На сегодняшний день существует классическая, с точки зрения аналитики, задача — анализ CDR телефонии. В рамках данной статьи мы расскажем о том, как две разные компании решали две совершенно разные задачи. Компания X анализировала CDR Cisco телефонии, а компания Y — CDR Asterisk телефонии. Почему мы пишем об этом в одной статье? Потому что в качестве инструмента для анализа обе компании используют Splunk, о котором мы много писали ранее.

Под катом вы найдете подробное описание задач и их решения с картинками и запросами.
Задачи
Компания X имеет порядка 30 департаментов, в которых порядка 400 внутренних номеров и около 100 000 звонков в месяц.
Компания Y имеет колл-центр на базе Asterisk телефонии с 1 млн звонком в день и хочет получать аналитику о его работе. Больше всего компания Y хочет знать количество конкурентных звонков (занятых time слотов) в определенный квант времени (например в каждый час), с распределением по внешним потокам. Плюс базовые kpi, такие как: средняя продолжительность звонков, средняя продолжительность разговора, процент отвеченных вызовов и прочее.
В данной статье мы не будем рассказывать о том как подключить данные Splunk и как сделать разбор полей (если интересно именно это, напишите нам — и мы сделаем отдельную статью об этом, но на самом деле никакого rocket science там нет). Мы покажем основные запросы, графики и дашборды.
Компания X
Аналитика по всей организации:
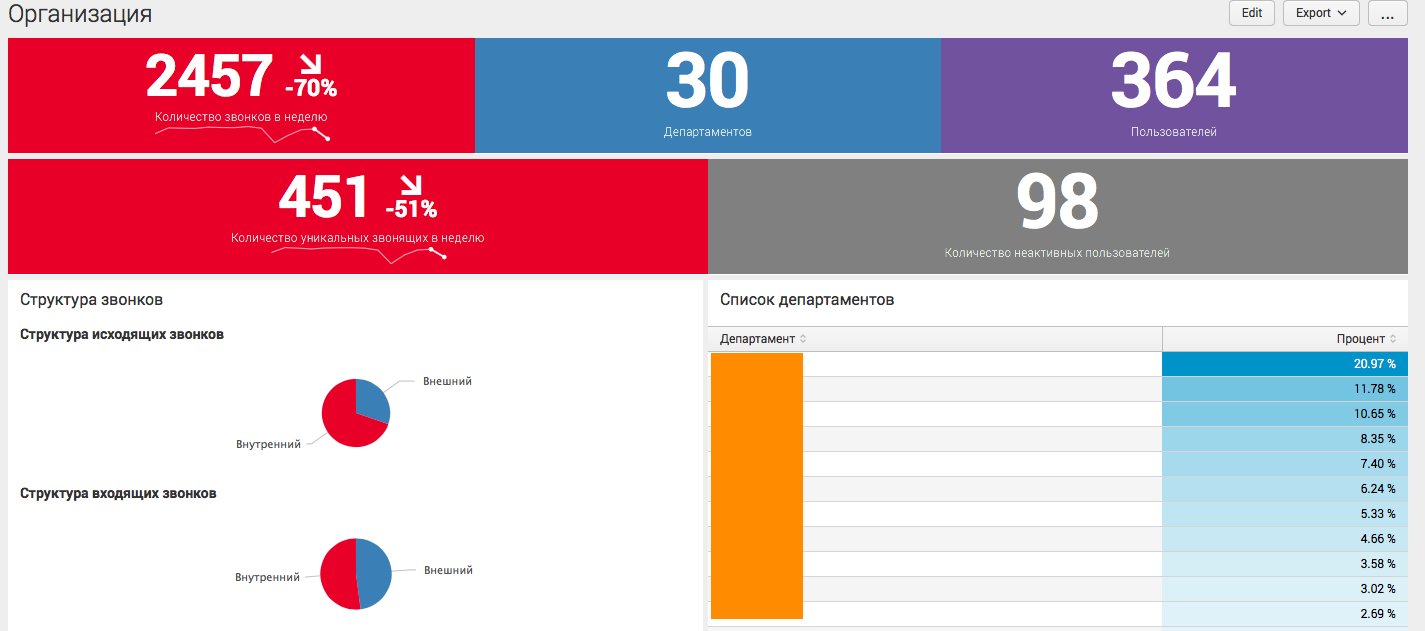
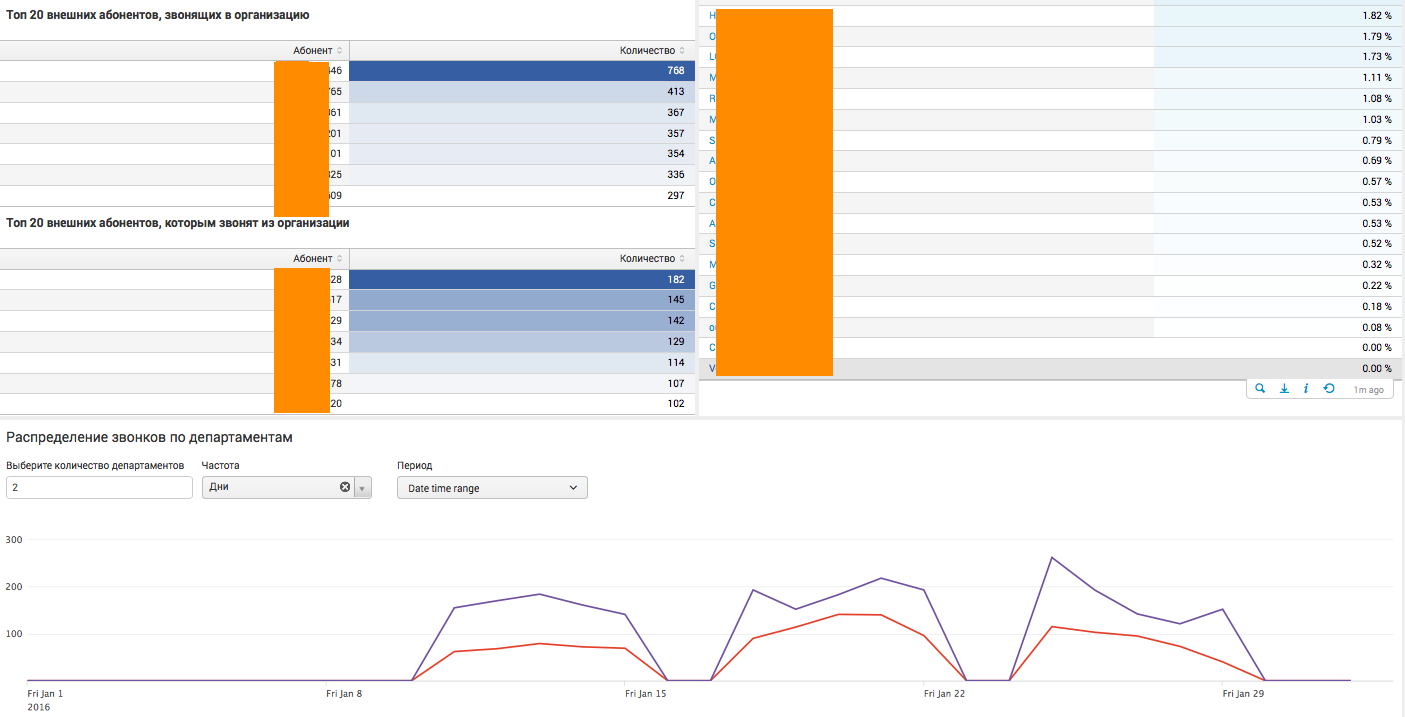
На данном дашборде собрана общая аналитика по всей компании в целом, с различными статистическими показателями. Дашборд живой, то есть имеет различные фильтры, а также может отправить пользователя на следующий уровень детализации. К примеру, при нажатии на определенный департамент или номер телефона, пользователь увидит аналитику в разрезе выбранного сегмента.
