buffer until full, then throw/abort
T* deallocate(T* ptr, std::size_t n); // no-op
};
void process(buffer& b)
{
using safe_vector = std::vector<float, safe_allocator<float>>;
safe_allocator<float> allocator(memory_pool);
safe_vector v(b.size(), 0.0f, allocator);
}Нам нужен аллокатор, который работает только на этом потоке, не имеет внутри никаких мьютексов, ничего такого, существует только в то время, пока мы делаем этот process, и вообще не является аллокатором, потому что он не аллоцирует память.
Вместо этого мы ему даём буфер, который заранее аллоцирован, memory pool. Что делает аллокатор? Он просто берёт куски из этого заранее аллоцированного буфера, пока буфер не кончится. А потом он бросает bad_alloc, или вызывает terminate, или делает что-нибудь такое. А deallocate у такого аллокатора вообще ничего не делает.
Это самый простой real-time-аллокатор. Тогда его можно просто использовать как шаблонный аргумент для всех STL-контейнеров, и он будет работать. Начиная с C++17 даже не нужно писать самим, мы можем всё собрать из частей стандартной библиотеки. Это будет выглядеть примерно так.
std::array<float, 1024> memory_pool;
void process(buffer& b)
{
std::pmr::monotonic_buffer_resource monotonic_resource(
memory_pool.data(),
memory_pool.size(),
std::pmr::null_memory_resource());
using allocator_t = std::pmr::polymorphic_allocator<float>;
allocator_t allocator(&monotonic_resource);
std::pmr::vector<float> my_vector(b.size(), 0.0f, allocator);
}Опять memory pool, заранее аллоцированный буфер. На сей раз мы уже не пишем свой аллокатор, а используем аллокатор из стандартной библиотеки — std::pmr::monotonic_buffer_resource, длинное сложное слово. Что он делает? Как раз то, о чём мы сказали на предыдущем слайде: берёт заранее аллоцированный буфер, наш memory pool и просто берёт куски из буфера, пока тот не кончится. deallocate вообще ничего не делает.
Когда буфер кончится, monotonic_buffer_resource вызывает другой аллокатор — upstream resource и берёт память уже оттуда. Это третий аргумент в конструкторе. Мы ему даём std::pmr::null_memory_resource — тоже класс из стандартной библиотеки, которая появилась в 17-м стандарте.
А null_memory_resource, как вы уже можете догадаться, вообще ничего не делает — сразу бросает std::bad_alloc, как только вы попытаетесь у неё взять память. Как раз такое поведение нам в данном случае и нужно. Мы здесь уже ничего сами имплементировать не должны, это весь код, он соберется вот так.
Я прочитал историю инструментов std::pmr в стандартной библиотеке. У меня сложилось впечатление, что это не совсем тот юз-кейс, для которого они были добавлены в стандарт. Я сам ещё не пользовался этими классами в продакшене, но когда я смотрю на спецификацию, мне кажется, это как раз более-менее то, что надо. Наверное, можно этим пользоваться.
Как насчёт других утилит, которые есть в стандарте? Есть std::pair/std::tuple, на стеке, поэтому они снова real-time safe по определению. Есть std::optional, просто значение и bool на стеке. Это тоже real-time safe, там никаких аллокаций не будет. Некоторые функции std::optional бросают исключение std::optional_access, так что этими функциями не надо пользоваться. Ещё есть std::variant, обёртка вокруг union.

Казалось бы, это тоже real-time safe. Но вариант, кстати, интересный: у него свойство, является ли оно real-time safe, очень сильно зависит от спецификации. Очень хороший пример, именно за такими деталями нужно следить: оказывается, boost::variant, которым тоже многие люди до сих пор пользуются, — не real-time safe. Потому что у него есть сильная гарантия исключений.
