
Если ваш сайт медленно грузится, вы рискуете тем, что люди не оценят ни то, какой он красивый, ни то, какой он удобный. Никому не понравится, когда все тормозит. Мы регулярно добавляем в Яндекс.Почту новую функциональность, иногда — исправляем ошибки, а это значит, у нас постоянно появляются новый код и новая логика. Все это напрямую влияет на скорость работы интерфейса.

Яндекс.Почту каждый день открывают миллионы человек из разных точек земного шара. И ни у кого она не должна тормозить, поэтому без различных измерений наша работа не обходится. В этом посте мы с alexeimoisseev и kurau решили рассказать о том, какие метрики у нас есть и какие задачи они решают. Возможно, это пригодится и вам.
Время первой загрузки страницы с почтой мы измеряем с помощью NTA. NTA используется следующим образом. Скорость первой загрузки (то, на что может повлиять фронтенд) измеряется от PerformanceTiming.domLoading до момента полной отрисовки (это не onload, а реальное время первой отрисовки писем). Я специально подчеркиваю это, так как многие измеряют скорость от PerformanceTiming.navigationStart. Между NavigationStart и domLoading может пройти много времени, ведь туда входит время редиректов, dns lookup, подключения и т. п. И такая метрика ошибочна. Скажем, за dns lookup и время подключения должны отвечать NOC и администраторы, а не фронтенд-разработчики. Соответственно, очень важно, даже в таких метриках, разделять зону ответственности.
Современные браузеры, в том числе IE9, имеют поддержку NTA.
Но этих замеров недостаточно. У пользователя почта загружается всего один раз, а потом он открывает десятки писем без перезагрузки страницы. И нам важно знать, как быстро это происходит.
Любые изменения страницы у нас происходят через единый модуль, который расставляет у себя таймеры на различные части (подготовка, запрос данных с сервера, шаблонизация, обновление DOM) и пробрасывает их модулям-потребителям. Таймеры расставляются через обычный Date.now(). То есть в момент нажатия на ссылку мы сохраняем в переменную значение Date.now(). После обновления DOM мы снова запоминаем Date.now() и вычисляем разницу с предыдущим значением.
Интересно, что до разделения процесса обновления на стадии мы дошли не сразу и в первых версиях измеряли только общее время выполнения и время запроса на сервер. Стадии и детальные измерения появились после неудачного релиза, где мы сильно замедлились и не могли понять почему. Сейчас модуль обновления сам логирует все свои стадии, и можно легко понять причину замедления: медленнее стал отвечать сервер либо слишком долго выполняется JavaScript.
Выглядит это примерно так:
Все тайминги собираются и при отправке рассчитываются. На этапах разница между “end” и “start” не считается, а все вычисления производятся в конце:
И на сервер прилетают подобные записи:
Этапы первой загрузки:
Этапы отрисовки любой страницы:
Следует заметить, что для честности «общее время исполнения» не является суммой всех метрик, а вычисляется отдельной метрикой «“начало” — “конец”». Это позволяет не терять стадии обновления. Детальные метрики позволяют быстрее найти проблему и в идеале должны примерно равняться общему времени исполнения. Полное равенство получить не удастся из-за Promise или setTimeout.
— Ок, теперь у нас есть метрики, и мы можем отправить их на сервер.
— Что же дальше?
— А давай построим график!
— Что будем считать?
Когда я слышу такую фразу, мне вспоминаются две шутки:
Как вы уже поняли, «среднее» в том смысле, в котором мы его чаще всего понимаем, – не что иное, как среднее арифметическое. В более общем случае оно имеет специальное название – «математическое ожидание», которое в дискретном случае (далее мы будем рассматривать именно его) как раз и является средним арифметическим. Вообще в статистике «средним» называют целое семейство мер центральной тенденции, каждая из которых с определенной точностью характеризует локализацию распределения данных.
В нашей ситуации мы имеем дело с данными, в которых есть выбросы, сильно влияющие на среднее арифметическое. Для наглядности возьмем «реальные» данные за день и построим гистограмму. Напомню, что при достаточно большом объеме данных она становится похожа на график плотности распределения.
