
Про асинхронность JavaScript написано много статей, документации и книг. Но вся информация сильно распределена по интернету, поэтому сложно быстро и полностью разобраться, что к чему, и составить цельную картину в голове. Не хватает одного исчерпывающего гайда. Именно эту потребность я и хочу закрыть своей статьёй.
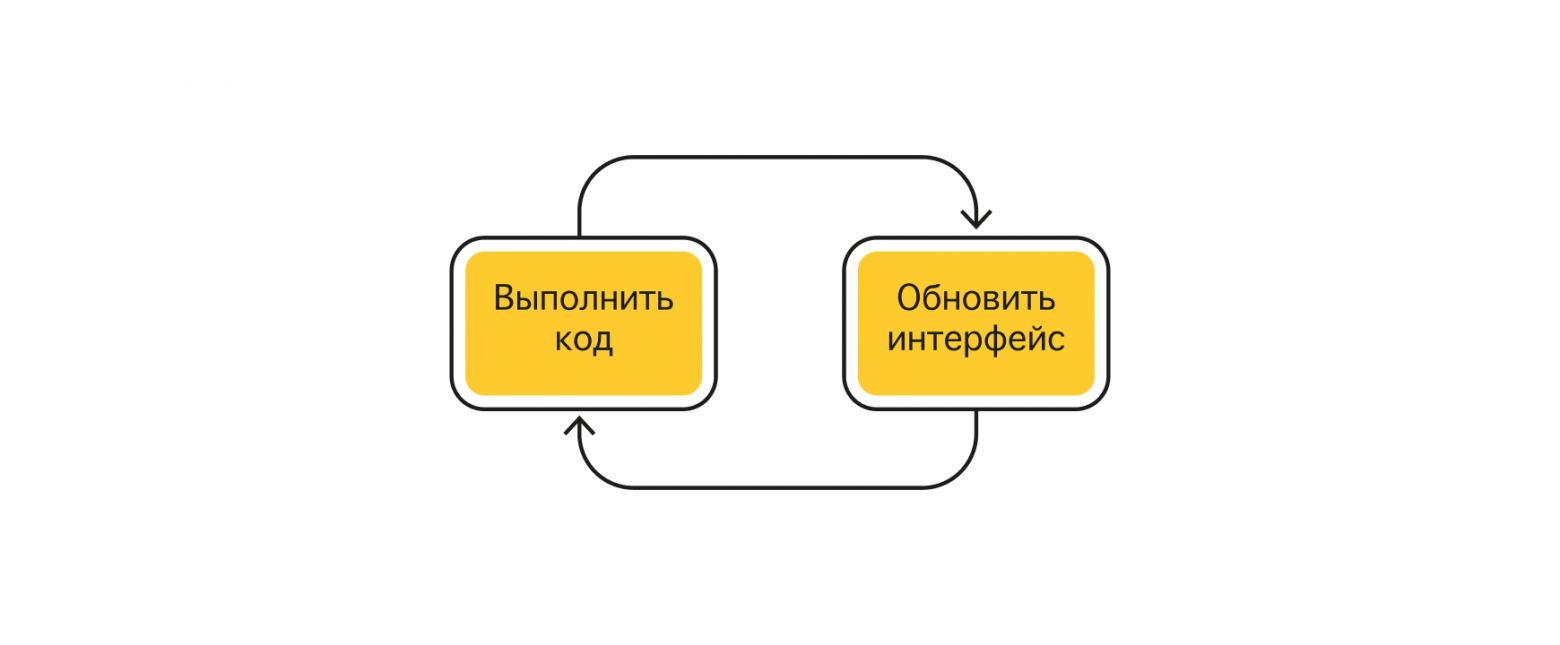
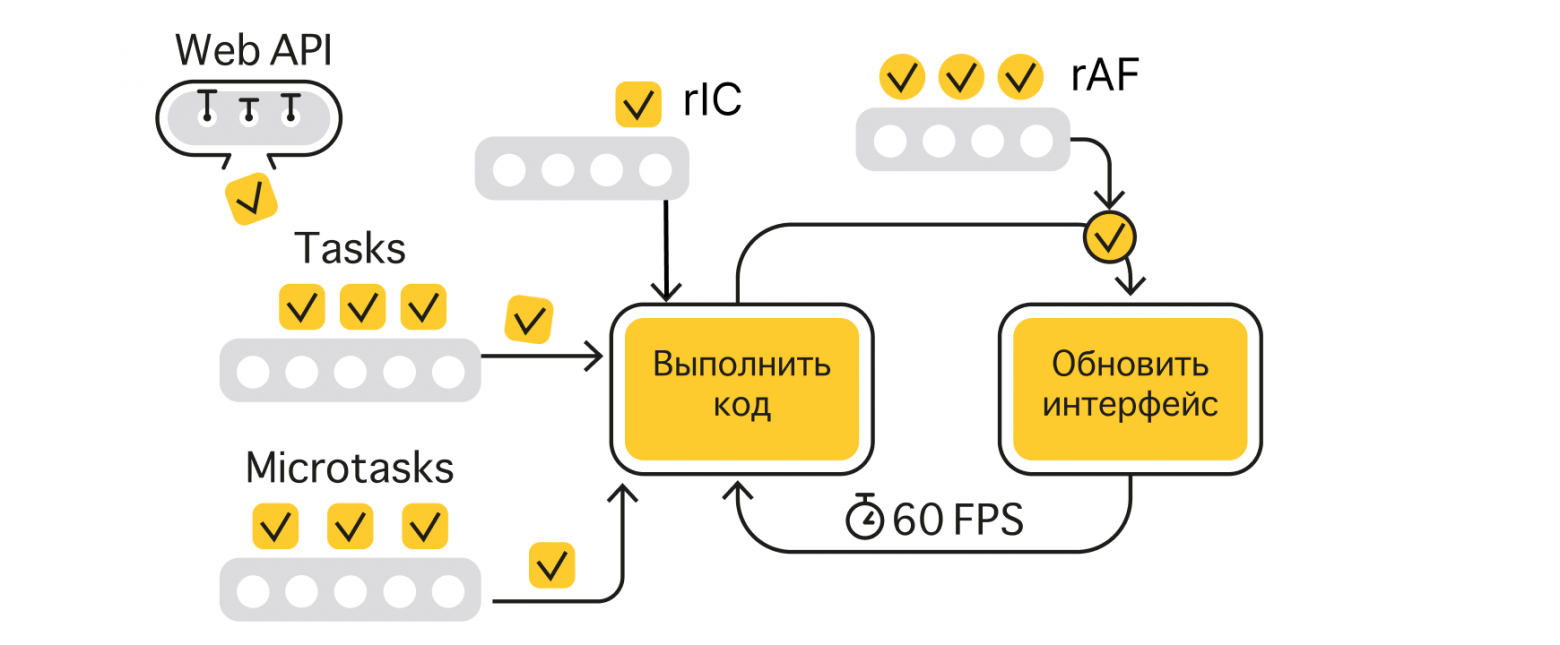
Для работы сайта браузер выделяет один-единственный поток, который должен успевать одновременно делать две важные задачи: выполнять код и обновлять интерфейс. Но один поток в один момент времени может совершать только одно действие. Поэтому поток выполняет эти задачи по очереди, чтобы создать иллюзию параллельного выполнения. Это и есть цикл событий (event loop).
Цикл событий — выполнение кода и обновление интерфейса
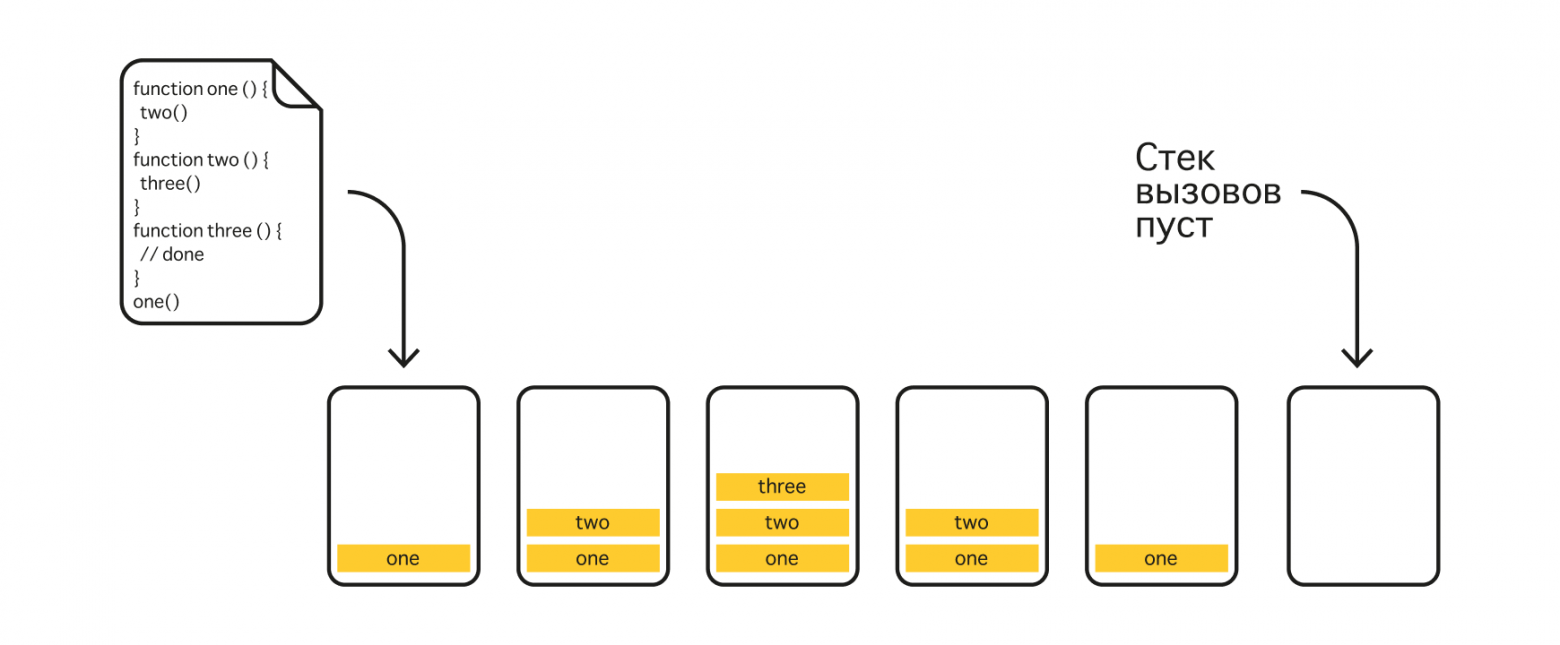
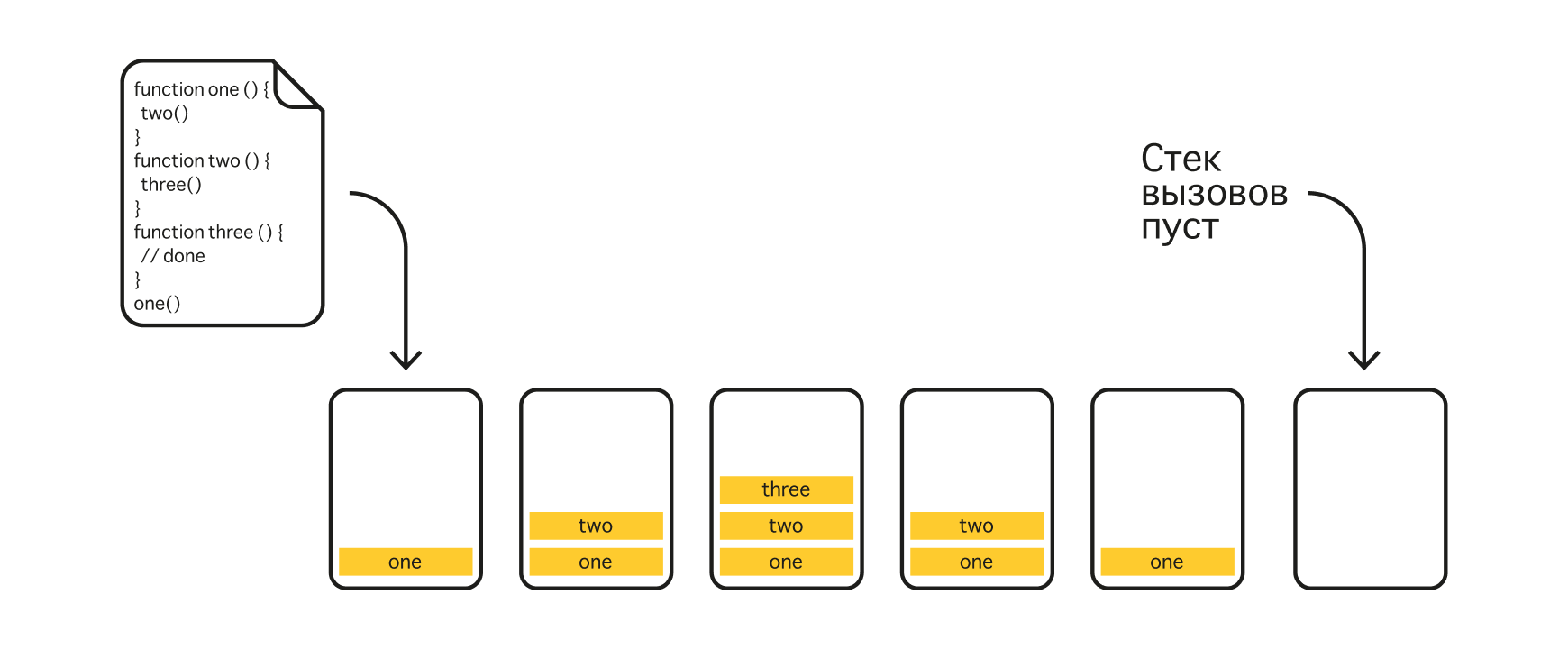
Выполнение кода происходит в стеке вызовов. Если функция внутри себя вызывает другую функцию, то вызов её самой приостанавливается до тех пор, пока выполняется другая функция, — таким образом получается эдакий стек вызовов. Как только все операции будут выполнены и стек опустеет, цикл событий может поместить в стек ещё какой-нибудь код для выполнения или обновить интерфейс пользователя.
