В 2021 году Huawei делает ставку на дальнейшее развитие корпоративных ADN-сетей. Что это за зверь, коротко обрисуем в этой статье по итогам доклада с прошедшего в конце 2020 года онлайн-форума Worldwide IP Club — сообщества, которое мы создали для обсуждения инноваций и для нетворкинга в телекоме.

Чтобы разобраться с Huawei Enterprise ADN, полезно будет сперва сделать краткий экскурс в те вызовы, с которыми сталкиваются корпоративные сети в наши дни.
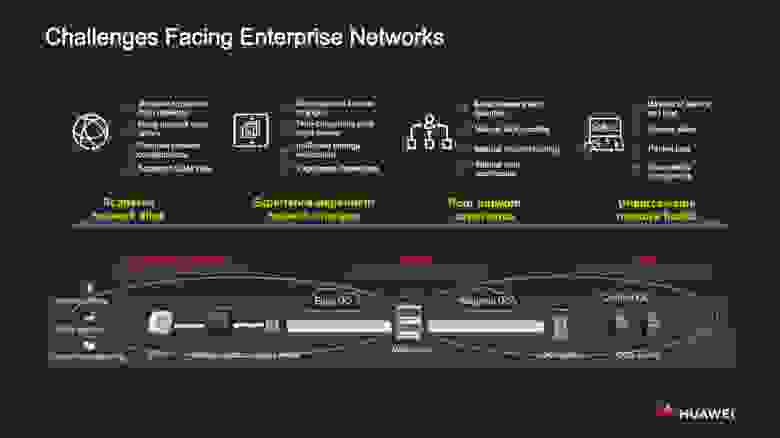
Сомнений нет, цифровая трансформация не обойдёт ни одну крупную организацию. И без достойной инфраструктурной опоры процесс этот немыслим. Чтобы отвечать требованиям цифровизации, корпоративная сеть должна быть надёжной, гибкой, масштабируемой.
У такой сети две основные части — сеть доступа и опорная сеть. На вышеприведённой схеме слева от региональной точки размещения оборудования располагается как раз таки сеть доступа, призванная обеспечивать подключение корпоративным кампусам, филиалам, внешним структурам, IoT-средам и т. д. Справа отображены межрегиональные и «межоблачные» соединения (interconnection).
Хотя фундаментально архитектура простейшая, на практике, как правило, приходится иметь дело с огромной разнородной сетью на базе оборудования разных вендоров. Затраты на его эксплуатацию и обслуживание подчас ощутимо превышают расходы на его покупку. Вот четыре главных «отягчающих обстоятельства», которые усложняют жизнь проектировщикам и администраторам современных корпсетей.
I. Разрозненность ресурсных ёмкостей (network silos), из-за которой сервисы оказываются отъединены от сетевой инфраструктуры, возникает неразбериха с чересчур многочисленными сетевыми задачами, конфигурация самой сети переусложняется, а O&M теряет эффективность.
II. Высокая степень гетерогенности сетей, с их пёстрым парком
оборудования. Отсюда вытекает множество трудностей, включая зависимость благополучной работы инфраструктуры от опыта отдельных экспертов, длительные циклы решения проблем, неэффективность проверок, а также ошибки, порождаемые необходимостью выполнять порядочную часть операций вручную.
III. Разделённость сервисов бизнес-уровня и сетевой инфраструктуры. В результате невозможно полноценное функционирование NaaS (Network as a Service) ни в отдельной зоне, ни между зонами сети. Под шквалом бесчисленных метрик сетевой активности, предупреждений и логов администратор оказывается не в состоянии гарантировать в любой момент времени безукоризненно точную работу сервисов.
IV. Отсутствие сквозной визуализации сети и инструментария для её всестороннего анализа. Это подлинный бич тех, кто строит сети и управляет ими. Неисправности удручающе часто вскрываются непосредственно во время работы сервисов, с ними успевают столкнуться пользователи, поскольку их не получается оперативно обнаружить и устранить.
