
Domain-Specific system based on console JAVA applications
Medium
8 min
Review
Hello, Habr! I'd like to share my experience developing such a system.
The defining parameters of a domain-specific system are:
Hello, Habr! I'd like to share my experience developing such a system.
The defining parameters of a domain-specific system are:

In the big data era, data is one of the most valuable assets for enterprises. The ultimate goal of data analytics is to power swift, agile business decision making. As database technologies advance at a breathtaking pace in recent years, a large number of excellent database systems have emerged. Some of them are impressive in wide-table queries but do not work well in complex queries. Some support flexible multi-table queries but are held back by slow query speed.
Each type of data has a data model that best represents them. However, in real business scenarios, there is no such thing as ultra-fast data analytics under the perfect data model. Big data engineers sometimes have to make compromises on data models. Such compromises may cause long latency in complex queries or damage the real-time query performance because engineers must take the trouble to convert complex data models into flat tables.
New business requirements put forward new challenges for database systems. A good OLAP database system must be able to deliver excellent performance in both wide-table and multi-table scenarios. This system must also reduce the workload of big data engineers and enable customers to query data of any dimension in real time without worrying about data construction.

Apache Druid has been a staple for real-time analytics. However, with evolving and sophisticated analytics demands, it has faced challenges in satisfying modern data performance needs. Enter StarRocks, a high-performance, open-source analytical database, designed to adeptly meet the advanced analytics needs of contemporary enterprises by offering robust capabilities and performance.
In this article, we’ll explore the functionalities, strengths, and challenges of both Apache Druid and StarRocks. Using practical examples and benchmark results, we aim to guide you in identifying which database might best meet your data needs.

The “test everything” principle doesn’t improve data quality — it destroys it. Hundreds of useless alerts create noise that drowns out truly important signals, and the team stops responding to them. Google and Monzo have already moved away from this approach.
Here’s how to shift from blanket testing to targeted checks at nodes with the greatest impact radius — and why one well-placed test at the source is worth more than a hundred checks downstream.

Filename Extension: .6nf
6NF File Format is a new bitemporal, sixth-normal-form (6NF)-inspired data exchange format designed for DWH and for reporting. It replaces complex hierarchical formats like XBRL, XML, JSON, and YAML

This world needs a new theory — a theory that could describe all the theories on the planet. A theory that could easily describe philosophy, mathematics, physics, and psychology. The one that makes all kinds of sciences computable.
This is exactly what we are working on. If we succeed, this theory will become the unified meta-theory of everything.
A year has passed since our last publication, and our task is to share the progress with our English-speaking audience. This is still not a stable version; it’s a draft. Therefore, we welcome any feedback, as well as your participation in the development of the links theory.
As with everything we have done before, the links theory is published and released into the public domain — it belongs to humanity, that means, it is yours. This work has many authors, but the work itself is far more important than any specific authorship. We hope that today it can become useful to more people.
We invite you to become a part of this exciting adventure.

Author: Sergey Lukyanchikov, C-NLTX/Open-Source
Disclaimer: The views expressed in this document reflect the author's subjective perspective on the current and potential capabilities of jBPM.
This text presents jBPM as a platform for orchestrating external AI-centric environments, such as Python, used for designing and running AI solutions. We will provide an overview of jBPM’s most relevant functionalities for AI orchestration and walk you through a practical example that demonstrates its effectiveness as an AI orchestration platform:

In recent years, discussions about the environmental impact of information and communication technologies (ICTs) have largely revolved around hardware — data centers, electronic waste, and energy consumption. However, an equally important factor has been overlooked: the software development methodologies themselves.
When I read the UNCTAD “Digital Economy Report 2024”, I was struck by the complete absence of any mention of how programming methodologies impact sustainability. There was no discussion of whether developers use algorithm-centric or code-centric methodologies when creating software, nor how these choices affect the environment.
This realization led me to introduce the concept of Eco-Methodological Sustainability — a new approach that highlights the role of structured software development methodologies in shaping an environmentally sustainable future for the digital economy.

Apache Kafka is a distributed event-streaming platform designed to handle real-time data feeds. It allows applications to publish, process, and subscribe to streams of data in a highly scalable, fault-tolerant manner.

In today's digital world, where applications process increasing amounts of sensitive data, ensuring reliable user authentication is critical. Authentication is the process of verifying the identity of a user who is trying to access a system. A properly chosen authentication method protects data from unauthorized access, prevents fraud, and increases user confidence.
However, with the development of technology, new authentication methods are emerging, and choosing the optimal solution can be difficult. This article will help developers and business owners understand the variety of authentication approaches and make informed choices.

