<< Читать первую часть статьи
Адресная арифметика (address arithmetic) — это способ вычисления адреса какого-либо объекта при помощи арифметических операций над указателями, а также использование указателей в операциях сравнения. Адресную арифметику также называют арифметикой над указателями (pointer arithmetic).
Большой процент 64-битных ошибок связан именно с адресной арифметикой. Часто ошибки возникают в тех выражениях, где совместно используются указатели и 32-битные переменные.
Рассмотрим первую из ошибок данного типа:
Причина, по которой в Win32 программе A + B == A — (-B), показана на рисунке 14.
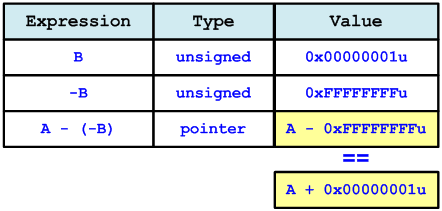
Рисунок 14 — Win32: A + B == A — (-B)
Причина, по которой в Win64 программе A + B != A — (-B), показана на рисунке 15.
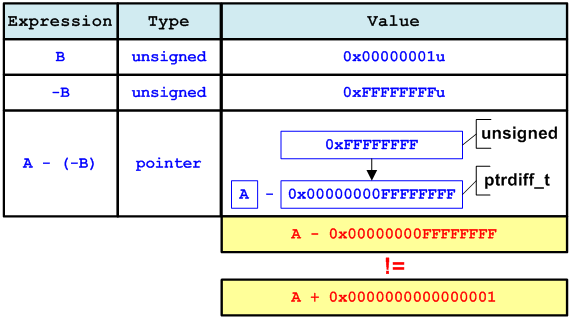
Рисунок 15 — Win64: A + B != A — (-B)
Ошибка будет устранена, если использовать подходящий memsize-тип. В данном случае используется тип ptrdfiff_t:
Рассмотрим еще один вариант ошибки, связанный с использованием знаковых и беззнаковых типов. В этот раз ошибка приведет не к неверному сравнению, а сразу к падению приложения.
Выражение «x * y» имеет значение 0xFFFFFFFB и имеет тип unsigned. Данный код, собранный в 32-битном варианте работоспособен, так как сложение указателя с 0xFFFFFFFB эквивалентно его уменьшению на 5. В 64-битной указатель после прибавления 0xFFFFFFFB начнет указывать далеко за пределы массива p1 (смотри рисунок 16).
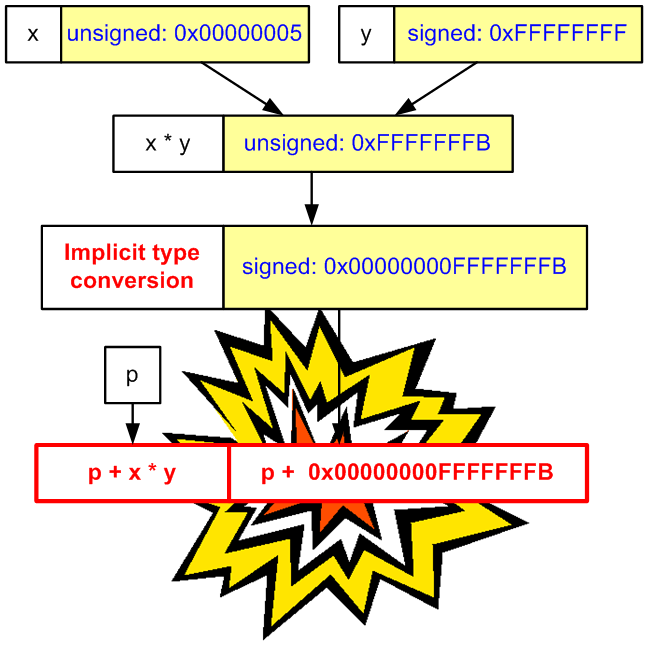
Рисунок 16 — Выход за границы массива
Исправление заключается в использовании memsize-типов и аккуратной работе со знаковыми и беззнаковыми типами:
Код взят из реальной программы математического моделирования, в которой важным ресурсом является объем оперативной памяти, и возможность на 64-битной архитектуре использовать более 4 гигабайт памяти существенно увеличивает вычислительные возможности. В программах данного класса для экономии памяти часто используют одномерные массивы, осуществляя работу с ними как с трехмерными массивами. Для этого существуют функции, аналогичные GetCell, обеспечивающие доступ к необходимым элементам.
Приведенный код корректно работает с указателями, если значение выражения " x + y * Width + z * Width * Height" не превышает INT_MAX (2147483647). В противном случае произойдет переполнение, что приведет к неопределенному поведению в программы.
Такой код мог всегда корректно работать на 32-битной платформе. В рамках 32-битной архитектуры программе недоступен объем памяти для создания массива подобного размеров. На 64-битной архитектуре это ограничение снято, и размер массива легко может превысить INT_MAX элементов.
Программисты часто допускают ошибку, пытаясь исправить код следующим образом:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}
Они знают, что по правилам языка Си++ выражение для вычисления индекса будет иметь тип ptrdiff_t и надеются за счет этого избежать переполнения. Но переполнение может произойти внутри подвыражения «y * Width» или «z * Width * Height», так как для их вычисления по-прежнему используется тип int.
Если вы хотите исправить код, не изменяя типов переменных, участвующих в выражении, то вы можете явно привести каждое подвыражение к типу ptrdiff_t:
Другое, более верное решение — изменить типы переменных:
Иногда в программах для удобства изменяют тип массива при его обработке. Опасное и безопасное приведение типов представлено в следующем коде:
Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов size_t и int совпадают, и мы видим вывод «2 2».
На 64-битной системе мы получили в выводе «2 17179869187», так как именно значение 17179869187 находится в 1-ом элементе массива sizetPtr (см. рисунок 17). В некоторых случаях именно такое поведение и бывает нужно, но обычно это является ошибкой.
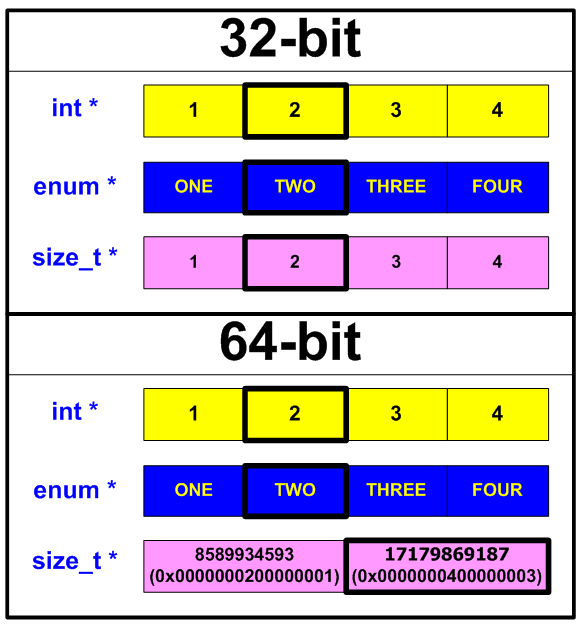
Рисунок 17 — Представление элементов массивов в памяти
Примечание. Тип enum в компиляторе Visual C++ по умолчанию совпадает размером с типом int, то есть является 32-битным типом. Использование enum другого размера возможно только с помощью расширения, считающимся нестандартным в Visual C++. Поэтому приведенный пример корректен в Visual C++, но с точки зрения других компиляторов приведение указателя на элементы int к указателю на элементы enum может быть также некорректным.
Иногда в программах указатели сохраняют в целочисленных типах. Обычно для этого используется такой тип, как int. Это, пожалуй, одна из самых распространенных 64-битных ошибок.