Значит, если мы присваиваем варианту новое значение, а в это время у нас бросается исключение, то boost::variant, имея вот эту сильную гарантию, откатывает присваивание назад. Например, у std::vector::push_back такая гарантия тоже есть. И boost::variant снова как бы восстановит значение, которое у него было раньше. Он делает это с помощью временного буфера, где мы кешируем старое значение, а в случае исключения можем его оттуда восстановить. Чтобы создать временный буфер, нам нужна аллокация памяти. Поэтому boost::variant — не real-time safe.
Спецификация с std::variant немного отличается. Там этой сильной гарантии исключений нет. Если во время присваивания новому значению std::variant бросается исключение, то std::variant вообще не будет иметь значения — приобретет специальное значение valueless_by_exception.
Поэтому нам не надо кешировать старое значение. Этот временный буфер нам не нужен, и аллокация тоже. Я очень рад, что комитет решил именно так специфицировать вариант в стандарте, потому что это значит, что он real-time safe.
Пошли дальше. Все, что употребляет type erasure в стандарте, — конечно, не real-time safe. Это касается таких классов, как std::any, std::function, которые делают type erasure. Потому что для этого нам в принципе нужна динамическая аллокация. Конечно, у них есть так называемое small object optimization, но это не портабельно, полагаться на это не стоит.

Кстати, std::function знает про аллокаторы, и у std::function есть специальный конструктор с tag-type std::allocator_arg_t. Поэтому std::function можно передать кастомный аллокатор. Например, этот псевдоаллокатор, который на самом деле ничего не аллоцирует, мы его видели ранее. Это, наверное, работает. Но я должен сказать, что в практике, в коде, я еще не видел такого, потому что есть альтернатива. Мы можем всегда пользоваться лямбдами. Лямбды всегда будут real-time safe, если, опять-таки, у вас захваты лямбды — real-time safe, если вы не будете, например, захватывать стринг по значению. Тогда сама по себе лямбда, определение лямбды не будет аллоцировать память. Это всё будет на стеке. В стандарте точно описано, как это поведение определено и что там происходит. И это всё — real-time safe.
Так что лямбда — хороший вариант. Конечно, если вы потом будете передавать эту лямбду как параметр дальше, вашему алгоритму, и ваша функция возьмёт её как std::function, то это вам не поможет: снова будет аллокация в конструкторе std::function.
Вам нужно написать шаблон с этими функциями, шаблонным параметром и передать эту лямбду туда, как это делают std-алгоритмы. Тогда все будет хорошо. В самом новом стандарте C++20, кроме лямбд, появились еще корутины — нечто вроде другого варианта функций. Корутины, к сожалению, не real-time safe, потому что в данном случае создание такого coroutine frame требует динамической аллокации, это стоит иметь в виду.
В некоторых случаях компилятор умеет оптимизировать аллокацию. Но на это полагаться, к сожалению, нельзя.
Посмотрим, какие еще есть классы в стандартной библиотеке. Есть, конечно, очень много инструментов для синхронизации потоков, разные варианты мьютексов, condition_variable. В 20-м стандарте появились другие примитивы синхронизаций: semaphore, latch, barrier. Они все очень полезные.
Открыть список инструментов
mutex
timed_mutex
recursive_mutex
recursive_timed_mutex
shared_mutex
shared_timed_mutex
scoped_lock
unique_lock
shared_lock
condition_variable
condition_variable_any
counting_semaphore
binary_semaphore
latch
barrier
timed_mutex
recursive_mutex
recursive_timed_mutex
shared_mutex
shared_timed_mutex
scoped_lock
unique_lock
shared_lock
condition_variable
condition_variable_any
counting_semaphore
binary_semaphore
latch
barrier
К сожалению, ни один из них не является real-time safe, потому что каждый из них требует взаимодействия системы с планировщиком потоков в какой-либо форме. Получается, что пользоваться ими на real-time-потоке мы не можем. Многие не совсем это понимают. Я видел, например, такой код.