Аналитика в рамках отдельного департамента:
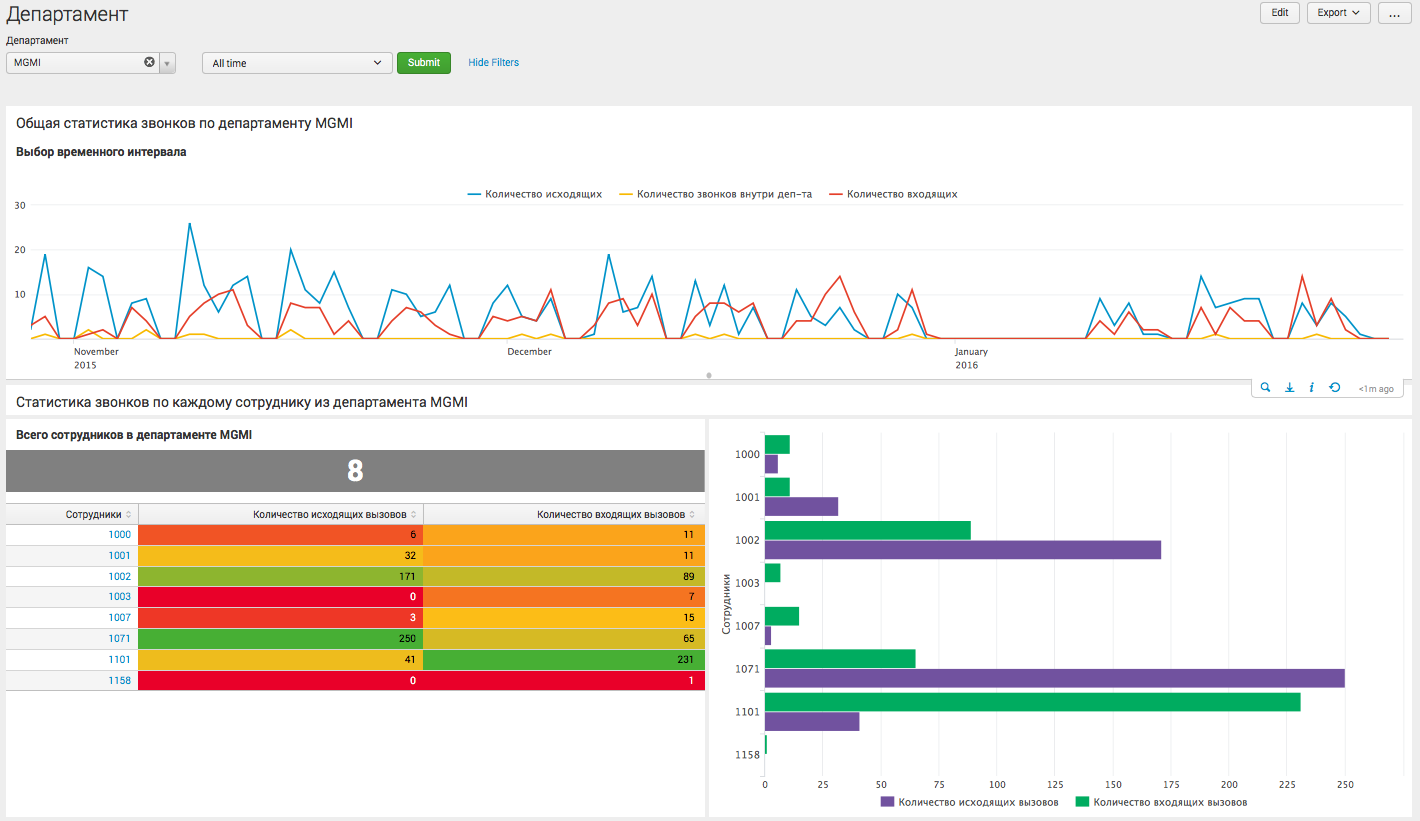
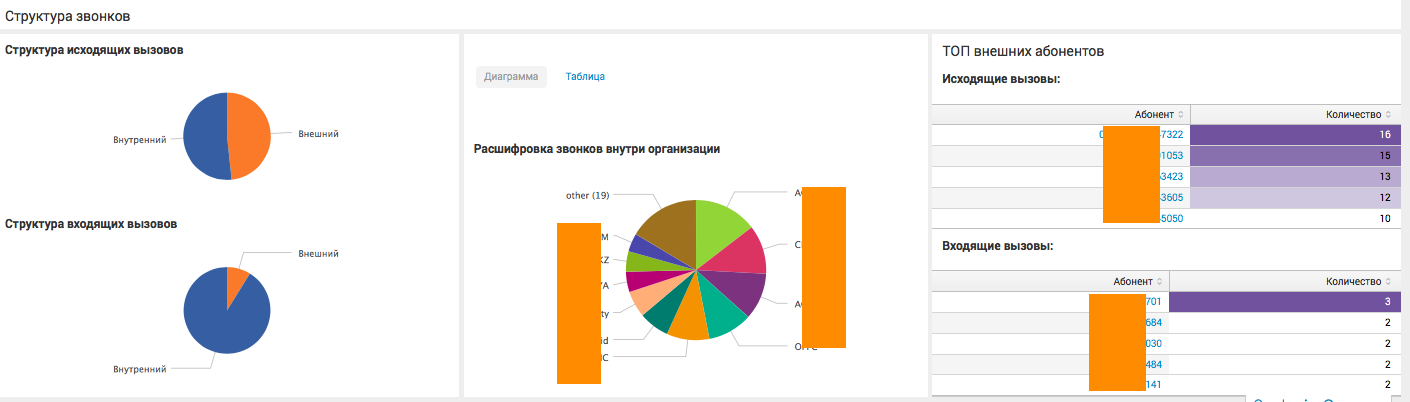
На этом дашборде пользователь видит детализацию по конкретному департаменту компании, и может сделать вывод как о статистике взаимодействия сотрудников данного отдела с другими внутренними департаментами, так и о внешних вызовах.