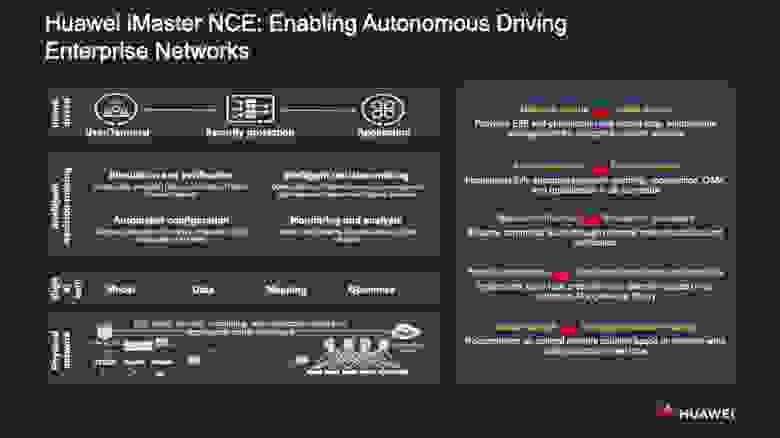
Чтобы справляться с перечисленными проблемами, Huawei создала решение на основе концепции сети с автономным управлением (autonomous driving network — ADN), именуемое iMaster NCE. В него заложена функциональность «цифрового двойника», end-to-end анализа намерений (более подробно о концепции intent-driven network мы уже писали на Хабре), а также технология интеллектуального принятия решений.
С помощью ADN, таким образом, удаётся осуществить пять важных преобразований.
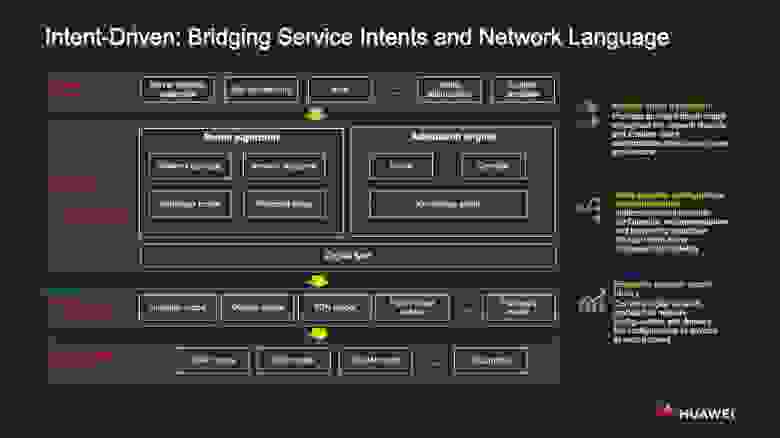
Главное же в модели анализа намерений (intent-driven) — перевод бизнес-запросов пользователей на сетевой уровень. У процесса выделяются три значимые составляющие.
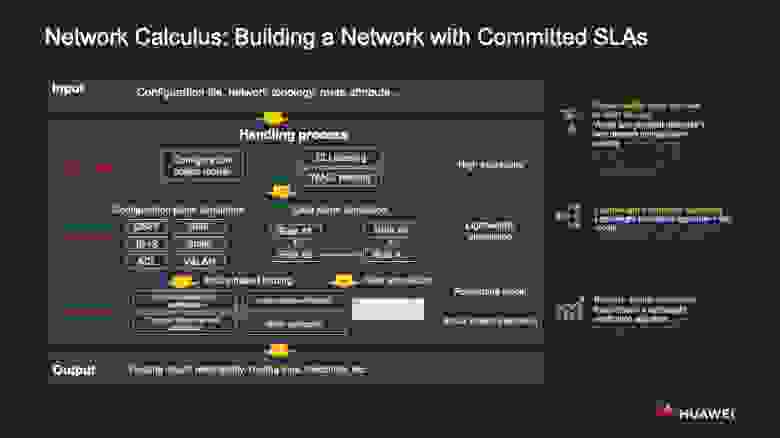
Давай обратимся к моделированию происходящего в сети, к тому, на какие сценарии он рассчитан и за счёт чего с его применением гораздо проще становится строить сети с поддержанием гарантированного уровня сервиса (SLA).
По сути, мы моделируем сетевую конфигурацию, ресурсы и систему переадресации, чтобы создать виртуальную сеть, которая будет отражать характеристики и специфику функционирования сети исходной, реальной.