std::mutex mtx;
shared_object obj;
void process(buffer& b)
{
if (std::unique_lock lock(mtx, std::try_to_lock); lock.owns_lock())
{
do_some_processing(b, obj);
}
else
{
std::ranges::fill(b, 0.0f); // fallback strategy: output silence
}
}Есть объект, shared_object, который нам нужен в real-time-потоке и, может быть, ещё в каком-нибудь потоке. Вокруг него есть мьютекс. Программист говорит: конечно, ждать мьютекса на real-time-потоке мы не можем, но можем вызвать std::try_to_lock. Он пытается приобрести мьютекс, потом мы можем делать с ним наш process. А если мьютекс занят другим потоком, тогда try_to_lock ничего не ждет, сразу возвращает false. Тогда мы можем идти по другой ветке и делать, например, fallback strategy: просто заполнить наш буфер нулями, будет тишина.

Это правда, что вызов try_to_lock — real-time safe. Проблема в этой скобочке. Если мы получили мьютекс и сделали наш process, а в это время другой поток захочет завладеть этим мьютексом, начнет блокировать и его ждать, то по достижении этой скобки нам нужно будет в нашем real-time-потоке этот другой поток разбудить. А это системный вызов. Нам нужно в какой-то форме взаимодействовать с планировщиком потоков. Так нельзя.
Поэтому всё просто. Плюсы имеют один только real-time safe механизм для синхронизации потоков: std::atomic. Только им мы можем пользоваться, чтобы синхронизировать real-time-поток с другими потоками.

Std::atomic можно пользоваться самим по себе, как переменной, если у нас одна переменная, разделяемая между real-time-потоком и другим потоком. На основе atomic можно написать разные lock-free--структуры данных.
Например, самая популярная, которая используется везде, — lock-free_queue. Причём я не рекомендую это имплементировать самим: это, оказывается, очень сложно. А потом с помощью atomic мы тоже можем написать spinlocks, а он, кстати, позволяет написать операцию try_lock, которую мы видели в предыдущем слайде, так, чтобы она была real-time safe.
Spinlocks можно написать либо наивным способом, либо есть более эффективная имплементация. На прошлогодней конференции у меня был доклад только на эту тему: как имплементировать такой spinlock.
Смотреть доклад
Важно иметь в виду: atomic и lock-free — тоже разные понятия. То, что нам здесь нужно, — именно lock-free. Это значит, что наш поток не будет ждать других потоков, не будет блокировать.
Слово atomic само по себе значит только то, что ваша переменная не может вести состояние гонки. А lock-free значит, что архитектура вашего компьютера имеет нативные CPU-инструкции для atomic-load, atomic-store, atomic-compare-exchange, для вот этого типа «Т», которым вы пользуетесь. Тогда мьютексы не нужны.
Если тип «Т» у вас, например, bool или int — конечно, на современной архитектуре всё будет в порядке. А если что-нибудь другое, то уже нужно быть осторожным.
using T = std::complex<double>;
// if this fails, your compiler will add locks -> not “real-time safe”
static_assert(std::atomic<T>::is_always_lock_free);Предположим, вы хотите использовать complex, сложное число в atomic. Это уже интересно. Тогда, чтобы быть уверенным, что ваш atomic — lock-free, нужно всегда писать такой static_assert. Ели это выражение у вас пройдет — все хорошо. А если оно ложное, значит, для этого типа lock-free-инструкции на вашей архитектуре нет. Atomic только гарантирует, что у вас не будет состояния гонки. В таком случае, чтобы это обеспечить, компилятор будет вставлять мьютексы, а это как раз нам не нужно. Поэтому надо писать этот static_assert. И это сильно зависит от машины. Например, конкретно этот static_assert с complex на моём MacBook проходит. А вот на PC, на другом моём компьютере, уже нет.
Мы поговорили про atomic. Теперь поговорим ещё об одной области стандартной библиотеки — генерации случайных чисел.
Если вы занимаетесь обработкой сигналов в real-time, это может вам понадобиться. Очень часто в аудио встречается кейс: например, у вас есть буфер и вы хотите наполнить его белым шумом.
