
Когда в последний раз падал ваш сервер? Как это отразилось на работе вашей организации? В 2013 г. институтом Ponemon, который занимается независимыми исследованиями в сфере информационной безопасности, был проведен опрос, показавший, что 91% организаций столкнулись с проблемой простоя в работе ЦОД. И хотя эта статистика не так ужасна сама по себе, по подсчетам экспертов 30% пострадавших так и не смогли восстановить работу, а это уже серьёзный повод для тревоги.
Руководители предприятий всегда думают, что все эти ужасы произойдут с кем-то другим, но только не с их организацией, хотя так рассуждают не только они. Большинству людей при слове «бедствие» на ум приходят ураганы и землетрясения, но оно, на самом деле, не всегда носит природный характер. Бедствием может обернуться человеческая ошибка или кибер-атака. Именно поэтому всегда стоит иметь «план Б» для защиты своих критически важных приложений и данных. Также важно знать, что пятиминутный простой – это не просто потеря возможной в это время прибыли. Это возможность потери репутации бренда и лояльности клиентов.

О чём стоит вспомнить, когда Вы или Ваше руководство решите сэкономить на мерах для восстановления?
По исследованию института Ponemon, среднему предприятию требуется в среднем 2 дня на восстановление работы. Средний годовой убыток на компанию (похоже на среднюю температуру по больнице, но всё же) составляет $366363. Есть также и скрытые убытки – это упущенная выгода и потеря репутации бренда. Например, если на 8 часов «падает» система резервирования билетов в крупной авиакомпании, в следующий раз клиенты, потерявшие кучу времени на борьбу с накладками, дважды подумают прежде, чем забронировать в ней рейс.
Организации, которые прибегают к помощи провайдеров аварийного-восстановления-как-услуги (disaster-recovery-as-a-service, DRaaS), оценили экономию как ключевое преимущество использования публичного облака для аварийного восстановления. Таковы результаты исследования Aberdeen Group – исследовательской компании, которая позволяет бизнес-структурам понять последствия и результаты от внедрения технологий. Не стоит бояться необходимости слишком больших капитальных вложений в повышение надёжности, можно просто подписать договор с провайдером DRaaS.
Затраты колеблются от $60 до $120 в месяц за один сервер в зависимости от количества серверов, необходимых для резервирования данных организации, и от размеров этих данных, а также зависят от таких факторов, как контрольная точка восстановления (recovery-point objective, RPO), контрольное время восстановления (recovery-time objective, RTO), и т.д.
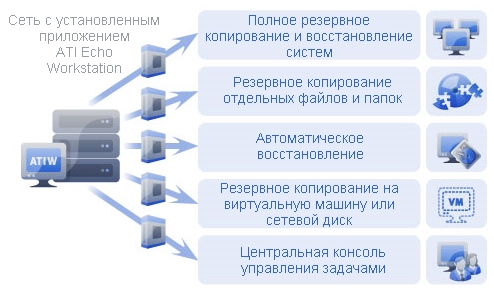
На сегодняшний день восстановление данных в облаке принимается бизнесом разной величины гораздо легче, чем пять лет назад. До появления виртуализации, затраты на восстановление были, по крайней мере, в три раза больше, т.к. требовалось несколько ДЦ, специализированное ПО и обширные сетевые соединения. Очень дорого осуществлять это в «материальном» мире. Поэтому только самые крупные организации могли позволить себе бюджет на восстановление. Сейчас виртуализация сделала процедуру резервного копирования и восстановления проще, путем инкапсуляции виртуальных серверов в несколько файлов, данные легко транспортируются, а стоимость процедуры уменьшается.
Восстановительные процедуры дают владельцам данных разнообразие подходов к восстановлению. Нужно защитить всю инфраструктуру или только приложения первого уровня? Время восстановления и точка восстановления закладывается в пределах приложений 1-3 уровней? Ушли в прошлое те дни, когда требовалось создавать, поддерживать и проплачивать дополнительный сайт, полностью идентичный основному.
По результатам исследования, проведенного Aberdeen Group, есть три фактора, оказывающих давление на организации на пути к использованию облачного резервирования данных: риск прерывания бизнес-процессов, потеря критически важных корпоративных данных и длительность процедуры восстановления. Те, кто включил в сервисное соглашение процедуру восстановления, тратят на это в три раза меньше времени и восстанавливают в два раза больше данных.
Представьте, что вы руководите кампанией в Delray Beach во Флориде. Это здорово… пока не случился ураган. Такое произошло с компанией Fleet Lease Disposal в октябре 2005 после урагана Wilma, который разрушил офис компании и один из ее главных дата-центров. К счастью компания быстро оправилась от потерь и спокойно работала следующие 4 месяца из резервного дата-центра в Нью Джерси. Спустя 4 года компания узнала, что на дополнительном сайте также не хватило соответствующего оборудования и пропускной способности для резервного восстановления.
