 или простой способ создания консистентныx резервныx копий без остановки сервера с помощью клонирования виртуальных машин
или простой способ создания консистентныx резервныx копий без остановки сервера с помощью клонирования виртуальных машинИдеальный бэкап в вакууме
Системный администратор, настраивая резервирование данных на сервере, рисует в своем воображении прекрасные образы. Скрипт резервного копирования добросовестно складывает данные в архив, где они лежат в сохранности, внушают спокойствие. Случается катаклизм, в результате которого информация на дисках превращаются в тоскливую последовательность нулей без единой единицы. Нарастает паника, директор запирается в своем кабинете с пистолетом. И тут появляется герой, хладнокровно восстанавливает данные из последней резервной копии и через пол-часа сервер работает как ни в чем не бывало. Под торжественную музыку герой уходит в закат.
Грубая реальность вносит коррективы: если при настройке копирования не предусмотреть множество мелочей, то при восстановлении может случиться так, что часть данных в бэкапе окажется повреждена непонятным образом. Легкое восстановление превратится в мучительные поиски кусочков в разных архивах и собирание из них одного целого. Уход в закат откладывается из-за нарушенной консистентности копии.
Неконсистентность копии
Понятие неконсистентности копии означает то, что вместо единого массива данных, отражающих состояние оригинала в один момент времени, копия состоит из нескольких частей, отражающих состояние соответствующих частей оригинала в разные моменты времени.
 Например, если мы одновременно увеличиваем один и тот же счетчик в двух разных файлах, то в неконсистентной копии эти файлы могут иметь несовпадающее значение. Другой пример, если по дороге идет человек с конем и мы решили их скопировать, то в неконсистентной копии вместо них по дороге будет один кентавр.
Например, если мы одновременно увеличиваем один и тот же счетчик в двух разных файлах, то в неконсистентной копии эти файлы могут иметь несовпадающее значение. Другой пример, если по дороге идет человек с конем и мы решили их скопировать, то в неконсистентной копии вместо них по дороге будет один кентавр.Как появляются кентавры
Самый простой и популярный способ резервного копирования — пофайловое копирование файловой системы. В архиве может сохраняться полная копия, создаваемая tar или cpio, или инкрементная с помощью dump, rsync, bacula. Все файлы файловой системы поочередно обходятся, возможно, проверяются на удовлетворение неким правилам и копируются в архив.
Первая очевидная причина нарушения консистентности — изменение файлов, происходящее во время копирования. Сервер продолжает выполнять свои обычные задачи, файлы создаются, обновляются, удаляются. Чем дольше длится копирование, чем больше объем всех данных, чем больше скорость изменения данных в оригинале — тем большая получается неконсистентность копии. В одних случаях это будет малокритично — например, если ночью копируется корпоративный веб-сайт, на котором в это время изменяются только логи. А вот если в это время записывались изменения в репозиторий SVN, то не смотря на то, что SVN использует транзакции, после восстановления из такого бэкапа можно столкнуться с потерей или перемешиванием версий у произвольных компонентов.
Как создаются клоны
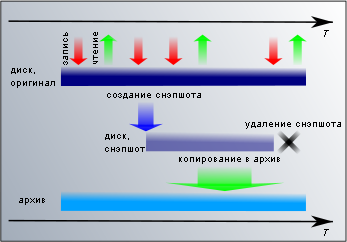 Для решения этой проблемы существует универсальная схема — клонирование диска или файловой системы, мгновенные снимки (snapshot). Реализации ее могут быть разными — например, с средствами самой файловой системы в UFS и ZFS, или уровнем ниже, на блочном устройстве в LVM/DeviceMapper или VHD. Со стороны пользователя это выглядит так, как будто в требуемый момент операционная система создает вторую копию файловой системы или блочного устройства. На создание снимка времени требуется очень мало (от нескольких миллисекунд до секунд), поэтому без ущерба для работы приложений блокируются все операции записи. В период создания снэпшота никаких изменений не происходит и копия получается консистентная.
