
В этот раз я хочу поговорить о функции printf. Все наслышаны об уязвимостях в программах, и что функции наподобие printf объявлены вне закона. Но одно дело знать, что лучше не использовать эти функции. А совсем другое — понять почему. В этой статье я опишу две классических уязвимости программ, связанных с printf. Хакером после этого вы не станете, но, возможно, по-новому взгляните на свой код. Вдруг, вы реализуете аналогичные уязвимые функции, даже не подозревая об этом.
СТОП. Подожди читатель, не проходи мимо. Я знаю, что ты увидел слово printf. И уверен, что автор статьи сейчас расскажет банальную историю о том, что функция не контролирует типы передаваемых аргументов. Нет! Статья будет не про это, а именно про уязвимости. Заходи почитать.
Предыдущая заметка находится здесь: Часть первая.
Введение
Взглянем на вот эту строчку:
printf(name);
Она кажется простой и безобидной. А между тем, в ней скрывается как минимум два способа, чтобы атаковать программу.
Начнем статью с демонстрационного примера, где есть эта строчка. Код может показаться вам странноватым. Так оно и есть. Оказалось не так просто написать программу, чтобы потом её атаковать. Дело в оптимизации, которую производит компилятор. Получается, что если написать слишком простую программу, то компилятор создает такой код, что ломать там нечего. Он использует регистры, а не стек для хранения данных, встраивает функции и тому подобное. Можно написать код с лишними действиями и циклами, чтобы компилятору не хватило свободных регистров, и он начал помещать данные в стек. К сожалению, пример получается слишком большой и запутанный. Про всё это можно написать отдельную детективную историю, но не будем.
Представленный пример является компромиссом между сложностью и необходимостью не дать компилятору «схлопнуть в ничто» слишком простой код. Признаюсь, немного я себе всё равно помог. Я отключил некоторые виды оптимизации, используемые в Visual Studio 2010. Во-первых, был отключен ключ /GL (Whole Program Optimization). Во–вторых, я использовал атрибут __declspec(noinline).
Прошу прощение за такое длинное вступление. Хотелось пояснить неуклюжесть программного кода. И сразу пресечь дискуссии на тему, что этот код можно написать лучше. Я знаю, что можно. Но не получается сделать код одновременно и коротким, и чтобы можно было показать уязвимость.
Демонстрационный пример
Полный код и проект для Visual Studio 2010 доступен здесь.
const size_t MAX_NAME_LEN = 60;
enum ErrorStatus {
E_ToShortName, E_ToShortPass, E_BigName, E_OK
};
void PrintNormalizedName(const char *raw_name)
{
char name[MAX_NAME_LEN + 1];
strcpy(name, raw_name);
for (size_t i = 0; name[i] != '\0'; ++i)
name[i] = tolower(name[i]);
name[0] = toupper(name[0]);
printf(name);
}
ErrorStatus IsCorrectPassword(
const char *universalPassword,
BOOL &retIsOkPass)
{
string name, password;
printf("Name: "); cin >> name;
printf("Password: "); cin >> password;
if (name.length() < 1) return E_ToShortName;
if (name.length() > MAX_NAME_LEN) return E_BigName;
if (password.length() < 1) return E_ToShortPass;
retIsOkPass =
universalPassword != NULL &&
strcmp(password.c_str(), universalPassword) == 0;
if (!retIsOkPass)
retIsOkPass = name[0] == password[0];
printf("Hello, ");
PrintNormalizedName(name.c_str());
return E_OK;
}
int _tmain(int, char *[])
{
_set_printf_count_output(1);
char universal[] = "_Universal_Pass_!";
BOOL isOkPassword = FALSE;
ErrorStatus status =
IsCorrectPassword(universal, isOkPassword);
if (status == E_OK && isOkPassword)
printf("\nPassword: OK\n");
else
printf("\nPassword: ERROR\n");
return 0;
}Функция _tmain() вызывает функцию IsCorrectPassword(). Если пароль верен или если он совпадает с магическим словом "_Universal_Pass_!", то программа выводит строку «Password: OK». Целью атак будет добиться, чтобы программа выводила именно эту строку.
Функция IsCorrectPassword() запрашивает у пользователя имя и пароль. Пароль считается корректным, если он совпадает с переданным в функцию магическим словом. Также он корректен, если первая буква пароля совпадает с первой буквой имени.
Вне зависимости от того, введен правильный пароль или нет, программа приветствует пользователя. Для этого вызывается функция PrintNormalizedName().
В функции PrintNormalizedName() всё самое интересное. Именно в ней, находится обсуждаемый «printf(name);». Подумайте, как с помощью этой строчки можно обмануть программу. Если знаете как, то дальше можно не читать.
Что делает функция PrintNormalizedName()? Она печатает имя, сделав первую букву заглавной, а остальные маленькими. Например, если ввести имя «andREy2008», то она распечатает «Andrey2008».
Первая атака
Предположим мы не знаем правильный пароль. Но знаем, что где-то есть некий магический пароль. Попробуем его поискать, используя printf(). Если адрес этого пароля есть где-то в стеке, то у нас есть шанс на успех. Есть идеи, как увидеть этот пароль на экране?
