

Уже вышла Java 18, но для всех, кто сидит на LTS, по-прежнему остаётся актуальной версия 17. Такие люди могут не отслеживать постоянно фичи каждой новой версии, а спокойно заниматься своими делами и иногда навёрстывать сразу всё.
И как раз на такое «навёрстывание» рассчитан доклад Тагира Валеева (tagir_valeev), с которым он осенью выступил на нашем мероприятии TechTrain. Люди, которые в последние годы тщательно отслеживали все новинки в Java, тут особо много нового не узнают. Зато для остальных это удобный единый ликбез по главным вещам сразу нескольких версий: от запечатанных классов до того, почему молодёжь может зарофлить над вами из-за префиксов get и is.
Поэтому в преддверии нового TechTrain и Java-конференции JPoint мы решили сделать для Хабра текстовую версию доклада. В этом посте речь идёт о языковых фичах, а отдельно опубликуем часть про изменения в API. Далее повествование идёт от лица спикера.
Оглавление
Java Release Train и LTS-версии
Что нового в Java?
– Text blocks
– Switch Expressions
– Pattern matching for instanceof
– Records
– Sealed classes
– Pattern matching for switch
Привет! Давайте начинать. Я работаю в компании JetBrains, и в этой компании я занимаюсь поддержкой языка Java в IntelliJ IDEA. У нас, джавистов, недавно был небольшой праздник — вышла Java 17. Я вас всех поздравляю с этим. Хотя у многих может возникнуть вопрос: «В смысле, какая Java 17, недавно же была 8».
Есть люди, которые непрестанно следят за тем, что происходит на передовой Java и знают всё про возможности новых версий. Если это вы, то извините: вы и так слишком умные, мой доклад не для вас.
Если вы не особо следите за тем, что происходит в новых версиях, то я вам кое-что про это расскажу. Но сразу предупреждаю — это рискованно, потому что есть шансы, что вы загоритесь желанием обновить свой продакшен сразу до версии 17. Придёте в понедельник на работу, выкатите на прод апдейт Java, у вас всё сломается, и вас уволят. Будьте осторожны.
Java Release Train и LTS-версии
Вот раньше были времена, да? Java выходила раз в два, в три, а то и в пять лет. Можно было спокойно и не спеша знакомиться с новой версией и её возможностями, принимать взвешенное решение о переходе.
А теперь что? Раз в полгода новая версия! Куда они только прут? Только про 9 прочитали, уже люди говорят, что пришло время на 11 переходить. Пока думал, надо ли переходить на 11, вышла 14. Начал миграцию — тут уже 16 в дверь стучится.
Но в этом есть и хорошие новости. Во-первых, реально скорость разработки языка выше не стала. Теперь каждая новая версия просто гораздо меньше отличается от предыдущей и включает меньше фич.
Во-вторых, среди версий есть особенные, которые называются «long-term support». Это те, у которых у Oracle имеется долговременная поддержка. Мы знаем, что есть и другие поставщики Java, у которых может быть свой график поддержки, но в целом мир ориентируется на этот график.
Если не обращать внимание на версии, у которых нет долговременной поддержки, то выглядит примерно как раньше:

LTS-версии выходили раз в шесть версий (примерно раз в три года). Если вы не такой фанат Java, как я, то можно игнорировать все промежуточные версии и концентрироваться только на LTS.
Чтобы было понятнее, я сделал вот такой алгоритм определения:
boolean isLTS(int version) {
return version <= 8 || (version - 11) % 6 == 0;
}Я был доволен, а затем Oracle в лице Майкла Райнхольда объявили: что-то мы медленно едем. Теперь LTS у нас будут выходить раз в два года. Код пришлось переписывать — даже такой простой метод нужно поддерживать.
static boolean isLTS(int version) {
return version <= 8 ||
version <= 17 && (version - 11) % 6 == 0 ||
version > 17 && (version - 17) % 4 == 0;
}Как вы заметили, недавно вышла не просто версия Java, а LTS-версия, а таком случае вероятно массовое обновление с 11 на 17, игнорируя большинство промежуточных версий. Поэтому, если мы делаем доклад про плюшки Java 17, нас интересует всё то, что появилось в промежутке между 11 и 17.
Что нового в Java?
В Java происходит много всего крутого, но обо всём мы поговорить не успеем. Я люблю говорить про производительность, у меня даже была пара докладов из серии «маленькие оптимизации». В них как раз можно узнать, что интересного происходило в промежутке между Java 11 и Java 17.
Но сегодня мы поговорим о новых крутых языковых фичах Java.
Напомню, что все серьёзные изменения в Java, — будь то язык, виртуальная машина или стандартные библиотеки, — создаются в рамках процесса, который называется JEP (JDK Enhancement Proposals), то есть предложения по улучшению JDK. JEP-ы появились во времена Java 8, и это довольно открытый процесс: за ним можно наблюдать и в нём даже можно участвовать.
Если предложение серьёзно рассматривается, оно получает свой коротенький номер и отображается на соответствующей странице. Нумерация JEP начинается с сотни (кроме некоторых информационных). Сейчас номера перевалили за 400, и хотя речь про «улучшения» («enhancements»), имеется немало JEP-ов, которые что-то удаляют. Скажем, JEP 407 удаляет RMI Activation (думаю, всем наплевать, и никто уже не пользуется этим), а JEP 411 помечает Security Manager как deprecate (а потом наверняка последует JEP с удалением). Вот такое «улучшение», которое затронет использующих Security Manager. Хотя для разработчиков JDK действительно улучшение: меньше кода — меньше багов и тормозов.
У JEP-ов есть набор статусов, и если JEP появился, это ещё не значит, что он когда-то будет реализован. Так как программисты очень любят рекурсию, работа над JEP — это тоже JEP, с номером 1. Там описаны все статусы и работа над статусами, а я собрал их вот в такой граф:
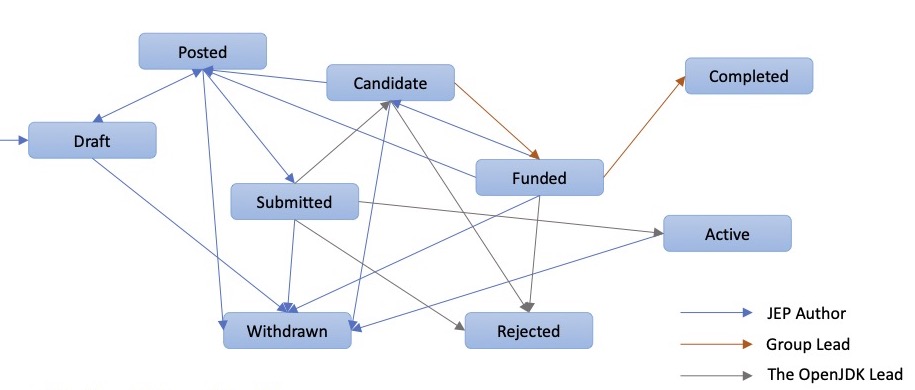
Мне кажется, что в реальности процесс отличается, потому что у программистов документация никогда не соответствует реализации, так что это просто красивая картинка с кучей стрелок.
Говоря о новых фичах джавы, обязательно стоит упомянуть так называемые превью-фичи (Preview Features). Суть превью-фич тоже описана в отдельном JEP-е. Мы любим Java за обратную совместимость: если в языке что-то появляется, то оно не меняется несовместимым образом и не исчезает совсем. Но это накладывает большие ограничения на дизайн новых фич. Если фичу сделали, её нельзя поменять, даже если сделали плохо. А как узнать, хорошо или плохо сделали, если фичей никто не успел воспользоваться до того, как её сделали?
Чтобы было время воспользоваться и переделать, придумали превью-фичи. Если новая фича находится в статусе превью, это значит, что она полностью сделана, полностью специфицирована и работает, но разработчики оставляют за собой право менять её (и зачастую действительно меняют) или вообще уничтожить (а вот такого ещё ни разу не случалось).
Чтобы воспользоваться превью-фичей, нужно включить опцию компилятора --enable-preview, а также явно указать релиз опцией --release. При этом, например, если у вас компилятор Java 17, то и релиз должен быть ровно 17. Кроме того, если вы используете превью фичу, то у вас будет предупреждение компилятора, которое вы не сможете подавить.

