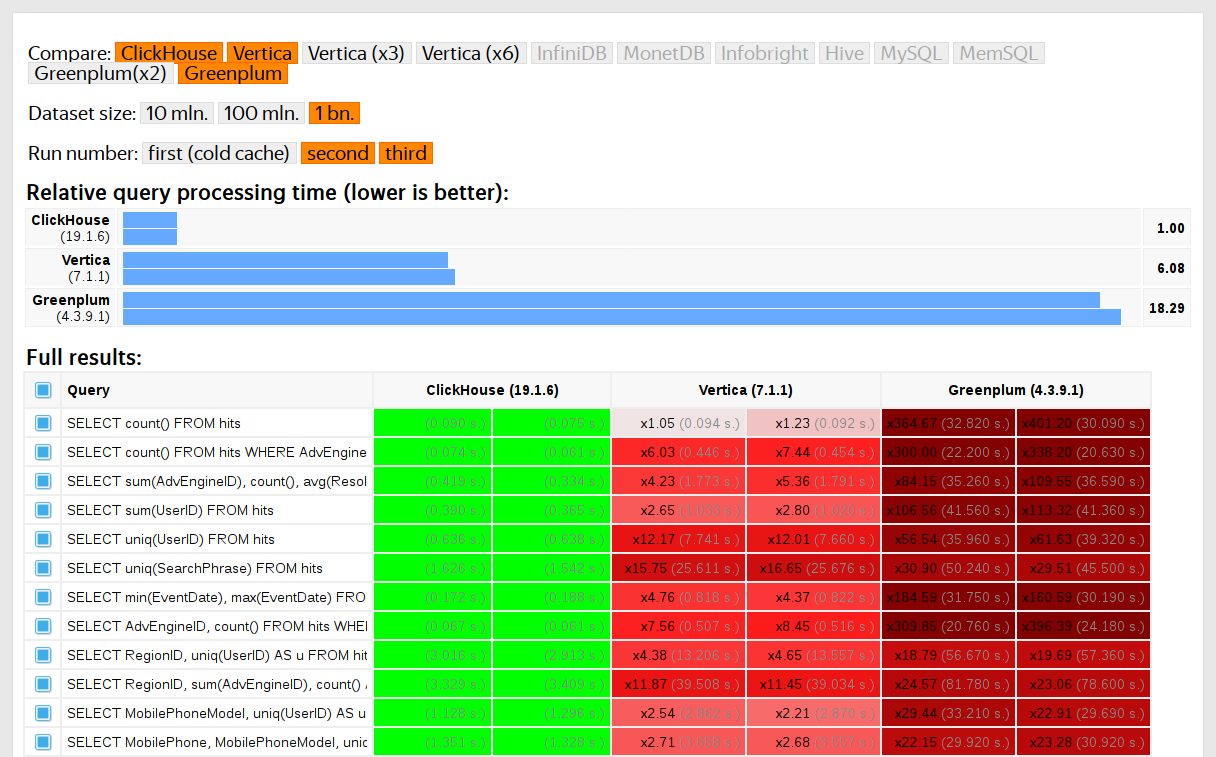
Big Data Tools Update 11 Is Out
3 min
EAP 11 of the Big Data Tools plugin for IntelliJ IDEA Ultimate, PyCharm, and DataGrip is available starting today. You can install it from the JetBrains Plugin Repository or inside your IDE.
Big Data Tools is a new JetBrains plugin that allows you to connect to Hadoop and Spark clusters and monitor nodes, applications, and jobs. It also brings support for editing and running Zeppelin notebooks inside IntelliJ IDEA and DataGrip, so you can create, edit, and run Zeppelin notebooks without ever having to leave your favorite IDE. The plugin offers smart navigation, code completion, inspections, quick-fixes, and refactoring inside notebooks.