Аналитика по конкретному пользователю:
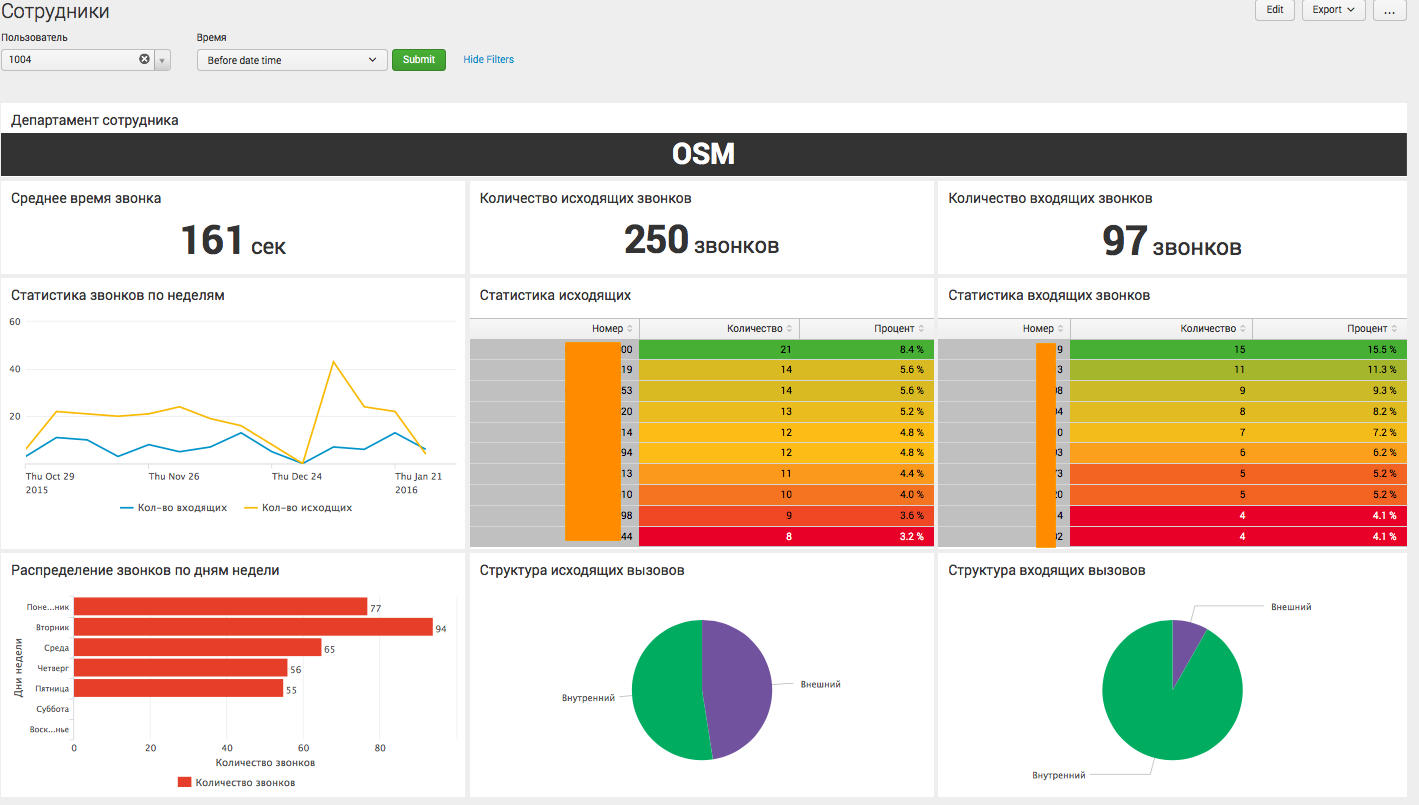
Это последний уровень детализации, где мы видим информацию, касающуюся определенного сотрудника организации, и можем судить о его активности.