// returns a random float in the interval [0, 1)
float get_random_sample()
{
return float(std::rand()) / float(INT_MAX);
}
void process(buffer& b)
{
// fill buffer with random white noise:
std::ranges::fill(b, get_random_sample);
}Значит, наполняем случайными числами между минус единицей и единицей. Или в данном случае ещё проще: между нулём и единицей. Мы просто создаём последовательность случайных чисел между нулём и единицей, пишем их в буфер, и у нас будет такой случайный белый шум.
Я очень часто вижу, как люди пишут вот такой код. Здесь есть баг: промежуток у нас полуоткрытый, а этот код может возвратить единицу. Но намного хуже, что люди до сих пор пользуются такой функцией — rand.

На мой взгляд, это совершенно бесполезная функция. И не потому, что у неё плохое качество случайностей, а потому, что мы не занимаемся криптографией. Мы просто генерируем шум. Поэтому нам здесь такая криптографическая точность и высококачественные случайные числа не нужны.

Но есть ещё, как минимум, две причины, почему rand пользоваться нельзя. Посмотрим стандарт, посмотрим на спецификации этой функции. Там, в первую очередь, написано, что rand не портабельный, так что последовательность чисел будет разная на разных платформах. Из-за этого будет сложнее писать тесты.
Намного хуже, что в стандарте есть такая фраза:

Фраза говорит, что ей разрешается имплементировать rand из стандартной библиотеки так, чтобы он не вводил в состояние гонки. И это именно те фразы в стандарте, на которые нужно обращать особое внимание.