При работе с виртуальной сетью мы прибегает к формальному доказательству — математическому методу, который позволяет удостовериться, отвечает ли сеть критериям SLA, таким как стабильное обеспечение сетевых соединений, непрерывная маршрутизация, правильно настроенная переадресация, непротиворечивость политик, уровни задержек и допустимых потерь пакетов и т. д.
Бегло пройдёмся по базовым сценариям применения метода.
Вкратце — сетевой анализ осуществляется в такой последовательности.

После того как все эти шаги сделаны, в дело вступает ранее упомянутая технология интеллектуального активного мониторинга. Она призвана цифровизовать всю сетевую инфраструктуру таким образом, чтобы сделать возможным комплексное управление её работой, поддержкой, оптимизацией и дальнейшим проектированием.
Пара примеров того, как это работает. Допустим, из какого-то бизнес-подразделения компании поступает сигнал о том, что у них «отвалился» доступ к приложению. Платформа iMaster NCE, прежде всего благодаря динамическому моделированию топологии сети, позволяет легко запросить и изучить в наглядном представлении все метрики, касающиеся приложения. Также благодаря навигатору маршрутизации удобно проследить на всех уровнях сети, откуда и куда шёл и идёт трафик, по принципу end-to-end — вплоть до конкретного физического устройства, например смартфона (проверяется досягаемость участков и элементов сети, петли и «чёрные дыры» маршрутизации и т. д.). В свою очередь, благодаря комплексной визуализации работы аналитического инструментария можно оперативно проверять, в порядке ли записи по конкретным устройствам в таблицах маршрутизации, а также мониторить уведомления, логи и записи об изменениях конфигурации. А с помощью рекомендованного службой RunBook решения (разумеется, администратор волен предпочесть поступить так, как сочтёт нужным) при необходимости быстро восстанавливается работоспособность составных частей сети и сервисов и устраняются неисправности в ней.
Другой сценарий — проверка состояния сети. Для этого используется модель с пятью уровнями контроля, на каждом из которых отслеживается свой срез инфраструктуры:
В фундаменте службы умного мониторинга лежат две технологии. Первая — ранее упомянутая система «цифровой двойник», которая опирается на виртуальное моделирование сетевой ситуации в реальном времени с применением больших данных, позволяющее с лёгкостью отслеживать причинно-следственные связи и находить источники затруднений. Критически важным для воплощения этой механики является наличие единой модели для воспроизведения жизненного цикла корпоративной сети.
Вторая — совокупность фронтенд- и бэкенд-решений, применяемых для построения высокоточной карты сетевой активности, которая как раз и строится на основе концепции «цифрового двойника». К фронтенд-части относятся интеллектуальный поиск, многоуровневая детализация аналитических сводок, навигация маршрутизации, комплексная система визуализации данных и т. д. Бэкенд — это в первую очередь движок для динамического воспроизведения сетевой топологии и система гибкого импорта сторонних сетевых моделей.

Работа умного мониторинга подкрепляется использованием интеллектуального метода анализа сетевой ситуации, основанного на графах знаний.
За счёт моделирования абстрактное описание сетевых элементов может быть преобразовано в конкретные запросы в плоскости объектной модели.
С помощью телеметрии отслеживаются сетевые KPI, потоки трафика на сервисном уровне, информация о конфигурации, логи сетевых событий — и с опорой на эти сведения алгоритмы машинного обучения на лету фиксируют отклонения от нормы и соотносят их с данными объектной модели.
Также платформа iMaster NCE предусматривает среду для безопасной отработки потенциальных последствий всевозможных сбоев: неполадки, которые имели место в других реально существующих сетях, «обкатываются» в симуляции данной конкретной сети. Таким образом, прибегая к совокупному опыту экспертов, ранее сумевших совладать с теми или иными нештатными сетевыми ситуациями, мы тренируем ML-модели, с тем чтобы они в дальнейшем более эффективно помогали преодолевать эксцессы — в том числе выявлять паттерны новых проблем и тем самым преумножать общее знание, доступное всем тем компаниям, которые используют iMaster NCE.

