
Генри Форд однажды сказал: «Лучшая машина — новая машина». Так и мы в группе компаний Тинькофф думаем про релизы софта. Инертность в процессе доставки фич и срочных фиксов рано или поздно приводит к большой технической задолженности перед заказчиком и чаще всего заканчивается стагнацией проекта в целом.
Гарантировать высокий показатель time to market, сохранив качество, — непростая задача. C моей точки зрения, нельзя сразу построить рельсы, по которым можно будет быстро и удобно доставлять изменения и спустя много месяцев после старта. Рост проекта обычно сопровождается ростом числа людей, работающих над ним, а значит, создает потенциальный источник хаоса внутри ваших релизов.
Наш опыт вряд ли стоит расценивать как инструкцию для достижения успеха, однако ряд идей показался мне достаточно интересным, чтобы поделиться с вами. Начнем.
Отправная точка нашей истории технически выглядит следующим образом. Система состоит из нескольких сервисов, кодовую базу которых шарит порядка 30 человек — несколько команд, которые разделяются по бизнес-направлениям, например обслуживание физических и юридических лиц. Я постараюсь вынести за скобки технические и архитектурные детали проекта, чтобы сфокусироваться на процессе самих релизов.
Мы работаем по Gitflow, поэтому статья будет прежде всего интересна тем, кто выбрал именно этот способ доставки.
Проблемы
Первая проблема, с которой мы столкнулись, связана с недостаточной автоматизацией процессов. Выполнение всех релизных активностей в нашей команде привязано к роли релизного менеджера (РМ).
Вот часть из них:
- Отведение релизных веток и создание тэгов.
- Слияние с master- и develop-ветками.
- Сборка и деплой артефактов, которые входят в релиз.
- Коммуникация со специалистами, принимающими участие в процессе, — например, с QA или админами.
Эти рутинные задачи требуют все больше и больше ресурсов по мере расширения проекта (в нашем случае — увеличения числа сервисов), поэтому первым шагом стоит автоматизировать все, что можно автоматизировать. Интегрируемся с CI/CD-тулой для того, чтобы по кнопке отводить и сливать релизные ветки, запускать тестовые сборки и деплоить артефакты; с task-tracking-тулой и корпоративным мессенджером для своевременной нотификации участника, ответственного за выполнение следующего шага — например, поменять статус задачи и настроить хук для отправки уведомления.


Релизному менеджеру все еще придется вручную резолвить потенциальные конфликты, возникающие при слиянии веток, однако быстрые и частые релизы должны свести их количество на нет.
Следующая проблема связана с тестированием.
Один из критериев сборки для нас — успешное выполнение тестов. Принято делить тесты, как минимум, на два вида: unit и интеграционные.
Unit-тесты позволяют проверить на корректность отдельные модули исходного кода программы, что на практике чаще всего сводится к проверке одного или нескольких методов, имеющих очевидную логическую связь.
Интеграционные тесты обычно проверяют работоспособность целого каскада таких модулей, то есть функционирование целой фичи со стороны клиента. Например, если в задаче был реализован rest-интерфейс, то мы проверим работоспособность авторизации, десериализацию самого запроса, валидность переданных полей, интеграцию с другими сервисами и базами данных, а также саму бизнес-логику. На первый взгляд может показаться, что такие тесты весьма самодостаточны и способны покрыть все потенциальные проблемные места. Не нужно разбираться, как работает каждый отдельный кирпичик, а вызываемый интерфейс инкапсулирует всю логику для того, чтобы на выходе получить простой ответ: работает или не работает.
На самом же деле они создают ряд отложенных проблем, вот часть из них:
- Участие большого числа тестируемых компонентов пропорционально влияет на время сборки и исполнения таких тестов.
- Инкапсуляция проверяемой логики часто приводит к тому, что бывает трудно гарантировать правильность результата тестирования. Часто мы подгоняем тест под результат, а еще чаще результат соответствует ожиданию из-за случайных сайд-эффектов.
- Теряется актуальность тестовых данных.