В 64-битной программе это некорректно, поскольку тип int остался 32-битным и не может хранить в себе 64-битный указатель. Часто это не удается заметить сразу. Благодаря стечению обстоятельств при тестировании указатель может всегда ссылаться на объекты, расположенные в младших 4 гигабайтах адресного пространства. В этом случае 64-битная программа будет удачно работать, и может неожиданно отказать только спустя большой промежуток времени (см. рисунок 18).
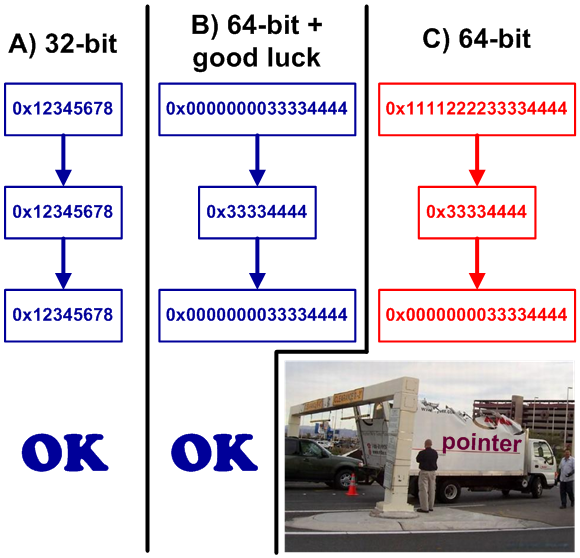
Рисунок 18 — Помещение указателя в переменную типа int
Если все же необходимо поместить указатель в переменную целочисленного типа, то следует использовать такие типы как intptr_t, uintptr_t, ptrdiff_t и size_t.
Когда возникает необходимость работать с указателем как с целым числом, иногда удобно воспользоваться объединением, как показано в примере, и работать с числовым представлением типа без использования явных приведений:
Данный код корректен на 32-битных системах и некорректен на 64-битных. Изменяя член m_n на 64-битной системе, мы работаем только с частью указателя m_p (смотри рисунок 19).
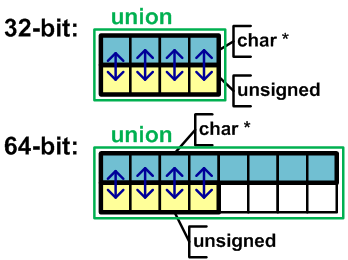
Рисунок 19 — Представление объединения в памяти на 32-битной и 64-битной системе.
Следует использовать тип, который будет соответствовать размеру указателя:
Смешанное использование 32-битных и 64-битных типов неожиданно может привести к возникновению вечных циклов. Рассмотрим синтетический пример, иллюстрирующий целый класс подобных дефектов:
Это цикл никогда не прекратится, если значение Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с количеством итераций менее значения UINT_MAX. Но 64-битный вариант программы может обрабатывать больше данных, и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие «Index != Count» никогда не выполнится, что и приводит к бесконечному циклу (см. рисунок 20).
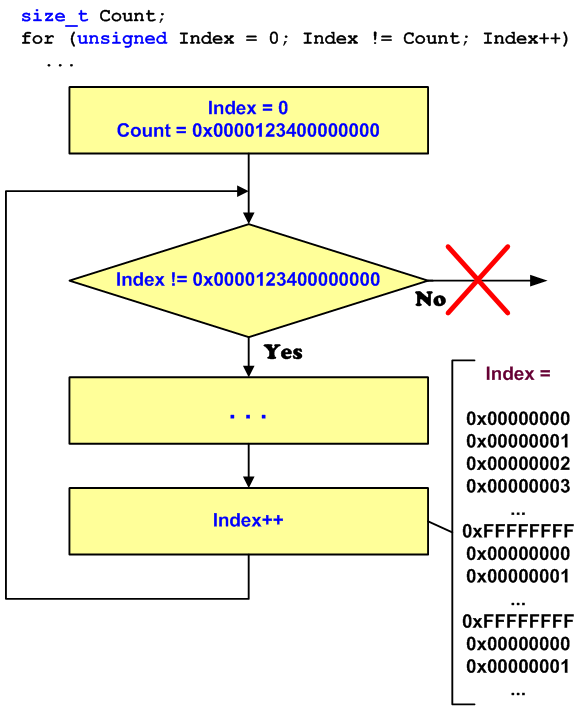
Рисунок 20 — Механизм возникновения вечного цикла
Работа с битовыми операциями требует особой аккуратности от программиста при разработке кроссплатформенных приложений, в которых типы данных могут иметь различные размеры. Поскольку перенос программы на 64-битную платформу также ведет к изменению размерности некоторых типов, то высока вероятность возникновения ошибок в участках кода, работающих с отдельными битами. Чаще всего это происходит из-за смешенной работы с 32-битными и 64-битными типами данных. Рассмотрим ошибку, возникшую в коде из-за некорректного применения операции NOT:
Ошибка заключается в том, что маска, заданная выражением "~(b — 1)", имеет тип ULONG. Это приводит к обнулению старших разрядов переменной «a», ходя должны были обнулиться только младшие четыре бита (см. рисунок 21).
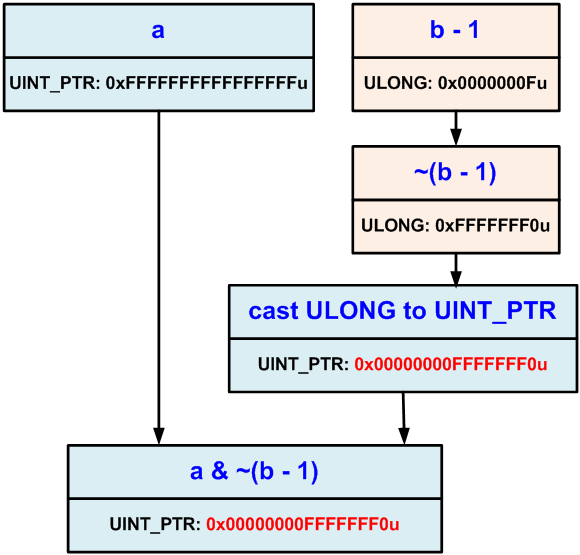
Рисунок 21 — Ошибка из-за обнуления старших бит
Исправленный вариант кода может выглядеть следующим образом:
Приведенный пример крайне прост, но хорошо демонстрирует класс ошибок, которые могут возникать при активной работе с битовыми операциями.
Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять бит с номерами от 0 до 31 в единицу. После переноса программы на 64-битную платформу возникает необходимость выставлять биты с номерами от 0 до 63. Однако данный код неспособен выставить старшие биты, с номерами 32-63. Обратите внимание, что числовой литерал «1» имеет тип int, и при сдвиге на 32 позиции произойдет переполнение, как показано на рисунке 22. Получим мы в результате 0 (рисунок 22-B) или 1 (рисунок 22-C) — зависит от реализации компилятора.
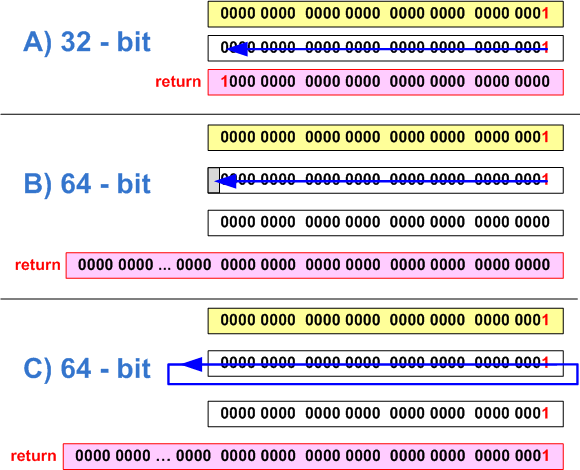
Рисунок 22 — a) корректная установка 31-ого бита в 32-битном коде (биты считаются от 0); b,c) — Ошибка установки 32-ого бита на 64-битной системе (два варианта поведения, зависящих от компилятора)
Для исправления кода необходимо сделать константу «1» того же типа, что и переменная mask:
Заметим также, что неисправленный код приведет еще к одной интересной ошибке. При выставлении 31 бита на 64-битной системе результатом работы функции будет значение 0xffffffff80000000 (см. рисунок 23). Результатом выражения 1 << 31 является отрицательное число -2147483648. Это число представляется в 64-битной целой переменной как 0xffffffff80000000.