Wearable Digital Health Technologies for Monitoring in Cardiovascular Medicine
This review article presents a three-part true-life clinical vignette that illustrates how digital health technology can aid providers caring for patients with cardiovascular disease. Specific information that would identify real patients has been removed or altered. Each vignette is followed by a discussion of how these methods were used in the care of the patient.
Below, we will discuss user-defined aggregation functions (UDAF) using org.apache.spark.sql.expressions.Aggregator, which can be used for aggregating groups of elements in a DataSet into a single value in any user-defined way.
Let’s start by examining an example from the official documentation that implements a simple aggregation
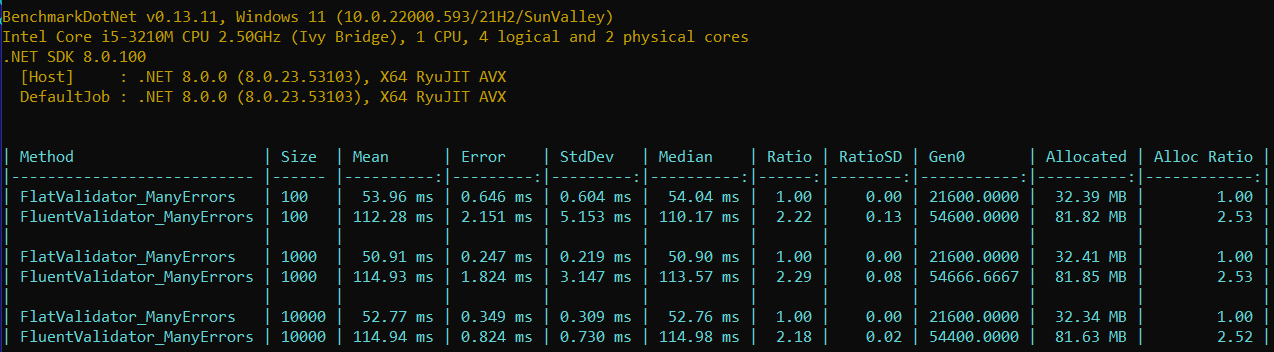
This is a step-by-step research of a clear and intuitive approach to validate custom data in .NET applications with help of the Minimal API filters and the FlatValidator.

In the evolving landscape of database technology, choosing the right database management system is crucial for the efficiency and scalability of applications. This article presents a detailed comparison of the performance between Microsoft's CosmosDB and MS SQL Server. We'll examine how each database performs under various load conditions and share some interesting findings.

No matter how many degrees you have or how high your experience level is, your recruiters need to evaluate your knowledge of UX design as a whole. But keep in mind that a job interview is not an exam, so here you are expected not to recite the textbook definitions learned by heart, but rather share your personal understanding of UX and your role as a designer in general. Consider talking about how you define UX, what creates value in the design, what are the necessary parts of a UX design process, what are the current trends in UX. You might also be asked to explain the difference between UI and UX to see how you understand the role of each in the development process.
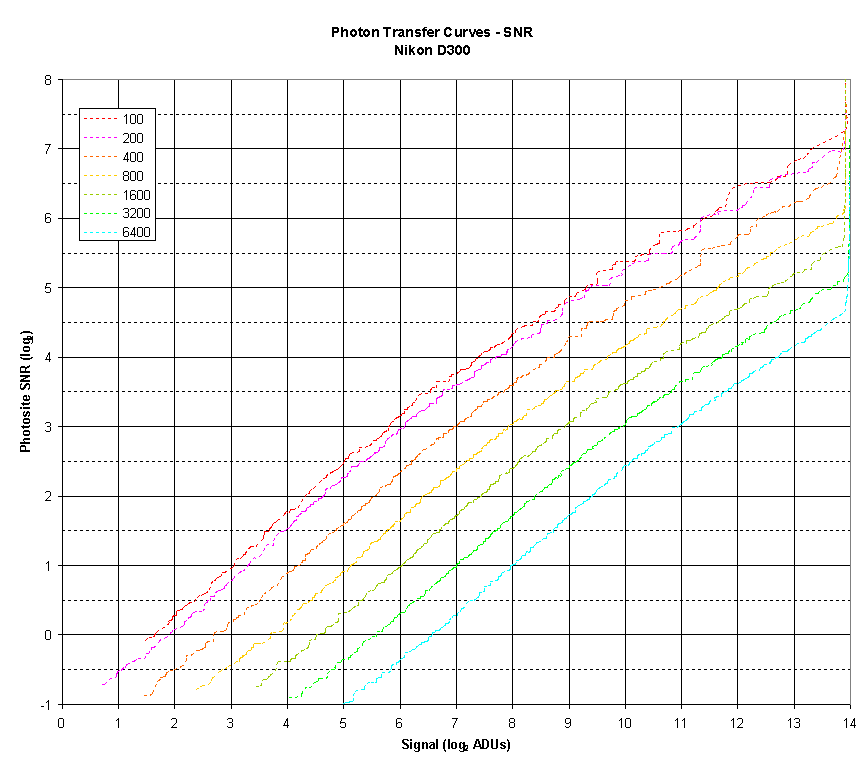
Hello, everyone! In this post, let's talk about how to (more) accurately measure the dynamic range of a camera sensor and what can be done with these measurements.
Of course, I am not an expert in computer vision, a programmer or a statistician, so please feel free to correct me in the comments if I make mistakes in this post. Here my interest was primarily focused on everyday and practical tasks, such as photography, but I believe the results may also be useful to computer vision professionals.

Let’s imagine you need access to the real-time data of some smart contracts on Ethereum (or Polygon, BSC, etc.) like Uniswap or even PEPE coin to analyze its data using the standard data scientist/analyst tools: Python, Pandas, Matplotlib, etc. In this tutorial, I’ll show you more sophisticated data access tools that are more like a surgical scalpel (The Graph subgraphs) than a well-known Swiss knife (RPC node access) or hammer (ready-to-use APIs). I hope my metaphors don’t scare you ?.
This article aims at explaining the mathematical sense of the Principal Component Analysis (PCA) in practice.

Brief problem formulation
The program accepts as input the absolute path to the image in the bmp extension and the path where you save the result of the work. Then, it rotates the image by 90 degrees counterclockwise. Afterwards, the program saves the new image.
The program is executed on C.