Для решения этой проблемы существует универсальная схема — клонирование диска или файловой системы, мгновенные снимки (snapshot). Реализации ее могут быть разными — например, с средствами самой файловой системы в UFS и ZFS, или уровнем ниже, на блочном устройстве в LVM/DeviceMapper или VHD. Со стороны пользователя это выглядит так, как будто в требуемый момент операционная система создает вторую копию файловой системы или блочного устройства. На создание снимка времени требуется очень мало (от нескольких миллисекунд до секунд), поэтому без ущерба для работы приложений блокируются все операции записи. В период создания снэпшота никаких изменений не происходит и копия получается консистентная.Годятся ли снэпшоты в качестве резервных копий? Для краткосрочный нужд — да. Например, перед какими-нибудь рискованными обновлениями будет полезно сделать снэпшот и, если что-то пойдет не так, откатить состояние по этому снэпшоту, а если все закончится хорошо, то снэпшот можно удалить. Использование снэпшотов имеет свою цену — замедление дисковых операций, увеличение расхода места на диске. Поэтому долговременное использование снэпшотов должно приносить пользы больше, чем будет теряться производительности. Для резервного копирования снэпшоты не годятся еще потому, что находятся там же, где и оригинал. Если пострадает оригинал, то с высокой вероятностью пострадает и копия.
В резервировании снэпшоты используются в качестве неизменной файловой системы, которую можно копировать в удаленное хранилище сколь угодно долго и консистентность копии в конце копирования нарушена не будет. Копирование может выполняться теми же самыми dump/tar/rsync/bacula. После того, как снэпшот использован, его удаляют, чтобы не тратить впустую ресурсы.
Консистентность данных сервера
Решает ли это задачу чистого восстановления? Только частично. Мы получаем консистентную копию файловой системы, но не получаем консистентную копию всей информации сервера. Ведь есть еще приложения, которые оперируют данными в оперативной памяти и сохраняют их на диске. В памяти данные приложения консистентны, но записанные на диск — не обязательно. Информация записывается в файл в том порядке, в котором это удобно для приложения и операционной системы. Точка зрения системы резервирования об этом порядке приложение не интересует. Состояние копии соответствует состоянию диска сервера после внезапного отключения, например, обесточивания.
Для веб-проектов потенциальная жертва неконсистентности — базы данных MySQL. Допустим, у нас активный проект с большим числом обновлений данных, в таблицы постоянно записываются данные. Сервер БД держит данные таблиц в оперативной памяти, периодически сбрасывая изменения на диск. К этому присоединяется еще операционная система, которая может задерживать данные в буферах записи, исходя из собственных соображений о том, что нужно для повышения производительности. Если мы сделаем в этот момент консистентную копию файловой системы, то в разных таблицах могут оказаться данные, актуальные на разные моменты времени, а в некоторых таблицах может быть нарушена целостность данных, если они в этот момент переносились в другое место.
Это приводит нас к необходимости учитывать особенности работы каждого приложения, изменяющего данные на сервере. И адаптировать процесс создания резервных копий, заставляющие каждое приложение, изменяющее данные, сохранять их на диск перед созданием копии и воздержаться от их изменения во время копирования. Для сервера MySQL это заключается в блокировании таблиц на запись и сбросе изменений на диск одной командой
FLUSH TABLES WITH READ LOCK, из разблокировании таблиц после создания копии командой UNLOCK TABLES. А если это Java-приложение со сторонними компонентами, об особенностях работы которых ничего не известно, ситуация осложняется и остается только полная остановка приложения. Для Windows-приложений предлагается специальный механизм Quiesce, с помощью которого операционная система дает знать приложениям, что она начинает бэкап и им нужно сбросить свои данные на диск или каким-то другим образом привести их на диске в консистентное состояние.На практике, именно эта часть либо часто упускается из виду при настройке резервного копирования, либо сисадмин (или разработчик) сознательно отказывается от дополнительных настроек, если считает, что риск в его ситуации незначительный и он не стоит дополнительных затрат на усложнение сценария копирования.
Виртуальные клоны виртуальных машин
Виртуальные машины за последние годы стали привычны и на десктопе, и на сервере. Прогресс делает жизнь людей более комфортной. Более комфортной он делает и жизнь системных администраторов. Серверные виртуальные машины удобно использовать для абстракции оборудования, для эффективного и плотного использования аппаратных ресурсов, для удобного администрирования большого числа функционально различных серверов, объединенных на небольшом количестве физических серверов. А еще виртуализация позволяет делать идеальный бекап, без мифических существ и фантастических мутантов.