Рисунок 23 — Ошибка установки 31-ого бита на 64-битной системе
Приведенная далее ошибка редка, но, к сожалению, достаточно сложна в понимании. Поэтому остановимся на ней чуть подробнее.
В 32-битной среде порядок вычисления выражения будет выглядеть, как показано на рисунке 24.
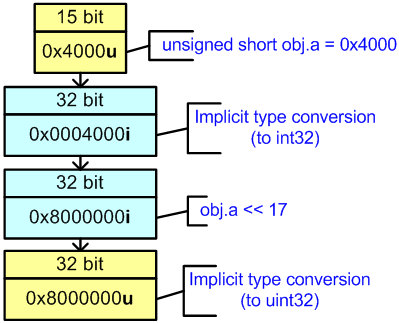
Рисунок 24 — Вычисление выражения «obj.a << 17» в 32-битном коде
Обратим внимание, что при вычислении выражения «obj.a << 17» происходит знаковое расширение типа unsigned short до типа int. Более наглядно, это может продемонстрировать следующий код:
Теперь посмотрим, к чему приводит наличие знакового расширения в 64-битном коде. Последовательность вычисления выражения показана на рисунке 25.
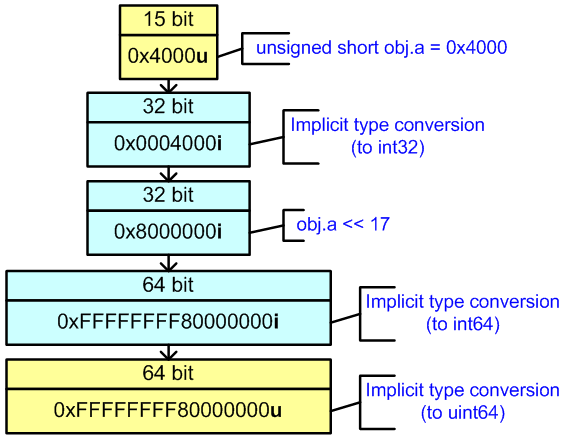
Рисунок 25 — Вычисление выражения «obj.a << 17» в 64-битном коде
Член структуры obj.a преобразуется из битового поля типа unsigned short в int. Выражение «obj.a << 17» имеет тип int, но оно преобразуется в ptrdiff_t и затем в size_t, перед тем как будет присвоено переменной addr. В результате мы получим число значение 0xffffffff80000000, вместо ожидаемого значения 0x0000000080000000.
Будьте внимательны при работе с битовыми полями. Для предотвращения описанной ситуации в нашем примере достаточно явно привести obj.a к типу size_t.
Важным элементом переноса программного решения на новую платформу является преемственность к существующим протоколам обмена данными. Необходимо обеспечить чтение существующих форматов проектов, осуществлять обмен данными между 32-битными и 64-битными процессами и так далее.
В основном, ошибки данного рода заключаются в сериализации memsize-типов и операциях обмена данными с их использованием:
Недопустимо использование типов, которые меняют свой размер в зависимости от среды разработки, в бинарных интерфейсах обмена данными. В языке Си++ большинство типов не имеют четкого размера и, следовательно, их все невозможно использовать для этих целей. Поэтому создатели средств разработки и сами программисты создают типы данных, имеющие строгий размер, такие как __int8, __int16, INT32, word64 и так далее.
Даже после внесения исправлений, касающихся размеров типа, вы можете столкнуться с несовместимостью бинарных форматов. Причина кроется в ином представлении данных. Наиболее часто это связано с другой последовательностью байт.
Порядок байт — метод записи байтов многобайтовых чисел (см. рисунок 26). Порядок от младшего к старшему (англ. little-endian) — запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86 и x86-64-процессорами. Порядок от старшего к младшему (англ. big-endian) — запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком байтов (англ. network byte order). Этот порядок байт используется процессорами Motorola 68000, SPARC.
Кстати, некоторые процессоры могут работать и в порядке от младшего к старшему, и наоборот. К их числу относится, например IA-64.

Рисунок 26 — Порядок байт в 64-битном типе на little-endian и big-endian системах
Разрабатывая бинарный интерфейс или формат данных, следует помнить о последовательности байт. А если 64-битная система, на которую Вы переносите 32-битное приложение, имеет иную последовательность байт, то вы просто будете вынуждены учесть это в своем коде. Для преобразования между сетевым порядком байт (big-endian) и порядком байт (little-endian), можно использовать функции htonl(), htons(), bswap_64, и так далее.
Помимо изменения размеров некоторых типов данных, ошибки могут возникать и из-за изменения правил их выравнивания в 64-битной системе (см. рисунок 27).
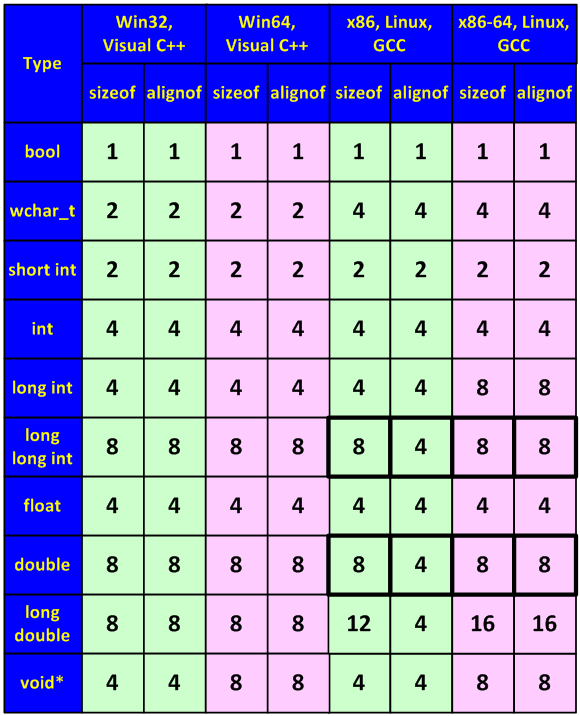
Рисунок 27 — Размеры типы и границы их выравнивания (значения точны для Win32/Win64, но могут варьироваться в «Unix-мире» и приводятся просто в качестве примера)
Рассмотрим пример описания проблемы, найденного в одном из форумов:
Столкнулся сегодня с одной проблемой в Linux. Есть структура данных, состоящая из нескольких полей: 64-битный double, потом 8 unsigned char и один 32-битный int. Итого получается 20 байт (8 + 8*1 + 4). Под 32-битными системами sizeof равен 20 и всё работает нормально. А под 64-битным Linux'ом sizeof возвращает 24. Т.е. идёт выравнивание по границе 64 бит.
Далее в форуме идут рассуждения о совместимости данных и просьба совета, как упаковать данные в структуре. Но не это сейчас интересно. Интереснее то, что здесь наблюдается очередной тип ошибки, который может возникнуть при переносе приложений на 64-битную систему.
Когда меняются размеры полей в структуре и из-за этого меняется сам размер структуры это понятно и привычно. Здесь другая ситуация. Размер полей остался прежний, но из-за иных правил выравнивания размер структуры все равно изменится (см. рисунок 28). Такое поведение может привести к разнообразным ошибкам, например в несовместимости форматов сохраняемых данных.
