Сегодня выходит ABBYY FineReader 11, и сейчас мы расскажем вам, чем он отличается от десятой версии. Прежде всего, достаточно заметно донастроились алгоритмы поиска на странице текста, картинок и таблиц – то, что у нас называют «Анализ документа», а в мире понятным словом zoning. Главное, к чему мы стремились, работая над новой версией, – улучшить «понимание» документов, с которыми пользователи сталкиваются каждый день: книг, договоров, журналов. Одним из легко заметных изменений стало то, что FineReader 11 научился находить вертикальные колонтитулы.

Как мы уже сказали, в новом FineReader блоки разных типов определяются более точно – это помогает правильнее «собирать» строки текста. Например, прошлая версия иногда впадала в ступор, видя ультра-модную вёрстку книжек с «авторскими заметками на полях»:

В результате такого выделения программа считала, что строки из второй колонки – это продолжение строк из первой, и текст выстраивался неправильно.
Теперь мы знаем о существовании таких книг и сообщили об этом нашему детищу. В результате блоки выделяются правильно.
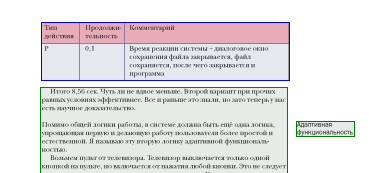
Кстати, на приведённых изображениях видно ещё одно продвижение FineReader’а на пути к совершенству – таблицы стали лучше разбиваться на ячейки. В среднем по сравнению с десятой версией количество ошибок разбиения таблиц на ячейки уменьшилось на 25%. Кроме того, ошибок при определении колонтитулов стало меньше на 40%, а картинки и диаграммы «находятся» лучше на 15%. Впрочем, вопрос, как измерять количество ошибок анализа, – довольно тонкий и, возможно, заслужит отдельного внимания. А с таблицами-то всё ясно – мы одной ошибкой считаем или разбиение ячейки на две, или наоборот, объединение двух ячеек в одну.