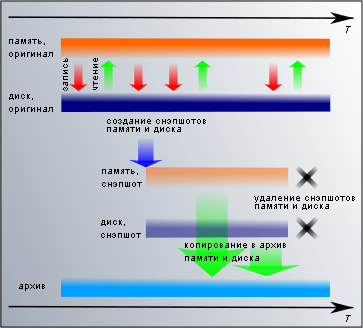 Многие среды виртуализации позволяют сохранить снимок работающей виртуальной машины (в отличие от диска, для этого чаще используется термин checkpoint, а не snapshot — чтобы не путать снимок памяти со снимком диска). В основном, они предназначены для разработки и тестирования, например, для сохранения состояние работающего сервера перед обновлением, чтобы при неудачном исходе откатиться назад. А с точки зрения резервного копирования, снимок памяти и диска является консистентной копией всех данных сервера. Таким образом, инструмент для получения идеального бэкапа у нас есть, и его нужно правильно применить.
Многие среды виртуализации позволяют сохранить снимок работающей виртуальной машины (в отличие от диска, для этого чаще используется термин checkpoint, а не snapshot — чтобы не путать снимок памяти со снимком диска). В основном, они предназначены для разработки и тестирования, например, для сохранения состояние работающего сервера перед обновлением, чтобы при неудачном исходе откатиться назад. А с точки зрения резервного копирования, снимок памяти и диска является консистентной копией всех данных сервера. Таким образом, инструмент для получения идеального бэкапа у нас есть, и его нужно правильно применить.В Citrix XenServer (включая XenServer Free) и XCP для создания снимка виртуальной машины с памятью и диском используется команда
xe vm-checkpoint. На время создания снимка работа виртуальной машины приостанавливается и после завершения продолжается. Снимок готов и находится в хранилище, но в таком виде его ценность как резервной копии невелика — как и в случае с снэпшотами диска, то, что хранится вместе с оригиналом, может пострадать вместе с оригиналом. Для получения копии, которую можно будет хранить где угодно, нужно воспользоваться командой xe vm-export, которая на выходе сохраняет память и диск виртуальной машины в xva-файл.Xen Hypervisor 4 в виде xend+xm, при размещении дисков машин на LVM, позволяет делать примерно то же самое. Стандартная команда
xm save -c (сохранение с checkpoint) позволяет сохранить снимок памяти и продолжить затем работу виртуальной машины. Снимок диска при этом не создается, предполагая что этим займется кто-то другой. Первое приходящее в голову решение — поставить домен на паузу, сделать снэпшот диска, и только после этого делать снэпшот виртуальной машины. Но оно не пройдет, для того, чтобы домен мог сохраняться, Xen требует, чтобы он был в рабочем состоянии. Есть несколько способов решить эту задачу, для нас в итоге самым удобным оказался вариант с небольшой модификацией xend (можно взять наш сокращенный патч для Debian 6 с Xen 4.0 и при необходимости доработать под свои нужды: www.truevds.ru/misc.xen-checkpoint-clone-patch). Для этого достаточно указать в коде функции, ответственной за создания checkpoint, что в конфигурации сохраняемой виртуальной машины используются снэпшоты дисков, а не их оригиналы, и перед возобновлением работы виртуальной машины сделать эти снэпшоты стандартным способом LVM. После этого у нас будет файл со снимком памяти виртуальной машины и раздел LVM со снимком диска.Кроме основанных на Xen систем виртуализации, аналогичные возможности предоставляет VMWare и Hyper-V. В их терминологии checkpoint называется snaphost.
Хороший клон — выключенный клон
 Хранить в архиве полные копии памяти и дисков виртуальной машины не очень накладно, если это какой-то маленький сервер с маленькими данными. Если пытаться использовать эту схему для чего-то серьезного, скажем, production-сервера для посещаемого сайта с оперативной памятью 8 Гб и объемом данных на диске около 100 Гб, передача по сети и хранение 108 Гб на каждую копию быстро сделают цену резервирования непомерно высокой.
Хранить в архиве полные копии памяти и дисков виртуальной машины не очень накладно, если это какой-то маленький сервер с маленькими данными. Если пытаться использовать эту схему для чего-то серьезного, скажем, production-сервера для посещаемого сайта с оперативной памятью 8 Гб и объемом данных на диске около 100 Гб, передача по сети и хранение 108 Гб на каждую копию быстро сделают цену резервирования непомерно высокой.Самый удобный способ хранения большого числа архивных копий — инкрементные бэкапы. Во время очередного копирования в архиве записывается не полная копия файловой системы, а только изменения, произошедшие после предыдущего копирования. Для этого нам требуется консистентная файловая система в которой находятся консистентные данные сервера.