Стек вызовов
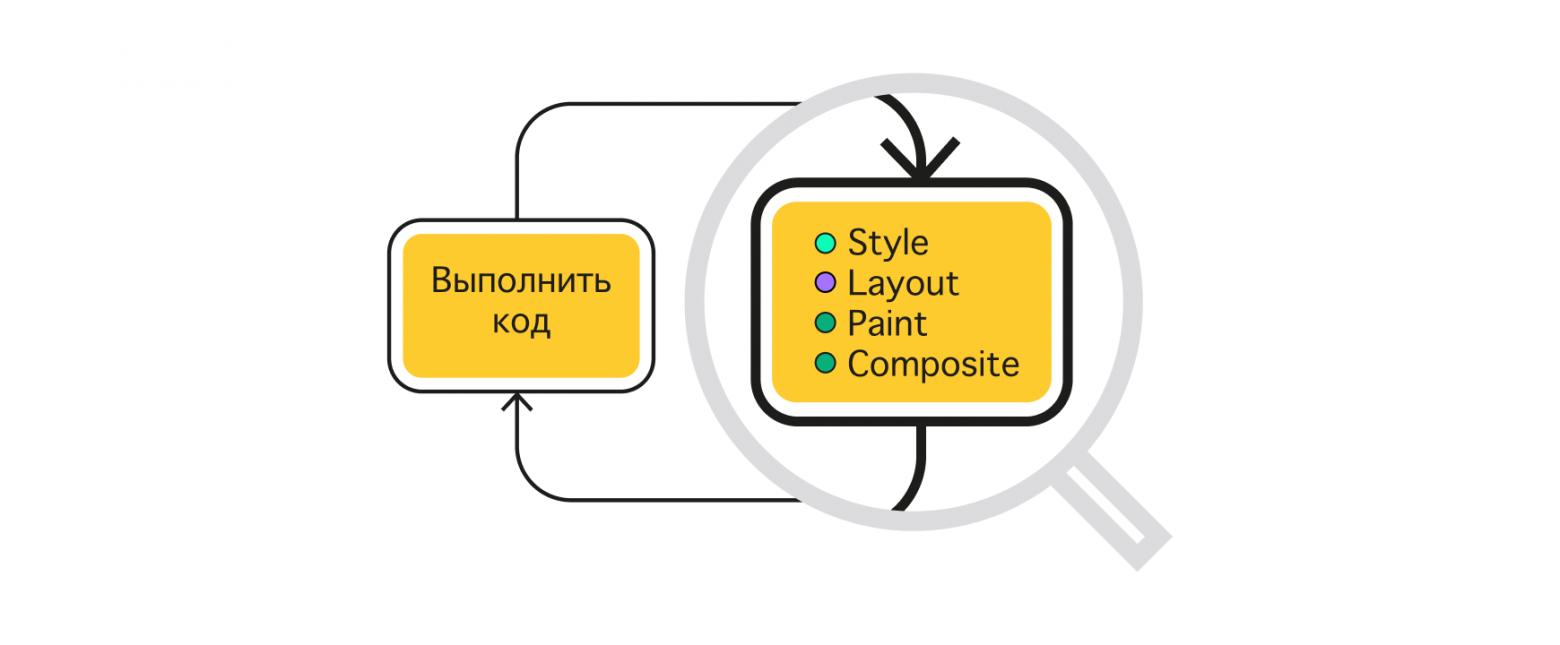
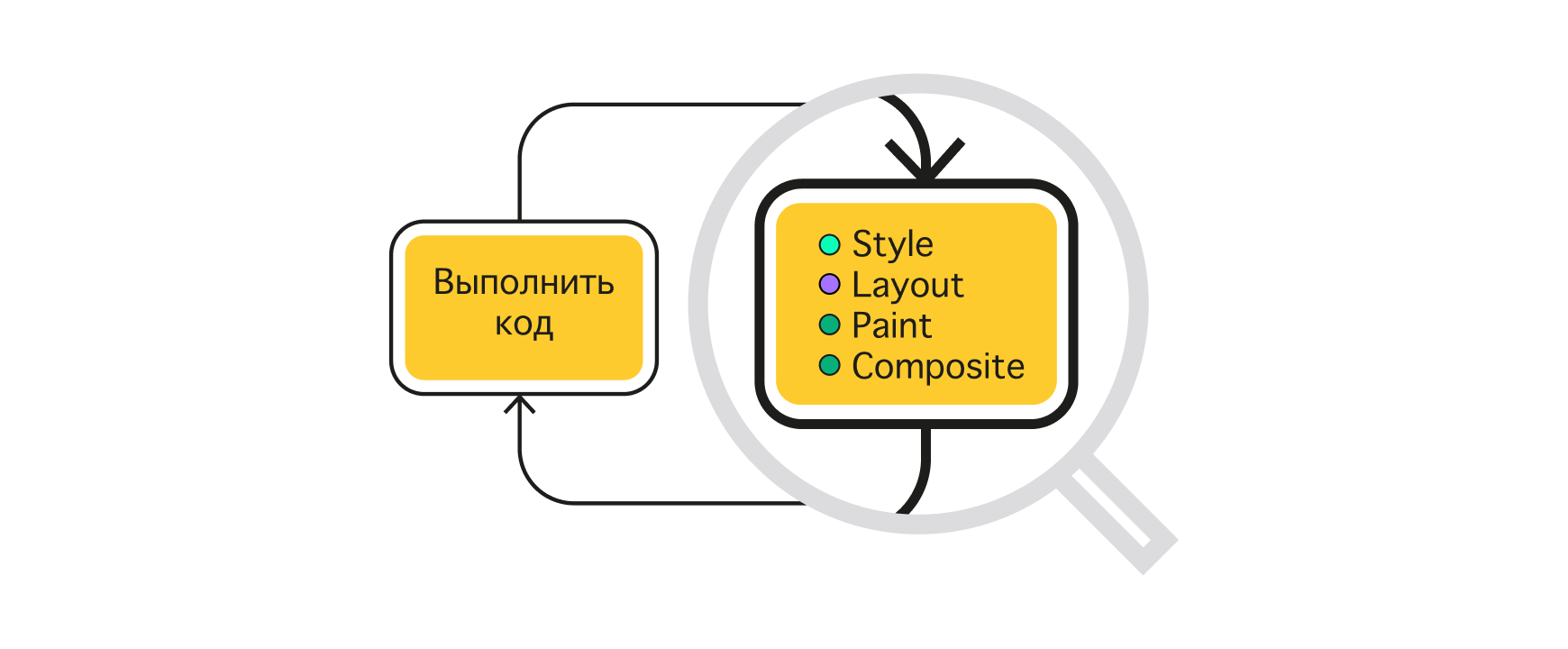
Обновление интерфейса пользователя выполняет движок браузера. Этот этап, как правило, состоит из четырёх шагов: style, layout (reflow), paint, composite. На этапе style браузер пересчитывает изменение стилей, вызванное операциями JavaScript, и рассчитывает медиа-выражения. Layout выполняет перерасчёт геометрии страницы, где происходит вычисление слоёв, расчёт взаимного расположения элементов и их влияния друг на друга. Во время шага paint движок отрисовывает элементы и применяет к ним стили, которые влияют только на внешний вид, например, на цвет, фон и т. п. Composite применяет оставшиеся специфические стили. Как правило, это трансформации, которые происходят в отдельном слое.
Браузер может пропускать некоторые операции, если они не нужны. Понимать, когда браузер выполняет или пропускает тот или иной шаг, может быть полезным для оптимизации веб-страницы. Более подробно о каждом этапе и его связи с производительностью можно прочитать во второй части хабрастатьи «Оптимизация производительности фронтенда».
Обновление интерфейса: style, layout (reflow), paint, composite
Первой операцией в цикле событий может быть как обновление интерфейса, так и выполнение кода. Если сайт использует синхронный тег script, то с большой вероятностью движок выполнит его перед тем, как отрисовать первый кадр интерфейса пользователя. Если же мы грузим скрипты асинхронно через async или defer, то велика вероятность, что до загрузки JavaScript браузер успеет отрисовать интерфейс пользователя.
Вариант с асинхронной загрузкой скриптов более предпочтительный, потому что начальный бандл, как правило, достаточно объёмный. Пока он полностью не выполнится, пользователь будет видеть белый экран, потому что цикл событий не сможет отрисовать интерфейс пользователя. При этом даже при асинхронной загрузке рекомендуется разбивать JavaScript-код на отдельные бандлы и сначала грузить только самое необходимое, потому что цикл событий очень последовательный: он полностью выполняет весь код в стеке вызовов и только потом переходит к обновлению интерфейса. Если в стеке вызовов будет слишком много кода, интерфейс будет обновляться с большой задержкой. У пользователя создастся впечатление, что сайт лагает. Если написать бесконечный цикл, то браузер так и будет выполнять код снова и снова, а обновление интерфейса не наступит никогда, поэтому страница просто зависнет и перестанет реагировать на действия пользователя.
Внутри стека вызовов будет выполняться как код, написанный разработчиком, так и код, встроенный по умолчанию и отвечающий за взаимодействие со страницей. Благодаря встроенному коду работают прокрутка, выделение, анимации и другие штуки, для которых, казалось бы, JavaScript не нужен. Стек вызовов будет выполнять встроенные скрипты даже тогда, когда мы запретим в браузере JavaScript. Для примера можно открыть пустую страницу about:blank без JavaScript, выполнить несколько кликов и увидеть, что стек вызовов выполнил код, отвечающий за обработку событий.
У цикла событий всегда есть работа, даже когда сайт написан без JavaScript
Задача — это JavaScript-код, который выполняется в стеке вызовов. Тик — выполнение задачи в стеке вызовов. Web API — свойства и методы в глобальном объекте Window.
Методы Web API работают либо синхронно, либо асинхронно: первые выполнятся в текущем тике, а вторые в одном из следующих тиков.
Хороший пример синхронных вызовов — это работа DOM:
Создание элемента, вставка в DOM и выставление свойств — это синхронные операции, которые выполняются в текущем тике. Поэтому совершенно нет разницы, когда мы выставим текст для кнопки — до вставки в DOM или после неё. Браузер обновит интерфейс только после полного завершения синхронных операций, так что пользователь увидит сразу актуальное состояние интерфейса.