Что ещё? Более стабильной стала работа с большими (более 100 файлов) пакетами документов. Теперь они обрабатываются с такой же скоростью, что и отдельные документы.
Изменения коснулись и обработки сфотографированных документов: лучше работает автоматическое исправление искажений. Кроме того, появился обновленный редактор изображений – в нём можно вручную скорректировать яркость, контрастность, уровни интенсивности света и тени или устранить трапециевидные искажения.
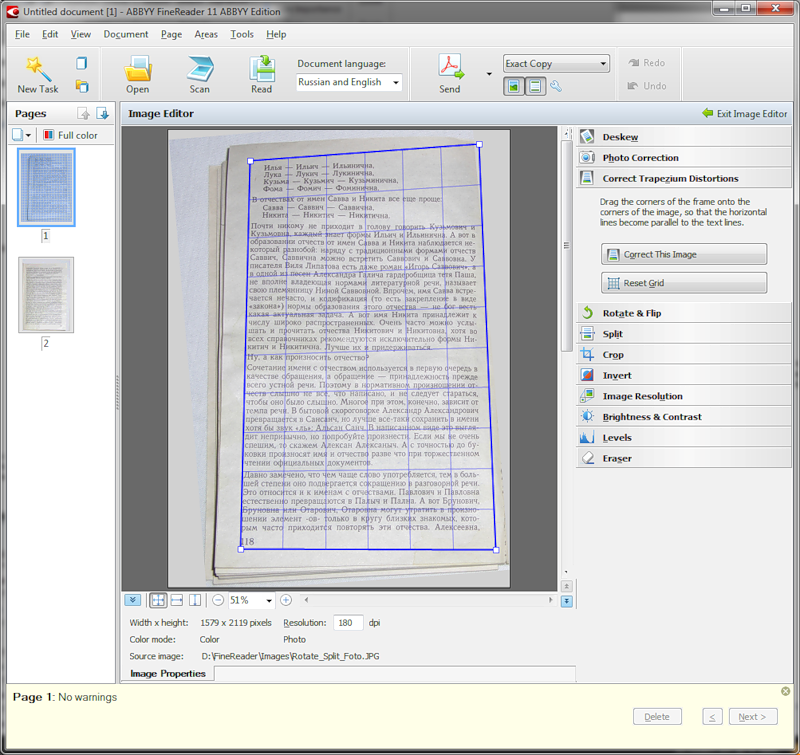
Улучшилась работа с многостраничными документами – теперь распознанные страницы лучше собираются в единый документ, в котором меньше ненужных делений на секции. Новая версия FineReader правильно определяет размер полей и позиционирование колонтитулов – это позволяет сохранять форматирование при экспорте в формат RTF.
Изменения коснулись и экспорта в PDF. Для разного типа задач можно использовать три новых режима сохранения – «Наилучшее качество», «Небольшой размер» и «Сбалансированный режим». Эти режимы задают параметры сохранения изображений, которые будут в вашем PDF. Первый режим понадобится вам, если вы хотите, чтобы картинки были высокого качества. Программа сохранит их с разрешением 300 dpi, при сжатии будут использованы форматы без потери качества ZIP, LZW, а также JPEG и J2K с параметром качества 80. Черно-белые изображения обрабатываются при помощи CCITT4 и JBIG2. Второй режим, «Небольшой размер» имеет смысл использовать, если вы сохраняете файл для архива или в других случаях, если важно сэкономить на весе файла. PDF сжат настолько, насколько это возможно при сохранении читаемости документа. Разрешение изображений здесь будет уже 150 dpi, параметр качества JPEG – 50. «Сбалансированный режим» – это своеобразный компромисс между качеством и размером файла: разрешение 300 dpi, параметр качества JPEG – 60. Что касается технологического аспекта, улучшена технология сжатия MRC (о ней мы писали здесь).