Но и это ещё не все. Если вы компилируете с флагом —enable-preview, то у результирующих .class-файлов прописывается особый номер версии. Такие класс-файлы виртуальная машина может загрузить только с опцией --enable-preview. При этом она не может загрузить файлы, сделанные для другой версии виртуальной машины.
Сделано это всё для того, чтобы не было нежданчиков, потому что превью-фича имеет право работать по-разному. Одна и та же программа на разных уровнях превью может иметь разное поведение.
IDEA, конечно, старается упростить вам жизнь по максимуму: вам надо всего лишь указать уровень превью в настройках проекта, и все опции компилятору и виртуальной машине IDEA передаст сама. Более того, обычно для этого даже в опции лезть не нужно.

Вот к примеру: у меня есть проект в Java 17, в нём выключено превью. Но в моём проекте есть превью-фича patterns in switch, о которой мы ещё поговорим сегодня. Стоит мне попытаться ею воспользоваться, как IDEA скажет: «Ой эта фича не поддерживается, но её можно включить». Вы просто нажимаете Alt + Shift + Enter, и у вас всё настраивается само.
Но! При первом использовании экспериментальной фичи IDEA выдаёт вам вот такое сообщение:

Видели когда-нибудь такое? Многие думают, что это какая-то юридическая ерунда, и нажимают Accept, не читая. А на самом деле зря. Здесь написана очень важная вещь — for testing and evaluation purposes only. Это означает, что не надо тащить эти превью-фичи в свой кровавый энтерпрайз.
Ещё вы можете увидеть такую всплывашку, где написано, что новые версии IDE могут убрать поддержку превью-фич старых версий. Это тоже очень важно.

Мы не поддерживаем все превью-уровни всех старых версий, обычно только на 1-2 версии назад, потому что это сопряжено с ненужными трудностями: например, в разных версиях может быть совершенно несовместимый синтаксис. Кроме того, превью-фичи ведь созданы для того, чтобы вы их попробовали и отправили фидбек разработчикам Java, чтобы они успели что-то исправить, если сделано плохо. А какой может быть фидбек, если с тех пор прошло три версии, и фича потеряла статус превью? Как-то поздновато для фидбека.
В итоге люди не читают, с чем соглашаются, берут превью-фичи в продакшен, потом выходит новая версия IDEA, где старые превью не поддерживаются, люди идут к нам жаловаться. Вот наш типичный тикет на этот счёт:

А мы их закрываем, «works as intended». Если вы начали пользоваться record-ами в Java 14 как превью-фичей, а уже вышла Java 16, будьте добры, обновитесь или перестаньте использовать records.
Я нарисовал все 6 превью-фич, которые на данный момент увидели свет:

Первая появилась в Java 12, и это были switch expressions. Интересно, что каждая превью-фича была в статусе превью ровно два релиза Java, или один год. Про это даже немного написано в JEP 12, что два релиза для превью — это норма. Поэтому если, например, pattern matching for switch появился в Java 17 в качестве превью-фичи, то в целом можно ожидать, что в Java 19 он войдёт в релиз. Или не войдёт. Мы не знаем.
Начиная с версии 12, все новые фичи именно языка Java сперва появлялись в режиме превью. Поэтому всё, что вы видите на картинке выше, — это всё, что происходило в языке. И мы с вами просто пойдём по этим пунктам.
Text blocks
Давайте отклонимся от хронологического порядка и сперва поговорим про блоки текста. Эта фича довольно независима от остальных, которые являются частью общей истории. А это — довольно обособленная штука, которую окончательно выпустили в Java 15.
public class Demo {
public static void main(String[] args) {
String query = """
SELECT DISTINCT s.name FROM conferences c
JOIN speaker2conf sc ON sc.conf_id = c.id
JOIN speakers s ON sc.speaker_id = s.id
WHERE EXTRACT(YEAR FROM c.start_date) = 2021""";
}
}Наконец-то в Java можно писать многострочные строковые литералы. Если кто-то пишет сырой HTML или SQL внутри Java-программ, то вам будет хорошо. Правила довольно простые, хотя они отличаются от других JVM-языков (таких как Groovy или Kotlin). Синтаксически решение позаимствовано из Swift, так что если вы на нём писали, вам будет привычно.
В первой строке у вас только три двойных кавычки (то есть шесть одинарных), и после них нельзя ничего писать — мы сразу же переходим на новую строчку. Дальше идёт текст литерала, и заканчивается он тоже тремя двойными кавычками.
У этого есть важное следствие. Так как мы завершаем строчку тройной двойной кавычкой, то мы можем не экранировать слешами одну двойную кавычку (и даже две). Например, если вы хотите кусок Java-программы вставить в Java-программу, то он вполне прилично выглядит:
public class Demo {
public static void main(String[] args {
String helloProgram = """
public class Hello {
public static void main(String[] args) {
System.out.printIn("Hello World!");
}
}""";
}
}Другой суперский момент: шесть пробелов в начале строки здесь на самом деле частью строки не являются.
В литерале ищется самый левый непробельный символ в каждой строчке, считается количество пробелов перед ним, и ровно столько пробелов удаляется из каждой строки. В итоге содержание строки не меняется, если вы переносите её в более вложенный блок или просто переформатируете программу с другой величиной отступа. Литерал выглядит красиво в исходнике, вам не надо его принудительно прижимать к левому краю.
А самое главное, что всё это делается во время компиляции, то есть никаких накладных расходов в рантайме.
Скажем, для аналогичного эффекта в Kotlin вам пришлось бы вызывать .trimIndent(), который вообще-то далеко не бесплатный, плюс надо не забыть его вызвать (хотя начиная с Kotlin 1.3.40, компилятор умеет от него избавляться). Так что видите, Java лучше Kotlin, переходите на Java!