Запросы
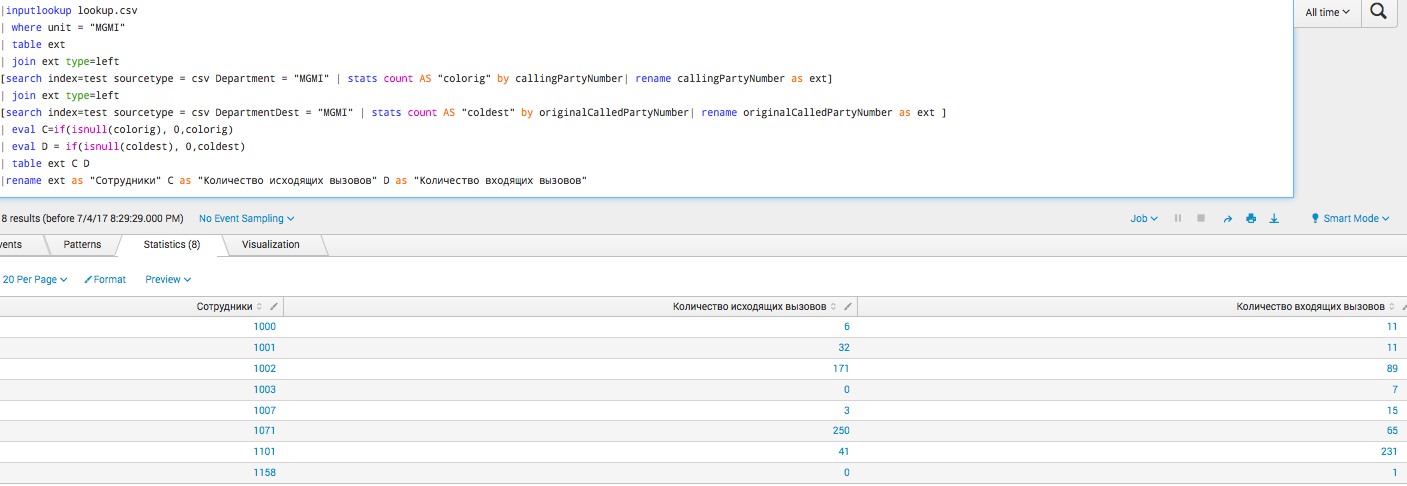
На самом деле все эти графики построены на достаточно простых запросах, уровень сложности сравним с теми, что мы обсуждали в наших предыдущих статьях. Ниже один из наиболее сложных:
Компания Y