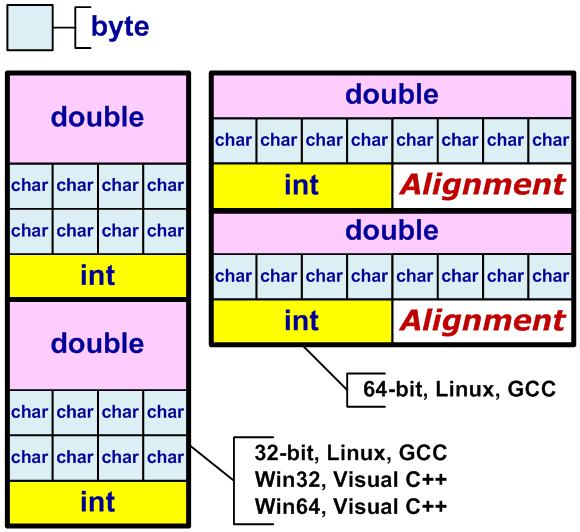
Рисунок 28 — Схематическое изображение структур и правил выравнивания типов
Иногда программисты используют структуры, в конце которых расположен массив переменного размера. Эта структура и выделение памяти для нее может выглядеть следующим образом:
Этот код будет корректно работать в 32-битном варианте, но его 64-битный вариант даст сбой.
При выделении памяти, необходимой для хранения объекта типа MyPointersArray, содержащего 5 указателей, необходимо учесть, что начало массива m_arr будет выровнено по границе 8 байт. Расположение данных в памяти на разных системах (Win32/Win64) показано на рисунке 29.
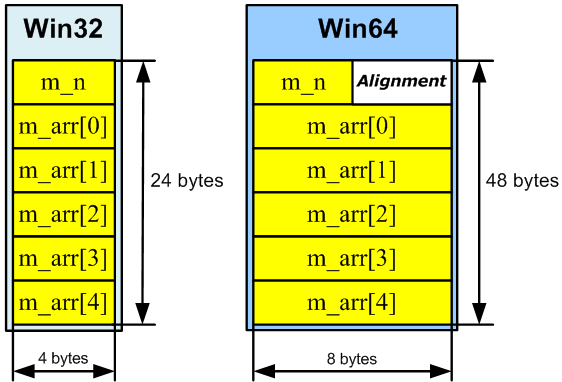
Рисунок 29 — Расположение данных в памяти в 32-битной и 64-битной системе
Корректный расчет размера должен выглядеть следующим образом:
В приведенном коде мы узнаем смещение последнего члена структуры и суммируем это смещение с его размером. Смещение члена структуры или класса можно узнать с использованием макроса offsetof или FIELD_OFFSET. Всегда используйте эти макросы для получения смещения в структуре, не опираясь на свои предположения о размерах типов и правилах их выравнивания.
При перекомпиляции программы может начать выбираться другая перегруженная функция (см. рисунок 30).
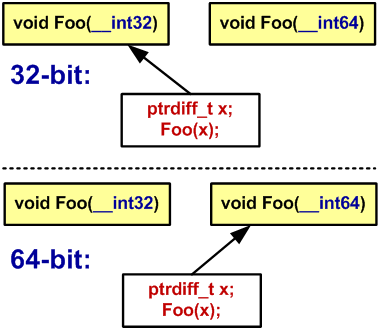
Рисунок 30 — Выбор перегруженной функции в 32-битной и 64-битной системе
Пример проблемы:
Неаккуратный программист помещал и затем выбирал из стека значения различных типов (ptrdiff_t и int). На 32-битной системе их размеры совпадали, все замечательно работало. Когда в 64-битной программе изменился размер типа ptrdiff_t, то в стек стало попадать больше байт, чем затем извлекаться.
Последний пример посвящен ошибкам в 32-битных программах, которые возникают при их выполнении в 64-битной среде. В состав 64-битных программных комплексов еще долго будут входить 32-битные модули, а следовательно необходимо обеспечить их корректную работу в 64-битной среде. Подсистема WoW64 очень хорошо справляется со своей задачей, изолируя 32-битное приложение, и практически все 32-битные приложения функционирует корректно. Однако иногда ошибки все же встречаются и в основном они связаны с механизмом перенаправления при работе с файлами и реестром Windows.
Например, в комплексе, состоящим из 32-битных и 64-битных модулей, при их взаимодействии следует учитывать, что они используют различные представления реестра. Таким образом, в одной из программ следующая строчка в 32-битном модуле стала неработоспособной:
Чтобы подружить эту программу с другими 64-битными частями, необходимо вписать ключ KEY_WOW64_64KEY:
Наилучший результат при поиске описанных в статье ошибок дает методика статического анализа кода. В качестве примера инструмента осуществляющего такой анализ, можно назвать разрабатываемый нами инструмент Viva64, входящий в состав PVS-Studio.
Методы статического поиска дефектов позволяют обнаруживать дефекты по исходному коду программы. При этом поведение программы оценивается на всех путях исполнения одновременно. За счет этого, возможно обнаружение дефектов, проявляющихся лишь на необычных путях исполнения при редких входных данных. Эта особенность позволяет дополнить методы тестирования, повышая надежность программ. Системы статического анализа могут использоваться при проведении аудита исходного кода, для систематического устранения дефектов в существующих программах, и встраиваться в цикл разработки, автоматически обнаруживая дефекты в создаваемом коде.
Пример 16. Адресная арифметика. A + B != A — (-B)
Адресная арифметика (address arithmetic) — это способ вычисления адреса какого-либо объекта при помощи арифметических операций над указателями, а также использование указателей в операциях сравнения. Адресную арифметику также называют арифметикой над указателями (pointer arithmetic).
Большой процент 64-битных ошибок связан именно с адресной арифметикой. Часто ошибки возникают в тех выражениях, где совместно используются указатели и 32-битные переменные.
Рассмотрим первую из ошибок данного типа:
char *A = "123456789"; unsigned B = 1; char *X = A + B; char *Y = A - (-B); if (X != Y) cout << "Error" << endl;
Причина, по которой в Win32 программе A + B == A — (-B), показана на рисунке 14.
Рисунок 14 — Win32: A + B == A — (-B)
Причина, по которой в Win64 программе A + B != A — (-B), показана на рисунке 15.
Рисунок 15 — Win64: A + B != A — (-B)
Ошибка будет устранена, если использовать подходящий memsize-тип. В данном случае используется тип ptrdfiff_t:
char *A = "123456789"; ptrdiff_t B = 1; char *X = A + B; char *Y = A - (-B);
Пример 17. Адресная арифметика. Знаковые и беззнаковые типы.
Рассмотрим еще один вариант ошибки, связанный с использованием знаковых и беззнаковых типов. В этот раз ошибка приведет не к неверному сравнению, а сразу к падению приложения.
LONG p1[100]; ULONG x = 5; LONG y = -1; LONG *p2 = p1 + 50; p2 = p2 + x * y; *p2 = 1; // Access violation
Выражение «x * y» имеет значение 0xFFFFFFFB и имеет тип unsigned. Данный код, собранный в 32-битном варианте работоспособен, так как сложение указателя с 0xFFFFFFFB эквивалентно его уменьшению на 5. В 64-битной указатель после прибавления 0xFFFFFFFB начнет указывать далеко за пределы массива p1 (смотри рисунок 16).

Рисунок 16 — Выход за границы массива
Исправление заключается в использовании memsize-типов и аккуратной работе со знаковыми и беззнаковыми типами:
LONG p1[100]; LONG_PTR x = 5; LONG_PTR y = -1; LONG *p2 = p1 + 50; p2 = p2 + x * y; *p2 = 1; // OK
Пример 18. Адресная арифметика. Переполнения.
class Region {
float *array;
int Width, Height, Depth;
float Region::GetCell(int x, int y, int z) const;
...
