> As of April 10, 2024,
> three months later,
> this article has been blocked by Roskomnadzor (RKN)
> within the territory of the Russian Federation.
> It has also been removed from the web archive archive.org.
> The article on Habr remains accessible from IP addresses in other countries.
> Yes, now to read about VPNs, you need a VPN.
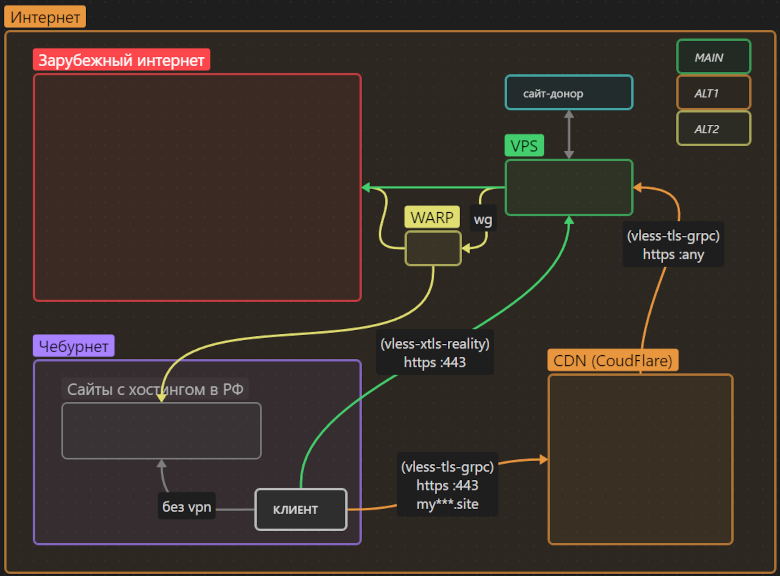
Against the backdrop of last year’s escalation of censorship in Russia, the articles by MiraclePTR were a breath of freedom for many Russian-speaking IT folks. I want to open the door to free information a bit wider and invite “non-techies” (“dummies”) who want to spin up a personal proxy server to bypass censorship but feel lost in the flood of information or got stopped by a confusing technical error.
In this article I’ve described a universal solution that provides transparent access to the global internet bypassing censorship, uses cutting-edge traffic obfuscation, doesn’t depend on the will of a single corporation, and most importantly has ample “safety margin” against interference from censors.
This article is aimed at “dummies” unfamiliar with the subject area. However, people “in the know” may also find something useful (for example, a slightly simpler setup for proxying via CloudFlare without having to run nginx on a VPS).
If you still don’t have a personal proxy to bypass censorship—this is your sign.