Даю подсказку. Функция printf() относится к семейству функций с переменным количеством аргументов. Работают такие функции так. В стек записывается произвольное количество данных. Функция printf() не знает, сколько данных записано в стек и какой у них тип. Она руководствуется исключительно строкой форматирования. Если написано "%d%s", то значит, из стека следует извлечь одно значение типа int и один указатель. Так как функция printf() не знает, сколько аргументов ей передали, то она может заглянуть глубже в стек и распечатать данные, которые никакого к ней отношения не имеет. Как правило, это приводит к access violation или к распечатке мусора. Однако, этим мусором можно воспользоваться.
Рассмотрим, как может выглядеть стек в момент, когда мы вызываем функцию printf():

Рисунок 1. Схематическое расположение данных в стеке.
Вызов функции «printf(name);» имеет только один аргумент, который является строкой форматирования. Это значит, что если мы вместо имени мы введём "%d", то распечатаем данные, которые лежат в стеке до адреса возврата в функцию PrintNormalizedName(). Попробуем:
Name: %d
Password: 1
Hello, 37
Password: ERROR
Пока данное действие малоосмысленно. Как минимум, вначале мы должны распечатать адреса возврата и всё содержимое буфера char name[MAX_NAME_LEN + 1];, который тоже расположен в стеке. И только потом, возможно, мы доберемся до чего-то интересного.
Если злоумышленник не имеет возможности дизассемблировать или отладить программу, то ему сложно понять, найдет он что-то в стеке или нет. Тем не менее, он может действовать следующим образом.
В начале, ввести: "%s". Потом ввести "%x%s". Потом ввести "%x%x%s" и так далее. Этим хакер будет перебирать по-очереди данные в стеке, и пытаться распечатать их как строку. Здесь ему помогает то, что все данные в стеке выровнены, как минимум по границе 4 байта.
Если честно, действуя так, у нас ничего не получится. Мы превысим лимит в 60 символов, так и не распечатав ничего полезного. На помощь нам придет "%f", который предназначен для печати значений типа double. Следовательно, с его помощью мы сможем двигаться по стеку сразу по 8 байт.
И вот она — долгожданная строчка:
%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%x(%s)
Результат:
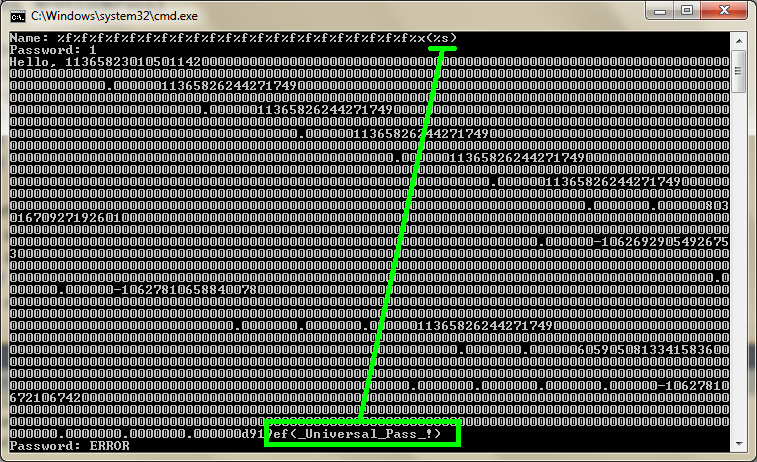
Рисунок 2. Распечатка пароля. Нажмите на рисунок для увеличения.
Попробуем эту строчку в качестве волшебного пароля:
Name: Aaa
Password: _Universal_Pass_!
Hello, Aaa
Password: OK
Ура! Мы смогли найти и вывести на экран приватные данные, к которым программа не планировала дать нам доступ. Причем, обратите внимание, для этого нет необходимости иметь доступ к самому двоичному коду программы. Достаточно усердия и настойчивости.
Выводы по первой атаке
Подобный способ получения приватных данных следует обдумать более широко. При разработке программ, содержащих функции с переменным количеством аргументов подумайте, существуют ли ситуации, когда через них могут утечь данные во внешний мир. Это может быть лог-файл, пакет, передаваемый по сети, и так далее.
В рассмотренном случае атака стала возможна из-за того, что на вход функции printf() поступает строка, которая может содержать управляющие команды. Чтобы этого избежать, было достаточно написать так:
printf("%s", name);Вторая атака
Вы знаете, что функция printf() может модифицировать память? Скорее всего, вы про это читали, но забыли. Речь идет о спецификаторе "%n". Он позволяет записать по указанному адресу количество символов, которые уже распечатала функция printf().
Если честно, атака, основанная на спецификаторе "%n" носит исключительно исторический характер. Начиная с Visual Studio 2005 возможность использования "%n" по умолчанию отключена. Чтобы провести эту атаку мне пришлось явно разрешить этот спецификатор. Вот это магическое действие:
_set_printf_count_output(1);
Чтобы стало понятнее, приведу пример использования "%n":
int i;
printf("12345%n6789\n", &i);
printf( "i = %d\n", i );Вывод программы:
123456789
i = 5
Как добраться до нужного указателя, находящегося в стеке, мы уже узнали. А теперь у нас в руках есть инструмент, который позволяет модифицировать память по этому указателю.