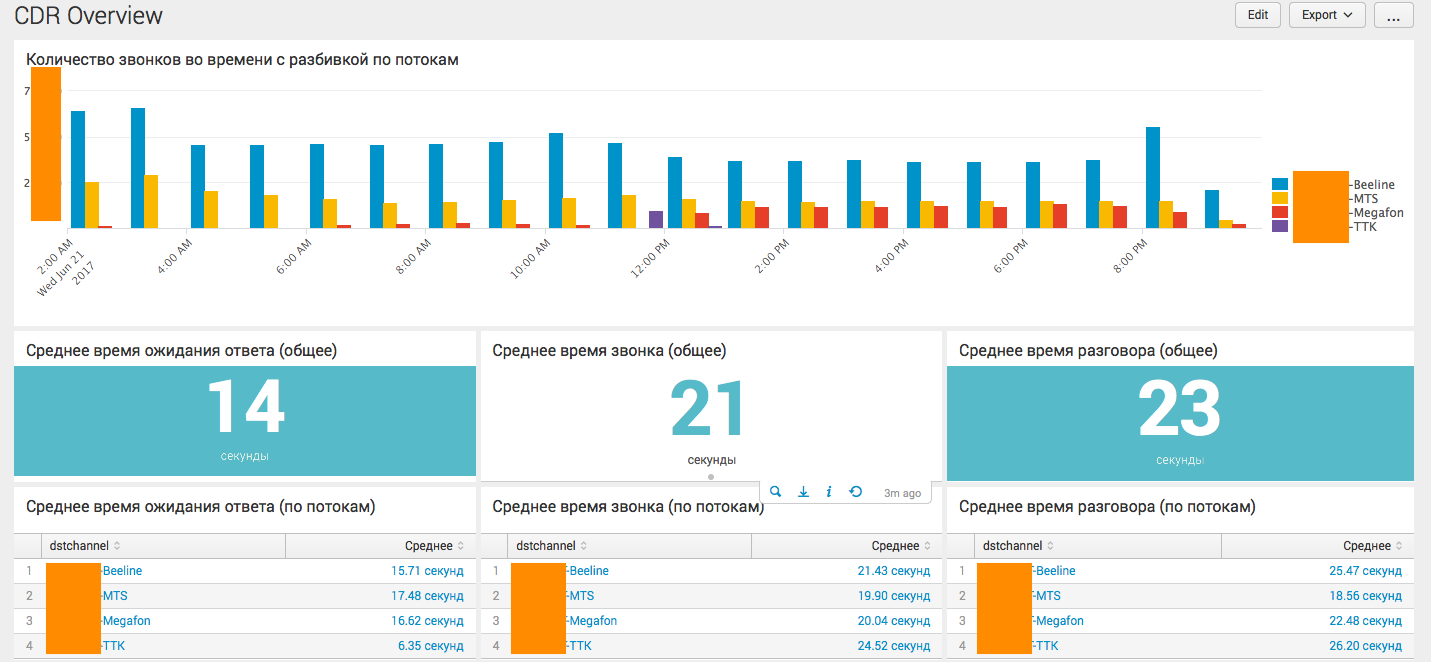
Здесь все намного проще, так как у колл-центра есть только один тип звонков, да и компанию в большей степени интересует только сводная информация. Однако, возможность дороботки и детализации не исключена, например по