Есть единственное состояние сервера, в котором данные на диске сохранены приложениями максимально корректно и в оперативной памяти не меняются. Это состояние — корректно остановленный сервер. Все приложения, хоть как-то заботящиеся о сохранности своих данных, ценят и с готовностью подчиняются, когда операционная система просит их завершить свою работу — через stop-скрипты или через отправку сигнала SIGTERM. Файловая система остановленного таким образом сервера и является максимально возможным консистентным состоянием всех данных сервера.
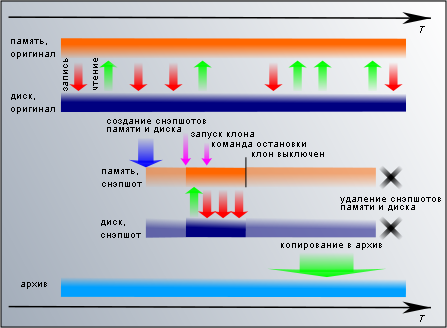 Нам нужна файловая система в таком состоянии. У нас есть клон — снэпшот виртуальной машины и снэпшот диска. Нам нужно запустить виртуальную машину клона и дать его операционной системе команду остановки (shutdown). В XenServer/XCP для этого нужно будет конвертировать снэпшот в темплейт командой
Нам нужна файловая система в таком состоянии. У нас есть клон — снэпшот виртуальной машины и снэпшот диска. Нам нужно запустить виртуальную машину клона и дать его операционной системе команду остановки (shutdown). В XenServer/XCP для этого нужно будет конвертировать снэпшот в темплейт командой xe snapshot-copy и затем стартовать новую машину на этом темплейте. Xen Hypervisor достаточно запустить машину через xm restore.Клон не должен иметь возможность навредить оригиналу. В качестве диска клон использует собственный снимок (в xend/xm по умолчанию это не так, но исправляется упомянутым ранее патчем, сохраняющим снимок виртуальной машины) — диск оригинала клону не доступен. Но если оригинал работал с сетью, то и у клона будет сетевой интерфейс с такими же настройками. При включении возникнет конфликт между клоном и оригиналом за право общения с внешним миром. Поэтому сетевой интерфейс клона нужно деактивировать или изолировать внутри отдельной виртуальной сети, не выходящей в реальную. Метод остановки сервера зависит от того, как он сконфигурирован и чаще всего для PV-машины будет достаточно команды
xm shutdow, а для HVM отправки ACPI power off.После отключения виртуальную машину клона можно удалить, и у нас остается снэпшот диска с чисто выполненной остановкой. Это будет файловая система с чистейшей консистентностью. Ее можно со спокойной душой отправлять в архив тем же методом, которым копируются обычные снэпшоты диска.
Цена победы
Есть мелкие трудности, связанные с тем, что для запуска клонов нужна оперативная память, которой вдруг может быть недостаточно; работа машины приостанавливается на время сохранения памяти. Их решение во много зависит от конкретных обстоятельств. Например, если мы, как порядочные люди, делаем резервирование ночью, то мы можем безболезненно отнять перед снимком у оригинала половину памяти и стартовать клона на освободившейся половине. Небольшая модификация xend позволяет делать снимок памяти даже без приостановки виртуальной машины (в XCP это тоже технически возможно, скорее всего у разработчиков просто пока не дошли до него руки).
Переносить серверы в виртуальные машины для высоконагруженного интернет-проекта может быть лишним. Имея десятки или сотни однотипных серверов, будет практичнее отладить до мелочей и унифицировать процедуру резервного копирования средствами приложений, воплотив потом ее одну множество раз, чем тратить небольшой процент ресурсов на накладные расходы виртуализации.
 Для интернет-проектов меньшего масштаба или для разношерстного набора корпоративных серверов, затраты на организацию чистого резервирования с помощью виртуализации окажутся наименьшими в большинстве случаев. В итоге мы получаем возможность делать нормальные консистентные бэкапы сервера не занимаясь подгонкой сценариев резервирования под все многообразие приложений. При этом уменьшается риск, что какой-то из компонентов будет забыт или не сработает. Герой, восстановив сервер за десять минут, поскачет в закат на коне, без риска превратиться в кентавра.
Для интернет-проектов меньшего масштаба или для разношерстного набора корпоративных серверов, затраты на организацию чистого резервирования с помощью виртуализации окажутся наименьшими в большинстве случаев. В итоге мы получаем возможность делать нормальные консистентные бэкапы сервера не занимаясь подгонкой сценариев резервирования под все многообразие приложений. При этом уменьшается риск, что какой-то из компонентов будет забыт или не сработает. Герой, восстановив сервер за десять минут, поскачет в закат на коне, без риска превратиться в кентавра.