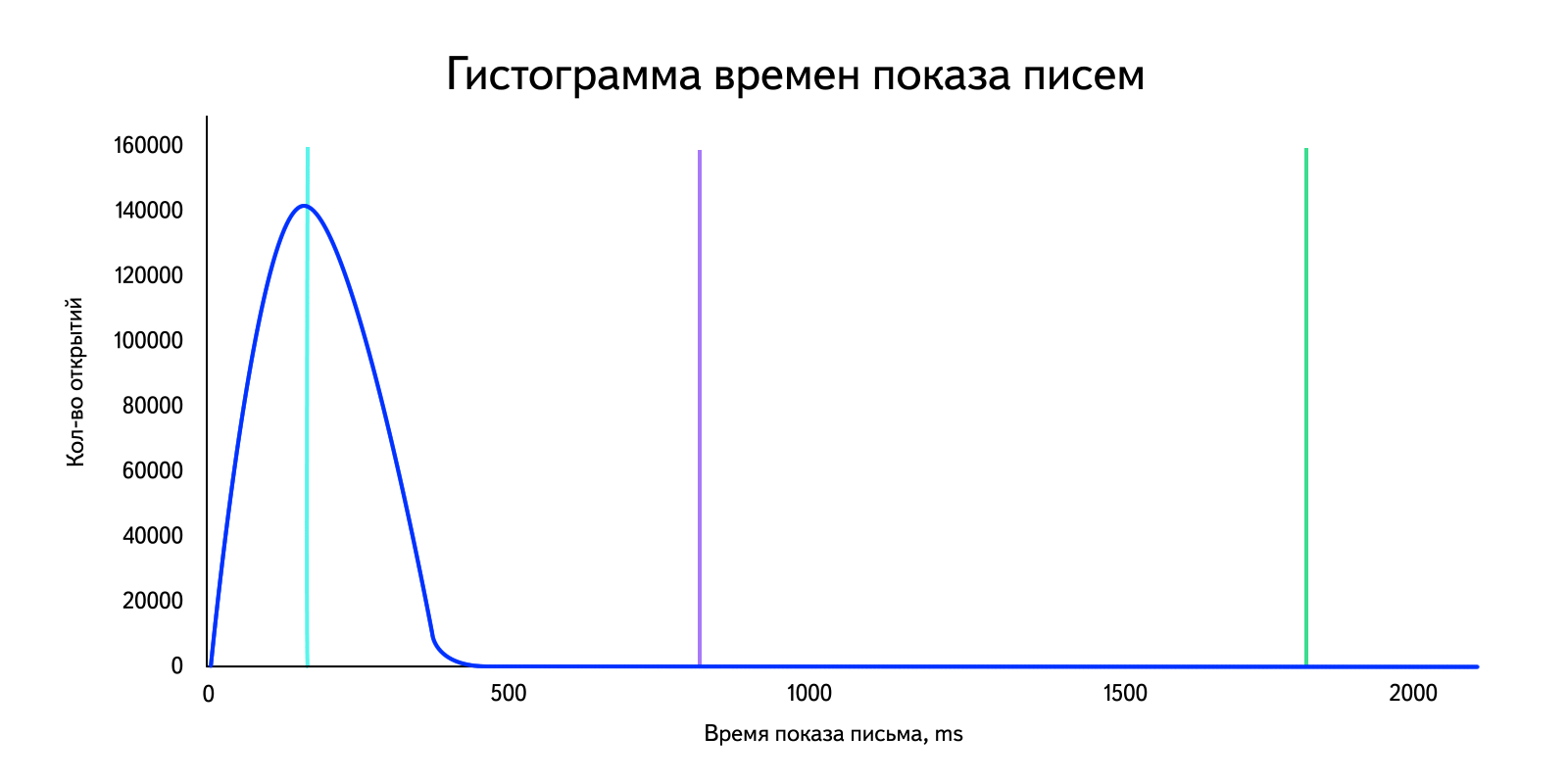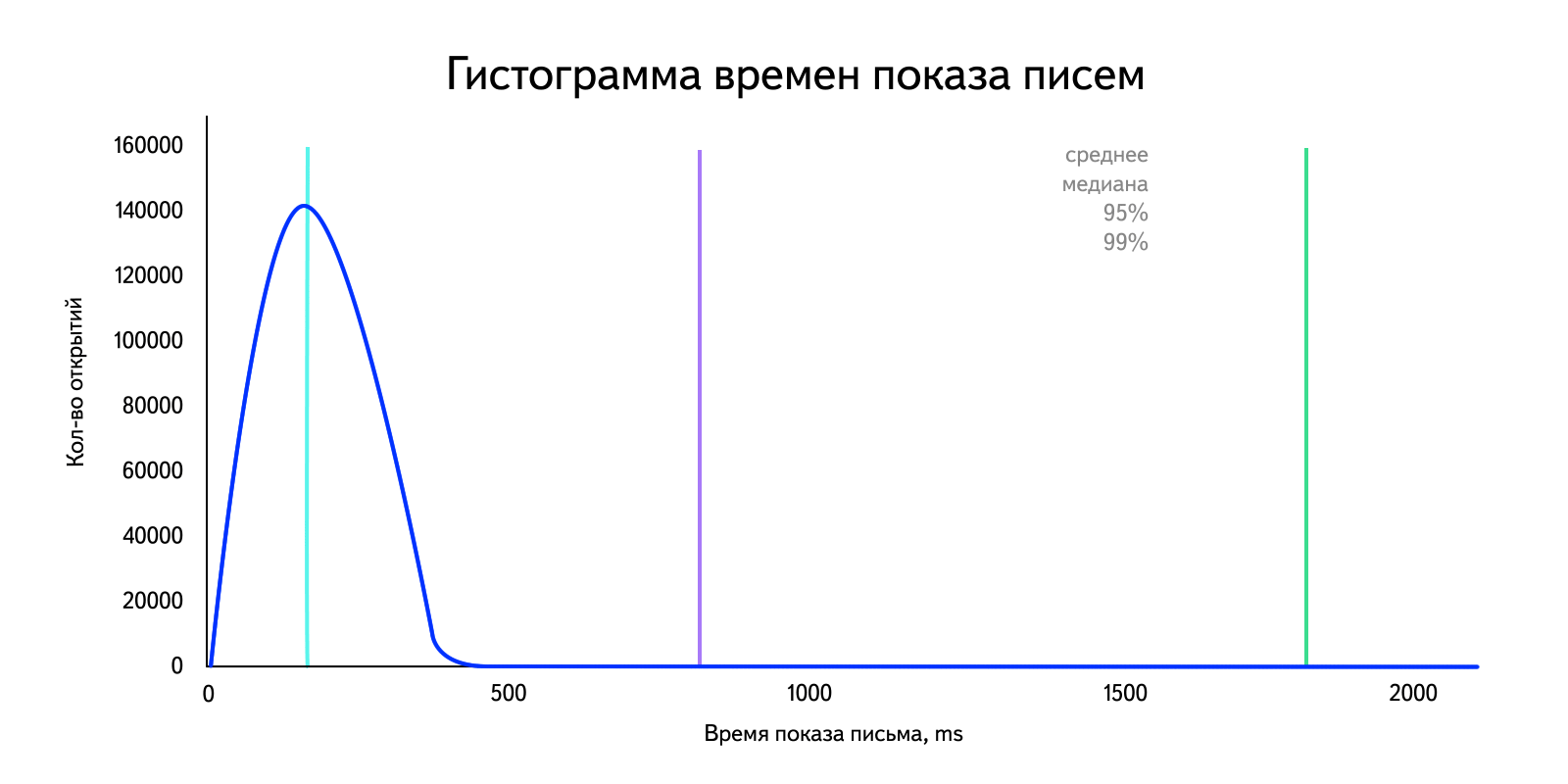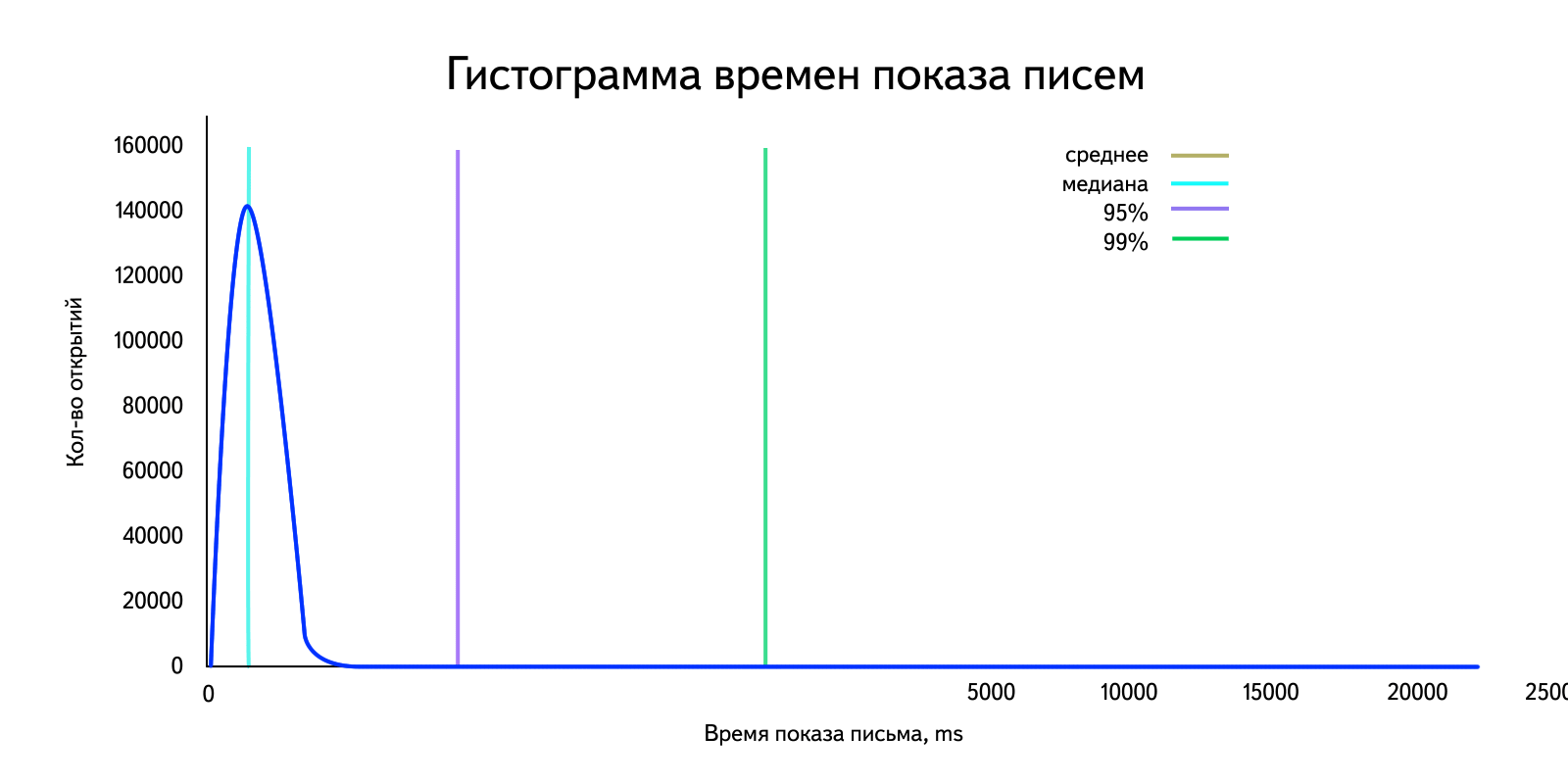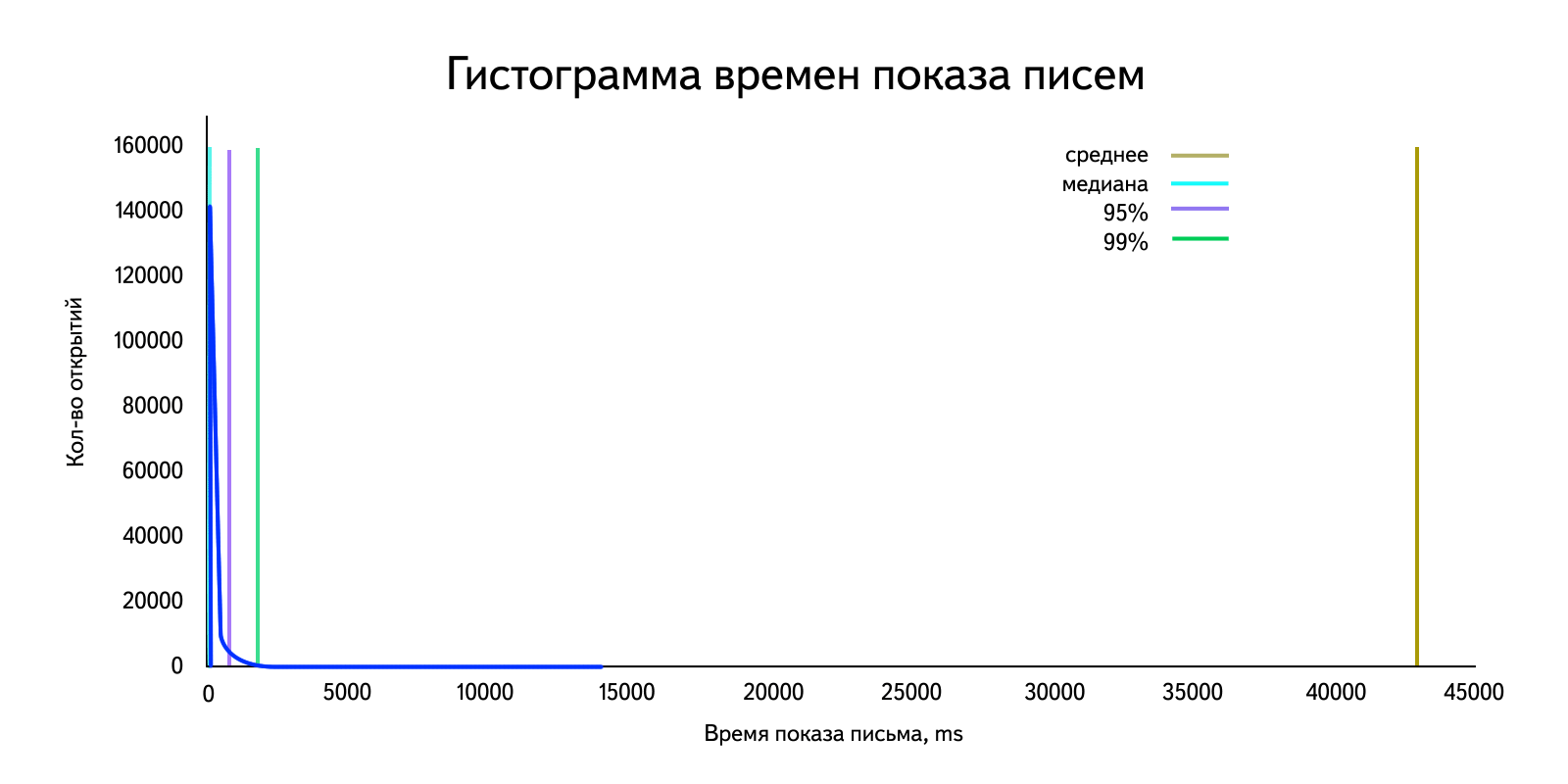
Посчитаем среднее арифметическое:
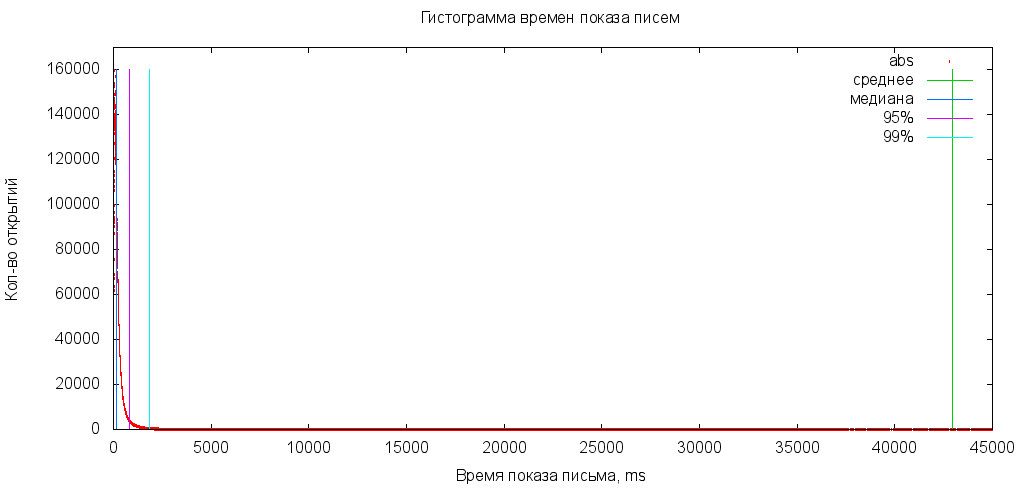
Жуть. Замечу, что в зависимости от количества выбросов это значение будет меняться. Это хорошо видно, если посчитать, например, среднее арифметическое для 99% пользователей, отбросив «больших»:
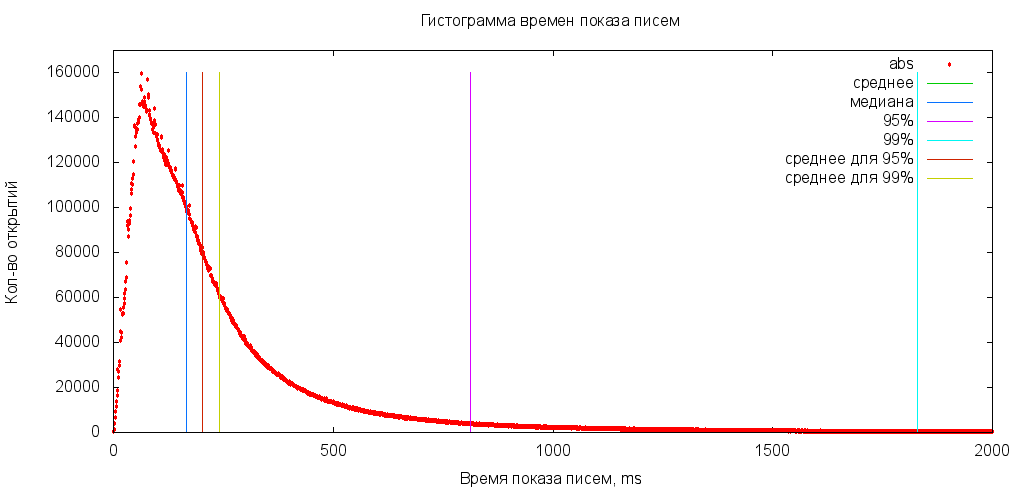