конкретному сотруднику. Ниже основной дашборд на основе CDR Asteriska:
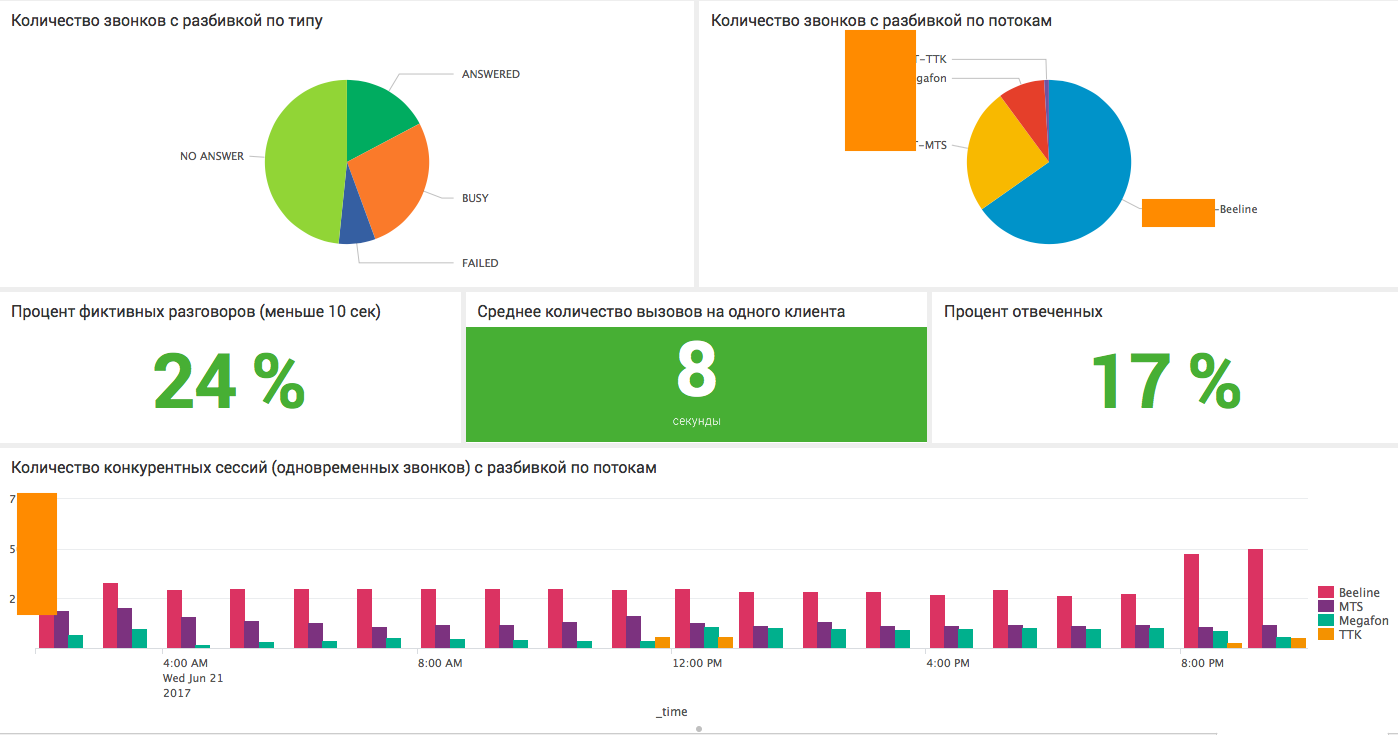
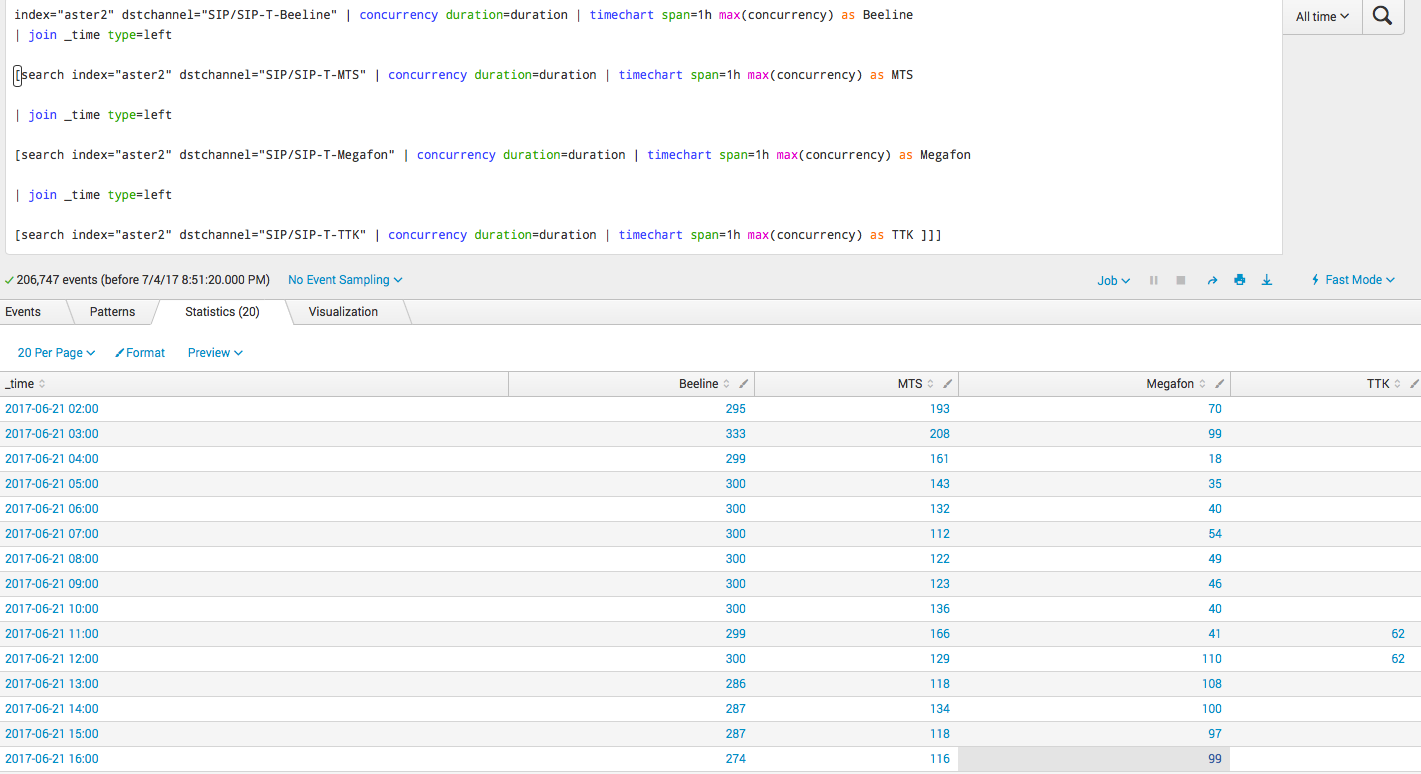
Наиболее интересным является самый нижний график, где решается задача по вычислению конкурентных сессий.