- Интеграциям со сторонними системами, особенно на тестовом окружении, часто свойственно падать. Это сводит на нет потраченное на прогон время, так как не всегда очевидно: это временное падение или поломка, вызванная нашими изменениями.
Для большинства проблем уже придумали решение. Но, как обычно бывает, решения не приходят без дополнительных ограничений или новых проблем.
Выбрать подходящие вам тесты и правильно их реализовать — очень непростая задача. Кроме того, важно найти баланс между качеством покрытия и скоростью сборок, чтобы оптимизировать ваши релизы.
В нашем случае мы остановились на гибриде. Мы продолжаем поднимать все необходимые компоненты для полного тестирования фичи, попутно мо́кая все возможные интеграции. Для сохранения контрактов API используем Pact, а для проверки интеграции с БД — Testcontainers.
Такой подход к написанию тестов в результате вылился в решение третьей проблемы — продолжительное время на ручное тестирование задачи. Стабильность гибридных тестов привела к появлению идеи привлечения QA-инженера на этапе спецификации задачи для составления тест-кейсов — это позволит пропускать их на этапе ручного тестирования. Интеграция с такими полезными продуктами, как TestRail и Allure стала своеобразным мостиком между разработчиком и тестировщиком. Создаётся контракт, выполнение которого пошагово отражается в сгенерированном при тестовой сборке отчете.
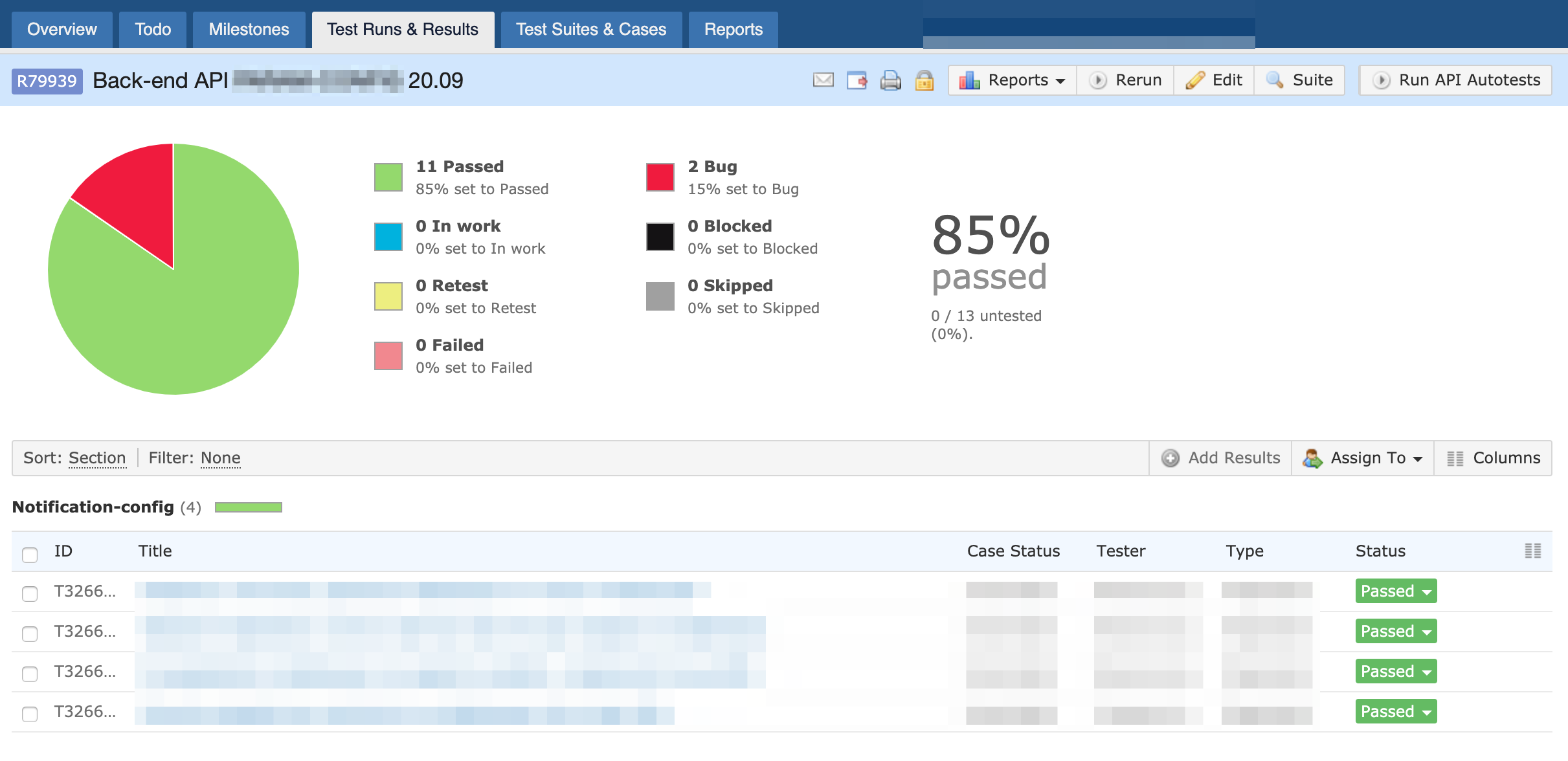


Осталось подключить отчеты к вашей task-tracking-туле для прозрачного отслеживания задачи. Наглядная история также позволит сократить время на составление и реализацию тестов для будущих связанных задач.
Таким образом, QA-инженеры экономят достаточно времени для того, чтобы сфокусироваться на проверке исключительных кейсов и интеграции с другими системами.
С этим связана последняя проблема. Для ручного тестирования все задачи сливаются из feature-веток в develop и запускают деплой на тестовый стенд.
Во-первых, при таком подходе нельзя говорить о чистом тестировании фичи, так как параллельно в develop могут попасть связанные изменения других разработчиков.