Способ оценивать выборку не по всем данным, а брать только подмножество часто используется в случае данных с выбросами. Для этого прибегают к специальным оценкам центральной тенденции, основанным на усечении данных. К этой группе относится в первую очередь медиана (Md).
Медиана
Как вы знаете, медиана – это серединное, а не среднее значение в выборке. Если у нас имеются числа 1, 2, 2, 3, 8, 10, 20, то медиана – 3, а среднее – 6,5. В общем случае медиана отлично показывает, сколько грузится средний пользователь. Даже если делить эти группы на «быстрые» и «медленные», все равно будет получаться правильное значение.
Допустим, медиана у нас равна 1 с. Это хорошо или плохо? А если мы ускорим на 100 мс и сделаем 0,9 с, то это будет что?
В случае ускорения или замедления медиана, конечно, изменится. Но она не может рассказать, сколько пользователей ускорилось, а сколько замедлилось. Могут ускоряться браузеры, обновляться компьютеры, можно оптимизировать код, а в итоге в вас будет одна мало что говорящая цифра.
Чтобы понять, на какую группу пользователей повлияли изменения, можно построить следующий график: берем временнЫе интервалы 0 – 100 мс, 100 мс – 300 мс, 300 мс – 1000 мс, 1000 мс – бесконечность и считаем, сколько процентов запросов уложилось в каждый из них.
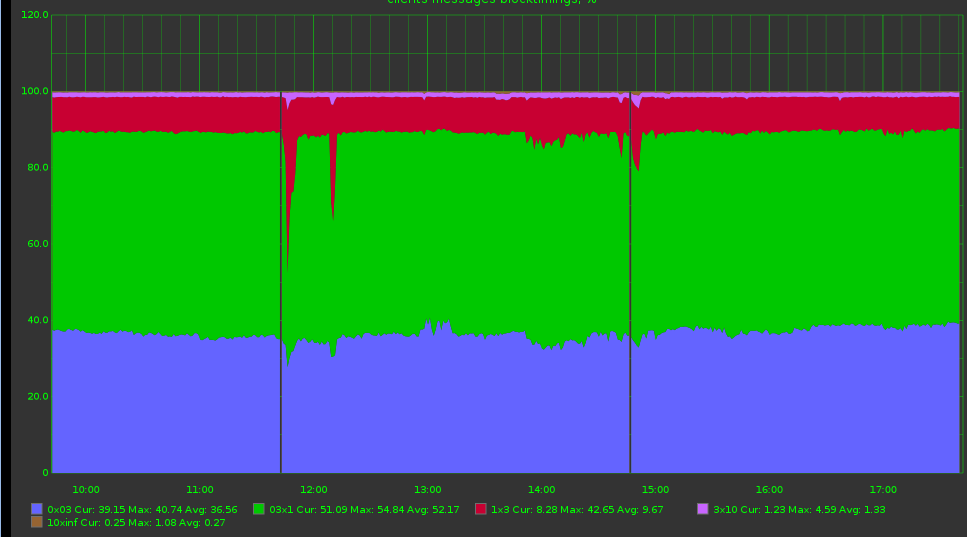
Но и тут возникает проблема. Каждый раз нам приходилось делать выводы: тут стало чуть лучше и тут стало немного похуже. Нельзя лисделать вывод сразу? еще больше упростить график?