Кстати, в случае с Java IDEA рисует вам дополнительную вертикальную полоску в текстовых блоках, по которым можно увидеть, что пробелы слева от неё обрезаются, а справа уже нет.
Ещё одна хорошая фича: если вы вдруг хотите сделать просто одну длинную строчку, и перевода строк в ней нет, то, чтобы она прилично выглядела в исходниках и не уезжала далеко вправо, мы можете ставить завершающий слеш, который будет значить, что строка продолжается дальше.
public class Demo {
public static void main(String[] args) {
String placeholder = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt \
ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco \
laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in \
voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat \
non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.""";
}
}При этом префиксы из пробелов продолжают обрезаться. Красота.
Но, конечно, людям что ни дай, они всё равно недовольны. Говорят, ну ладно, многострочные литералы сделали — а параметризовать эти литералы как? Параметризуемые строки-то не сделали.
Действительно, не сделали, но некоторые улучшения есть и тут. Раньше был статический метод String.format, а теперь появился аналогичный instance-метод .formatted.
public class StudentsDTO {
private Connection conn;
public void addStudent(String name, int grade) throws SQLException {
String query = """
INSERT INTO Students(grade, name)
Values(%d, '%s')""".formatted(grade, name);
conn.createStatement().execute(query);
}
}
String name = "Robert'); DROP TABLE Students;--";
int grade = 1;
addStudent(name, grade);Можно писать многострочный text block, потом добавлять .formatted() и указывать все параметры, которые мы туда подставляем. Получается надёжный красивый код, которым вполне можно пользоваться в продакшене.
Но шутки в сторону. Внезапная новость произошла буквально на днях. Эксперты проекта Amber выложили новый дизайн-документ о шаблонизации строк в Java. Если следовать этому документу, то в будущем мы сможем писать вот так:
public class StudentsDTO {
private Connection conn;
public void addStudent(String name, int grade) throws SQLException {
Statement statement = conn."""
INSERT INTO Students(grade, name)
VALUES(\{grade}, \{name})""";
statement.execute(query);
}
}
String name = "Robert'); DROP TABLE Students;--";
int grade = 1;
addStudent(name, grade);И это не просто возможность действительно параметризовать строку, чтобы прямо внутри неё вставлялись переменные. Здесь объект Connection может сам обрабатывать вставки по своему усмотрению. Это не просто конкатенация, а значит, он может добавить всё необходимое экранирование и уберечься от SQL-инъекций. Результатом необязательно будет строка, это может быть и statement, что удобно.
Обращаю ваше внимание, что эта штука исключительно в ранней стадии, неизвестно, когда это будет, в какой форме и будет ли вообще.
А вот с чем текстовые блоки нам не помогли, так это с регулярными выражениями. Как требовалось удваивать обратный слеш, так и требуется:
String myRegexp = "(\\w+)\\\\(\\w+)";
String myRegexpTextBlock = """
(\\w+)\\\\(\\w+)""";Тут даже не знаю, что посоветовать. Либо пишите на Kotlin, либо не используйте регулярные выражения, либо страдайте дальше.
Switch expressions
Идём дальше. Switch expressions были окончательно стандартизованы в Java 14. Это целое семейство фич, связанных с прокачкой switch.
Вот предположим, что у нас обычный старомодный многословный switch:

Давайте посмотрим, что с ним можно сделать. Шаг номер 1, самый простой: можно склеивать несколько подряд идущих кейсов через запятую, не повторяя слова кейс.

Одну строчку выиграли, красота.
Шаг номер 2, куда интереснее. Вместо старого синтаксиса с двоеточиями мы можем использовать новый синтаксис со стрелками:

Похоже на лямбды, но это не лямбды. Обратите внимание, что в варианте со стрелками мы можем забыть про break как про страшный сон, потому что одна ветка со стрелками никогда не проваливается в другую ветку. Я ненавижу break в switch, и думаю, я не один такой. К счастью, наступает светлое будущее, и если вы мигрируете на новую Java, вам становится хорошо.
Но это все ещё switch statement. Мы можем превратить его в switch expression.

Это третий шаг. Теперь switch используется как выражение, у которого есть возвращаемое значение. Мы можем не присваивать переменную в каждой ветке, а присвоить её один раз в инициализаторе. Понятно, что в конце, после фигурной скобки, нам нужна точка с запятой — в данном случае она указывает конец объявления переменной. Всё это просто объявление переменной legs.
В данном случае возможен ещё и четвёртый шаг. У expression обязательно должно быть значение. Что бы ни пришло в switch в качестве входного выражения, мы должны это обработать и вернуть что-то на выходе, или в крайнем случае кинуть исключение.

Но здесь нам пришло на вход enum-значение, и компилятор видит, что все четыре варианта enum мы уже перебрали, а это значит, что дефолтную ветку писать не обязательно, потому что компилятор может вставить её в байткоде автоматически. Это может потребоваться, если вы компилируете enum отдельно и добавляете новое значение. Тогда та дефолтная ветка выполнится, и у вас вылетит exception.
В итоге мы имеем пять строчек кода вместо 15. Плохие новости для тех, кому платят за строчки.