Начав работать с провайдерами DRaaS, компании удалось восстановить данные менее, чем за час, сэкономить тысячи долларов и человеко-часов, отбив затраты на процедуру восстановления менее, чем за 18 месяцев. Используя репликацию данных и облачные сервисы, теперь компания может рассчитывать на быстрое восстановление, особенно в сезон ураганов.
По данным опроса, проведенного Aberdeen Group, компании, которые используют DRaaS, быстрее восстанавливают свою работу – это второе преимущество использования облачных сервисов.
Многие считают, что сохранять данные на съемных носителях аналогично резервному копированию. Защита данных важна, но возможность эффективно и быстро восстанавливать данные просто необходима в процессе восстановления. Хранение данных без задействования виртуальных ресурсов и способность легко протестировать восстановление вне условий сбоя – это всего лишь бекап, который не обеспечивает непрерывность бизнес-процессов.
Например, одна ведущая компания в сфере биотехнологий упростила процесс резервирования до такой степени, что просто отказалась от использования нескольких дата-центров в пользу одного, инфраструктура которого производит полное резервирование данных и всех приложений.
Предприятия могут опробовать свой план восстановления в любое время. Очень важно убедиться, что ИТ среда запустится на другой площадке, и все данные сохранятся. Компании могут отрепетировать действия при плановой или внеплановой остановке работы и убедиться, что план по резервному восстановлению сработает. В 2012 Forrester опубликовал данные, что только половина компаний проводит полноценное тестирование резервного восстановления раз в год. И хотя компании ссылаются на нехватку ресурсов для тестирования, эти процессы сейчас большей частью автоматизированы и требуют меньшего вмешательства со стороны человека.
Когда компании Verdande Technology понадобилось расширить инфраструктуру, не делая существенных вложений, она обратилась к провайдерам облачного резервного восстановления для принятия гибких, экономически эффективных мер по расширению тестового пространства, одновременно с этим уменьшив количество оборудования и связанных с ним сложностей.
«Теперь у нас есть и гибкость, и контроль, который мы хотели» — сказал Питер Верлен, системный ИТ-инженер компании. «Мы можем удаленно настраивать тестовую площадку в соответствии с требованиями тестирования, а наши провайдеры выставляют нам счета только за то, что мы используем. Больше нам не приходится волноваться о том, где, когда и как мы проведем тестирование».
Задача тестирования в том, чтобы убедиться в доступности и восстанавливаемости всех систем, которые необходимы в работе. Ведь когда сбой происходит на самом деле. Думать об этом уже поздно.
Руководители предприятий всегда думают, что все эти ужасы произойдут с кем-то другим, но только не с их организацией, хотя так рассуждают не только они. Большинству людей при слове «бедствие» на ум приходят ураганы и землетрясения, но оно, на самом деле, не всегда носит природный характер. Бедствием может обернуться человеческая ошибка или кибер-атака. Именно поэтому всегда стоит иметь «план Б» для защиты своих критически важных приложений и данных. Также важно знать, что пятиминутный простой – это не просто потеря возможной в это время прибыли. Это возможность потери репутации бренда и лояльности клиентов.
О чём стоит вспомнить, когда Вы или Ваше руководство решите сэкономить на мерах для восстановления?
Аварийное восстановление экономически эффективно
По исследованию института Ponemon, среднему предприятию требуется в среднем 2 дня на восстановление работы. Средний годовой убыток на компанию (похоже на среднюю температуру по больнице, но всё же) составляет $366363. Есть также и скрытые убытки – это упущенная выгода и потеря репутации бренда. Например, если на 8 часов «падает» система резервирования билетов в крупной авиакомпании, в следующий раз клиенты, потерявшие кучу времени на борьбу с накладками, дважды подумают прежде, чем забронировать в ней рейс.
Организации, которые прибегают к помощи провайдеров аварийного-восстановления-как-услуги (disaster-recovery-as-a-service, DRaaS), оценили экономию как ключевое преимущество использования публичного облака для аварийного восстановления. Таковы результаты исследования Aberdeen Group – исследовательской компании, которая позволяет бизнес-структурам понять последствия и результаты от внедрения технологий. Не стоит бояться необходимости слишком больших капитальных вложений в повышение надёжности, можно просто подписать договор с провайдером DRaaS.
Затраты колеблются от $60 до $120 в месяц за один сервер в зависимости от количества серверов, необходимых для резервирования данных организации, и от размеров этих данных, а также зависят от таких факторов, как контрольная точка восстановления (recovery-point objective, RPO), контрольное время восстановления (recovery-time objective, RTO), и т.д.