Конечно, пользоваться этим неудобно. Во-первых, мы можем записать только сразу 4 байта (размер типа int). Если нам нужно большое число, то вначале функция printf() будет должна вывести очень много символов. Чтобы этого не делать, может помочь спецификатор "%00u". Спецификатор влияет на значение текущего количества выведенных байт. Подробнее вникать в тонкости не будем.
В нашем случае всё проще. Нам достаточно записать в переменную isOkPassword любое значение, неравное 0. Адрес этой переменной передаются в функцию IsCorrectPassword(), а значит, находится где-то в стеке. Пусть вас не смущает, что переменная передается как ссылка. На низком уровне, ссылка является обыкновенным указателем.
Вот строка, которая позволит нам модифицировать переменную IsCorrectPassword:
%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f %n
Спецификатор "%n" не учитывает количество символов, выведенных с помощью таких спецификаторов, как "%f". Поэтому, перед "%n" поставим один пробел, чтобы записать в isOkPassword значение 1.
Пробуем:
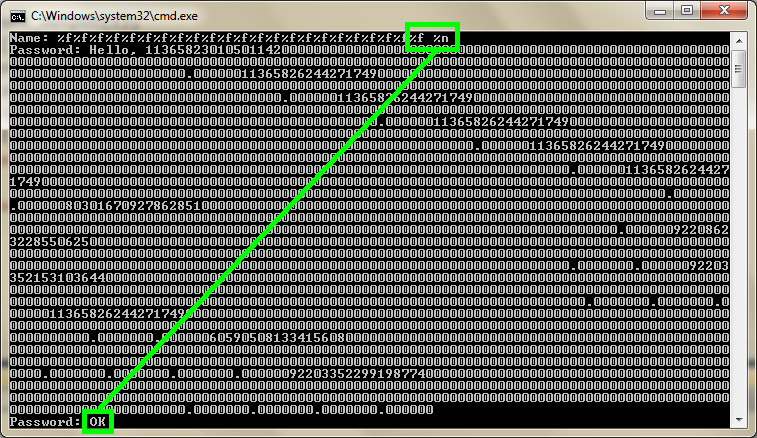
Рисунок 3. Запись в память. Нажмите на рисунок для увеличения.
Впечатляет? Но это ещё далеко не всё. Можно произвести запись почти по произвольному адресу. Если выводимая строка находится в стеке, то мы можем дойти до нужных символов и использовать их как адрес.
Например, мы можем написать строку, содержащую подряд символы с кодами 'xF8', 'x32', 'x01', 'x7F'. Получается, что в строке есть жестко закодированное число, которое эквивалентно значению 0x7F0132F8. В конце мы поставим спецификатор "%n". Используя "%x" или другие спецификаторы, мы можем добраться до закодированного числа 0x7F0132F8 и записать количество выведенных символов по этому адресу. У такого способа есть ограничения, но он всё равно очень любопытен.
Выводы по второй атаке
Можно сказать, что атака второго рода сейчас вряд ли возможна. Как видите, поддержка спецификатора "%n" в современных библиотеках по умолчанию выключена. Однако можно создать свой самодельный механизм, который будет предрасположен данному виду уязвимости. Будьте аккуратны, когда введенные извне данные, управляют тем, что и куда записать в память.
Конкретно в этом случае, проблемы опять не возникнет, если написать так:
printf("%s", name);Общие выводы
Здесь рассмотрено только два простых примера уязвимости. Конечно, их существует намного больше. Здесь не делается попытка описать или хотя бы перечислить их. В статье планировалось показать, что опасность может представлять даже такая простая конструкция как printf(name).
Отсюда следует важный вывод. Если вы не специалист по безопасности, то лучше следовать всем рекомендациям, о которых пишут. Суть рекомендаций бывает слишком тонка, чтобы оценить весь спектр угроз самостоятельно. Ведь вы наверняка читали, что printf() опасная функция. Но я уверен, что многие, из читающих эту статью, впервые узнали о глубине кроличьей норы.
Если вы пишите приложение, которое потенциально может служить объектом атаки, соблюдайте максимальную аккуратность. То, что на ваш взгляд является совершенно безобидным кодом, может содержать уязвимость. Если вы не видите в коде подвоха, это не означает, что его нет.
Соблюдайте все рекомендации компилятора об использовании обновленных версий строковых функций. Имеется в виду, использование sprintf_s вместо sprintf и так далее.
Ещё лучше — вообще откажитесь от низкоуровневой работы со строками. Эти функции — наследие языка Си. Сейчас есть std::string. Есть безопасные способы формирования строк, такие как boost::format или std::stringstream.
P.S. Кто-то, прочитав вывод, сказал — «это и так было понятно». Но будьте честны. До прочтения этой статьи вы знали и помнили о том, что printf() может писать в память? А ведь это является большой уязвимостью. По крайней мере, являлось таковой раньше. Сейчас есть другие, не менее коварные.