Ранее перечисленные технологии дают возможность администратору сети быстро обнаруживать неисправности. Однако интеллектуального анализа мало — важно помогать человеку принимать максимально эффективные решения по их преодолению, в чём и заключается самая суть ADN: теперь такие решения вырабатываются и претворяются в жизнь с непосредственной помощью ИИ.
Сбор намерений и проводимый на лету анализ данных о происходящем в сети, выработка решений, их внедрение и анализ последствий их принятия образуют замкнутый контур, который и делает возможным умное принятие решений. Залогом эффективности такой модели работы служат четыре фактора.
Инженеры Huawei продолжают совершенствовать ADN-решения, чтобы повышать степень «самостоятельности» сетевой инфраструктуры и её способности к «самовосстановлению», и мы непременно будем писать о новых разработках в этом направлении. А ознакомиться с решением iMaster NCE-Fabric вживую можно в нашем демооблаке с помощью пресейл-инженеров Huawei.

Чтобы разобраться с Huawei Enterprise ADN, полезно будет сперва сделать краткий экскурс в те вызовы, с которыми сталкиваются корпоративные сети в наши дни.
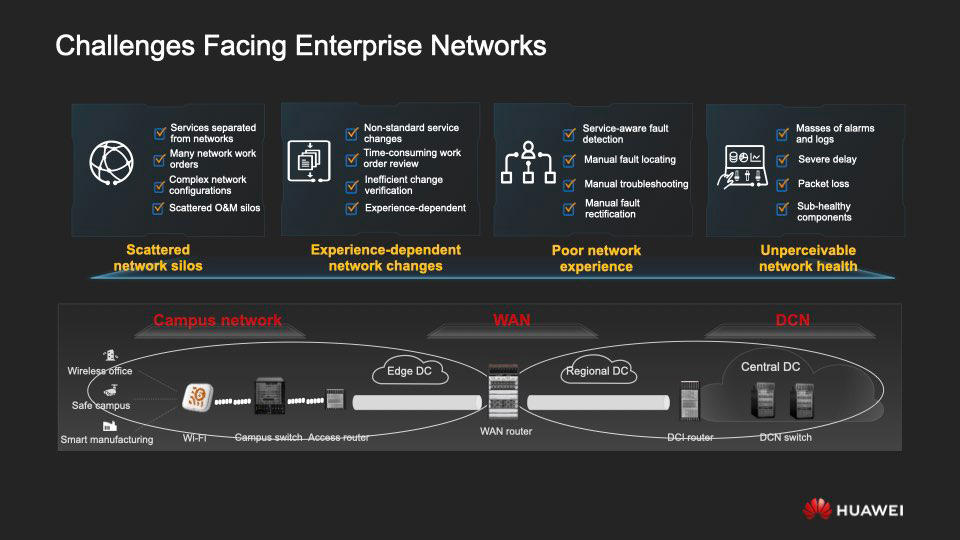
Сомнений нет, цифровая трансформация не обойдёт ни одну крупную организацию. И без достойной инфраструктурной опоры процесс этот немыслим. Чтобы отвечать требованиям цифровизации, корпоративная сеть должна быть надёжной, гибкой, масштабируемой.
У такой сети две основные части — сеть доступа и опорная сеть. На вышеприведённой схеме слева от региональной точки размещения оборудования располагается как раз таки сеть доступа, призванная обеспечивать подключение корпоративным кампусам, филиалам, внешним структурам, IoT-средам и т. д. Справа отображены межрегиональные и «межоблачные» соединения (interconnection).
Хотя фундаментально архитектура простейшая, на практике, как правило, приходится иметь дело с огромной разнородной сетью на базе оборудования разных вендоров. Затраты на его эксплуатацию и обслуживание подчас ощутимо превышают расходы на его покупку. Вот четыре главных «отягчающих обстоятельства», которые усложняют жизнь проектировщикам и администраторам современных корпсетей.
I. Разрозненность ресурсных ёмкостей (network silos), из-за которой сервисы оказываются отъединены от сетевой инфраструктуры, возникает неразбериха с чересчур многочисленными сетевыми задачами, конфигурация самой сети переусложняется, а O&M теряет эффективность.