Запросы
Ниже один из наиболее сложных запросов, как раз про конкурентные сессии:
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Под катом вы найдете подробное описание задач и их решения с картинками и запросами.
Задачи
Компания X имеет порядка 30 департаментов, в которых порядка 400 внутренних номеров и около 100 000 звонков в месяц.
- Компания X хочет получать аналитику звонков внутренних пользователей как наружу так и между собой. Необходимо получать информацию о количестве телефонных звонков, количестве звонящих пользователей, распределении входящих и исходящих звонков, самых звонящих абонентах внутри/извне.
- Необходимы отчеты, показывающие как сотрудники из различных департаментов взаимодействуют с контрагентами. Зачастую такую задачу тяжело объективно решить на основании опросов, а благодаря анализу телефонных звонков можно получить максимально объективную картину.
- Необходимо оценить интенсивность звонков, для понимания активности работы менеджеров внутри организации.
Компания Y имеет колл-центр на базе Asterisk телефонии с 1 млн звонком в день и хочет получать аналитику о его работе. Больше всего компания Y хочет знать количество конкурентных звонков (занятых time слотов) в определенный квант времени (например в каждый час), с распределением по внешним потокам. Плюс базовые kpi, такие как: средняя продолжительность звонков, средняя продолжительность разговора, процент отвеченных вызовов и прочее.
Решения задач
В данной статье мы не будем рассказывать о том как подключить данные Splunk и как сделать разбор полей (если интересно именно это, напишите нам — и мы сделаем отдельную статью об этом, но на самом деле никакого rocket science там нет). Мы покажем основные запросы, графики и дашборды.
Компания X
Аналитика по всей организации:
На данном дашборде собрана общая аналитика по всей компании в целом, с различными статистическими показателями. Дашборд живой, то есть имеет различные фильтры, а также может отправить пользователя на следующий уровень детализации. К примеру, при нажатии на определенный департамент или номер телефона, пользователь увидит аналитику в разрезе выбранного сегмента.
Аналитика в рамках отдельного департамента:
На этом дашборде пользователь видит детализацию по конкретному департаменту компании, и может сделать вывод как о статистике взаимодействия сотрудников данного отдела с другими внутренними департаментами, так и о внешних вызовах.
Аналитика по конкретному пользователю:
Это последний уровень детализации, где мы видим информацию, касающуюся определенного сотрудника организации, и можем судить о его активности.
Запросы
На самом деле все эти графики построены на достаточно простых запросах, уровень сложности сравним с теми, что мы обсуждали в наших предыдущих статьях. Ниже один из наиболее сложных:
|inputlookup lookup.csv
| where unit = "MGMI"
| table ext
| join ext type=left
[search index=test sourcetype = csv Department = "MGMI" | stats count AS "colorig" by callingPartyNumber| rename callingPartyNumber as ext]
| join ext type=left
[search index=test sourcetype = csv DepartmentDest = "MGMI" | stats count AS "coldest" by originalCalledPartyNumber| rename originalCalledPartyNumber as ext ]
| eval C=if(isnull(colorig), 0,colorig)
| eval D = if(isnull(coldest), 0,coldest)
| table ext C D
|rename ext as "Сотрудники" C as "Количество исходящих вызовов" D as "Количество входящих вызовов"Компания Y
Здесь все намного проще, так как у колл-центра есть только один тип звонков, да и компанию в большей степени интересует только сводная информация. Однако, возможность дороботки и детализации не исключена, например по конкретному сотруднику. Ниже основной дашборд на основе CDR Asteriska:
Наиболее интересным является самый нижний график, где решается задача по вычислению конкурентных сессий.
Запросы
Ниже один из наиболее сложных запросов, как раз про конкурентные сессии:
index="aster2" dstchannel="Beeline" | concurrency duration=duration | timechart span=1h max(concurrency) as Beeline
| join _time type=left
[search index="aster2" dstchannel="MTS" | concurrency duration=duration | timechart span=1h max(concurrency) as MTS
| join _time type=left
[search index="aster2" dstchannel="Megafon" | concurrency duration=duration | timechart span=1h max(concurrency) as Megafon
| join _time type=left
[search index="aster2" dstchannel="TTK" | concurrency duration=duration | timechart span=1h max(concurrency) as TTK ]]]Заключение
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