Что ещё интересного тут есть? Давайте посмотрим, что может быть справа от стрелочки.
Тут оказывается целых три варианта:
int legs = switch (pet) {
case DOG, CAT -> 4;
case PARROT -> {
System.out.printIn("Попка-дурак!");
yield 2;
}
case GOLDFISH ->
throw new IllegalArgumentException("Ноги у рыбов?! Красивое…");
};Это может быть просто выражение, например, число 4. Тогда его результат просто возвращается наружу switch.
Это может быть блок. И это новая штука для Java, потому что у вас внутри expression появляется возможность писать любые statement (if, for, while, try-catch…). Единственное ограничение — вы не можете изнутри этого блока сделать прыжок наружу. Вы не можете сделать return из вышестоящего метода или break из вышестоящего цикла, вы можете только прыгать внутри этого блока и кидать исключения. В конце этого блока вы обязаны вернуть значение, и решили делать это с помощью yield statement — вы пишете полуключевое слово yield и указываете то значение, которое вы возвращаете.
Вы можете писать throw. Можно было бы обернуть его в блок и вернуться ко второму способу, но именно для throw решили сделать сокращение, заворачивать его в блок необязательно.
Кстати, добавление ключевых слов — это очень больно, потому что можно сломать текущие программы. Поэтому приходится идти на странные компромиссы.

Например, вот это была вполне корректная программа до Java 14, а теперь уже нет. Объявить метод с именем «yield» всё ещё можно, но вы не можете вызвать этот метод просто так, без квалификатора, потому что синтаксический разбор воспринимает это как тот самый новый оператор yield и начинает ругаться: что это ваш yield не в switch.
Чтобы вызывать такие методы, надо обязательно указывать квалификатор: например, имя класса или слово this:

Ну да, а кому сейчас легко?
Кстати, если вы не готовы прямо сейчас переходить на более новую версию Java, то стоит подумать о будущем — когда-нибудь ведь перейдете. У нас в IDEA есть инспекция, которая называется forward compatibility. Она старается вас заранее предупредить, какой код сломается, если вы когда нибудь в будущем перейдёте на новую версию. Есть смысл поглядывать, не выдаёт ли она предупреждений на вашем коде, и вовремя их исправлять.
Pattern matching for instanceof
Идём дальше. Pattern matching for instanceof стандартизована в Java 16. Если вкратце, то можно делать вот так:

После всем знакомого instanceof вы пишете новую переменную, и эта переменная заводится автоматически. String s или LocalDate date — это то, что называется модным словом pattern. Это позволяет не просто сопоставить значение obj с каким-нибудь типом, но и определить новую переменную. Достаточно красиво и естественно для тех, кто много лет пишет на Java. Раньше в таких случаях мы упоминали тип три раза (сначала в instanceof, потом при объявлении переменной и при касте в неё), с Java 10 и var стало можно сократить до двух, но всё равно это лишняя церемония.
Новый более компактный способ написания выглядит симпатично, но за этим стоят интересные побочные эффекты. Например, становится сложнее понять, где у нас определена эта самая новая переменная, которую мы ввели в instanceof. Можем ли мы вот так использовать переменную в цепочке условий сразу после instanceof?

По логике, можем, и да, это валидный код. Но у нас в IntelliJ есть такой рефакторинг, как invert if statement, то есть вы можете перевернуть ветки if и else и заменить условия на противоположные. Давайте так и сделаем:

Условия поменялись, «and» сменилось на «or», а поскольку у нас нет ветки else, то мы просто возвращаемся из текущего метода, а тело перемещается ниже.
Теоретически, программа не должна была сломаться, потому что это чисто механическое действие. Тогда получается, что переменной s можно пользоваться и уже после if, и внутри условия || s.isEmpty(). И это так, скоуп этой переменной или область её действия — это два разрывных куска: всё, что идёт после or, и всё, что идёт уже после всего if.

А вот в теле if это s не определено, потому что instanceof мог не пройти, когда мы попали в тело if, поэтому и s там пользоваться нельзя.
А вот если мы из тела if можем выйти, тогда s нельзя пользоваться и после if, потому что это означает, что на следующую строчку после if мы могли попасть и если условие выполнилось, и если не выполнилось:

В спецификации чётко прописано: чтобы переменная продолжала быть определённой после if, тело if должно завершиться выходом, исключением или чем-то ещё ненормальным.
Интересно, что если в каком-то месте вы пытаетесь воспользоваться переменной паттерна, а она там не действует, то ищется по соответствующим скоупам выше соответствующая переменная. Если бы у вас в текущем классе было бы поле с именем «s», то вы могли бы получить неожиданные эффекты, потому что вы могли бы где-то вместо паттерна случайно сослаться на поле. Так что лучше паттерны и переменные не называть так же, как у вас названы поля.
Интересный момент с паттернами — это то, что такой паттерн является полноценной локальной переменной.
@Target(ElementType.LOCAL_VARIABLE)
@interface LocalAnno{}
void printIfString(Object obj) {
if (obj instanceof @LocalAnno final String s){
System.out.printIn(s.trim());
}
}Во-первых, у него допустим модификатор final, а если не писать final, то переменную можно менять. Во-вторых, аннотации, допустимые для локальных переменных, можно использовать и на переменной паттерна. Не знаю, кому это надо, но это часть большой истории по унификации локальных переменных и паттернов.
С дженериками особых чудес не произошло, они как стирались, так и стираются. Вот такой код, например, абсолютно валиден:

Потому что приведение типов под капотом является проверяемым: виртуальная машина может проверить, является ли данный list — ArrayList, а параметризация у нас одинаковая, это легально.
А вот того, что больше хотелось бы, сделать совсем нельзя:

Вот этот код — это ошибка компиляции, потому что в рантайме мы не можем проверить, является ли тип элементов произвольного списка строками. В старой Java вы могли сделать приведение типов, и у вас появилось бы предупреждение, что это непроверяемое приведение типов. Но в итоге решили, что в instanceof такое прятать неразумно — если вы делаете странные вещи, синтаксический сахар вам не положен.
Records
Теперь про записи или рекорды (records). Они тоже окончательно стали стандартизованными в Java 16. Вот таким нехитрым способом вы получаете классный класс:
public record Point(int x, int y) {}Здесь у нас есть x и y — это компоненты записи, а вся штука в скобочках — это заголовок или record header. Давайте посмотрим, как бы выглядел эквивалентный класс в предыдущих версиях Java:

Тут ещё хуже, чем в switch expression, потому что мы превратили 40 строчек в одну, если вам платят за строчки, то это вообще ужасная новость. Для вас автоматически сгенерировали два поля и конструктор, в конструкторе эти поля присвоили, сделали вам getter-ы, которые возвращают значение, сделали equals(), hashCode() и toString(), и всё это произошло автоматом.
Но есть ряд особенностей, которые некоторым людям не нравятся. Во-первых, поля только финальные и нет setter-ов — вы не можете заставить запись сгенерировать нефинальные поля. После того, как подкрутили виртуальную машину, даже через reflection или Unsafe поменять их стало не так-то просто. Навтыкали подводных камней.
Во-вторых, в запись нельзя добавить дополнительные поля. Статические можно, а обычные нет. Даже если вы хотите просто кэшировать hashCode(), чтобы переиспользовать при повторных вызовах, вы не можете это сделать. Полное состояние записи описывается её компонентами, и ничем больше.
В-третьих, методы для чтения полей (или аксессоры) называются так же, как сами поля: никаких префиксов. Некоторых с этого больше всего бомбит: как же так, перечеркнули всю 25-летнюю культуру бойлерплейта! Get, is — столпы кровавого энтерпрайза, а теперь впали в немилость.
В-четвёртых, сам класс записи — финальный. Он неявно наследует абстрактный класс java.lang.Record. В этом плане он похож на enum: вы не можете унаследовать от записи и не можете унаследовать запись, вы можете только реализовать интерфейсы. Но в принципе и на том спасибо. В наше время интерфейсы имеют и дефолтные методы, и статические методы, и даже приватные. В общем, с интерфейсами можно жить.
В остальном записи можно кастомизировать: добавлять свои методы, переопределять любые генерированные методы своей логикой. Здесь ещё есть дополнительная интересная фича — это компактный конструктор.
В каждой записи есть канонический конструктор, сигнатура которого совпадает с сигнатурой самой записи. Если вы его не написали, то он генерируется автоматом. Но его можно написать и самостоятельно, например, чтобы валидировать: предположим, вас не устраивают отрицательные координаты. Добавили валидационный код и потом присвоили поля:
public record Point(int x, int y) {
public Point(int x, int y) {
if (x < 0 || y < 0) {
throw new IllegalArgumentException();
}
this.x = x;
this.y = y;
}
}Но есть способ лучше. Можно не писать сигнатуру конструктора и параметры в скобочках, потому что они все равно совпадают с хедером:

В этом случае компилятор автоматически добавит присваивание полей. Вы просто компактно сделали свою валидацию.
Предполагается, что записи соблюдают некоторые свойства:
- Неизменяемы.
- Всегда имеют канонический конструктор с параметрами, соответствующими компонентам.
- Всегда имеет аксессоры с именами, соответствующими компонентам.
- Две записи, сконструированные с одинаковыми параметрами, равны по equals и имеют равный hashCode.
- Если считать компоненты через аксессоры и создать из них новую запись, она будет равна исходной по equals и иметь такой же hashCode.
То есть это не просто синтаксический сахар, а семантически богатая штука. Понятно, что вы можете переопределить запись так, что свойства будут нарушаться, но это вы уже сами виноваты.
Хорошая запись эти свойства соблюдает, благодаря чему она, с одной стороны, полностью прозрачна: вы можете всегда разобрать её на составляющие без всякого грязного залезания в приватные поля, и собрать снова, потому что у публичной записи канонический конструктор и аксессоры тоже непременно публичные. С другой стороны, она безопасна, потому что если она правильно написана, то вы всегда можете добавить валидацию или защитное копирование в канонический конструктор или в аксессоры. Предполагается, что любой механизм сериализации или десериализации записей будет действовать через вызов аксессоров и канонического конструктора, без доступа напрямую к полям. Так что вы не сможете реализовать сломанный объект с нарушенными инвариантами.
Для этого прокачали рефлексию, через которую вы можете получить компоненты записи, получить объект нового класса RecordComponent и у него достать аксессор (через .getAccessor, ну да, всё-таки «get»).

В общем, можно получить модельную структуру записи. Специального метода для получения канонического конструктора, к сожалению, нет, но такой метод несложно написать вручную:

Мы берём компоненты, запрашиваем их типы, собираем в массив, и ищем конструктор с такими типами, всё просто.
Заметьте: раз у всех записей есть общий суперкласс Record, можно легко создать метод, в котором на входе принимать только записи.
Вы можете писать свой движок сериализации, который дружит с записями, этим всерьёз озаботился Jackson — теперь записи сериализуются в json и обратно в соответствии с их структурой. Самое главное, что они это сделали, ещё когда фича была в состоянии превью. Это тоже крутое преимущество превью-фич — к выходу Java 16 у вас уже есть готовые протестированные библиотеки, которые умеют сериализовать записи.
А что со стандартной Java-сериализацией, которая обычно вообще не вызывает конструкторов? Оказывается, для записей её специально прокачали: теперь она уважает их контракт. Чтобы сделать запись сериализуемой, нужно просто дописать implements Serializable, и ничего больше:
public record Point(int x, int y) implements Serializable {
public static void main(String[] args) throws IOException {
Point point = new Point(-1, -1);
var result = new ByteArrayOutputStream();
try (var oos = new ObjectOutputStream(result)) {
oos.writeObject(point);
}
System.out.printIn(Base64.getEncoder().encodeToString(result.toByteArray()));
}
}
r00ABXNyAAVQb21udAAAAAAAAAAAAgACSQABeEkAAXl4cP//////////Я убрал проверку на отрицательные числа и сериализовал точку с отрицательными координатами.
Потом мы пробуем эту строчку десериализовать:
public record Point(int x, int y) implements Serializable {
public static void main(String[] args) throws IOException {
Point point = new Point(-1, -1);
var result = new ByteArrayOutputStream();
try (var oos = new ObjectOutputStream(result)) {
oos.writeObject(point);
}
System.out.printIn(Base64.getEncoder().encodeToString(result.toByteArray()));
}
}
r00ABXNyAAVQb21udAAAAAAAAAAAAgACSQABeEkAAXl4cP//////////
public record Point(int x, int y) implements Serializable {
public static void main (String[] args) throws IOException, ClassNotFoundException {
var input = Base64.getDecoder()
.decode("r00ABXNyAAVQb21udAAAAAAAAAAAAgACSQABeEkAAXl4cP//////////");
try (var ols = new ObjectInputStream(new
ByteArrayInputStream(input))) {
Point point = (Point) ols.readObject();
System.out.printIn(point);
}
}
}
Point[x=-1, y=-1]Всё создаётся успешно, как и ожидалось.
А теперь мы возвращаем наш компактный конструктор и говорим «точки с отрицательными координатами нас не устраивают»:
public record Point(int x, int y) implements Serializable {
public Point {
if (x < 0 || y < 0) {
throw new IllegalArgumentException();
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
var input = Base64.getDecoder()
.decode("r00ABXNyAAVQb21udAAAAAAAAAAAAgACSQABeEkAAXl4cP//////////");
try (var ols = new ObjectInputStream(new
ByteArrayInputStream(input))) {
Point point = (Point) ols.readObject();
System.out.printIn(point);
}
}
}И что же? У нас в потоке точка с отрицательными координатами, как мы её создадим? А никак. Десериализация падает с исключением, и это классно:

Всё, как ожидалось: внутри есть специальный метод readRecord(), который эти записи обрабатывает. Десериализация обычных объектов всё ещё идёт в обход конструктора. Если бы это была не запись, то мы бы получили объект с нарушенным инвариантом, либо нам пришлось бы самим писать readObject(). А с записями все инварианты проверяются, и сериализация снова безопасна.
Кстати, записи исключительно полезны в качестве локальных или приватных классов для одноразового использования. Многие просили, чтобы в Java наконец-то сделали стандартные классы, типа «пара», «тройка», какой-нибудь tuple. К счастью, этого не сделали, но сделали записи, потому что они гораздо круче.
Например, у нас есть простая задача: мы хотим найти лучших клиентов по какому-то score, у нас есть метод calculateScore():
List<Customer> findTopScoredCustomers(List<Customer> allCustomers) {
return allCustomers.stream()
.sorted(comparing(customer -> calculateScore(customer), reverseOrder()))
.limit(10)
.toList();
}Кстати, ещё одно нереально крутое улучшение, которое появилось в Java 16 — это новый метод .toList() в Stream API. Теперь можно не писать collect(Collectors.toList()), а сократить. И это не просто сокращение: во-первых, он быстрее, чем коллектор, а во-вторых, он возвращает неизменяемый список. Ещё один повод проапгрейдиться.
Но вернёмся к записям. Предположим, что calculateScore() — это очень медленная функция. Если мы помещаем её внутрь компаратора, то для одного и того же клиента сортировка будет её вызывать несколько раз. Чтобы оптимизировать, нам бы сперва посчитать все score, потом отсортировать, используя посчитанные, а потом выкинуть score, потому что они нам не нужны. Нам бы тут пригодились пары, но их нет.
На самом деле, никто не мешает нам их создать:
List<Customer> findTopScoredCustomers(List<Customer> allCustomers) {
return allCustomers.stream()
.sorted(comparing(customer -> calculateScore(customer), reverseOrder()))
.limit(10)
.toList();
}
List<Customer> findTopScoredCustomers(List<Customer> allCustomers) {
record CustomerAndScore(Customer customer, double score) {}
return allCustomers.stream()
.map(c -> new CustomerAndScore(c, calculateScore(c)))
.sorted(comparing(CustomerAndScore::score, reverseOrder()))
.map(CustomerAndScore::customer)
.limit(10)
.toList();
}Мы создаём прямо внутри метода однострочную запись CustomerAndScore — попользоваться и выбросить. Перед сортировкой добавляем .map, после сортировки снова .map, достаём нужный компонент, и всё прекрасно работает. При этом у нас прямо на месте созданы говорящие имена, всё красиво и приятно.
Поэтому если у вас в проекте есть класс Pair, удалите его скорее. Не используйте пары от двух целых чисел, потому что никто не знает, что это, и можно случайно присвоить пары, которые имеют абсолютно разный смысл. А вообще-то сила Java — это сильная типизация. Вместо этого заводите однострочные записи и используйте там, где надо.

Для этого слайда я тоже создал пару в виде записи, потому что записи можно делать параметризованными или дженериками, тут никаких ограничений нет. Но всё равно так не делайте.
Вернемся к локальным записям. Вы же знаете, что локальные классы могут захватывать контекст? Переменные из окружающего метода? Вот здесь мы сделали в записи метод и используем args, то есть параметр метода main, который у нас снаружи.

Обычно это реализуется так: в классе создается скрытое поле, у конструктора создается скрытый параметр, и через этот параметр поле скрытым образом присваивается и потом используется. А как быть с записями? Мы же договорились, что у них не может быть полей, кроме тех, что соответствуют компонентам. Как этот код будет работать?
Ответ — никак. Такой код не компилируется. Записи всегда считаются неявно статическими, им запрещено захватывать какой бы то ни было контекст.
Но ведь статических локальных классов никогда не было. Как объявить запись во вложенном или анонимном классе? В них статики вообще не положено.
На самом деле, то, что в Java статическое нельзя было объявить в нестатическом — это абсолютно искуственное ограничение. Оно ничем не обусловлено, просто когда-то решили, что так программировать будет понятнее. Сейчас стало ясно, что зря ограничили.
Поэтому мало того, что вы статические записи можете объявить где угодно, вы теперь можете объявлять локальные интерфейсы, локальные enum, которые тоже становятся неявно статическими, и любые статические члены в нестатическом контексте.

Здесь у меня и enum внутри метода, и интерфейс внутри метода. Мы тот же интерфейс реализовали в качестве анонимного класса, в этом анонимном классе сделали статическое поле, статический метод, — все эти штуки были невозможны в Java 15, а в Java 16 — пожалуйста, невозможное возможно.
Sealed classes
Наконец мы подошли к функциональности, которая действительно была стандартизована ровно в Java 17, а не раньше — sealed classes или запечатанные классы.
До сих пор вы могли либо объявить класс final и полностью запретить наследование от него, либо не объявлять final, и тогда наследует, кто хочет. Теперь у нас появился более точечный контроль: вы можете разрешить наследование ограниченному специально объявленному списку подклассов. Других наследников быть не может.