Когда мы пишем асинхронный код, то гарантируем, что задача будет выполняться в следующем тике. При этом он может начаться как до обновления интерфейса, так и после. Например, когда циклу событий требуется выполнить очередную задачу, он может либо выполнить её сразу после предыдущей, либо сначала обновить интерфейс, а только потом выполнить следующую задачу. Для разработчиков это не играет особой роли. Важно просто понимать, что асинхронная задача выполнится когда-то в будущем.
Хороший пример асинхронного вызова — это запрос данных с сервера. Через функцию обратного вызова описывается задача, которая будет выполнена когда-то в будущем после получения данных:
Подсистема браузера, которая отвечает за работу с сетью, выполнит запрос в отдельном потоке, который будет работать независимо. Пока запрос будет выполняться фоном, цикл событий может спокойно обновлять интерфейс и выполнять код. После того как данные успешно загрузятся, задание, которое мы описали через функцию обратного вызова, станет готовым для выполнения в одном из следующих тиков нашего основного цикла заданий.
Задач, готовых к выполнению после асинхронных вызовов, может быть несколько. Поэтому для передачи их в стек вызовов на выполнение существует специальная очередь.
Задачи попадают в очередь через асинхронный браузерный API. Сперва где-то в отдельном потоке выполняется асинхронная операция, а после её завершения в очередь добавляется задача, готовая к выполнению в стеке вызовов.

Очередь задач
Понимая эту концепцию, можно разобрать одну особенность таймеров в JavaScript, которые тоже являются асинхронным API.
Когда мы запускаем таймер, движок начинает вести обратный отсчёт в отдельном потоке и по готовности задача добавляется в очередь. Можно было бы подумать, что таймер выполнится через одну секунду, но на самом деле это не так. В лучшем случае через одну секунду он добавится в очередь заданий, а код будет выполнен только после того, как до него дойдёт очередь.
Точно такая же история с обработчиками событий. Каждый раз, когда мы регистрируем обработчик событий, мы привязываем к нему задачу, которая будет добавлена в очередь после наступления события:
Чтобы сайты были быстрыми и «отзывчивыми», браузеру надо создать иллюзию, что он одновременно выполняет код пользователя и обновляет интерфейс. Но поскольку цикл событий работает строго последовательно, браузеру приходится быстро переключаться между задачами, чтобы пользователь ни о чём не догадался.
Как правило, мониторы обновляют картинку с частотой 60 кадров в секунду (значение сильно зависит от дисплея и может быть как 144 Гц, так и 30 Гц в режиме энергосбережения), поэтому цикл событий старается с такой же скоростью выполнять код и обновлять интерфейс. Для примера, если обновление происходит с частотой 60 Гц, то на выполнение задачи остаётся 16,6 миллисекунды. Если наш код будет выполняться быстрее, то браузер будет просто часто обновлять дисплей. Но если код будет выполняться медленно, то частота кадров начнёт снижаться, и у пользователя появится ощущение, что сайт лагает.
Для большинства сценариев 16,6 миллисекунды вполне достаточно. Но иногда на клиентской стороне требуется выполнять тяжёлые вычисления, которые могут потребовать гораздо больше времени. Для этого есть специальные методики.
Оптимизировать большие задачи можно двумя путями: либо через разбиение их на подзадачи и выполнение последних в разных тиках, либо через вынесение вычисления в отдельный поток.
Выполнить что-то в следующем тике можно, например, через setTimeout с минимальной задержкой.
Кроме того есть экспериментальная функция postTask, которая является частью Scheduling API и в данный момент доступна только в Chrome. Через неё можно не только выполнять задачи асинхронно для разгрузки основного потока, но и устанавливать для них приоритет. Более подробно об этом можно почитать в статье Джереми Вагнера «Optimize long tasks».
Для запуска отдельного потока подойдёт Web Worker API:
Для веб-воркера создаётся отдельный поток, где будут происходить вычисления независимо от основного цикла событий. Как только вычисления закончатся, воркер через postMessage сможет отправить данные в основной цикл событий и задача, связанная с их обработкой, будет добавлена в очередь и выполнена в одном из следующих тиков. Но у веб-воркера есть ограничения. Например, внутри нельзя работать с DOM, однако вычислительные задачи будут работать.
Если данные вычислений нужны внутри других вкладок в рамках одного источника (same origin), то вместо обычного воркера можно использовать SharedWorker. Кроме того, для некоторых задач может быть полезен ServiceWorker, но это уже другая история. Подробнее про воркеры можно прочитать, например, вот тут.
Кроме веб-воркеров есть другой, менее очевидный способ создать отдельный поток — открыть окно или фрейм на другом домене, чтобы нарушить политику same origin. Тогда у окна или фрейма будет свой собственный независимый цикл событий, который сможет выполнять какую-то работу и взаимодействовать с основным окном так же, как и веб-воркер через механизм postMessage. Это достаточно специфическое поведение, которое может по-разному выглядеть в разных браузерах, его можно проверить, например, через демку со Stack Overflow.
Микрозадачи — это те задачи, которые хранятся в специальной отдельной очереди.

Очередь микрозадач
Задачи попадают в эту очередь при использовании обещаний, асинхронных функций, встроенном вызове queueMicrotask или для Observer API.
Очередь микрозадач более приоритетная, задачи из неё выполняются раньше обычных. Кроме того, у неё есть важная особенность — цикл событий будет выполнять микрозадачи до тех пор, пока очередь не опустеет. Благодаря этому, движок гарантирует, что все задачи из очереди имеют доступ к одинаковому состоянию DOM.
Это поведение можно наглядно увидеть на примере с обещаниями, где каждый последующий обработчик получает доступ к одному и тому же состоянию DOM (на момент установки обещания):
Есть замечательный наглядный сайт JavaScript Visualizer 9000, где можно более подробно изучить, как работают очереди задач и микрозадач. Ещё советую хорошую хабрастатью, где разбираются обещания.
requestAnimationFrame (или сокращённо rAF) позволяет выполнить JavaScript-код прямо перед обновлением интерфейса. Каким-то другим способом, например через таймеры, эмулировать такое поведение практически невозможно.
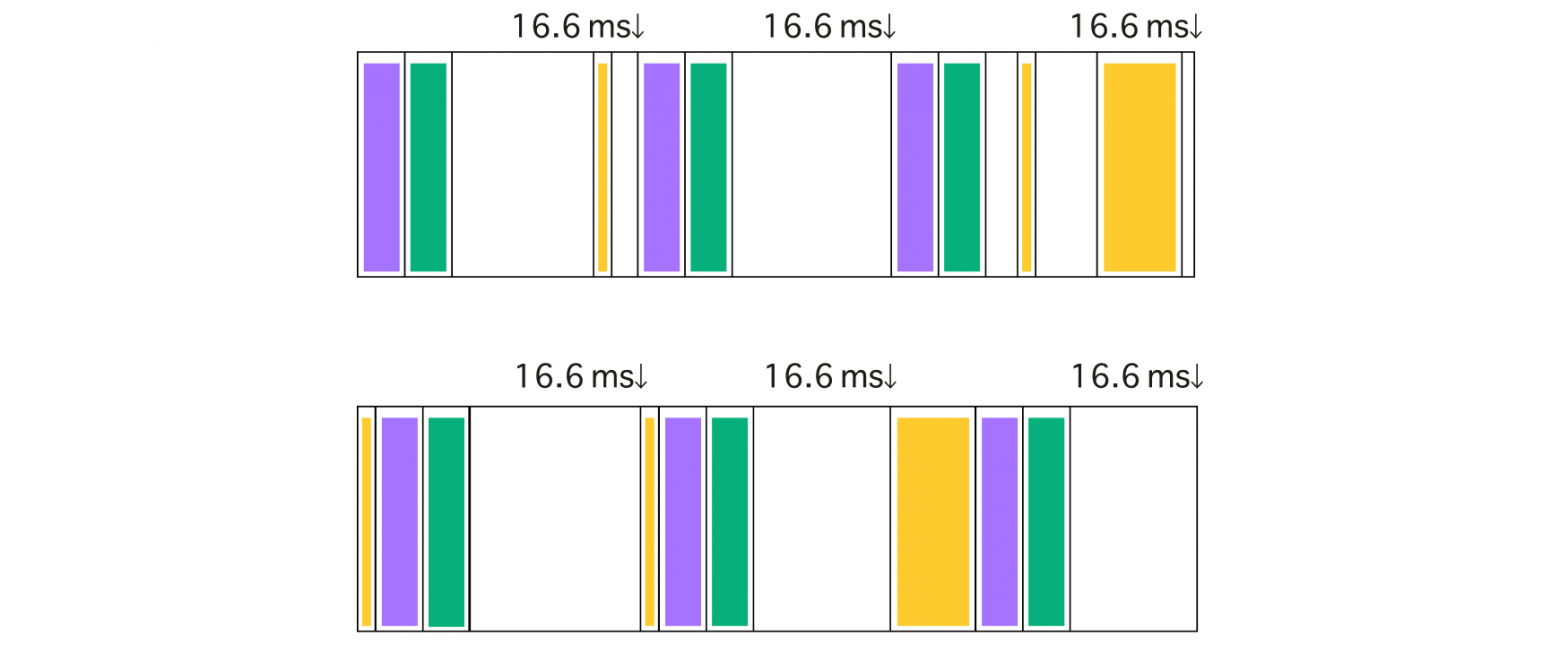
Вверху без rAF, внизу через rAF
Основная задача requestAnimationFrame — это плавное выполнение JavaScript-анимаций, но используют его нечасто, так как анимации проще и эффективнее задать средствами CSS. Тем не менее он занимает своё полноценное место в цикле событий.
Задач, которые нужно выполнить перед обновлением следующего кадра, может быть несколько, поэтому у requestAnimationFrame есть своя отдельная очередь.

requestAnimationFrame
Задачи из очереди выполняются один раз перед обновлением интерфейса в порядке их добавления:
Написать повторяющуюся задачу, которая будет выполняться снова и снова, можно через рекурсивную функцию. Причём, если по какой-то причине потребуется отменить выполнение, это можно сделать через cancelAnimationFrame. Но надо убедиться, что в него передаётся актуальный идентификатор, потому что каждый вызов rAF создаёт новый requestId.
Небольшая, но дельная статья по теме requestAnimationFrame есть в блоге Флавио Коупса.
requestIdleCallback (или сокращённо rIC) добавляет задачи в ещё одну (четвёртую) очередь, которая будет выполняться в период простоя браузера, когда нет более приоритетных задач из других очередей.
В качестве второго аргумента можно указать timeout и, если задача не будет выполнена в течение указанного числа миллисекунд, то она добавится в обычную очередь, после чего выполнится в порядке общей очереди.
По аналогии с requestAnimationFrame, чтобы регулярно добавлять задачу в очередь, потребуется написать рекурсивную функцию, а для остановки — передать актуальный идентификатор в cancelIdleCallback.
requestIdleCallback
В отличие от других очередей, рассмотренных ранее, requestIdleCallback — это всё ещё отчасти экспериментальное API, поддержка которого отсутствует в Safari. Кроме того, эта функция имеет ряд ограничений, из-за которых её удобно использовать только для небольших неприоритетных задач без взаимодействия с DOM, например для отправки аналитических данных. Более подробно о requestIdleCallback можно почитать в материале «Using requestIdleCallback» Пола Льюиса.
Очередь микрозадач — это самая приоритетная очередь, с неё начинается выполнение кода. Работа браузера с этой очередью продолжается до тех пор, пока в ней есть задачи, сколько бы времени это ни заняло.
Из очереди задач движок выполняет, как правило, одно или несколько заданий, стараясь уложиться в 16,6 миллисекунды. Как только пройдёт отведённое время, движок пойдёт обновлять интерфейс, даже если в очереди остались задачи. К ним он вернётся на следующем витке цикла событий.
requestAnimation выполнит все задачи из своей очереди, потому что он гарантирует выполнение кода перед обновлением интерфейса. Но если в ходе выполнения кто-то добавит новые задания в очередь, то они выполнятся уже на следующем витке.
Когда наступит время простоя и в других очередях не будет более приоритетных задач, выполнится одно или несколько заданий requestIdleCallback. Таким образом, эта очередь чем-то похожа на очередь задач, но с более низким приоритетом.