II. Высокая степень гетерогенности сетей, с их пёстрым парком
оборудования. Отсюда вытекает множество трудностей, включая зависимость благополучной работы инфраструктуры от опыта отдельных экспертов, длительные циклы решения проблем, неэффективность проверок, а также ошибки, порождаемые необходимостью выполнять порядочную часть операций вручную.
III. Разделённость сервисов бизнес-уровня и сетевой инфраструктуры. В результате невозможно полноценное функционирование NaaS (Network as a Service) ни в отдельной зоне, ни между зонами сети. Под шквалом бесчисленных метрик сетевой активности, предупреждений и логов администратор оказывается не в состоянии гарантировать в любой момент времени безукоризненно точную работу сервисов.
IV. Отсутствие сквозной визуализации сети и инструментария для её всестороннего анализа. Это подлинный бич тех, кто строит сети и управляет ими. Неисправности удручающе часто вскрываются непосредственно во время работы сервисов, с ними успевают столкнуться пользователи, поскольку их не получается оперативно обнаружить и устранить.

Чтобы справляться с перечисленными проблемами, Huawei создала решение на основе концепции сети с автономным управлением (autonomous driving network — ADN), именуемое iMaster NCE. В него заложена функциональность «цифрового двойника», end-to-end анализа намерений (более подробно о концепции intent-driven network мы уже писали на Хабре), а также технология интеллектуального принятия решений.
- Принцип intent-driven. На протяжении всего жизненного цикла сети те, кто ею управляет, могут использовать простой WYSIWYG-инструментарий для того, чтобы держать её под полным своим контролем.
- Интеллектуальное принятие решений. Система упрощает человеку выбор оптимальных решений. Например, на этапе развёртывания сервиса она способна «подсказать» подходящие сетевые настройки и конфигурации, а при анализе проблем даёт возможность быстро найти первопричину неполадки и сама предлагает шаги по её устранению.
- «Цифровой двойник». В iMaster NCE включена функциональность многоуровневого моделирования и управления KPI инфраструктуры с опорой на большие данные, которая оперирует «виртуальными слепками» любых физических устройств, входящих в состав сети. При этом решение осуществляет двунаправленное картирование между сетью и её «двойником».
С помощью ADN, таким образом, удаётся осуществить пять важных преобразований.
- Упразднить «сетецентричный», пассивный подход к управлению инфраструктурой и заменить его таким, при котором проактивно анализируются намерения её пользователей, благодаря чему, в частности, удаётся нивелировать зависимость от специфики конкретной реализации сети. iMaster NCE развёртывает сквозную автономную оптимизацию сети по замкнутому циклу.
- Отказаться от автоматизации частичной, на базе жёстких предварительных настроек, в пользу автоматизации гибкой, завязанной на многоуровневом моделировании. В результате от и до автоматизируются проектирование и построение сети, O&M-процессы и дальнейшее совершенствование инфраструктуры.
- Перейти от ручных проверок к поддержанию устойчивой работоспособности сервисов с помощью интеллектуальных технологий. Модель в числе прочего предусматривает симуляцию последствий события до того, как оно произойдёт в действительности, равно как и окончательное подтверждение действий постфактум, с возможностью откатить изменения.
- Сделать шаг от «реактивного» управления сетью к интеллектуальному проактивному мониторингу и анализу изменений. Администраторы сети видят проблему в зачатке — ещё до того, как она повлияет на тот или иной сервис и её заметят пользователи, — и могут оперативно разобраться с ней.
- Заменить работу с опорой на человеческий фактор, преимущественно на опыт экспертов, применением модели, где преобладает принятие решений с помощью «умных» технологий, в том числе при проектировании сети, мониторинге, анализе и оптимизации сетевых взаимодействий

Главное же в модели анализа намерений (intent-driven) — перевод бизнес-запросов пользователей на сетевой уровень. У процесса выделяются три значимые составляющие.
- Формирование отвлечённой модели намерений (intent abstraction). В корпоративных сетях большая часть намерений относится к взаимодействиям между пользователями, конечными устройствами и приложениями. Как следствие, необходима модель, которая будет обобщать их требования на протяжении всего жизненного цикла сети и обеспечивать их кастомизацию, основанную на сценарном подходе.