Когда вы научитесь считать метрики и делать графики, у всех появится желание строить их для ВСЕГО. В итоге мы получим прекрасные 100500 графиков, кучу разрозненных метрик, где каждый показывает начальнику то, что ему более выгодно. Плохо? Конечно, плохо! При возникновении проблем непонятно на что смотреть! Сотни графиков – и все правильные.
Стандартная ситуация: бэкенд строит свои графики, БД – другие, фронтенд – третьи. А где же пользователь? В конечном итоге мы же все работаем на него и график надо строить от него. Как это сделать?
APDEX – интеграционная метрика, которая сразу говорит: хорошо или плохо. Метрика работает очень просто. Мы выбираем временной интервал [0; t], такой, что если время показа страницы попало в него, то пользователь счастлив. Берем еще один интервал, (t; 4t] (в четыре раза больше первого), и считаем, что если страница показана за это время, то пользователь в целом удовлетворен скоростью работы, но уже не настолько счастлив. И применяем формулу:
Получается значение от нуля до единицы, которое, видимо, лучше всего показывает, хорошо или плохо работает почта.
В формуле APDEX несчастливые или в целом удовлетворенные пользователи влияют на оценку больше, чем счастливые, а значит, стоит работать именно с ними. В идеале должна получаться единица.
В Яндексе APDEX используется довольно широко. Такую популярность он получил во многом потому, что его результаты можно обрабатывать автоматически, так как это всего лишь одна цифра. Напротив, в случае графика с множественными интервалами определить, «хорошо или плохо», может только человек.
В то же время использование APDEX не отменяет построения других графиков. Те же процентили нужны и полезны в случае разбора проблем, по ним будет понятно, что происходит. Таким образом, он является вспомогательным графиком.
Правильный график – тот, который покажет реальное взаимодействие пользователя с вашим сайтом. Можно бесконечно улучшать бэкенд и делать его сколь угодно быстрым, но пользователю, по большому счету, на это плевать. Если тормозит фронтенд, бэкенд не поможет, и наоборот. К поиску проблемы всегда надо идти от конечного пользователя.
Возьмем, например, абстрактного пользователя из Екатеринбурга. Когда мы, давным-давно, начали вводить метрики скорости, то обнаружили, что чем дальше пользователь от Москвы, тем медленнее у него работает почта. Почему? Все очень просто: наши ДЦ тогда находились в столице, а скорость света имеет конечное значение. Сигналу надо преодолевать тысячи километров по проводам. Простой расчет показывает, что расстояние в 2000 км свет пройдет примерно за 7 мс. В реальности потребуется даже больше времени, потому что свет путешествует не в вакууме и не по прямой, по пути встречается много маршрутизаторов и т. д. Таким образом, оптимизируй не оптимизируй, а каждый TCP-пакет будет иметь задержку в десятки миллисекунд. Естественно, что в такой ситуации вкладываться надо не в оптимизацию кода, а в создание CDN, чтобы любой пользователь оказался ближе к нам.
Иногда получается, что вы видите ровные графики, а пользователи жалуются на тормоза. Это всегда означает, что либо у вас ошибка в измерениях, либо вы измеряете не то. Метрики надо стресс-тестировать, чтобы исключать ошибки в самих метриках. Причем стресс-тестирование должно выполняться не средствами самой метрики, а со стороны.
Замедляйте бэкенды, добавляйте циклы или отвечайте ошибками. Смотрите, как изменяются метрики на каждом этапе: от бэкенда к фронтенду и браузеру. Только так вы можете убедиться, что измеряете то, что действительно нужно.
Например, мы в стресс-тестировании как-то дошли до того, что каждый второй запрос отвечал ошибкой. Это позволило нам определить, входит перезапрос данных в метрики или нет.
Очень важно, чтобы оптимизация не была единоразовой или от случая к случаю. Над метриками скорости надо организовывать процесс. Для начала хватит реалтаймовых графиков и тестирования каждого релиза на скорость. Таким образом, мы останемся честными сами с собой и будем понимать, где именно мы медленные. Налаженный процесс позволяет отслеживать релизы, в которых произошли изменения в скорости, а значит, мы точно сможем это исправить. Даже если у вашей команды нет времени целенаправленно и постоянно заниматься оптимизацией, можно хотя бы следить за тем, чтобы не становилось хуже.

Яндекс.Почту каждый день открывают миллионы человек из разных точек земного шара. И ни у кого она не должна тормозить, поэтому без различных измерений наша работа не обходится. В этом посте мы с alexeimoisseev и kurau решили рассказать о том, какие метрики у нас есть и какие задачи они решают. Возможно, это пригодится и вам.
Что нам интересно
- Время первой загрузки интерфейса.
- Время отрисовки любого блока на странице (от клика до того, как он появился в DOM и готов взаимодействовать с пользователем).
- Количество аномально долгих отрисовок страницы и их причины (например, аномально долгим мы считаем любой переход больше двух секунд).