Если где-то написана подобная фраза, а она встречается в нескольких местах в стандарте, значит, там могут быть мьютексы и любая такая функция — не real-time safe. Значит, нужно пользоваться плюсовыми генераторами случайных чисел, которые у нас есть. Как минимум, mersenne_twister_engine, linear_congruential_engine и subtract_with_carry_engine. Из них mersenne_twister — наверное, самый популярный.
Что насчёт них? Посмотрим в стандарте.

Там написано, что у любого генератора случайных чисел, который соответствует стандарту, эта функция, вызов, генерация нового числа имеет амортизированную константную сложность. Значит, это опять не real-time safe.
Я пытался понять, почему так. Я не специалист по генерации случайных чисел, и у меня какое-то время назад в Твиттере был такой разговор.
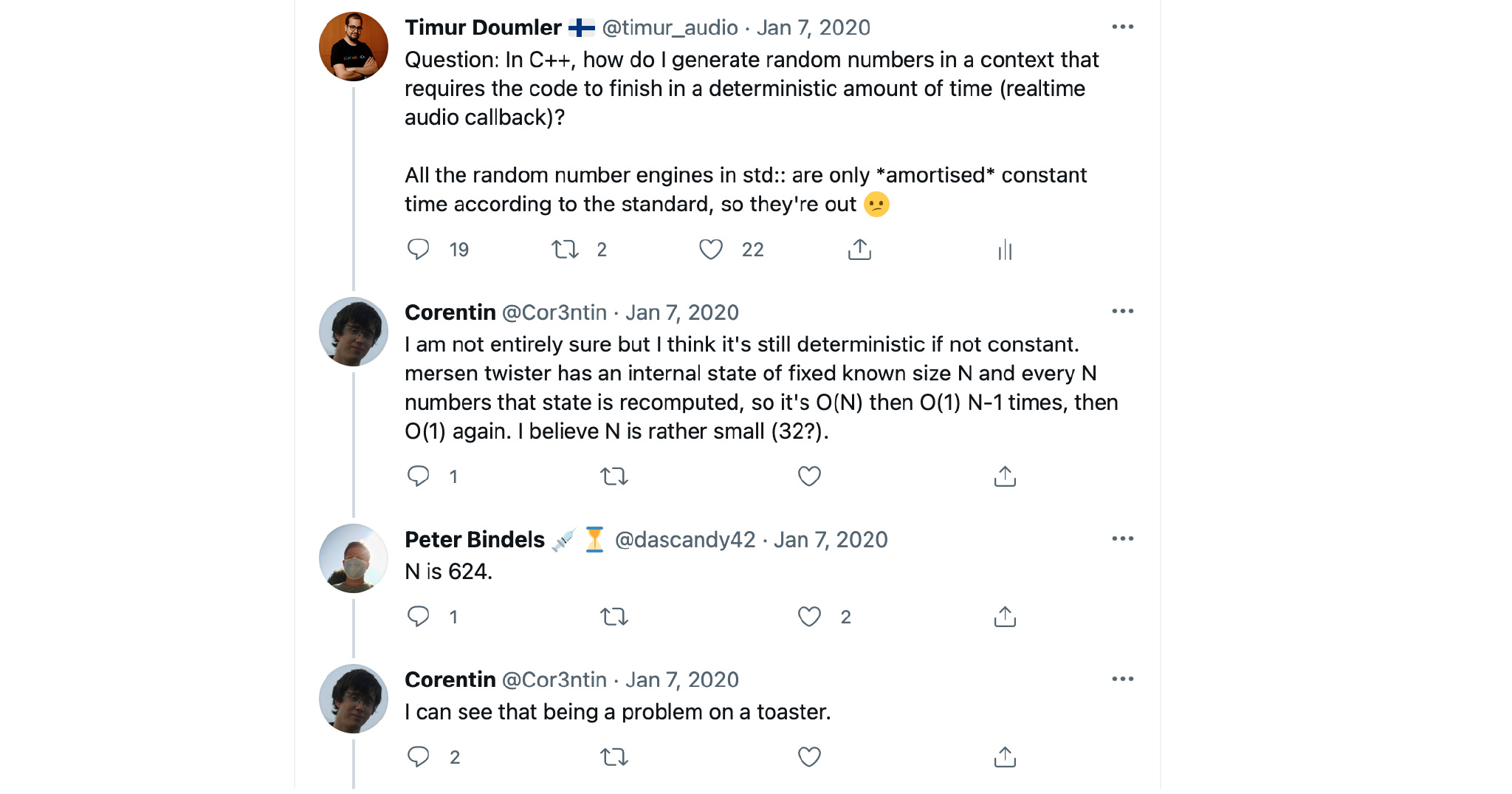
Я задал вопрос: что делать? Оказалось, что, действительно, если вызывать mersenne_twister, обычно он вам просто сгенерирует новое число. Но иногда он может решить: давайте пересчитаем всё наше внутреннее состояние. Это нам в real-time совсем не надо.

В плюсах есть ещё два генератора случайных чисел. Один из них — linear_congruential_engine. Здесь всё вроде бы лучше. В стандарте написано, что именно он делает. Мне кажется, это вполне можно имплементировать с константной сложностью. Наверное, нормальная имплементация этого генератора будет иметь константную, а не амортизированную константную сложность. Но стандарт не даёт такой гарантии. Он не уточняет сложность каждого генератора, а просто говорит, что у них у всех амортизированная константная сложность. Но стандарт говорит, что этот генератор делает, и там вроде бы всё нормально.
Я этим генератором пользовался в аудиокоде, и проблем на практике не возникло. Конечно, он не самый эффективный для нашего юз-кейса.