Для этого надо, во-первых, добавить новый модификатор sealed, во-вторых, добавить такой список permits, которому мы разрешаем наследовать. Только тем классам, которые там перечислены, будет можно наследовать.
Список permits можно не объявлять, если все наши наследники объявлены в том же самом исходном файле, что и этот sealed class, например, в качестве вложенных классов или просто так.
При этом наследники sealed class обязаны явно указать свое отношение к дальнейшему наследованию.

Тут три варианта:
- либо это
final, тогда дальнейших наследников не предполагается - либо это
sealed, тогда задача сведена к предыдущей (в примере я не стал писатьpermitsдля собак, а в том же классе указал несколько наследников) - либо, если вы хотите сделать открытую подиерархию, чтобы наследовать мог кто угодно, вы должны написать ещё одно новое слово
non-sealed. В моём примере это значит, что я не забыл написать модификатор, а явно хочу, чтобы кошек мог наследовать кто угодно.
Если вы пишете permits, то наследники могут быть в другом файле, но должны быть в том же пакете. А если вы используете модули, которые появились в Java 9, то можно и в другом пакете, главное — в том же модуле.
Самое главное — это не просто сахар при компиляции. У sealed classes есть поддержка со стороны виртуальной машины. Даже в рантайме, с помощью какого-нибудь loadClass, вы не сможете сгенерировать нового наследника. Поэтому той иерархии, которую вы объявили, вы всегда можете доверять. Похожего эффекта раньше можно было добиться, если вы объявляли у класса конструктор типа private или package private: тогда наследовать этот класс было проблематично, потому что конструктор было трудно вызвать.
Однако у sealed class есть некоторое преимущество. Во-первых, можно объявлять sealed interface. С ними фокус с конструкторами не работал, потому что у интерфейсов нет конструкторов. Вы не могли создать интерфейс, которым пользователь может спокойно пользоваться, но не может создавать свои реализации. Теперь у вас есть такая возможность.
public sealed interface Pet permits Cat, Dog, Parrot, Goldfish {
…Во-вторых, список подклассов доступен рефлективно. Там тоже появились методы из sealed и getPermittedSubclasses(). Пока не очень понятно, зачем это может пригодиться, но виртуальная машина в курсе этой иерархии.
public static void main(String[] args) {
boolean sealed = Pet.class.isSealed();
if (sealed) {
Class<?>[] subclasses = Pet.class.getPermittedSubclasses();
System.out.printIn(Arrays.toString(subclasses));
}
}
[class Cat, class Dog, class Parrot, class Goldfish]В-третьих, для sealed class-ов есть более строгий анализ конвертируемости типов. Обычно любой интерфейс для нефинального класса компилятор проглатывает, потому что даже если этот класс не реализует этот интерфейс, всегда же может существовать подкласс, который всё-таки его реализует. Этот подкласс в том числе мог быть сгенерирован в рантайме.
А теперь, если у нас иерархия запечатана, то компилятор прямо при компиляции может пробежаться по всей иерархии и увидеть, что ни один из наследников не реализует этот интерфейс Runnable, а значит, этот instanceof заведомо бессмысленный, и тут будет ошибка компиляции.

А что будет в-четвёртых, я расскажу потом.
В некоторой степени records и sealed classes формируют алгебраические типы данных (как бы).
// Тип-сумма
sealed interface X0rY {}
// Тип-произведение
record XAndY(X x, Y y) {}
final class X implements X0rY {}
final class Y implements X0rY {}Sealed interface является типом-суммой над своими реализациями (либо X, либо Y), а record — типом-произведением для своих компонентов (X и Y). Это несколько ограниченно, так как для создания типа-суммы вы должны контролировать всех наследников: в тип-сумму, например, нельзя включить класс стандартной библиотеки.
Но зато вы можете включить один и тот же класс или интерфейс в несколько sealed-иерархий.
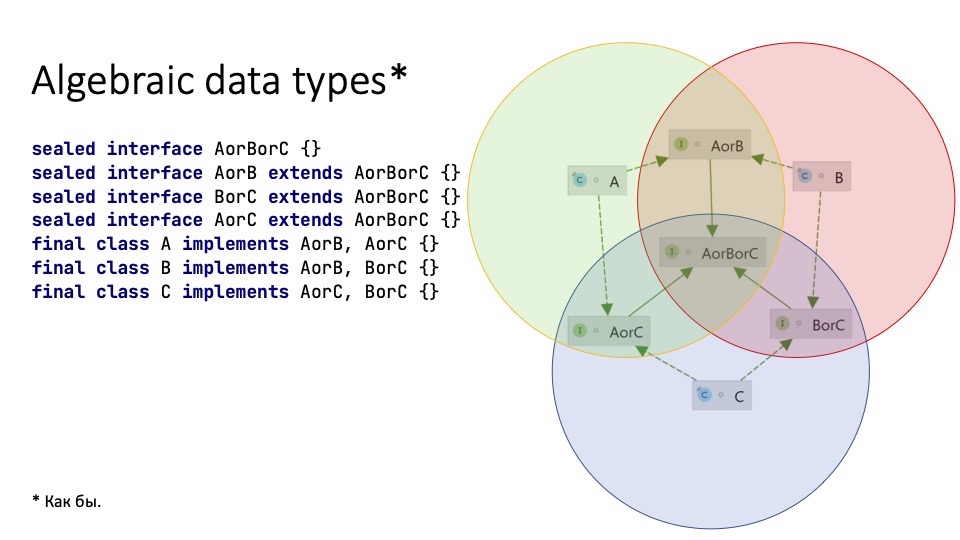
Тут ничего нельзя расширить. Java стала на полшага ближе к Haskell, ура!
Pattern matching for switch
И мы перешли к самой новой фиче, Pattern matching for switch. В Java 17 она появилась только в превью, так что в продакшен её тащить не стоит, но поиграться можно.
static String asString(Object value) {
return switch (value) {
case Enum<?> e -> e.getDeclaringClass().getSimpleName() + "." + e.name();
case Collection c -> "Collection [size = %d]".formatted(c.size());
case Object[] arr -> "Array [length = %d]".formatted(arr.length);
case String s && s.length() > 50 -> '"'+s.substring(0, 50)+"...\"";
case String s -> '"' + s + '"';
case null -> "null";
default -> value.toString();
};
}Обращаю внимание, что это первый цикл превью, в деталях фича наверняка ещё поменяется, поэтому если вы читаете эту расшифровку где-то в конце 2022 или 2023 года, будьте особо осторожны.
Благодаря этой фиче можно сделать switch почти по любому типу. В case-ветках вместо констант теперь можно указывать вместо паттерны — те самые, которые были в instanceof, но теперь в switch.
В примере мы пытаемся вывести произвольный объект в презентабельном виде, и у нас получается очень компактный красивый код.
Также появился новый тип паттернов — паттерны с guard, то есть с дополнительным условием. В условии может быть любое выражение — туда можно даже ещё один switch впихнуть, я проверял. Это позволяет нам писать более красивый код и превратить больше цепочек if в switch.
При этом в старых switch порядок веток особо не имел значения, потому что все ветки были взаимоисключающие. Здесь ветки могут быть не взаимоисключающими, поэтому компилятор идёт строго сверху вниз. Как только первая ветка удовлетворяет нашему условию, мы в неё заходим и все остальные ветки игнорируем. Как и раньше, выполняется всегда только одна ветка. Поэтому в примере выше второй случай String s не требует дополнительных условий: туда просто попадут все те строки, которые не попали под предыдущие условия.
Также наконец появилась возможность сделать свитчи, дружелюбные к null. Раньше они падали с NPE, теперь же можно явно написать case null, с которым падать не будет.
Большая ценность новых switch — они следят за ошибками, которые вы могли допустить. Например, вот такой switch не скомпилируется, потому что вы использовали более частный паттерн String s после более общего паттерна CharSequence:

Если вы пришли сюда со строкой, она пойдёт в CharSequence, потому что он выше. В таком случае паттерн String мёртв, вы в него никак попасть не можете. Компилятор это замечает и говорит, что у вас возможна ошибка. Даже статический анализатор не нужен, эту багу находит компилятор.
C дополнительными условиями аналогичная штука. Понятно, что условия императивные: не сравнишь, какое из них доминирует над другим. Но если у вас будет паттерн без дополнительных условий, а потом такой же паттерн с условием, то понятно, что во второй вы никогда не попадёте. Компилятор нас тут тоже наругает.

Ещё одна интересная штука: ветку с null можно прикрутить к любому одному паттерну. Тогда в соответствующей переменной паттерна придёт null.
static void testSwitch(Object value) {
switch (value) {
case null, String s -> System.out.printIn(s);
default -> {}
}
}В этом месте немного спорно сделано, и вопросы с null в принципе поднимали бурю комментариев, поэтому здесь ещё может что-то поменяться.
Ещё одна особенность новых switch — они обязательно должны быть полными, даже если это switch statement. Раньше мы выяснили, что switch expressions должны быть полными, а switch statements изначально полными не были. Теперь вам обязательно надо покрыть все возможные варианты и указать ветку default. Но для совместимости то, что работало раньше, продолжает работать и сейчас.

В первом кейсе мы сделали старый switch по строкам, это switch statement — обработали две строки, если придет третья, то ничего не произойдет. А вот если вы давали case null (как во втором случае), то это уже новый switch, ведь раньше такое писать было нельзя. В итоге этот switch не компилируется, потому что у нас нет ветки default. Нам нужно дописать что-нибудь такое:

Но мы помним, что дефолт указывать не всегда обязательно: если у нас switch по enum и покрыты все ветки, то можно не писать. Аналогичная штука появилась и с sealed-иерархиями, и это — то самое в-четвёртых, о котором я говорил раньше в блоке Sealed classes.
Давайте для примера замутим алгебраический тип с помощью записей и sealed classes.

Будем представлять простое синтаксическое дерево. У нас есть узлы дерева — это константы, операции сложения, операции умножения. Видите, как круто: мы в четыре строчки объявили целую иерархию классов. Вот она — стильная модная Java без всякого бойлерплейта. Записи, как мы помним, сами по себе финальные, final можно не писать, у нас иерархия полностью закрыта.
Предположим, мы хотим вычислять выражения, соответствующие этим деревьям, причём вычислять внешним образом, не засоряя сам класс логикой вычислений. Классическое решение, как учат в «Банде четырёх» — это Visitor.

Мы добавляем один метод accept в родительский интерфейс, определяем интерфейс Visitor и в каждой реализации вызываем соответствующий метод интерфейса. Написали кучу кода, но по факту ещё ничего не сделали, в духе старой Java. Сам вычислитель выглядел бы как-то так:
static int evaluate(Node node) {
return node.accept(new NodeVisitor<>() {
public Integer visitConst(Const c) {
return c.value();
}
public Integer visitPlus(Plus p) {
return evaluate(p.left()) + evaluate(p.right());
}
public Integer visit Multiply(Multiply m) {
return evaluate (m.left()) * evaluate(m.right());
}
});
}В таком Visitor есть преимущество: если появится новый тип выражений, то там надо будет расширить интерфейс NodeVisitor, и тогда мы увидим ошибки компиляции во всех точках, где Visitor используется. Нам придется их всех обновить, чтобы поддержать новое выражение. Но в целом Visitors — это страшное уродство. Они негибкие, тут ещё боксинг приходится делать, если возвращать нечего — писать return null.
Хотя старые учебники говорят, что instanceof — это не тру ООП, многие всё же предпочли бы писать вот так, без всяких Visitor, и я в том числе:
static int evaluate(Node node) {
if (node instanceof Const c) {
return c.value();
} else if (node instanceof Plus p) {
return evaluate(p.left()) + evaluate(p.right());
} else if (node instanceof Multiply m) {
return evaluate(m.left()) * evaluate(m.right());
}
throw new AssertionError("Unknown node type: " + node.getClass());
}Когда есть паттерны для instanceof, вообще красиво становится. Но тут есть опасность: появился новый вид выражений, компилятор вам ничего не сказал, и у вас в рантайме полетело исключение. Эту проблему как раз решают switch, которые обязаны быть полными.

Когда мы переписываем это все на switch, всё становится во-первых, компактней, а во-вторых, компилятор следит, что эта иерархия полностью закрыта. Дефолт можно не писать, а если появится новый наследник, то компилятор сразу начнёт ругаться. Круто!
(продолжение следует)
Это доклад с прошлогоднего мероприятия TechTrain, а мы уже вовсю готовим следующее: оно пройдёт 14 мая, бесплатно, онлайн. Программа и регистрация — по ссылке.
А для Java-разработчиков мы в июне проведём большую конференцию JPoint. И впервые за два года там будет не только онлайн, но и офлайн-день! Программа станет известна позже, а уже известные подробности и билеты — на сайте JPoint.