Время первой загрузки страницы с почтой мы измеряем с помощью NTA. NTA используется следующим образом. Скорость первой загрузки (то, на что может повлиять фронтенд) измеряется от PerformanceTiming.domLoading до момента полной отрисовки (это не onload, а реальное время первой отрисовки писем). Я специально подчеркиваю это, так как многие измеряют скорость от PerformanceTiming.navigationStart. Между NavigationStart и domLoading может пройти много времени, ведь туда входит время редиректов, dns lookup, подключения и т. п. И такая метрика ошибочна. Скажем, за dns lookup и время подключения должны отвечать NOC и администраторы, а не фронтенд-разработчики. Соответственно, очень важно, даже в таких метриках, разделять зону ответственности.
Современные браузеры, в том числе IE9, имеют поддержку NTA.
Но этих замеров недостаточно. У пользователя почта загружается всего один раз, а потом он открывает десятки писем без перезагрузки страницы. И нам важно знать, как быстро это происходит.
Любые изменения страницы у нас происходят через единый модуль, который расставляет у себя таймеры на различные части (подготовка, запрос данных с сервера, шаблонизация, обновление DOM) и пробрасывает их модулям-потребителям. Таймеры расставляются через обычный Date.now(). То есть в момент нажатия на ссылку мы сохраняем в переменную значение Date.now(). После обновления DOM мы снова запоминаем Date.now() и вычисляем разницу с предыдущим значением.
Интересно, что до разделения процесса обновления на стадии мы дошли не сразу и в первых версиях измеряли только общее время выполнения и время запроса на сервер. Стадии и детальные измерения появились после неудачного релиза, где мы сильно замедлились и не могли понять почему. Сейчас модуль обновления сам логирует все свои стадии, и можно легко понять причину замедления: медленнее стал отвечать сервер либо слишком долго выполняется JavaScript.
Выглядит это примерно так:
this.timings[‘look-ma-im-start’] = Date.now();this.timings[‘look-ma-finish’] = Date.now();Все тайминги собираются и при отправке рассчитываются. На этапах разница между “end” и “start” не считается, а все вычисления производятся в конце:
var totalTime = this.timings[‘look-ma-finish’] - this.timings[‘look-ma-im-start’];И на сервер прилетают подобные записи:
serverResponse=50&domUpdate=60&yate=100Что мы измеряем
Этапы первой загрузки:
- подготовка,
- загрузка статики (HTTP-запрос и парсинг),
- исполнение модулей (объявление деклараций моделей, видов и т. п.),
- инициализация базовых объектов,
- отрисовка,
- выполнение обработчиков события «первая отрисовка».
Этапы отрисовки любой страницы:
- подготовка к запросу на сервер,
- запрос данных с сервера,
- шаблонизация,
- обновление DOM,
- обработка событий у view,
- выполнение callback «после отрисовки».
Следует заметить, что для честности «общее время исполнения» не является суммой всех метрик, а вычисляется отдельной метрикой «“начало” — “конец”». Это позволяет не терять стадии обновления. Детальные метрики позволяют быстрее найти проблему и в идеале должны примерно равняться общему времени исполнения. Полное равенство получить не удастся из-за Promise или setTimeout.
— Ок, теперь у нас есть метрики, и мы можем отправить их на сервер.
— Что же дальше?
— А давай построим график!
— Что будем считать?
А давай посчитаем среднее
Когда я слышу такую фразу, мне вспоминаются две шутки:
- В среднем у человека меньше двух рук.
- Зарплата депутата – 100 000 рублей, зарплата врача – 10 000 рублей. Средняя зарплата – 55 000 рублей.
Как вы уже поняли, «среднее» в том смысле, в котором мы его чаще всего понимаем, – не что иное, как среднее арифметическое. В более общем случае оно имеет специальное название – «математическое ожидание», которое в дискретном случае (далее мы будем рассматривать именно его) как раз и является средним арифметическим. Вообще в статистике «средним» называют целое семейство мер центральной тенденции, каждая из которых с определенной точностью характеризует локализацию распределения данных.
В нашей ситуации мы имеем дело с данными, в которых есть выбросы, сильно влияющие на среднее арифметическое. Для наглядности возьмем «реальные» данные за день и построим гистограмму. Напомню, что при достаточно большом объеме данных она становится похожа на график плотности распределения.
Посчитаем среднее арифметическое:

Жуть. Замечу, что в зависимости от количества выбросов это значение будет меняться. Это хорошо видно, если посчитать, например, среднее арифметическое для 99% пользователей, отбросив «больших»:

Способ оценивать выборку не по всем данным, а брать только подмножество часто используется в случае данных с выбросами. Для этого прибегают к специальным оценкам центральной тенденции, основанным на усечении данных. К этой группе относится в первую очередь медиана (Md).
Медиана
Как вы знаете, медиана – это серединное, а не среднее значение в выборке. Если у нас имеются числа 1, 2, 2, 3, 8, 10, 20, то медиана – 3, а среднее – 6,5. В общем случае медиана отлично показывает, сколько грузится средний пользователь. Даже если делить эти группы на «быстрые» и «медленные», все равно будет получаться правильное значение.
Допустим, медиана у нас равна 1 с. Это хорошо или плохо? А если мы ускорим на 100 мс и сделаем 0,9 с, то это будет что?