Хорошая новость для пользователей Linux: в FineReader 11 можно сохранять и конвертировать изображения документов и PDF-файлы в формат ODT (OpenOffice.org Writer). Форматирование исходного документа, как обычно, переносятся в новый формат, поэтому тратить время на дополнительное редактирование не придется. Кроме того, появился экспорт в DjVu.
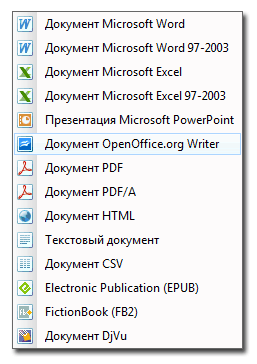
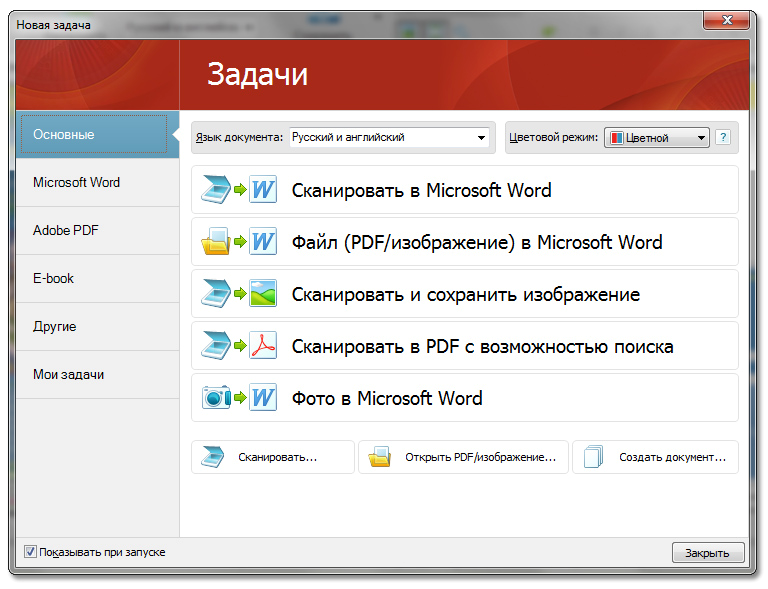
Ещё FineReader 11 умеет преобразовать бумажные книги в электронные: теперь доступно сохранение результатов распознавания не только в HTML (как это было в «десятке»), но и в форматы Electronic Publication (.ePub) and FictionBook (.fb2), оптимизированные для смартфонов, электронных книг и планшетных компьютеров. Причём сценарий создания электронных книг вынесен в окно «Новая задача», которое появляется при старте программы.
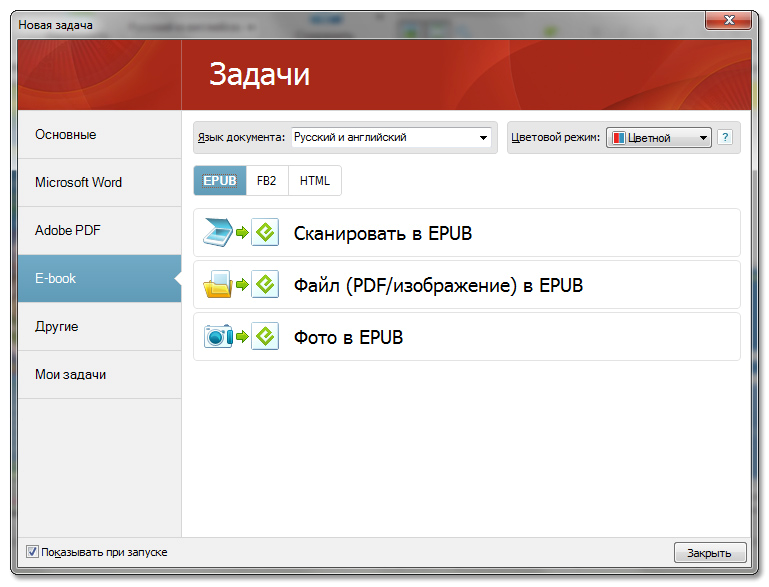
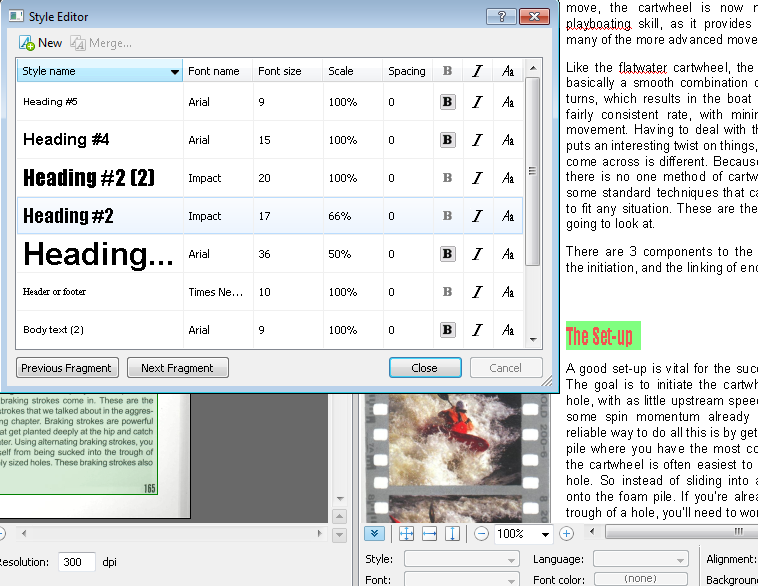
Усовершенствован редактор стилей документа. Теперь настраивать все параметры стилей можно в одном диалоге, а изменения происходят сразу во всем документе.
Изменения коснулись и интерфейса. В окно «Новая задача» вынесены функции, которые бывают нужны чаще всего. Кроме того, в Corporate Edition интерфейс можно настроить под себя, добавляя новые сценарии или импортируя созданные другими пользователями.
Если вы очень торопитесь и хотите распознать документ максимально быстро, можно использовать ещё одну новую функцию – чёрно-белый режим распознавания.