Взаимодействие с очередями происходит через:
В Node.js цикл событий работает схожим образом: сначала выполняется задание, затем нужно заглянуть в очередь за следующим. Но набор очередей отличается, а также отсутствуют этапы, связанные с обновлением интерфейса, потому что код работает на сервере. Подробнее о циклах событий в Node.js можно почитать в серии статей, которые написал Дипал Джаясекара (Deepal Jayasekara). Для быстрого понимания setImmediate и process.nextTick есть хорошее объяснение на Stack Overflow.
Это удобный и простой способ взаимодействовать с асинхронным API, но если быть с ним неаккуратным, возникает много проблем.
Ад обратных вызовов (callback hell) — самая частая проблема, которую вспоминают, когда говорят про недостатки функций обратного вызова.
Последовательность асинхронных вызовов через функции обратного вызова становится похожа на пирамиду судьбы (pyramid of doom).
Можно подумать, что это самый главный недостаток функций обратного вызова, но на этом проблемы с ними только начинаются.
Дело в том, что сходу нельзя определить, как именно будет вызвана функция обратного вызова — синхронно или асинхронно, а ведь от этого может сильно зависеть логика нашего кода. Чтобы разобраться наверняка, придётся прочитать реализацию функции. А это требует дополнительных действий и усложняет отладку.
В узких кругах эта проблема широко известна как проблема монстра Залго, которого лучше не выпускать на свободу.
Жёсткая сцепленность — это проблема зависимости одной части кода от другой при обработке последовательных асинхронных операций:
Если ошибка наступит на этапе №1, надо будет обработать только её. Но если ошибка произойдёт уже на этапе №2, то придётся отменить этап №2, а затем и этап №1 тоже. И чем больше этапов, тем больше проблем при обработке ошибок.
Инверсия управления — это передача нашего кода в библиотеку, которую писали другие разработчики:
Мы полагаемся на то, что наша задача будет вызвана так, как надо, но всё может быть далеко не так. Другая библиотека может вызвать функцию слишком рано или слишком поздно, делать это слишком часто или редко, поглотить ошибки и исключения, передать неправильные аргументы или вовсе не вызвать нашу функцию.
Исходя из сказанного, можно подумать, что работа с асинхронностью через функции обратного вызова — это сплошные сложности. Отчасти так и есть, но, к счастью, со всеми этими проблемами помогают справиться обещания.
Обещания напоминают талончики с номером заказа в кафе. Когда мы делаем заказ, вместо еды мы получаем талончик с номером. Дальше возможны два сценария. Первый: заказ успешно приготовят и через некоторое время выдадут на стойке получения заказов. Второй: что-то может пойти не так, например, закончатся нужные ингредиенты, тогда сотрудник кафе сообщит нам, что не может приготовить наш заказ, и предложит вернуть деньги или заказать что-то другое.
Обещания создаются через конструктор Promise, который обязательно вызывается через new. Конструктор принимает только один аргумент — функцию обратного вызова с двумя параметрами: resolve и reject. Внутри обещания вызывается асинхронная операция с функцией обратного вызова. В свою очередь внутри этой функции вызывается либо resolve, либо reject, которые устанавливают обещание либо на выполнение, либо на отказ соответственно.
Вот так вот можно выставить обещание либо на выполнение, либо на отказ:
После того как обещание установлено, результат можно получить через метод then:
Обработать отказ можно либо через второй параметр в then, либо через catch:
Значение обещания устанавливается один раз, после чего его уже не изменить:
Для удобства можно использовать статические методы — функции-конструкторы Promise.resolve и Promise.reject, которые создают сразу установленное обещание:
У обещаний ещё есть метод finally, который что-то сделает независимо от успеха или неудачи. Это чем-то похоже на приготовление блюда в духовке: неважно, пригорело наше блюдо или нет — духовку всё равно надо будет выключить.
Самая главная польза обещаний в том, что мы можем выстраивать из них цепочки асинхронных операций:
Если где-то произойдёт ошибка, то отказ пропустит обработчики на выполнение и долетит до ближайшего обработчика отказа, после чего цепочка продолжит работать в штатном режиме:
Возвращать значение можно и внутри catch, оно будет точно так же обработано в цепочке:
Если цепочка завершится, а ошибка останется необработанной, то сработает событие Unhandeled Promise Rejection, на которое можно подписаться, чтобы отслеживать необработанные ошибки внутри обещаний:
Важно понимать, что обработка ошибок работает только тогда, когда цепочка непрерывна. Если опустить return и создать обещание, установленное на отказ, то последующий catch не сможет его обработать:
У обещаний есть две неявные особенности. Во-первых, методы then и catch всегда возвращают новое обещание. Во-вторых, внутри себя они перехватывают любые ошибки и, если что-то пошло не так, возвращают обещание, установленное на отказ, с причиной ошибки.
Возвращение нового обещания
Каждый вызов then или catch создаёт новое обещание, значение которого либо undefined, либо явно выставляется через return.
Благодаря этому, вместо создания временных переменных можно сразу сделать удобную цепочку вызовов:
При этом, если вернуть обещание, его значение распакуется и всё будет работать точно так же.
За счёт этого можно избегать вложенных обещаний и всегда писать код с одним уровнем вложенности:
Спрятанный try/catch
Другая особенность обещаний связана с обработкой ошибок. Функции обратных вызовов, которые передаются в методы обещаний, оборачиваются в try/catch. Если что-то пойдёт не так, то try/catch перехватит ошибку и установит её в качестве причины отказа обещания:
Это всё равно что самостоятельно написать вот такой код:
Таким образом, внутри обещаний можно обойтись без try/catch, потому что обещания сделают это за нас. Главное — потом правильно обработать причину отказа в catch.
Это объекты, в которых есть
Скорее всего, это полифилы обещаний до ES6. Обещания распакуют такие объекты, а затем завернут их в полноценные ES6-обещания. По такому принципу работают resolve, Promise.resolve, then и catch.
Благодаря этому обеспечивается совместимость с кодом, написанным до ES6:
Есть одна особенность: если в Promise.resolve передать обычное обещание, то оно не распакуется и вернётся без изменений. При этом resolve, then, catch распакуют значение и создадут новое обещание.
Но самое интересное — это поведение reject и Promise.reject, которые работают совершенно иначе. Если туда передать любой объект, в том числе и обещание, они просто вернут его как причину отказа:
У обещаний есть шесть полезных статических методов. Два из них мы уже разобрали — это Promise.resolve и Promise.reject. Давайте посмотрим на другие четыре.
Для наглядности напишем функцию, которая поможет получать установленное обещание через какое-то время:
Все четыре метода, которые мы разберём ниже, принимают массив значений. Но каждый из этих методов работает по своему, и результаты они возвращают разные.
Promise.all
Этот вызов возвращает массив значений или первый отказ:
Если хотя бы одно обещание завершится неудачей, то вместо массива значений в catch прилетит причина отказа:
Для пустого массива сразу вернётся пустой результат:
Promise.race
Этот метод возвращает первое значение или первый отказ:
Если отказ произойдёт первым, то race установится на отказ:
Если передать в Promise.race пустой массив, то обращение зависнет в состоянии выполнения и не будет установлено ни на выполнение, ни на отказ:
Promise.any
Вызов возвращает первое значение или массив с причинами отказа, если ни одно обещание не завершилось успешно:
Когда все обещания установятся на отказ, то any вернёт объект ошибки, в котором информацию об отказах можно будет достать из поля errors:
Для пустого массива вернётся ошибка:
Promise.allSettled
Метод дождётся выполнения всех обещаний и вернёт массив специальных объектов:
Для пустого массива сразу вернётся пустой результат:
Когда требуется перейти от функций обратного вызова к обещаниям, на помощь приходит промисификация — специальная функция-помощник, которая превращает функцию, работающую с callback, в функцию, которая возвращает обещание:
Работа промисификации зависит от сигнатуры функций в коде, потому что требуется учитывать порядок аргументов, а также параметры callback. В примере выше предполагается, что функция обратного вызова передаётся последним аргументом, а в качестве параметров сначала принимает ошибку, а затем результат.
Обещания устраняют недостатки функций обратного вызова. Они всегда асинхронные и одноразовые, код линейный и не обладает жёсткой сцепленностью, можно не переживать за ад обратных вызовов.
Но как быть, если обещание всё-таки зависло и не устанавливается ни на выполнение, ни на отказ? В этом случае можно использовать Promise.race, чтобы прервать выполнение зависшего или очень длинного запроса по таймауту:
В любом случае важно понимать: несмотря на многие преимущества обещаний, всё равно кое-где придётся использовать функции обратного вызова, и это нормально. Через них работают обработчики событий и многие асинхронные методы API, например setTimeout, поэтому в таких случаях нет смысла промисифицировать и удобнее использовать функции обратного вызова. В конце концов, они нам также понадобятся, чтобы создать обещание. Главное запомнить, что, если где-то есть цепочка последовательных вызовов, там обязательно надо использовать обещания.
Обещания — это фундамент для работы с асинхронностью, но над этим фундаментом есть очень удобная надстройка async/await, которая реализуется благодаря корутинам.
Корутина (coroutine, cooperative concurrently executed routine) — это сопрограмма или, проще говоря, особая функция, которая может приостанавливать свою работу и запоминать состояние, а также имеет несколько точек входа и выхода.
В JavaScript в качестве корутин выступают функции-генераторы, которые возвращают итератор. Итератор может приостанавливать свою работу, запоминать текущее состояние и взаимодействовать с внешним кодом через .next и .throw.
Благодаря таким возможностям корутин, можно написать специальную функцию следующего вида:
И затем через неё последовательно вызывать асинхронные операции:
Это оказалось настолько удобно, что позже в JavaScript добавили конструкции async/await.
Это синтаксический сахар, реализованный через обещания и корутины, который делает работу с асинхронными операциями более удобной.
Модификатор async ставится перед функцией и делает её асинхронной:
Результат асинхронной функции — это всегда обещание. Для удобства можно представлять асинхронную функцию как обычную, которая заворачивает свой результат в обещание:
Результат асинхронной функции извлекается через then или через await:
Await немного удобнее обещаний, но у него есть серьёзное ограничение — его можно вызывать только внутри асинхронной функции. При этом асинхронность становится «прилипчивой» — стоит один раз написать асинхронный вызов, и дороги назад, в синхронный мир, уже нет. Какое-то время с этим ничего нельзя было сделать, но потом появился верхнеуровневый await.
Верхнеуровневый await (top level await) позволяет использовать этот оператор за пределами асинхронных функций:
Но его можно использовать только либо внутри ES6-модулей, либо в DevTools. Такое ограничение связано с тем, что await — это синтаксический сахар, который работает через модули.
Например, модуль с верхнеуровневым await для разработчика выглядит так:
Ни внутри модуля, ни внутри основной программы нет асинхронных функций, но при этом они необходимы для работы await. Как же тогда работает этот код?
Дело в том, что движок сам возьмёт на себя задачу обернуть await в асинхронную функцию, поэтому где-то «под капотом», без синтаксического сахара, верхнеуровневый await будет выглядеть примерно так:
Никакой магии. Просто синтаксический сахар.
Есть два способа обработать ошибку внутри асинхронных функций. Первый — поставить catch после вызова функции, второй — обернуть вызов await в конструкцию try/catch.
Поскольку асинхронные функции — это обещания, после вызова можно поставить catch и обработать ошибку.
Такой способ будет работать, но, скорее всего, try/catch подойдёт лучше, потому что даст возможность обработать исключение сразу в теле функции:
Другое важное преимущество: в отличие от catch, конструкция try/catch сможет обработать верхнеуровневый await.
Оператор await приостанавливает выполнение задачи до завершения асинхронной операции. Если перед каждой асинхронной операцией бездумно ставить await, это может привести к неоптимальной работе кода из-за последовательной загрузки несвязанных данных.
Например, список статей и картинок, которые никак друг с другом не связаны, через await можно было бы загрузить вот так:
Тогда данные, которые можно было бы получить параллельно, будут запрашиваться последовательно. До тех пор пока первая часть данных не загрузится полностью, работа со второй частью не начнётся. Из-за этого задача будет выполняться дольше, чем могла бы. Допустим, каждый запрос выполняется за две секунды, тогда на полную загрузку данных уйдёт четыре секунды. Но если данные грузить параллельно, через Promise.all, то вся информация загрузится в два раза быстрее:
Вот и всё, что вы, вероятно, хотели знать про асинхронность в браузере. Надеюсь, теперь вы хорошо понимаете, как действует цикл событий, сможете выбраться из ада обратных вызовов, легко работаете с обещаниями и грамотно используете async/await. Если я что-то забыл, напоминайте в комментариях.