};
float Region::GetCell(int x, int y, int z) const {
return array[x + y * Width + z * Width * Height];
}Код взят из реальной программы математического моделирования, в которой важным ресурсом является объем оперативной памяти, и возможность на 64-битной архитектуре использовать более 4 гигабайт памяти существенно увеличивает вычислительные возможности. В программах данного класса для экономии памяти часто используют одномерные массивы, осуществляя работу с ними как с трехмерными массивами. Для этого существуют функции, аналогичные GetCell, обеспечивающие доступ к необходимым элементам.
Приведенный код корректно работает с указателями, если значение выражения " x + y * Width + z * Width * Height" не превышает INT_MAX (2147483647). В противном случае произойдет переполнение, что приведет к неопределенному поведению в программы.
Такой код мог всегда корректно работать на 32-битной платформе. В рамках 32-битной архитектуры программе недоступен объем памяти для создания массива подобного размеров. На 64-битной архитектуре это ограничение снято, и размер массива легко может превысить INT_MAX элементов.
Программисты часто допускают ошибку, пытаясь исправить код следующим образом:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}
Они знают, что по правилам языка Си++ выражение для вычисления индекса будет иметь тип ptrdiff_t и надеются за счет этого избежать переполнения. Но переполнение может произойти внутри подвыражения «y * Width» или «z * Width * Height», так как для их вычисления по-прежнему используется тип int.
Если вы хотите исправить код, не изменяя типов переменных, участвующих в выражении, то вы можете явно привести каждое подвыражение к типу ptrdiff_t:
float Region::GetCell(int x, int y, int z) const {
return array[ptrdiff_t(x) +
ptrdiff_t(y) * Width +
ptrdiff_t(z) * Width * Height];
}Другое, более верное решение — изменить типы переменных:
typedef ptrdiff_t TCoord;
class Region {
float *array;
TCoord Width, Height, Depth;
float Region::GetCell(TCoord x, TCoord y, TCoord z) const;
...
};
float Region::GetCell(TCoord x, TCoord y, TCoord z) const {
return array[x + y * Width + z * Width * Height];
}Пример 19. Изменение типа массива
Иногда в программах для удобства изменяют тип массива при его обработке. Опасное и безопасное приведение типов представлено в следующем коде:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64-bit system: 2 17179869187Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов size_t и int совпадают, и мы видим вывод «2 2».
На 64-битной системе мы получили в выводе «2 17179869187», так как именно значение 17179869187 находится в 1-ом элементе массива sizetPtr (см. рисунок 17). В некоторых случаях именно такое поведение и бывает нужно, но обычно это является ошибкой.
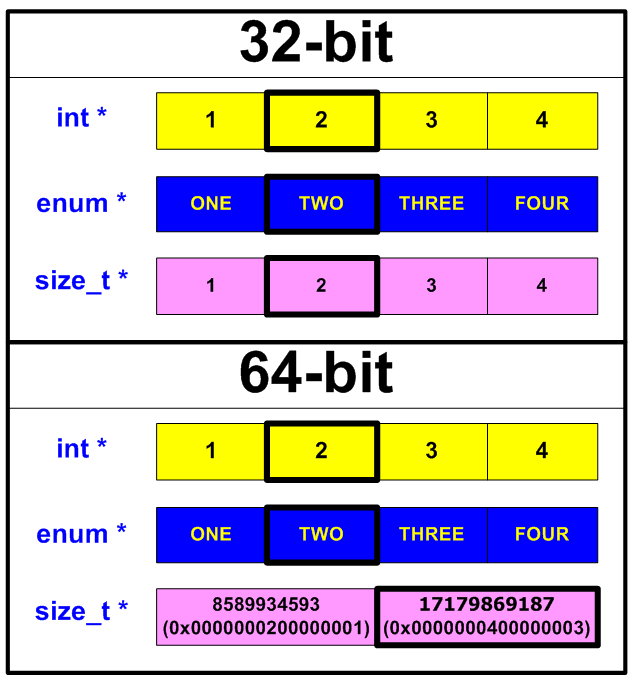
Рисунок 17 — Представление элементов массивов в памяти
Примечание. Тип enum в компиляторе Visual C++ по умолчанию совпадает размером с типом int, то есть является 32-битным типом. Использование enum другого размера возможно только с помощью расширения, считающимся нестандартным в Visual C++. Поэтому приведенный пример корректен в Visual C++, но с точки зрения других компиляторов приведение указателя на элементы int к указателю на элементы enum может быть также некорректным.
Пример 20. Упаковка указателя в 32-битный тип
Иногда в программах указатели сохраняют в целочисленных типах. Обычно для этого используется такой тип, как int. Это, пожалуй, одна из самых распространенных 64-битных ошибок.
char *ptr = ...; int n = (int) ptr; ... ptr = (char *) n;
В 64-битной программе это некорректно, поскольку тип int остался 32-битным и не может хранить в себе 64-битный указатель. Часто это не удается заметить сразу. Благодаря стечению обстоятельств при тестировании указатель может всегда ссылаться на объекты, расположенные в младших 4 гигабайтах адресного пространства. В этом случае 64-битная программа будет удачно работать, и может неожиданно отказать только спустя большой промежуток времени (см. рисунок 18).
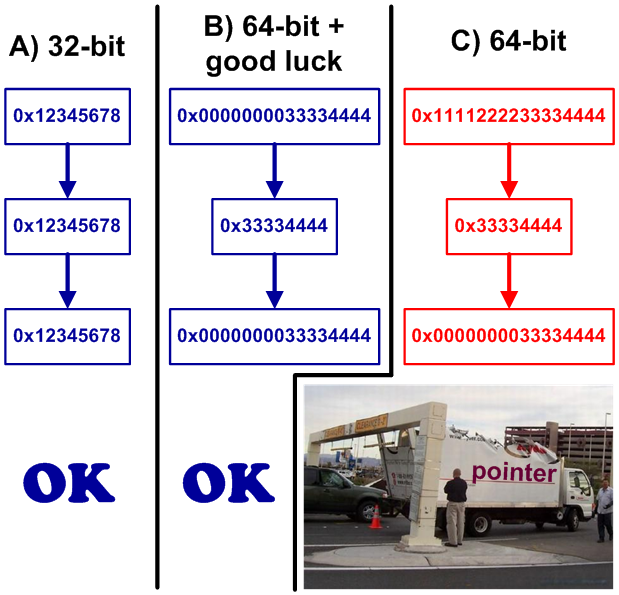
Рисунок 18 — Помещение указателя в переменную типа int
Если все же необходимо поместить указатель в переменную целочисленного типа, то следует использовать такие типы как intptr_t, uintptr_t, ptrdiff_t и size_t.
Пример 21. Memsize-типы в объединениях
Когда возникает необходимость работать с указателем как с целым числом, иногда удобно воспользоваться объединением, как показано в примере, и работать с числовым представлением типа без использования явных приведений:
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
u.m_p = str;
u.m_n += delta;Данный код корректен на 32-битных системах и некорректен на 64-битных. Изменяя член m_n на 64-битной системе, мы работаем только с частью указателя m_p (смотри рисунок 19).
Рисунок 19 — Представление объединения в памяти на 32-битной и 64-битной системе.
Следует использовать тип, который будет соответствовать размеру указателя:
union PtrNumUnion {
char *m_p;
uintptr_t m_n; //type fixed
} u;Пример 22. Вечный цикл
Смешанное использование 32-битных и 64-битных типов неожиданно может привести к возникновению вечных циклов. Рассмотрим синтетический пример, иллюстрирующий целый класс подобных дефектов:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; Index++)
{ ... } Это цикл никогда не прекратится, если значение Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с количеством итераций менее значения UINT_MAX. Но 64-битный вариант программы может обрабатывать больше данных, и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие «Index != Count» никогда не выполнится, что и приводит к бесконечному циклу (см. рисунок 20).