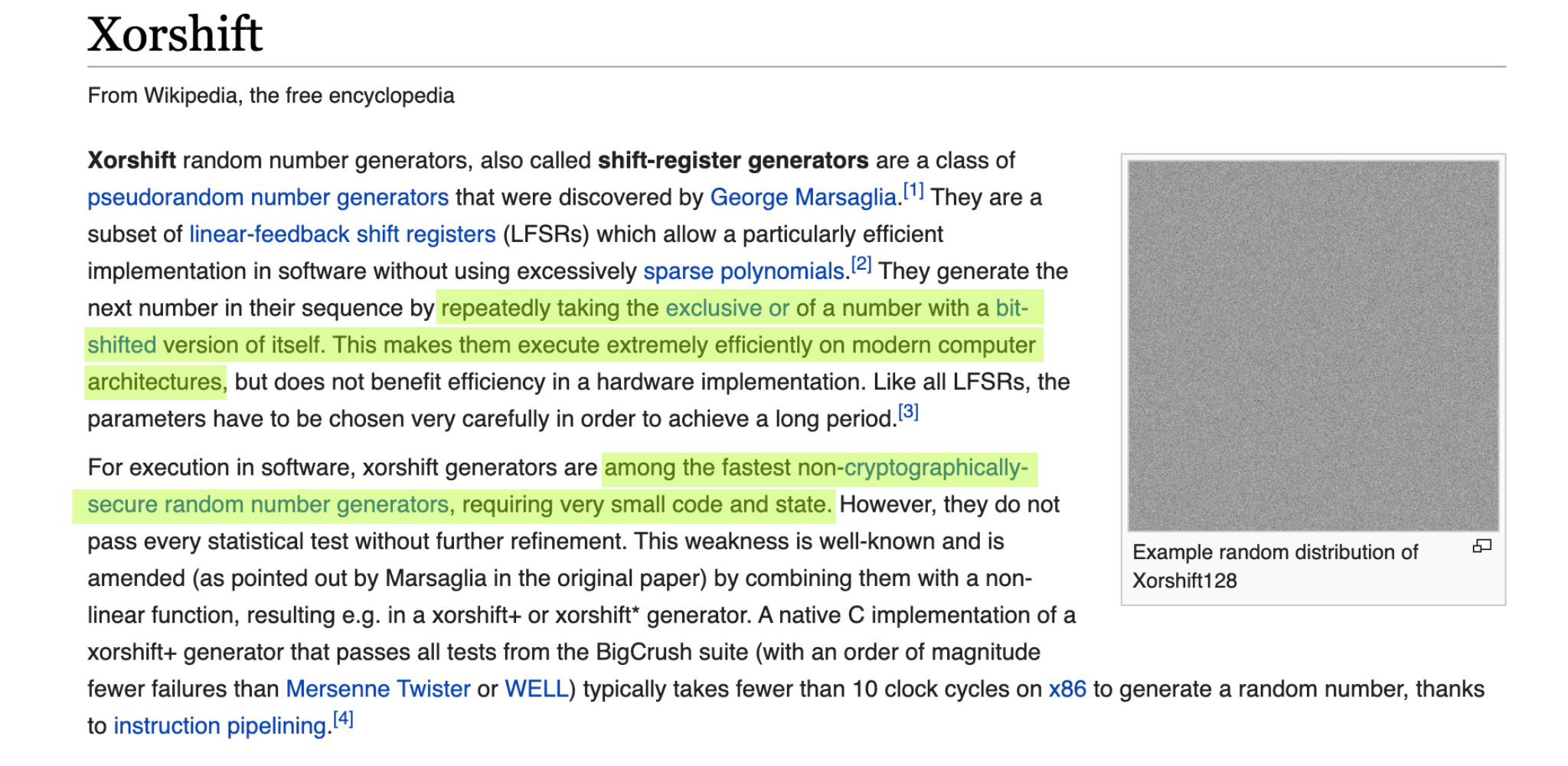
Самый эффективный, лучший генератор, который я нашел для обработки сигналов в real-time, — это Xorshift. Его в стандарте нет. У него нет свойства cryptographically secure, но нас оно не интересует. Он крайне быстрый, крайне эффективный и real-time safe. Рекомендую пользоваться именно им.
Предположим, у нас есть имплементация, их можно найти несколько, и она соответствует стандартному интерфейсу.
struct random_sample_gen
{
// returns a random float in the interval [0, 1)
float operator()() { return distr(rng);
}
private:
xorshift_rand rng { std::random_device{}() };
std::uniform_real_distribution<float> distr { 0, 1.0f };
};
void process(buffer& b)
{
std::ranges::fill(b, random_sample_gen{});
}Значит, теперь у нас есть наша xorshift_rand_engine. Как мы теперь будем генерировать случайные числа между нулём и единицей прямо по правилам современного C++? Получится такой код. Оказывается, если мы хотим в современных плюсах сгенерировать случайные числа с таким равномерным распределением между нулём и единицей, то для этого есть специальный кластер в стандарте.