- Преобразование намерений (intent conversion). Высокоуровневые бизнес-намерения необходимо спроецировать на сетевой уровень и в конечном счёте конвертировать в прикладные рекомендации. Эта трансформация достигается за счёт двух технологий.
- «Умные» рекомендации, основанные на алгоритмах моделирования, с учётом топологии сети и её ресурсов, поведенческих моделей, предпочтительных политик и пр., и адаптационном «движке», который включает в себя механизм поиска решений (solver), компилятор и граф знаний.
- Онлайн-проектирование на основе концепции «цифрового двойника». Платформа не только предлагает решение, но и предоставляет для его проверки и обкатки «песочницу» с наглядной симуляцией, которая позволяет довести это решение до ума.
- Не зависящее от вендоров хранилище сетевых моделей. Это базис для работы с намерениями и автоматизации сетевой инфраструктуры. Сюда входят:
- модели автоматизации корпоративной сети;
- вендор-независимые модели абстрактного описания сетевых элементов;
- сторонние модели (SDN, OVS и др.);
- модели, задаваемые пользователями.
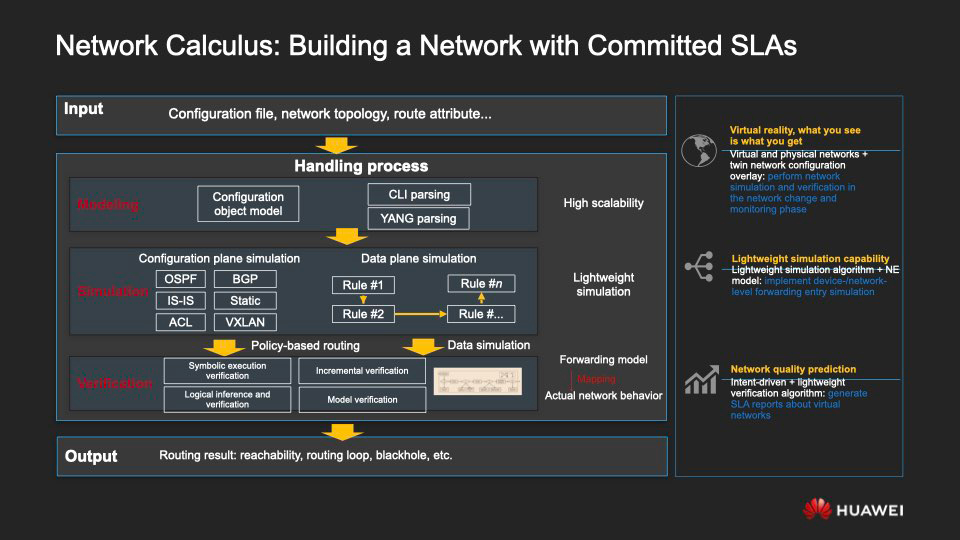
Давай обратимся к моделированию происходящего в сети, к тому, на какие сценарии он рассчитан и за счёт чего с его применением гораздо проще становится строить сети с поддержанием гарантированного уровня сервиса (SLA).
По сути, мы моделируем сетевую конфигурацию, ресурсы и систему переадресации, чтобы создать виртуальную сеть, которая будет отражать характеристики и специфику функционирования сети исходной, реальной.
При работе с виртуальной сетью мы прибегает к формальному доказательству — математическому методу, который позволяет удостовериться, отвечает ли сеть критериям SLA, таким как стабильное обеспечение сетевых соединений, непрерывная маршрутизация, правильно настроенная переадресация, непротиворечивость политик, уровни задержек и допустимых потерь пакетов и т. д.
Бегло пройдёмся по базовым сценариям применения метода.
- В ходе всестороннего end-to-end моделирования намерений решение заблаговременно проверяется на целесообразность, чтобы новые намерения не нарушили тех процессов, что уже проистекают в сети.
- После имплементации намерения в корпоративной сети проверяется, функционирует ли та, как ожидается, и отслеживаются риски всевозможных эксцессов — прежде чем те успеют повлиять на работу сервисов.
- Поведение виртуальной сети проверяется в сценариях с участием одной зоны, в межзональных, в гибридных (с использованием облачных ресурсов и т. д.), и она опять же может в автоматическом режиме полностью изолироваться от основной корпоративной сети.