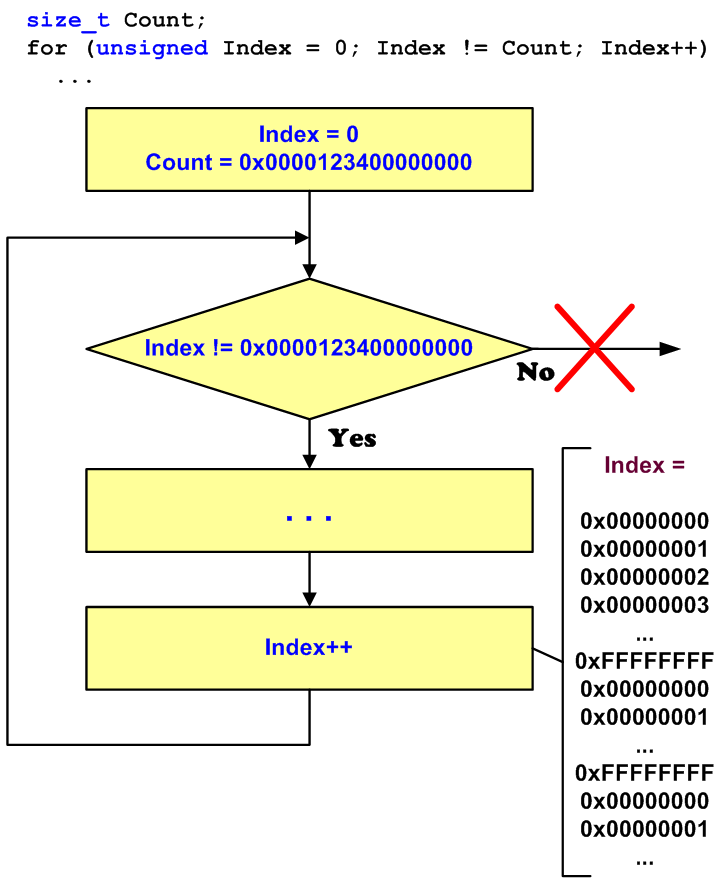
Рисунок 20 — Механизм возникновения вечного цикла
Пример 23. Работа с битами и операция NOT
Работа с битовыми операциями требует особой аккуратности от программиста при разработке кроссплатформенных приложений, в которых типы данных могут иметь различные размеры. Поскольку перенос программы на 64-битную платформу также ведет к изменению размерности некоторых типов, то высока вероятность возникновения ошибок в участках кода, работающих с отдельными битами. Чаще всего это происходит из-за смешенной работы с 32-битными и 64-битными типами данных. Рассмотрим ошибку, возникшую в коде из-за некорректного применения операции NOT:
UINT_PTR a = ~UINT_PTR(0); ULONG b = 0x10; UINT_PTR c = a & ~(b - 1); c = c | 0xFu; if (a != c) cout << "Error" << endl;
Ошибка заключается в том, что маска, заданная выражением "~(b — 1)", имеет тип ULONG. Это приводит к обнулению старших разрядов переменной «a», ходя должны были обнулиться только младшие четыре бита (см. рисунок 21).
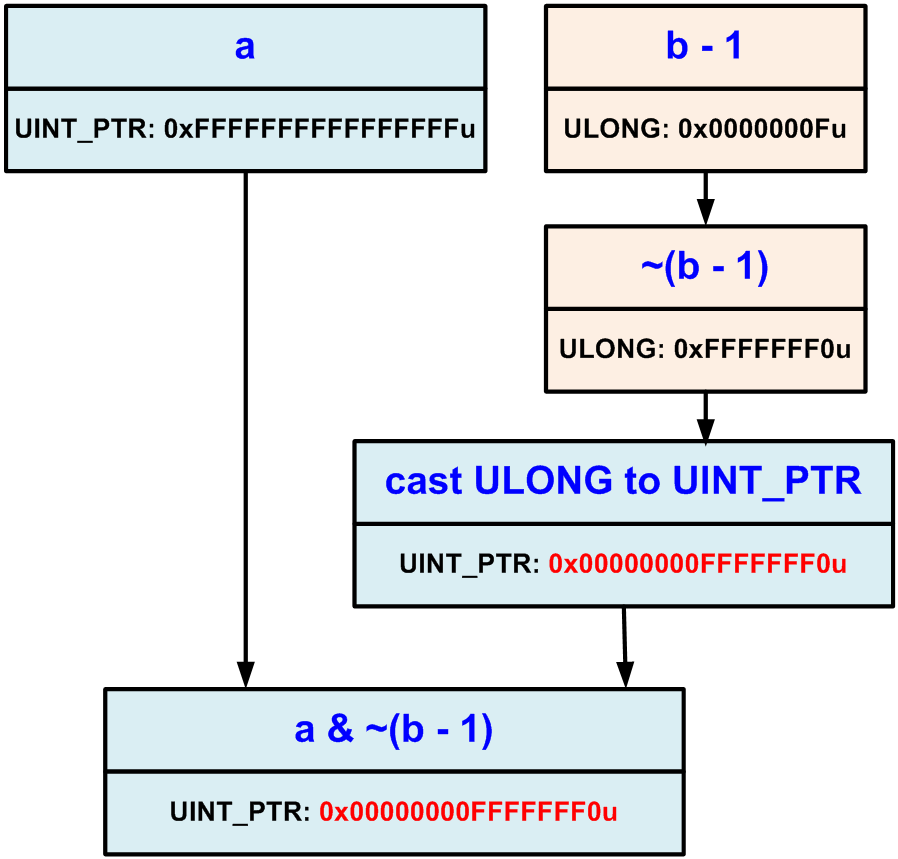
Рисунок 21 — Ошибка из-за обнуления старших бит
Исправленный вариант кода может выглядеть следующим образом:
UINT_PTR c = a & ~(UINT_PTR(b) - 1);
Приведенный пример крайне прост, но хорошо демонстрирует класс ошибок, которые могут возникать при активной работе с битовыми операциями.
Пример 24. Работа с битами, сдвиги
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять бит с номерами от 0 до 31 в единицу. После переноса программы на 64-битную платформу возникает необходимость выставлять биты с номерами от 0 до 63. Однако данный код неспособен выставить старшие биты, с номерами 32-63. Обратите внимание, что числовой литерал «1» имеет тип int, и при сдвиге на 32 позиции произойдет переполнение, как показано на рисунке 22. Получим мы в результате 0 (рисунок 22-B) или 1 (рисунок 22-C) — зависит от реализации компилятора.
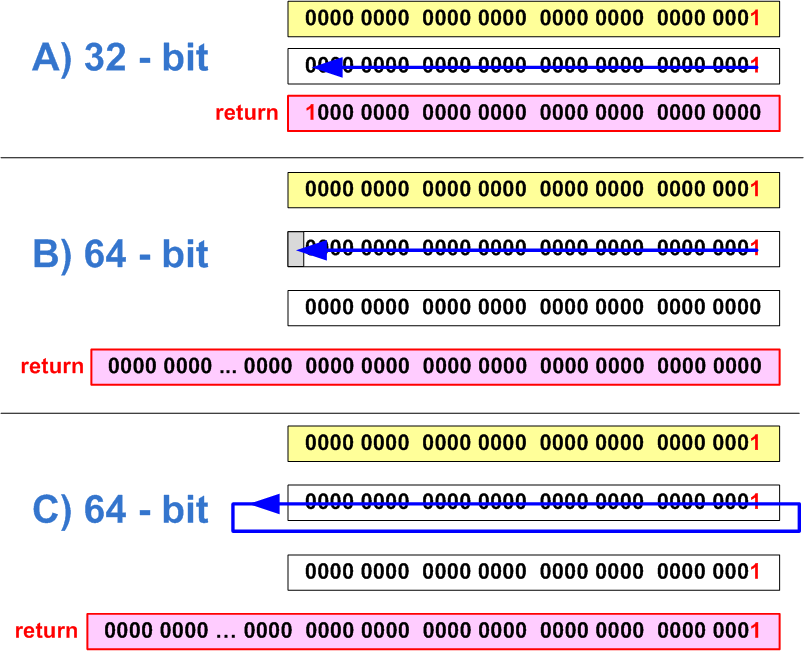
Рисунок 22 — a) корректная установка 31-ого бита в 32-битном коде (биты считаются от 0); b,c) — Ошибка установки 32-ого бита на 64-битной системе (два варианта поведения, зависящих от компилятора)
Для исправления кода необходимо сделать константу «1» того же типа, что и переменная mask:
ptrdiff_t mask = static_cast<ptrdiff_t>(1) << bitNum;
Заметим также, что неисправленный код приведет еще к одной интересной ошибке. При выставлении 31 бита на 64-битной системе результатом работы функции будет значение 0xffffffff80000000 (см. рисунок 23). Результатом выражения 1 << 31 является отрицательное число -2147483648. Это число представляется в 64-битной целой переменной как 0xffffffff80000000.