- Цикл событий
Задачи, тики и Web API
Очередь задач
16,6 миллисекунды на задачу
Обработка больших задач
Микрозадачи
requestAnimationFrame
requestIdleCallback
Сравнение очередей
Цикл событий в Node.js - Функции обратного вызова
Ад обратных вызовов
Не выпускайте Залго
Жёсткая сцепленность
Проблема доверия - Обещания
Цепочки обещаний и проброс отказа
Неявное поведение
Возвращение нового обещания
Спрятанный try/catch
Thenable-объекты
Статические методы
Promise.all
Promise.race
Promise.any
Promise.allSettled
Промисификация
Обещания или функции обратного вызова?
Корутины - Async/await
Верхнеуровневый await и асинхронные модули
Обработка ошибок
Не все await одинаково полезны - Заключение
Цикл событий
Для работы сайта браузер выделяет один-единственный поток, который должен успевать одновременно делать две важные задачи: выполнять код и обновлять интерфейс. Но один поток в один момент времени может совершать только одно действие. Поэтому поток выполняет эти задачи по очереди, чтобы создать иллюзию параллельного выполнения. Это и есть цикл событий (event loop).

Цикл событий — выполнение кода и обновление интерфейса
Выполнение кода происходит в стеке вызовов. Если функция внутри себя вызывает другую функцию, то вызов её самой приостанавливается до тех пор, пока выполняется другая функция, — таким образом получается эдакий стек вызовов. Как только все операции будут выполнены и стек опустеет, цикл событий может поместить в стек ещё какой-нибудь код для выполнения или обновить интерфейс пользователя.
Стек вызовов
Обновление интерфейса пользователя выполняет движок браузера. Этот этап, как правило, состоит из четырёх шагов: style, layout (reflow), paint, composite. На этапе style браузер пересчитывает изменение стилей, вызванное операциями JavaScript, и рассчитывает медиа-выражения. Layout выполняет перерасчёт геометрии страницы, где происходит вычисление слоёв, расчёт взаимного расположения элементов и их влияния друг на друга. Во время шага paint движок отрисовывает элементы и применяет к ним стили, которые влияют только на внешний вид, например, на цвет, фон и т. п. Composite применяет оставшиеся специфические стили. Как правило, это трансформации, которые происходят в отдельном слое.
Браузер может пропускать некоторые операции, если они не нужны. Понимать, когда браузер выполняет или пропускает тот или иной шаг, может быть полезным для оптимизации веб-страницы. Более подробно о каждом этапе и его связи с производительностью можно прочитать во второй части хабрастатьи «Оптимизация производительности фронтенда».
Обновление интерфейса: style, layout (reflow), paint, composite
Первой операцией в цикле событий может быть как обновление интерфейса, так и выполнение кода. Если сайт использует синхронный тег script, то с большой вероятностью движок выполнит его перед тем, как отрисовать первый кадр интерфейса пользователя. Если же мы грузим скрипты асинхронно через async или defer, то велика вероятность, что до загрузки JavaScript браузер успеет отрисовать интерфейс пользователя.
Вариант с асинхронной загрузкой скриптов более предпочтительный, потому что начальный бандл, как правило, достаточно объёмный. Пока он полностью не выполнится, пользователь будет видеть белый экран, потому что цикл событий не сможет отрисовать интерфейс пользователя. При этом даже при асинхронной загрузке рекомендуется разбивать JavaScript-код на отдельные бандлы и сначала грузить только самое необходимое, потому что цикл событий очень последовательный: он полностью выполняет весь код в стеке вызовов и только потом переходит к обновлению интерфейса. Если в стеке вызовов будет слишком много кода, интерфейс будет обновляться с большой задержкой. У пользователя создастся впечатление, что сайт лагает. Если написать бесконечный цикл, то браузер так и будет выполнять код снова и снова, а обновление интерфейса не наступит никогда, поэтому страница просто зависнет и перестанет реагировать на действия пользователя.
Внутри стека вызовов будет выполняться как код, написанный разработчиком, так и код, встроенный по умолчанию и отвечающий за взаимодействие со страницей. Благодаря встроенному коду работают прокрутка, выделение, анимации и другие штуки, для которых, казалось бы, JavaScript не нужен. Стек вызовов будет выполнять встроенные скрипты даже тогда, когда мы запретим в браузере JavaScript. Для примера можно открыть пустую страницу about:blank без JavaScript, выполнить несколько кликов и увидеть, что стек вызовов выполнил код, отвечающий за обработку событий.
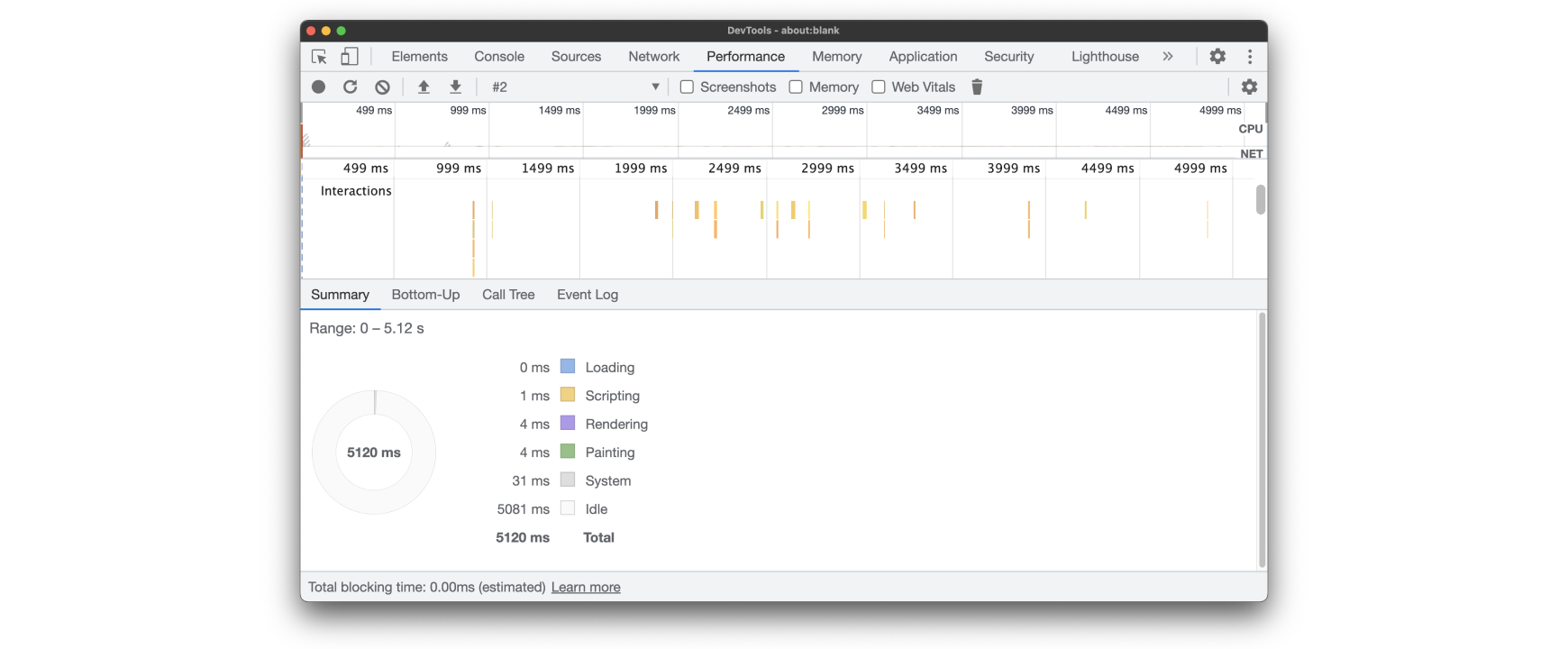
У цикла событий всегда есть работа, даже когда сайт написан без JavaScript
Задачи, тики и Web API
Задача — это JavaScript-код, который выполняется в стеке вызовов. Тик — выполнение задачи в стеке вызовов. Web API — свойства и методы в глобальном объекте Window.
Методы Web API работают либо синхронно, либо асинхронно: первые выполнятся в текущем тике, а вторые в одном из следующих тиков.
Хороший пример синхронных вызовов — это работа DOM:
const button = document.createElement('button')
document.body.appendChild(button)
button.textContent = 'OK'Создание элемента, вставка в DOM и выставление свойств — это синхронные операции, которые выполняются в текущем тике. Поэтому совершенно нет разницы, когда мы выставим текст для кнопки — до вставки в DOM или после неё. Браузер обновит интерфейс только после полного завершения синхронных операций, так что пользователь увидит сразу актуальное состояние интерфейса.
Когда мы пишем асинхронный код, то гарантируем, что задача будет выполняться в следующем тике. При этом он может начаться как до обновления интерфейса, так и после. Например, когда циклу событий требуется выполнить очередную задачу, он может либо выполнить её сразу после предыдущей, либо сначала обновить интерфейс, а только потом выполнить следующую задачу. Для разработчиков это не играет особой роли. Важно просто понимать, что асинхронная задача выполнится когда-то в будущем.
Хороший пример асинхронного вызова — это запрос данных с сервера. Через функцию обратного вызова описывается задача, которая будет выполнена когда-то в будущем после получения данных:
fetch('/url')
.then((response) => {
// выполнится когда-то в будущем
})Подсистема браузера, которая отвечает за работу с сетью, выполнит запрос в отдельном потоке, который будет работать независимо. Пока запрос будет выполняться фоном, цикл событий может спокойно обновлять интерфейс и выполнять код. После того как данные успешно загрузятся, задание, которое мы описали через функцию обратного вызова, станет готовым для выполнения в одном из следующих тиков нашего основного цикла заданий.
Задач, готовых к выполнению после асинхронных вызовов, может быть несколько. Поэтому для передачи их в стек вызовов на выполнение существует специальная очередь.
Очередь задач
Задачи попадают в очередь через асинхронный браузерный API. Сперва где-то в отдельном потоке выполняется асинхронная операция, а после её завершения в очередь добавляется задача, готовая к выполнению в стеке вызовов.

Очередь задач
Понимая эту концепцию, можно разобрать одну особенность таймеров в JavaScript, которые тоже являются асинхронным API.
setTimeout(() => {
// поставить задачу в очередь через 1000 мс
}, 1000)Когда мы запускаем таймер, движок начинает вести обратный отсчёт в отдельном потоке и по готовности задача добавляется в очередь. Можно было бы подумать, что таймер выполнится через одну секунду, но на самом деле это не так. В лучшем случае через одну секунду он добавится в очередь заданий, а код будет выполнен только после того, как до него дойдёт очередь.
Точно такая же история с обработчиками событий. Каждый раз, когда мы регистрируем обработчик событий, мы привязываем к нему задачу, которая будет добавлена в очередь после наступления события:
document.body.addEventListener('click', () => {
// поставить задачу в очередь, когда наступит событие
})16,6 миллисекунды на задачу
Чтобы сайты были быстрыми и «отзывчивыми», браузеру надо создать иллюзию, что он одновременно выполняет код пользователя и обновляет интерфейс. Но поскольку цикл событий работает строго последовательно, браузеру приходится быстро переключаться между задачами, чтобы пользователь ни о чём не догадался.
Как правило, мониторы обновляют картинку с частотой 60 кадров в секунду (значение сильно зависит от дисплея и может быть как 144 Гц, так и 30 Гц в режиме энергосбережения), поэтому цикл событий старается с такой же скоростью выполнять код и обновлять интерфейс. Для примера, если обновление происходит с частотой 60 Гц, то на выполнение задачи остаётся 16,6 миллисекунды. Если наш код будет выполняться быстрее, то браузер будет просто часто обновлять дисплей. Но если код будет выполняться медленно, то частота кадров начнёт снижаться, и у пользователя появится ощущение, что сайт лагает.
Для большинства сценариев 16,6 миллисекунды вполне достаточно. Но иногда на клиентской стороне требуется выполнять тяжёлые вычисления, которые могут потребовать гораздо больше времени. Для этого есть специальные методики.