Разумеется, в этом случае за скорость придётся заплатить возможной потерей качества, но мы постарались сделать так, чтобы цена не была слишком высокой.
Всё описанное выше, кроме изменений функций в окне «Новая задача», относится к двум версиям – ABBYY FineReader 11 Professional Edition и ABBYY FineReader 11 Corporate Edition. В корпоративной версии в режиме редактирования можно применить функцию удаления конфиденциальной информации – она помечается и при экспорте удаляется.

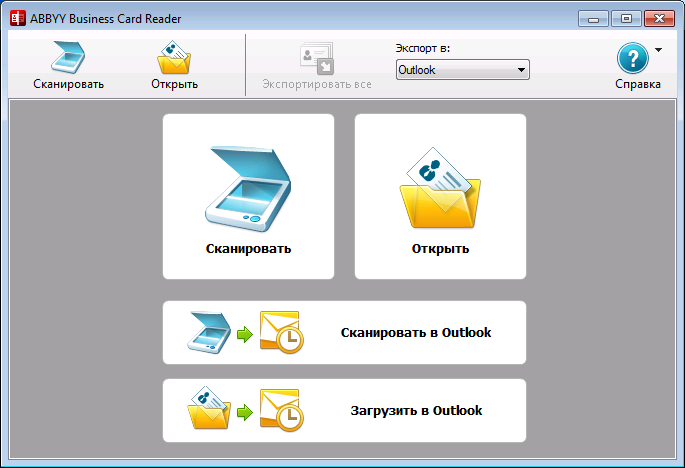
Для пользователей корпоративной версии мы подготовили ещё и бонус – программу ABBYY Business Card Reader. Многие из вас уже знакомы с мобильной версией этой программы, теперь она переехала и на десктоп. Отсканировать визитку и загрузить данные в Microsoft Outlook с распределением данных контакта по соответствующим полям можно одной кнопкой, используя предопределенный сценарий работы. Конечно, если необходимо, данные можно проверить и отредактировать.
Отдельно хочется сказать о работе с языками. У нас наконец-то появилось распознавание арабского языка, причём качество – на уровне конкурентов, а то и выше. Арабский OCR клиенты у нас давно просили, так что получите – распишитесь. Кроме этого, FineReader научился распознавать туркменский (латиница) и вьетнамский. Появилась словарная поддержка для арабского, вьетнамского, японского, двух вариантов корейского и латыни.
Ещё мы стали быстрее распознавать документы на некоторых азиатских языках: скорость распознавания корейского увеличилась аж на 30% без потери в качестве, японского – на 10%. Наши ребята довольно долго отслеживали, «тонкие места» с помощью разных профайлеров (помимо доморощенных счётчиков-таймеров использовались интеловский VTune и AQTime от AutomatedQA Corp). Такого, чтобы магическим взглядом найти место в коде, которое можно переписать и впятеро ускорить программу у нас по счастью не случалось, а про неделю потраченного времени и ускорение на два процента писать как-то не с руки, так что оставим тему, что там поменяли.
Мы рассказали вам об основных изменениях в новой версии FineReader, которую уже сейчас можно купить в нашем магазине. Хотите узнать больше — читайте подробнее на сайте ABBYY.
Ну а если вы хотите попробовать новый FineReader и написать о нем обзор, обозначьтесь в комментах – и мы выдадим вам промо-код. Их у нас три штуки!
Трое желающих написать обзор уже отметилось в комментариях. Скоро на Хабре!

Как мы уже сказали, в новом FineReader блоки разных типов определяются более точно – это помогает правильнее «собирать» строки текста. Например, прошлая версия иногда впадала в ступор, видя ультра-модную вёрстку книжек с «авторскими заметками на полях»:

В результате такого выделения программа считала, что строки из второй колонки – это продолжение строк из первой, и текст выстраивался неправильно.
Теперь мы знаем о существовании таких книг и сообщили об этом нашему детищу. В результате блоки выделяются правильно.

Кстати, на приведённых изображениях видно ещё одно продвижение FineReader’а на пути к совершенству – таблицы стали лучше разбиваться на ячейки. В среднем по сравнению с десятой версией количество ошибок разбиения таблиц на ячейки уменьшилось на 25%. Кроме того, ошибок при определении колонтитулов стало меньше на 40%, а картинки и диаграммы «находятся» лучше на 15%. Впрочем, вопрос, как измерять количество ошибок анализа, – довольно тонкий и, возможно, заслужит отдельного внимания. А с таблицами-то всё ясно – мы одной ошибкой считаем или разбиение ячейки на две, или наоборот, объединение двух ячеек в одну.
Что ещё? Более стабильной стала работа с большими (более 100 файлов) пакетами документов. Теперь они обрабатываются с такой же скоростью, что и отдельные документы.
Изменения коснулись и обработки сфотографированных документов: лучше работает автоматическое исправление искажений. Кроме того, появился обновленный редактор изображений – в нём можно вручную скорректировать яркость, контрастность, уровни интенсивности света и тени или устранить трапециевидные искажения.