Конкретно для float есть uniform_real_distribution. Тогда нам нужно обернуть наш генератор случайных чисел в такой объект, который нам даёт желаемое равномерное распределение.
Но, конечно, опять возникает вопрос: какова сложность этой операции? Является ли она real-time safe? Такой вопрос нас ждёт прямо на каждом шагу, если мы в нашем real-time-коде хотим пользоваться стандартной библиотекой.

Если мы посмотрим в стандарт, то увидим: для этих равномерных распределений написано следующее. Оказывается, в плюсах они имеют сразу два неудачных свойства.
Первое свойство: их алгоритм не определён. Это, мне кажется, не очень удачно: получается, если вы берёте просто голый плюсовый генератор случайных чисел, он вам даст одинаковую последовательность на каждой платформе.
Но если вы обернёте этот генератор в стандартное распределение и запустите это на Clang, GCC и Microsoft Visual C++, вы получите три разные последовательности. Писать тесты, опять-таки, будет сложнее.
Второй момент: стандарт вообще ничего не говорит о таких сложностях. Нам нужно самим разобраться, что эти распределения делают в стандарте.

Оказывается, эти uniform_*_distribution в стандарте имеют амортизированную сложность, потому что если берут случайное число, то могут от него отказаться и запросить новое. Сколько раз они это будут делать, теорией не ограничено.
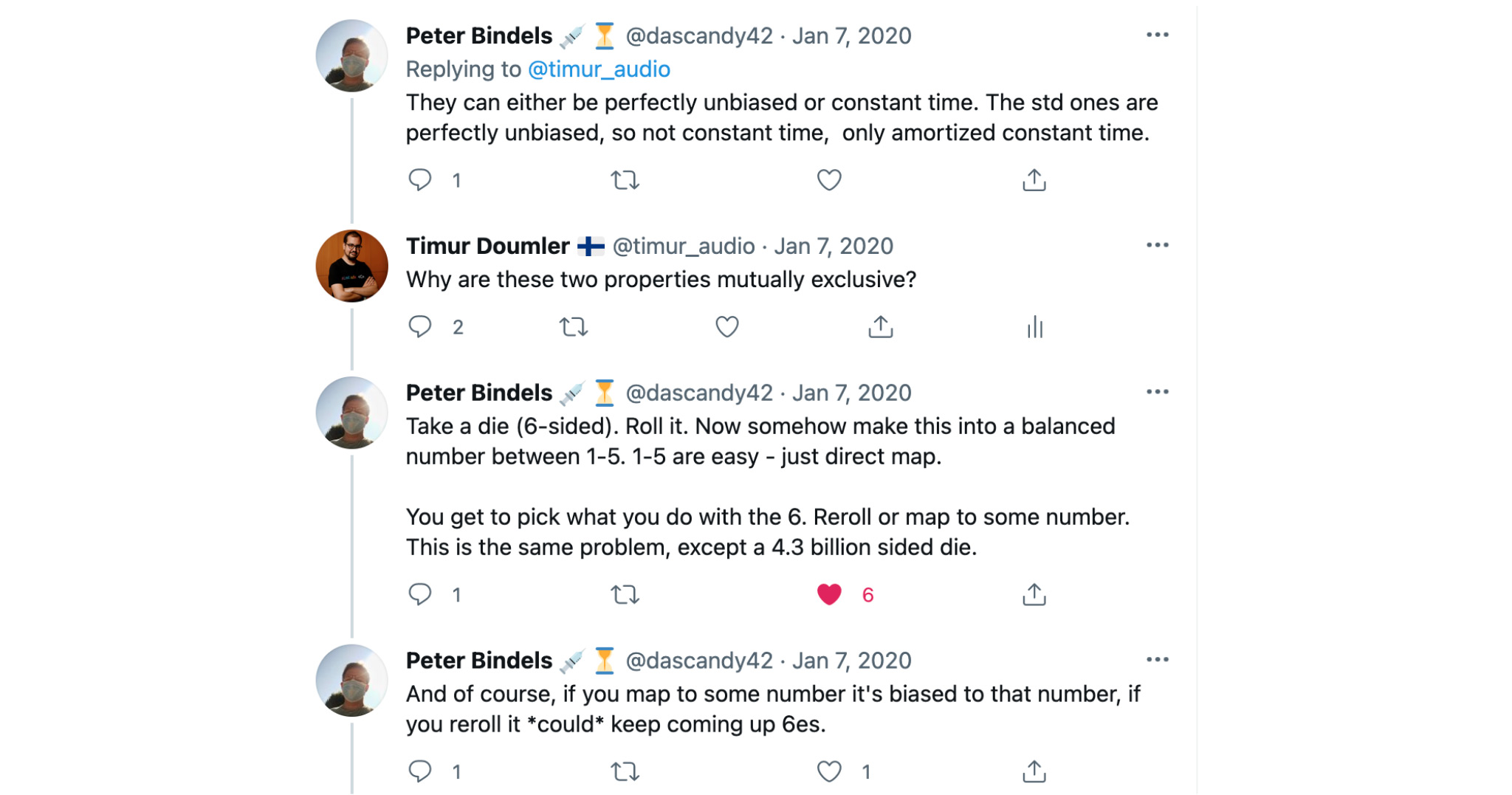
Опять я полез в Твиттер, чтобы пытаться понять, в чем же дело. И Питер Бинделс (Peter Bindels) мне всё объяснил. Оказалось, что, действительно, равномерное распределение можно либо имплементировать так, чтобы полностью отсутствовал bias, а значит, у каждого возможного числа будет абсолютно одинаковая вероятность, либо получить константную сложность. Но иметь и то и другое, к сожалению, невозможно. А в стандарте написано, что у этих распределений отсутствует bias — значит, сложность у них не константная.