Рисунок 23 — Ошибка установки 31-ого бита на 64-битной системе
Пример 25. Работа с битами и знаковое расширение
Приведенная далее ошибка редка, но, к сожалению, достаточно сложна в понимании. Поэтому остановимся на ней чуть подробнее.
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t x = obj.a << 17; //Sign Extension
printf("x 0x%Ix\n", x);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000В 32-битной среде порядок вычисления выражения будет выглядеть, как показано на рисунке 24.
Рисунок 24 — Вычисление выражения «obj.a << 17» в 32-битном коде
Обратим внимание, что при вычислении выражения «obj.a << 17» происходит знаковое расширение типа unsigned short до типа int. Более наглядно, это может продемонстрировать следующий код:
#include <stdio.h>
template <typename T> void PrintType(T)
{
printf("type is %s %d-bit\n",
(T)-1 < 0 ? "signed" : "unsigned", sizeof(T)*8);
}
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
int main(void)
{
BitFieldStruct bf;
PrintType( bf.a );
PrintType( bf.a << 2);
return 0;
}
Result:
type is unsigned 16-bit
type is signed 32-bitТеперь посмотрим, к чему приводит наличие знакового расширения в 64-битном коде. Последовательность вычисления выражения показана на рисунке 25.
Рисунок 25 — Вычисление выражения «obj.a << 17» в 64-битном коде
Член структуры obj.a преобразуется из битового поля типа unsigned short в int. Выражение «obj.a << 17» имеет тип int, но оно преобразуется в ptrdiff_t и затем в size_t, перед тем как будет присвоено переменной addr. В результате мы получим число значение 0xffffffff80000000, вместо ожидаемого значения 0x0000000080000000.
Будьте внимательны при работе с битовыми полями. Для предотвращения описанной ситуации в нашем примере достаточно явно привести obj.a к типу size_t.
...
size_t x = static_cast<size_t>(obj.a) << 17; // OK
printf("x 0x%Ix\n", x);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0x80000000Пример 26. Сериализация и обмен данными
Важным элементом переноса программного решения на новую платформу является преемственность к существующим протоколам обмена данными. Необходимо обеспечить чтение существующих форматов проектов, осуществлять обмен данными между 32-битными и 64-битными процессами и так далее.
В основном, ошибки данного рода заключаются в сериализации memsize-типов и операциях обмена данными с их использованием:
size_t PixelsCount; fread(&PixelsCount, sizeof(PixelsCount), 1, inFile);
Недопустимо использование типов, которые меняют свой размер в зависимости от среды разработки, в бинарных интерфейсах обмена данными. В языке Си++ большинство типов не имеют четкого размера и, следовательно, их все невозможно использовать для этих целей. Поэтому создатели средств разработки и сами программисты создают типы данных, имеющие строгий размер, такие как __int8, __int16, INT32, word64 и так далее.
Даже после внесения исправлений, касающихся размеров типа, вы можете столкнуться с несовместимостью бинарных форматов. Причина кроется в ином представлении данных. Наиболее часто это связано с другой последовательностью байт.
Порядок байт — метод записи байтов многобайтовых чисел (см. рисунок 26). Порядок от младшего к старшему (англ. little-endian) — запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86 и x86-64-процессорами. Порядок от старшего к младшему (англ. big-endian) — запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком байтов (англ. network byte order). Этот порядок байт используется процессорами Motorola 68000, SPARC.
Кстати, некоторые процессоры могут работать и в порядке от младшего к старшему, и наоборот. К их числу относится, например IA-64.

Рисунок 26 — Порядок байт в 64-битном типе на little-endian и big-endian системах
Разрабатывая бинарный интерфейс или формат данных, следует помнить о последовательности байт. А если 64-битная система, на которую Вы переносите 32-битное приложение, имеет иную последовательность байт, то вы просто будете вынуждены учесть это в своем коде. Для преобразования между сетевым порядком байт (big-endian) и порядком байт (little-endian), можно использовать функции htonl(), htons(), bswap_64, и так далее.
Пример 27. Изменение выравнивания типов
Помимо изменения размеров некоторых типов данных, ошибки могут возникать и из-за изменения правил их выравнивания в 64-битной системе (см. рисунок 27).
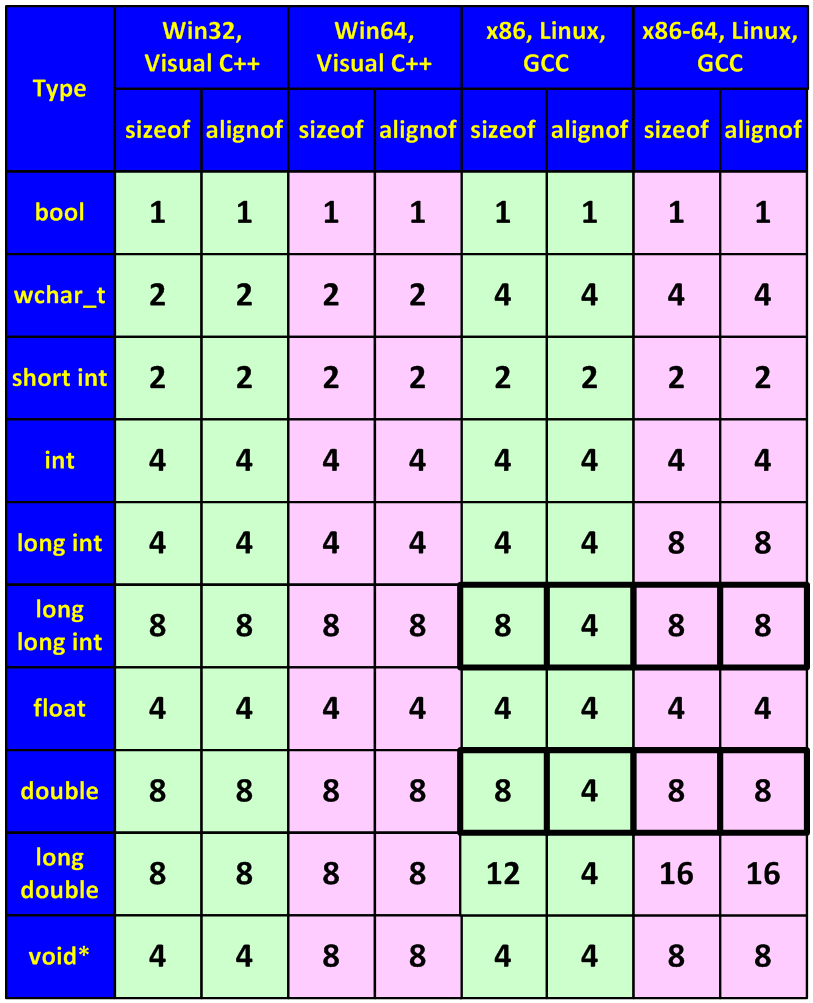
Рисунок 27 — Размеры типы и границы их выравнивания (значения точны для Win32/Win64, но могут варьироваться в «Unix-мире» и приводятся просто в качестве примера)
Рассмотрим пример описания проблемы, найденного в одном из форумов:
Столкнулся сегодня с одной проблемой в Linux. Есть структура данных, состоящая из нескольких полей: 64-битный double, потом 8 unsigned char и один 32-битный int. Итого получается 20 байт (8 + 8*1 + 4). Под 32-битными системами sizeof равен 20 и всё работает нормально. А под 64-битным Linux'ом sizeof возвращает 24. Т.е. идёт выравнивание по границе 64 бит.