Улучшилась работа с многостраничными документами – теперь распознанные страницы лучше собираются в единый документ, в котором меньше ненужных делений на секции. Новая версия FineReader правильно определяет размер полей и позиционирование колонтитулов – это позволяет сохранять форматирование при экспорте в формат RTF.
Изменения коснулись и экспорта в PDF. Для разного типа задач можно использовать три новых режима сохранения – «Наилучшее качество», «Небольшой размер» и «Сбалансированный режим». Эти режимы задают параметры сохранения изображений, которые будут в вашем PDF. Первый режим понадобится вам, если вы хотите, чтобы картинки были высокого качества. Программа сохранит их с разрешением 300 dpi, при сжатии будут использованы форматы без потери качества ZIP, LZW, а также JPEG и J2K с параметром качества 80. Черно-белые изображения обрабатываются при помощи CCITT4 и JBIG2. Второй режим, «Небольшой размер» имеет смысл использовать, если вы сохраняете файл для архива или в других случаях, если важно сэкономить на весе файла. PDF сжат настолько, насколько это возможно при сохранении читаемости документа. Разрешение изображений здесь будет уже 150 dpi, параметр качества JPEG – 50. «Сбалансированный режим» – это своеобразный компромисс между качеством и размером файла: разрешение 300 dpi, параметр качества JPEG – 60. Что касается технологического аспекта, улучшена технология сжатия MRC (о ней мы писали здесь).
Хорошая новость для пользователей Linux: в FineReader 11 можно сохранять и конвертировать изображения документов и PDF-файлы в формат ODT (OpenOffice.org Writer). Форматирование исходного документа, как обычно, переносятся в новый формат, поэтому тратить время на дополнительное редактирование не придется. Кроме того, появился экспорт в DjVu.

Ещё FineReader 11 умеет преобразовать бумажные книги в электронные: теперь доступно сохранение результатов распознавания не только в HTML (как это было в «десятке»), но и в форматы Electronic Publication (.ePub) and FictionBook (.fb2), оптимизированные для смартфонов, электронных книг и планшетных компьютеров. Причём сценарий создания электронных книг вынесен в окно «Новая задача», которое появляется при старте программы.

Усовершенствован редактор стилей документа. Теперь настраивать все параметры стилей можно в одном диалоге, а изменения происходят сразу во всем документе.

Изменения коснулись и интерфейса. В окно «Новая задача» вынесены функции, которые бывают нужны чаще всего. Кроме того, в Corporate Edition интерфейс можно настроить под себя, добавляя новые сценарии или импортируя созданные другими пользователями.

Если вы очень торопитесь и хотите распознать документ максимально быстро, можно использовать ещё одну новую функцию – чёрно-белый режим распознавания.

Разумеется, в этом случае за скорость придётся заплатить возможной потерей качества, но мы постарались сделать так, чтобы цена не была слишком высокой.
Всё описанное выше, кроме изменений функций в окне «Новая задача», относится к двум версиям – ABBYY FineReader 11 Professional Edition и ABBYY FineReader 11 Corporate Edition. В корпоративной версии в режиме редактирования можно применить функцию удаления конфиденциальной информации – она помечается и при экспорте удаляется.

Для пользователей корпоративной версии мы подготовили ещё и бонус – программу ABBYY Business Card Reader. Многие из вас уже знакомы с мобильной версией этой программы, теперь она переехала и на десктоп. Отсканировать визитку и загрузить данные в Microsoft Outlook с распределением данных контакта по соответствующим полям можно одной кнопкой, используя предопределенный сценарий работы. Конечно, если необходимо, данные можно проверить и отредактировать.

Отдельно хочется сказать о работе с языками. У нас наконец-то появилось распознавание арабского языка, причём качество – на уровне конкурентов, а то и выше. Арабский OCR клиенты у нас давно просили, так что получите – распишитесь. Кроме этого, FineReader научился распознавать туркменский (латиница) и вьетнамский. Появилась словарная поддержка для арабского, вьетнамского, японского, двух вариантов корейского и латыни.
Ещё мы стали быстрее распознавать документы на некоторых азиатских языках: скорость распознавания корейского увеличилась аж на 30% без потери в качестве, японского – на 10%. Наши ребята довольно долго отслеживали, «тонкие места» с помощью разных профайлеров (помимо доморощенных счётчиков-таймеров использовались интеловский VTune и AQTime от AutomatedQA Corp). Такого, чтобы магическим взглядом найти место в коде, которое можно переписать и впятеро ускорить программу у нас по счастью не случалось, а про неделю потраченного времени и ускорение на два процента писать как-то не с руки, так что оставим тему, что там поменяли.
Мы рассказали вам об основных изменениях в новой версии FineReader, которую уже сейчас можно купить в нашем магазине. Хотите узнать больше — читайте подробнее на сайте ABBYY.
Трое желающих написать обзор уже отметилось в комментариях. Скоро на Хабре!