Обработка больших задач
Оптимизировать большие задачи можно двумя путями: либо через разбиение их на подзадачи и выполнение последних в разных тиках, либо через вынесение вычисления в отдельный поток.
Выполнить что-то в следующем тике можно, например, через setTimeout с минимальной задержкой.
function longTask () {
toDoSomethingFirst()
setTimeout(() => {
toDoSomethingLater()
}, 0)
}Кроме того есть экспериментальная функция postTask, которая является частью Scheduling API и в данный момент доступна только в Chrome. Через неё можно не только выполнять задачи асинхронно для разгрузки основного потока, но и устанавливать для них приоритет. Более подробно об этом можно почитать в статье Джереми Вагнера «Optimize long tasks».
Для запуска отдельного потока подойдёт Web Worker API:
const worker = new Worker('worker.js')
worker.addEventListener('message', () => {
// получить данные
})
// отправить данные
worker.postMessage('any data')Для веб-воркера создаётся отдельный поток, где будут происходить вычисления независимо от основного цикла событий. Как только вычисления закончатся, воркер через postMessage сможет отправить данные в основной цикл событий и задача, связанная с их обработкой, будет добавлена в очередь и выполнена в одном из следующих тиков. Но у веб-воркера есть ограничения. Например, внутри нельзя работать с DOM, однако вычислительные задачи будут работать.
Если данные вычислений нужны внутри других вкладок в рамках одного источника (same origin), то вместо обычного воркера можно использовать SharedWorker. Кроме того, для некоторых задач может быть полезен ServiceWorker, но это уже другая история. Подробнее про воркеры можно прочитать, например, вот тут.
Кроме веб-воркеров есть другой, менее очевидный способ создать отдельный поток — открыть окно или фрейм на другом домене, чтобы нарушить политику same origin. Тогда у окна или фрейма будет свой собственный независимый цикл событий, который сможет выполнять какую-то работу и взаимодействовать с основным окном так же, как и веб-воркер через механизм postMessage. Это достаточно специфическое поведение, которое может по-разному выглядеть в разных браузерах, его можно проверить, например, через демку со Stack Overflow.
Микрозадачи
Микрозадачи — это те задачи, которые хранятся в специальной отдельной очереди.
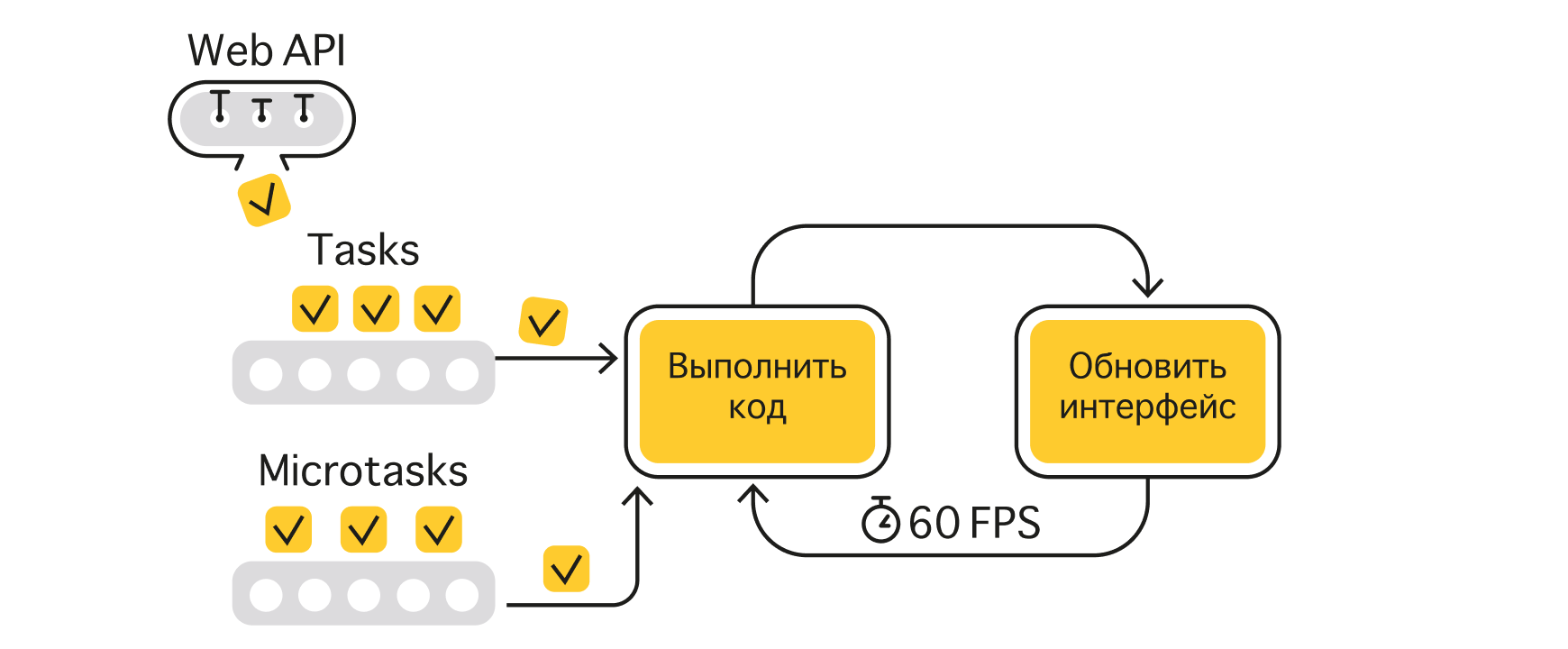
Очередь микрозадач
Задачи попадают в эту очередь при использовании обещаний, асинхронных функций, встроенном вызове queueMicrotask или для Observer API.
Promise.resolve.then(() => {
// микрозадача
})
async function () {
// микрозадача
}
queueMicrotask(() => {
// микрозадача
})
new MutationObserver(() => {
// микрозадача
}).observe(document.body, { childList: true, subtree: true })Очередь микрозадач более приоритетная, задачи из неё выполняются раньше обычных. Кроме того, у неё есть важная особенность — цикл событий будет выполнять микрозадачи до тех пор, пока очередь не опустеет. Благодаря этому, движок гарантирует, что все задачи из очереди имеют доступ к одинаковому состоянию DOM.
Это поведение можно наглядно увидеть на примере с обещаниями, где каждый последующий обработчик получает доступ к одному и тому же состоянию DOM (на момент установки обещания):
Смотреть код
const div = document.createElement('div')
document.body.appendChild(div)
let height = 0
function changeDOM () {
height += 1
div.style.height = `${height}px`
requestAnimationFrame(changeDOM)
}
requestAnimationFrame(changeDOM)
setTimeout(() => {
const promise = Promise.resolve()
.then(() => {
console.log(div.style.height)
})
.then(() => {
console.log(div.style.height)
})
promise
.then(() => {
console.log(div.style.height)
})
}, 1000)
// все console.log выведут одинаковое значение
Есть замечательный наглядный сайт JavaScript Visualizer 9000, где можно более подробно изучить, как работают очереди задач и микрозадач. Ещё советую хорошую хабрастатью, где разбираются обещания.
requestAnimationFrame
requestAnimationFrame (или сокращённо rAF) позволяет выполнить JavaScript-код прямо перед обновлением интерфейса. Каким-то другим способом, например через таймеры, эмулировать такое поведение практически невозможно.

Вверху без rAF, внизу через rAF
Основная задача requestAnimationFrame — это плавное выполнение JavaScript-анимаций, но используют его нечасто, так как анимации проще и эффективнее задать средствами CSS. Тем не менее он занимает своё полноценное место в цикле событий.
Задач, которые нужно выполнить перед обновлением следующего кадра, может быть несколько, поэтому у requestAnimationFrame есть своя отдельная очередь.
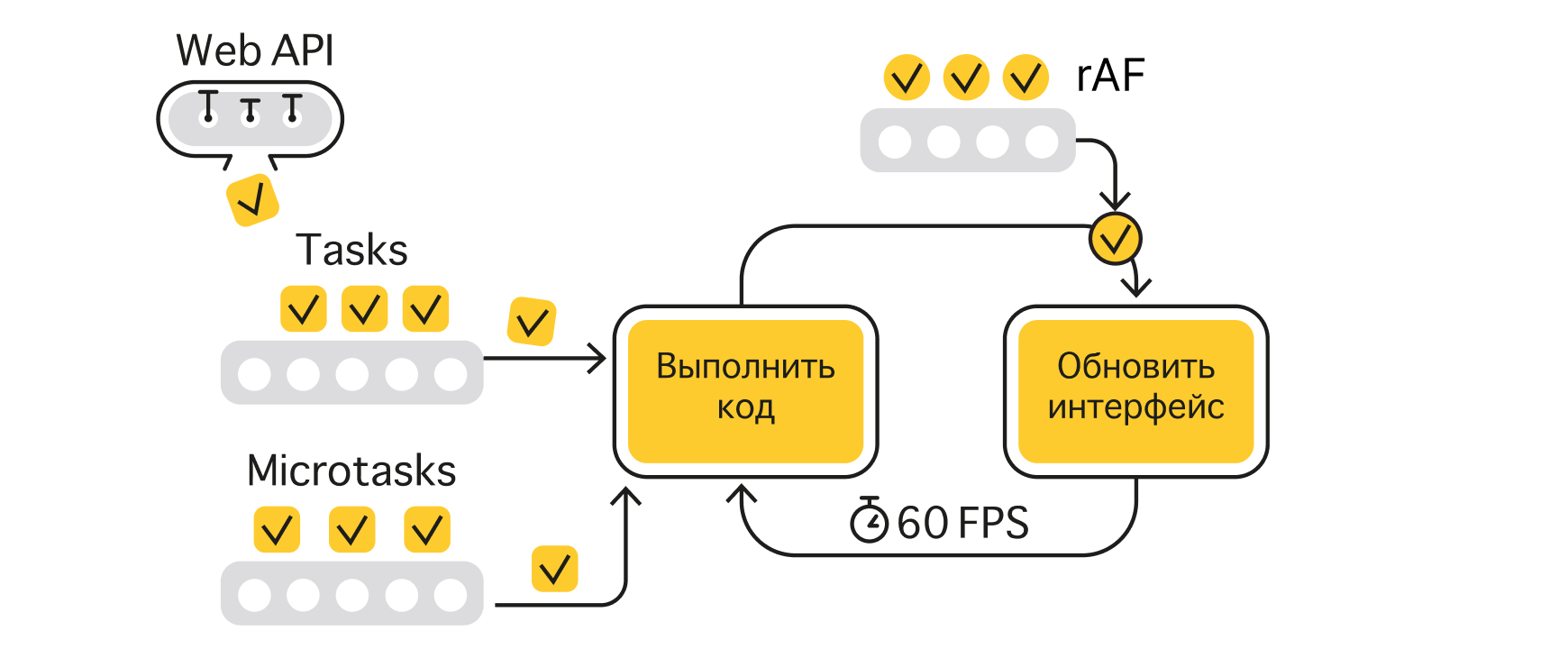
requestAnimationFrame
Задачи из очереди выполняются один раз перед обновлением интерфейса в порядке их добавления:
requestAnimationFrame(() => {
console.log('one')
})
requestAnimationFrame(() => {
console.log('two')
})
requestAnimationFrame(() => {
console.log('three')
})
// one two three
Написать повторяющуюся задачу, которая будет выполняться снова и снова, можно через рекурсивную функцию. Причём, если по какой-то причине потребуется отменить выполнение, это можно сделать через cancelAnimationFrame. Но надо убедиться, что в него передаётся актуальный идентификатор, потому что каждый вызов rAF создаёт новый requestId.
let requestId
function animate () {
requestId = requestAnimationFrame(animate)
}
requestId = requestAnimationFrame(animate)
setTimeout(() => {
// отменить анимации через какое-то время
cancelAnimationFrame(requestId)
}, 3000)Небольшая, но дельная статья по теме requestAnimationFrame есть в блоге Флавио Коупса.
requestIdleCallback
requestIdleCallback (или сокращённо rIC) добавляет задачи в ещё одну (четвёртую) очередь, которая будет выполняться в период простоя браузера, когда нет более приоритетных задач из других очередей.
function sendAnalytics () {
// отправить данные для аналитики
}
requestIdleCallback(sendAnalytics, { timeout: 2000 })В качестве второго аргумента можно указать timeout и, если задача не будет выполнена в течение указанного числа миллисекунд, то она добавится в обычную очередь, после чего выполнится в порядке общей очереди.