Вкратце — сетевой анализ осуществляется в такой последовательности.
- На основе имеющейся сетевой топологии и информации о сетевых элементах строится управляющая модель виртуальной сети.
- Чтобы сгенерировать систему переадресации в виртуальной сети, используется симуляционная конфигурация.
- Задействуется метод формального доказательства, чтобы смоделировать поведение сети во всех аспектах, как то: конфигурация, распределение ресурсов, маршрутизация.
- Платформа алгоритмически предлагает рекомендации по внесению изменений в сеть.

После того как все эти шаги сделаны, в дело вступает ранее упомянутая технология интеллектуального активного мониторинга. Она призвана цифровизовать всю сетевую инфраструктуру таким образом, чтобы сделать возможным комплексное управление её работой, поддержкой, оптимизацией и дальнейшим проектированием.
Пара примеров того, как это работает. Допустим, из какого-то бизнес-подразделения компании поступает сигнал о том, что у них «отвалился» доступ к приложению. Платформа iMaster NCE, прежде всего благодаря динамическому моделированию топологии сети, позволяет легко запросить и изучить в наглядном представлении все метрики, касающиеся приложения. Также благодаря навигатору маршрутизации удобно проследить на всех уровнях сети, откуда и куда шёл и идёт трафик, по принципу end-to-end — вплоть до конкретного физического устройства, например смартфона (проверяется досягаемость участков и элементов сети, петли и «чёрные дыры» маршрутизации и т. д.). В свою очередь, благодаря комплексной визуализации работы аналитического инструментария можно оперативно проверять, в порядке ли записи по конкретным устройствам в таблицах маршрутизации, а также мониторить уведомления, логи и записи об изменениях конфигурации. А с помощью рекомендованного службой RunBook решения (разумеется, администратор волен предпочесть поступить так, как сочтёт нужным) при необходимости быстро восстанавливается работоспособность составных частей сети и сервисов и устраняются неисправности в ней.
Другой сценарий — проверка состояния сети. Для этого используется модель с пятью уровнями контроля, на каждом из которых отслеживается свой срез инфраструктуры:
- стабильно ли функционирует оборудование — в порядке ли платы, вентиляторы, блоки питания, процессоры, память и т. д.;
- нет ли проблем в соединениях между входящими в сеть физическими устройствами, в том числе в норме ли статусы портов и трафик, длина очередей и коэффициент оптического затухания, не слишком ли велик процент «битых» пакетов и пр.;
- работают ли агрегация M-LAG, маршрутизация посредством OSPF, BGP и др.;
- всё ли хорошо с наложенной сетевой инфраструктурой, включая текущие статусы BD, VNI, VRF, EVPN и SRV6;
- штатно ли осуществляется переадресация на уровне сервисов, и в частности каковы настройка TCP-соединения.
В фундаменте службы умного мониторинга лежат две технологии. Первая — ранее упомянутая система «цифровой двойник», которая опирается на виртуальное моделирование сетевой ситуации в реальном времени с применением больших данных, позволяющее с лёгкостью отслеживать причинно-следственные связи и находить источники затруднений. Критически важным для воплощения этой механики является наличие единой модели для воспроизведения жизненного цикла корпоративной сети.
Вторая — совокупность фронтенд- и бэкенд-решений, применяемых для построения высокоточной карты сетевой активности, которая как раз и строится на основе концепции «цифрового двойника». К фронтенд-части относятся интеллектуальный поиск, многоуровневая детализация аналитических сводок, навигация маршрутизации, комплексная система визуализации данных и т. д. Бэкенд — это в первую очередь движок для динамического воспроизведения сетевой топологии и система гибкого импорта сторонних сетевых моделей.

Работа умного мониторинга подкрепляется использованием интеллектуального метода анализа сетевой ситуации, основанного на графах знаний.
За счёт моделирования абстрактное описание сетевых элементов может быть преобразовано в конкретные запросы в плоскости объектной модели.
С помощью телеметрии отслеживаются сетевые KPI, потоки трафика на сервисном уровне, информация о конфигурации, логи сетевых событий — и с опорой на эти сведения алгоритмы машинного обучения на лету фиксируют отклонения от нормы и соотносят их с данными объектной модели.