Далее в форуме идут рассуждения о совместимости данных и просьба совета, как упаковать данные в структуре. Но не это сейчас интересно. Интереснее то, что здесь наблюдается очередной тип ошибки, который может возникнуть при переносе приложений на 64-битную систему.
Когда меняются размеры полей в структуре и из-за этого меняется сам размер структуры это понятно и привычно. Здесь другая ситуация. Размер полей остался прежний, но из-за иных правил выравнивания размер структуры все равно изменится (см. рисунок 28). Такое поведение может привести к разнообразным ошибкам, например в несовместимости форматов сохраняемых данных.
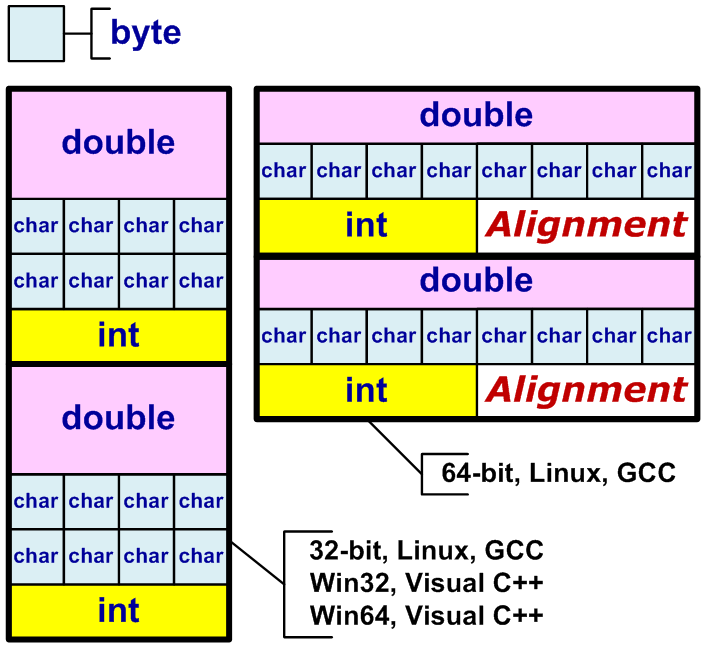
Рисунок 28 — Схематическое изображение структур и правил выравнивания типов
Пример 28. Выравнивания типов и почему нельзя писать sizeof(x) + sizeof(y)
Иногда программисты используют структуры, в конце которых расположен массив переменного размера. Эта структура и выделение памяти для нее может выглядеть следующим образом:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( sizeof(DWORD) + 5 * sizeof(PVOID) );
...Этот код будет корректно работать в 32-битном варианте, но его 64-битный вариант даст сбой.
При выделении памяти, необходимой для хранения объекта типа MyPointersArray, содержащего 5 указателей, необходимо учесть, что начало массива m_arr будет выровнено по границе 8 байт. Расположение данных в памяти на разных системах (Win32/Win64) показано на рисунке 29.
Рисунок 29 — Расположение данных в памяти в 32-битной и 64-битной системе
Корректный расчет размера должен выглядеть следующим образом:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( FIELD_OFFSET(struct MyPointersArray, m_arr) +
5 * sizeof(PVOID) );
...В приведенном коде мы узнаем смещение последнего члена структуры и суммируем это смещение с его размером. Смещение члена структуры или класса можно узнать с использованием макроса offsetof или FIELD_OFFSET. Всегда используйте эти макросы для получения смещения в структуре, не опираясь на свои предположения о размерах типов и правилах их выравнивания.
Пример 29. Перегруженные функции
При перекомпиляции программы может начать выбираться другая перегруженная функция (см. рисунок 30).
Рисунок 30 — Выбор перегруженной функции в 32-битной и 64-битной системе
Пример проблемы:
class MyStack {
...
public:
void Push(__int32 &);
void Push(__int64 &);
void Pop(__int32 &);
void Pop(__int64 &);
} stack;
ptrdiff_t value_1;
stack.Push(value_1);
...
int value_2;
stack.Pop(value_2);Неаккуратный программист помещал и затем выбирал из стека значения различных типов (ptrdiff_t и int). На 32-битной системе их размеры совпадали, все замечательно работало. Когда в 64-битной программе изменился размер типа ptrdiff_t, то в стек стало попадать больше байт, чем затем извлекаться.
Пример 30. Ошибки в 32-битных модулях, работающих в WoW64
Последний пример посвящен ошибкам в 32-битных программах, которые возникают при их выполнении в 64-битной среде. В состав 64-битных программных комплексов еще долго будут входить 32-битные модули, а следовательно необходимо обеспечить их корректную работу в 64-битной среде. Подсистема WoW64 очень хорошо справляется со своей задачей, изолируя 32-битное приложение, и практически все 32-битные приложения функционирует корректно. Однако иногда ошибки все же встречаются и в основном они связаны с механизмом перенаправления при работе с файлами и реестром Windows.
Например, в комплексе, состоящим из 32-битных и 64-битных модулей, при их взаимодействии следует учитывать, что они используют различные представления реестра. Таким образом, в одной из программ следующая строчка в 32-битном модуле стала неработоспособной:
lRet = RegOpenKeyEx(HKEY_LOCAL_MACHINE, "SOFTWARE\\ODBC\\ODBC.INI\\ODBC Data Sources", 0, KEY_QUERY_VALUE, &hKey);
Чтобы подружить эту программу с другими 64-битными частями, необходимо вписать ключ KEY_WOW64_64KEY:
lRet = RegOpenKeyEx(HKEY_LOCAL_MACHINE, "SOFTWARE\\ODBC\\ODBC.INI\\ODBC Data Sources", 0, KEY_QUERY_VALUE | KEY_WOW64_64KEY, &hKey);
Заключение
Наилучший результат при поиске описанных в статье ошибок дает методика статического анализа кода. В качестве примера инструмента осуществляющего такой анализ, можно назвать разрабатываемый нами инструмент Viva64, входящий в состав PVS-Studio.
Методы статического поиска дефектов позволяют обнаруживать дефекты по исходному коду программы. При этом поведение программы оценивается на всех путях исполнения одновременно. За счет этого, возможно обнаружение дефектов, проявляющихся лишь на необычных путях исполнения при редких входных данных. Эта особенность позволяет дополнить методы тестирования, повышая надежность программ. Системы статического анализа могут использоваться при проведении аудита исходного кода, для систематического устранения дефектов в существующих программах, и встраиваться в цикл разработки, автоматически обнаруживая дефекты в создаваемом коде.
Библиографический список
- Андрей Карпов, Евгений Рыжков. Уроки разработки 64-битных приложений на языке Си/Си++. http://www.viva64.com/ru/articles/x64-lessons/
- Андрей Карпов. Что такое size_t и ptrdiff_t. http://www.viva64.com/art-1-1-72510946.html
- Андрей Карпов, Евгений Рыжков. 20 ловушек переноса Си++ — кода на 64-битную платформу. http://www.viva64.com/art-1-1-1958348565.html
- Евгений Рыжков. Учебное пособие по PVS-Studio. http://www.viva64.com/art-4-1-1796251700.html
- Андрей Карпов. 64-битный конь, который умеет считать. http://www.viva64.com/art-1-1-1064884779.html