По аналогии с requestAnimationFrame, чтобы регулярно добавлять задачу в очередь, потребуется написать рекурсивную функцию, а для остановки — передать актуальный идентификатор в cancelIdleCallback.

requestIdleCallback
В отличие от других очередей, рассмотренных ранее, requestIdleCallback — это всё ещё отчасти экспериментальное API, поддержка которого отсутствует в Safari. Кроме того, эта функция имеет ряд ограничений, из-за которых её удобно использовать только для небольших неприоритетных задач без взаимодействия с DOM, например для отправки аналитических данных. Более подробно о requestIdleCallback можно почитать в материале «Using requestIdleCallback» Пола Льюиса.
Сравнение очередей
Очередь микрозадач — это самая приоритетная очередь, с неё начинается выполнение кода. Работа браузера с этой очередью продолжается до тех пор, пока в ней есть задачи, сколько бы времени это ни заняло.
Из очереди задач движок выполняет, как правило, одно или несколько заданий, стараясь уложиться в 16,6 миллисекунды. Как только пройдёт отведённое время, движок пойдёт обновлять интерфейс, даже если в очереди остались задачи. К ним он вернётся на следующем витке цикла событий.
requestAnimation выполнит все задачи из своей очереди, потому что он гарантирует выполнение кода перед обновлением интерфейса. Но если в ходе выполнения кто-то добавит новые задания в очередь, то они выполнятся уже на следующем витке.
Когда наступит время простоя и в других очередях не будет более приоритетных задач, выполнится одно или несколько заданий requestIdleCallback. Таким образом, эта очередь чем-то похожа на очередь задач, но с более низким приоритетом.
Взаимодействие с очередями происходит через:
- задачи — таймеры, события (включая обработку postMessage);
- микрозадачи — обещания, асинхронные функции, Observer API, queueMicrotask;
- requestAnimationFrame, requestIdleCallback — соответствующие вызовы API.
Цикл событий в Node.js
В Node.js цикл событий работает схожим образом: сначала выполняется задание, затем нужно заглянуть в очередь за следующим. Но набор очередей отличается, а также отсутствуют этапы, связанные с обновлением интерфейса, потому что код работает на сервере. Подробнее о циклах событий в Node.js можно почитать в серии статей, которые написал Дипал Джаясекара (Deepal Jayasekara). Для быстрого понимания setImmediate и process.nextTick есть хорошее объяснение на Stack Overflow.
Функции обратного вызова
Это удобный и простой способ взаимодействовать с асинхронным API, но если быть с ним неаккуратным, возникает много проблем.
Ад обратных вызовов
Ад обратных вызовов (callback hell) — самая частая проблема, которую вспоминают, когда говорят про недостатки функций обратного вызова.
Последовательность асинхронных вызовов через функции обратного вызова становится похожа на пирамиду судьбы (pyramid of doom).
fetchToken(url, (token) => {
fetchUser(token, (user) => {
fetchRole(user, (role) => {
fetchAccess(role, (access) => {
fetchReport(access, (report) => {
fetchContent(report, (content) => {
// Welcome to Callback Hell
})
})
})
})
})
})Можно подумать, что это самый главный недостаток функций обратного вызова, но на этом проблемы с ними только начинаются.
Не выпускайте Залго
Дело в том, что сходу нельзя определить, как именно будет вызвана функция обратного вызова — синхронно или асинхронно, а ведь от этого может сильно зависеть логика нашего кода. Чтобы разобраться наверняка, придётся прочитать реализацию функции. А это требует дополнительных действий и усложняет отладку.
syncOrAsync(() => {
// как именно выполняется код?
})
// синхронная реализация
function syncOrAsync (callback) {
callback()
}
// асинхронная реализация
function syncOrAsync (callback) {
queueMicrotask(callback)
}В узких кругах эта проблема широко известна как проблема монстра Залго, которого лучше не выпускать на свободу.
Жёсткая сцепленность
Жёсткая сцепленность — это проблема зависимости одной части кода от другой при обработке последовательных асинхронных операций:
firstStep((error, data) => {
if (error) {
// отменить этап №1
}
secondStep((error, data) => {
if (error) {
// отменить этап №2, а затем №1
}
})
}))Если ошибка наступит на этапе №1, надо будет обработать только её. Но если ошибка произойдёт уже на этапе №2, то придётся отменить этап №2, а затем и этап №1 тоже. И чем больше этапов, тем больше проблем при обработке ошибок.
Проблема доверия
Инверсия управления — это передача нашего кода в библиотеку, которую писали другие разработчики:
import { thirdPartyCode } from 'third-party-package'
thirdPartyCode(() => {
// инверсия управления
})Мы полагаемся на то, что наша задача будет вызвана так, как надо, но всё может быть далеко не так. Другая библиотека может вызвать функцию слишком рано или слишком поздно, делать это слишком часто или редко, поглотить ошибки и исключения, передать неправильные аргументы или вовсе не вызвать нашу функцию.
Исходя из сказанного, можно подумать, что работа с асинхронностью через функции обратного вызова — это сплошные сложности. Отчасти так и есть, но, к счастью, со всеми этими проблемами помогают справиться обещания.
Обещания
Обещания напоминают талончики с номером заказа в кафе. Когда мы делаем заказ, вместо еды мы получаем талончик с номером. Дальше возможны два сценария. Первый: заказ успешно приготовят и через некоторое время выдадут на стойке получения заказов. Второй: что-то может пойти не так, например, закончатся нужные ингредиенты, тогда сотрудник кафе сообщит нам, что не может приготовить наш заказ, и предложит вернуть деньги или заказать что-то другое.
Обещания создаются через конструктор Promise, который обязательно вызывается через new. Конструктор принимает только один аргумент — функцию обратного вызова с двумя параметрами: resolve и reject. Внутри обещания вызывается асинхронная операция с функцией обратного вызова. В свою очередь внутри этой функции вызывается либо resolve, либо reject, которые устанавливают обещание либо на выполнение, либо на отказ соответственно.
Вот так вот можно выставить обещание либо на выполнение, либо на отказ:
// выставить обещание на выполнение
const resolvedPromise = new Promise((resolve, reject) => {
setTimeout(() => { resolve('^_^') }, 1000)
})
// выставить обещание на отказ
const rejectedPromise = new Promise((resolve, reject) => {
setTimeout(() => { reject('O_o') }, 1000)
})После того как обещание установлено, результат можно получить через метод then:
resolvedPromise.then((value) => {
console.log(value) // ^_^
})Обработать отказ можно либо через второй параметр в then, либо через catch:
rejectedPromise.then(
(value) => {
// ... проигнорировано
},
(error) => {
console.log(error) // O_o
}
)
rejectedPromise.catch((error) => {
console.log(error) // O_o
})Значение обещания устанавливается один раз, после чего его уже не изменить:
const promise = new Promise((resolve, reject) => {
resolve('^_^')
reject('O_o') // уже никак не повлияет на состояние Promise
})
promise.then((value) => {
console.log(value) // ^_^
})
promise.then((value) => {
console.log(value) // ^_^
})Для удобства можно использовать статические методы — функции-конструкторы Promise.resolve и Promise.reject, которые создают сразу установленное обещание:
Promise.resolve('^_^').then((value) => {
console.log(value) // ^_^
})
Promise.reject('O_o').catch((error) => {
console.log(error) // O_o
})У обещаний ещё есть метод finally, который что-то сделает независимо от успеха или неудачи. Это чем-то похоже на приготовление блюда в духовке: неважно, пригорело наше блюдо или нет — духовку всё равно надо будет выключить.
Promise.resolve('^_^').finally(() => {
// какая-то работа
}).then((value) => {
console.log(value) // ^_^
})
Promise.reject('O_o').finally(() => {
// какая-то работа
}).catch((error) => {
console.log(error) // O_o
})Цепочки обещаний и проброс отказа
Самая главная польза обещаний в том, что мы можем выстраивать из них цепочки асинхронных операций:
Promise.resolve('^')
.then((value) => {
return value + '_'
})
.then((value) => {
return value + '^'
})
.then((value) => {
console.log(value) // ^_^
})Если где-то произойдёт ошибка, то отказ пропустит обработчики на выполнение и долетит до ближайшего обработчика отказа, после чего цепочка продолжит работать в штатном режиме:
Promise.resolve()
.then(() => {
return Promise.reject('O_o')
})
.then(() => {
// все обработчики на выполнение будут пропущены
})
.catch((error) => {
console.log(error) // O_o
})
.then(() => {
// продолжаем выполнять цепочку в штатном режиме
})Возвращать значение можно и внутри catch, оно будет точно так же обработано в цепочке:
Promise.reject('O_o')
.catch((error) => {
console.log(error) // O_o
return '^_^'
})
.then((value) => {
console.log(value) // ^_^
})Если цепочка завершится, а ошибка останется необработанной, то сработает событие Unhandeled Promise Rejection, на которое можно подписаться, чтобы отслеживать необработанные ошибки внутри обещаний:
window.addEventListener('unhandledrejection', (event) => {
console.log('Необработанная ошибка Promise. Позор вам!')
console.log(event) // PromiseRejectionEvent
console.log(event.reason) // O_o
})
Promise.reject('O_o') // Unhandled Promise RejectionВажно понимать, что обработка ошибок работает только тогда, когда цепочка непрерывна. Если опустить return и создать обещание, установленное на отказ, то последующий catch не сможет его обработать:
Promise.resolve()
.then(() => {
Promise.reject('O_o')
})
.catch(() => {
// будет пропущено, потому что не указан return
// будет выброшено UnhandledPromiseRejection
})Неявное поведение
У обещаний есть две неявные особенности. Во-первых, методы then и catch всегда возвращают новое обещание. Во-вторых, внутри себя они перехватывают любые ошибки и, если что-то пошло не так, возвращают обещание, установленное на отказ, с причиной ошибки.
Возвращение нового обещания
Каждый вызов then или catch создаёт новое обещание, значение которого либо undefined, либо явно выставляется через return.
Благодаря этому, вместо создания временных переменных можно сразу сделать удобную цепочку вызовов:
// можно и так:
const one = Promise.resolve('^')
const two = one.then((value) => {
return value + '_'
})
const three = two.then((value) => {
return value + '^'
})
three.then((value) => {
console.log(value) // ^_^
})
// но так гораздо лучше:
Promise.resolve('^')
.then((value) => {
return value + '_'
})
.then((value) => {
return value + '^'
})
.then((value) => {
console.log(value) // ^_^
})При этом, если вернуть обещание, его значение распакуется и всё будет работать точно так же.
Promise.resolve()
.then(() => {
return Promise.resolve('^_^')
})
.then((value) => {
console.log(value) // ^_^
})За счёт этого можно избегать вложенных обещаний и всегда писать код с одним уровнем вложенности:
// можно и так:
Promise.resolve('^')
.then((value) => {
return Promise.resolve(value + '_')
.then((value) => {
return Promise.resolve(value + '^')
.then((value) => {
console.log(value) // ^_^
})
})
})
// но так гораздо лучше:
Promise.resolve('^')
.then((value) => {
return Promise.resolve(value + '_')
})
.then((value) => {
return Promise.resolve(value + '^')
})
.then((value) => {
console.log(value) // ^_^
})Спрятанный try/catch
Другая особенность обещаний связана с обработкой ошибок. Функции обратных вызовов, которые передаются в методы обещаний, оборачиваются в try/catch. Если что-то пойдёт не так, то try/catch перехватит ошибку и установит её в качестве причины отказа обещания:
Promise.resolve()
.then(() => {
undefined.toString()
})
.catch((error) => {
console.log(error) // TypeError: Cannot read property 'toString' of undefined
})Это всё равно что самостоятельно написать вот такой код:
Promise.resolve()
.then(() => {
try {
undefined.toString()
} catch (error) {
return Promise.reject(error)
}
})
.catch((error) => {
console.log(error) // TypeError: Cannot read property 'toString' of undefined
})Таким образом, внутри обещаний можно обойтись без try/catch, потому что обещания сделают это за нас. Главное — потом правильно обработать причину отказа в catch.