Также платформа iMaster NCE предусматривает среду для безопасной отработки потенциальных последствий всевозможных сбоев: неполадки, которые имели место в других реально существующих сетях, «обкатываются» в симуляции данной конкретной сети. Таким образом, прибегая к совокупному опыту экспертов, ранее сумевших совладать с теми или иными нештатными сетевыми ситуациями, мы тренируем ML-модели, с тем чтобы они в дальнейшем более эффективно помогали преодолевать эксцессы — в том числе выявлять паттерны новых проблем и тем самым преумножать общее знание, доступное всем тем компаниям, которые используют iMaster NCE.
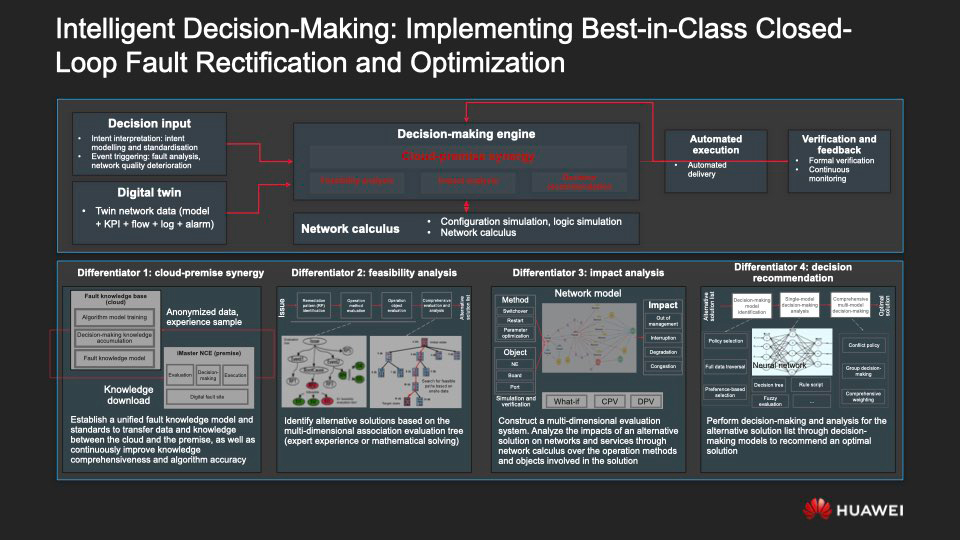
Ранее перечисленные технологии дают возможность администратору сети быстро обнаруживать неисправности. Однако интеллектуального анализа мало — важно помогать человеку принимать максимально эффективные решения по их преодолению, в чём и заключается самая суть ADN: теперь такие решения вырабатываются и претворяются в жизнь с непосредственной помощью ИИ.
Сбор намерений и проводимый на лету анализ данных о происходящем в сети, выработка решений, их внедрение и анализ последствий их принятия образуют замкнутый контур, который и делает возможным умное принятие решений. Залогом эффективности такой модели работы служат четыре фактора.
- Синергия между облачными ресурсам и тем, что находится во внутреннем контуре организации: мы располагаем единой моделью знаний о сетевых взаимодействиях и стандартами, которые позволяют передавать эти знания и данные между on-premise и cloud-частью гибридной инфраструктуры и далее совершенствовать ML-алгоритмы, на которых основан iMaster NCE.
- Анализ осуществимости решений. Многомерное дерево решений помогает подбирать максимально целесообразные альтернативные решения.
- Анализ влияния. Платформа умеет с высокой точностью прогнозировать результаты, которые способно повлечь за собой принятие тех или иных рекомендаций, применительно к сети в целом и к отдельным сервисам.
- Моделирование решений. Система подсказывает администратору оптимальный способ устранения неисправности.
***
Инженеры Huawei продолжают совершенствовать ADN-решения, чтобы повышать степень «самостоятельности» сетевой инфраструктуры и её способности к «самовосстановлению», и мы непременно будем писать о новых разработках в этом направлении. А ознакомиться с решением iMaster NCE-Fabric вживую можно в нашем демооблаке с помощью пресейл-инженеров Huawei.