Окей, я ускорил отрисовку на 100мс
В случае ускорения или замедления медиана, конечно, изменится. Но она не может рассказать, сколько пользователей ускорилось, а сколько замедлилось. Могут ускоряться браузеры, обновляться компьютеры, можно оптимизировать код, а в итоге в вас будет одна мало что говорящая цифра.
Чтобы понять, на какую группу пользователей повлияли изменения, можно построить следующий график: берем временнЫе интервалы 0 – 100 мс, 100 мс – 300 мс, 300 мс – 1000 мс, 1000 мс – бесконечность и считаем, сколько процентов запросов уложилось в каждый из них.

Но и тут возникает проблема. Каждый раз нам приходилось делать выводы: тут стало чуть лучше и тут стало немного похуже. Нельзя ли
Дорогая, я сделал еще один график
Когда вы научитесь считать метрики и делать графики, у всех появится желание строить их для ВСЕГО. В итоге мы получим прекрасные 100500 графиков, кучу разрозненных метрик, где каждый показывает начальнику то, что ему более выгодно. Плохо? Конечно, плохо! При возникновении проблем непонятно на что смотреть! Сотни графиков – и все правильные.
Стандартная ситуация: бэкенд строит свои графики, БД – другие, фронтенд – третьи. А где же пользователь? В конечном итоге мы же все работаем на него и график надо строить от него. Как это сделать?
APDEX
APDEX – интеграционная метрика, которая сразу говорит: хорошо или плохо. Метрика работает очень просто. Мы выбираем временной интервал [0; t], такой, что если время показа страницы попало в него, то пользователь счастлив. Берем еще один интервал, (t; 4t] (в четыре раза больше первого), и считаем, что если страница показана за это время, то пользователь в целом удовлетворен скоростью работы, но уже не настолько счастлив. И применяем формулу:
(количество счастливых пользователей + количество в целом удовлетворенных/2) / (количество всех пользователей).
Получается значение от нуля до единицы, которое, видимо, лучше всего показывает, хорошо или плохо работает почта.
В формуле APDEX несчастливые или в целом удовлетворенные пользователи влияют на оценку больше, чем счастливые, а значит, стоит работать именно с ними. В идеале должна получаться единица.
В Яндексе APDEX используется довольно широко. Такую популярность он получил во многом потому, что его результаты можно обрабатывать автоматически, так как это всего лишь одна цифра. Напротив, в случае графика с множественными интервалами определить, «хорошо или плохо», может только человек.
В то же время использование APDEX не отменяет построения других графиков. Те же процентили нужны и полезны в случае разбора проблем, по ним будет понятно, что происходит. Таким образом, он является вспомогательным графиком.
Какой же график правильный
Правильный график – тот, который покажет реальное взаимодействие пользователя с вашим сайтом. Можно бесконечно улучшать бэкенд и делать его сколь угодно быстрым, но пользователю, по большому счету, на это плевать. Если тормозит фронтенд, бэкенд не поможет, и наоборот. К поиску проблемы всегда надо идти от конечного пользователя.
Возьмем, например, абстрактного пользователя из Екатеринбурга. Когда мы, давным-давно, начали вводить метрики скорости, то обнаружили, что чем дальше пользователь от Москвы, тем медленнее у него работает почта. Почему? Все очень просто: наши ДЦ тогда находились в столице, а скорость света имеет конечное значение. Сигналу надо преодолевать тысячи километров по проводам. Простой расчет показывает, что расстояние в 2000 км свет пройдет примерно за 7 мс. В реальности потребуется даже больше времени, потому что свет путешествует не в вакууме и не по прямой, по пути встречается много маршрутизаторов и т. д. Таким образом, оптимизируй не оптимизируй, а каждый TCP-пакет будет иметь задержку в десятки миллисекунд. Естественно, что в такой ситуации вкладываться надо не в оптимизацию кода, а в создание CDN, чтобы любой пользователь оказался ближе к нам.
One more thing
Иногда получается, что вы видите ровные графики, а пользователи жалуются на тормоза. Это всегда означает, что либо у вас ошибка в измерениях, либо вы измеряете не то. Метрики надо стресс-тестировать, чтобы исключать ошибки в самих метриках. Причем стресс-тестирование должно выполняться не средствами самой метрики, а со стороны.
Замедляйте бэкенды, добавляйте циклы или отвечайте ошибками. Смотрите, как изменяются метрики на каждом этапе: от бэкенда к фронтенду и браузеру. Только так вы можете убедиться, что измеряете то, что действительно нужно.
Например, мы в стресс-тестировании как-то дошли до того, что каждый второй запрос отвечал ошибкой. Это позволило нам определить, входит перезапрос данных в метрики или нет.
Заключение
Очень важно, чтобы оптимизация не была единоразовой или от случая к случаю. Над метриками скорости надо организовывать процесс. Для начала хватит реалтаймовых графиков и тестирования каждого релиза на скорость. Таким образом, мы останемся честными сами с собой и будем понимать, где именно мы медленные. Налаженный процесс позволяет отслеживать релизы, в которых произошли изменения в скорости, а значит, мы точно сможем это исправить. Даже если у вашей команды нет времени целенаправленно и постоянно заниматься оптимизацией, можно хотя бы следить за тем, чтобы не становилось хуже.