Наверное, на практике проблем не будет, но в теории они могут вызывать генератор неограниченное количество раз. Наверное, на практике это произойдёт, только если генератор случайных чисел у вас какой-то такой:
dilbert.com/strip/2001-10-25
Или, например, такой:

xkcd.com/221
Тогда у вас будет кейс, при котором ваше распределение в худшем случае будет просто идти бесконечно и никогда не вернётся.
Ещё раз: на практике это, наверное, не проблема. Но чтобы перестраховаться, быть уверенным в сложности моего кода, я решил не пользоваться этими стандартными распределениями, а написать код вот так, быстро и грязно.
struct random_sample_gen
{
// returns a random float in the interval [0, 1)
float operator()()
{
auto x = float (rng() - rng.min()) / float (rng.max() + 1);
if (x == 1.0f) x -= std::numeric_limits<float>::epsilon();
return x;
}
private:
xorshift_rand rng { std::random_device{}() };
};
void process(buffer& b)
{
std::ranges::fill(b, random_sample_gen{});
}В таком распределении, конечно, нет полного отсутствия bias. Чисто математически распределение не стопроцентно равномерное. Но на практике для моих юз-кейсов этого вполне достаточно. Все тесты проходят. Сложность константная. Такой вызов занимает абсолютно одинаковое время каждый раз, если даёт результат в этом полуоткрытом интервале.
Если нужно распределение чисел с плавающей точкой, как здесь, то обычно у нас будет деление. Если нужно распределение целых чисел, то обычно где-нибудь будет оператор modulus. Но главное, что всё это — real-time safe.
Слайды закончились, мы дошли до конца. Я надеюсь, что вы составили впечатление о том, как пользоваться стандартной библиотекой для обработки сигналов в real-time, за чем нужно следить и как читать стандарт.

Хочу поблагодарить многих людей, которые помогли мне всё это понять. С этими pmr-аллокаторами и равномерными распределениями мне особенно помогли Фэбиен Ренн-Джайлс (Fabian Renn-Giles) и Питер Бинделс (Peter Bindels).