Thenable-объекты
Это объекты, в которых есть
then:const thenable = {
then (fulfill) {
fulfill('@_@')
}
}Скорее всего, это полифилы обещаний до ES6. Обещания распакуют такие объекты, а затем завернут их в полноценные ES6-обещания. По такому принципу работают resolve, Promise.resolve, then и catch.
Promise.resolve(thenable)
.then((value) => {
console.log(value) // @_@
})
new Promise((resolve) => {
resolve(thenable)
}).then((value) => {
console.log(value) // @_@
})
Promise.resolve()
.then(() => {
return thenable
})
.then((value) => {
console.log(value) // @_@
})Благодаря этому обеспечивается совместимость с кодом, написанным до ES6:
const awesomeES6Promise = Promise.resolve(thenable)
awesomeES6Promise.then((value) => {
console.log(value) // @_@
})Есть одна особенность: если в Promise.resolve передать обычное обещание, то оно не распакуется и вернётся без изменений. При этом resolve, then, catch распакуют значение и создадут новое обещание.
const thenable = {
then (fulfill) {
fulfill('@_@')
}
}
const promise = Promise.resolve('@_@')
const resolvedThenable = Promise.resolve(thenable)
const resolvedPromise = Promise.resolve(promise)
console.log(thenable === resolvedThenable) // false
console.log(promise === resolvedPromise) // trueНо самое интересное — это поведение reject и Promise.reject, которые работают совершенно иначе. Если туда передать любой объект, в том числе и обещание, они просто вернут его как причину отказа:
const promise = Promise.resolve('@_@')
Promise.reject(promise)
.catch((value) => {
console.log(value) // Promise {<fulfilled>: "@_@"}
})Статические методы
У обещаний есть шесть полезных статических методов. Два из них мы уже разобрали — это Promise.resolve и Promise.reject. Давайте посмотрим на другие четыре.
Для наглядности напишем функцию, которая поможет получать установленное обещание через какое-то время:
const setPromise = (value, ms, isRejected = false) =>
new Promise((resolve, reject) =>
setTimeout(() => isRejected ? reject(value) : resolve(value), ms))Все четыре метода, которые мы разберём ниже, принимают массив значений. Но каждый из этих методов работает по своему, и результаты они возвращают разные.
Promise.all
Этот вызов возвращает массив значений или первый отказ:
Promise.all([
setPromise('^_^', 400),
setPromise('^_^', 200),
]).then((result) => {
console.log(result) // [ "^_^", "^_^" ]
})Если хотя бы одно обещание завершится неудачей, то вместо массива значений в catch прилетит причина отказа:
Promise.all([
setPromise('^_^', 400),
setPromise('O_o', 200, true),
]).catch((error) => {
console.log(error) // O_o
})Для пустого массива сразу вернётся пустой результат:
Promise.all([])
.then((result) => {
console.log(result) // []
})Promise.race
Этот метод возвращает первое значение или первый отказ:
Promise.race([
setPromise('^_^', 100),
setPromise('O_o', 200, true),
]).then((result) => {
console.log(result) // ^_^
})Если отказ произойдёт первым, то race установится на отказ:
Promise.race([
setPromise('^_^', 400),
setPromise('O_o', 200, true),
]).catch((error) => {
console.log(error) // O_o
})Если передать в Promise.race пустой массив, то обращение зависнет в состоянии выполнения и не будет установлено ни на выполнение, ни на отказ:
Promise.race([])
.then(() => {
console.log('resolve не выполнится никогда')
}).catch(() => {
console.log('reject тоже')
})Promise.any
Вызов возвращает первое значение или массив с причинами отказа, если ни одно обещание не завершилось успешно:
Promise.any([
setPromise('^_^', 400),
setPromise('O_o', 200, true),
]).then((result) => {
console.log(result) // ^_^
})Когда все обещания установятся на отказ, то any вернёт объект ошибки, в котором информацию об отказах можно будет достать из поля errors:
Promise.any([
setPromise('O_o', 400, true),
setPromise('O_o', 200, true),
]).catch((result) => {
console.log(result.message) // All promises were rejected
console.log(result.errors) // [ "O_o", "O_o" ]
})Для пустого массива вернётся ошибка:
Promise.any([])
.catch((error) => {
console.log(error.message) // All promises were rejected
})Promise.allSettled
Метод дождётся выполнения всех обещаний и вернёт массив специальных объектов:
Promise.allSettled([
setPromise('^_^', 400),
setPromise('O_o', 200, true),
]).then(([resolved, rejected]) => {
console.log(resolved) // { status: "fulfilled", value: "^_^" }
console.log(rejected) // { status: "rejected", reason: "O_o" }
})Для пустого массива сразу вернётся пустой результат:
Promise.allSettled([])
.then((result) => {
console.log(result) // []
})Промисификация
Когда требуется перейти от функций обратного вызова к обещаниям, на помощь приходит промисификация — специальная функция-помощник, которая превращает функцию, работающую с callback, в функцию, которая возвращает обещание:
function promisify (fn) {
return function (...args) {
return new Promise((resolve, reject) => {
function callback(error, result) {
return error ? reject(error) : resolve(result)
}
fn(...args, callback)
})
}
}
function asyncApi (url, callback) {
// ... выполнить асинхронную операцию
callback(null, '^_^')
}
promisify(asyncApi)('/url')
.then((result) => {
console.log(result) // ^_^
})Работа промисификации зависит от сигнатуры функций в коде, потому что требуется учитывать порядок аргументов, а также параметры callback. В примере выше предполагается, что функция обратного вызова передаётся последним аргументом, а в качестве параметров сначала принимает ошибку, а затем результат.
Обещания или функции обратного вызова?
Обещания устраняют недостатки функций обратного вызова. Они всегда асинхронные и одноразовые, код линейный и не обладает жёсткой сцепленностью, можно не переживать за ад обратных вызовов.
Но как быть, если обещание всё-таки зависло и не устанавливается ни на выполнение, ни на отказ? В этом случае можно использовать Promise.race, чтобы прервать выполнение зависшего или очень длинного запроса по таймауту:
Promise.race([
fetchLongRequest(),
new Promise((_, reject) => setTimeout(reject, 3000)),
]).then((result) => {
// получили данные
}).catch((error) => {
// или отказ по таймеру
})В любом случае важно понимать: несмотря на многие преимущества обещаний, всё равно кое-где придётся использовать функции обратного вызова, и это нормально. Через них работают обработчики событий и многие асинхронные методы API, например setTimeout, поэтому в таких случаях нет смысла промисифицировать и удобнее использовать функции обратного вызова. В конце концов, они нам также понадобятся, чтобы создать обещание. Главное запомнить, что, если где-то есть цепочка последовательных вызовов, там обязательно надо использовать обещания.
Корутины
Обещания — это фундамент для работы с асинхронностью, но над этим фундаментом есть очень удобная надстройка async/await, которая реализуется благодаря корутинам.
Корутина (coroutine, cooperative concurrently executed routine) — это сопрограмма или, проще говоря, особая функция, которая может приостанавливать свою работу и запоминать состояние, а также имеет несколько точек входа и выхода.
В JavaScript в качестве корутин выступают функции-генераторы, которые возвращают итератор. Итератор может приостанавливать свою работу, запоминать текущее состояние и взаимодействовать с внешним кодом через .next и .throw.
Благодаря таким возможностям корутин, можно написать специальную функцию следующего вида:
function async (generator) {
const iterator = generator()
function handle({ done, value }) {
return done ? value : Promise.resolve(value)
.then((x) => handle(iterator.next(x)))
.catch((e) => handle(iterator.throw(e)))
}
return handle(iterator.next())
}И затем через неё последовательно вызывать асинхронные операции:
async(function* () {
const response = yield fetch('example.com')
const json = yield response.json()
// обработать json
})Это оказалось настолько удобно, что позже в JavaScript добавили конструкции async/await.
Async/await
Это синтаксический сахар, реализованный через обещания и корутины, который делает работу с асинхронными операциями более удобной.
Модификатор async ставится перед функцией и делает её асинхронной:
async function asyncFunction () {
return '^_^'
}Результат асинхронной функции — это всегда обещание. Для удобства можно представлять асинхронную функцию как обычную, которая заворачивает свой результат в обещание:
function asyncFunction () {
return Promise.resovle('^_^')
}Результат асинхронной функции извлекается через then или через await:
asyncFunction().then((value) => {
console.log(value) // ^_^
})
(async () => {
const value = await asyncFunction()
console.log(value) // ^_^
})()Await немного удобнее обещаний, но у него есть серьёзное ограничение — его можно вызывать только внутри асинхронной функции. При этом асинхронность становится «прилипчивой» — стоит один раз написать асинхронный вызов, и дороги назад, в синхронный мир, уже нет. Какое-то время с этим ничего нельзя было сделать, но потом появился верхнеуровневый await.
Верхнеуровневый await и асинхронные модули
Верхнеуровневый await (top level await) позволяет использовать этот оператор за пределами асинхронных функций:
const connection = await dbConnector()
const jQuery = await import('http://cdn.com/jquery')Но его можно использовать только либо внутри ES6-модулей, либо в DevTools. Такое ограничение связано с тем, что await — это синтаксический сахар, который работает через модули.
Например, модуль с верхнеуровневым await для разработчика выглядит так:
// module.mjs
const value =
await Promise.resolve('^_^')
export { value }
// main.mjs
import {
value
} from './module.mjs'
console.log(value) // ^_^Ни внутри модуля, ни внутри основной программы нет асинхронных функций, но при этом они необходимы для работы await. Как же тогда работает этот код?
Дело в том, что движок сам возьмёт на себя задачу обернуть await в асинхронную функцию, поэтому где-то «под капотом», без синтаксического сахара, верхнеуровневый await будет выглядеть примерно так:
// module.mjs
export let value
export const promise = (async () => {
value = await Promise.resolve('^_^')
})()
export { value, promise }
// main.mjs
import {
value,
promise
} from './module.mjs'
(async () => {
await promise
console.log(value) // ^_^
})()Никакой магии. Просто синтаксический сахар.
Обработка ошибок
Есть два способа обработать ошибку внутри асинхронных функций. Первый — поставить catch после вызова функции, второй — обернуть вызов await в конструкцию try/catch.
Поскольку асинхронные функции — это обещания, после вызова можно поставить catch и обработать ошибку.
async function asyncFunction () {
await Promise.reject('O_o')
}
asyncFunction()
.then((value) => {
// вдруг ошибка?
})
.catch((error) => {
// тогда ошибку поймает catch
})Такой способ будет работать, но, скорее всего, try/catch подойдёт лучше, потому что даст возможность обработать исключение сразу в теле функции:
async function asyncFunction () {
try {
await Promise.reject('O_o')
} catch (error) {
// перехватить ошибку
}
}
asyncFunction().then((value) => {
// мы в безопасности
})Другое важное преимущество: в отличие от catch, конструкция try/catch сможет обработать верхнеуровневый await.
Не все await одинаково полезны
Оператор await приостанавливает выполнение задачи до завершения асинхронной операции. Если перед каждой асинхронной операцией бездумно ставить await, это может привести к неоптимальной работе кода из-за последовательной загрузки несвязанных данных.
Например, список статей и картинок, которые никак друг с другом не связаны, через await можно было бы загрузить вот так:
const articles = await fetchArticles()
const pictures = await fetchPictures()
// ... какие-то действия с articles и picturesТогда данные, которые можно было бы получить параллельно, будут запрашиваться последовательно. До тех пор пока первая часть данных не загрузится полностью, работа со второй частью не начнётся. Из-за этого задача будет выполняться дольше, чем могла бы. Допустим, каждый запрос выполняется за две секунды, тогда на полную загрузку данных уйдёт четыре секунды. Но если данные грузить параллельно, через Promise.all, то вся информация загрузится в два раза быстрее:
const [articles, pictures] = await Promise.all([
fetchArticles(),
fetchPictures(),
])Заключение
Вот и всё, что вы, вероятно, хотели знать про асинхронность в браузере. Надеюсь, теперь вы хорошо понимаете, как действует цикл событий, сможете выбраться из ада обратных вызовов, легко работаете с обещаниями и грамотно используете async/await. Если я что-то забыл, напоминайте в комментариях.