Во-вторых, при отведении релизной ветки может оказаться, что QA не успели протестировать часть задач. Встает выбор: откатывать изменения, затронутые этими задачами, или притормозить релиз до конца тестирования.
Такой выбор придется делать постоянно, если только вы не изолируете ваше тестовое окружение. Важно, чтобы в тестируемом компоненте не было никаких изменений, кроме внесенных задачей. В нашем случае нужно иметь возможность поднимать один или несколько сервисов, в ветки которых попали изменения, и управлять роутингом внутри кластера, направляя на эти инстансы только необходимые нам запросы от QA. Задача усложняется, если на кластере уже используются механизмы балансировки, которые тоже придется учитывать.
Реализовав такую возможность, мы стали проводить ручное тестирование прямо на отдельных feature-ветках: деплоить нужный сервис на время тестирования, изолированно встраиваясь в общее окружение. Сливая только готовые задачи в develop-ветку и избавившись от блокировок, мы сами начали определять, каким изменениям стоит попадать в релиз, а каким — нет.
Стоит отметить, что такое решение вряд ли станет серебряной пулей для тех команд, которые вносят изменения практически в одни и те же файлы. В таком случае складирование фич обратно пропорционально количеству возникающих конфликтов при слиянии. На практике при достаточно частых релизах такое случается крайне редко в команде с пятьюдесятью разработчиками.
Вместо вывода
Резюмируя, можно выделить основные подходы, которые могут помочь с ускорением релизов:
- Автоматизация рутинных операций.
- Прозрачность процессов для всех принимающих участие.
- Необходимый баланс между скоростью и качеством в написании автоматизированных тестов.
- Сокращение времени на ручное тестирование.
- Изоляция окружения для тестирования.
Важно понимать, что в выборе тех или иных подходов, принципов и стратегий всегда стоит отталкиваться от контекста вашей проблемы. Существует масса не менее надежных и более изысканных способов для ускорения доставки вашего софта клиенту. Попытка реагировать на вновь возникающие сложности и привела к описанным выше выводам. Для нас же они стали первым шагом к более смелому подходу к выпуску релизов.