Восстановление легко организовать
На сегодняшний день восстановление данных в облаке принимается бизнесом разной величины гораздо легче, чем пять лет назад. До появления виртуализации, затраты на восстановление были, по крайней мере, в три раза больше, т.к. требовалось несколько ДЦ, специализированное ПО и обширные сетевые соединения. Очень дорого осуществлять это в «материальном» мире. Поэтому только самые крупные организации могли позволить себе бюджет на восстановление. Сейчас виртуализация сделала процедуру резервного копирования и восстановления проще, путем инкапсуляции виртуальных серверов в несколько файлов, данные легко транспортируются, а стоимость процедуры уменьшается.
Восстановительные процедуры дают владельцам данных разнообразие подходов к восстановлению. Нужно защитить всю инфраструктуру или только приложения первого уровня? Время восстановления и точка восстановления закладывается в пределах приложений 1-3 уровней? Ушли в прошлое те дни, когда требовалось создавать, поддерживать и проплачивать дополнительный сайт, полностью идентичный основному.
Снижается потеря данных
По результатам исследования, проведенного Aberdeen Group, есть три фактора, оказывающих давление на организации на пути к использованию облачного резервирования данных: риск прерывания бизнес-процессов, потеря критически важных корпоративных данных и длительность процедуры восстановления. Те, кто включил в сервисное соглашение процедуру восстановления, тратят на это в три раза меньше времени и восстанавливают в два раза больше данных.
Представьте, что вы руководите кампанией в Delray Beach во Флориде. Это здорово… пока не случился ураган. Такое произошло с компанией Fleet Lease Disposal в октябре 2005 после урагана Wilma, который разрушил офис компании и один из ее главных дата-центров. К счастью компания быстро оправилась от потерь и спокойно работала следующие 4 месяца из резервного дата-центра в Нью Джерси. Спустя 4 года компания узнала, что на дополнительном сайте также не хватило соответствующего оборудования и пропускной способности для резервного восстановления.
Начав работать с провайдерами DRaaS, компании удалось восстановить данные менее, чем за час, сэкономить тысячи долларов и человеко-часов, отбив затраты на процедуру восстановления менее, чем за 18 месяцев. Используя репликацию данных и облачные сервисы, теперь компания может рассчитывать на быстрое восстановление, особенно в сезон ураганов.
Восстановление проходит быстро и эффективно
По данным опроса, проведенного Aberdeen Group, компании, которые используют DRaaS, быстрее восстанавливают свою работу – это второе преимущество использования облачных сервисов.
Многие считают, что сохранять данные на съемных носителях аналогично резервному копированию. Защита данных важна, но возможность эффективно и быстро восстанавливать данные просто необходима в процессе восстановления. Хранение данных без задействования виртуальных ресурсов и способность легко протестировать восстановление вне условий сбоя – это всего лишь бекап, который не обеспечивает непрерывность бизнес-процессов.
Например, одна ведущая компания в сфере биотехнологий упростила процесс резервирования до такой степени, что просто отказалась от использования нескольких дата-центров в пользу одного, инфраструктура которого производит полное резервирование данных и всех приложений.
Тестирование 1, 2, 3…
Предприятия могут опробовать свой план восстановления в любое время. Очень важно убедиться, что ИТ среда запустится на другой площадке, и все данные сохранятся. Компании могут отрепетировать действия при плановой или внеплановой остановке работы и убедиться, что план по резервному восстановлению сработает. В 2012 Forrester опубликовал данные, что только половина компаний проводит полноценное тестирование резервного восстановления раз в год. И хотя компании ссылаются на нехватку ресурсов для тестирования, эти процессы сейчас большей частью автоматизированы и требуют меньшего вмешательства со стороны человека.
Когда компании Verdande Technology понадобилось расширить инфраструктуру, не делая существенных вложений, она обратилась к провайдерам облачного резервного восстановления для принятия гибких, экономически эффективных мер по расширению тестового пространства, одновременно с этим уменьшив количество оборудования и связанных с ним сложностей.
«Теперь у нас есть и гибкость, и контроль, который мы хотели» — сказал Питер Верлен, системный ИТ-инженер компании. «Мы можем удаленно настраивать тестовую площадку в соответствии с требованиями тестирования, а наши провайдеры выставляют нам счета только за то, что мы используем. Больше нам не приходится волноваться о том, где, когда и как мы проведем тестирование».
Задача тестирования в том, чтобы убедиться в доступности и восстанавливаемости всех систем, которые необходимы в работе. Ведь когда сбой происходит на самом деле. Думать об этом уже поздно.
